tasklet上下文内存分配触发might_alloc检查及同步回收调用链
一、背景
tasklet作为一个特殊的软中断,常常用于做一些相对优先级较高但又不方便放到硬中断处理逻辑里的事情。另外,tasklet有一个相对重要的特性,就是一个tasklet其对应的触发的回调同一时刻只能运行一个,这个天然的排序性可以简化一些需要考虑并发场景的逻辑;但是同时,它也正因为这个排序性,有时候多个tasklet的schedule同时执行时,回调也会因此处理得不够及时。这一点我们在之前的博客 内核调度代码关键路径下的低延迟唤醒_linux条件变量唤醒存在延迟-CSDN博客 里的 3.2 一节里有介绍,可以通过per-cpu的方式进行加速,防止都schedule到同一个tasklet实例后导致的并发性能问题。
这篇博客里,我们在第二章里讲tasklet的回调函数里的上下文环境相关的一个内存分配标志位的检查所导致的一处warning的call trace,进行跟踪分析;在第三章里详细跟踪一下从kmalloc到最终的同步回收逻辑的完整的调用链。
二、call trace的分析
2.1 分析call trace的代码源头
下图是复现的call trace的截图:
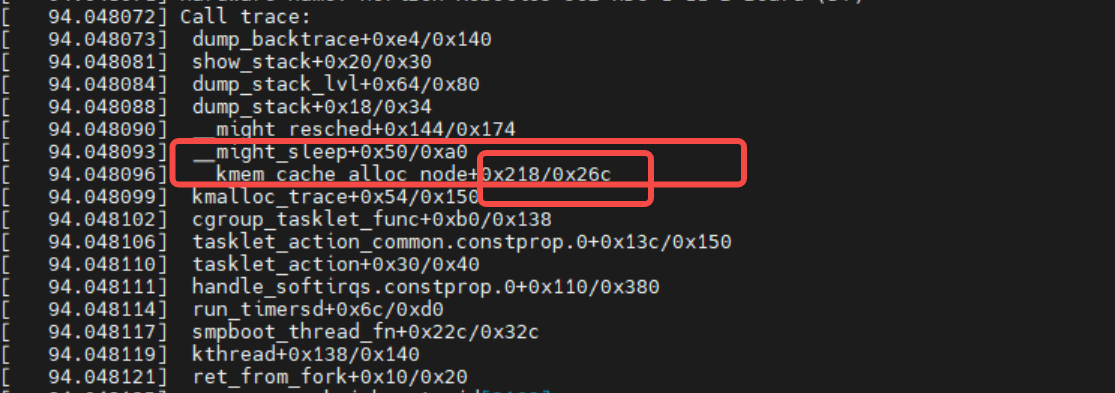
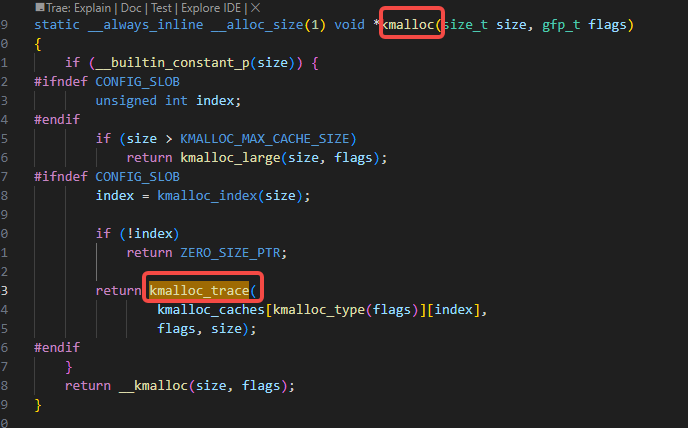
我们反汇编跟踪一下是call trace报在哪里,找上图里的__kmem_cache_alloc_node函数的offset 0x218的位置,如下图:


也就是在下图里的位置:
