数据库连接池技术与 Druid 连接工具类实现
目录
1. 数据库连接池简介
1.1. 什么是数据库连接池
1.2. 不使用数据库连接池可能存在的问题
1.3. JDBC数据库连接池的必要性
1.4. 数据库连接池的优点
1.5. 常用的数据库连接池
2. Druid连接池
2.1. Druid简介
2.2. Druid使用步骤
2.2.1. 第一步的步骤详解:
2.2.2. 第二步的步骤详解:
2.2.3. druid配置信息
2.3. 通过数据库连接池获取连接
2.3.1. 获取读取druid配置的字节输入流
2.3.2. 创建Properties对象
2.3.3. 加载配置文件
2.3.4. 获取连接池对象
2.3.5. 获取连接
3. 基于Druid连接池获取数据库连接工具类
4. 总结
本文来讲解数据库地址池和Druid的配置使用以及使用JDBC来实现地址池
个人主页:艺杯羹
系列专栏:JDBC
1. 数据库连接池简介
1.1. 什么是数据库连接池
数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态地对池中的连接进行申请,使用,释放
它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
当数据库连接空闲时间太长,超过了规定的最长空闲时长,就把这个连接释放掉
这样做是为了防止连接一直占着却没人用 ,要是不释放,就会出现连接浪费,也就是数据库连接遗漏的问题。通过这种方式,能大大提升对数据库操作的速度和效率
1.2. 不使用数据库连接池可能存在的问题
- 连接建立耗时:用 DriverManager 获取连接,会加载 Connection、验证信息等过程耗时
- 资源利用低效:按需建连、用完断开,连接无法复用,高并发时大量占用系统资源,可致服务器崩溃
- 易引发内存泄漏:连接使用后若未断开,程序异常时会造成数据库内存泄漏,甚至需重启数据库
1.3. JDBC数据库连接池的必要性
- 数据库连接池的基本思想:为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个
- 数据库连接池初始化按最小连接数创建连接并维持,最大连接数限制连接总量,超量请求排队等待
简单来说就是
数据库连接池就像个连接 “仓库”。程序启动时,在池里备好一定数量的连接。要用连接的时候从池里拿,用完后再放回去。它能够做连接的分配、管理和释放的工作,还通过设定最小、最大连接数来保障连接数量合理
1.4. 数据库连接池的优点
- 资源重用(连接复用,减少创建开销)
-
更快的系统反应速度(现成的连接,响应耗时短)
-
新的资源分配手段(按需要的多少分配,控连接数量)
-
统一的连接管理(集中管控,规范连接操作)
1.5. 常用的数据库连接池
这里介绍三款数据库连接池
- c3p0:是一个开源组织提供的数据库连接池,速度相对较慢,稳定性还可以
- DBCP:是Apache提供的数据库连接池。速度相对c3p0较快,但自身存在bug
- Druid:是阿里提供的数据库连接池,据说是集DBCP、c3p0优点于一身的数据库连接池,目前经常使用
所以接下来使用Druid连接池来实现功能
2. Druid连接池
2.1. Druid简介
Druid是阿里提供的数据库连接池,它结合了C3P0、DBCP等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况
