pandas :从入门到进阶的系统实践笔记
pandas :从入门到进阶的系统实践笔记
pandas 是 Python 在结构化数据处理领域的事实标准。本篇将数据分析常见的工作流拆解为:
- 数据结构与基本读写
- 载入后检查与类型管理
- 行列选取与条件过滤
- 缺失值、去重与映射更新
- 分组、聚合与交叉表
- 重塑、连接与层次索引
- 时间序列、滚动窗口与性能优化
文章目录
- pandas :从入门到进阶的系统实践笔记
- 1 数据结构与基本读写 —— 最小可运行样例
- 2 载入后检查与类型管理 —— 保证“数据正确”再谈分析
- 3 行列选取与条件过滤 —— 定位信息的三种方式
- 4 缺失值、去重与映射更新 —— 清洗阶段的高频操作
- 5 分组、聚合与交叉表 —— 把“描述统计”写在一行里
- 1 `dept_report` :分组聚合的链式写法
- 为何还要 `reset_index()`?
- 1. 分组聚合后,分组键自动变成 **索引**
- 2. `reset_index()` 的作用
- 2 `age_bins` 与 `pd.crosstab` :将连续值离散化并查看分布
- 6 重塑、连接与层次索引 —— 将表格转换为算法友好的形态
- 1. 宽长变换、表连接与层次索引 —— 结构化数据的“形态管理”
- 预置原始表 `df`
- 2 `merge`:按 **`name`** 把奖金表拼进主表
- 3 `set_index`:构造 **层次索引**(`MultiIndex`)
- 小结
- 7 时间序列、滚动窗口与性能优化 —— 面向生产的最后一公里
- 结语
1 数据结构与基本读写 —— 最小可运行样例
场景:人事部门收到一份 CSV,需要快速浏览并追加几条测试数据。
import pandas as pd# ① 读入示例数据(如无文件可直接执行字典示例)
df = pd.DataFrame({'name' : ['Tom', 'Lucy', 'Tom', 'Jack', 'Tom'],'age' : [20, 21, 23, 22, 25],'dept' : ['IT', 'HR', 'IT', 'FIN', 'IT'],'salary': [5800, 6200, 5900, 6500, 6100]
})# ② 演示写出到本地与重新读入