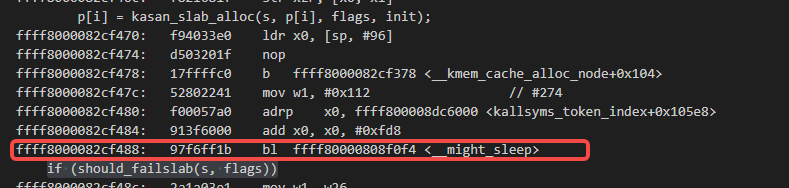
搜索上图里红色的call trace位置的下方的代码,可以找到如下的slab_pre_alloc_hook函数里的下图里的代码:
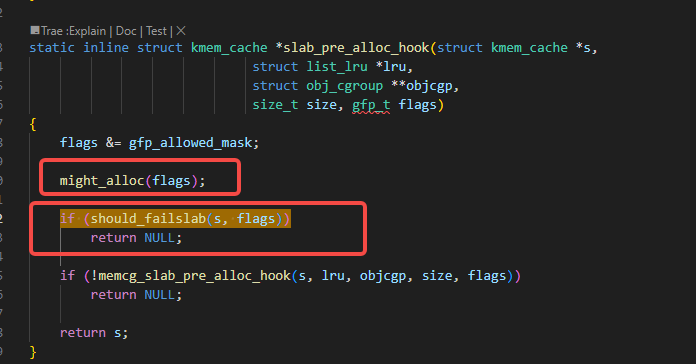
也就是下图里的might_alloc函数:
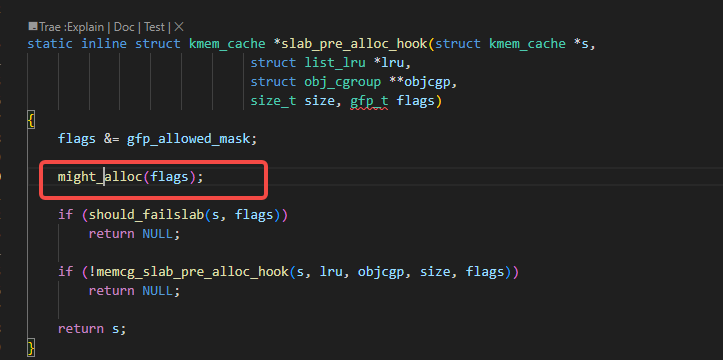
看一下might_alloc函数的实现:
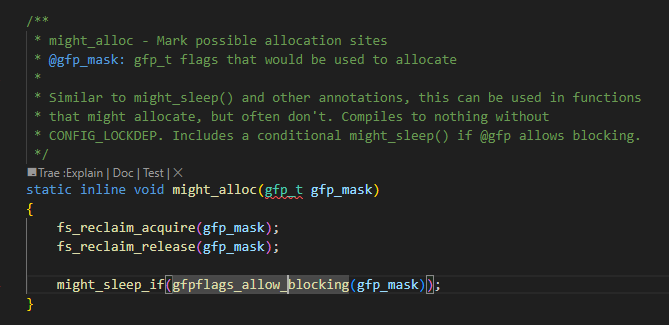
可以从上图里看到是在might_sleep_if(gfpflags_allow_blocking(gfp_mask));有进行是否可能睡眠的判断,我们进一步看gfpflags_allow_blocking函数:

可以看到gfpflags_allow_blocking函数是根据内存分配时带的gfp_t标志位参数,判断是否有__GFP_DIRECT_RECLAIM标志位,如果有,则判断下来它是可能会睡眠的。
我们看一下最常用的GFP_KERNEL的标志位参数的定义:
![]()
而__GFP_RECLAIM则是:
![]()
所以GFP_KERNEL标志位参数作为分配的标志位入参进行内存分配的话,程序运行到might_sleep_if时,might_sleep_if的cond就是true,然后如下图might_sleep_if的宏定义:

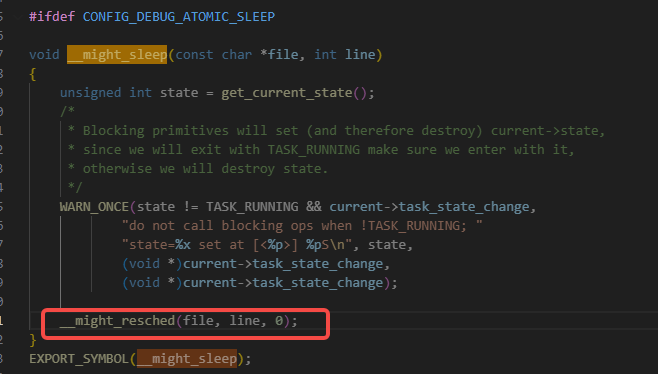
