PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录
- 音频处理技术及应用
- 音频处理技术
- 音视频摘要技术
- 音频识别及应用
- 梅尔频率倒谱系数音频特征
- 尔频率倒谱系数简介及参数提取过程
- 音频处理
- 快速傅里叶变换(FFT)
- 能量谱处理
- 离散余弦转换
- 练习案例:音频建模
- 加载音频数据源
- 波形变换的类型
- 绘制波形频谱图
- 波形Mu-Law 编码
- 对比前后波形的比较
- 练习案例:音频相似度分析
- 案例说明
- 实现代码
- 结果分析
音频处理技术及应用
- 音频信号具有采集设备简单、存储空间小、处理速度快等优势,本节介绍其核心技术及应用场景。
音频处理技术
-
音频处理技术的商业化应用日益广泛。例如,微软于2021年收购智能语音公司Nuance,主要看中其在医疗领域的对话式AI和云端解决方案。Nuance的Dragon语音转录软件采用深度学习技术,持续提升识别精度,该技术已应用于苹果Siri等产品。
-
随着移动设备的普及和算力提升,现代智能终端普遍配备声音传感器和高效处理器,使音频处理技术广泛应用于以下领域: 多媒体数据检索 、环境检测与自适应调整 、视觉辅助系统(在视线受阻或光照不足时提供补充信息)
-
关键技术突破包括:
- 环境类别识别:设备可通过音频分析自动切换模式(如手机识别场景类型)
- 辅助功能增强:助听器等设备整合环境识别功能,提升用户体验
- 场景感知:系统能通过声音特征(如对话、背景音)判断环境类型(如区分餐厅和车辆)
-
音频场景建模主要解决两个问题: 特定场所的声学特征建模(如餐厅、车站) 场景内对象/事件的声学特征检测(如笑声、鸣笛声)。尽管已开发MFCC等特征提取方法,但由于声音信号的复杂性,建模分析仍面临挑战。
音视频摘要技术
该技术通过提取关键内容实现信息压缩:
- 音频摘要:识别重要转折点,生成时间缩短但保留核心内容的版本
- 视频摘要:浓缩长视频的关键片段,特别适用于监控录像分析
关键技术实现:
- 音频兴趣度量化:
- 分割音频为等长片段
- 提取MFCC特征并计算协方差矩阵
- 通过特征空间映射评估兴趣度(实验证明可有效识别笑声等特征音)
- 音视频融合分析:场景转换常伴随声音变化(如球赛进球时的欢呼声),可辅助关键帧提取
音频识别及应用
主要解决海量音频数据的高效检索问题,核心应用包括:
-
音频分类: 四大类别:语音、音乐、环境音、静音
- 处理流程: 静音检测(基于能量阈值) ,MFCC特征提取,基于MDL的高斯建模分割,分层分类(语音/音乐/环境音)
-
音乐情感分析: 情感模型:
- 类别模型(6种基础情感)
- 维度模型(情感空间坐标)
- 应用价值:实现多媒体内容的情绪化索引和检索
梅尔频率倒谱系数音频特征
- 在语音识别(SpeechRecognition)和说话者识别(SpeakerRecognition)方面,最常用到的语音特征就是梅尔频率倒谱系数(MFCC)。
尔频率倒谱系数简介及参数提取过程
- 梅尔频率倒谱系数(MFCC)是音频处理中常用的特征提取方法。它的设计模仿了人耳对声音的感知特点。
-
基本原理:人耳对低频声音更敏感(比如能更好地区分低音变化),高频区域的区分能力相对较弱
-
计算过程:
- 先设置一组三角滤波器(低频区域滤波器密集,高频区域稀疏)
- 让音频信号通过这些滤波器
- 记录每个滤波器输出的能量值
- 对这些能量值做进一步处理得到最终特征
- 主要优势:不受原始声音内容影响(适用于各种声音);抗噪能力强(在嘈杂环境中仍能准确提取特征);符合人耳听觉特性(提取的特征更贴近实际听感)
- 这种方法让机器能像人耳一样"听懂"声音的关键特征。
- MFCC参数的提取过程如图
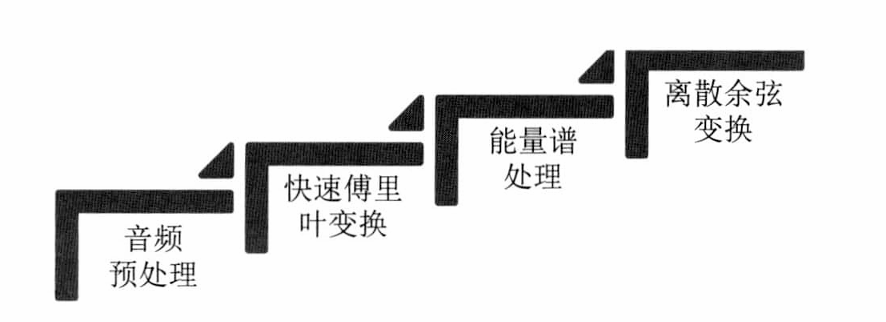
音频处理
- 信号预处理过程包括预加重,分侦,加载。预加重的过程即使将语音信号通过一个高通滤波器得到新的信号,如语音信号 s ( n ) s(n) s(n)通过高通滤波器 H ( z ) = l − α × ( z − l ) H(z)=l-α×(z-l) H(z)=l−α×(z−l)预加重后得到的信号为 s 2 ( n ) = s ( n ) − a × s ( n − l ) s_2(n)=s(n)-a×s(n-l) s2(n)=s(n)−a×s(n−l),其中,系数 a a a介于 0.9 0.9 0.9和 1.0 1.0 1.0之间。预加重的目的是补偿音频信号被隐藏的高频部分,从而凸显高频的共振峰。
