MPCount: 人群计数的单域泛化
Paper: https://arxiv.org/pdf/2403.09124.pdf
Code: https://github.com/Shimmer93/MPCount
目录
0. 摘要
1. 引言
2. 相关工作
2.1. 全监督人群计数
2.2. 人群计数域适应(DA)
2.3. 单域泛化(SDG)
3. MPCount
3.1.人群计数相关知识
3.2. 方案概述
3.3. 注意力记忆库 (AMB)
3.4.内容错误掩码(CEM)
3.5.注意一致性损失(ACL)
3.6. 逐补丁分类 (PC)
3.7. 模型训练
4. 说明性实验结果
4.1. 数据集
4.2.实现
4.3. 评估指标
4.4.与SOTA的比较
4.5. 消融研究
5.结论
附:
模型定义:
0. 摘要
密度图回归方法由于其结果的可靠性,已被广泛应用于基于图像的人群计数任务中。然而,当在未知的场景的数据上进行测试时,这种方法往往会遭受严重的性能下降,即所谓的“域转移”问题。为了解决这个问题,我们在这项工作中研究了用于人群计数的单域泛化 (SDG)。现有的 SDG 方法主要用于图像分类和分割,由于其回归性质和标签歧义(即模棱两可的像素级基本事实),很难扩展到我们的案例。我们提出了 MPCount,这是一种即使对于窄源分布数据集也同样有效的新型 SDG 方法。MPCount 存储密度图回归的不同密度值,并通过只有一个记忆库、内容错误掩码和注意力一致性损失来重建域不变特征。通过将图像划分为网格,它使用补丁分类作为辅助任务来减轻标签歧义。通过对不同数据集的大量实验,MPCount被证明在源分布较窄的训练数据中观察到的不同场景下,显著提高了计数精度。
1. 引言
基于图像的人群计数是估计图像中人(或物体)的数量。最近的主流计数方法是密度图回归,其中从输入图像中提取具有连续像素值的密度图,通过对所有这些像素值求和得到总人群计数。在训练期间,groundtruth密度图是通过平滑由人类头部位置给出的点注释来生成的。密度图回归已被证明可以在人群计数方面取得令人鼓舞的结果。
现有的训练模型主要假设测试数据共享相同的源分布,即完全监督学习。然而,这种假设在实践中很难符合,因为有着相机位置、天气条件等变化。与训练数据(即源域)到不可见测试数据(即目标域)的这种偏差被称为域移位,这严重降低了深度学习模型在实际部署中的性能。
为了缓解域转移问题,已经提出了域适应 (DA) 方法将知识从源域转移到目标域,通常是通过使用目标域数据微调预训练模型 [2, 10, 39, 44]。尽管结果很有希望,但 DA 的微调过程通常很费力。此外,目标域数据在现实中可能不容易获得。
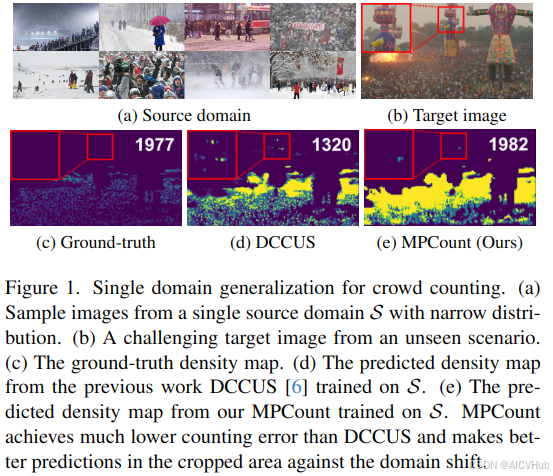
与 DA 相比,域泛化 (DG) 旨在在不改变目标数据的情况下将模型推广到任何未观察到的目标域。由于目标域不需要数据和模型微调,DG 更方便部署在看不见的或不可预测的域中。在这项工作中,我们考虑了用于基于图像的人群计数的单域泛化 (SDG) 的挑战性案例,其中只有一个源域,可能分布窄(图 1a),用于训练。
一种常见的通用 SDG 技术是构建来自图像不同增强版本的域不变特征。这种方法已被证明对各种任务很有希望[5,13,34]。与数据增强无关,许多其他 SDG 方法被提出用于分类和分割,以进一步提高性能。不幸的是,它们中的大多数不能扩展到人群计数这样一种没有类别信息的回归任务。此外,虽然分类和分割任务中的标签是精确和域不变的,但基于密度的人群计数的标签通常是模棱两可的。这种“标签歧义”源于这样一个事实,即密度值是从点注释生成的,因此在不同的场景下,人类头部和背景可能被分配到相似的值。
[6]最近的工作基于将源划分为多个子域,实现了用于人群计数的DG。虽然令人鼓舞,但它需要一个相当广泛的源域分布。我们首次提出了一种在没有子域划分的情况下称为 MPCount 的人群计数 SDG 方法,该方法有效且可扩展以缩小源分布。我们在图1中强调了它的性能,与最先进的方案相比。MPCount通过以下两个新的组件实现了其优越的性能:
- 一个注意力记忆库 (AMB) 来解决密度回归:MPCount 只使用一个注意力记忆库 (AMB),它将从人群图像及其数据增强版本中编码的一对特征作为输入。为了覆盖具有有限内存大小回归的连续密度值,AMB 将每个特征向量重构为记忆向量的注意力。这些记忆向量从不同风格但内容相似(即人群密度)的一对特征中学习域不变表示。我们提出了内容错误掩码 (CEM) 从输入特征中消除与域相关的内容,其特点是实例归一化特征元素对之间存在较大差异。此外,新采用的注意力一致性损失 (ACL) 强制输入特征产生的注意力分数的相似性,确保记忆向量的一致性。
- 逐补丁分类 (PC) 来解决标签歧义:为了解决标签歧义,MPCount 采用了一种新颖的辅助任务,称为逐补丁分类 (PC)。在这个任务中,每个人群图像被均匀地划分为固定大小的正方形补丁,比如16 × 16,分为两类,即包含人头、不包含人头。在密度回归过程中过滤掉分类为无头的区域中的密度值,从而通过较粗但更精确的patchwise二进制标签克服了像素级的歧义。
