Filament引擎(一) ——渲染框架设计
filament是谷歌开源的一个基于物理渲染(PBR)的轻量级、高性能的实时渲染框架,其框架架构设计并不复杂,后端RHI的设计也比较简单。重点其实在于项目中材质、光照模型背后的方程式和理论,以及对它们的实现。相关的信息,可以参考官方给出的文档。filament比较注重运行效率,在实现上也使用了一些抽象和技巧,这些也是比较有意思的代码,可以学习和借鉴。
框架的整体设计
按照github项目中的说明,filament是适用主流平台的实时物理渲染引擎,设计的目的是期望在Android上小而快。
Filament is a real-time physically based rendering engine for Android, iOS, Linux, macOS, Windows, and WebGL. It is designed to be as small as possible and as efficient as possible on Android.
在其设计中,使用Entity、components下各Manager中用来表示Component的数据结构及Manager本身,再加上Renderer,形成了ECS(Entity-Component-System)架构。
另外filament中存在一个backend的子工程,是一套自定义的RHI(Render Hardware Interface),封装了诸如OpenGL、Vulkan、Metal的后端渲染API(PS:没有DirectX,Windows平台,官方默认使用Vulkan)。
在“ECS”和“RHI”之间,filament通过Renderer类,内部使用RenderPass、FrameGraph等来组织backend提供的RHI进行渲染,承担最重要的“RenderSystem”的工作。
渲染后端RHI设计
Filament的渲染后端RHI非常轻量,并没有什么复杂的设计,使用起来也相对比较简单。不过它在异步渲染的实现上有一些不太好看但是实用的“奇淫巧技”。
Filament定义了一个RHI空对象基类HwBase,然后派生了一系列的RHI对象,包括HwVertexBuffer、HwIndexBuffer、HwProgram、HwTexture、HwRenderTarget等等。基本上和其他诸多渲染框架采用的是类似的概念,然后不同的后端渲染(OpenGL/Vulkan/Metal)继承这些对象,进行了不同后端的实现,如基于HwProgram派生了OpenGLProgram、VulkanProgram以及MetalProgram。其他各类对象也是类似。
另外Filament有一个Driver的基类,基于这个Driver基类,派生了各后端渲染的Driver,包括VulkanDriver/MetalDriver/OpenGLDriver/NoopDriver,没有DirectXDriver,Windows平台,官方使用Vulkan来进行渲染。Driver作为渲染的主要入口,所有RHI对象的创建销毁及更新,都经由Driver来进行调用。
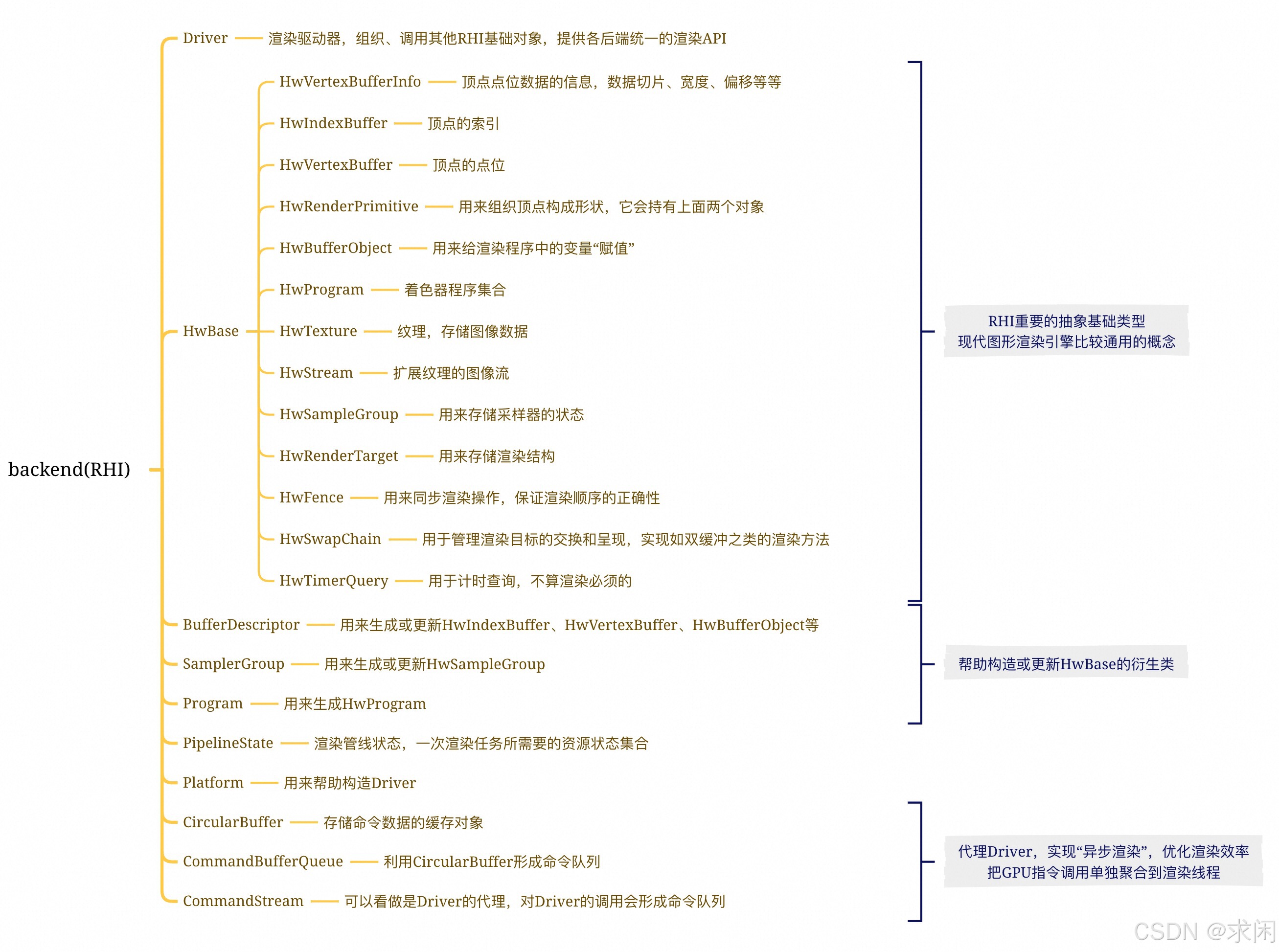
RHI的使用流程
Filament的RHI抽象和封装度并不复杂,所以在使用上,如果有用过OpenGL、Vulkan、Metal的API,那么理解Filament的后端渲染也比较简单。主要的使用流程参考以下代码:
// 1. 初始化RHI的Driver
auto backend = filament::Backend::METAL;
auto platform = PlatformFactory::create(&backend);
Platform::DriverConfig const driverConfig;
auto driver = platform->createDriver(nullptr, driverConfig);
auto api = driver;
// 2. 创建SwapChainHandle,作为输出。如果需要输出到Window上,需要利用Window指针来进行创建
// api.createSwapChain(view.ptr, 0)