df.to_csv('staff.csv', index=False)
df = pd.read_csv('staff.csv')
要点
DataFrame构造器可接收字典、NumPy 数组、列表嵌套、Series 字典等多种类型,键自动变列名;read_csv / to_csv类似“hello world”,后续可替换为read_excel、read_sql、to_parquet等更贴合生产场景的接口。
2 载入后检查与类型管理 —— 保证“数据正确”再谈分析
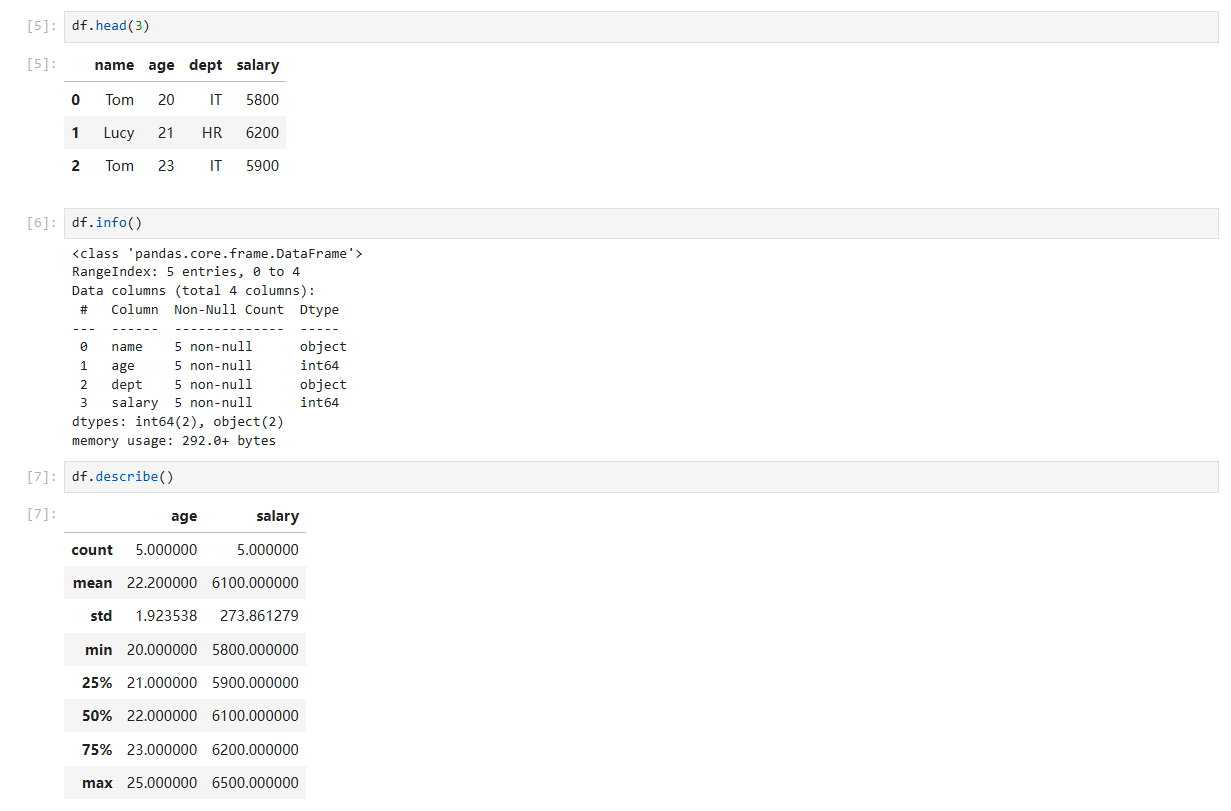
df.head(3) # 抽样检查字段顺序与取值
df.info() # 非空计数、字段类型、内存占用
df.describe() # 数值列描述统计
常见异常
| 现象 | 典型原因 | 修复思路 |
|---|---|---|
数字列被识别为 object | 文件中混入空格或千位分隔符 | pd.to_numeric(errors='coerce') |
| 内存占用过大 | 文本低基数字段仍用 object | 转换为 category |
出现 NaN | 非数字标记 (-、n/a) 未被识别 | read_csv(na_values=['-','n/a']) |
类型压缩例
df['dept'] = df['dept'].astype('category')
df['age'] = df['age'].astype('int16')
3 行列选取与条件过滤 —— 定位信息的三种方式
| 任务 | 推荐接口 | 说明 |
|---|---|---|
| 单列 | df['col'] | 返回 Series |
| 显式标签 | df.loc[row_label, col_label] | 安全、可读 |
| 整数位置 | df.iloc[row_idx, col_idx] | 不受标签影响 |
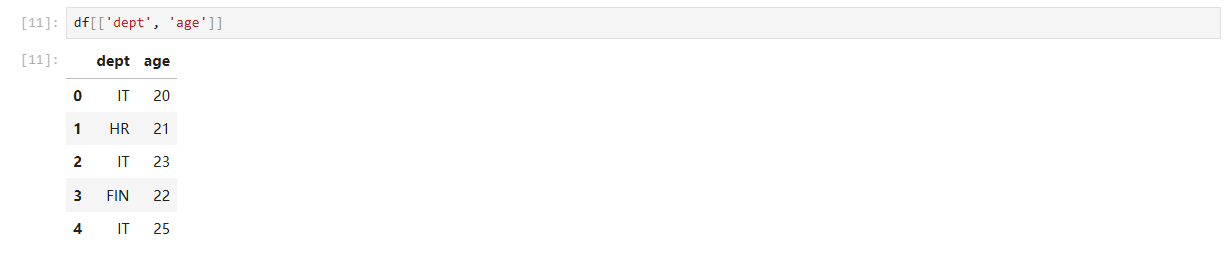
# 案例:查询 IT 部门、年龄大于 22 岁的员工
subset = df.loc[(df['dept'] == 'IT') & (df['age'] > 22),['name', 'age', 'salary']]
易错点:布尔条件必须用圆括号包裹,否则优先级导致
