LLM笔记(九)KV缓存(2)
文章目录
- 1. 背景与动机
- 2. 不使用 KV Cache 的情形
- 2.1 矩阵形式展开
- 2.2 计算复杂度
- 3. 使用 KV Cache 的优化
- 3.1 核心思想
- 3.2 矩阵形式展开
- 3.3 计算复杂度对比
- 4. 总结
- 5. GPT-2 中 KV 缓存的实现分析
- 5.1 缓存的数据结构与类型
- 5.2 在注意力机制 (`GPT2Attention`) 中使用缓存
- 5.3 缓存的更新机制 (`Cache.update`)
- 5.4 在模型整体 (`GPT2Model`) 的 `forward` 方法中处理
- 5.5 因果掩码 (Causal Mask) 与 KV 缓存的配合
- 5.6 支持多种高效的注意力实现
- 5.7 KV 缓存的完整工作流程 (自回归生成)
- 5.7.1 初始步骤 (t=0):
- 5.7.2 后续步骤 (t > 0):
- KV 缓存的显著优势
- 看图学kv 很形象清楚
- gpt2源码
- 分析transformer模型的参数量、计算量、中间激活、KV cache量化分析了缓存
- kv解读
1. 背景与动机
在自回归生成(autoregressive generation)任务中,Transformer 解码器需要在每一步中根据前面已生成的所有 token 重新计算注意力(Attention),这会产生大量重复计算。引入 KV Cache(Key–Value Cache)后,能够将已计算的键值对缓存下来,仅对新增的 Query 进行点乘与加权,从而大幅降低时间与算力开销。
2. 不使用 KV Cache 的情形
2.1 矩阵形式展开
-
第 1 步(生成第一个 token)
Q 1 , K 1 , V 1 ∈ R 1 × d Q_1, K_1, V_1 \in \mathbb{R}^{1\times d} Q1,K1,V1∈R1×d
A t t e n t i o n 1 = s o f t m a x ( Q 1 K 1 ⊤ d ) , V 1 Attention_1 = \mathrm{softmax}\Bigl(\frac{Q_1 K_1^\top}{\sqrt d}\Bigr),V_1 Attention1=softmax(dQ1K1⊤),V1
-
第 2 步(生成第二个 token)
构造全序列的矩阵:
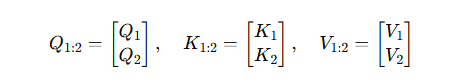
需重算完整注意力矩阵:
A t t e n t i o n 1 : 2 = s o f t m a x ( Q 1 : 2 K 1 : 2 ⊤ d ) , V 1 : 2 Attention_{1:2} = \mathrm{softmax}\Bigl(\frac{Q_{1:2}K_{1:2}^\top}{\sqrt d}\Bigr),V_{1:2} Attention1:2=softmax(dQ1:2K1:2⊤),V1:2
计算出一个 2 × 2 2\times 2 2×2 矩阵,但我们只取最后一行作为输出。
-
第 n 步
Q 1 : n , K 1 : n , V 1 : n ∈ R n × d , A t t e n t i o n 1 : n = s o f t m a x ( Q 1 : n K 1 : n ⊤ d ) , V 1 : n Q_{1:n},K_{1:n},V_{1:n}\in\mathbb{R}^{n\times d},\quad Attention_{1:n} = \mathrm{softmax}\Bigl(\tfrac{Q_{1:n}K_{1:n}^\top}{\sqrt d}\Bigr),V_{1:n} Q1:n,K1:n,V1:n∈Rn×d,Attention1:n=softmax(dQ1:nK1:n⊤),V1:n
每步均重新构建并计算 n × n n\times n n×n 注意力矩阵。
2.2 计算复杂度
-
注意力矩阵构建: O ( n 2 ⋅ d ) O(n^2\cdot d) O(n2⋅d)。
-
整体推理阶段:若生成总长度为 N N N,则总复杂度近似为
∑ n = 1 N O ( n 2 d ) ; = ; O ( N 3 d ) \sum_{n=1}^N O(n^2 d);=;O(N^3 d) ∑n=1NO(n2d);=;O(N3d),
由于每步都做重复计算,效率极低。
3. 使用 KV Cache 的优化
3.1 核心思想
-
缓存已计算的 K, V:对于前序列位置的键值对,只需计算一次并存储。
-
仅对新增 Query 进行点乘:第 n n n 步仅需计算 Q n Q_n Qn 与所有缓存 K 的点乘,得到长度为 n n n 的注意力权重,再加权叠加对应的 V。
3.2 矩阵形式展开
-
第 1 步:如前,无缓存,计算
A t t e n t i o n 1 = s o f t m a x ( Q 1 K 1 ⊤ / d ) , V 1 Attention_1 = \mathrm{softmax}(Q_1K_1^\top/\sqrt d),V_1 Attention1=softmax(Q1K1⊤/d),V1. -
第 2 步:
-
新增 Q 2 ∈ R 1 × d Q_2\in\mathbb{R}^{1\times d} Q2∈R1×d;
-
缓存矩阵已扩展为
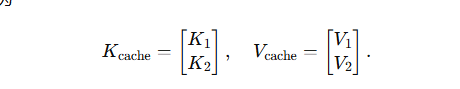
-
