MinerU教程第二弹丨MinerU 本地部署保姆级“喂饭”教程
新来的小伙伴看这里!👋 是不是刚接触 MinerU 有点懵?安装报错、部署卡住、配置一头雾水……别慌!今天这篇超基础教程,就是你的“救命指南”!从零开始,手把手带你搞定本地部署🌟 快上车!
🚀什么是MinerU?
MinerU是一款由上海人工智能实验室 OpenDataLab 团队开发的开源 PDF 转 Markdown 工具,可以高质量地提取 PDF 文档内容,生成结构化的 Markdown 格式文本,可用于RAG、LLM语料准备等场景。本指南将帮助您在本地部署并使用 MinerU。
各位开发大神,一定要好好仔仔细细地研读一下 MinerU github readme 。同时也可以浏览项目issue,很多常见问题都可以迎刃而解!
MinerU Readme 地址(中文)https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
敲黑板!MinerU 仓库中有些目录虽然常被开发者忽视,但它们对于理解项目架构与功能扩展却至关重要。以下是对部分关键文件夹的简要介绍:
MinerU/├── demo/ # 用于运行转换演示的脚本├── docker/ # 用于容器化的 Dockerfile 配置文件├── docs/ # 存储各类说明文档├── projects/ # 存放由 MinerU 衍生或相关的项目│ ├── gradio_app/ # MinerU Gradio 界面的源代码│ ├── multi_gpu/ # 为 MinerU 提供多 GPU 支持的解决方案│ ├── web_api/ # 提供本地 Web API 接口的服务端代码
⭐ MinerU 功能特性
MinerU具有以下核心功能:
1. 文档处理
● 删除页眉、页脚、脚注、页码等元素,确保语义连贯
● 保留原文档的结构,包括标题、段落、列表等
● 提取图像、图片描述、表格、表格标题及脚注
2. 格式转换
● 自动识别并转换文档中的公式为LaTeX格式
● 自动识别并转换文档中的表格为HTML格式
3. 运行环境
● 支持纯 CPU 环境运行
● 支持 GPU 加速,提升处理效率
🔧本地部署系统要求
在开始安装前,请确保您的系统满足以下要求:
基础环境
● Python 3.10~3.13
● Conda(包管理器)
GPU加速要求(可选)
● NVIDIA显卡(显存≥6GB)
基础环境配置推荐:
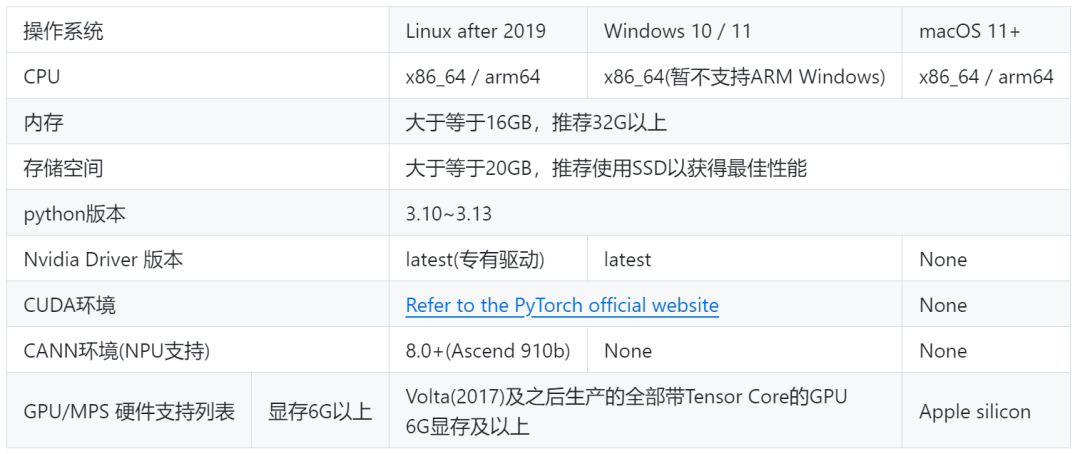
更多详情,请查看:https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
接下来是具体的安装步骤:
⚙️ 1.环境配置
1.1 创建Conda环境
需指定Python版本>=3.10
conda create -n mineru 'python=3.12' -yconda activate minerupip install -U "magic-pdf[full]" -i https://mirrors.aliyun.com/pypi/simple#-i 是指定国内的加速源,可选清华源或阿里云源,此处用阿里云源示例
1.2 下载模型文件
首次使用需下载模型文件,提供两种下载方式:
📥 方法一:从Hugging Face下载模型(国际用户推荐)
pip install huggingface_hub
curl -o download_models_hf.py https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models_hf.py
python download_models_hf.py📥 方法二:从ModelScope下载模型(国内用户推荐)
pip install modelscope
curl -o download_models.py https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py
python download_models.py📁 模型默认存储路径示例:
model_dir: C:\Users\用户名\.cache\modelscope\hub\models\opendatalab\PDF-Extract-Kit-1___0/models
layoutreader_model_dir: C:\Users\用户名\.cache\modelscope\hub\models\ppaanngggg\layoutreader💡提示:
下载完成后,系统会自动在用户目录下生成 magic-pdf.json 配置文件,你可以在这个配置文件中修改部分配置,实现不同功能的开关,如表格识别、公式识别关闭或开启(默认二者都是开启的,关闭只需将对应的值改 'true' 为 'false' )。
用户目录位置:
● Windows:C:\Users\用户名
● Linux:/home/用户名
● macOS:/Users/用户名
🧠 补充说明:
● 之前用 'pip install -U "magic-pdf[full]"' 安装的依赖已经保存在mineru环境里。
● 只要没有删除这个环境或修改环境目录,这些内容都会保留。
● 每次关掉终端后再次使用,只需运行 'conda activate mineru' 即可。
🚀 2. GPU加速配置
2.1 CUDA加速设置
这里以 Windows(NVIDIA 显卡) 为例。如果您的 NVIDIA 显卡显存 ≥ 6GB,可配置 CUDA 加速。这里我们以 CUDA 12.8 安装为例:
(还需提前安装 NVIDIA 显卡所匹配的 pytorch 版本,但安装步骤此处不做展开,可根据下方“提示”及第二篇文章自行配置)
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu128修改用户目录中配置文件 magic-pdf.json :
{// other config"device-mode": "cuda"}
💡提示:
● Pytorch 是 MinerU 运行所必须的深度学习模型的依赖库,执行第1节步骤会自动安装适配 CPU 场景的 Pytoch ,如果使用 GPU,还需重新调整 Pytorch 版本以适配对应的 GPU ;Windows 和 Linux 系统对于 Pytorch 的安装也存在差异,具体安装细节与说明,请参考《零基础入门:MinerU 和 PyTorch、CUDA的关系》。
🧩 3. 功能测试
3.1 单文件测试
执行以下命令自动测试功能:
cd demomagic-pdf -p demo1.pdf -o ./output
💡 提示: ./ 是指是一个相对路径,它表示当前工作目录(也就是你在终端中运行命令时所在的目录);执行完上述命令后,检查 output 文件夹,有输出文件说明部署成功。
3.2 批量PDF转换
📋 操作步骤:
✅ 步骤 1:获取批量转换脚本
下载名为 batch_demo.py 的 Python 文件。你可以将此文件保存在你希望执行转换的任何目录下。
下载地址:https://github.com/opendatalab/MinerU/blob/master/demo/batch_demo.py
✅ 步骤 2:准备 PDF 文件
在 batch_demo.py 文件的目录下新建如下文件夹:
pdfs # batch_demo.py 相对于脚本的路径 ✅ 步骤 3:执行批量转换:
打开你的终端或命令提示符,导航到你保存 batch_demo.py 文件的目录。例如,如果你的 batch_demo.py 文件保存在 demo 文件夹中,你可以执行以下命令:
cd demopython batch_demo.py
✅ 步骤 4:查看转换结果:
转换后的结果将默认输出到与 batch_demo.py 文件同级目录下的一个名为 output 的文件夹中。
output # 相对于脚本的路径按照上述步骤,你已经成功本地部署 MinerU 并可以进行 PDF 文档解析了。不过很多小伙伴还有 MinerU 本地 API 服务的需求,比如我们上一篇文章提到的 MinerU Dify插件教程里的场景二,那接下来就来看看怎么配置 MinerU 本地 API。(点击回顾:MinerU教程第一弹丨Dify插件超详细配置攻略和工作流搭建案例,不允许还有人不会)
🔌 4. 搭建本地 API 服务
4.1 Conda 方式安装
✅ 步骤 1:创建Conda环境
需指定 Python 版本为3.10
conda create -n mineru_api 'python=3.10' -yconda activate mineru_api
✅ 步骤 2:安装依赖
# 进入api目录cd projects/web_api# 安装依赖pip install -r requirements.txt
✅ 步骤 3:启动服务
# 启动服务python app.py
4.2 Docker安装方式
✅ 步骤 1:构建方式
docker build -t mineru-api .或者使用代理:docker build --build-arg http_proxy=http://127.0.0.1:7890 --build-arg https_proxy=http://127.0.0.1:7890 -t mineru-api .✅ 步骤 2:启动命令
docker run --rm -it --gpus=all -p 8000:8000 mineru-api💡 提示 上述任意一种方式安装完成后,可以通过如下地址访问(测试)
http://localhost:8000/docshttp://127.0.0.1:8000/docs
📝 5. 如何彻底卸载通过 Conda 安装的 MinerU(含 magic-pdf\[full])?
✅ 步骤 1:退出当前环境(如果你还在`mineru` 环境中)
conda deactivate✅ 步骤 2:删除整个 Mineru 虚拟环境
conda remove -n mineru --all确保输出中没有 mineru 环境,说明已经卸载彻底。
💡提示: 如果你是在 Conda 的 base 默认环境中 安装并运行了 MinerU API(通过 `pip install -r requirements.txt` 安装依赖),这意味着:
● 所有的依赖都混在 base 环境里;
- 没有单独的虚拟环境,卸载时需要精准清理特定依赖。
🗑️ 6. 如何卸载 MinerU API?
6.1 卸载你通过 Conda 和 pip 安装的 MinerU API 环境,可以按照以下步骤进行清理:
✅ 步骤 1:删除 Conda 环境
你创建的 Conda 环境名为 mineru_api,可使用以下命令删除它:
conda deactivateconda remove -n mineru_api --all
这将删除整个 mineru_api 环境及其所有依赖。
✅ 步骤 2:可选:删除项目目录(如果你克隆了 GitHub 项目)
如果你通过 git clone 下载了 MinerU 项目文件,可以直接删除目录,例如:
rm -rf path/to/MinerU例如你是在 ~/projects/MinerU 目录下:
rm -rf ~/projects/MinerU✅ 步骤 3:可选:清理 pip 缓存
如果你想进一步清理 pip 下载的缓存文件:
pip cache purge6.2 卸载你通过Docker 构建和运行 MinerU 的 PDF 解析 API 镜像,主要包括以下两步:
✅ 步骤 1:停止并移除容器(如果有残留)
你用了 --rm 参数(docker run --rm),这意味着容器在停止后会自动删除,所以无需手动删除容器,这一步可以跳过。
但你可以用以下命令确认没有运行中的 MinerU 容器:
docker ps如果看到 mineru-api 仍在运行,可以手动停止:
docker stop <容器ID或名称>✅ 步骤 2:删除镜像
删除名为 mineru-api 的镜像:
docker rmi mineru-api如遇“镜像正在使用”的提示,可加 -f 强制删除:
docker rmi -f mineru-api✅ 步骤 3:可选:清理构建缓存
Docker 会留下很多中间层镜像和缓存文件,如果你想释放空间:
docker system prune -a⚠️ 警告:该命令会删除所有未使用的容器、网络、镜像、构建缓存。慎用!至此,相信你已经掌握了 MinerU 本地部署、API构建、卸载等操作,快去试试吧

如果上述操作对你来说仍显得复杂,或者始终缺少相应的硬件条件,那强烈推荐!!!你使用官方提供的 MinerU 客户端,无需编写代码、零学习成本,即可快速完成文档免费转换:https://mineru.net/