- 预处理过程的第二个步骤是分帧,语音信号分帧的目的是将若干个取样点集合作为一个观测单位,即处理单位,一般认为 10 ~ 30 m s 10~30ms 10~30ms的语音信号是稳定的,比如采样率为 44.1 k H z 44.1kHz 44.1kHz的声音信号,取20ms长度为一个帧长,那么一个帧长由 44100 × 0.02 = 882 44100×0.02=882 44100×0.02=882个取样点组成。通常为了避免相邻两帧之间的变化过大,会在两相邻帧之间设置一段的重叠区域,重叠区域的长度一般是帧长的一半或 1 / 3 1/3 1/3。
- 在完成预加重和分帧之后,下一步是对每一帧应用汉明窗。通常,在处理语音信号时,“加窗”意味着一次只处理窗口内的数据。由于实际的语音信号往往很长,无法一次性全部处理。只需要每次分析一段数据即可。通过构造特定的函数实现,函数在处理区间内取非零值,在非处理区间内则为零。汉明窗就是这样一种函数,任何信号与汉明窗,任何信号与汉明窗相乘后,结果的一部分将是非零值,其余部分则为零。处理完一个窗口内的数据后,需要移动窗口,通常移动的步长是帧长的一半或三分之一以产生重叠。
- 汉明窗函数的形式
w ( n , a ) = ( 1 − a ) − a × c o s ( 2 π × n N − 1 ) 0 ≤ n ≤ N − 1 w(n,a)=(1-a)-a\times cos(2\pi \times \frac{n}{N-1}) 0\leq n\leq N-1 w(n,a)=(1−a)−a×cos(2π×N−1n)0≤n≤N−1 - N N N是处理数据点的个数(帧长),分帧是窗函数截取原音频信号形成的,一般a取值为0.46,汉明窗函数还可以写成如下形式:
KaTeX parse error: Undefined control sequence: \leqN at position 89: …{N-1}) 0\leq n \̲l̲e̲q̲N̲\\ 0\quad \te… - 加汉明窗后的声音信号如下:
s ( n ) = s ( n ) × w ( n ) n = 0 , 1 , . . . , N − 1 s(n)=s(n)\times \qquad w(n) n=0,1,...,N-1 s(n)=s(n)×w(n)n=0,1,...,N−1
快速傅里叶变换(FFT)
- 快速傅里叶变换(FastFourierTransform,FFT)是一种高效计算离散傅里叶变换(DFT)的算法,在音频处理中有着广泛的应用。
- 原始音频信号在时域上难以直观体现特征,因此需要通过加汉明窗后进行快速傅里叶变换(FFT),将其转换到频域来观察声音的能量分布特征。
- FFT是对离散傅里叶变换(DiscreteFourierTransform,DFT)的改进算法,快速算法实现的基本思想是分析原有变换的计算特点以及某些子运算的特殊性,想办法减少乘法和加法操作次数,换一种方式实现原变换的效果。
- 语音信号的离散傅里叶变换如下
S a ( k ) = ∑ n = 0 N − 1 s ( n ) ∗ e − j 2 π k / N 0 ≤ k ≤ N S_a(k)=\sum_{n=0}^{N-1}s(n)*e^{-j2\pi k/N} \qquad 0\leq k \leq N Sa(k)=n=0∑N−1s(n)∗e−j2πk/N0≤k≤N - s ( n ) s(n) s(n)是加窗后的语音信号, N N N表示傅里叶变换的点数。
- FFT是利用分治策略和对称性来减少DFT计算中的冗余步骤,从而提高了计算效率。这种算法特别适合信号处理中的频谱分析,因为它可以快速地从时域信号中提取出频域信息。
能量谱处理
- 音频预处理后,就需要计算能量谱,即求频谱幅度的平方。其计算方法是,将能量谱输入一组Mel频率的三角带通滤波器组,三角滤波器的中心频率为 f ( m ) , m = 1 , 2 , . . . , M f(m),m=1,2,...,M f(m),m=1,2,...,M,f(m)的取值随m取值的减小而缩小,随着m取值的增大而变宽,Mel频率代表的是一般人耳对于频率的感受度,其与一般的频率间的关系如下。