就执行到了might_sleep逻辑里了,在打开CONFIG_DEBUG_ATOMIC_SLEEP编译选项的情况下,might_sleep有如下定义:

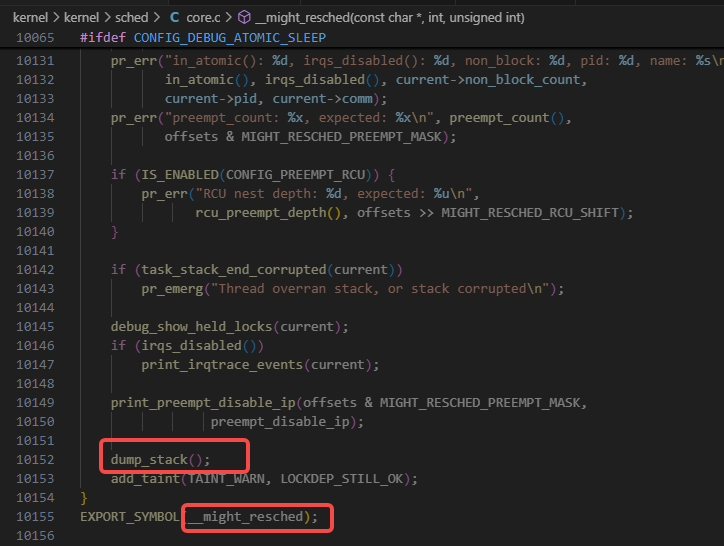
然后might_sleep在打开CONFIG_DEBUG_ATOMIC_SLEEP编译选项的情况下,会如下图运行__might_resched函数:
然后有如下图里的dump_stack的call trace打印:
2.2 tasklet的callback里不合理的使用导致call trace打印
下图就是错误的tasklet的callback里的分配函数的使用:
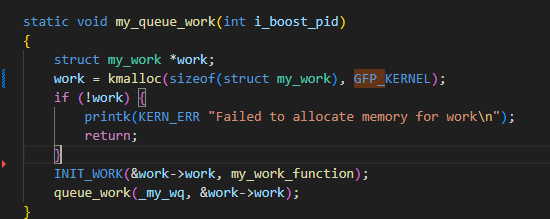
因为上图里在进行kmalloc分配时,传入了GFP_KERNEL这个标志位参数,而GFP_KERNEL这个标志位参数进行内存分配时可能会导致睡眠。
而tasklet的上下文环境是软中断执行环境,在使用上它是不允许睡眠的,虽然,我们在rt-linux里使用spinlock它一般来说都是类似mutex的实现,而spinlock是可以在软中断处理函数里使用的,这么说难道在rt-linux下软中断处理逻辑里是可以进行睡眠了?并不能这么说,因为spinlock我们预期是运行时间较短的操作,所谓乐观锁就是能快速进入锁,有这么一个预期,同时也默认认为持锁期间是较短的,而那些可能导致长时间睡眠的函数,如这里的传入GFP_KERNEL的kmalloc,其睡眠的时间就不能预期很短了,和使用spinlock预期较短的时间相比是不一样的。
