spark的缓存提升本质以及分区数量和task执行时间的先后
文章目录
- 示例代码
- 缓存效果分析
- 第1次 user.count
- 第2次 user.count——这里解释了spark缓存提升的本质原因
- 关于分区数量和task数量以及task的执行流程
- 有多少个分区就有多少线程task并发执行
- 不同分区数量对计算效率的提升
示例代码
import org.apache.spark.storage.StorageLevelval path="file:///home/hadoop/sogouoneday.txt"
val input=sc.textFile(path).map(x=>x.split("\t")).map(x=>(x(1),1))// 执行缓存前,先进入spark的web端http://localhost:4040/storage/查看 缓存情况。
input.cache() // 等价于input.persist(StorageLevel.MEMORY_ONLY)
val user=input.reduceByKey((a,b)=>a+b)
user.count
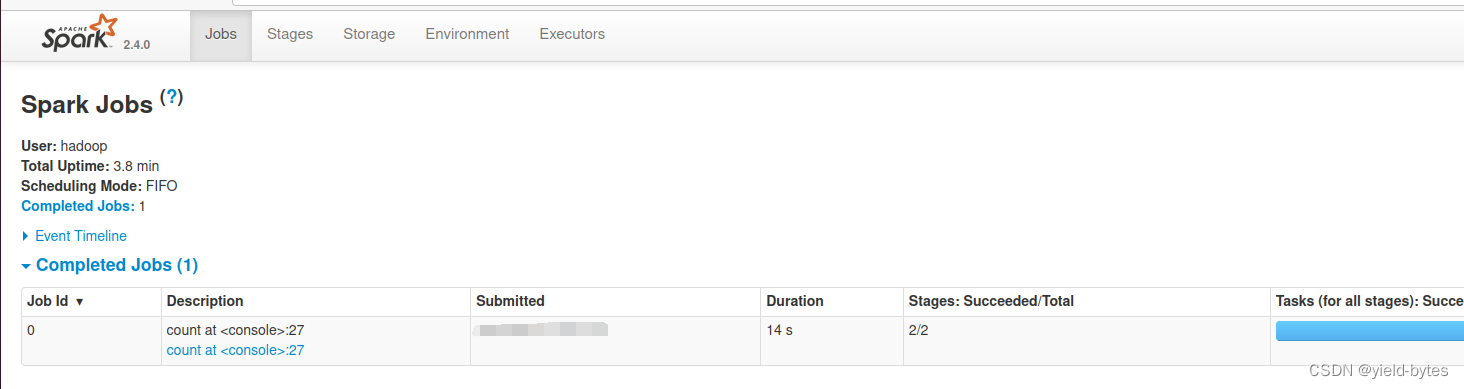
user.count,第一次运行用14s
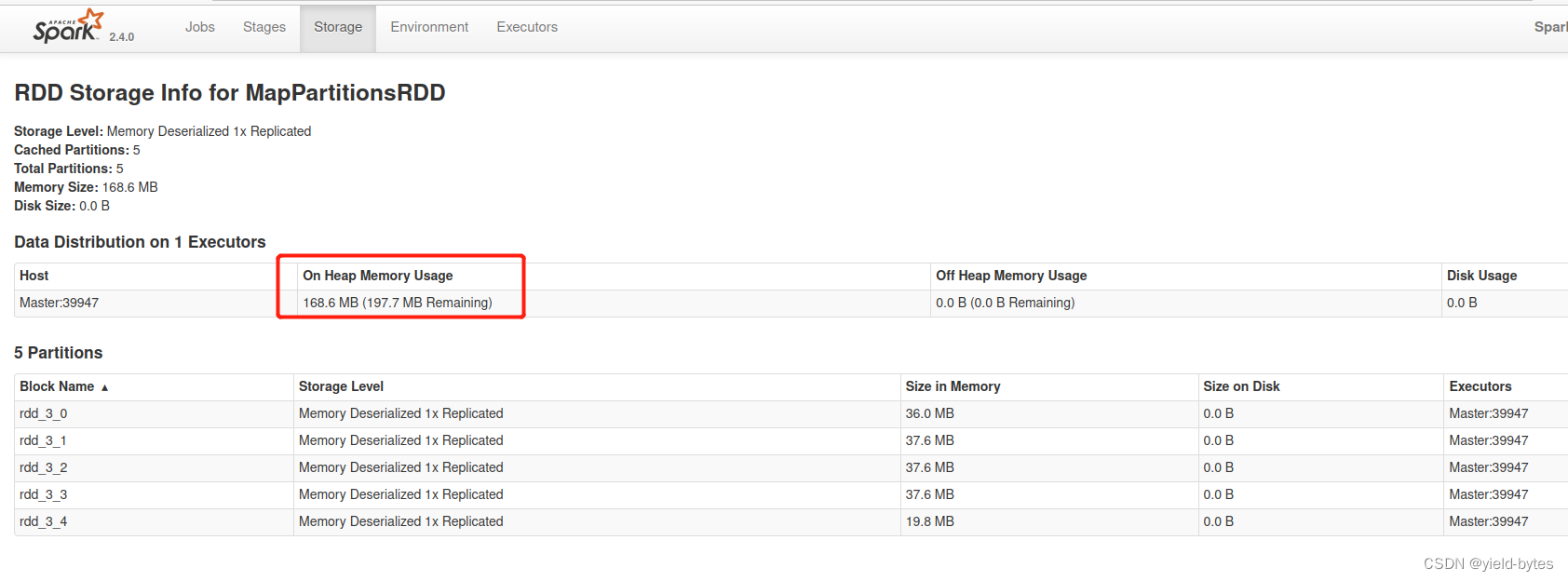
缓存界面提示:
因为数据只有145M,因此可以100%在内存里面缓存

缓存效果分析
第1次 user.count
可以看到有两个阶段,因为整个代码有一条窄依赖关系链,以及单个宽依赖,stage划分是根据出现宽依赖来划分,可以看到,spark第一次读取数据转为RDD的map阶段耗时最多
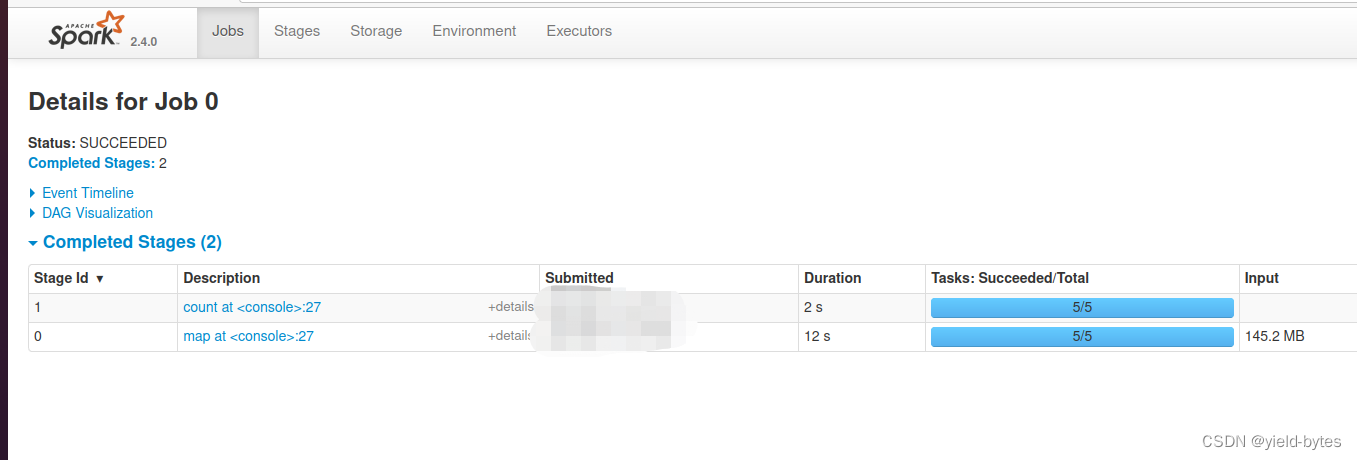
可以看到第一次map这里有5个task工作,因此第一次肯定少不了把数据从其他地方加载到spark的jvm内存!