只做一次 1 × 2 1\times 2 1×2 点乘:
A t t e n t i o n 2 = s o f t m a x ( Q 2 K c a c h e ⊤ d ) , V c a c h e Attention_2 = \mathrm{softmax}\Bigl(\tfrac{Q_2 K_{\mathrm{cache}}^\top}{\sqrt d}\Bigr),V_{\mathrm{cache}} Attention2=softmax(dQ2Kcache⊤),Vcache,
输出即为所需的 1 × d 1\times d 1×d 向量。
-
-
第 n 步:
K c a c h e ∈ R n × d , V c a c h e ∈ R n × d , A t t e n t i o n n = s o f t m a x ( Q n K c a c h e ⊤ d ) , V c a c h e K_{\mathrm{cache}}\in\mathbb{R}^{n\times d},\quad V_{\mathrm{cache}}\in\mathbb{R}^{n\times d},\quad Attention_n = \mathrm{softmax}\Bigl(\tfrac{Q_n K_{\mathrm{cache}}^\top}{\sqrt d}\Bigr),V_{\mathrm{cache}} Kcache∈Rn×d,Vcache∈Rn×d,Attentionn=softmax(dQnKcache⊤),Vcache.
3.3 计算复杂度对比
| 模式 | 每步复杂度 | 总体复杂度(生成长度 N N N) |
|---|---|---|
| 无 Cache | O ( n 2 d ) O(n^2 d) O(n2d) | O ( N 3 d ) O(N^3 d) O(N3d) |
| 有 KV Cache | O ( n d ) O(n d) O(nd) | ∑ n = 1 N O ( n d ) = O ( N 2 d ) \displaystyle\sum_{n=1}^N O(n d)=O(N^2 d) n=1∑NO(nd)=O(N2d) |
- 加速比:从二次方级别 O ( n 2 ) O(n^2) O(n2) 降到线性级别 O ( n ) O(n) O(n),对长序列提升显著。
4. 总结
-
多头注意力(Multi-Head)
每个 head 独立缓存自己的 K, V 矩阵,计算时分别点乘再拼接。总体计算与存储线性可扩展。 -
缓存管理
-
内存占用:缓存矩阵大小随生成长度增长,应考虑清理过旧不再需要的序列(如 sliding window)。
-
Batch 推理:对多条序列并行生成时,可为每条序列维护独立缓存,或统一按最大长度对齐。
-
-
硬件优化
-
内存带宽:KV Cache 减少重复内存载入,对带宽友好;
-
并行度:线性点乘更易与矩阵乘加(GEMM)指令级并行融合。
-
-
实践中常见问题
- Cache 不命中:若使用 prefix-tuning 等技术动态修改 key/value,需谨慎处理缓存一致性。
- 数值稳定性:长序列高维 softmax 易出现梯度消失/爆炸,可结合温度系数或分段归一化。
5. GPT-2 中 KV 缓存的实现分析
GPT-2(以及许多其他基于 Transformer 的自回归模型)在生成文本时,为了提高效率,会使用一种称为 KV 缓存 (Key-Value Cache) 的机制。其核心思想是:在生成第 t 个 token 时,计算注意力所需的键 (Key) 和值 (Value) 向量可以部分来自于已经生成的 t-1 个 token。通过缓存这些历史的 K 和 V 向量,可以避免在每一步生成时都对整个已生成序列重新进行昂贵的 K 和 V 计算。
5.1 缓存的数据结构与类型
Hugging Face Transformers 库为 GPT-2 提供了灵活的缓存管理机制,主要通过 Cache 基类及其子类实现。
Cache(基类): 定义了缓存对象的基本接口,例如update(更新缓存) 和get_seq_length(获取当前缓存的序列长度) 等方法。DynamicCache:- 这是自回归生成时最常用的缓存类型。
- 它允许缓存的序列长度动态增长。当生成新的 token 时,新计算出的 K 和 V 向量会被追加到已有的缓存后面。
- 不需要预先分配固定大小的内存,更加灵活,但可能在内存管理上有一些开销。
StaticCache:- 在创建时就需要预先分配固定大小的内存空间来存储 K 和 V 向量。
- 适用于已知最大生成长度或需要更可控内存占用的场景。
- 如果生成的序列长度超过了预分配的大小,可能会出错或需要特殊处理。
EncoderDecoderCache:- 主要用于 Encoder-Decoder 架构的模型 (如 T5, BART)。
- 它内部会分别管理编码器-解码器注意力(交叉注意力)的 KV 缓存和解码器自注意力的 KV 缓存。
- GPT-2 是一个仅解码器 (Decoder-only) 模型,所以主要关注自注意力的缓存。
# 相关类的导入,展示了缓存工具的多样性
from transformers.cache_utils import Cache, DynamicCache, EncoderDecoderCache, StaticCache
5.2 在注意力机制 (GPT2Attention) 中使用缓存