三、内存分配逻辑里的可能导致睡眠的调用链
刚才我们讲到了在kmalloc这种内存分配逻辑里会进行might_sleep的检查,检查到是中断上下文环境,就不允许执行可能睡眠的函数(会打印call trace进行提示),虽然它只是一个提示,但是如果真的睡眠了,而且睡眠时间较长之后,就会导致系统的底层逻辑的卡顿,继而可能导致系统崩溃。
我们来看一下内存分配逻辑里可能导致睡眠的调用链。其实上面在介绍might_sleep_if(gfpflags_allow_blocking(gfp_mask));的实现时就已经说明了只会在带上了直接回收标志位,也就是__GFP_DIRECT_RECLAIM时,才可能陷入睡眠。
3.1 kmalloc到reclaim_throttle的完整的调用链
跟了一下kmalloc到最终的可能睡眠的函数的完整调用链如下:
kmalloc->kmalloc_trace->__kmem_cache_alloc_node->slab_alloc_node->__slab_alloc->___slab_alloc->new_slab->allocate_slab->alloc_slab_page->alloc_pages->alloc_pages_node->__alloc_pages_node->__alloc_pages->__alloc_pages_slowpath->__alloc_pages_direct_reclaim->__perform_reclaim->try_to_free_pages->do_try_to_free_pages->shrink_zones->consider_reclaim_throttle->reclaim_throttle
