计算机的基本组成与性能
1. 冯·诺依曼体系结构:计算机组成的金字塔
1.1. 计算机的基本硬件组成
1.CPU - 中央处理器(Central Processing Unit)。
2.内存(Memory)。
3.主板(Motherboard)。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。
4.输入(Input)/ 输出(Output)设备,也就是I/O 设备。
5.显卡(Graphics Card)。显卡里有除了 CPU 之外的另一个“处理器”,也就是GPU(Graphics Processing Unit,图形处理器。
鼠标、键盘以及硬盘,这些都是插在主板上的。作为外部 I/O 设备,它们是通过主板上的南桥(SouthBridge)芯片组,来控制和 CPU 之间的通信的。
1.2. 冯·诺依曼体系结构
冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。这里面暗含了两个概念,一个是“可编程”计算机,一个是“存储”计算机。
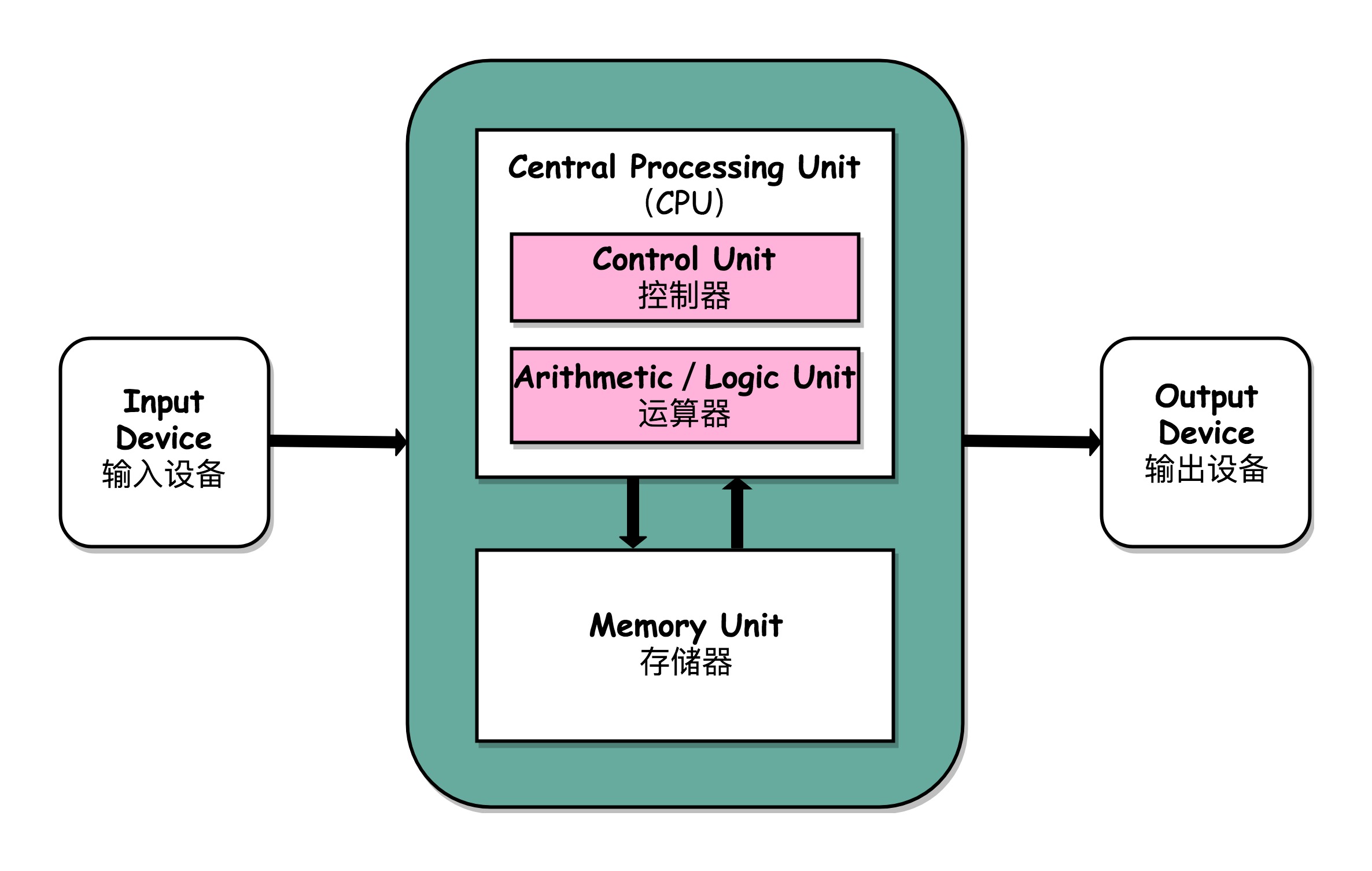
所有的计算机程序,也都可以抽象为从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中。
计算机的两个核心指标,性能和功耗。
2. 计算机的性能
2.1. 衡量计算机性能的两个指标
响应时间(Response time)或者叫执行时间(Execution time)。响应时间指的就是,我们执行一个程序,到底需要花多少时间。花的时间越少,自然性能就越好。
吞吐率(Throughput)或者带宽(Bandwidth)。吞吐率是指我们在一定的时间范围内,到底能处理多少事情。这里的“事情”,在计算机里就是处理的数据或者执行的程序指令。
2.2. 计算机的计时单位:CPU 时钟
Linux 下 time 的命令,运行time 命令会返回三个值,第一个是real time,也就是 Wall Clock Time,也就是运行程序整个过程中流逝掉的时间;第二个是user time,也就是 CPU 在运行你的程序,在用户态运行指令的时间;第三个是sys time,是 CPU 在运行你的程序,在操作系统内核里运行指令的时间。程序实际花费的 CPU 执行时间(CPU Time),就是 user time 加上 sys time。
程序的 CPU 执行时间 =CPU 时钟周期数(CPU Cycles)×时钟周期时间(Clock Cycle)