为了验证 MPCount,我们对包括 ShanghaiTech A (SHA) 和 B (SHB) 和 JHU-Crowd++ 在内的各种人群计数数据集进行了广泛的实验。我们引入了一种新的具有挑战性的窄源分布设置,其中只有同一类别的图像,例如 JHU-Crowd++ 中的“雪”(SN)和“雾/雾霾”(FH)用于训练。我们证明了MPCount不仅在传统的数据集间基准上取得了良好的性能,而且在我们新引入的窄源设置下也取得了良好的性能。令 S → T 表示源域为 S 且目标域为 T 的情况。与现有技术相比,MPCount 在 SN → FH 上显着降低了 21.8% 的错误率,FH →SN 降低了 18.6%,SHB → SHA 上的 18.2%,SHA → SHB 上的 9.5%。
2. 相关工作
2.1. 全监督人群计数
人群计数的主流方法是密度图回归,其中图像的每个像素分配一个计数值,这些值的总和就是总人数的估计。大多数方法侧重于通过采用新颖的网络设计 [1, 16, 17, 31, 45] 或损失函数 [20, 26, 36, 37] 来提高完全监督设置下的计数精度。虽然已经展示了令人鼓舞的结果,但由于泛化能力有限,它们的性能通常在分布外数据上进行评估时显着下降。此外,一些作品 [4, 22, 38] 在某些目的的人群计数中提出了辅助任务。然而,这些任务仍然需要像素级的预测,并且对解决标签歧义的贡献很小。
2.2. 人群计数域适应(DA)
域适应 (DA) 在人群计数中得到了广泛的研究,通过将源域信息适应特定的目标域来解决域转移问题。虽然一些方法研究监督 DA,其中来自目标域的标记数据可用 [40, 44],但大多数方法处理无监督 DA,仅使用未标记的目标域数据 [2, 7, 18, 39, 41, 47]。尽管取得了显着的进步,但 DA 方法通常需要来自目标域的数据,这在实践中可能不容易获得。
2.3. 单域泛化(SDG)
域泛化 (DG) 方法旨在仅使用源域数据来训练具有泛化能力的网络,当只有一个源域可用时,单域泛化 (SDG) 就是DG的一个特殊情况。SDG 有多种技术,包括 1) 对抗性数据生成 [15, 25, 46, 50]、2) 特征归一化/白化变换 [5, 12, 23, 24, 43] 和 3) 领域通用网络设计,例如卷积层 [35]、视觉转换器 [32] 和内存库 [3]。在各种 SDG 方法中,一种常见的通用技术是用数据增强和从不同的特征增强版本中提取域不变信息[5,13,43]来模拟域转移。虽然 SDG 在分类和分割中引起了广泛的关注,但由于其回归性质和标签歧义,它在人群计数中仍然是一个新兴领域。
DCCUS [6] 研究了人群计数的 SDG。在这种方法中,源域被动态聚类为子域,模拟为元学习策略中的元训练和测试集。提出了两种类型的内存模块和几种损失来区分和记录域不变和相关信息。DCCUS 专门为回归设计了记忆机制,但没有考虑模糊标签的问题。此外,当源域服从窄分布时,子域划分过程可能会经历降低的有效性,影响计数模型的泛化能力。MPCount 在没有子域划分的情况下,采用新的补丁分类来解决标签歧义问题。此外,在不需要子域分区的情况下引入了用于回归的单个存储库,使 MPCount 即使在窄分布的源域中也能很好地泛化。
3. MPCount
本节详细描述了我们的 MPCount 方案。我们首先回顾第3.1节中人群计数的基本概念。接下来,在第3.2节中,我们对整个方案进行了全面的概述。然后我们详细阐述了为密度回归设计的注意力记忆库(第 3.3 节),然后是内容错误掩码(第 3.4 节)和注意力一致性损失(第 3.5 节)。之后,我们讨论了提出解决模糊标签挑战的补丁分类(第 3.6 节)。最后,我们在第 3.7 节中详细介绍了整体训练损失。
3.1.人群计数相关知识
首先,我们通过密度图回归回顾了基于深度学习的人群计数的基本知识。我们的目标是训练一个参数为θ的神经网络N,它接受输入图像I∈RH×W×3,并输出大小为H×W的密度图ˆD=N(I;θ)。估计计数ˆc是ˆD中所有像素级密度值的总和,即,
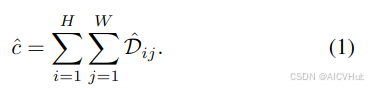
ground-truth密度图的生成通常遵循[28]中的方法。给定人头点注释H,其中每个h∈H是头部位置的坐标,地面真实密度图D∈RH×W被计算为应用于每个头部坐标h的2D高斯滤波器的总和,即,
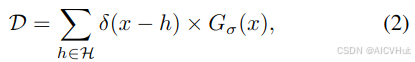
其中 δ(·) 是离散增量函数,Gσ (·) 是具有固定方差 σ 的高斯核。监督网络的一个常见目标函数N可以写成:
![]()
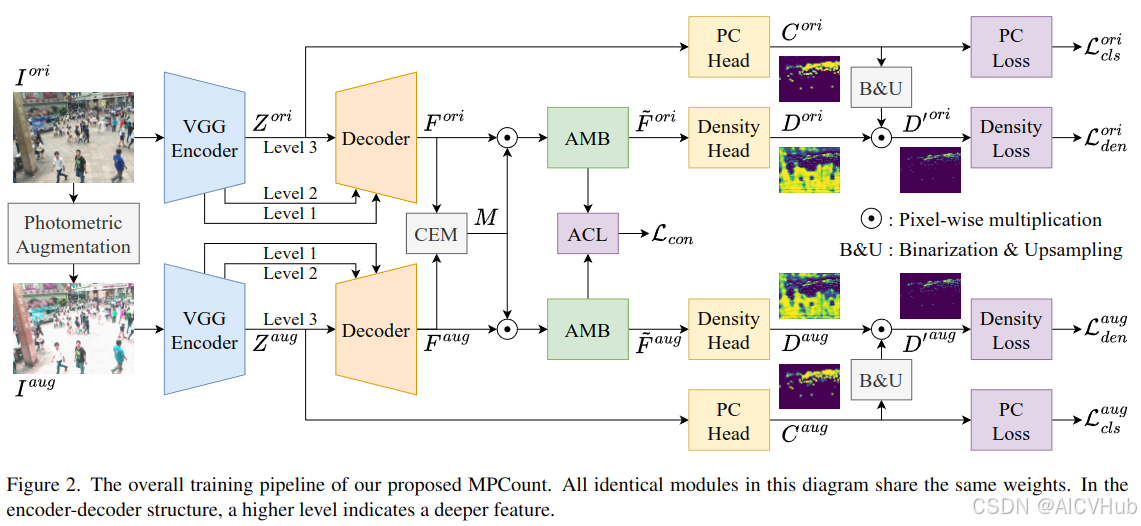
3.2. 方案概述
我们的方法的整体结构如图2所示。在训练过程中,将光度变换应用于原始图像,生成增强版本
。特征提取器将它们编码为特征
和
,并对它们应用内容错误掩码 (CEM) M。通过注意力记忆库 (AMB) 将掩码特征重构为 ̃
和
,并传递给密度头进行人群密度预测。同时,特征提取器
和
编码的最高级特征被馈送到逐补丁分类 (PC) 头中,并将预测的 PC 映射 (PCMs)
和
二值化并调整大小为掩码,以在估计的密度图
和
中过滤掉没有人类头的区域。最终预测
和
是两个密度图,其中一些区域被 PCM 掩盖。整个训练过程在密度损失、PC 损失和注意力一致性损失 (ACL) 的组合下进行监督。推理过程仅使用
作为输入,并输出单个密度图
。
3.3. 注意力记忆库 (AMB)
注意力记忆库 (AMB) 旨在自动学习域不变特征以进行密度回归。[14] 提出了一个记忆库,其中内存向量是单独更新的,每个存储库对应于某个类别。然而,这种设计不能应用于回归任务,因为有限数量的内存向量不能覆盖连续的密度值。受[6]的启发,我们将每个特征向量重构为对记忆向量的注意,使任何密度值都可以表示为记忆库中代表性值的线性组合。