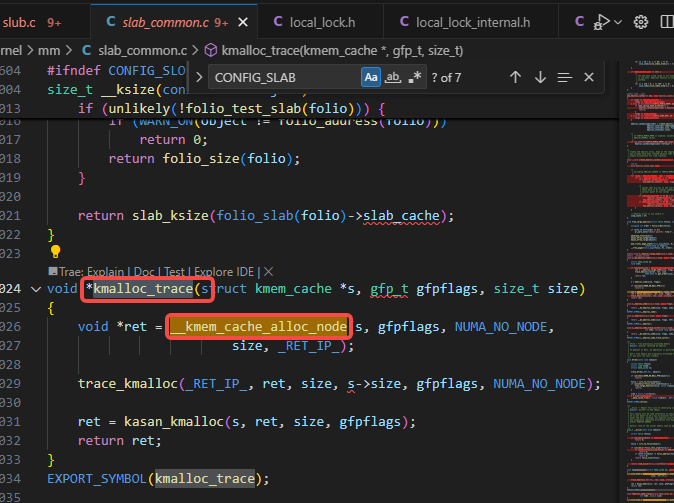
kmalloc调用了kmalloc_trace:
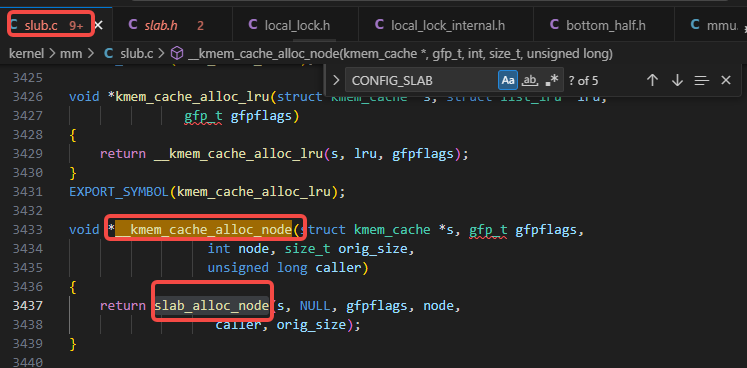
kmalloc_trace调用了__kmem_cache_alloc_node:
__kmem_cache_alloc_node调用了slab_alloc_node:
slab_alloc_node调用了__slab_alloc:
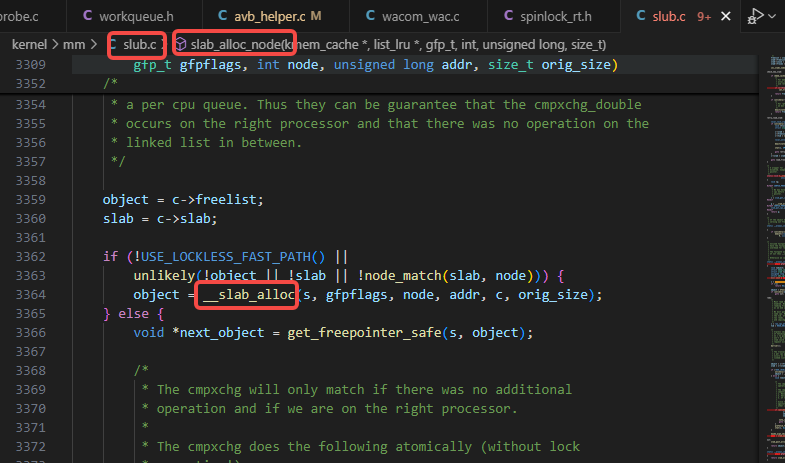
__slab_alloc调用了___slab_alloc:

___slab_alloc调用了new_slab:
就是说在slab分配发现已预分配出来的内存里无法进行当前的这一个内存分配请求的话,就申请一个对应的新的slab,如下图:
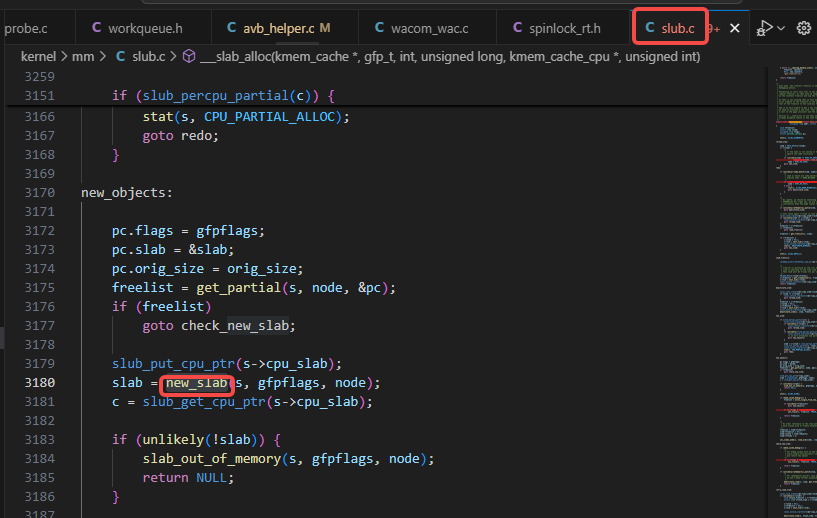
new_slab调用了allocate_slab:
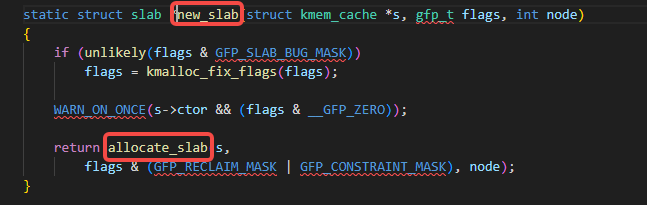
allocate_slab调用了alloc_slab_page:
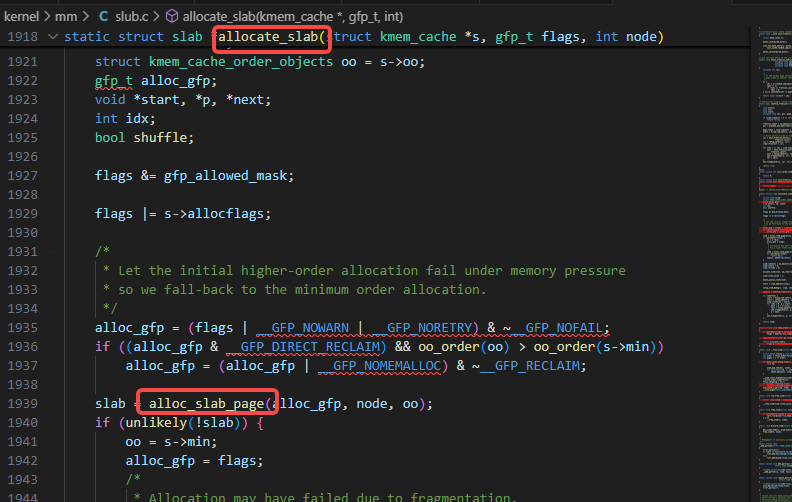
alloc_slab_page调用了alloc_pages:
测试系统上没有NUMA,所以只会调用到alloc_pages,不会调用到__alloc_pages_node:
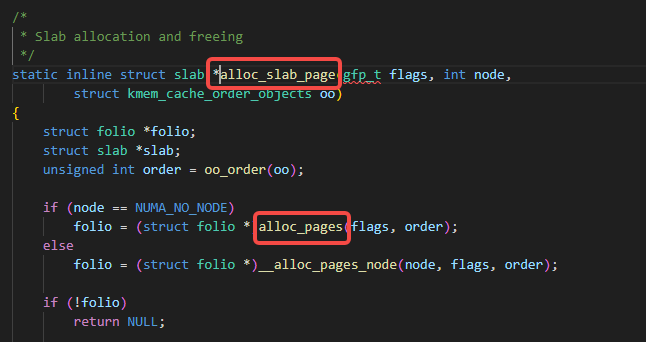
alloc_pages调用了alloc_pages_node:
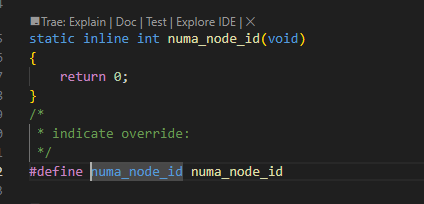
(未打开CONFIG_NUMA时)下图里的numa_node_id是0:
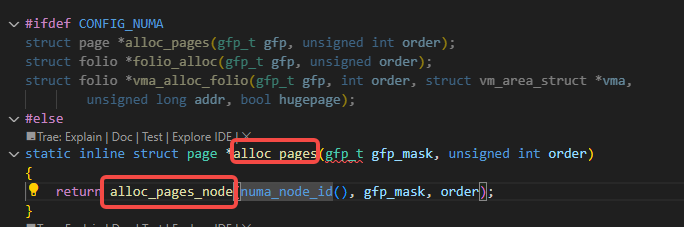
alloc_pages_node调用了__alloc_pages_node:
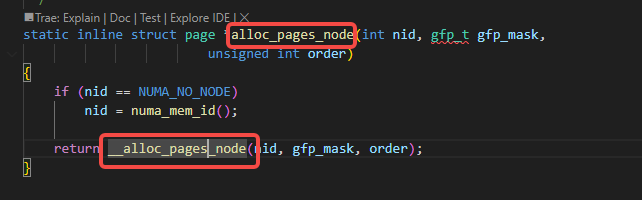
__alloc_pages_node调用了__alloc_pages:
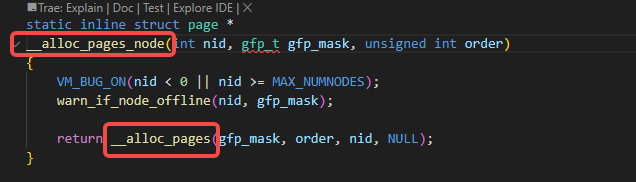
__alloc_pages调用了__alloc_pages_slowpath:
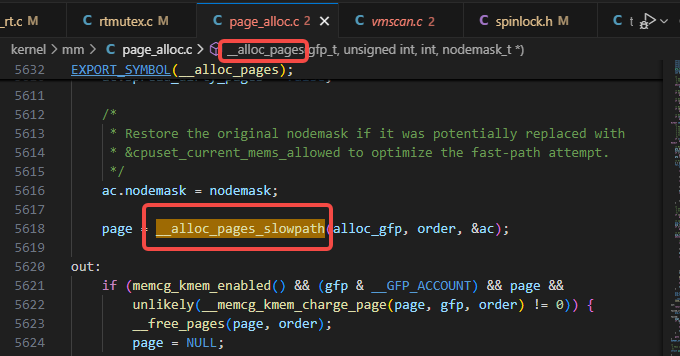
__alloc_pages_slowpath调用了__alloc_pages_direct_reclaim:
要注意,它是只在can_direct_reclaim是true的时候,才会走到下图里的__alloc_pages_direct_reclaim逻辑的:
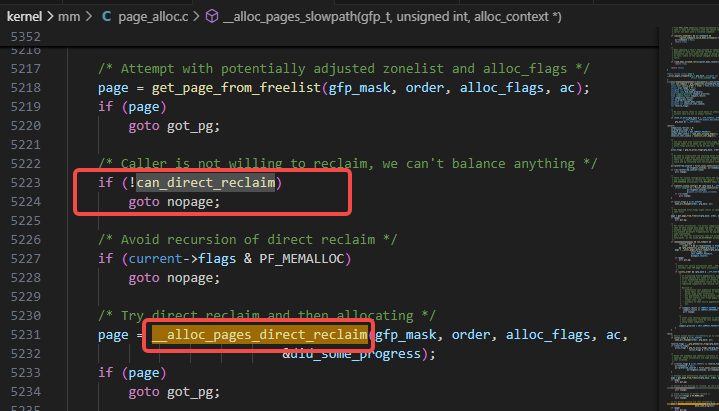
__alloc_pages_direct_reclaim调用了__perform_reclaim:
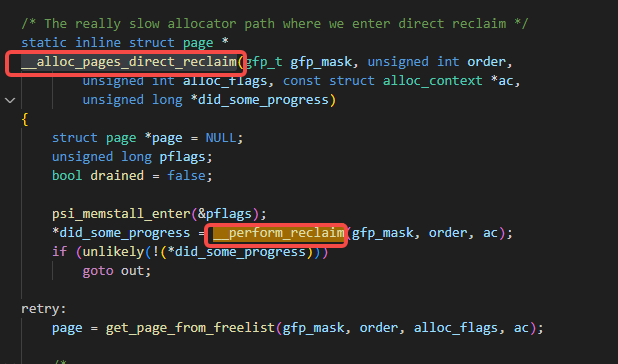
