Claude 4 系列 Opus 4 与 Sonnet 4正式发布:Claude 4新特性都有哪些?
随着 Claude 4 系列(Opus 4 与 Sonnet 4)的正式发布,Anthropic 把自家大模型从“会聊天”推进到“能当自主代理”──不仅推理更深、上下文更长,还内置代码执行、多模态理解、工具调用等一揽子全新能力;同时,它已在 GitHub Copilot、Amazon Bedrock 与 Google Vertex AI 等平台同步上线,并在多项基准上刷新行业纪录。本文按“先鸟瞰,再拆解”的思路,带你一次看懂 Claude 4 的全部新特性、性能参数、生态落地与迁移要点。

文章目录
- 一、Claude 4 系列概述
- 二、核心规格速览
- 三、新特性深度解析
- 1. 深层推理与规划
- 2. 代理化执行(Agentic Capability)
- 3. 代码生态一体化
- 4. 超长上下文与记忆
- 5. 原生多模态
- 6. 混合推理引擎
- 7. 新 API 组件
- 8. 安全与合规升级
- 四、生态集成现状
- 五、性能基准与实测
- 六、价格与可用性
- 七、竞争格局速览
- 八、开发者迁移与最佳实践
- 九、常见问答
一、Claude 4 系列概述
- 发布时间:2025 年 5 月 23 日
- 型号:旗舰 Opus 4 与高性价比 Sonnet 4,皆为“混合推理(hybrid-reasoning)”模型
- 定位:持续数小时的自主任务(Agentic Workflows)与“一键即回”的快速问答两种模式可随需切换
二、核心规格速览
| 指标 | Opus 4 | Sonnet 4 |
|---|---|---|
| 上下文窗口 | 500 k – 1 M tokens(官方计划扩至 2 M) | 200 k tokens(兼顾速度) |
| 多模态 | 原生文本 + 图像 + 音频输入 | 同上 |
| 代码执行 | 支持沙箱运行、绘图和数据处理 | 支持 |
