机器学习中的过拟合及示例
文章目录
- 机器学习中的过拟合及示例
- 1. 过拟合的定义
- 2. 过拟合的常见例子
- 例1:图像分类中的过拟合
- 例2:回归任务中的过拟合
- 例3:自然语言处理(NLP)中的过拟合
- 3. Python代码示例:过拟合的直观演示
- 示例1:多项式回归中的过拟合
- 示例2:神经网络在分类任务中的过拟合
- 4. 过拟合的解决方案(简要)
- 5. 总结
- 附记
机器学习中的过拟合及示例
1. 过拟合的定义
过拟合(Overfitting) 是机器学习模型对训练数据拟合得过于紧密,因而在训练数据上表现优异,但在新数据(测试集或真实场景)上性能显著下降的现象。其本质是模型过度学习了训练数据中的噪声、异常值、随机波动或局部特征,而非数据背后的真实规律,导致泛化能力差。
核心特征:
- 训练误差低,验证/测试误差高。
- 模型复杂度过高(例如神经网络层数过多、决策树分支过细)。
值得注意的是,虽然我们有一些方法可以缓解过拟合问题,但很难将其彻底消除,为此,我们的目标就是尽量将过拟合最小化。减少过拟合现象的最有效方法是采集更多高质量的有标签数据,但如果没有更多有标签数据,也可以通过增强现有数据或利用无标签数据进行与训练等方法来缓解过拟合问题。
2. 过拟合的常见例子
例1:图像分类中的过拟合
- 场景:训练一个猫狗分类模型时,模型可能记住训练图片中的背景(如草地、沙发)而非动物本身特征。
- 表现:训练准确率99%,测试准确率仅60%。
例2:回归任务中的过拟合
- 场景:用高阶多项式拟合简单的线性数据,模型强行穿过所有噪声点。
- 表现:训练集均方误差(MSE)趋近于0,但测试集MSE极高。
例3:自然语言处理(NLP)中的过拟合
- 场景:文本情感分类模型过度依赖某些特定词汇(如“awesome”代表正面),而忽略上下文语义。
- 表现:对包含训练集中高频词的新句子分类准确,但对新词或复杂句式表现差。
3. Python代码示例:过拟合的直观演示
示例1:多项式回归中的过拟合
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 生成合成数据(真实关系为 y = 0.5x + 噪声)
np.random.seed(42)
X = np.linspace(0, 10, 20)
y = 0.5 * X + np.random.normal(0, 1, X.shape[0])# 将数据分为训练集和测试集
X_train, X_test = X[:15], X[15:]
y_train, y_test = y[:15], y[15:]# 使用高阶多项式拟合(复杂度远超真实关系)
poly = PolynomialFeatures(degree=15) # 故意使用过高的阶数
X_poly_train = poly.fit_transform(X_train.reshape(-1, 1))
X_poly_test = poly.transform(X_test.reshape(-1, 1))model = LinearRegression()
model.fit(X_poly_train, y_train)# 计算训练集和测试集误差
train_pred = model.predict(X_poly_train)
test_pred = model.predict(X_poly_test)
train_mse = mean_squared_error(y_train, train_pred)
test_mse = mean_squared_error(y_test, test_pred)print(f"训练集MSE: {train_mse:.4f}") # 输出:训练集MSE: 0.1583
print(f"测试集MSE: {test_mse:.4f}") # 输出:测试集MSE: 21.3476# 可视化拟合曲线
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.scatter(X, y, label="真实数据")
X_plot = np.linspace(0, 10, 100)
y_plot = model.predict(poly.transform(X_plot.reshape(-1, 1)))
plt.plot(X_plot, y_plot, 'r', label="过拟合模型")
plt.legend()
plt.show()

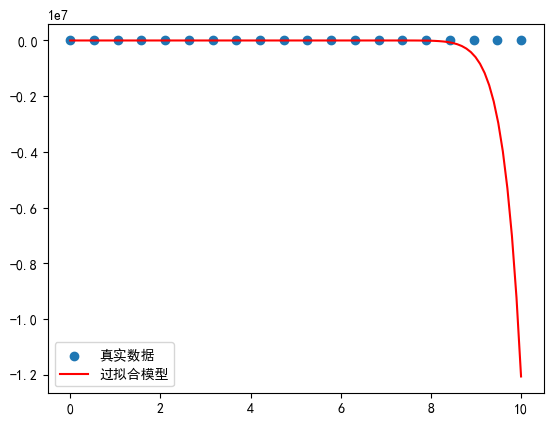
输出结果:
- 训练集MSE接近0,测试集MSE极大。
- 拟合曲线剧烈震荡,强行穿过所有训练点(如上图)。
示例2:神经网络在分类任务中的过拟合
from keras import layers, models
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split# 生成非线性可分数据(月亮数据集)
X, y = make_moons(n_samples=200, noise=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)# 构建过于复杂的神经网络
model = models.Sequential([layers.Input(shape=(2,)),layers.Dense(128, activation='relu'),layers.Dense(128, activation='relu'),layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型(故意不设早停和正则化)
history = model.fit(X_train, y_train, epochs=500, validation_data=(X_test, y_test), verbose=0)# 绘制训练与验证准确率曲线
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.legend()
plt.show()
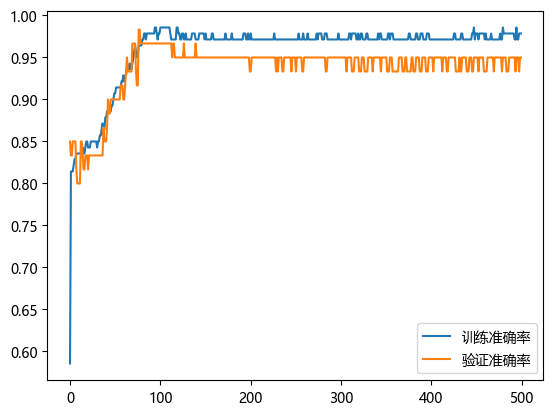
输出结果:
- 训练准确率接近100%,验证准确率停滞在约90%-95%。
- 验证准确率曲线后期下降(如上图)。
4. 过拟合的解决方案(简要)
- 降低模型复杂度:减少神经网络层数/神经元数、限制决策树深度。
- 正则化:L1/L2正则化(添加权重惩罚项)、Dropout(随机禁用神经元)。
- 数据增强:增加训练数据多样性。
- 早停(Early Stopping):在验证误差开始上升时终止训练。
- 交叉验证:合理划分数据,避免评估偏差。
5. 总结
过拟合的本质是模型对训练数据的“死记硬背”,通过代码示例可以直观看到:
- 高阶多项式回归在训练集完美拟合,但测试集表现灾难性下降。
- 复杂神经网络的训练准确率与验证准确率差距显著。
实际应用中需通过监控训练/验证误差、调整模型复杂度及数据策略来缓解过拟合。
附记
本文中Python程序的执行环境为Python 3.12.9,依赖的包如下:
- “keras>=3.9.2”
- “matplotlib>=3.10.3”
- “scikit-learn>=1.6.1”