auto swapChain = api.createSwapChainHeadless(256, 256, 0);
api.makeCurrent(swapChain, swapChain);
// 3. 创建ProgramHandle,后续用来进行渲染,依赖Program对象,注意,Program和ProgramHandle不是同一个东西,Program就是用来创建ProgramHandle的一个参数集合
Program progCfg; // 进行相关配置
progCfg.shaderLanguage(ShaderLanguage::MSL);
projCfg.shader(ShaderStage::VERTEX, mVertexBlob.data(), mVertexBlob.size());
projCfg.shader(ShaderStage::FRAGMENT, mFragmentBlob.data(), mFragmentBlob.size());
projCfg.setSamplerGroup(0, ShaderStageFlags::ALL_SHADER_STAGE_FLAGS, psamplers, sizeof(psamplers) / sizeof(psamplers[0]));
auto program = api.createProgram(progCfg);
// 4. 创建渲染需要的纹理,更新纹理数据
auto tex = api.createTexture(SamplerType::SAMPLER_2D, 1, TextureFormat::RGBA8, 1, 512, 512, 4, usage);
PixelBufferDescriptor descriptor = createImage();
api.update3DImage(tex, 1, 0, 0, 0, 512, 512, 1, std::move(descriptor));
// 5. 设置采样方式
SamplerGroup samplers(1);
SamplerParams sparams = {};
sparams.filterMag = SamplerMagFilter::LINEAR;
sparams.filterMin = SamplerMinFilter::LINEAR_MIPMAP_NEAREST;
samplers.setSampler(0, { tex, sparams });
auto sgroup = api.createSamplerGroup(samplers.getSize(), utils::FixedSizeString<32>("Test"));
api.updateSamplerGroup(sgroup, samplers.toBufferDescriptor(api));
api.bindSamplers(0, sgroup);
// 6. 开始一帧渲染,一个完整的渲染周期,可能由很多次渲染组成的一个渲染帧
api.beginFrame(0, 0, 0);
// 7. 创建RenderTarget,配置RenderPassParams,进而开启RenderPass。RenderPass一般表示的是在一个渲染目标上进行的一系列渲染。
RenderPassParams params = {};
params.flags.clear = TargetBufferFlags::COLOR;
params.clearColor = {0.f, 0.f, 1.f, 1.f};
params.flags.discardStart = TargetBufferFlags::ALL;
params.flags.discardEnd = TargetBufferFlags::NONE;
params.viewport.height = 512;
params.viewport.width = 512;
auto renderTarget = api.createDefaultRenderTarget(0);
api.beginRenderPass(renderTarget, params);
// 8. 配置PipelineState