AMB 由维度为 C 的 M 个内存向量组成。给定一个扁平的输入特征图
,我们首先计算特征 F(query)和内存 V(key)之间的注意力分数 A。然后将重构的特征图
计算为 V(value)与 A 的线性组合作为权重。重建过程可以总结如下:
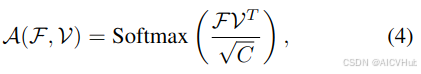

虽然 [6] 依赖于对应于不同子域的多个存储库来区分域不变和相关信息,但我们只使用了单个 AMB,并提出了新的 CEM(第 3.4 节)和 ACL(第 3.5 节),以确保它存储域不变表示。为此,我们的特征重建机制可以在没有子域划分的情况下工作,即使在源分布较窄的情况下也能有效。
3.4.内容错误掩码(CEM)
CEM 被提议通过排除可能的领域相关内容信息来保证输入特征对中包含的内容的相似性。解开特征中的样式和内容的常用技术是实例归一化 (IN) [33],其中特征统计(通道均值和方差)被认为包含样式信息,而实例归一化特征保留内容信息。基于这个想法,我们假设实例归一化特征的差异反映了域转移对特征内容的影响,并可能误导 AMB 学习与领域相关的信息。因此,我们在输入特征中过滤掉链实例归一化版本之间的差异高于某个阈值的元素,从而产生一对具有相似内容信息的特征,用于域不变特征重建。
更具体地说,给定从原始和增强图像中提取的特征,和
,我们定义内容错误掩码
如下:
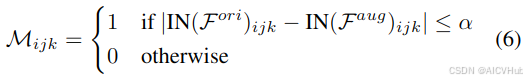
其中 α 是阈值,指示错误值是否反映了域转移引起的内容信息可能不一致。给定 F 是和
之一,我们通过以下方式过滤掉与领域相关的内容信息:
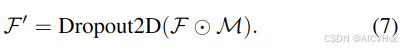
这一步将随机 2D dropout 应用于 F',以防止内存仅依赖于某些通道。
3.5.注意一致性损失(ACL)
第3.4节中保留的和
的风格信息可能会对AMB内存向量上的注意力分布产生很大的差异,即使它们包含相同的内容信息。为了确保每个内存向量始终存储特定的域不变表示,我们提出了注意力一致性损失 (ACL) 来强制从
和
生成的注意力分数的相似性。
我们将方程式4中的 A作为分布,ACL 计算为
生成的
与
生成的
之间的距离。这里选择简单的欧几里得距离作为距离度量,因为它在训练期间的计算稳定性:
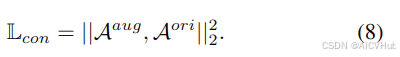
3.6. 逐补丁分类 (PC)

如第 3.1 节所述,ground-truth 密度图通常仅基于点注释计算。在不同的场景中,由于头部大小不同,人类头部和背景的像素可能被分配相同的密度值(图3a),违反了标签准确且域不变的常见假设,导致人群计数中的标签模糊。
为了解决标签歧义,我们提出了一种新的辅助任务,称为patch-wise分类(PC)及其对应的监督信号patch-wise分类图(PCM),如图3b所示。PCM将图像均匀地划分为P × P (P = 16经验)补丁,并将每个补丁分为两类:包含人头。这种补丁级预测通过提供更粗糙但更准确的补丁级信息来减轻像素级密度图中的不确定性。
在实践中,补丁大小为 P 的真值 PCM C 可以计算为:
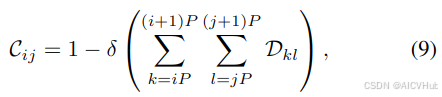
其中 D 是 真值 密度图,δ(·) 是离散增量函数。
模型通过二元交叉熵 BCE的监督来预测一个PCM :
![]()
随后,对进行二值化和调整大小以获得与预测密度图
的维度相匹配的
。然后使用
对
中没有人群分类的区域进行掩码,得到最终的密度图
:
![]()
最后,利用真值密度图D对密度回归头进行监督,利用eq.(3)中的公共欧氏距离作为目标函数:
![]()
3.7. 模型训练
整体训练损失是密度损失、pc 损失和注意力一致性损失的组合,可以写成:
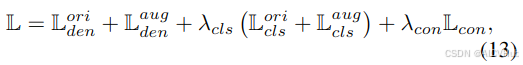
其中 λ_cls 和 λ_con 是权重参数来平衡不同的损失项。
4. 说明性实验结果
4.1. 数据集
我们在四种主流人群计数数据集上评估我们的方法:shanghaitech 部分 a & b, ucf-qnrf 和 jhu-crowd++。

- shanghaitech [45] 由两部分组成,sha (a) 和 shb (b)。sha 包含 300 个训练图像和 182 个测试图像,而 shb 包含 400 个训练图像和 316 个测试图像。sha中的图像是从互联网上收集的,具有高度拥挤的场景。相比之下,shb 是从 shanghai 的几个街道捕获的,其图像显示人群密度通常低于 sha 中的人群密度。
- ucf-qnrf (q) [11] 由 1201 个训练图像和 334 个测试图像组成。这是一个具有挑战性的数据集,具有广泛的人群密度、场景、视点和照明条件。
- jhu-crowd++ [29] 是一个包含 4372 张图像的大规模数据集,训练集、验证集和测试集分别有 2722、500 和 1600 张图像。此外,该数据集还提供了图像级标签,包括 16 种场景和 4 种天气条件。对于场景注释,有 879 张图像标记为“staium”(sd)和 573 个标记“街道”(st),用作两个源域。对于天气注释,我们使用 201 张图像标记为“雪”(sn)和 168 张图像标记为“雾/雾霾”(fh)作为源域。在每个域中,80% 的图像被选为训练集,其余 20% 用于测试。具有相同标签的数据属于比主流数据集更窄的分布,因此对于 sdg 更具挑战性。这些特定场景和特定天气领域的说明性样本如图4所示。