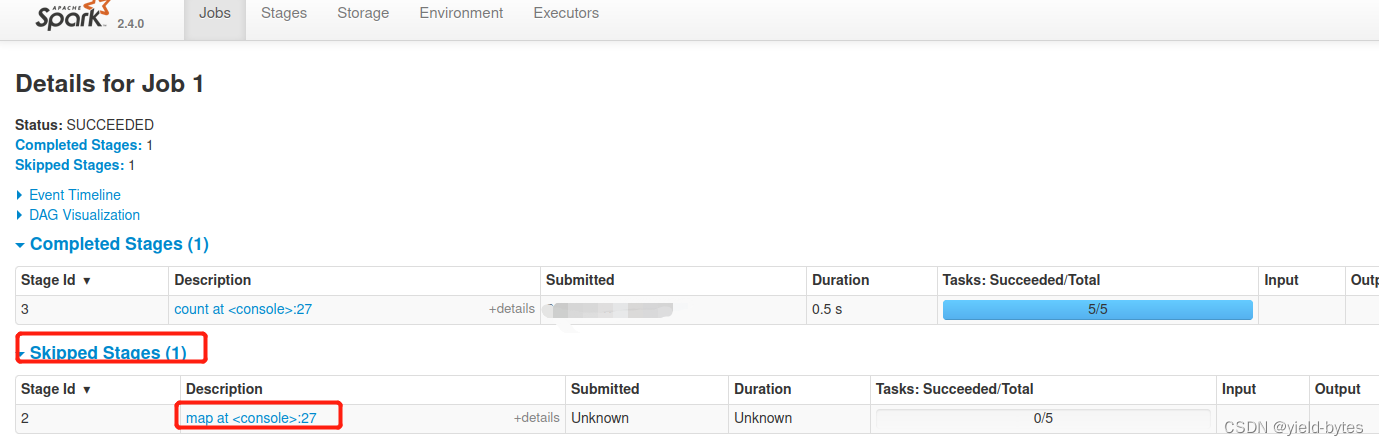
第2次 user.count——这里解释了spark缓存提升的本质原因
相当于“前人种树后人乘凉”的效果,这里第二次的user.count已经不需要map这个处理,因为input这个rdd已经缓存了,不需要重新读取再来执行map操作,从下图可以看出“Skipped Stages”,里面是空的,说明没有task线程去跑。对比第一次的同界面,可以看到第一次map这里有5个task工作,因此第一次肯定少不了把数据从其他地方加载到spark的jvm内存!

关于分区数量和task数量以及task的执行流程