| “思考模式” | Extended-Thinking β,可在深思 vs. 工具用途中自动权衡 | 同上 |
| 安全级别 | ASL-3,强化奖励黑客防护 | ASL-2 |
三、新特性深度解析
1. 深层推理与规划
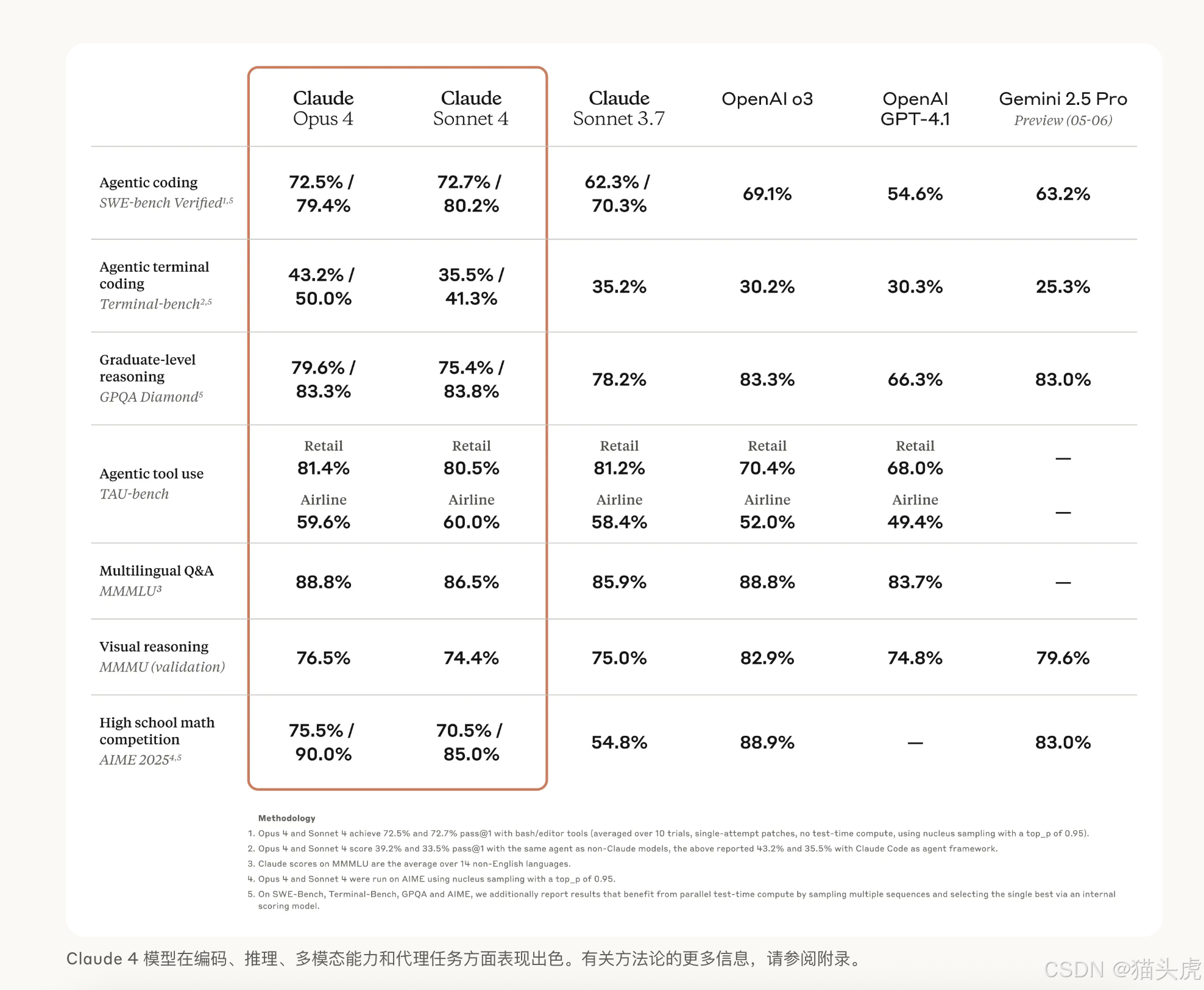
Opus 4 在 TAU-bench 和 Pokémon 长程任务 中表现突出:能连续 24 h 自主游戏,对比 3.x 版仅 45 min 的耐力大幅提升 。
2. 代理化执行(Agentic Capability)
- 多阶段工作流:可自动拆解目标、调用外部搜索与工具,再合并结果 。
- 思考摘要(Thinking Summaries):实时暴露链式推理,让开发者审计中间步骤 。
3. 代码生态一体化
- Claude Code CLI:本地命令行代理,已实测连续编程 7 h 修改多文件项目 。
- 沙箱 Code-Run 工具:模型可运行 Python/JS 片段、加载数据集并生成图表 。
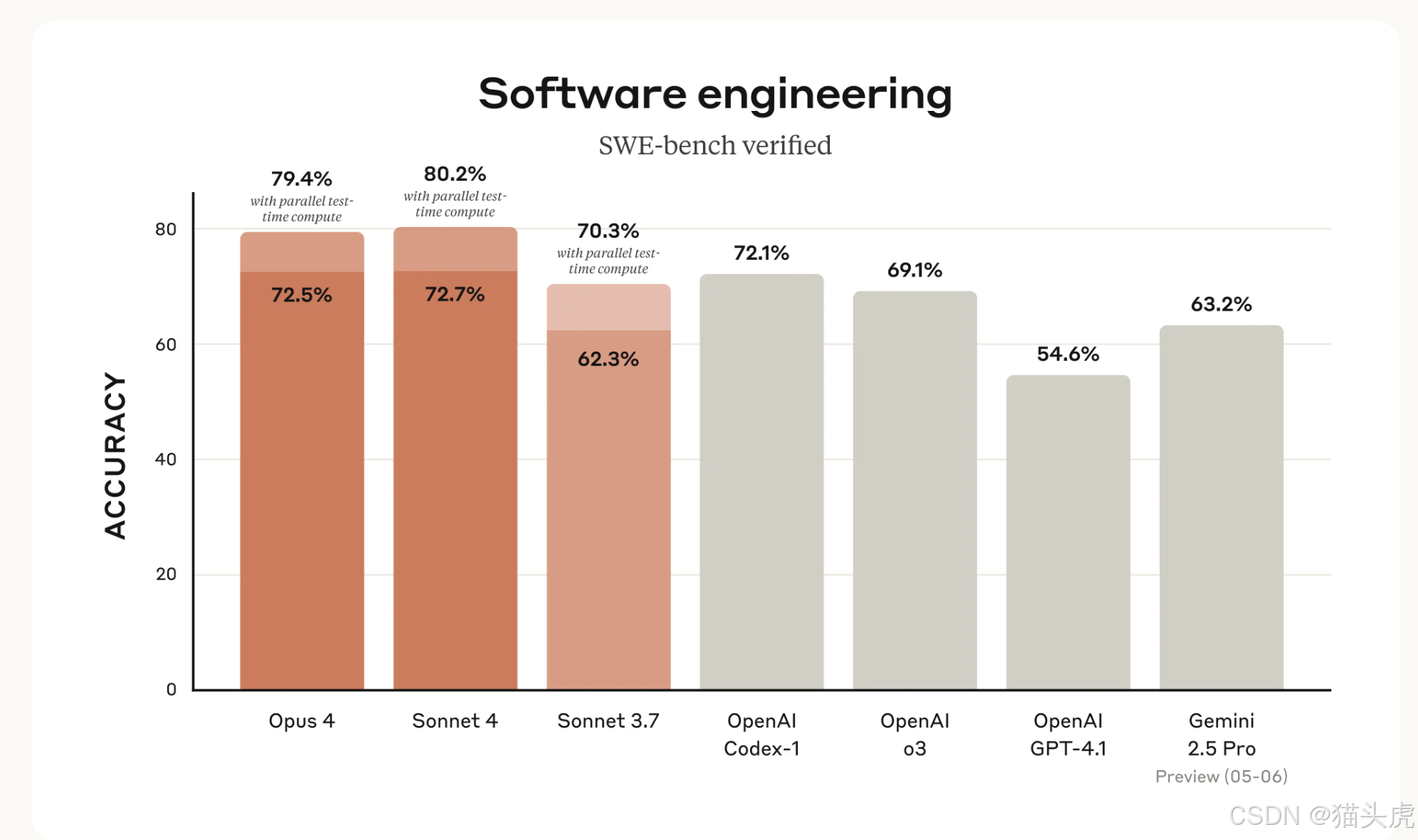
- SWE-bench 夺冠,超越 GPT-4o 与 Gemini 2.5 Pro 在复杂重构上的得分 。

4. 超长上下文与记忆
非官方测试显示 Opus 4 在 500 k token 文档检索中仍能精准引用关键信息,Reddit 社区已放出截屏 。
5. 原生多模态
Claude 4 模型卡确认已开放 Vision & Audio 接口,支持图像诊断、音频转写与语义理解等场景 。
6. 混合推理引擎
“Near-Instant” 模式最快数百毫秒返回;“Extended-Thinking” 模式可让 AI 在后台思考数分钟直至最佳解答,开发者可通过参数 mode=extended 切换 。
7. 新 API 组件