令 s → t 表示 s 是源域的情况,t 是目标域。利用数据集进行了两种不同设置下的实验:1)整个数据集被视为单个域:a → b / q, b → a / q 和 q → a / b; 2)根据图像级标签将数据集划分为子集,一个子集构成一个域:sd ↔ sr 和 sn ↔ fh。
4.2.实现
我们采用 vgg16-bn [27] 作为我们模型中的特征提取器。密度回归头是具有1×1滤波器的单个卷积层,而分类头由3×3和1×1卷积层组成。除最后一层之外的所有卷积层之后都使用批量归一化。对于数据增强,我们应用了三种类型的光度变换,颜色抖动,高斯模糊和锐化。我们还随机裁剪大小为320 × 320的图像补丁,同时对原始图像和增强图像采用随机水平翻转。我们选择adamw[19]作为优化器,1cyclelr[30]作为学习率调度器,最大学习率设置为1e-3,最大epoch为300。内存大小m设置为1024,维数c为256。我们使用0.5的内容误差阈值α,损失权重λcls和λcon都设置为10。
4.3. 评估指标
我们用平均绝对误差 (mae) 和均方误差 (mse) 来评估我们的方法,定义如下:
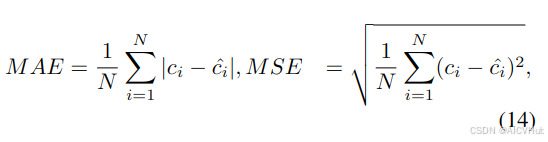
其中 n 是测试图像的数量,ci 是第 i 个图像的 真值 计数,^ci 是预测计数。这两个指标的较低值表示更好的性能。
4.4.与SOTA的比较
在本小节中,我们将我们的mpcount与不同基准上最先进的方法进行比较,如图5所示:
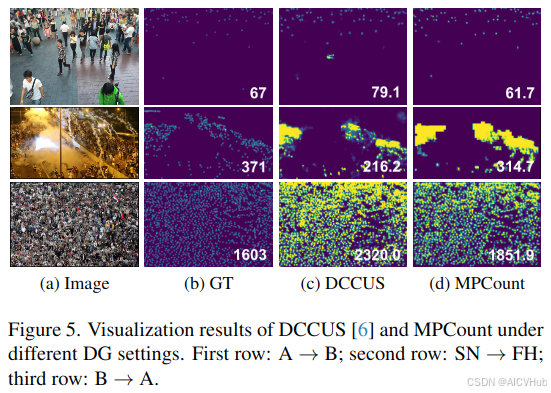
表1 显示了 a → b / q, b → a / q 和 q → a / b 的结果。所选基线可以分为三类:
- 完全监督的人群计数:bl [20]、dmcount [37]、sasnet [31]、chfl [26] 和 man [17]。
- 人群计数的域适应:rbt [18]、c2mot [41]、fgfd [47]、daot [48] 和 fsim [49]。
- 单域泛化:ibn [23]、sw [24]、isw [5]、dg-man [21] 和 dccus [6]。
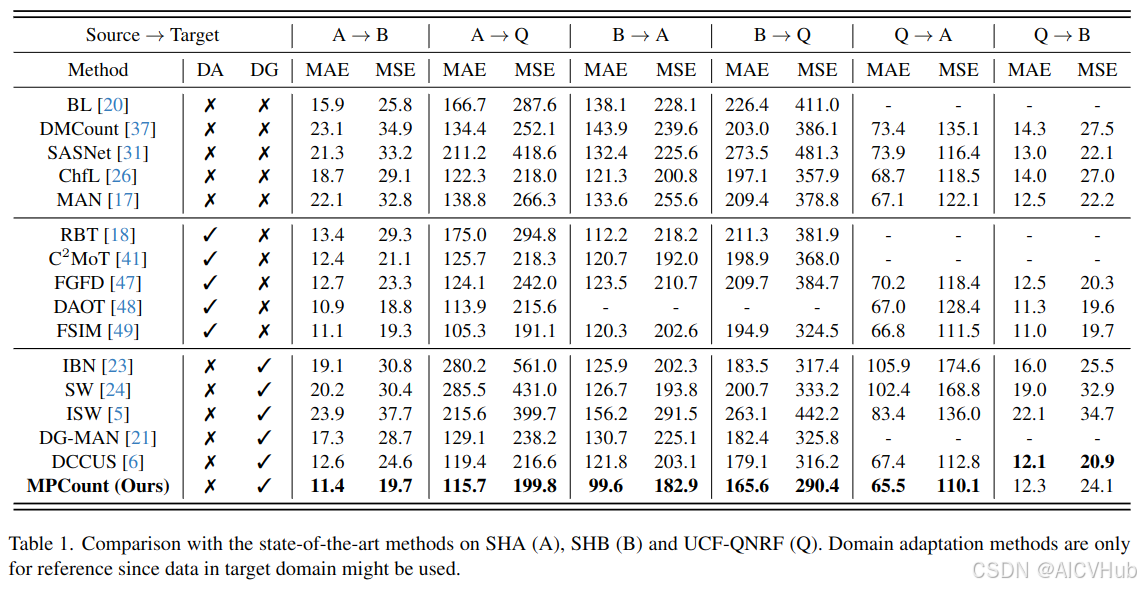
所有结果都是从以前的论文中复制的,除了 ibn、sw 和 isw,它们是最初设计用于分类或分割的基于特征归一化/白化的 sdg 方法,并适应我们人群计数。域适应方法仅列出以供参考,因为来自目标域的数据通常在适应期间可见。
在大多数这些设置下,我们的 mpcount 优于所有 dg 方法,包括 b → a 上的显着误差减少 18.2%。值得注意的是,即使与 da 方法相比,mpcount 在某些情况下也表现出出色的性能,为我们设计的有效性提供了令人信服的证据。
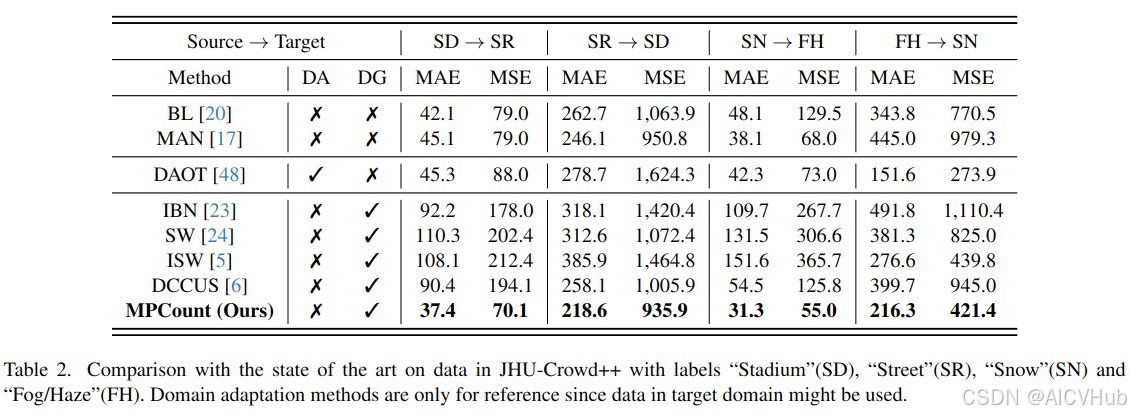
在表2中,我们进一步对场景特定领域 sd ↔ sr 和特定天气域 sn ↔ fh 进行了实验。bl[20]、man[17]、daot[48]和dccus[6]使用他们发布的代码进行训练,而ibn[23]、sw[24]和isw[5]是我们自己改编的。我们观察到基于归一化/白化的方法不能取得令人满意的结果,这可能是因为从特征统计中消除了有用的信息。DCcus 也比完全监督的方法获得了更差的结果,这反映了当源域分布较窄时,聚类过程可能无法产生有意义的子域。相比之下,我们的 mpcount 在所有测试方法中仍然表现最好,证明了它在域分布较窄的挑战性条件下的优越性。
4.5. 消融研究
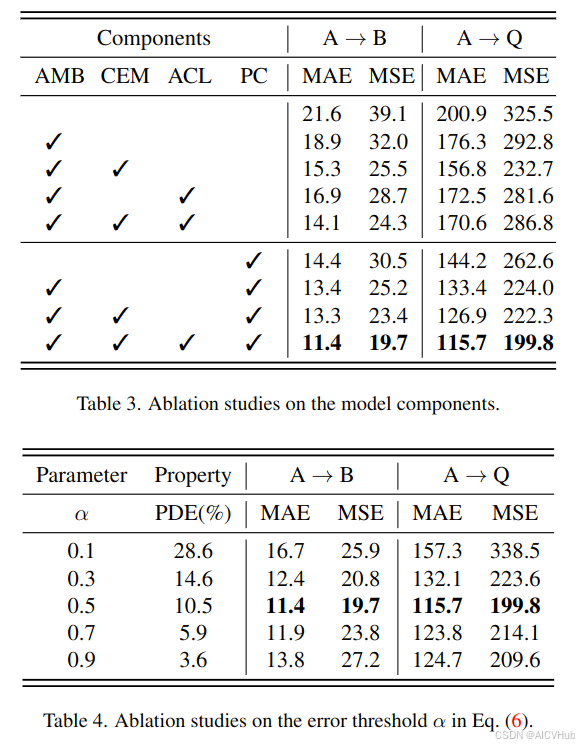
在本节中,我们在模型组件 a → b / q 的设置下进行消融研究和其他分析。我们从一个简单的编码器-解码器结构化基线模型开始,并单独添加或删除每个组件以验证其有效性。实验结果显示在表3中。
- 注意力记忆库:在添加 amb 之后,性能在两个目标域上不断提高,如选项卡所示。3.这验证了amb可以有效地帮助模型通过重构域不变特征进行密度回归进行泛化。
- 内容错误掩码和注意力一致性损失:接下来,我们测试了 cem 和 acl 对 amb 的影响。选项卡中的结果。3 表明这两个组件通常可以提高性能,尤其是在存在 pc 时。
- 逐补丁分类:最后,带有 pc 的模型优于没有 pc 的模型,如选项卡中所示。3.这表明这样的辅助任务对于dg很有用,通过补偿具有精确补丁级标签的模糊像素级标签。
α 的影响:eq.(6)中提到的CEM α的阈值控制特征中减少的元素(pde)的部分。根据表4中的结果,α = 0.5 在所有设置下都产生了最佳性能,pde 为 10.5%。还指出,使用过大的 α (0.9) 值可能不足以过滤掉与领域相关的信息,而太小的值 (0.1) 将让有用的信息消除。
M 和 C 的影响:每个向量 c 的内存向量 m 和维度的数量是 amb 的两个重要参数。为了独立演示它们的效果,我们在保持另一个固定的同时调整一个参数。选项卡中的结果。5 显示,在所有参数变化中,m = 1024,c = 256 是最佳选择。
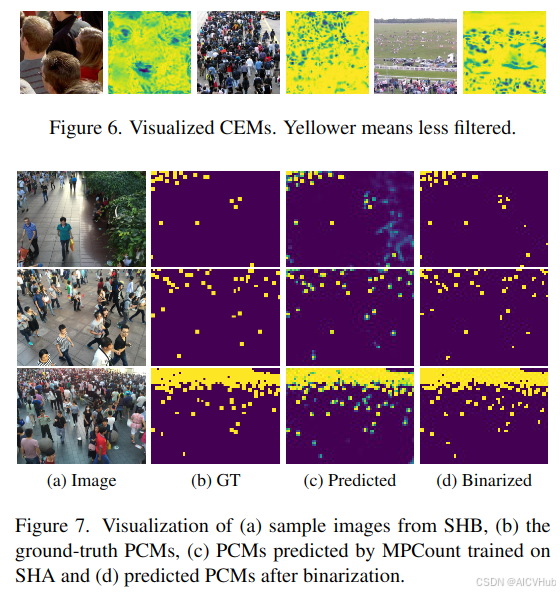
CEMs的可视化: 我们在图6中展示了cems的可视化,每个可视化沿通道维度求和。结果表明,人群信息通常对域转移的敏感性高于环境。