m e l ( f ) = 2595 ∗ l g ( 1 + f 700 ) mel(f)=2595*lg(1+\frac{f}{700}) \\ mel(f)=2595∗lg(1+700f) - 或者
m e l ( f ) = 1125 ∗ l g ( 1 + f 700 ) mel(f)=1125*lg(1+\frac{f}{700}) mel(f)=1125∗lg(1+700f) - 人耳对频率的感受度是呈对数变化的,在高频部分人耳对声音的感受越来越粗糙,在低频部分则相对敏感。三角滤波器引入的目的是平滑化频谱,消除谐波的作用,并突出原始信号的共振峰,因此MFCC参数不能呈现原始语音的音调或音高,即提取声音信号的MFCC特征时,不受语音音调的影响。三角滤波器的频率响应定义如下所示,其中
∑ m = 0 M − 1 H m ( k ) = 1 \sum_{m=0}^{M-1}H_m(k)=1 m=0∑M−1Hm(k)=1
H m ( k ) = { 0 k < f ( m − 1 ) 2 ( k − f ( m − 1 ) ) ( f ( m + 1 ) − f ( m − 1 ) ) ( f ( m ) − f ( m − 1 ) ) f ( m − 1 ) ⩽ k ⩽ f ( m ) 2 ( f ( m + 1 ) − k ) ( f ( m + 1 ) − f ( m − 1 ) ) ( f ( m + 1 ) − f ( m ) ) f ( m ) ⩽ k ⩽ f ( m − 1 ) 0 k ⩾ f ( m + 1 ) \begin{equation} H _ { m } ( k ) = \left\{ \begin{array} { l l } { 0 } & { k < f ( m - 1 ) } \\ { \cfrac { 2 ( k - f ( m - 1 ) ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m ) - f ( m - 1 ) ) } } & { f ( m - 1 ) \leqslant k \leqslant f ( m ) } \\ { \cfrac { 2 ( f ( m + 1 ) - k ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m + 1 ) - f ( m ) ) } } & { f ( m ) \leqslant k \leqslant f ( m - 1 ) } \\ { 0 } & { k \geqslant f ( m + 1 ) } \end{array} \right. \end{equation} Hm(k)=⎩ ⎨ ⎧0(f(m+1)−f(m−1))(f(m)−f(m−1))2(k−f(m−1))(f(m+1)−f(m−1))(f(m+1)−f(m))2(f(m+1)−k)0k<f(m−1)f(m−1)⩽k⩽f(m)f(m)⩽k⩽f(m−1)k⩾f(m+1)
离散余弦转换
- 离散余弦转换是一种在数字信号处理中非常有用的工具,它通过将信号转换为频域表示,帮助分析和处理信号,尤其在图像和音频编码领域有着重要的应用。例如,我们对对数能量做离散余弦转换(DCT),得到的 C ( n ) C(n) C(n) 即为 M M M 阶的Mel倒谱参数,通常取前12个作为最终的MFCC特征。计算公式如下:
C ( n ) = ∑ m = 0 N − 1 S ( m ) cos ( π n ( m − 0.5 ) M ) 0 ≤ n < M C(n) = \sum_{m=0}^{N-1} S(m) \cos \left( \frac{\pi n (m - 0.5)}{M} \right) \quad 0 \leq n < M C(n)=m=0∑N−1S(m)cos(Mπn(m−0.5))0≤n<M
- 上式得到的倒谱参数只能反映语音信号的静态特性,如果要获得语音信号的动态特性需采用静态特性的差分谱描述,结合动态和静态的特征能更有效地提高对信号的识别性能,计算差分参数的公式如下:
d t = { C t + 1 − C t t < K ∑ k = 1 K k ( C t + k − C t − k ) 2 ∑ k = 1 K k 2 其他 C t − C t − 1 t ≥ Q − K d_t = \begin{cases} C_{t+1} - C_t & t < K \\ \frac{\sum_{k=1}^{K} k (C_{t+k} - C_{t-k})}{\sqrt{2 \sum_{k=1}^{K} k^2}} & \text{其他} \\ C_t - C_{t-1} & t \geq Q - K \end{cases} dt=⎩ ⎨ ⎧Ct+1−Ct2∑k=1Kk2∑k=1Kk(Ct+k−Ct−k)Ct−Ct−1t<K其他t≥Q−K
- 其中, Q Q Q 表示的是倒谱系数的阶数, d t d_t dt 表示第 t t t 个一阶差分, C t C_t Ct 表示第 t t t 个倒谱系数, K K K 表示的是一阶导数的时间差,取1或2。
练习案例:音频建模
加载音频数据源
import torchaudio
import matplotlib.pyplot as plt#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
# 显示波形
print("波形形状:{}".format(waveform.size()))
# 显示采样率
print("波形采样率:{}".format(sample_rate))
# 绘制波形图并添加标题和坐标轴标签
plt.figure()
plt.plot(waveform.t().numpy())
plt.title("Audio Waveform")
plt.xlabel("Sample Points")
plt.ylabel("Amplitude")
plt.show()
波形形状:torch.Size([2, 8935836])
波形采样率:44100
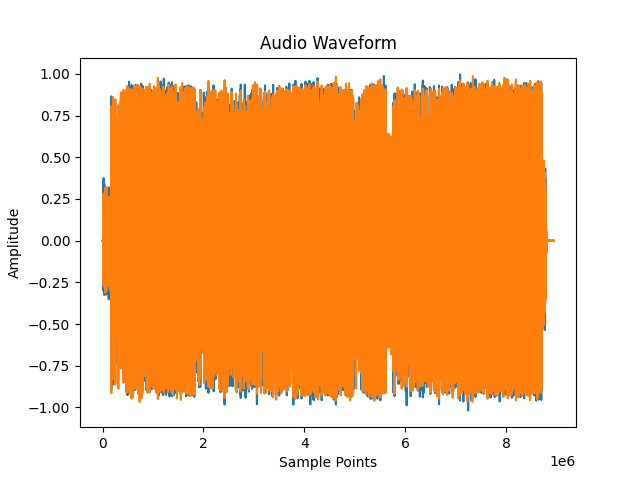
波形变换的类型
torchaudio库支持的波形转换类型如下。
| 功能名称 | 描述 |
|---|---|
| 重采样 (Resample) | 将波形重采样为其他采样率。 |
| 频谱图 (Spectrogram) | 从波形创建频谱图。 |
| GriffinLim | 使用Griffin-Lim转换从线性比例幅度谱图计算波形。 |
| ComputeDeltas | 计算张量(通常是声谱图)的增量系数。 |
| ComplexNorm | 计算复数张量的范数。 |
| MelScale | 使用转换矩阵将正常STFT转换为Mel频率STFT。 |
| AmplitudeToDB | 将频谱图从功率/振幅标度变为分贝标度。 |
| MFCC | 根据波形创建梅尔频率倒谱系数。 |
| MelSpectrogram | 使用PyTorch中的STFT功能从波形创建MEL频谱图。 |
| MuLawEncoding | 基于mu-law压扩对波形进行编码。 |
| MuLawDecoding | 解码mu-law编码的波形。 |
| TimeStretch | 在不更改给定速率的音高的情况下,及时拉伸频谱图。 |
| FrequencyMasking | 在频域中屏蔽频谱图应用。 |
| TimeMasking | 在时域中屏蔽频谱图应用。 |
绘制波形频谱图
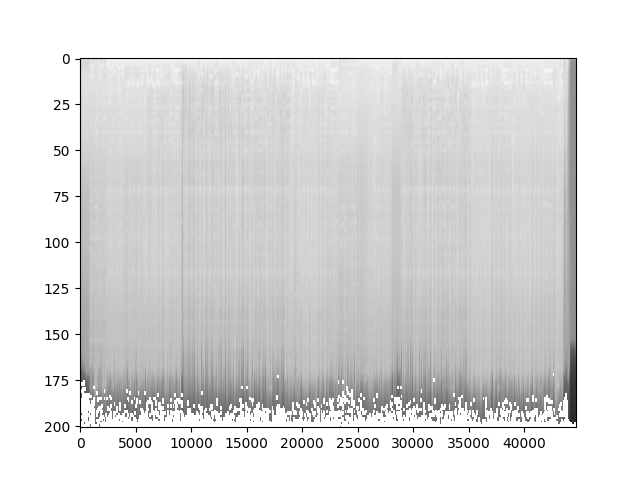
- 以对数刻度查看频谱图的对数。首先使用torchaudio库中的Spectrogram函数将波形数据转换为频谱图。然后打印出频谱图的形状,并使用Matplotlib库绘制并显示频谱图。通过观察频谱图,可以了解信号在不同频率上的能量分布情况。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
#对数刻度查看频谱图
spectrogram = torchaudio.transforms.Spectrogram()(waveform)
# 打印频谱图的形状,即频谱图的尺寸
print("频谱图形状:{}".format(spectrogram.size()))
plt.figure()
"""
# 显示频谱图的对数变换结果spectrogram.log2()[0,:,:].numpy()表示取频谱图的对数变换结果,并将其转换为NumPy 数组cmap='gray用于指定颜色映射为灰度色aspect="auto”表示自动调整图像的纵横比
"""
plt.imshow(spectrogram.log2()[0,:,:].numpy(),cmap='gray',aspect="auto")
