算法岗实习八股整理——深度学习篇(不断更新中)
目录
- 激活函数
- 特征
- 典型例子
- sigmod函数
- tanh函数
- 补充:零中心化输出优势
- 非线性特性如何提升神经网络表现
激活函数
特征
- 非线性:激活函数满足非线性时,才不会被单层网络替代,神经网络才有意义
- 可微性:优化器大多数是用梯度下降法更新梯度,如果不可微的话,就不能求导,也不能更新参数
- 单调性:激活函数是单调的,能够保证网络的损失函数是凸函数,更容易收敛
典型例子
sigmod函数
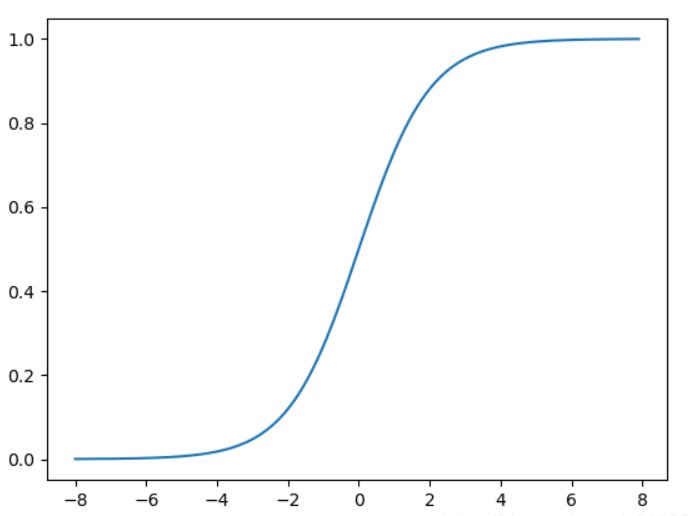
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
(1)取值范围为(0,1)
- 它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或者相差不是特别大的时候效果比较好。
- 当x无穷大的时候,函数值趋近于1;当x无穷小的时候,趋近于0。相当于对输入进行了归一化操作。
- 连续可导,0点导函数的值最大,并且两边逐渐减小。
(2)优缺点
- 优点: 平滑、易于求导。
- 缺点:
1)激活函数计算量大,反向传播求误差的时候,求导涉及到除法,很容易出现梯度消失的情况,从而无法完成深层网络的训练。
2)x在无穷大或者负无穷小的时候,导数(梯度)为0,即出现了梯度弥散现象(梯度值越来越小)
3)导数的值在(0,0.25)之间,在多层神经网络中,我们需要对输出层到输入层逐层进行链式求导。这样就导致多个0到0.25之间的小数相乘,造成了结果取0,梯度消失
4)Sigmoid函数存在幂运算,计算复杂度大,训练时间长
5)Sigmoid 函数的输出不是 0 均值,并且其导数始终为正,这可能导致后一层神经元接收到的输入信号均值偏离 0,并且梯度的方向可能过于单一。这些问题可能会影响神经网络的训练效率和性能。
理解一下:
如果激活函数的输出不是 0 均值,那么后一层神经元接收到的输入信号的均值也不是 0。这可能会导致网络的每一层的输入分布逐渐偏离 0 均值,从而影响网络的收敛速度和稳定性。
如果输入数据始终是正的,那么在反向传播过程中,梯度的符号可能会始终为正。这可能导致权重更新的方向始终一致,从而减慢收敛速度,甚至导致网络陷入局部最优。
(3)导数
σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) ) = e − x ( 1 + e − x ) 2 \sigma'(x)= \sigma(x) \cdot (1 - \sigma(x))=\frac{e^{-x}}{(1+e^{-x})^2} σ′(x)=σ(x)⋅(1−σ(x))=(1+e−x)2e−x
导数的值在(0,0.25)之间。
tanh函数
更详细的tanh函数解析可见大大link1
