联合索引失效情况分析
一.模拟表结构:
背景:
MySQL版本——8.0.37
表结构DDL:
CREATE TABLE `unite_index_table` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`clomn_first` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '列1',`clomn_second` bigint NOT NULL COMMENT '列2',`clomn_third` bigint NOT NULL COMMENT '列3',`clomn_fourth` int NOT NULL COMMENT '列4',`clomn_fifth` bigint NOT NULL COMMENT '列5',`clomn_sixth` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '列6',`clomn_seventh` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '列7',`clomn_eighth` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '列8',`clomn_ninth` int NOT NULL COMMENT '列9',`clomn_tenth` varchar(1024) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '列10',`clomn_eleventh` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '列11',`clomn_twelfth` bigint NOT NULL COMMENT '列12',`clomn_thirteenth` bigint NOT NULL COMMENT '列13',`clomn_fourteenth` bigint NOT NULL COMMENT '列14',`clomn_fifteenth` tinyint NOT NULL DEFAULT '1' COMMENT '列15',PRIMARY KEY (`id`),KEY `idx_clomn_fifth` (`clomn_fifth`),KEY `idx_unite` (`clomn_second`,`clomn_third`,`clomn_twelfth`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC COMMENT='模拟表';表结构比较奇怪,是为了模拟实际生产的表结构,表结构信息进行脱敏;
创建mock数据:
DROP PROCEDURE
IFEXISTS generate_mock_data;DELIMITER //
CREATE PROCEDURE generate_mock_data ( IN row_count INT ) BEGINDECLAREi INT DEFAULT 0;START TRANSACTION;-- 开始事务WHILEi < row_count DOINSERT INTO unite_index_table (clomn_first,clomn_second,clomn_third,clomn_fourth,clomn_fifth,clomn_sixth,clomn_seventh,clomn_eighth,clomn_ninth,clomn_tenth,clomn_eleventh,clomn_twelfth,clomn_thirteenth,clomn_fourteenth,clomn_fifteenth )VALUES(SUBSTRING( MD5( RAND( ) ), 1, 20 ),FLOOR( RAND( ) * 10000000000 ),FLOOR( RAND( ) * 10000000000 ),FLOOR( RAND( ) * 100000 ),FLOOR( RAND( ) * 10000000000 ),SUBSTRING( MD5( RAND( ) ), 1, 64 ),IF( RAND( ) > 0.5, SUBSTRING( MD5( RAND( ) ), 1, 64 ), NULL ),IF( RAND( ) > 0.5, SUBSTRING( MD5( RAND( ) ), 1, 20 ), NULL ),FLOOR( RAND( ) * 256 ),IF( RAND( ) > 0.5, SUBSTRING( MD5( RAND( ) ), 1, 1024 ), NULL ),IF( RAND( ) > 0.5, SUBSTRING( MD5( RAND( ) ), 1, 64 ), NULL ),FLOOR( RAND( ) * 10000000000 ),UNIX_TIMESTAMP( ),UNIX_TIMESTAMP( ),FLOOR( RAND( ) * 2 ) );SET i = i + 1;END WHILE;COMMIT;-- 提交事务END //
DELIMITER;
CALL generate_mock_data ( 1000000 );
DROP PROCEDURE
IFEXISTS generate_mock_data;二.不同情况下的查询:
背景补充:
1.做模拟查询的时候,如果使用区间查询(>,>=,<,<=,!=,between and),区间查询的值需要再表中存在,而不是超出区间,不然可能会导致explain分析该SQL会使用索引(实则为查询值越界)
补充:
key_len (JSON name: key_length) | The Due to the key storage format, the key length is one greater for a column that can be |
2.key_len 的计算基于索引中每列的数据类型、字符集以及是否允许 NULL。以下是一些常见数据类型的索引长度:
- INT:4 字节。
- BIGINT:8 字节。
- VARCHAR(n):根据字符集计算。例如,utf8mb4 字符集下,VARCHAR(20) 可能占用 n * 4 字节(utf8mb4 每个字符最多 4 字节)。
- CHAR(n):与 VARCHAR 类似,但 CHAR 是固定长度。
- 如果列允许 NULL,则会额外增加 1 字节(用于存储 NULL 标志)。
在联合索引中,key_len 是查询中实际用到的索引列的长度之和。MySQL 会根据查询条件和最左匹配原则,决定使用索引的前几列。
key_len展示所使用到的索引key的长度,会根据具体使用到的索引的联合索引的key个数以及索引列的类型发生变化;
例如: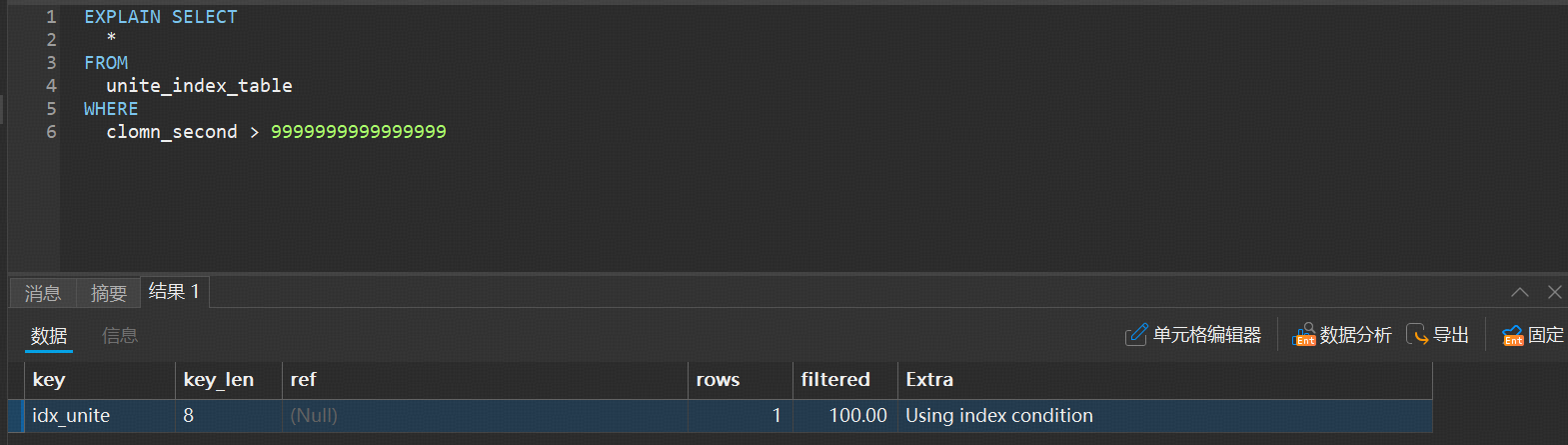
仅使用首列索引;
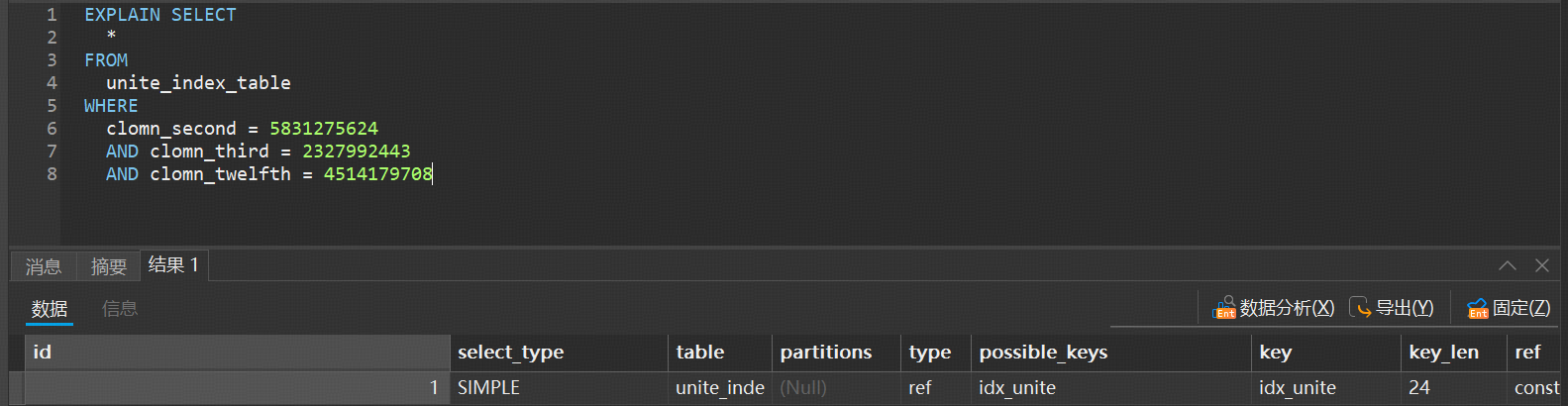 使用所有索引列;
使用所有索引列;
能使用到索引的情况:
1.使用索引的首列等值查询和第三列区间查询:
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_twelfth >= 7827883584 AND clomn_second = 2058342613| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ref | idx_unite | idx_unite | 8 | const | 574 | 33.33 | Using index condition |
分析得出,因为使用了联合索引的第一列,所以查询是使用到了索引,具体使用情况为:Using index condition
联合索引哪怕是仅用到了索引首列,也是可以走索引优化查询(另外提一嘴,是否走联合索引和where条件后的列先后顺序无关,最左匹配和查询时列索引顺序毫无关系,MySQL对SQL会进行解释器优化);
2.使用索引首列等值查询,第二列区间查询,第三列区间查询
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_twelfth != 3665470530 AND clomn_second = 6132267663 AND clomn_third >= 845697131| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | range | idx_unite | idx_unite | 16 | 1 | 90 | Using index condition |
使用到了索引,key_len为16,表名使用了索引的首列和次列;
