stable diffusion论文解读
High-Resolution Image Synthesis with Latent Diffusion Models
论文背景
LDM是Stable Diffusion模型的奠基性论文
于2022年6月在CVPR上发表

传统生成模型具有局限性:
- 扩散模型(DM)通过逐步去噪生成图像,质量优于GAN,但直接在像素空间操作导致高计算开销。
- 随着分辨率提升,扩散模型的优化和推理成本呈指数级增长,限制了实际应用
如DDPM生成的图像分辨率普遍不超过256×256,而LDM生成的图像分辨率可以超过1024×1024.
而LDM通过将扩散过程迁移至潜在空间,解决了传统模型的计算瓶颈,同时保持生成质量与灵活性。
论文框架方法
论文中框架示意图如图所示:
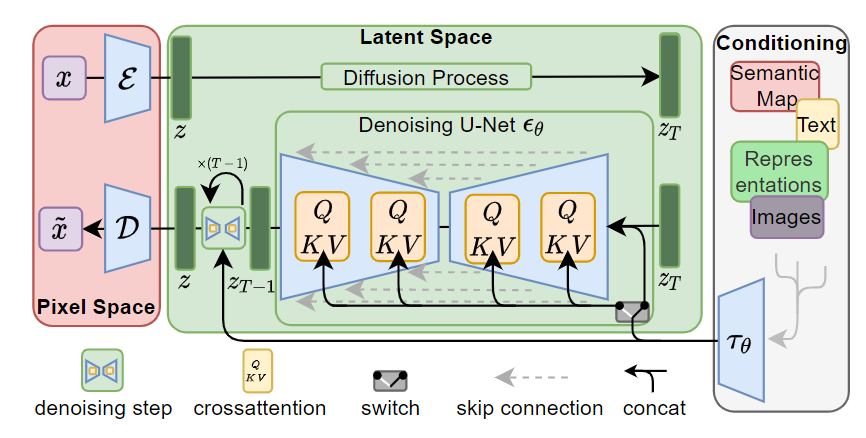
在训练阶段:
- 预训练自动编码器(AE)和条件生成编码器(如clip)
- 输入图片x,经过自动编码器压缩到隐空间ε(x)=z
- 随机采样时间步T,对Z进行加噪到ZTZT
- 对右边框里的条件进行条件编码τθ(y)τθ(y)和ZTZT一起输入UNet网络中
- 进行交叉注意力计算,其中ZTZT作为Q向量,τθ(y)τθ(y)作为K,V向量计算注意力,这样做是让图像的每个位置根据文本的语义来决定关注哪些部分
- 最后Unet输出两个向量,一个是无条件预测噪声,一个是文本预测噪声。
无条件预测噪声输入是空字符串
- 使用CFG计算最终预测噪声ϵguided(zt,t,τθ(y))=ϵθ(zt,t,τθ(y))+s⋅(ϵθ(zt,t,τθ(y))−ϵθ(zt,t,∅))ϵguided(zt,t,τθ(y))=ϵθ(zt,t,τθ(y))+s⋅(ϵθ(zt,t,τθ(y))−ϵθ(zt,t,∅))
- 使用损失函数进行反向传播计算
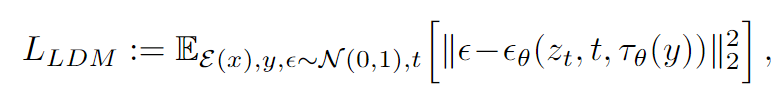
在生成阶段:
- 以随机噪声ZTZT作为起点
- 输入文本作为条件,编码后一起进入Unet进行交叉注意力计算
- 输出预测噪声ϵguided(zt,t,τθ(y))ϵguided(zt,t,τθ(y))
- 使用调度器进行逐步去噪计算(如DDPM,DDIM)成为ZT−1ZT−1
- 重复以上过程,直到Z
- 通过自动编码器的解码器部分把Z迁移到像素空间,D(z),即生成图像
交叉注意力机制中的维度变换
图像编码后变成 C=4, H'=64, W'=64,展平后作为Q(zt⇒Q∈R(H′W′)×dzt⇒Q∈R(H′W′)×d),文本通过编码器的编码表示为c=[t1,t2,...,tL]⇒Embedding∈RL×dc=[t1,t2,...,tL]⇒Embedding∈RL×d,K和V表示为K,V∈RL×dK,V∈RL×d,计算注意力权重A=softmax(QK⊤√d)∈R(H′W′)×LA=softmax(QK⊤d)∈R(H′W′)×L,输出为Attention(Q,K,V)=A⋅V∈R(H′W′)×dAttention(Q,K,V)=A⋅V∈R(H′W′)×d
# 潜在空间输入(prepare_latents生成)
latents.shape = (batch_size * num_images_per_prompt, 4, H//8, W//8)# 文本嵌入处理(encode_prompt输出)
prompt_embeds.shape = (batch_size, max_sequence_length, embedding_dim)# IP适配器图像嵌入处理
image_embeds[0].shape = (batch_size * num_images_per_prompt, num_images, emb_dim)# UNet输入/输出维度
