车道线检测:自动驾驶的“眼睛”
在自动驾驶技术的庞大体系中,车道线检测扮演着至关重要的角色,它就像是自动驾驶汽车的“眼睛”,帮助车辆感知道路边界,从而实现安全、准确的行驶。今天,我们就来深入探讨一下车道线检测的奥秘,看看它是如何让自动驾驶汽车“看清”道路的。
一、车道线检测的重要性
想象一下,当你驾驶汽车在高速公路上行驶时,车道线是引导你保持在正确车道上的关键标识。对于自动驾驶汽车来说,准确检测车道线是实现自动驾驶功能的基础。如果车道线检测不准确,车辆可能会偏离车道,甚至引发交通事故。因此,车道线检测的准确性和可靠性直接关系到自动驾驶的安全性。
二、车道线检测的方法
目前,车道线检测主要有三种主流方法:基于图像分割的方法、基于锚点的方法和基于参数的方法。接下来,我们将逐一深入探讨这三种方法。
(一)基于图像分割的车道线检测
基于图像分割的方法是目前最流行的一种车道线检测方法。它的核心思想是将车道线检测问题转化为图像分割问题。具体来说,就是将输入的图像分割成不同的区域,其中每个区域对应不同的车道线或背景。
1. 如何将车道检测视为分割问题
在图像分割中,输入是一张图像,而输出是一张分割掩模(mask)。这张分割掩模与输入图像的尺寸相同,但每个像素的值不再是原始的颜色值,而是表示该像素属于哪个类别的标签。对于车道线检测,输出的分割掩模中,车道线的像素会被标记为特定的类别(如左车道线、右车道线等),而背景像素则被标记为背景类别。
2. 可使用的架构
大多数用于图像分割的模型都采用编码器-解码器(encoder-decoder)架构。编码器负责提取输入图像的特征,而解码器则根据这些特征生成分割掩模。在车道线检测领域,LaneNet 是一个非常流行的模型。
LaneNet 的架构如下图所示:
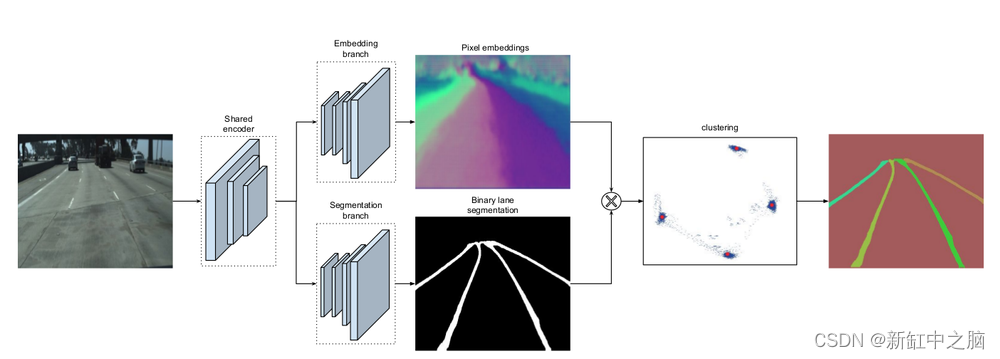
输入图像首先经过一个预训练的编码器(如 E-Net 编码器),然后进入两个模型头。底部模型头是一组上采样层,用于生成二进制分割掩模,回答“这个像素是否属于车道线”的问题;顶部模型头则是一组进行像素嵌入的上采样层,用于进行实例分割。
实例分割的关键在于为每个像素分配唯一的嵌入(embedding),这样属于同一车道线的像素就会具有相似的嵌入,而属于不同车道线的像素则具有不同的嵌入。通过这种方式,LaneNet 不仅可以检测车道线,还可以区分不同的车道线,例如区分左车道线和右车道线,以及实线和虚线。
3. 曲线拟合
得到分割掩模后,还需要进行曲线拟合,将分割掩模中的车道线点拟合成连续的曲线。曲线拟合有三种主要方法:直接曲线拟合、鸟瞰图拟合和神经网络拟合。
- 直接曲线拟合:在图像空间内直接拟合曲线,通过找到适合 2D 平面中检测到的车道点的多项式来实现。这种方法简单,但对现实世界的准确性(如重新投影到 3D 空间时)和消失点的处理存在挑战。
- 鸟瞰图拟合:将图像转换为鸟瞰图(BEV),然后在鸟瞰图中拟合曲线。这种方法通常更精确,因为它考虑了车道线在三维空间中的实际形状。
- 神经网络拟合:一些模型(如 LaneNet 中的 H-Net)直接使用神经网络预测多项式系数或变换参数,从而实现曲线拟合。
(二)基于锚点的车道线检测
基于锚点的方法是另一种常见的车道线检测方法。它的核心思想是将车道线检测问题转化为对锚点的回归问题。这种方法类似于目标检测中的锚框(anchor box)机制,但针对的是车道线。
1. 什么是锚点
在目标检测中,锚框是预定义的边界框,用于表示可能的目标位置和形状。类似地,在基于锚点的车道线检测中,锚点是预定义的线段,用于表示可能的车道线位置和形状。
- 锚生成:在图像上生成预定义的锚点。这些锚点可以是直线或曲线,具体取决于车道线的形状和方向。通常,会根据数据集的统计信息来设计锚点,以便它们能够覆盖各种可能的车道线形状。
- 锚“移位”/偏差:模型预测锚点的调整,使其与实际车道线对齐。这包括调整锚点的位置、形状和大小,以更好地匹配图像中的车道线。