GPT2Attention 类的 forward 方法是 KV 缓存机制的核心应用点。
class GPT2Attention(nn.Module): ... def forward( self, hidden_states: Optional[Tuple[torch.FloatTensor]], layer_past: Optional[Tuple[torch.Tensor]] = None, # 旧版本的缓存参数名 past_key_value: Optional[Cache] = None, # 新版本的缓存对象 attention_mask: Optional[torch.FloatTensor] = None, head_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = False, output_attentions: Optional[bool] = False, cache_position: Optional[torch.LongTensor] = None, # 指示新token在缓存中的位置 ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: # 1. 计算当前输入 hidden_states 的 Q, K, V # self.c_attn 是一个线性层,通常一次性计算出 Q, K, V 然后分割 query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2) # 2. 将 Q, K, V 重塑为多头形式 (batch_size, num_heads, seq_len, head_dim) query = self._split_heads(query, self.num_heads, self.head_dim) key = self._split_heads(key, self.num_heads, self.head_dim) value = self._split_heads(value, self.num_heads, self.head_dim) # 3. KV 缓存处理 if past_key_value is not None: # 如果是 EncoderDecoderCache,根据是否交叉注意力选择正确的缓存 if isinstance(past_key_value, EncoderDecoderCache): # ... (GPT-2 不直接使用此逻辑,但展示了其通用性) pass # 使用 cache_position 来更新缓存中的特定位置 cache_kwargs = {"cache_position": cache_position} # 调用缓存对象的 update 方法 # key 和 value 是当前新计算的 K, V # self.layer_idx 标识当前是哪一层的缓存 key, value = past_key_value.update(key, value, self.layer_idx, cache_kwargs) # 此时的 key 和 value 包含了历史信息和当前新计算的信息 # 4. 计算注意力权重 (Q @ K^T) # ... attn_weights = torch.matmul(query, key.transpose(-1, -2)) # ... 应用注意力掩码 (causal mask, padding mask) ... # 5. 计算注意力输出 (attn_weights @ V) attn_output = torch.matmul(attn_weights, value) # ... 合并多头,返回结果 ... if use_cache: # 如果使用缓存,则 present_key_value 就是更新后的 past_key_value present_key_value = past_key_value else: present_key_value = None return attn_output, present_key_value # 返回注意力的输出和更新后的缓存
关键点解释:
past_key_value(或layer_past): 这是从上一个时间步或上一个调用传递过来的缓存对象。它包含了到目前为止所有先前 token 的 K 和 V 向量。cache_position: 这是一个非常重要的参数,尤其是在使用了诸如 Flash Attention 2 等更高级的注意力实现时。它告诉缓存update方法以及注意力计算函数,新的 K 和 V 向量应该被放置在缓存张量的哪个位置。这对于正确地处理填充(padding)和动态序列长度至关重要。例如,如果当前输入的是第t个 token(从0开始计数),cache_position可能就是t。self.layer_idx: Transformer 模型通常由多个相同的注意力层堆叠而成。每一层都有自己独立的 KV 缓存。layer_idx用于标识当前正在处理的是哪一层的缓存,确保数据被正确地存取。use_cache: 控制是否使用和返回缓存。在训练时通常为False(除非进行特定类型的训练,如 teacher forcing 的逐token训练),在推理(生成)时为True。
5.3 缓存的更新机制 (Cache.update)
Cache 对象的 update 方法是实现缓存的核心。虽然具体的实现会因 DynamicCache 或 StaticCache 而异,但其基本逻辑是:
class DynamicCache(Cache): def __init__(self): self.key_cache: List[torch.Tensor] = [] # 每层一个 tensor self.value_cache: List[torch.Tensor] = [] # 每层一个 tensor self.seen_tokens = 0 # 已缓存的token数量 def update( self, key_states: torch.Tensor, # 新计算的 key value_states: torch.Tensor, # 新计算的 value layer_idx: int, # 当前层索引 cache_kwargs: Optional[Dict[str, Any]] = None, ) -> Tuple[torch.Tensor, torch.Tensor]: # 获取 cache_position cache_position = cache_kwargs.get("cache_position") # 如果是第一次更新这一层 (或缓存为空) if layer_idx >= len(self.key_cache): # 初始化该层的缓存张量 # ... 根据 key_states 和 value_states 的形状以及预估的最大长度(或动态调整) self.key_cache.append(torch.zeros_like(key_states_preallocated)) self.value_cache.append(torch.zeros_like(value_states_preallocated)) # 将新的 key_states 和 value_states 写入到缓存的指定位置 # 对于 DynamicCache,通常是直接拼接或在预分配空间中按位置写入 if cache_position is not None: # 使用 cache_position 精确地更新缓存的特定部分 # 例如: self.key_cache[layer_idx][:, :, cache_position, :] = key_states # self.value_cache[layer_idx][:, :, cache_position, :] = value_states # 这里的维度可能需要根据实际实现调整 # 重要的是理解 cache_position 的作用 # 例如,如果 key_states 的形状是 (batch, num_heads, new_seq_len, head_dim) # cache_position 的形状可能是 (batch, new_seq_len) 或广播的 (new_seq_len) # 需要将 key_states 放置到 self.key_cache[layer_idx] 的正确"槽位" # 对于自回归,通常 new_seq_len = 1 self.key_cache[layer_idx].index_copy_(dim=2, index=cache_position, source=key_states) self.value_cache[layer_idx].index_copy_(dim=2, index=cache_position, source=value_states) # 更新已见过的token数量 self.seen_tokens = cache_position[-1] + 1 # 取最后一个新token的位置加1 else: # 旧的、不使用 cache_position 的逻辑(通常是简单拼接) self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=2) self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=2) self.seen_tokens += key_states.shape[2] # 返回包含所有历史信息(包括刚更新的)的 K 和 V 状态 return self.key_cache[layer_idx], self.value_cache[layer_idx]
update 方法的关键职责:
- 接收当前新计算的
key_states和value_states。 - 根据
layer_idx找到对应层的缓存。 - (可选,但推荐)使用
cache_position将新的 K, V 向量精确地放置到缓存张量的正确位置。这对于处理批处理中不同样本有不同历史长度的情况(例如,在束搜索beam search后或 speculative decoding 后),或者在有填充 token 时非常重要。 - 返回完整的、包含所有历史信息和当前新信息的 K, V 向量,供后续的注意力计算使用。
- 更新内部状态,如已缓存的 token 数量 (
seen_tokens)。
5.4 在模型整体 (GPT2Model) 的 forward 方法中处理
GPT2Model 的 forward 方法负责协调整个模型的流程,包括缓存的初始化、传递和 cache_position 的计算。