PipelineState state;
state.program = program;
state.rasterState.colorWrite = true;
state.rasterState.depthWrite = false;
state.rasterState.depthFunc = RasterState::DepthFunc::A;
state.rasterState.culling = CullingMode::NONE;
// 9. 构建Primitive,Primitive主要包括顶点位置、顶点索引等相关数据
auto vertexBufferObj = api.createBufferObject(size, BufferObjectBinding::VERTEX, BufferUsage::STATIC);
auto vertexBufferInfo = api.createVertexBufferInfo(bufferCount, attributeCount, attributes);
auto vertexBuffer = api.createVertexBuffer(vertexBufferObj, vertexBufferInfo);
auto indexBuffer = api.createIndexBuffer(elementType, mIndexCount, BufferUsage::STATIC);
api.updateIndexBuffer(indexBuffer, std::move(indexBufferDesc), 0);
auto primitive = api.createRenderPrimitive( vertexBuffer, indexBuffer, PrimitiveType::TRIANGLES);
// 10. 渲染指令
api.draw(state, primitive, 0, mIndexCount, 1);
// 11. 终止RenderPass。
api.endRenderPass();
// 12. 一帧内要进行的所有渲染指令调用完后,提交并结束一帧渲染
api.commit(swapChain);
api.endFrame()
// 13. 如果当前的渲染任务结束了,不会再执行了,销毁所有资源。
api.destroySamplerGroup(sgroup);
api.destroyProgram(program);
api.destroySwapChain(swapChain);
api.destroyRenderTarget(renderTarget);
// 14. 如果所有渲染结束,要终止渲染了,结束渲染
api.finish();
driver->purge();
driver->terminate();
以上是简化的一个渲染流程中,在实际的渲染过程中,我们一般会进行多帧循环渲染。在一帧渲染过程中,我们也可能会有多个renderpass,甚至有subrenderpass。RenderTarget、Program、PipelineState、Primitive等RHI对象的创建,我们也不是一定要按照上面的顺序来进行,只需要在被使用前创建好既可。
Driver中提供了startCapture来进行CPU和GPU的监测,我们一般也并不需要用到。而且在实现上也只有MetalDriver调用了Metal的API进行了实现。需要使用时,在需要进行监测的区间,调用startCapture/stopCapture即可。
异步渲染的实现
以上的调用,主要是用来说明Filament的使用流程,但是在实际的应用中,考虑到渲染效率和对渲染帧率的要求,我们往往需要进行异步渲染,把CPU和G的操作尽量并行起来。这时候,所有Filament的渲染指令的调用,都需要被发送到另外的线程中进行执行。我们不能再直接使用Driver对象去进行相关渲染指令的调用,而应该用CommandStream。
在Filament中有一个DriverAPI.inc的头文件,采用宏定义的方式,定义了一系列的渲染API,宏的具体实现又由引入者来进行。
最终呈现的效果,就是Driver定义了一系列的Driver的API,各后端实现对其进行了继承,并实现。