&对错位。



4 缺失值、去重与映射更新 —— 清洗阶段的高频操作
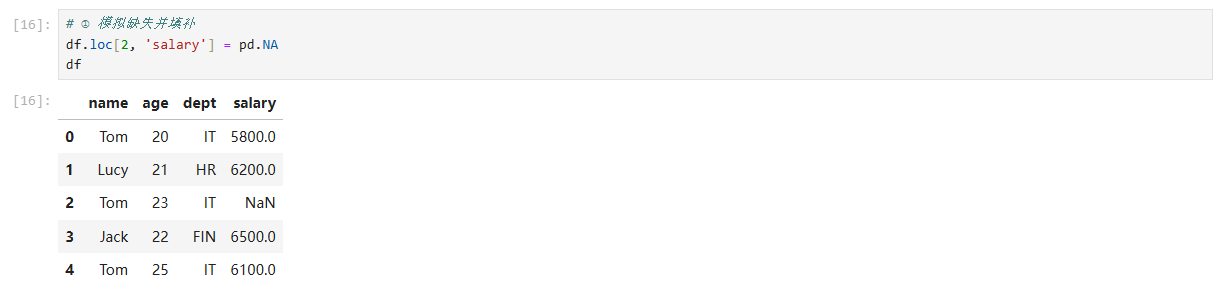
# ① 模拟缺失并填补
df.loc[2, 'salary'] = pd.NA
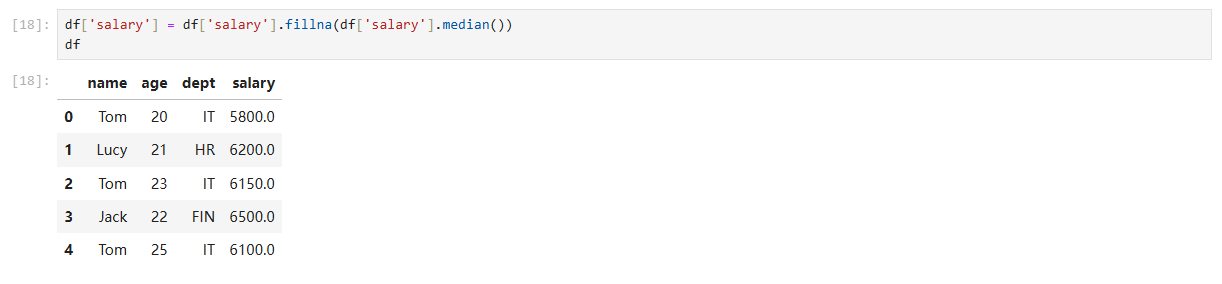
df['salary'] = df['salary'].fillna(df['salary'].median())
# ② 按 name 去重(保留首条)
df_unique = df.drop_duplicates('name')

# ③ 拓展业务:按映射表批量重命名部门
mapping = {'IT': 'TECH', 'FIN': 'FINANCE'}
df['dept'] = df['dept'].replace(mapping)
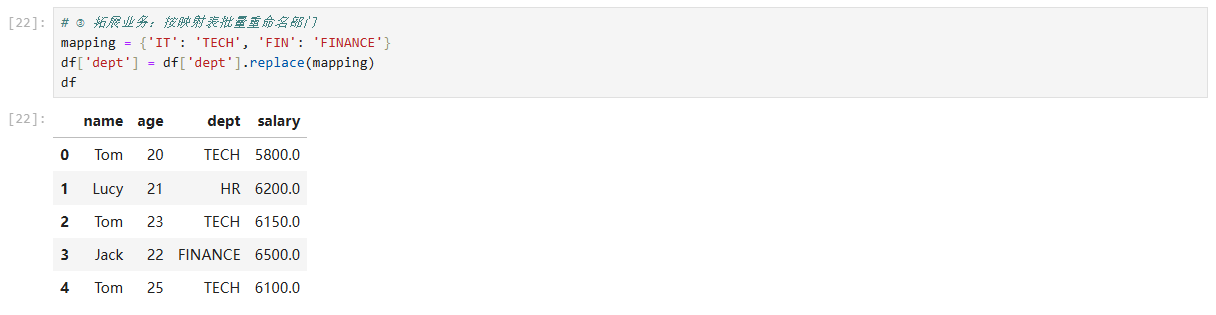
设计要点
fillna可接收标量、字典或同长度 Series;drop_duplicates支持keep='last'与keep=False(全部删除);replace同时支持字典/正则,优于循环apply。
5 分组、聚合与交叉表 —— 把“描述统计”写在一行里
dept_report = (df.groupby('dept').agg(count=('name', 'size'),avg_age=('age', 'mean'),avg_salary=('salary', 'mean')).reset_index()
)1 dept_report :分组聚合的链式写法
dept_report = (df.groupby('dept') # ←①.agg( # ←②count = ('name', 'size'), # ┐avg_age = ('age', 'mean'), # │avg_salary = ('salary', 'mean')) # ┘.reset_index() # ←③
)
| 步骤 | 关键调用 |
|---|---|
① df.groupby('dept') | 将整张表按 dept 列拆分为若干子表(IT 组、FIN 组等)。之后对每个子表单独做运算。返回值是 DataFrameGroupBy 对象。 |