- 非极大值抑制(NMS):通过 NMS 消除冗余的锚点预测,只保留最有可能的车道线。
2. 深入研究 LaneATT 模型
LaneATT 是基于锚点方法中一个非常先进的模型。它的架构如下图所示:
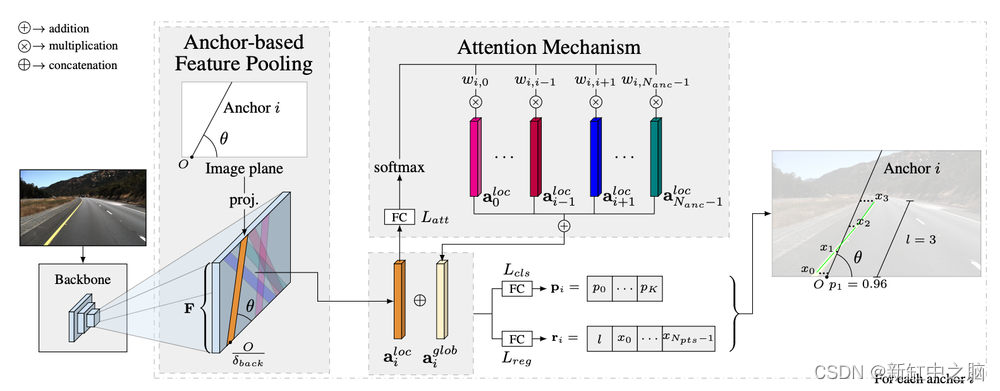
- 特征提取:输入图像首先通过一个骨干网络(如 CNN)提取特征。
- 锚生成:使用注意力机制生成锚点。注意力机制会集中在图像中可能存在车道线的区域,避免在天空或其他无关区域生成锚点。
- 锚“移位”/偏差:对于每个锚点,模型预测其与实际车道线的偏差,并进行分类,以区分不同类型的车道线(如虚线与实线)。
- 非极大值抑制:通过 NMS 消除重叠的车道线预测,最终得到准确的车道线位置。
(三)基于参数的车道线检测
基于参数的方法是车道线检测的另一种方法。它的核心思想是将车道线表示为参数化的曲线(如多项式曲线),然后通过回归这些参数来检测车道线。
1. 多项式拟合
车道线通常可以用多项式曲线来表示。例如,一阶多项式表示直线,二阶多项式表示简单的曲线,而三阶多项式可以表示更复杂的曲线。
- 一阶多项式:(y = ax + b),表示直线。
- 二阶多项式:(y = ax^2 + bx + c),表示简单的曲线。
- 三阶多项式:(y = ax^3 + bx^2 + cx + d),表示更复杂的曲线。
在车道线检测中,通常使用三阶多项式来拟合车道线,因为它可以很好地表示各种形状的车道线。
2. PolyLaneNet 模型
PolyLaneNet 是基于参数方法的一个典型模型。它的核心思想是直接回归车道线的多项式系数。
- 输入图像:输入图像首先通过一个骨干网络提取特征。
- 回归多项式系数:模型直接预测车道线的多项式系数(如三阶多项式的 a、b、c、d)。
- 车道线重建:根据预测的多项式系数,重建车道线的曲线。
这种方法的优点是速度快、简单,但可能在泛化能力上稍弱,因为它依赖于多项式拟合。
三、传统方法与深度学习方法的对比
在深度学习方法出现之前,传统的车道线检测方法主要依赖于计算机视觉技术,如 Canny 边缘检测、霍夫变换等。这些方法虽然在某些情况下可以工作,但存在明显的局限性:
- 鲁棒性差:传统方法对光照变化、阴影和复杂背景的适应性较差,容易出现误检。
- 速度慢:传统方法通常需要多个步骤来处理图像,速度较慢,难以满足实时性要求。
相比之下,深度学习方法具有以下优势:
- 鲁棒性强:深度学习模型可以通过大量数据训练,学习到车道线的各种特征,从而在不同环境下都能保持较高的检测精度。
- 速度快:现代深度学习模型可以在 GPU 上高效运行,能够满足实时性要求。
- 泛化能力好:深度学习模型可以学习到车道线的通用特征,从而在不同场景下都能表现出良好的性能。
四、未来发展方向
车道线检测技术正在不断发展,未来的发展方向主要包括以下几个方面:
- 3D 车道线检测:目前的车道线检测主要集中在 2D 图像上,但未来的发展方向是向 3D 车道线检测迈进。通过 3D 车道线检测,可以更准确地感知车道线在三维空间中的位置和形状,从而提高自动驾驶的安全性和可靠性。
- 多模态融合:将图像、激光雷达、毫米波雷达等多种传感器数据融合起来,可以更全面地感知道路环境,提高车道线检测的精度。
- 端到端学习:端到端学习是指直接从输入图像到输出车道线的映射,无需中间步骤。这种方法可以简化模型结构,提高检测速度,是未来车道线检测的一个重要发展方向。
五、总结
车道线检测是自动驾驶技术的核心之一,它通过检测车道线来引导车辆安全行驶。目前,车道线检测主要有基于图像分割、基于锚点和基于参数三种方法。每种方法都有其优缺点,适用于不同的场景。随着技术的不断发展,车道线检测将朝着 3D 检测、多模态融合和端到端学习的方向发展,为自动驾驶汽车提供更可靠、更准确的车道线感知能力。
希望这篇文章能帮助你更好地理解车道线检测技术。如果你对这个话题感兴趣,不妨深入研究一下相关论文和技术,相信你会有更多有趣的发现!