__perform_reclaim调用了try_to_free_pages:
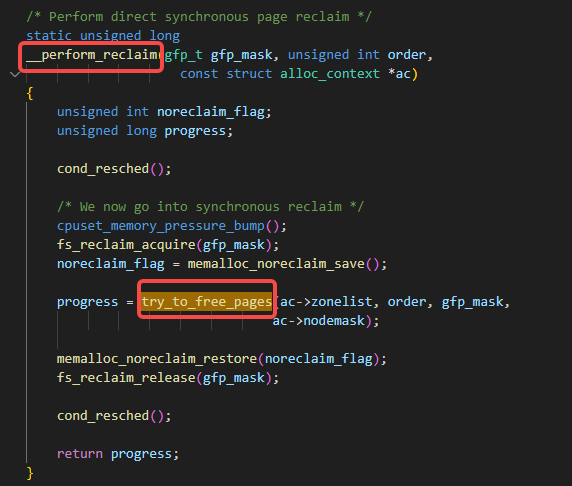
try_to_free_pages调用了do_try_to_free_pages:
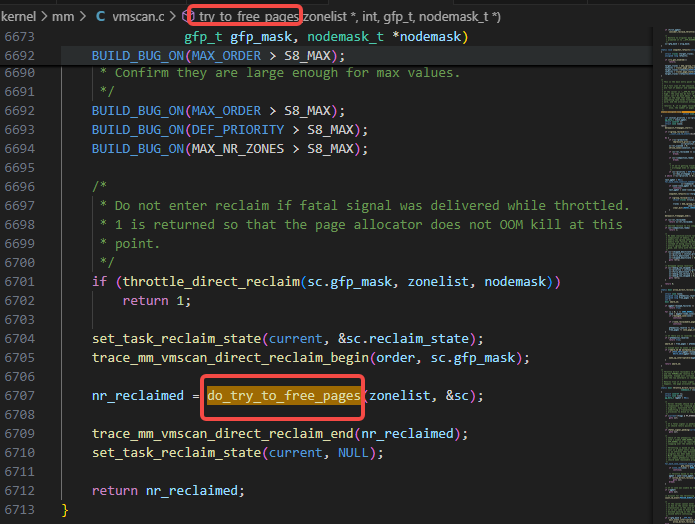
do_try_to_free_pages调用了shrink_zones:
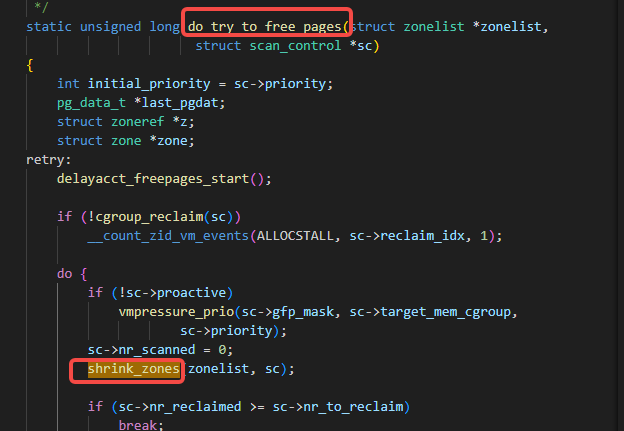
shrink_zones调用了consider_reclaim_throttle:
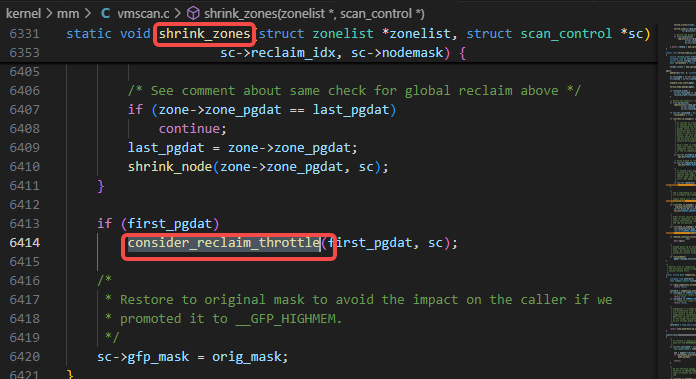
consider_reclaim_throttle调用了reclaim_throttle:
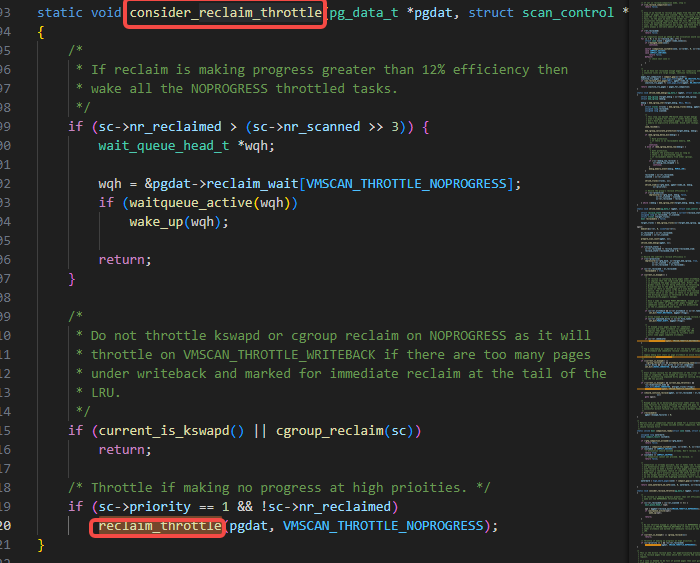
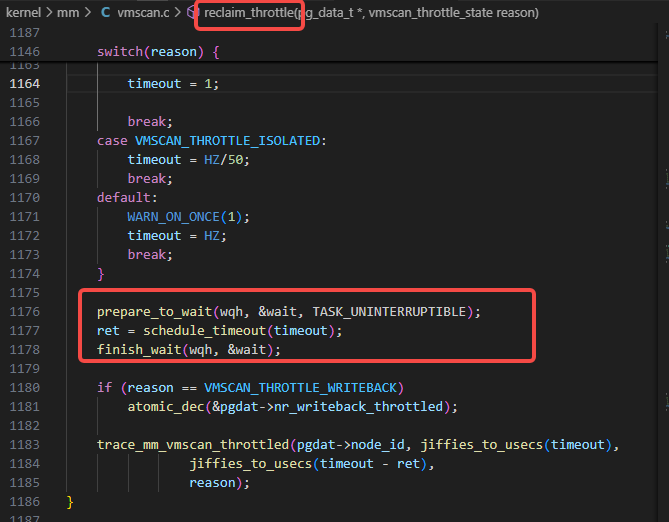
reclaim_throttle里如下图里的schedule的逻辑:
3.2 关于slab、slob、slub
刚才介绍到了slab、slub的一些接口,我们稍微展开介绍一下。
现在的系统里一般都是用的CONFIG_SLUB来代替CONFIG_SLAB,slub是基于slab核心实现的,slub改写自slob,是slob的优化后版本,比slab性能更好。如下图是内核文档里的相关说明:

我们通过编译也可以确认系统上使能了哪些:
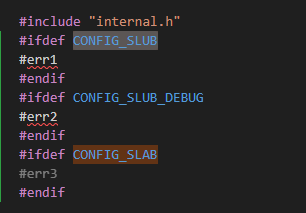