② .agg(...) | 命名聚合 语法:新列名 = (原列名, 聚合函数) - ('name', 'size') 统计组内行数,起名 count(等价于 SQL 里的 COUNT(*))。 - ('age', 'mean') 计算年龄平均值,起名 avg_age。 - ('salary', 'mean') 计算工资平均值,起名 avg_salary。 |
③ .reset_index() | 分组键 dept 此时是索引;调用后把它恢复成普通列,得到“宽格式” DataFrame,方便后续与其他表连接或导出。 |
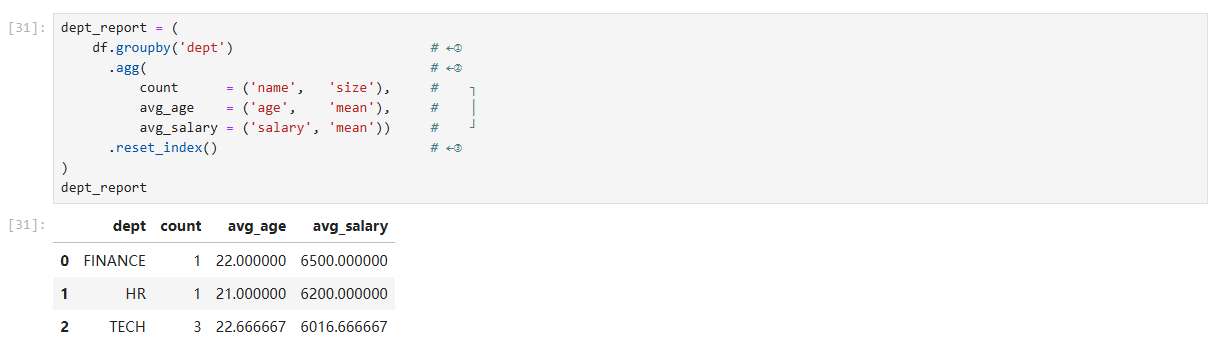
为何还要 reset_index()?
在 pandas 中,每个 DataFrame 都有两大部分:
| 组成 | 作用 | 默认形态 |
|---|---|---|
| 索引 (index) | 行标签,决定行的“名字” | 连续整数 0, 1, 2 … |
| 列 (columns) | 真正的数据字段 | 建表时给定的列名 |
1. 分组聚合后,分组键自动变成 索引
g = df.groupby('dept').agg(count=('name', 'size'))
print(g)
输出(省略列宽):
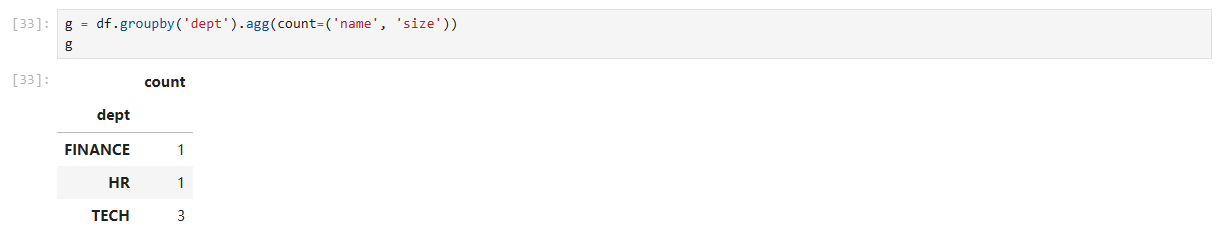
- 左边灰色区域就是 索引;此时
dept不再是普通列,而是行标签。 - 如果再继续链式运算(例如
g.loc['TECH'])很方便,但:g['dept']会报错——因为dept已不在columns中;- 想与另一张表做
merge、或直接to_csv()再导入数据库时,行索引通常会被忽略或丢失。
2. reset_index() 的作用
report = g.reset_index()
print(report)
输出:

dept被“搬”回数据列;- 行索引重新变成默认的整数 0, 1, 2;
- “宽格式 DataFrame”——每一列都是显式变量。
reset_index() 本质上是把“行标签”还原为“普通列”。
如果你的下一步打算 继续做分析(例如再次
groupby或.loc过滤),保留索引往往更方便;
而打算 连接其它表、导出或建模 时,把索引还原为列会减少额外处理——这就是它常被写在链式调用最后一步的原因。
2 age_bins 与 pd.crosstab :将连续值离散化并查看分布
age_bins = pd.cut(df['age'], # ←①bins=[0, 22, 25, 100], # ←②labels=['≤22', '23–25', '26+']) # ←③ct = pd.crosstab(df['dept'], # 行变量age_bins, # 列变量(刚得到的区间标签)normalize='index') # ←④
| 步骤 | 关键调用 |
|---|---|
① df['age'] | 选中待切分的连续变量——员工年龄。 |
② bins=[0, 22, 25, 100] | 设定三个闭区间:(0, 22]、(22, 25]、(25, 100]。首端默认开区间、末端闭区间,确保任何合法年龄只落入一个区间。 |
③ labels=[...] | 为每个区间指定易读标签:≤22、23–25、26+。生成结果是 Categorical Series,长度与 df 一致。 |
④ pd.crosstab(..., normalize='index') | 交叉表统计:行维度用 dept,列维度用刚得到的年龄段。 - 默认计数, - normalize='index' 把每行总计缩放为 1,得到行内比例,相当于说“在 IT 部门中,23–25 岁占 60 %”这类描述。 |
结果结构
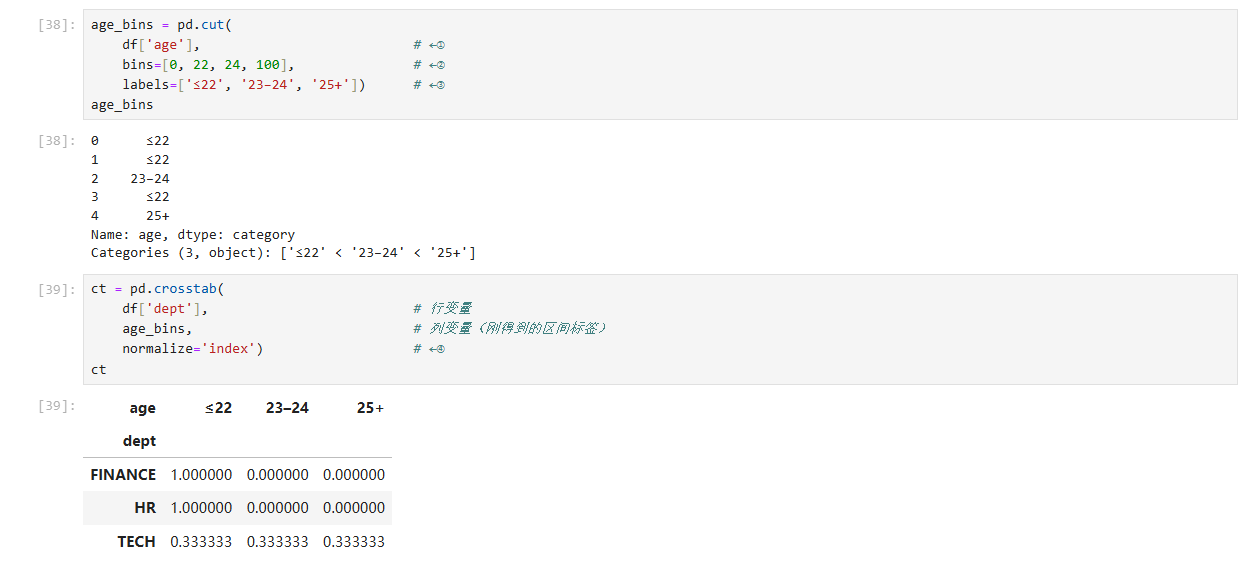
• 业务含义:
dept_report侧重“每个部门总体概况”,而交叉表ct进一步揭示“各部门内部年龄结构”。
• 常见扩展:若需要累计比例,可把normalize=None拿掉获得计数,再自行计算;如要显示百分比,后接ct.mul(100).round(1)。
6 重塑、连接与层次索引 —— 将表格转换为算法友好的形态
# 1) 宽转长:为可视化或 sklearn OneHotEncoder 做准备
long = df.melt(id_vars=['name'], value_vars=['age', 'salary'],var_name='metric', value_name='value')# 2) 合并奖金表