latent_model_input.shape = [batch*2, 4, H//8, W//8] # 当启用CFG时
noise_pred.shape = [batch*2, 4, H//8, W//8] # UNet输出噪声预测
假设参数设置
prompt = "一只坐在月球上的猫"
height = 512
width = 512
num_images_per_prompt = 1
guidance_scale = 7.5
batch_size = 1 # 根据prompt长度自动确定# 关键计算步骤演示
# ---------------------------
# 步骤1:潜在空间(latents)维度计算
latents_shape = (batch_size * num_images_per_prompt, # 1*1=14, # UNet输入通道数height // 8, # 512/8=64width // 8 # 512/8=64
)
print(f"潜在空间维度: {latents_shape}") # -> (1, 4, 64, 64)# 步骤2:文本编码维度(假设使用CLIP模型)
prompt_embeds_shape = (batch_size, 77, # CLIP最大序列长度768 # CLIP文本编码维度
)
print(f"文本嵌入维度: {prompt_embeds_shape}") # -> (1, 77, 768)# 步骤3:CFG处理后的嵌入
if guidance_scale > 1:prompt_embeds = torch.cat([negative_embeds, positive_embeds])print(f"CFG嵌入维度: {prompt_embeds.shape}") # -> (2, 77, 768)# 步骤4:UNet输入维度(假设启用CFG)
latent_model_input = torch.cat([latents] * 2)
print(f"UNet输入维度: {latent_model_input.shape}") # -> (2, 4, 64, 64)# 步骤5:噪声预测输出
noise_pred = unet(latent_model_input, ...)[0]
print(f"噪声预测维度: {noise_pred.shape}") # -> (2, 4, 64, 64)# 步骤6:CFG调整后的噪声
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
print(f"调整后噪声维度: {noise_pred.shape}") # -> (1, 4, 64, 64)# 最终输出图像
image = vae.decode(latents / vae.config.scaling_factor)[0]
print(f"输出图像维度: {image.shape}") # -> (1, 3, 512, 512)def cross_attention(query, key, value):# 输入维度说明# query: 来自潜在噪声 [batch=2, 4*64*64=16384] → 投影为 [2, 16384, 768]# key/value: 来自文本嵌入 [2, 77, 768]# 步骤1:计算注意力分数attention_scores = torch.matmul(query, # [2, 16384, 768] key.transpose(-1, -2) # [2, 768, 77] → 转置后维度) # 矩阵乘法结果 → [2, 16384, 77]# 步骤2:计算注意力权重attention_probs = torch.softmax(attention_scores, # [2, 16384, 77]dim=-1 # 对最后一个维度(文本标记维度)做归一化) # 保持维度 [2, 