pcms的可视化。我们从mpcount中可视化预测和二值化的pcms进行定性分析。如图7所示,mpcount预测准确的pcms,提供人群位置的可靠信息。在原始预测pcms中,分类分数低的不可信预测,在二值化pcms中被过滤掉。结果表明,pc可以有效地缓解标签歧义问题,并有助于更强大的人群计数模型对抗域转移。
5.结论
本文提出mpcount来解决可能存在窄源分布的人群计数的单域泛化问题。mpcount 解决了两个独特的挑战,即密度回归和标签歧义。我们提出了一个注意力记忆库来重建用于回归的域不变特征,内容错误掩码消除与领域相关的内容信息和注意力一致性损失,以确保记忆向量的一致性。patch-wise分类是一种新的辅助任务,用准确的信息来缓解模糊的像素级标签,增强了密度预测的鲁棒性。在知名数据集上的大量实验表明,在不同的不可见场景和狭窄的源域下,mpcount在各种基准上都取得了显著最好的结果。
附:
模型定义:
详见:https://github.com/Shimmer93/MPCount/blob/main/models/models.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
from einops import rearrange
from math import sqrtclass ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1, bias=False, bn=False, relu=True):super().__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation=dilation, bias=bias)self.bn = nn.BatchNorm2d(out_channels) if bn else Noneself.relu = nn.ReLU(inplace=True) if relu else Nonedef forward(self, x):y = self.conv(x)if self.bn is not None:y = self.bn(y)if self.relu is not None:y = self.relu(y)return ydef upsample(x, scale_factor=2, mode='bilinear'):if mode == 'nearest':return F.interpolate(x, scale_factor=scale_factor, mode=mode)else:return F.interpolate(x, scale_factor=scale_factor, mode=mode, align_corners=False)class DGModel_base(nn.Module):def __init__(self, pretrained=True, den_dropout=0.5):super().__init__()self.den_dropout = den_dropoutvgg = models.vgg16_bn(weights=models.VGG16_BN_Weights.DEFAULT if pretrained else None)self.enc1 = nn.Sequential(*list(vgg.features.children())[:23])self.enc2 = nn.Sequential(*list(vgg.features.children())[23:33])self.enc3 = nn.Sequential(*list(vgg.features.children())[33:43])self.dec3 = nn.Sequential(ConvBlock(512, 1024, bn=True),ConvBlock(1024, 512, bn=True))self.dec2 = nn.Sequential(ConvBlock(1024, 512, bn=True),ConvBlock(512, 256, bn=True))self.dec1 = nn.Sequential(ConvBlock(512, 256, bn=True),ConvBlock(256, 128, bn=True))self.den_dec = nn.Sequential(ConvBlock(512+256+128, 256, kernel_size=1, padding=0, bn=True),nn.Dropout2d(p=den_dropout))self.den_head = nn.Sequential(ConvBlock(256, 1, kernel_size=1, padding=0))def forward_fe(self, x):x1 = self.enc1(x)x2 = self.enc2(x1)x3 = self.enc3(x2)x = self.dec3(x3)y3 = xx = upsample(x, scale_factor=2)x = torch.cat([x, x2], dim=1)x = self.dec2(x)y2 = xx = upsample(x, scale_factor=2)x = torch.cat([x, x1], dim=1)x = self.dec1(x)y1 = xy2 = upsample(y2, scale_factor=2)y3 = upsample(y3, scale_factor=4)y_cat = torch.cat([y1, y2, y3], dim=1)return y_cat, x3def forward(self, x):y_cat, _ = self.forward_fe(x)y_den = self.den_dec(y_cat)d = self.den_head(y_den)d = upsample(d, scale_factor=4)return dclass DGModel_mem(DGModel_base):def __init__(self, pretrained=True, mem_size=1024, mem_dim=256, den_dropout=0.5):super().__init__(pretrained, den_dropout)self.mem_size = mem_sizeself.mem_dim = mem_dimself.mem = nn.Parameter(torch.FloatTensor(1, self.mem_dim, self.mem_size).normal_(0.0, 1.0))self.den_dec = nn.Sequential(ConvBlock(512+256+128, self.mem_dim, kernel_size=1, padding=0, bn=True),nn.Dropout2d(p=den_dropout))self.den_head = nn.Sequential(ConvBlock(self.mem_dim, 1, kernel_size=1, padding=0))def forward_mem(self, y):b, k, h, w = y.shapem = self.mem.repeat(b, 1, 1)m_key = m.transpose(1, 2)y_ = y.view(b, k, -1)logits = torch.bmm(m_key, y_) / sqrt(k)y_new = torch.bmm(m_key.transpose(1, 2), F.softmax(logits, dim=1))y_new_ = y_new.view(b, k, h, w)return y_new_, logitsdef forward(self, x):y_cat, _ = self.forward_fe(x)y_den = self.den_dec(y_cat)y_den_new, _ = self.forward_mem(y_den)d = self.den_head(y_den_new)d = upsample(d, scale_factor=4)return dclass DGModel_memadd(DGModel_mem):def __init__(self, pretrained=True, mem_size=1024, mem_dim=256, den_dropout=0.5, err_thrs=0.5):super().__init__(pretrained, mem_size, mem_dim, den_dropout)self.err_thrs = err_thrsself.den_dec = nn.Sequential(ConvBlock(512+256+128, 256, kernel_size=1, padding=0, bn=True))def jsd(self, logits1, logits2):p1 = F.softmax(logits1, dim=1)p2 = F.softmax(logits2, dim=1)# pm = (0.5 * (p1 + p2))# jsd = 0.5 / logits1.shape[2] * (F.kl_div(p1.log(), pm, reduction='batchmean') + \# F.kl_div(p2.log(), pm, reduction='batchmean'))# log_p1 = F.log_softmax(logits1, dim=1)# log_p2 = F.log_softmax(logits2, dim=1)# jsd = F.kl_div(log_p2, log_p1, reduction='batchmean', log_target=True) / logits1.shape[2]jsd = F.mse_loss(p1, p2)return jsddef forward_train(self, img1, img2):y_cat1, _ = self.forward_fe(img1)y_cat2, _ = self.forward_fe(img2)y_den1 = self.den_dec(y_cat1)y_den2 = self.den_dec(y_cat2)y_in1 = F.instance_norm(y_den1, eps=1e-5)y_in2 = F.instance_norm(y_den2, eps=1e-5)e_y = torch.abs(y_in1 - y_in2)e_mask = (e_y < self.err_thrs).clone().detach()y_den_masked1 = F.dropout2d(y_den1 * e_mask, self.den_dropout)y_den_masked2 = F.dropout2d(y_den2 * e_mask, self.den_dropout)y_den_new1, logits1 = self.forward_mem(y_den_masked1)y_den_new2, logits2 = self.forward_mem(y_den_masked2)loss_con = self.jsd(logits1, logits2)d1 = self.den_head(y_den_new1)d2 = self.den_head(y_den_new2)d1 = upsample(d1, scale_factor=4)d2 = upsample(d2, scale_factor=4)return d1, d2, loss_conclass DGModel_cls(DGModel_base):def __init__(self, pretrained=True, den_dropout=0.5, cls_dropout=0.3, cls_thrs=0.5):super().__init__(pretrained, den_dropout)self.cls_dropout = cls_dropoutself.cls_thrs = cls_thrsself.cls_head = nn.Sequential(ConvBlock(512, 256, bn=True),nn.Dropout2d(p=self.cls_dropout),ConvBlock(256, 1, kernel_size=1, padding=0, relu=False),nn.Sigmoid())def transform_cls_map_gt(self, c_gt):return upsample(c_gt, scale_factor=4, mode='nearest')def transform_cls_map_pred(self, c):c_new = c.clone().detach()c_new[c<self.cls_thrs] = 0c_new[c>=self.cls_thrs] = 1c_resized = upsample(c_new, scale_factor=4, mode='nearest')return c_resizeddef transform_cls_map(self, c, c_gt=None):if c_gt is not None:return self.transform_cls_map_gt(c_gt)else:return self.transform_cls_map_pred(c)def forward(self, x, c_gt=None):y_cat, x3 = self.forward_fe(x)y_den = self.den_dec(y_cat)c = self.cls_head(x3)c_resized = self.transform_cls_map(c, c_gt)d = self.den_head(y_den)dc = d * c_resizeddc = upsample(dc, scale_factor=4)return dc, cclass DGModel_memcls(DGModel_mem):def __init__(self, pretrained=True, mem_size=1024, mem_dim=256, den_dropout=0.5, cls_dropout=0.3, cls_thrs=0.5):super().__init__(pretrained, mem_size, mem_dim, den_dropout)self.cls_dropout = cls_dropoutself.cls_thrs = cls_thrsself.cls_head = nn.Sequential(ConvBlock(512, 256, bn=True),nn.Dropout2d(p=self.cls_dropout),ConvBlock(256, 1, kernel_size=1, padding=0, relu=False),nn.Sigmoid())def transform_cls_map_gt(self, c_gt):return upsample(c_gt, scale_factor=4, mode='nearest')def transform_cls_map_pred(self, c):c_new = c.clone().detach()c_new[c<self.cls_thrs] = 0c_new[c>=self.cls_thrs] = 1c_resized = upsample(c_new, scale_factor=4, mode='nearest')return c_resizeddef transform_cls_map(self, c, c_gt=None):if c_gt is not None:return self.transform_cls_map_gt(c_gt)else:return self.transform_cls_map_pred(c)def forward(self, x, c_gt=None):y_cat, x3 = self.forward_fe(x)y_den = self.den_dec(y_cat)y_den_new, _ = self.forward_mem(y_den)c = self.cls_head(x3)c_resized = self.transform_cls_map(c, c_gt)d = self.den_head(y_den_new)dc = d * c_resizeddc = upsample(dc, scale_factor=4)return dc, cclass DGModel_final(DGModel_memcls):def __init__(self, pretrained=True, mem_size=1024, mem_dim=256, cls_thrs=0.5, err_thrs=0.5, den_dropout=0.5, cls_dropout=0.3, has_err_loss=False):super().__init__(pretrained, mem_size, mem_dim, den_dropout, cls_dropout, cls_thrs)self.err_thrs = err_thrsself.has_err_loss = has_err_lossself.den_dec = nn.Sequential(ConvBlock(512+256+128, self.mem_dim, kernel_size=1, padding=0, bn=True))def jsd(self, logits1, logits2):p1 = F.softmax(logits1, dim=1)p2 = F.softmax(logits2, dim=1)# pm = (0.5 * (p1 + p2))# jsd = 0.5 / logits1.shape[2] * (F.kl_div(p1.log(), pm, reduction='batchmean') + \# F.kl_div(p2.log(), pm, reduction='batchmean'))# log_p1 = F.log_softmax(logits1, dim=1)# log_p2 = F.log_softmax(logits2, dim=1)# jsd = F.kl_div(log_p2, log_p1, reduction='batchmean', log_target=True) / logits1.shape[2]jsd = F.mse_loss(p1, p2)return jsddef forward_train(self, img1, img2, c_gt=None):y_cat1, x3_1 = self.forward_fe(img1)y_cat2, x3_2 = self.forward_fe(img2)y_den1 = self.den_dec(y_cat1)y_den2 = self.den_dec(y_cat2)y_in1 = F.instance_norm(y_den1, eps=1e-5)y_in2 = F.instance_norm(y_den2, eps=1e-5)e_y = torch.abs(y_in1 - y_in2)e_mask = (e_y < self.err_thrs).clone().detach()# e_y = torch.square(y_in1 - y_in2)# e_mask = ((e_y).mean(dim=1, keepdim=True) < self.err_thrs).clone().detach()# print(e_mask.sum() / e_mask.numel())loss_err = F.l1_loss(y_in1, y_in2) if self.has_err_loss else 0y_den_masked1 = F.dropout2d(y_den1 * e_mask, self.den_dropout)y_den_masked2 = F.dropout2d(y_den2 * e_mask, self.den_dropout)y_den_new1, logits1 = self.forward_mem(y_den_masked1)y_den_new2, logits2 = self.forward_mem(y_den_masked2)loss_con = self.jsd(logits1, logits2)c1 = self.cls_head(x3_1)c2 = self.cls_head(x3_2)c_resized_gt = self.transform_cls_map_gt(c_gt)c_resized1 = self.transform_cls_map_pred(c1)c_resized2 = self.transform_cls_map_pred(c2)c_err = torch.abs(c_resized1 - c_resized2)c_resized = torch.clamp(c_resized_gt + c_err, 0, 1)d1 = self.den_head(y_den_new1)d2 = self.den_head(y_den_new2)dc1 = upsample(d1 * c_resized, scale_factor=4)dc2 = upsample(d2 * c_resized, scale_factor=4)c_err = upsample(c_err, scale_factor=4)return dc1, dc2, c1, c2, c_err, loss_con, loss_err