补充说明:
//将clomn_second全部设置为1,让索引列失去特异性,验证第一种情况是否仍然成立:
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_twelfth >= 7827883584 AND clomn_second = 1| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ref | idx_unite | idx_unite | 8 | const | 304216 | 33.33 | Using index condition |
虽然索引失去了特异性,仍然使用了索引,但是此时的key_len变成了8;
//再将clomn_third全部设置为2,让索引列失去特异性,验证第二种情况是否仍然成立:
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_twelfth != 3665470530 AND clomn_second = 1 AND clomn_third = 2| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ALL | idx_unite | 606845 | 100 | Using where |
出乎意料的,联合索引第一列索引和第二列索引列同时失去特异性后,导致查询不能够走到索引,造成全表扫描
不能使用到索引的情况:
1.索引第一列为区域查询(带有>或者<),不包含其他列
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_second > 251963017| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ALL | idx_unite | 610742 | 50 | Using where |
查询仅带有首列的区间查询, 查询不能走联合索引
2.索引第一列为区间查询(带有>或者<)
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_second > 251963017 AND clomn_third = 5251684771| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ALL | idx_unite | 610742 | 5 | Using where |
因为首行非等值查询,而是区间查询,且有其他查询列,联合查询不走索引(上一个示例都不会索引,这个更不会)
3.使用联合索引的第二列和第三列
EXPLAIN SELECT*
FROMunite_index_table
WHEREclomn_third = 5251684771 AND clomn_twelfth > 2058342| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| 1 | SIMPLE | unite_index_table | ALL | 610742 | 3.33 | Using where |
由于没有筛选首列,联合索引没能走到联合索引的优化,即通常讲的不满足最左匹配原则;
三.总结:
总体结论
- 首列等值查询是关键:
- 只要首列(clomn_second)使用等值查询(=),即使后续列使用区间查询(>、>=)或不等值查询(!=),联合索引仍可使用。
- 首列区间查询导致索引失效:
- 当首列使用区间查询(>、<等),无论后续列条件如何,联合索引无法使用,导致全表扫描。
- 最左匹配原则:
- 联合索引必须从首列开始匹配,跳过首列直接查询后续列无法利用索引。
- 特异性影响:
- 首列失去特异性时,索引仍可使用,但性能下降(扫描行数增加)。
- 首列和后续列均失去特异性时,索引可能失效,导致全表扫描。
- 查询条件顺序无关:
- WHERE子句中列的顺序不影响索引使用,MySQL优化器会自动调整。
建议:
- 索引设计:
- 将常用等值查询的列放在联合索引的前列,确保满足最左匹配原则。
- 避免将区间查询列作为索引首列。
- 特异性优化:
- 确保索引列具有足够的区分度,避免值重复率过高。
- 定期分析数据分布,调整索引策略。
- 查询优化:
- 优先使用等值条件过滤首列数据,再处理范围条件。