2.2. Druid使用步骤
- 导入druid-1.2.8.jar包到lib目录下,并引入到项目中
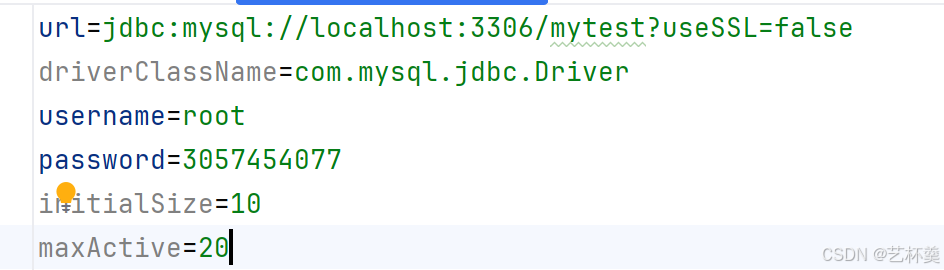
- 在src下创建一个druid.properties类型的文件,并写入
url=jdbc:mysql://localhost:3306/mytest?useSSL=false driverClassName=com.mysql.jdbc.Driver username=root password=root initialSize=10 maxActive=20
这个url要配置自己的数据库名称
如果不知道怎么配置,我之前写过一篇文章,里面讲过
传送门:数据库连接 (* ̄︶ ̄)
2.2.1. 第一步的步骤详解:
本文最前面有druid-1.2.8.jar的压缩包可以免费下载😊,下载后解压即可
再复制这个压缩到,回到idea,单击lib目录 ---> Ctrl + v 复制
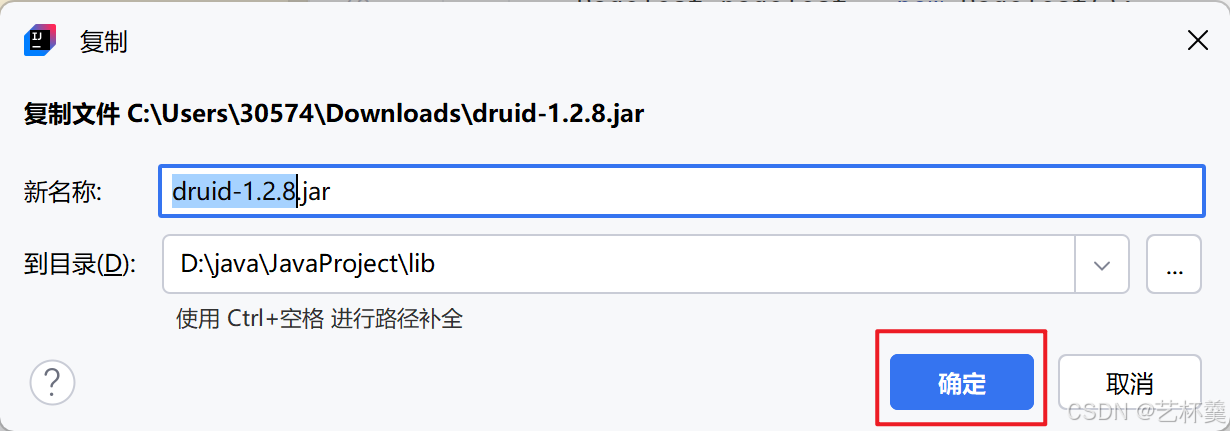
确定即可
2.2.2. 第二步的步骤详解:
新建 ---> 文件 ---> 输入:druid.properties ---> 里面再写入要写入的数据即可

2.2.3. druid配置信息
druid配置信息的参数,也就是刚刚要在druid.properties中写的配置项
| 配置项 | 说明 |
|---|---|
| name | 用于区分多个数据源,未配置则自动生成特定格式名字 |
| url | 连接数据库的地址 |
| username | 连接数据库的用户名 |
| password | 连接数据库的密码 |
| driverClassName | 可自行配置,也可由 druid 根据 url 自动识别驱动类型,建议配置 |
| initialSize | 初始化时创建的物理连接数量 |
| maxActive | 连接池允许的最大连接数量 |
| minIdle | 连接池保持的最小连接数量 |
| maxWait | 获取连接时的最大等待时间(毫秒),配置后默认启用公平锁,可配非公平锁 |
| poolPreparedStatements | 是否缓存 preparedStatement,对部分数据库性能提升大,mysql 下建议关闭 |
| maxOpenPreparedStatements | 启用 PSCache 需配置大于 0,此时 poolPreparedStatements 自动为 true,Druid 中可配较大值 |
| validationQuery | 检测连接有效性的 sql 查询语句,为 null 时相关检测失效 |
| testOnBorrow | 申请连接时检测连接有效性,会降低性能 |
| testOnReturn | 归还连接时检测连接有效性,会降低性能 |
| testWhileIdle | 建议配置为 true,不影响性能且保证安全性,空闲超一定时间检测 |
| timeBetweenEvictionRunsMillis | 检测连接的间隔时间,也是 testWhileIdle 判断依据 |
| numTestsPerEvictionRun | 不再使用 |
| minEvictableIdleTimeMillis | 无明确说明 |
