【深度学习:理论篇】--Pytorch之nn.Module详解
目录
1.torch.nn.Module--概述
2.torch.nn.Module--简介
3.torch.nn.Module--实现
3.1.Sequential来包装层
3.2.children和modules
1.torch.nn.Module--概述
1. PyTorch vs. Keras 的设计差异
- Keras(高层框架):
- 推荐通过继承
Layer类自定义层,而非直接继承Model(官方建议)。 - 严格区分“层”和“模型”,强调模块化组合。
- 推荐通过继承
- PyTorch(灵活统一):
- 没有严格的层/模型区分,自定义层、模块或整个模型,统一继承
nn.Module。 - 比如
Linear(全连接层)、Sequential(顺序容器)都是Module的子类。
- 没有严格的层/模型区分,自定义层、模块或整个模型,统一继承
2. 为什么只用 nn.Module,不用 autograd.Function?
nn.Module的优势:- 自动管理参数(如
parameters())、支持 GPU/CPU 切换、内置训练/评估模式(train()/eval())。 - 无需手动写反向传播,PyTorch 自动计算梯度。
- 自动管理参数(如
autograd.Function的局限:- 需手动实现
forward和backward,复杂且容易出错,仅适用于特殊需求(如自定义不可导操作)。
- 需手动实现
“一切皆 Module”:PyTorch 通过 nn.Module 提供统一接口,无论是单层、多层的块,还是完整模型,都按相同方式组织。
2.torch.nn.Module--简介
class Module(object):的主要模块:
| 类别 | 方法 | 功能说明 |
|---|---|---|
| 初始化与核心 | __init__(self) | 构造函数,初始化模块(需调用 super().__init__()) |
forward(self, *input) | 必须重写,定义前向传播逻辑 | |
__call__(self, *input, **kwargs) | 使实例可调用(如 model(x)),自动调用 forward() | |
| 模块管理 | add_module(name, module) | 添加子模块(如 self.add_module('linear', nn.Linear(10, 2))) |
children() | 返回直接子模块的迭代器(不递归) | |
named_children() | 返回 (name, module) 对的迭代器(直接子模块) | |
modules() | 递归返回所有子模块的迭代器 | |
named_modules() | 递归返回 (name, module) 对的迭代器 | |
| 参数管理 | parameters(recurse=True) | 返回所有参数的迭代器(默认递归子模块) |
named_parameters() | 返回 (name, parameter) 对的迭代器(如 'linear.weight') | |
| 设备移动 | cuda(device=None) | 将模块参数和缓冲区移动到 GPU |
cpu() | 将模块参数和缓冲区移动到 CPU | |
| 训练/评估模式 | train(mode=True) | 设置为训练模式(影响 Dropout、BatchNorm 等) |
eval() | 设置为评估模式(等价于 train(False)) | |
| 梯度管理 | zero_grad() | 重置所有参数的梯度(默认设为 None,PyTorch 1.7+ 推荐) |
| 辅助方法 | __repr__() | 返回模块的字符串表示(打印模型结构) |
__dir__() | 返回模块的属性列表(通常无需直接调用) |
注意:
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法。但有一些注意技巧:
- 一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然我也可以吧不具有参数的层也放在里面;
- 一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替
- forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
总结:使用pytorch定义神经网络时,
1.必须继承那nn.Module
2.必须包含__init__构造函数和forward前向传播这两个方法
3.__init__是定义网络结构,forward是前向传播
举例:
import torch
import torch.nn as nnclass MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1, 1) # 输入3通道,输出32通道self.relu1 = nn.ReLU()self.max_pooling1 = nn.MaxPool2d(2, 1) # kernel_size=2, stride=1self.conv2 = nn.Conv2d(32, 32, 3, 1, 1) # 注意:输入应为32通道(修正处)self.relu2 = nn.ReLU()self.max_pooling2 = nn.MaxPool2d(2, 1)# 计算全连接层输入尺寸(需根据实际输出调整)self.dense1 = nn.Linear(32 * 222 * 222, 128) # 临时值,后面会修正self.dense2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.max_pooling1(x)x = self.conv2(x)x = self.relu2(x)x = self.max_pooling2(x)x = x.view(x.size(0), -1) # 展平x = self.dense1(x)x = self.dense2(x)return x# 创建输入张量(假设输入为224x224的RGB图像)
x = torch.randn(4, 3, 224, 224) # batch_size=4, 通道=3, 高=224, 宽=224# 实例化模型
model = MyNet()# 打印网络结构
print("模型结构:")
print(model)# 前向传播
print("\n输入形状:", x.shape)
output = model(x)
print("输出形状:", output.shape) # 应为 [4, 10]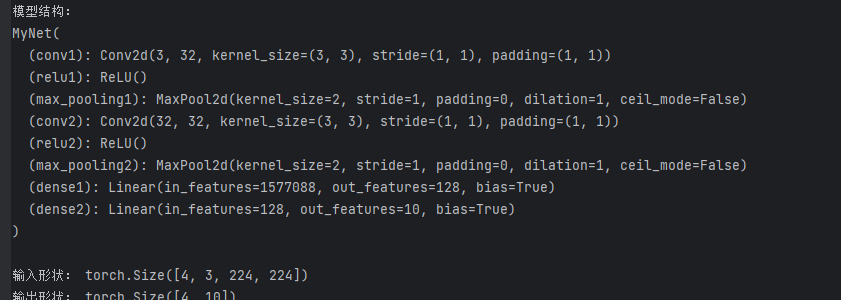
在forward里面实现所有层的连接关系,当然这里依然是顺序连接的
总结:所有放在构造函数__init__里面的层的都是这个模型的“固有属性”.