class GPT2Model(GPT2PreTrainedModel): def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, # 旧版缓存元组 attention_mask: Optional[torch.FloatTensor] = None, # ... use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, cache_position: Optional[torch.LongTensor] = None, ) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]: # ... (处理输入ID和嵌入) ... inputs_embeds = self.wte(input_ids) # 词嵌入 position_embeds = self.wpe(position_ids) # 位置嵌入 hidden_states = inputs_embeds + position_embeds # 1. 缓存初始化和类型转换 if use_cache: if past_key_values is None: # 如果是第一次调用或没有提供缓存 # 根据配置决定使用哪种缓存,通常是 DynamicCache # 例如:self.config.cache_implementation == "dynamic" past_key_values = DynamicCache() elif not isinstance(past_key_values, Cache): # 为了兼容旧的元组形式的缓存,将其转换为新的 Cache 对象 past_key_values = DynamicCache.from_legacy_cache(past_key_values) # else: past_key_values 保持为 None # 2. 计算 cache_position if cache_position is None: # 如果外部没有提供 cache_position # 获取当前缓存中已有的 token 数量 past_seen_tokens = past_key_values.get_seq_length(self.config.num_hidden_layers) if past_key_values is not None else 0 # 当前输入序列的长度 current_seq_length = inputs_embeds.shape[1] # cache_position 从 past_seen_tokens 开始,长度为 current_seq_length cache_position = torch.arange( past_seen_tokens, past_seen_tokens + current_seq_length, device=inputs_embeds.device ) # else: 使用外部传入的 cache_position # ... (准备注意力掩码,考虑因果关系和缓存长度) ... # 3. 逐层传递和更新缓存 all_hidden_states = () if output_hidden_states else None all_self_attentions = () if output_attentions else None # next_decoder_cache 用于收集下一轮的缓存 (如果 use_cache 为 True) # 在新的 Cache 对象设计中,past_key_values 本身会被原地更新或返回更新后的版本 # 因此,这个 next_decoder_cache 可能不再是必需的,或者其角色由 past_key_values 自身承担 for i, block in enumerate(self.h): # self.h 是 GPT2Block 的列表 # ... # 将当前层的缓存 (如果存在) 和 cache_position 传递给 GPT2Block # GPT2Block 内部会再将其传递给 GPT2Attention layer_outputs = block( hidden_states, layer_past=None, # 旧参数,通常为None attention_mask=extended_attention_mask, head_mask=head_mask[i], encoder_hidden_states=None, encoder_attention_mask=None, use_cache=use_cache, output_attentions=output_attentions, past_key_value=past_key_values, # 传递整个缓存对象 cache_position=cache_position, ) hidden_states = layer_outputs[0] # 更新 hidden_states # 如果 use_cache,block 会返回更新后的缓存,这里 past_key_values 已被更新 # (在 Cache 对象实现中,update 方法通常返回更新后的完整缓存状态, # 或者直接在对象内部修改,取决于具体实现) # ... (处理输出) ... return BaseModelOutputWithPast( last_hidden_state=hidden_states, past_key_values=past_key_values if use_cache else None, # 返回更新后的缓存 hidden_states=all_hidden_states, attentions=all_self_attentions, )