df_bonus = pd.DataFrame({'name': ['Tom', 'Lucy', 'Jack'],'bonus': [500, 450, 550]})
df_full = df.merge(df_bonus, on='name', how='left')# 3) 层次索引示例:部门、姓名双层索引
hier = df.set_index(['dept', 'name']).sort_index()
1. 宽长变换、表连接与层次索引 —— 结构化数据的“形态管理”
这一节集中演示四种常见操作:
melt宽→长 — 方便可视化与机器学习管道pivot长→宽 — 还原或重排字段merge连接 — 类 SQL 的关联查询set_index层次索引 — 多维索引与分层切片
预置原始表 df
| name | age | salary | dept |
|---|---|---|---|
| Tom | 20 | 5800 | TECH |
| Lucy | 21 | 6200 | HR |
| Tom | 23 | 5900 | TECH |
| Jack | 22 | 6500 | FINANCE |
| Tom | 25 | 6100 | TECH |
- 宽转长:为可视化或 sklearn OneHotEncoder 做准备
long = df.melt(id_vars=['name'], # 不变的标识列value_vars=['age', 'salary'], # 拆分目标列var_name='metric', # 拆分后列名存放位置value_name='value' # 拆分后数值存放位置
)
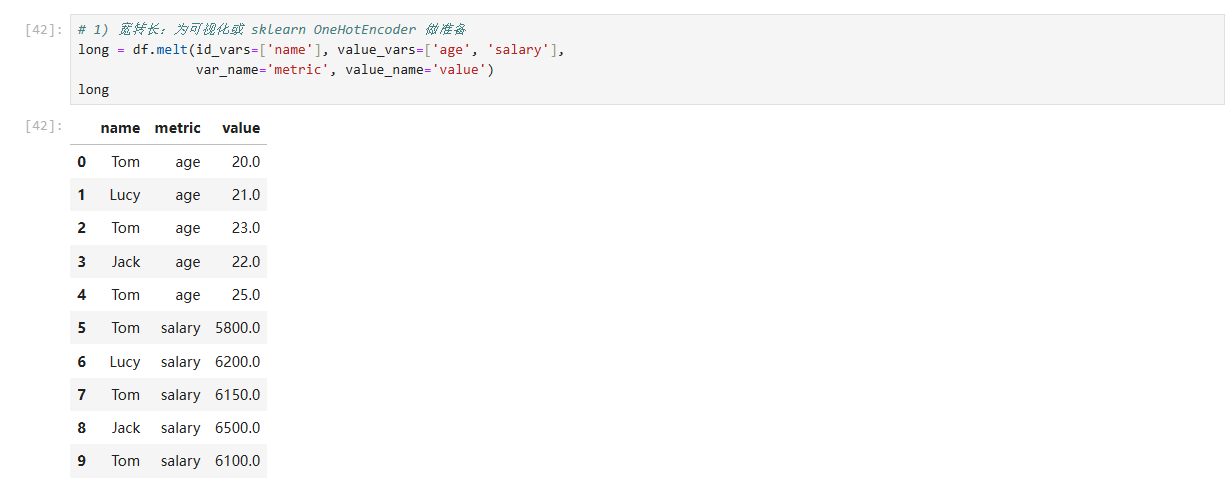
参数说明
| 参数 | 功能 | 典型取值 |
|---|---|---|
id_vars | 保持不动的列(标识) | 主键、时间戳 |
value_vars | 需要“拆行”的列 | 连续/离散数值 |
var_name | 新列,用于标记原列名 | “metric”“variable” |
value_name | 新列,存数值本身 | “value”“amount” |
应用场景
- 可视化 Seaborn/Altair 通常要求“长表”输入 (
x、y、hue); - 机器学习