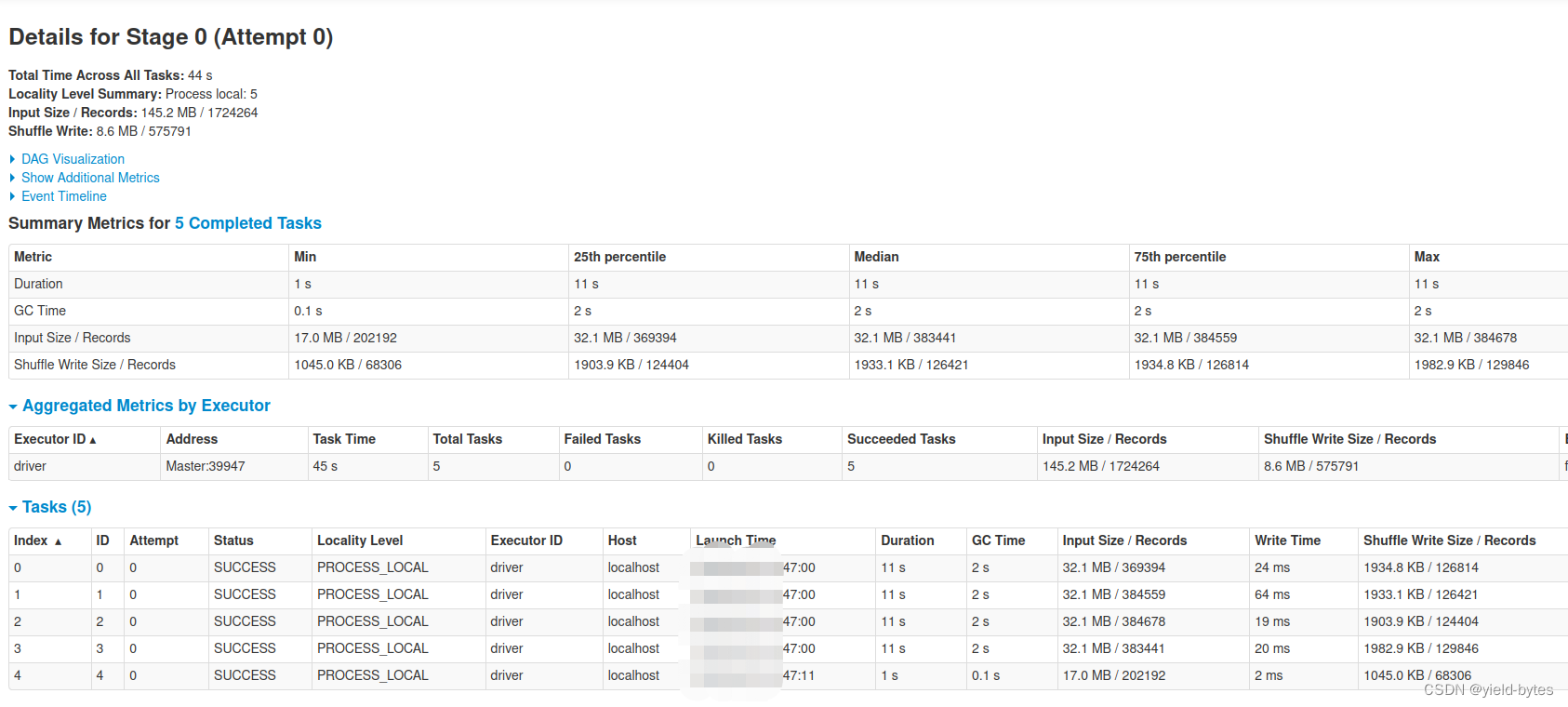
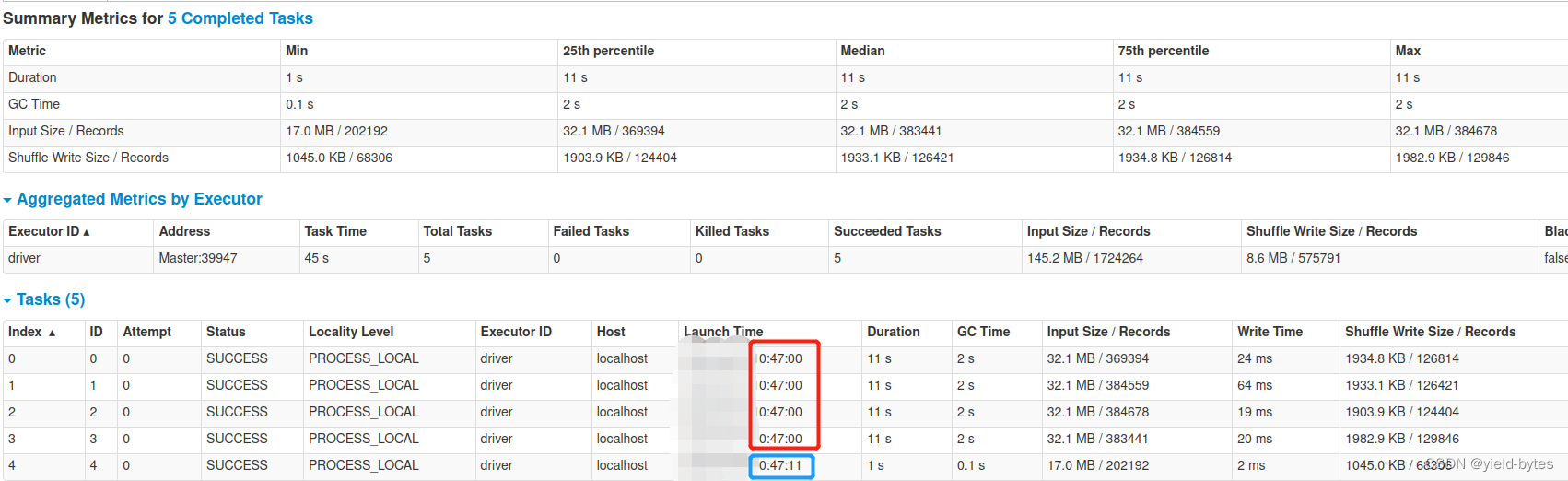
因为数据是145M,虚拟机有4个核,自动分区为4+1共5个分区,因此executor进程需要开启5个线程,也即5个task
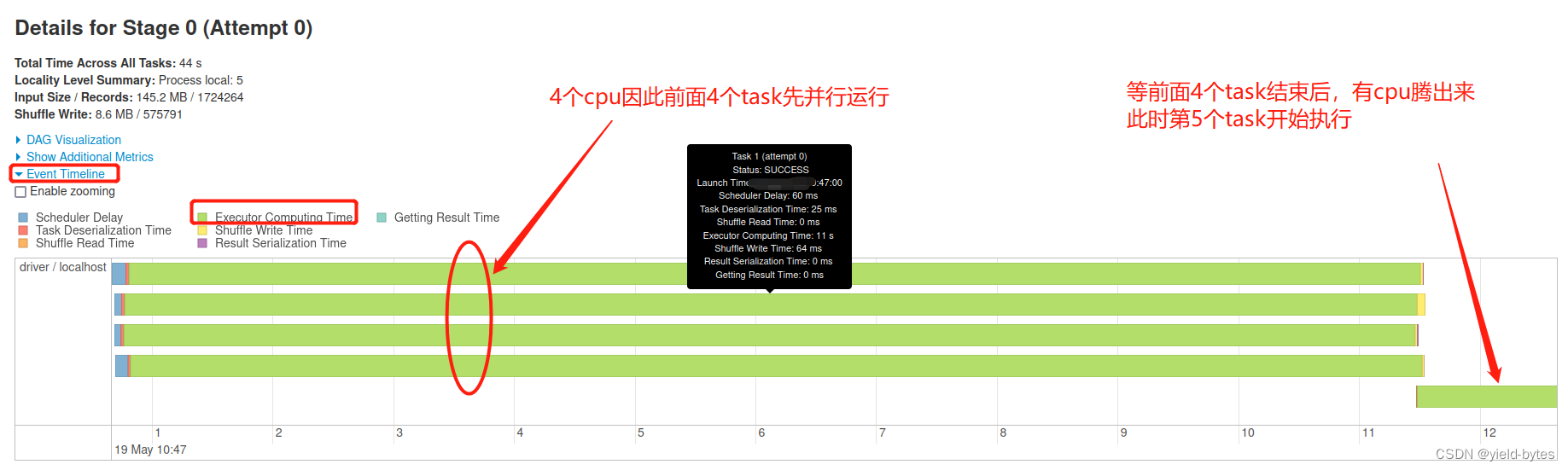
那么这5个task是同时执行代码吗? 显然不是,如下图所示:
因为虚拟机有4个核,因此前面4个分区是并行执行,从47:00开始,到47:11结束,用时11秒
接着第5个task才能开始执行,也即有cpu核数可以用了,因此要等前面4个cpu算完后,才能开始,从47:11秒开始!
从以下的event timeline可以非常清楚看出,cpu个数决定task并行运行的流程
有多少个分区就有多少线程task并发执行
例如现在读取时指定10个分区
val inputRDD=sc.textFile(path,10).map(x=>x.split("\t")).map(x=>(x(1),1))
执行后,spark安排了10个tasks,当然每个task负责的数据量从32M降到14.6M,那么这个10个task的运行时序是怎么调度的呢?