Anthropic 同步发布 Files API、MCP 连接器 与 Prompt Cache(1 h),方便长链调用及大文件传输 。
8. 安全与合规升级
- ASL-3 级别风险控制:引入新型奖励护栏,减少“奖励黑客(reward hacking)” 2 。
- 多层次内容过滤与可解释日志,提高企业审计可行性 。
四、生态集成现状
| 平台 | 集成方式 | 亮点 |
|---|---|---|
| Amazon Bedrock | anthropic.claude-opus-4 / anthropic.claude-sonnet-4 | 服务器无锁切换模型、支持代理链规划 |
| Google Vertex AI | “Partner Model” 上线 | 直接调用 Tool-Use 扩展,与 Gemini 系列互补 |
| GitHub Copilot | Public Preview | Copilot 在大型重构里默认启用 Sonnet 4,复杂修复触发 Opus 4 |
五、性能基准与实测
- SWE-bench 代码修复领先 7 pp 于 GPT-4o 。
- TAU-bench 复杂代理排名第一,平均任务深度 1 031 步 。
- Humanity’s Last Exam 取得 18.8 % 的前沿成绩 。
- The Verge 实测显示在连贯记忆任务中“短路率”降低 65 % 。
- TechCrunch 证实 Claude 4 能在多步工作流中保持聚焦且不遗忘中途指令 。
六、价格与可用性
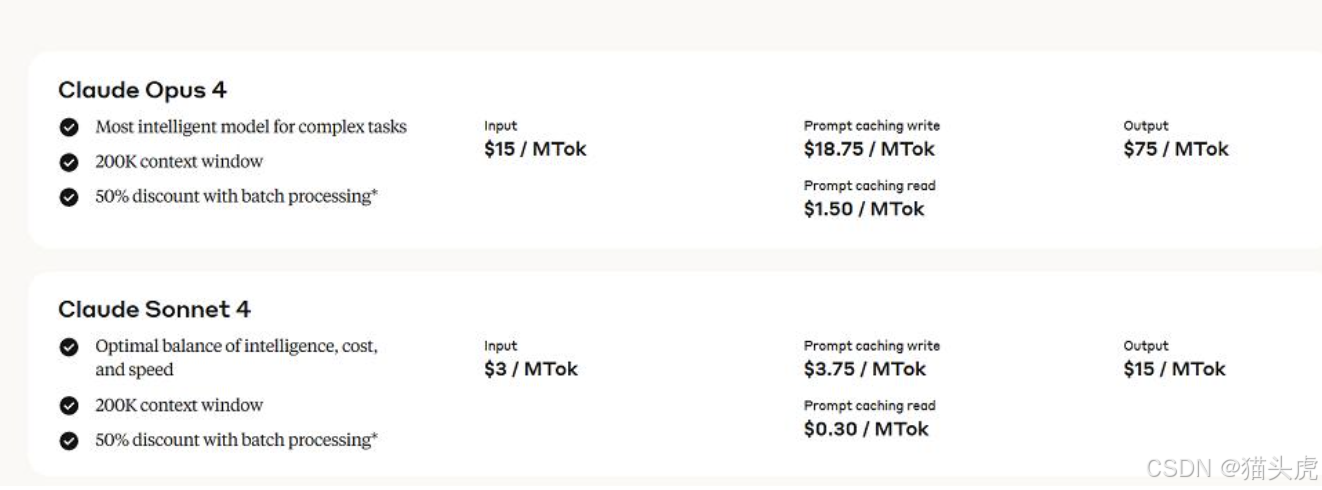
- Opus 4:付费套餐可用,Token 单价较 Opus 3 提升约 20 %,但同等任务总成本下降 35 %(推理效率提升) 。
- Sonnet 4:付费与免费档位均可调用,免费用户每日额度 50 messages 。
七、竞争格局速览
| 模型 | 代码能力 | 长上下文 | 多模态 | 代理化 |
|---|---|---|---|---|