Intel Core-i7-7700HQ 2.8GHz,这里的 2.8GHz 就是电脑的主频(Frequency/Clock Rate)。在这个 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。
对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)”。
程序的 CPU 执行时间 = 指令数×CPI×Clock Cycle Time
如果想要解决性能问题,其实就是要优化这三者:
- 时钟周期时间,就是计算机主频,这个取决于计算机硬件。
- 每条指令的平均时钟周期数 CPI,就是一条指令到底需要多少 CPU Cycle。
- 指令数,代表执行我们的程序到底需要多少条指令、用哪些指令。
3. 如何提升计算机的性能
3.1. 功耗:CPU 的“人体极限”
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。而这两者,都会增加功耗,带来耗电和散热的问题。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
3.2. 并行优化,理解阿姆达尔定律
从奔腾 4 开始,Intel 意识到通过提升主频比较“难”去实现性能提升,边开始推出 Core Duo 这样的多核 CPU,通过提升“吞吐率”而不是“响应时间”,来达到目的。
阿姆达尔定律(Amdahl’s Law):对于一个程序进行优化之后,处理器并行运算之后效率提升的情况。
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
在“摩尔定律”和“并行计算”之外,在整个计算机组成层面,还有这样几个原则性的性能提升方法。
- 加速大概率事件。最典型的就是,过去几年流行的深度学习,整个计算过程中,99% 都是向量和矩阵计算,于是,工程师们通过用 GPU 替代 CPU,大幅度提升了深度学习的模型训练过程。
- 通过流水线提高性能。我们把 CPU 指令执行的过程进行拆分,细化运行,也是现代 CPU 在主频没有办法提升那么多的情况下,性能仍然可以得到提升的重要原因之一。
- 通过预测提高性能。通过预先猜测下一步该干什么,而不是等上一步运行的结果,提前进行运算,也是让程序跑得更快一点的办法。“分支和冒险”、“局部性原理”这些 CPU 和存储系统设计方法,其实都是在利用我们对于未来的“预测”,提前进行相应的操作,来提升我们的程序性能。