CommandStream没有继承Driver,但是通过引入DriverAPI.inc,实现了一套和Driver的API一一对应,可以将Driver的各命令提交到队列中的方法。
DriverAPI.inc使用宏调用的方式定义了一系列的函数,宏的定义又并不是在DriverAPI.inc中,几个宏DECL_DRIVER_API、DECL_DRIVER_API_SYNCHRONOUS以及DECL_DRIVER_API_RETURN都是留给引用者定义,并在文件后undef这三个宏避免污染。每次引用DriverAPI.inc前,必须定义这三个宏,否则会编译报错。
Vulkan/Metal/OpenGL等各后端对于DECL_DRIVER_API的定义并没什么差别,就是直接声明对应名称的函数。只有NoopDriver,在定义DECL_DRIVER_API_RETURN进行了空实现。
CommandStream/Dispatcher也都引入了DriverAPI.inc。
Dispatcher中DECL_DRIVER_API的定义就是一个function,那么引入DriverAPI.inc实际上,就是定义了一堆的Function,这么做主要是为了帮助CommandStream实现DriverAPI.inc中的方法时,来进行Command的构建。
CommandStream中的DECL_DRIVER_API的定义,是根据方法名(methodName),利用Dispatcher,构建出一个调用Driver.methodName的Command。这种实现方式虽然阅读起来稍微麻烦一点,但是需要进行Driver函数的扩展会可以减少很多工作。
CommandStream中需要的Command是通过模板的方式进行定义的,参考CommandType和Command模板,由Command自己存储所有指令执行时所需要的参数信息。CommandStream中有一个CircularBuffer,用来存储所有的Command,Cammand一般都是在CommandStream调用DriverAPI.inc声明的相关API时进行创建。创建过程是先根据Command对象需要的大小来申请内存,然后在这块内存上构建(也可以说是初始化)Command对象。
在使用上,CommandStream和Driver具有基本一致的函数,利用Filament的backend去实现异步渲染时,相对同步渲染,只需要以下几步:
- 创建
CommandBufferQueue,然后利用Driver实例和CommandBufferQueue中的CircularBuffer去构造一个CommandStream。 - 创建一个渲染线程,在渲染线程中循环等待渲染指令,然后执行渲染指令。在必要的时候进行退出。
- 在另外的线程里面像使用
Driver一样,使用CommandStream去执行相关命令接口。
当然,这是简化的说明,在实际使用中肯定还需要做一些额外的处理工作。Filament在使用其backend时,基于backend的api进行了进一步的封装,以简化调用。
渲染系统的实现
在filament中,实际上是由Renderer类承担了渲染系统的职责,其执行渲染工作的核心代码比较简单:
if (renderer->beginFrame(window->getSwapChain())) {for (filament::View* offscreenView: mOffscreenViews) {renderer->render(offscreenView);}for (auto const& view: window->mViews) {renderer->render(view->getView());}if (postRender) {postRender(mEngine, window->mViews[0]->getView(), mScene, renderer);}renderer->endFrame();
}
其主要使用流程为:
- beginFrame开启一帧渲染。beginFrame的时候,需要指定一个SwapChain,决定了最终渲染输出的位置。