plt.show()
频谱图形状:torch.Size([2, 201, 44680])
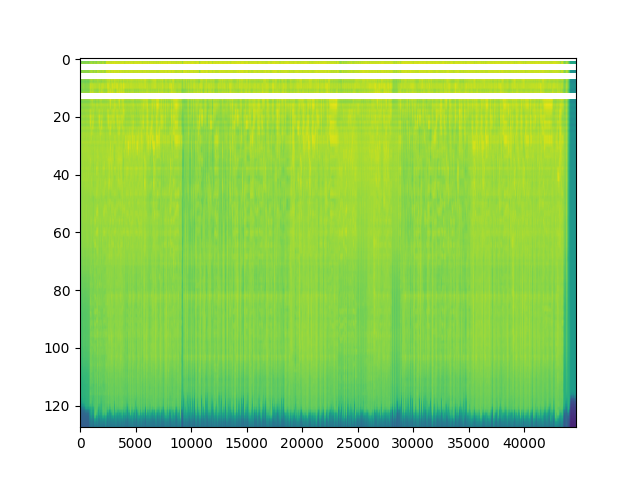
- 使用对数刻度查看梅尔频谱图。将波形数据转换为梅尔频谱图,并将其可视化显示出来,以便观察信号在梅尔频率尺度上的能量分布情况。使用MelSpectrogram函数来生成梅尔频谱图。梅尔频谱图是一种特殊的频谱表示,它基于梅尔频率尺度,常用于语音处理等领域。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
#对数刻度查看梅尔光谱图
spectrogram = torchaudio.transforms.MelSpectrogram()(waveform)
print("梅尔频谱图形状:{}".format(spectrogram.size()))
plt.figure()
# 显示梅尔频谱图的对数变换结果
p = plt.imshow(spectrogram.log2()[0,:,:].detach().numpy(),cmap='viridis',aspect="auto")
plt.show()
梅尔频谱图形状:torch.Size([2, 128, 44680])
- 重新采样波形,一次一个通道。重采样常用于改变波形的采样率,以便适应不同的需求或处理。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
# 计算新的采样率,将原始采样率除以15
new_sample_rate = sample_rate/15
# 选择要处理的通道,设置为0
channel = 0
# 使用Resample函数对波形进行重采样将原始采样率和新的采样率作为参数传递给函数,并将波形数据的指定通道转换为一维张量
transformed = torchaudio.transforms.Resample(sample_rate,new_sample_rate)(waveform[channel,:].view(1,-1))
# 打印变换后波形的形状,即尺寸信息
print("变换后波形形状:{}".format(transformed.size()))
plt.figure()
# 绘制变换后的波形 transformed[O,:]表示取变换后波形的第一个样本,并将其转换为NumPy数组进行绘图
plt.plot(transformed[0,:].numpy())
plt.show()
变换后波形形状:torch.Size([1, 595723])
波形Mu-Law 编码
- 基于Mu-Law编码对信号进行编码,需要信号在-1和1之间。由于张量只是一个常规的PyTorch张量,因此可以在其上应用标准运算符。
print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_.min(),waveform_.max(),waveform_.mean()))
波形最小值:-1.0179462432861328
波形最大值:0.9967186450958252
波形平均值:-1.8553495465312153e-05
- 对波形进行归一化,使其处于-1到1之间。
#波形的归一化
def normalize(tensor):tensor_minusmean = tensor - tensor.mean()return tensor_minusmean/tensor_minusmean.abs().max()waveform_normalize = normalize(waveform)print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_normalize.min(),waveform_normalize.max(),waveform_normalize.mean()))
波形最小值:-1.0
波形最大值:0.9791827201843262
波形平均值:1.3822981648203836e-09
- 应用编码波形,绘制波形图帮助理解变换后的波形特征。
#新波形Mu-Law编码
transformed = torchaudio.transforms.MuLawEncoding()(waveform_normalize)