sklearn.preprocessing.OneHotEncoder、深度学习 Tabular 数据管道更易接收(id, feature, value)三列。
2 merge:按 name 把奖金表拼进主表
df_bonus = pd.DataFrame({'name': ['Tom', 'Lucy', 'Jack'],'bonus': [500, 450, 550]
})df_full = df.merge(df_bonus, # 右表on='name', # 连接键how='left' # 保留左表全部行
)
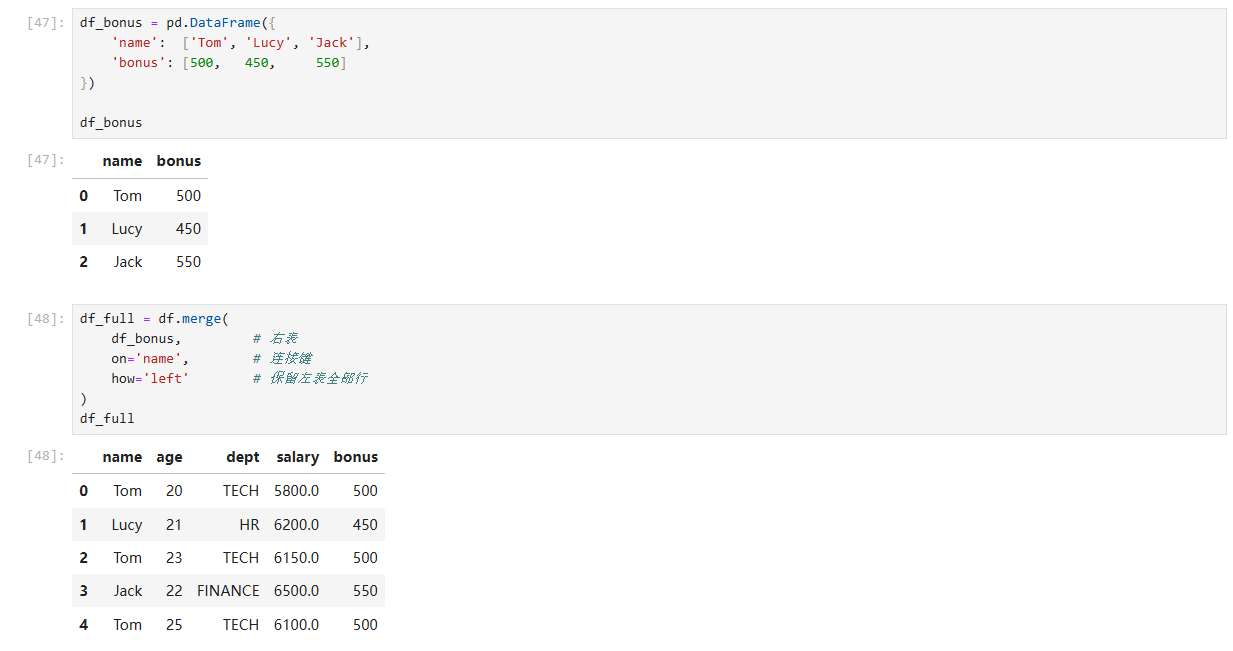
关键点
| 参数 | 说明 | 对应 SQL |
|---|---|---|
on / left_on / right_on | 连接键(列名或列表) | ON a.name = b.name |
how | 'inner', 'left', 'right', 'outer' | INNER / LEFT OUTER … JOIN |
suffixes | 列名冲突时自动追加后缀 | 同名字段歧义解决方案 |
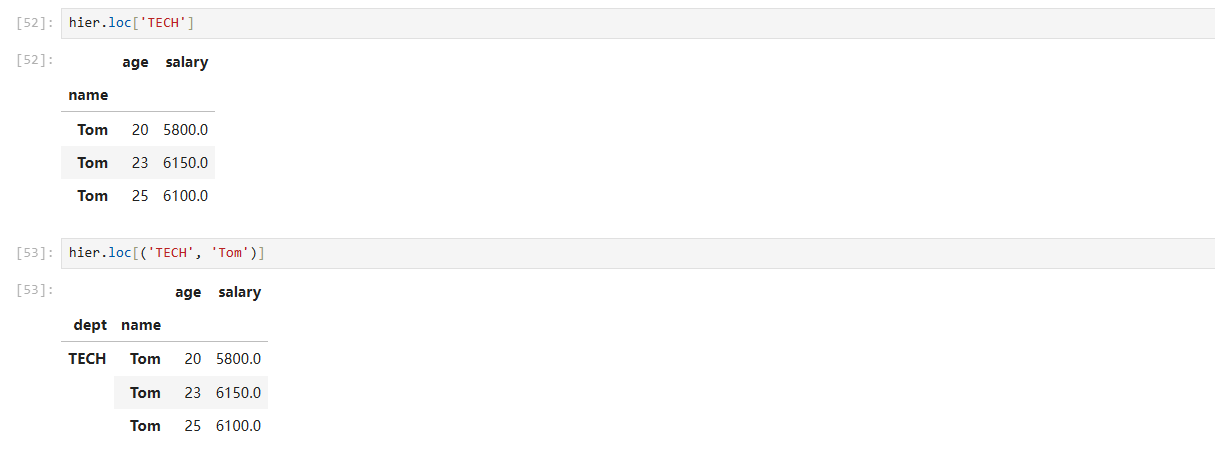
3 set_index:构造 层次索引(MultiIndex)
hier = (df.set_index(['dept', 'name']) # 两列形成多级行索引.sort_index() # 便于层次切片
)

检索示例
# 1) 取 TECH 部门全部记录
tech_only = hier.loc['TECH']# 2) 取 TECH 部门 Tom 的所有字段
tech_tom = hier.loc[('TECH', 'Tom')]
优势与注意事项
| 优势 | 场景 |
|---|---|
| 自然表达多维切片 | 部门→个人→日期 |
与 groupby(level=…) 、 unstack() 配合 | 快速计算矩阵化指标 |
| 注意 | 说明 |
|---|---|
MultiIndex 不被大多数外部存储(CSV、SQL)直接识别 | 导出前请 reset_index() |
| 过深层次或含高基数字符串会增加索引维护成本 | 根据查询模式权衡层次数 |
小结
- 宽↔长 :
melt与pivot/pivot_table解决“列转行 / 行转列” —— 分析与可视化常用; - 连接 :
merge用类 SQL 语法,把维度信息或指标补全到主表; - 层次索引 :
set_index为高维分析提供“一行多键”标签,便利分层分组与切片。
7 时间序列、滚动窗口与性能优化 —— 面向生产的最后一公里
# 假设新增入职日期
df['hire_date'] = pd.to_datetime(['2022-01-10', '2021-12-03','2020-08-15', '2023-02-01','2019-07-07'])# ① 以 hire_date 为索引重采样到月
monthly_salary = (df.set_index('hire_date')['salary'].resample('M').mean()
)# ② 计算 3 行滚动平均
df['salary_ma3'] = df['salary'].rolling(window=3).mean()# ③ 使用 query / eval 加速链式条件
high_paid_it = df.query("dept == 'TECH' and salary > 6000")
query 与 eval 避免 Python 级别循环,可在列数多、条件复杂时明显提速;若仍有性能瓶颈,可考虑 pandas.api.types 子模块的 pd.Categorical、pd.to_datetime(..., cache=True) 或借助 Polars / DuckDB 等混合方案。
结语
通过以上七个模块,我们从“把文件读成 DataFrame”出发,逐步覆盖了:
- 基础结构 ——
DataFrame构造、读写接口 - 数据校验 ——
head / info / describe、类型压缩 - 定位与清洗 —— 切片、缺失、去重、映射
- 聚合与重塑 ——
groupby、melt / pivot、merge - 时序与窗口 ——
resample、rolling - 性能实践 ——
query / eval、category优化
掌握这些后,可在单机环境里完成 99 %的日常数据工程与分析任务。
载入 → 检查 → 清洗 → 分组 → 重塑 → 导出
ache=True)` 或借助 Polars / DuckDB 等混合方案。