| connectionInitSqls | 物理连接初始化时执行的 sql |
| exceptionSorter | 数据库抛不可恢复异常时,据此抛弃连接 |
| filters | 通过别名配置扩展插件,如监控、日志、防 sql 注入插件 |
| proxyFilters | 与 filters 为组合关系 |
标红是常用的配置项
2.3. 通过数据库连接池获取连接
2.3.1. 获取读取druid配置的字节输入流
InputStream is = DruidTest.class.getClassLoader().getResourceAsStream("druid.properties");2.3.2. 创建Properties对象
Properties pos = new Properties();2.3.3. 加载配置文件
pos.load(is);2.3.4. 获取连接池对象
DataSource ds = DruidDataSourceFactory.createDataSource(pos);2.3.5. 获取连接
Connection connection = ds.getConnection();数据库连接池获取连接完整代码
public class DruidTest {public static void main(String[] args) throws Exception {// 获取读取druid配置的字节输入流InputStream is = DruidTest.class.getClassLoader().getResourceAsStream("druid.properties");// 创建Properties对象Properties pos = new Properties();// 加载配置文件pos.load(is);// 获取连接池对象DataSource ds = DruidDataSourceFactory.createDataSource(pos);// 获取连接Connection connection = ds.getConnection();// 输出测试,是否获取到了connectionSystem.out.println(connection);}
}3. 基于Druid连接池获取数据库连接工具类
在刚开始讲过JDBC的连接工具类
那么连接池也可以抽取一个工具来使用,这样对于后序的操作更方便实现
因为之前讲过JDBC的连接工具类,连接池的也差不多,就直接给出实现代码了
public class JdbcDruidUtil {//数据库连接池对象private static DataSource dataSource;static{try {// 获取读取配置文件的字节输入流对象InputStream is = JdbcDruidUtil.class.getClassLoader().getResourceAsStream("druid.properties");// 创建Properties对象Properties pop = new Properties();// 加载配置文件pop.load(is);// 创建连接池对象dataSource = DruidDataSourceFactory.createDataSource(pop);}catch(Exception e){e.printStackTrace();}}// 获取数据库连接对象public static