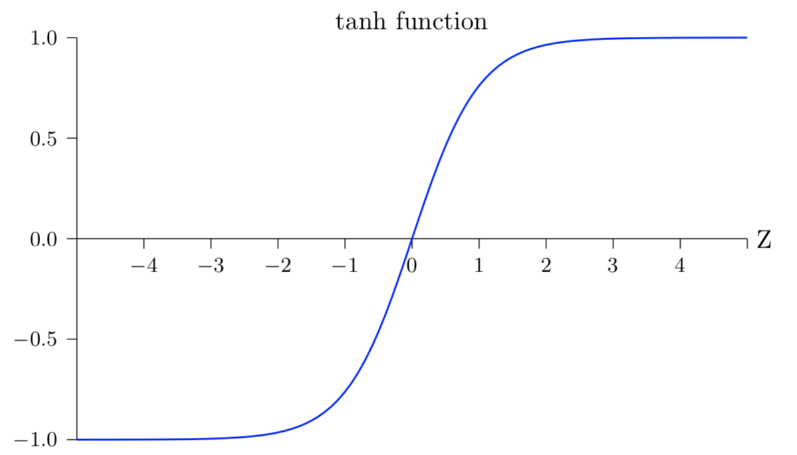
t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x
(1) 双曲正切函数(双曲余弦除双曲正弦)
当 x 趋近于正无穷时,tanh(x) 趋近于 1;当 x 趋近于负无穷时,tanh(x) 趋近于 -1。
在 x=0 处,tanh(x)=0,并且该点是图像的对称中心。
(2)导数
t a n h ′ ( x ) = 1 − ( e x − e − x e x + e − x ) 2 = 1 − t a n h ( x ) 2 tanh'(x)=1-(\frac{e^x-e^{-x}}{e^{x}+e^{-x}})^2=1-tanh(x)^2 tanh′(x)=1−(ex+e−xex−e−x)2=1−tanh(x)2
梯度(导数)的取值在(0, 1]之间
(3)特点
- tanh函数输出满足0均值(补上了sigmod的缺点)
- 当tanh(x)接近正负1的时候,导数会趋于0,可能引发梯度消失问题
- 梯度(导数)的取值在(0, 1]之间,最大梯度为1,能够保证梯度在变化过程中不消减,缓解了Sigmoid函数梯度消失的问题
- 存在幂运算,计算量大
- 在时间序列建模、情感分析和回归任务中,表现出色。
(4)与sigmod关系
t a n h ( x ) = 2 ⋅ s i g m o d ( 2 x ) − 1 tanh(x)=2\cdot sigmod(2x)-1 tanh(x)=2⋅sigmod(2x)−1
补充:零中心化输出优势
-
权重更新更高效:
零中心化意味着正负输出值的对称性,这让权重的正负变化更加平衡,避免了像 Sigmoid 那样总是向一个方向偏移。
梯度更新时不容易产生偏移,从而加快收敛速度。 -
适合对称分布的数据:
如果输入数据经过标准化(均值为 0),tanh的输出能更好地保持对称性,从而与数据的分布更加匹配。 -
减小梯度爆炸风险:
零中心化输出有助于稳定梯度传播,避免因输出值过于偏向正值或负值而导致的梯度爆炸问题。
非线性特性如何提升神经网络表现
- 引入非线性能力:
如果没有激活函数,神经网络的每一层只能执行线性运算(矩阵乘法和加法),即便网络很深,最终的输出仍是线性变换,无法解决复杂的非线性问题。
tanh将输入数据通过非线性映射变换为[−1,1],使网络能够学习复杂的特征模式。 - 对中间特征的放大与压缩 :
在[−2,2]的输入范围内,tanh 对输入值的变化较为敏感,能放大特征差异,从而更好地捕捉细节信息。
对于极值输入(非常大或非常小的值)tanh 将输出压缩到接近-1或1,起到了正则化的作用,避免过拟合。 - 平滑的梯度变化:
tanh 是一个平滑的函数,其导数在大多数区间内都较为稳定。这让网络能够更平稳地调整权重,尤其是在处理非平滑输入时。