| Claude Opus 4 | ★★★★★ | 1 M | ✅ | ★★★★★ |
| GPT-4o (OpenAI o3) | ★★★★☆ | 128 k | ✅ | ★★★★☆ |
| Gemini 2.5 Pro | ★★★★☆ | 2 M | ★★★★☆ | ★★★★☆ |
Claude 4 在编码与长任务可靠性上仍占优势,但多模态深度由 Gemini 领跑,OpenAI 则在推理-速度权衡方面策略更灵活。
八、开发者迁移与最佳实践
- API 端点升级:
anthropic_version=v4即可切换;旧版 v3 SDK 向后兼容,但不支持 Files API 。 - Prompt 适配:利用“思考摘要”减少内部 chain-of-thought 冗余,避免 prompt inflation。
- 工具调用策略:先让模型自主决定
invoke_tool=true,再限制白名单指令以降低滥用风险 。 - 本地缓存:Prompt Cache 能将 60 min 内重复子任务成本降至 1/100。
九、常见问答
Q 1:Opus 4 真能读 1 M tokens 吗?
社区反馈在 750 k 量级已可稳定运行;1 M 需企业计划白名单 。
Q 2:多模态 API 何时开放上传视频?
Anthropic 官方称“未来数月”将扩容至短视频片段测试 。
Q 3:安全差异 VS GPT-4o?
Claude 4 默认启用更严格 reward hacking 检测(ASL-3),OpenAI 在 o3 中采用 RL-HF + safety-refiner,两者思路不同但级别相近 。
这一代 Claude 4 以更长记忆、更深推理和可执行工具链,瞄准“真·AI 代理”落地场景。若你的应用需让大模型独立完成复杂、长链、多步骤任务,且对代码可靠性要求极高,Opus 4 会是值得尝鲜的选择;而追求成本-性能平衡或面向免费用户,则可先用 Sonnet 4 作为主力。