Connection getConnection(){Connection connection = null;try {connection = dataSource.getConnection();} catch (SQLException throwables) {throwables.printStackTrace();}return connection;}// 关闭连接对象public static void closeConnection(Connection connection){try {connection.close();} catch (SQLException throwables) {throwables.printStackTrace();}}// 提交事务public static void commit(Connection connection){try {connection.commit();} catch (SQLException throwables) {throwables.printStackTrace();}}// 事务回滚(撤销)public static void rollback(Connection connection){try {connection.rollback();} catch (SQLException throwables) {throwables.printStackTrace();}}// 关闭Statement对象public static void closeStatement(Statement statement){try {statement.close();} catch (SQLException throwables) {throwables.printStackTrace();}}// 关闭ResultSetpublic static void closeResultSet(ResultSet resultSet) {try {resultSet.close();} catch (SQLException throwables) {throwables.printStackTrace();}}// DML操作时关闭资源public static void closeResource(Statement statement,Connection connection){//先关闭Statement对象closeStatement(statement);//在关闭Connection对象closeConnection(connection);}// 查询时关闭资源public static void closeResource(ResultSet resultSet,Statement statement,Connection connection){// 先关闭ResultSetcloseResultSet(resultSet);// 在闭Statement对象closeStatement(statement);// 最后关闭Connection对象closeConnection(connection);}
}4. 总结
到现在为止,数据库地址池就讲解完毕了,接下里用一张思维导图来总结一下
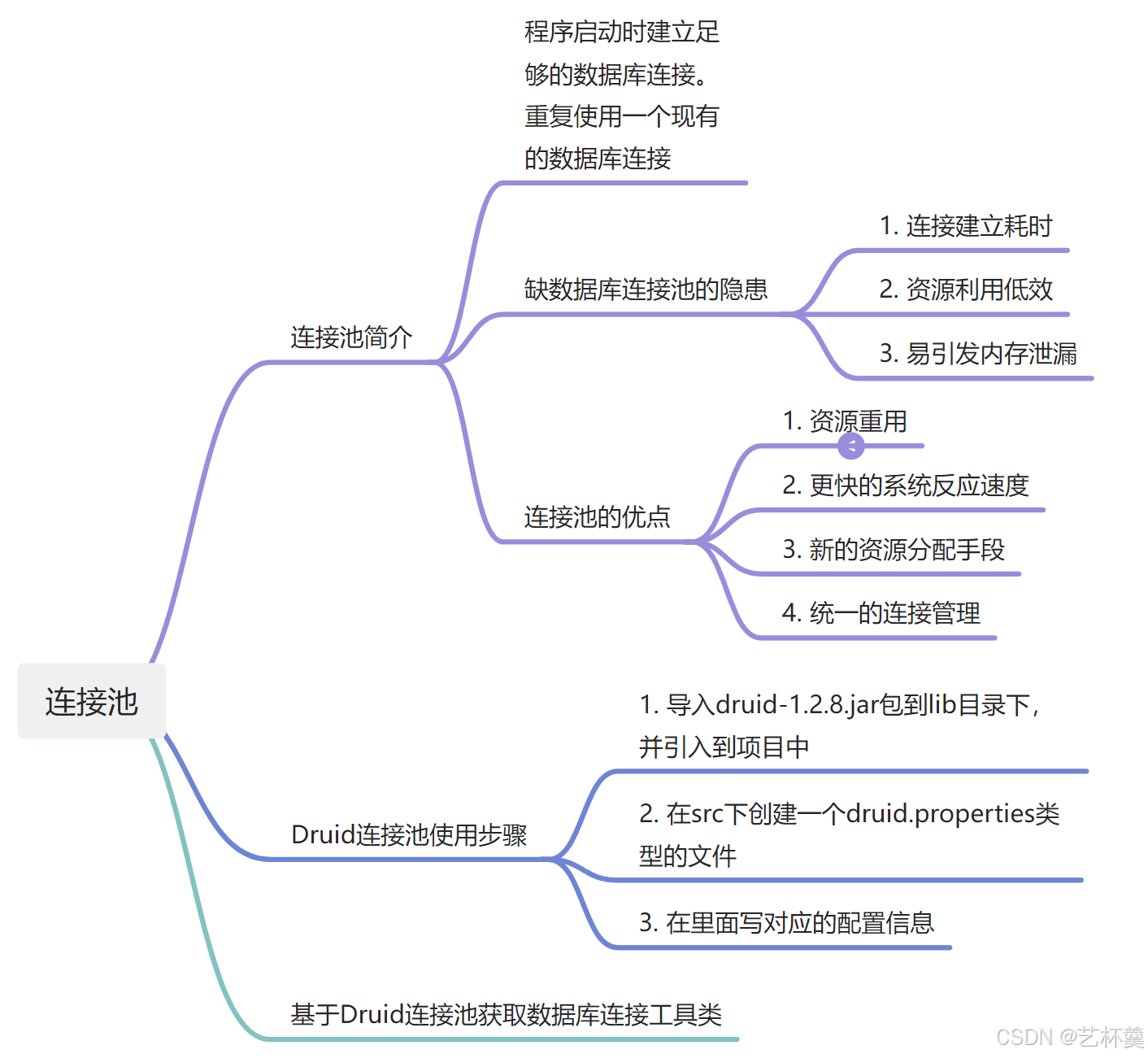
希望能够帮助到大家😊