5.5 因果掩码 (Causal Mask) 与 KV 缓存的配合
在自回归生成中,模型只能注意到当前 token 及其之前的所有 token,不能注意到未来的 token。这是通过因果掩码实现的。当使用 KV 缓存时,因果掩码的构建需要考虑到缓存中已有的 token 数量。
class GPT2Attention(_GPT2Attention): def _update_causal_mask( self, attention_mask: torch.Tensor, # 原始的 attention_mask (可能包含 padding) input_tensor: torch.Tensor, # 当前输入的 hidden_states cache_position: torch.Tensor, past_key_values: Cache, # 当前的缓存对象 output_attentions: bool, ): # 获取当前输入的序列长度 (通常为1,在自回归生成的每一步) input_seq_length = input_tensor.shape[1] # 获取缓存中已有的序列长度 past_seen_tokens = past_key_values.get_seq_length(self.layer_idx) # 总的上下文长度 = 缓存长度 + 当前输入长度 total_context_length = past_seen_tokens + input_seq_length # _prepare_4d_causal_attention_mask_with_cache_position 会生成一个正确的掩码 # 这个掩码会确保: # 1. 查询 Q (来自当前输入) 只能注意到键 K (来自缓存+当前输入) 中对应位置及之前的部分。 # 2. 处理好 padding (如果 attention_mask 中有指示)。 # 形状通常是 (batch_size, 1, query_length, key_length) # 其中 query_length 是当前输入的长度 (如1) # key_length 是总的上下文长度 (past_seen_tokens + input_seq_length) causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position( attention_mask, input_shape=(input_tensor.shape[0], input_seq_length), # 当前输入的形状 target_length=total_context_length, # K, V 的总长度 dtype=input_tensor.dtype, cache_position=cache_position, # 关键!用于确定当前 Q 在 K,V 序列中的相对位置 ) return causal_mask
_prepare_4d_causal_attention_mask_with_cache_position 这个辅助函数会创建一个上三角矩阵(或类似结构),其中未来的位置会被掩盖掉(例如,设置为一个非常小的负数,以便 softmax 后变为0)。cache_position 在这里的作用是,确保即使当前查询 Q 的序列长度很短(例如为1),它在与历史的 K, V 进行比较时,依然能正确地只关注到历史和当前 K, V 中该 Q 之前的部分。
5.6 支持多种高效的注意力实现
Hugging Face Transformers 库允许 GPT-2(以及其他模型)利用更高效的注意力后端实现,例如:
eager: PyTorch 的标准、原生注意力实现。sdpa(Scaled Dot Product Attention): PyTorch 2.0 引入的高度优化的注意力函数torch.nn.functional.scaled_dot_product_attention。它通常比 eager模式更快,内存效率也更高,并且可以自动选择最优的底层实现(如 FlashAttention 或 memory-efficient attention)。flash_attention_2: 直接集成 FlashAttention v2 库。这是一种专门为现代 GPU 设计的、IO 感知的精确注意力算法,速度非常快,内存占用小。
KV 缓存机制的设计需要与这些高效实现兼容。例如,torch.nn.functional.scaled_dot_product_attention 和 FlashAttention 都支持直接传入包含历史和当前信息的完整 K, V 张量。cache_position 在这里尤为重要,因为它可以帮助这些高效后端理解哪些部分是新的,哪些是旧的,以及如何正确应用因果掩码。
# 在 GPT2Attention 的 forward 方法中
self.config._attn_implementation 存储了选择的注意力实现方式 ("eager", "sdpa", "flash_attention_2") ... (计算 query, key, value) ...
... (更新 key, value 使用 past_key_value 和 cache_position) ...