注意:model(x)相当于model.forward(x)
3.torch.nn.Module--实现
Module类是非常灵活的,可以有很多灵活的实现方式,下面将一一介绍。
3.1.Sequential来包装层
即将几个层包装在一起作为一个大的层(块),前面的一篇文章详细介绍了Sequential类的使用,包括常见的三种方式,以及每一种方式的优缺点,参见:pytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型-CSDN博客
方式一:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block = nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(2))self.dense_block = nn.Sequential(nn.Linear(32 * 3 * 3, 128),nn.ReLU(),nn.Linear(128, 10))# 在这里实现层之间的连接关系,其实就是所谓的前向传播def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((0): Linear(in_features=288, out_features=128, bias=True)(1): ReLU()(2): Linear(in_features=128, out_features=10, bias=True))
)
'''方式二:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block = nn.Sequential(OrderedDict([("conv1", nn.Conv2d(3, 32, 3, 1, 1)),("relu1", nn.ReLU()),("pool", nn.MaxPool2d(2))]))self.dense_block = nn.Sequential(OrderedDict([("dense1", nn.Linear(32 * 3 * 3, 128)),("relu2", nn.ReLU()),("dense2", nn.Linear(128, 10))]))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
'''方式三:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block=torch.nn.Sequential()self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))self.conv_block.add_module("relu1",torch.nn.ReLU())self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))self.dense_block = torch.nn.Sequential()self.dense_block.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))self.dense_block.add_module("relu2",torch.nn.ReLU())self.dense_block.add_module("dense2",torch.nn.Linear(128, 10))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
'''3.2.children和modules
特别注意:Sequential类虽然继承自Module类,二者有相似部分,但是也有很多不同的部分,集中体现在:
Sequenrial类实现了整数索引,故而可以使用model[index] 这样的方式获取一个曾,但是Module类并没有实现整数索引,不能够通过整数索引来获得层
def children(self):"""返回当前模块的直接子模块的迭代器(不包括子模块的子模块)。"""# 示例:若当前模块包含子模块 conv1 和 fc1,则 children() 返回 [conv1, fc1]def named_children(self):"""返回当前模块的直接子模块的迭代器,并附带子模块的名称(格式:(name, module))。"""# 示例:返回 [('conv1', Conv2d(...)), ('fc1', Linear(...))]def modules(self):"""递归返回当前模块及其所有子模块的迭代器(深度优先遍历)。"""# 示例:返回 [当前模块, conv1, conv1.weight, ..., fc1, ...]def named_modules(self, memo=None, prefix=''):"""递归返回当前模块及其所有子模块的迭代器,并附带模块的完整路径名称(格式:(name, module))。"""# 示例:返回 [('', 当前模块), ('conv1', conv1), ('conv1.weight', conv1.weight), ...]'''
注意:这几个方法返回的都是一个Iterator迭代器,故而通过for循环访问,当然也可以通过next
'''
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block=torch.nn.Sequential()self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))self.conv_block.add_module("relu1",torch.nn.ReLU())self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))self.dense_block = torch.nn.Sequential()self.dense_block.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))self.dense_block.add_module("relu2",torch.nn.ReLU())self.dense_block.add_module("dense2",torch.nn.Linear(128, 10))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()1.model.children()方法
for i in model.children():print(i)print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 Sequential 类型,所以有可以使用下标index索引来获取每一个Sequenrial 里面的具体层'''运行结果为:
Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
<class 'torch.nn.modules.container.Sequential'>
Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
)
<class 'torch.nn.modules.container.Sequential'>
'''
(2)model.named_children()方法
for i in model.children():print(i)print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 返回一个tuple,tuple 的第一个元素是'''运行结果为:
('conv_block', Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
<class 'tuple'>
('dense_block', Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
))
<class 'tuple'>
'''(3)model.modules()方法
for i in model.modules():print(i)print("==================================================")
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
==================================================
Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
==================================================
Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
==================================================
ReLU()
==================================================
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
==================================================
Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
)
==================================================
Linear(in_features=288, out_features=128, bias=True)
==================================================
ReLU()
==================================================
Linear(in_features=128, out_features=10, bias=True)
==================================================
'''(4)model.named_modules()方法
for i in model.named_modules():print(i)print("==================================================")
'''运行结果是:
('', MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
))
==================================================
('conv_block', Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
==================================================
('conv_block.conv1', Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
==================================================
('conv_block.relu1', ReLU())
==================================================
('conv_block.pool1', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
==================================================
('dense_block', Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
))
==================================================
('dense_block.dense1', Linear(in_features=288, out_features=128, bias=True))
==================================================
('dense_block.relu2', ReLU())
==================================================
('dense_block.dense2', Linear(in_features=128, out_features=10, bias=True))
==================================================
'''(1)model的modules()方法和named_modules()方法都会将整个模型的所有构成(包括包装层、单独的层、自定义层等)由浅入深依次遍历出来,只不过modules()返回的每一个元素是直接返回的层对象本身,而named_modules()返回的每一个元素是一个元组,第一个元素是名称,第二个元素才是层对象本身。
(2)如何理解children和modules之间的这种差异性。注意pytorch里面不管是模型、层、激活函数、损失函数都可以当成是Module的拓展,所以modules和named_modules会层层迭代,由浅入深,将每一个自定义块block、然后block里面的每一个层都当成是module来迭代。而children就比较直观,就表示的是所谓的“孩子”,所以没有层层迭代深入。