print("变换后波形形状: {}".format(transformed.size()))plt.figure()
plt.plot(transformed[0,:].numpy())
plt.show()
- 解码并观察到解码后新波形的形状和特征。Mu-Law编码是Mu-Law编码的逆操作,用于将编码后的波形还原为原始波形的近似。绘制波形图可以帮助直观地理解解码后的波形特征。
#对新波形解码
reconstructed = torchaudio.transforms.MuLawDecoding()(transformed)
print("新波形形状: {}".format(reconstructed.size()))plt.figure()
plt.plot(reconstructed[0,:].numpy())
plt.show()
对比前后波形的比较
- 分析波形变换前后是否存在较大差异,可以将原始波形与归一化和Mu-Law变换后的波形进行比较。评估原始波形和重构波形之间的相似度或差异程度。
#比较原始波形与新波形
epsilon = 1e-8
err = ((waveform - reconstructed).abs() / (waveform.abs() + epsilon)).mean()
print("原始信号和重构信号之间的差异: {:.2%}".format(err))
原始信号和重构信号之间的差异: 27.08%
练习案例:音频相似度分析
案例说明
- 通过使用torchaudio库和余弦相似度研究两个音频之间的相似程度,从而根据用户喜欢的音频信号进行音乐等方面的推荐。
实现代码
import torch
import torchaudio
import soundfile
import matplotlib.pyplot as plt
# 支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题filename1 = "教程1.wav"
waveform1,sample_rate1 = torchaudio.load(filename1)
print("Shape of waveform:{}".format(waveform1.size())) #音频大小
print("sample rate of waveform:{}".format(sample_rate1))#采样率
plt.figure()
plt.plot(waveform1.t().numpy())
plt.title("教程1波形")
plt.show()filename2 = "教程2.wav"
waveform2,sample_rate2 = torchaudio.load(filename2)
print("Shape of waveform:{}".format(waveform2.size())) #音频大小print("sample rate of waveform:{}".format(sample_rate2))#采样率
plt.figure()
plt.plot(waveform2.t().numpy())
plt.title("教程2波形")
plt.show()similarity = torch.cosine_similarity(waveform1, waveform2, dim=0)
print('similarity', similarity)
# 输出平均差异值
print(similarity.mean())
# 输出中位数
print(similarity.median())
结果分析
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487])
tensor(-6.3115e-05)
tensor(0.)
- 余弦相似度是一种常用的相似性度量,用于衡量两个向量之间的相似程度。这里用于比较两个波形之间的相似度运行结果为
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487]) - 相似度矩阵的均值
similarity.mean()计算相似度矩阵的均值。 - 相似度矩阵的中位数
similarity.median()接近于0,说明两个音频不相思。