rt-linux下的底层锁依赖因cgroup cpu功能导致不相干进程的高时延问题
一、背景
rt-linux系统由于增加了非常多的主动抢占点,并改写了spinlock的实现(不再禁用强占),从而让系统对高实时进程的响应相比普通linux做到的更加快速。虽然普通linux如果设置preempt full模式,其实时性也是有一定保障的(详细见之前的博客 内核调度抢占模式——voluntary和full对比_preempt dynamic-CSDN博客),但是相比rt-linux来说还是略显不足。
rt-linux有高实时性的好处,自然也有其劣势,一是增加主动抢占点所导致的上下文切换频繁,二是对普通linux里的一些功能支持得不够理想,这里说的就是cgroup cpu功能。
在之前的博客 rt-linux下的cgroup cpu的死锁bug-CSDN博客 里,我们已经提及了一个rt-linux的cgroup cpu的一个死锁bug,这篇博客我们讲rt-linux下的cgroup cpu的另外一个问题,虽然不会造成死锁,但是会造成一些看似好不相干的进程之间的依赖,叠加上cgroup cpu的throttle就导致了比较高的时延。
二、问题详细分析
2.1 问题现象及根因分析
在之前的博客 rt-linux下的D状态的堆栈抓取及TASK_RTLOCK_WAIT状态-CSDN博客 里在描述rt-linux系统下的任务的TASK_RTLOCK_WAIT状态时举的例子其实就是与cgroup cpu限额底层锁不同进程间关联的这个问题相关的。
如下图:
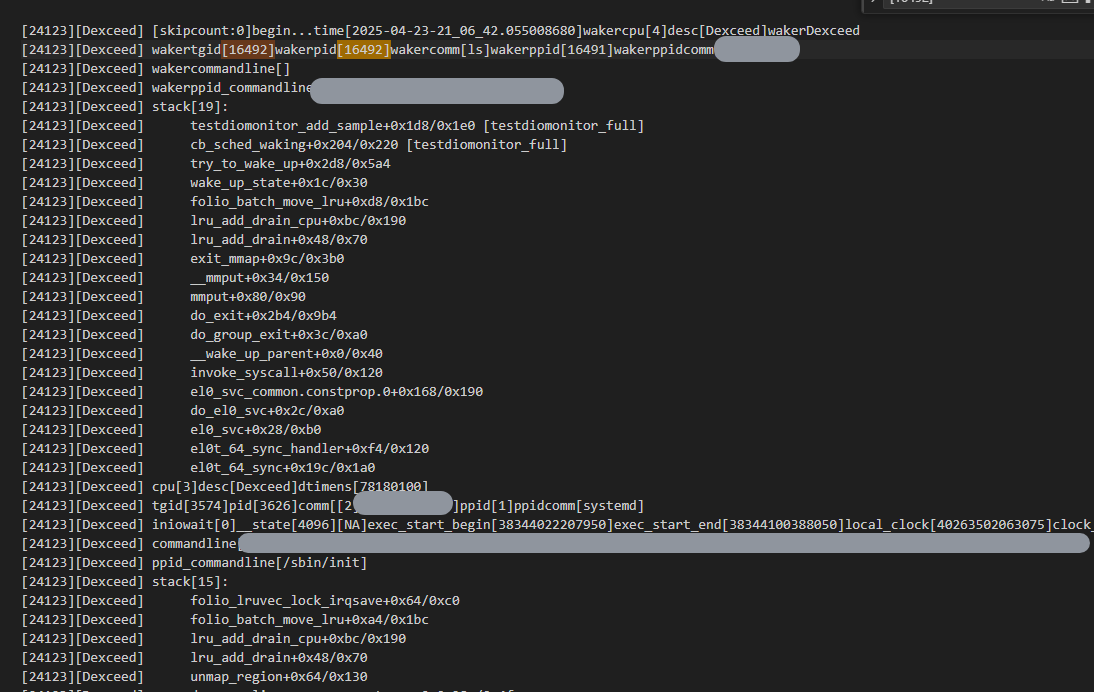
tgid 16492里的一个ls的脚本和tgid 3574进程里的一个线程因为lru_add_drain_cpu这么一个非常底层的内存lru逻辑相关的一个底层锁相互间有了依赖。
而ls脚本因为所属的cgroup被限额了,导致了另外一个看似不相关的一个进程收到了影响。
![]()

在之前的博客 rt-linux下的cgroup cpu的死锁bug-CSDN博客 里的 第一章 背景里我们有一定的讲解:
“
它会导致一些看似很不合理的情况,比如两个看似毫无关系的进程却有因为其中一个执行到一半被cgroup限额了导致另外一个进程一直在等前者继续运行从而来唤醒自己。老实说,这种情况应该也能在普通内核开启cgroup的cpu限额后也能出现,但是普通内核由于spinlock是禁用抢占的,而底层逻辑里的锁大部分还是spinlock,所以普通内核里因为cgroup限额导致底层逻辑阻塞两个看似不相关的进程的情况还是比较少的。另外一方面,普通内核里如果发生类似的情况就是使用了mutex,而使用了mutex那就是可以认为是能忍受一定的等待的,同样的,对于底层逻辑也一样,底层逻辑里要使用mutex的地方肯定也都是默认能忍受一定等待的,那么这时候发生cgroup cpu的限额导致这样的等待又多持续了一段时间,那也理应能接受的。
虽然rt-linux有针对锁有优先级继承的逻辑来保证杜绝优先级反转的情况,比如如果普通进程访问了一个spinlock但是被RT进程抢占了,而RT进程执行完之后,普通进程所在的cgroup组又限额导致普通进程不能进一步执行逻辑,而导致spinlock一直退不出来。这时候,如果是一个实时进程要访问该锁,那么由于优先级继承的逻辑,普通进程就会被临时提高优先级,提到到要用锁的进程的优先级和自己优先级中的较高者,这个例子里就是提高到实时优先级,所以普通进程又能执行下去了。关于该优先级反转的进一步细节见之前的博客 rt-linux之防止优先级反转-CSDN博客 。
但是,刚才说是要使用该锁的进程是实时进程的情况,但是如果要使用该锁的后者并不是实时进程,而是普通进程的话,那么就算提高优先级也是在普通进程这个调度类范畴,也受cgroup cpu的管控,仍然无法拿到额外的运行时间,还得等cgroup cpu的period timer重新补充时间来运行。这就会导致后面要拿锁的进程要等很长的时间,而后面要拿锁的进程和前者持锁被throttle的进程可能它们之间是表面并不关联的,关联的部分可能就是底层的逻辑,这就会导致一些比较诡异难理解的现象出来。