16384, 77]# 步骤3:应用注意力到valueoutput = torch.matmul(attention_probs, # [2, 16384, 77]value # [2, 77, 768]) # 结果维度 → [2, 16384, 768]# 步骤4:重塑为潜在空间维度output = output.view(2, 4, 64, 64, 768) # 恢复空间结构output = output.permute(0, 4, 1, 2, 3) # [2, 768, 4, 64, 64]output = self.to_out(output) # 通过最后的线性层投影回4通道return output # [2, 4, 64, 64]
数据集以及指标介绍
数据集介绍

CelebA-HQ 256 × 256数据集,是一个大规模的人脸属性数据集,拥有超过200K张名人图片,每张图片都有40个属性注释(如身份,年龄、表情、发型等)。

从Flickr网站爬取的人脸数据集集合,涵盖多样化的年龄、种族、表情、配饰(如眼镜、帽子)等属性

这两个数据集都是LSUN(大规模场景理解)数据集的子集,两个数据集分别表示教堂和卧室场景的数据,包含教堂建筑的不同视角、结构和环境条件,覆盖多样化的卧室场景,包括不同装修风格、家具布局和光照条件
指标介绍
IS分数介绍
Inception Score 的定义为:
IS(G)=exp(Ex∼pg[DKL(p(y|x)∥p(y))])IS(G)=exp(Ex∼pg[DKL(p(y|x)‖p(y))])
x~pg:生成图像样本来自生成模型的分布 。
p(y|x):通过预训练分类器(如Inception v3)对生成图像的类别预测概率分布。
p(y):预测类别的边缘分布。类别可以是猫,狗,猪等诸如此类的动物。
其中如果生成图像明确、质量高,则p(y|x)的熵就会比较低,如果生成图像比较多样,则p(y)的熵就会较高,体现在公式中则IS分数会较高。
FID分数介绍
主要是计算生成图像分布和真实图像分布在特征空间中的距离
公式FID=∥μr−μg∥22+Tr(Σr+Σg−2(ΣrΣg)12)FID=‖μr−μg‖22+Tr(Σr+Σg−2(ΣrΣg)12)
μr,Σrμr,Σr:真实图像分布的均值和协方差矩阵。
μg,Σgμg,Σg:生成图像分布的均值和协方差矩阵。
∥μr−μg∥22‖μr−μg‖22:欧几里得距离的平方。
TrTr:矩阵的迹。
(ΣrΣg)12(ΣrΣg)12:协方差矩阵的乘积的平方根。
两个分布的均值和协方差越低,FID越低,生成图像质量越接近生成的图像
prec和recall
这里的指标和一般理解的不一样。
会先用Inception网络分别提取真实图像和生成图像的特征点
用集合的角度解释:
Precision ≈ 生成图像中,有多少落在真实图像分布的“支持区域”里(真实性)
Recall ≈ 真实图像中,有多少被生成图像的“支持区域”覆盖(多样性)
实验分析
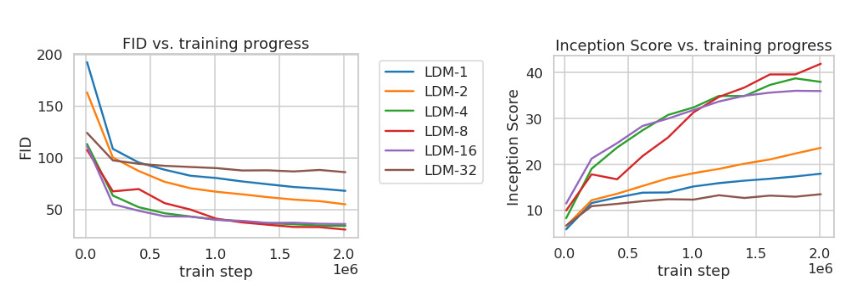
研究不同下采样因子f对生成图像质量和训练效率的影响
下采样因子:指的是自动编码器中的参数。
可以看到下采样因子为4或8时表现最好。因为如果因子过小,会导致维度高,计算缓慢,因子过大,会损失很多信息,导致最后生成图像生成质量较差
后续的实验将基于此展开
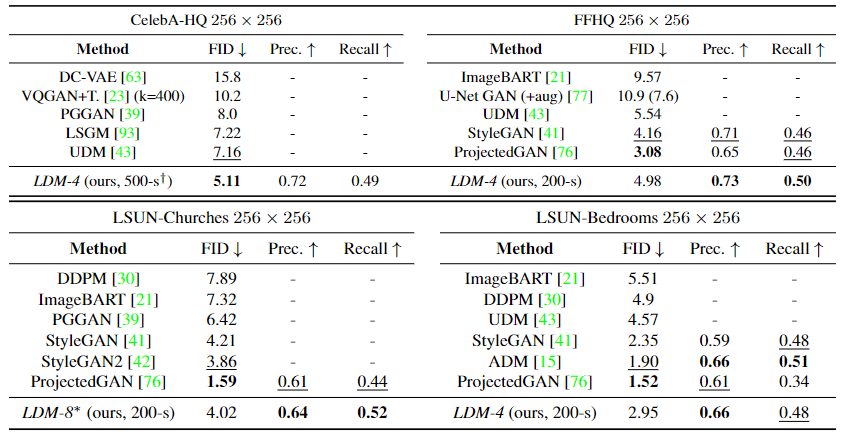
在这个实验里可以看到,LDM在CelebA-HQ中取得了最优的FID分数,在其他数据集上的表现也是中规中矩。
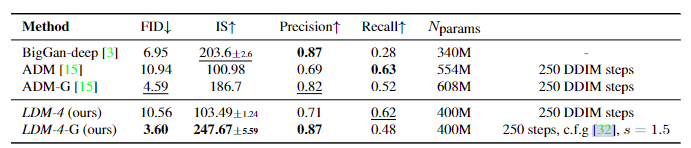
这个实验里展示了LDM在类别生成任务中的表现,可以看到使用cfg引导的LDM展现出了非常优秀的性能,在FID和IS分数上表现优异,虽然recall略低,但是使用的参数量也大幅减少了。