- render执行一帧渲染。render执行一帧渲染的时候,不是直接就进行了渲染,而是构建FrameGraph,并进行compile,然后execute。
- endFrame结束一帧渲染
Renderer的每一次渲染,都是执行一次renderJob(这个函数比较复杂,理论上应该拆一下)。它进行的工作,主要就是构建一个FrameGraph,通过对其进行“编译”,再执行,以达到优化渲染的目的。FrameGraph的构建看起来非常复杂,主要进行的工作是将外部设置的信息,转换成FrameGraph中的ResourceNode、PassNode、VirtualResource等列表,并在此过程中,构建DependencyGraph,以明确PassNode、ResourceNode的依赖关系。
FrameGraph的“编译”(compile),主要做了以下事情:
- 遍历它所包含的所有的
PassNode。对于每个PassNode, 会通过DependencyGraph,去获取它所依赖的资源,并把这些资源信息注册到PassNode当中。RendererTarget的数据的更新在资源注册后,通过调用PassNode.resolve进行。在资源信息注册到PassNode时,每个资源会记录并更新最早使用它的节点和最晚使用它的节点, 以便后续根据这个信息,来进行真实资源的创建和销毁。 - 而后,资源列表会被遍历,然后借助资源中记录的最早和最晚使用它的节点信息,来把资源直接挂载到相应节点的资源构造(
Resource.devirtualize)和资源析构列表(Resource.destroy),这样就后续就可以方便合理的进行资源的按需创建和销毁。 - 遍历所有的资源节点,解析它们的用途(
Resource.usage),后续资源进行真实资源创建时(Resource.devirtualize),需要用到。
FrameGraph的“执行”(execute),也是遍历它所包含的所有PassNode,针对每个PassNode进行一下工作:
- 资源准备,
VirtualResource.devirtualize - RenderPassNode执行
- 根据RenderPassData列表,进行必要的RenderTarget的构造
- mPassBase->execute,将指令进行部分解析,转换成RHI指令数据,加入到Engine下的CommandStream中,由CircularBuffer进行存储和管理。
- 析构前面构造的RenderTarget
- 资源析构,
VirtualResource.destroy
需要注意的是,其中的资源构造和资源析构,并不一定是在一次循环里对同一个资源进行。而是根据需要,在资源不再被后续的PassNode使用时,才会被析构。
在异步模式下,filament的FEngine构建时候,会启动一个渲染线程,用来通过CommandStream对应的CommandBuffferQueue,来循环从CircularBuffer中获取指令列表,让真正的Driver来进行执行.执行完成后CircularBuffer中相应的指令空间就会被回收,用来接受CommandStream给的新指令。
ECS的实现
前面说到,Filament上层是一个ECS的设计。我们将其拆开来理解。引擎中的Entity结构非常简单,它在内存中实际上就是一个unit32_t,代表的Entity的索引,它本身并不持有Component的数据,相对来说非常简单,重点在于Component和System。
Filament中的Component更多的是一个概念,每类Component都有一个对应的Manager,Manager包含了:
- Component的数据结构
- 向Entity中增删此Component。实际上Component的数据实例,是由Manager持有和管理,并记录和Entity的关联。
- 查询某个Entity,是否具备Component。
- 更新Entity中对应Component的数据
Filament中的ComponentManager包括CameraManager、LightManager、RenderableManager、TransformManager。这些Manager的实现大同小异,都是依赖utils::SingleInstanceComponentManager、utils::EntityInstance这些模板类来做的实现。