此时 key 和 value 是拼接/更新后的完整 K, V if self.config._attn_implementation == "sdpa": # 使用 PyTorch SDPA # is_causal=True 会自动应用因果掩码 # attn_mask 可能需要根据 SDPA 的要求进行调整 attn_output = torch.nn.functional.scaled_dot_product_attention( query, key, value, attn_mask=adjusted_attn_mask, dropout_p=self.attn_dropout.p, is_causal=True )
elif self.config._attn_implementation == "flash_attention_2": # from flash_attn import flash_attn_func # 可能需要对 query, key, value 的形状或数据类型进行调整以适应 flash_attn_func # causal=True 会应用因果掩码 attn_output = flash_attn_func( query.transpose(1, 2), # FlashAttention 可能期望 (batch, seq_len, num_heads, head_dim) torch.stack((key.transpose(1,2), value.transpose(1,2)), dim=0), # K, V 打包 dropout_p=self.attn_dropout.p, causal=True, )
else: # "eager" # ... (标准的 PyTorch matmul 实现) ...
5.7 KV 缓存的完整工作流程 (自回归生成)
5.7.1 初始步骤 (t=0):
- 用户提供初始的
input_ids(例如,一个[BOS]token 或者一段提示文本)。 past_key_values为None。- 模型
forward方法被调用。 use_cache通常为True。- 初始化一个空的
DynamicCache对象作为past_key_values。 - 计算
cache_position,此时它通常是从 0 开始的序列 (e.g.,torch.arange(0, initial_input_len)). - 对于每一注意力层:
- 计算当前
input_ids对应的 Q, K, V。 - 由于
past_key_values刚被初始化(内部缓存为空),update方法会将这些新计算的 K, V 存入缓存的第一批位置。 - 使用这些 K, V (此时它们只包含当前输入的信息) 和 Q 进行注意力计算。
- 计算当前
- 模型输出 logits (用于预测下一个 token) 和更新后的
past_key_values(现在包含了第一个输入的 K,V)。
5.7.2 后续步骤 (t > 0):
- 从上一步的 logits 中采样得到新的
input_ids(通常是一个新的 token)。 - 将上一步返回的
past_key_values(包含了 t-1 步及之前所有 token 的 K,V) 作为输入传递给模型。 - 模型
forward方法再次被调用。 use_cache为True。- 计算
cache_position。此时,past_key_values.get_seq_length()会返回已缓存的 token 数量 (例如t)。新的cache_position会是torch.tensor([t]),表示这个新 token 是序列中的第t+1个元素 (如果从1开始计数的话,或者第t个位置如果从0开始计数)。 - 对于每一注意力层:
- 只对新输入的单个 token 计算其 Q, K, V (这些是"小"张量)。
- 调用
past_key_values.update(new_key, new_value, layer_idx, cache_kwargs={"cache_position": cache_position})。update方法会将这个新 token 的 K, V 追加到对应层缓存中已有的 K, V 之后,并返回完整的 K (包含所有t+1个 token) 和完整的 V。
- 使用新 token 的 Q 和完整的 (历史+当前) K, V 计算注意力。因果掩码会确保 Q 只注意到 K,V 中它自己及之前的部分。
- 模型输出 logits 和再次更新后的
past_key_values。
这个过程一直重复,直到生成了 [EOS] token 或达到最大长度。
KV 缓存的显著优势
- 避免冗余计算: 这是最核心的优势。在生成第
t个 token 时,前t-1个 token 的 K 和 V 向量已经计算并存储在缓存中,无需重新计算。注意力机制只需要为新的当前 token 计算 K 和 V,然后将它们与缓存中的历史 K,V 结合起来。 - 显著提高生成速度: 尤其对于长序列生成,每次迭代的计算量从 O(N²)(N为当前总长度)降低到接近 O(N)(主要是新 Q 与历史 K,V 的交互),因为主要计算瓶颈(K,V的生成)只针对新token进行。
- 支持高效的批处理生成: 虽然每个样本在批次中可能有不同的已生成长度(特别是在使用可变长度输入或某些采样策略时),通过
cache_position和可能的填充/掩码机制,KV 缓存可以有效地处理这种情况。 - 与先进注意力实现的兼容性: 如前所述,KV 缓存的设计与 SDPA、FlashAttention 等高效后端良好集成,使得模型可以同时享受到算法优化和底层硬件加速的好处。