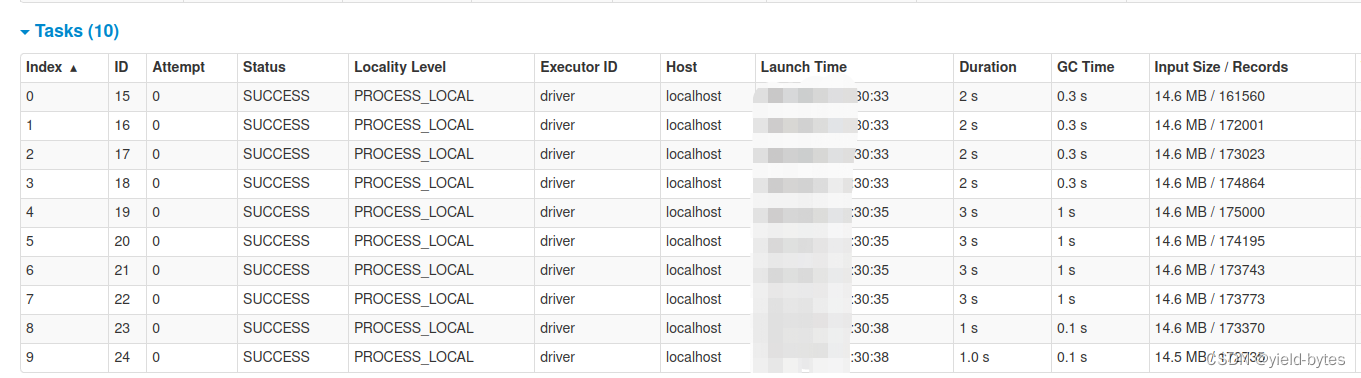
可以看到10个tasks并不是同时执行的,因为只有4个cpu,因此第1组4个task先在33秒进行,第2组task等第1组结束后,从35秒开会执行,最后两个task等第2组完成后,从38秒开始执行。
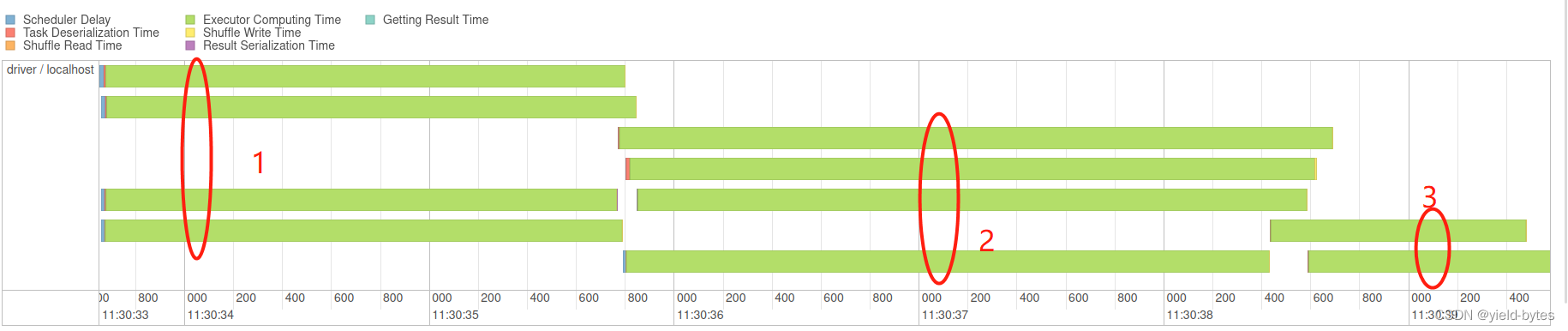
不同分区数量对计算效率的提升
显然分区数量越多,task线程虽然固定,但时cpu是交替执行,计算效率有明细提升
145M,5个分区,用时14s,如果指定spark读取数据时,将其逻辑划分10个分区,那么计算时间用时只需要7s