以RenderableManager为例,其内部存在一个mManager成员,对象类型继承自utils::SingleInstanceComponentManager模板类,如下代码所示。
using Base = utils::SingleInstanceComponentManager<Box, // AABBuint8_t, // LAYERSMorphWeights, // MORPH_WEIGHTSuint8_t, // CHANNELSInstancesInfo, // INSTANCESVisibility, // VISIBILITYutils::Slice<FRenderPrimitive>, // PRIMITIVESBones, // BONESFMorphTargetBuffer* // MORPHTARGET_BUFFER
>;struct Sim : public Base {using Base::gc;using Base::swap;struct Proxy {// all of this gets inlinedUTILS_ALWAYS_INLINEProxy(Base& sim, utils::EntityInstanceBase::Type i) noexcept: aabb{ sim, i } { }union {// this specific usage of union is permitted. All fields are identicalField<AABB> aabb;Field<LAYERS> layers;Field<MORPH_WEIGHTS> morphWeights;Field<CHANNELS> channels;Field<INSTANCES> instances;Field<VISIBILITY> visibility;Field<PRIMITIVES> primitives;Field<BONES> bones;Field<MORPHTARGET_BUFFER> morphTargetBuffer;};};UTILS_ALWAYS_INLINE Proxy operator[](Instance i) noexcept {return { *this, i };}UTILS_ALWAYS_INLINE const Proxy operator[](Instance i) const noexcept {return { const_cast<Sim&>(*this), i };}
};Sim mManager;
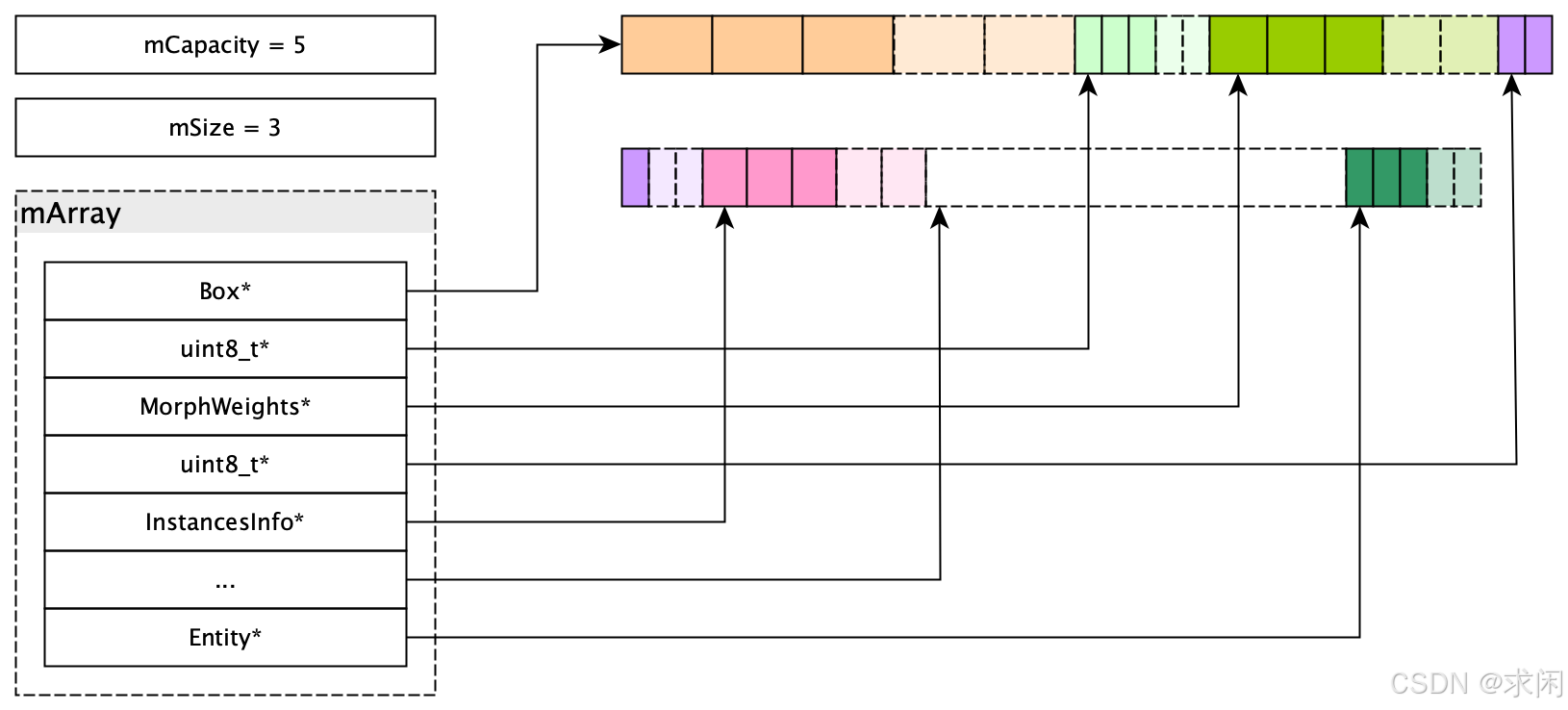
RenderableManager对外的函数,最后基本上是对mManager的包装。mManager用一个StructureOfArrays的模板类对象实例mData,来管理着当前Manager对应类别的所有Component数据集。上面SingleInstanceComponentManager模板传入的参数,实际就构成了Component的数据结构。Sim定义了下标运算符,使mManager可以像数组一样通过索引取得Component的代理对象,访问Component数据。
但是,**在内存中实际存储时,并不是按照Component的数据结构来存储的,而是把相同的属性的数据放到了一起。**StructureOfArrays中,mArray是一个std::tuple,存储了所有属性数据的起始地址。以FRenderableManager中mManager的数据存储为例,图示如下:
在Filament的ECS中,S其实主要就一个,渲染系统Renderer,上面已对其渲染执行的过程进行了简单的分析。其构建FrameGraph的过程比较复杂,涉及到诸多信息的处理,另外还包含一些View的操作,后面有时间再对其构建过程进行解读。
欢迎转载,转载请保留文章出处。求闲的博客[https://blog.csdn.net/junzia/article/details/141300106]