”
再理一下根因,如下:
1)普通进程在被强占前是进入了锁
2)普通进程是被RT进程打断(lazy preempt功能因为是rt进程所以无效生效)
3)普通进程被加入到了cgroup组(导致被RT进程打断后RT进程结束运行后,普通进程无法及时恢复运行)
4)普通进程被加入到cgroup组的限额周期较长(比如当前默认设的是100ms,导致再次补时间的点较慢)
上面讲到的 2)里的lazy preempt功能在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里的 1.4.4 一节里有做详细介绍。
2.2 普通linux上也有轻度的类似问题
普通linux里虽然spinlock是禁用抢占的,所以底层spinlock锁不会因为cgroup cpu限额导致问题,但是对于mutex而言,这样的问题也是一样存在的,比如内核里常用的一些rwsem的锁如mmap的读写锁这种等等。不过,因为普通linux上要因为cgroup cpu产生问题也是和mutex有关的,所以,预期上使用了mutex就不能认为能马上结束,等待者在等待mutex lock时也不能预期马上能进入锁,所以这一点上逻辑上所造成的影响也是可控的,所以,我称之为是“轻度”的类似问题。
三、可能的解法
3.1 回到用户态才进行throttle的改法
这个改法是 Valentin Schneider 进行尝试的一个改法,相关改法的最新链接是 Commits · mainline/sched/fair/throttle-on-exit-v4 · Valentin Schneider / Linux · GitLab 。
这不是一个正式的改法,且在rt-linux上实测下来还是有问题的。
大致的一个思想就是使用与某个task_struct任务相关联的一个linux机制task work机制来进行cgroup cpu的延迟throttle。
但是由于这个改法动到了cgroup cpu的调度的原有流程,加上在rt-linux上各种上下文切换场景,这样的大的改动要真正能在rt-linux上工作起来预测还需要沉淀一段时间。
另外一方面,这个到用户态才进行throttle的改法也非常大的影响了rt-linux系统上的实时性,本身rt-linux就需要高实时性,使用cgroup就是为了确保一些不重要的任务过分占用cpu时间导致其他关键任务没有及时拿到cpu时间,而这样的改动无疑是破坏了这样的是一个实时性的效果。
3.2 临时调整被cgroup cpu限额的已经进锁的任务的优先级
在上面 2.1 里我们已经分析了根因的逻辑链,其中一个重要的点是普通进程被实时进程打断导致lazy-preempt功能失效。当然这里面可能并不全是spinlock这种会使用lazy-preempt功能的情况,还有mutex的这种lazy-preempt不覆盖的情况。但是有点是肯定的,一旦优先级调整到实时之后,cgroup cpu就无法影响(一般我们是不用rt进程的cgroup cpu的throttle的,另外,rt-linux里也有注释说明了rt-linux里不能使用rt的cgroup cpu throttle CONFIG_RT_GROUP_SCHED,在之前的博客 CFS及RT调度整体介绍_rt调度器-CSDN博客 里的第二章 组调度里有提及)。
我们可以不改调度系统的原有流程,通过设置一些标记位,如是否被cgroup throttle以及是否在锁之内,通过标志位的组合判断,来判断是否需要临时调整优先级,把已经进入锁且被cgroup throttle的任务临时提高优先级到实时。
当然,这么说是感觉比较容易,实际上在实施过程中还是有大量的细节需要考虑的。