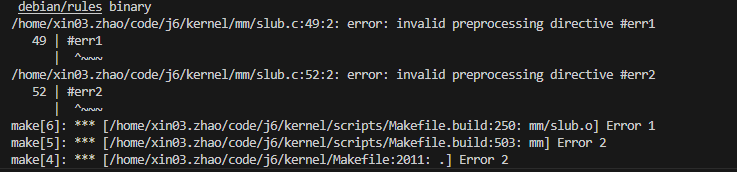
可以通过上面两个图确认是打开了CONFIG_SLUB和CONFIG_SLUB_DEBUG,没有打开CONFIG_SLAB。
如下图可以看到,CONFIG_SLAB不打开的话,slab.c是不会被编到的:
3.3 内存分配里其他的会引起睡眠的逻辑
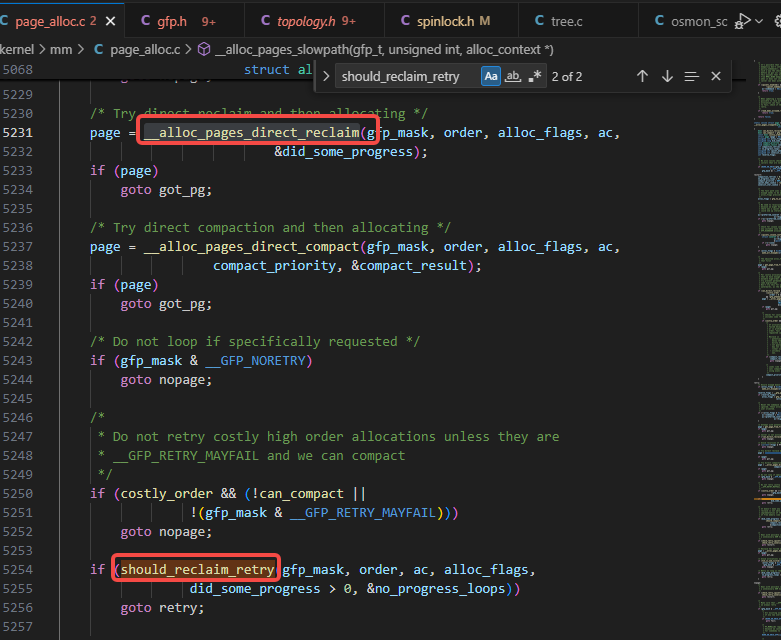
内存分配所触发的内存直接回收逻辑的场景除了上面 3.1 里以外,还有下图里的should_reclaim_retry所触发的逻辑,should_reclaim_retry逻辑是在__alloc_pages_direct_reclaim之后执行的:
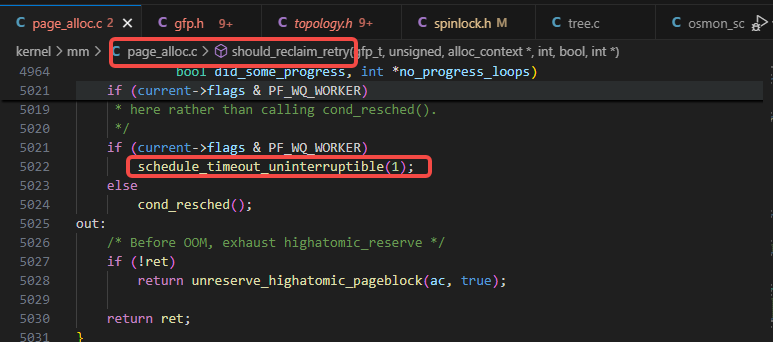
在should_reclaim_retry函数里会调用schedule的函数,如下图:
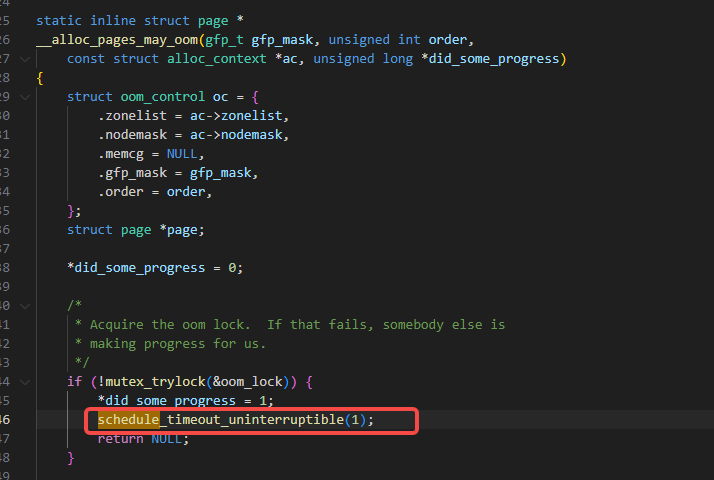
另外一种会引起睡眠的逻辑是走的oom逻辑,但是和 3.1 里介绍的一样,也是需要标志位带上__GFP_DIRECT_RECLAIM才会走的,因为can_direct_reclaim的下图的判断是在__alloc_pages_may_oom之前的:

...

...
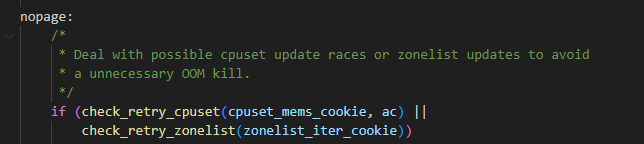
我们来继续跟一下__alloc_pages_may_oom函数,可以从下图看到__alloc_pages_may_oom函数里有schedule的逻辑: