Python集合
一、Python集合概述
Python集合(set)是一种无序、可变且不包含重复元素的数据结构。集合在Python中通过哈希表实现,这使得它在成员检测和去重操作中具有极高的效率。
集合与列表、元组的主要区别:
无序性:元素没有固定顺序
唯一性:自动去除重复项
可变性:可以动态添加删除元素
元素限制:只能包含可哈希(不可变)类型
二、集合的创建与初始化
1. 基本创建方法
使用花括号创建
colors = {'red', 'green', 'blue'}
使用set()构造函数创建
numbers = set([1, 2, 3, 4, 5])
空集合必须使用set()创建
empty_set = set() # 正确
not_empty_set = {} # 错误,这会创建字典
- 特殊创建方式
从字符串创建字符集合
char_set = set('hello') # {'h', 'e', 'l', 'o'}
使用生成器表达式创建
squares = set(x*x for x in range(10))
从字典键创建集合
dict_keys = {'a':1, 'b':2}
key_set = set(dict_keys) # {'a', 'b'}
三、集合操作详解
1. 基本操作
添加元素
s = {1, 2, 3}
s.add(4) # {1, 2, 3, 4}
s.update([5,6]) # {1, 2, 3, 4, 5, 6}
删除元素
s.remove(3) # {1, 2, 4, 5, 6} 元素不存在会报错
s.discard(10) # 安全删除,元素不存在不会报错
popped = s.pop() # 随机移除并返回一个元素
s.clear() # 清空集合
2. 集合运算
python
A = {1, 2, 3, 4}
B = {3, 4, 5, 6}
基本运算
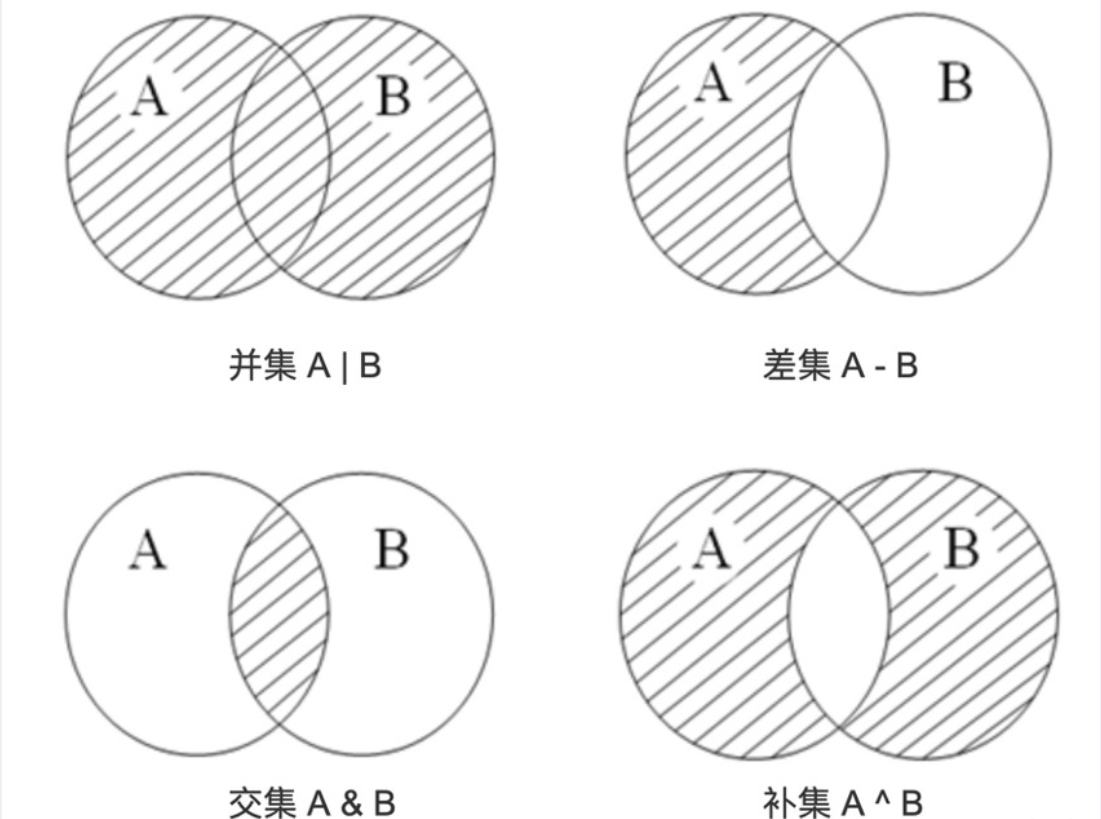
print(A | B) # 并集: {1, 2, 3, 4, 5, 6}
print(A & B) # 交集: {3, 4}
print(A - B) # 差集(A有B没有): {1, 2}
print(B - A) # 差集(B有A没有): {5, 6}
print(A ^ B) # 对称差集(只在A或只在B): {1, 2, 5, 6}
比较运算
print(A <= B) # 子集判断
print(A < B) # 真子集判断
print(A >= B) # 超集判断
print(A > B) # 真超集判断
print(A.isdisjoint(B)) # 是否无交集
四、集合的高级应用
1. 数据去重
列表去重
duplicates = [1, 2, 2, 3, 4, 4, 4]
unique = list(set(duplicates)) # [1, 2, 3, 4]
保持原始顺序的去重
from collections import OrderedDict
unique_ordered = list(OrderedDict.fromkeys(duplicates))
2. 大型数据查找
创建100万个元素的集合和列表
large_set = set(range(1_000_000))
large_list = list(range(1_000_000))
性能对比
%timeit 999_999 in large_set # 约0.0001秒
%timeit 999_999 in large_list # 约0.01秒
3. 集合推导式
基本集合推导式
squares = {x**2 for x in range(10)}
带条件的集合推导式
even_squares = {x**2 for x in range(10) if x%2 == 0}
多数据源推导式
combined = {(x,y) for x in [1,2,3] for y in ['a','b']}
五、冻结集合(frozenset)
冻结集合是不可变版本的集合,具有以下特点:
不可添加或删除元素
可哈希,可用作字典键
可作为其他集合的元素
fs = frozenset([1, 2, 3])
d = {fs: "example"} # 有效
冻结集合运算
fs1 = frozenset([1,2,3])
fs2 = frozenset([3,4,5])
union = fs1 | fs2 # frozenset({1, 2, 3, 4, 5})
六、总结与思考
学习Python集合这一周以来,我最初只是把它当作一种简单的去重工具,但随着深入使用,发现它远比我想象的要强大得多。记得第一次用集合给列表去重时,那种一行代码解决问题的快感,让我立刻喜欢上了这个数据结构。
在实际项目中,集合真正展现了它的价值。上周处理用户数据时,我需要找出两个百万级用户列表的重合部分。如果使用列表嵌套循环,估计程序要跑好几分钟。而改用集合的交集运算后,不到一秒就出了结果。这种效率上的巨大提升,让我深刻理解了选择合适数据结构的重要性。
集合的无序特性曾经让我有些困扰。有次我试图用集合存储需要按顺序处理的数据,结果自然遇到了问题。这个教训让我明白,每种数据结构都有其适用场景,不能强行套用。就像螺丝刀不能当锤子用一样,集合最适合的是那些不关心顺序,但需要快速查找和去重的场合。
最让我惊喜的是集合运算的简洁表达。以前需要写十几行循环代码才能实现的共同好友查找功能,现在用简单的交集运算符"&"就能完成。这种表达上的简洁性,不仅减少了代码量,更让程序逻辑变得一目了然。
不过集合也不是万能的。记得有一次我试图把字典存入集合,结果遇到了类型错误。这才知道集合元素必须是可哈希的,像列表、字典这样的可变类型不行。这类小陷阱提醒我,在享受集合便利的同时,也要清楚它的限制。
现在写代码时,我会习惯性思考:"这里用集合会不会更合适?"这种思维转变,让我的代码效率提升了不少。特别是在处理标签系统、权限校验这类需要频繁检查元素是否存在的场景,集合的表现总是令人满意。
总的来说,Python集合就像是一个被很多人低估的工具。它看似简单,但用好了能解决很多实际问题。学习数据结构的意义,不仅在于记住它们的API,更要理解每种结构背后的设计思想,知道在什么场景下该用什么工具。集合的教学让我明白,编程中的优雅往往来自于对基础知识的深刻理解和灵活运用。