【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库
二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人
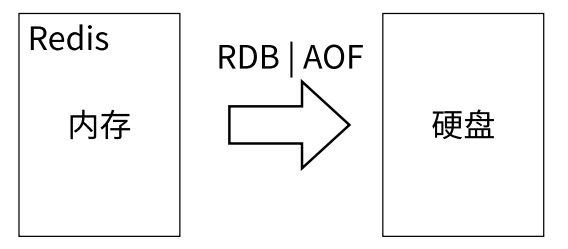
Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时,内存中的数据不会 “丢失”
三、特性
1、速度快
最主要原因:Redis 的所有数据都是存放在内存中的,所以它的读写性能非常惊人
Redis 使用了单线程,预防了多线程可能产生的竞争问题,减少了不必要的线程之间的竞争开销
Redis 后来引入了多线程机制,但主要也是在处理网络和 IO,不涉及到数据命令,即命令的执行仍然采用了单线程模式
对比:多线程提高效率的前提:CPU 密集型的任务,使用多个线程可以充分利用 CPU 多核资源。但 Redis 的核心任务是操作内存的数据结构,不会吃很多 CPU。如果此时选择多线程,多核资源也用不上,因为单个核心的处理速度已经很快了,不仅没有明显的提升,同时还要考虑线程安全、加锁(一旦竞争就会阻塞,阻塞又会涉及到什么时候唤醒)
从网络的角度上,Redis 使用了 IO 多路复用的方式(epoll),使用一个线程管理多个 socket
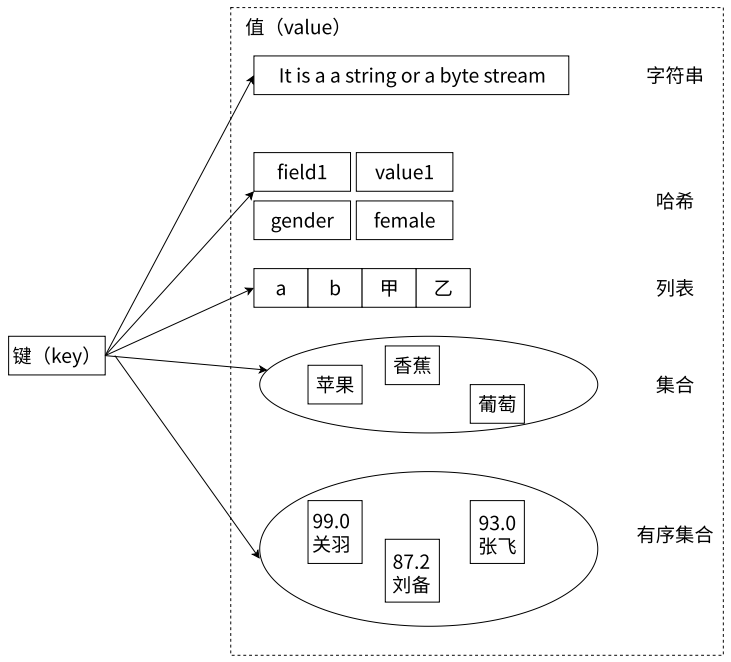
2、基于键值对的数据结构服务器
与很多键值对数据库不同的是,Redis 中的值不仅可以是字符串,而且还可以是具体的数据结构,这样便于在许多应用场景的开发,同时也能提高开发效率
Redis 的全称是 REmote Dictionary Server,它主要提供了 5 种数据结构:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(ordered set / zet),同时在字符串的基础之上演变出了位图(Bitmaps)和 HyperLogLog 两种神奇的 “数据结构”,并且随着 LBS(基于位置服务)的不断发展,Redis 3.2. 版本种加入有关 GEO(地理信息定位)的功能
3、丰富的功能
- 键过期功能,可以用来实现缓存
- 发布订阅功能,可以用来实现消息系统
- 支持 Lua 脚本功能,可以利用 Lua 创造出新的 Redis 命令
- 简单的事务功能,能在⼀定程度上保证事务特性
- 流水线(Pipeline)功能,这样客户端能将一批命令一次性传到 Redis,减少网络的开销
4、简单稳定
Redis 的简单主要表现在 3 个方面
- Redis 的源码很少,相对于很多 NoSQL 数据库来说代码量相对要少很多
- Redis 使用单线程模型,这样不仅使得 Redis 服务端处理模型变得简单,而且也使得客户端开发变得简单
- Redis 不需要依赖于操作系统中的类库,Redis 自己实现了事件处理的相关功能
Redis 具备相当的稳定性,在大量使用过程中,很少出现因为 Redis 自身 BUG 而导致宕掉的情况
5、客户端语言多(扩展能力,Extensibility)
Redis 提供了简单的 TCP 通信协议,很多编程语言可以很方便地接入到 Redis
可以在 Redis 原有的功能基础上再进行扩展。Redis 提供了一组 API,通过 C、C++、Rust 这几个语言编写 Redis 扩展(本质上就是一个动态链接库),让 Redis 支持更多的数据结构,以及支持更多的命令
6、持久化(Persistence)
将数据放在内存中是不安全的(易失),一旦发生断电或者机器故障,重要的数据可能就会丢失,因此 Redis 提供了 2 种持久化方式
- RDB
- AOF
可以用两种策略将内存的数据保存到硬盘中(内存为主、硬盘为辅,硬盘相当于对内存中的数据进行了备份),就保证了数据的可持久性。如果 Redis 重启,那么就会在重启时加载硬盘中的备份数据,使 Redis 的内存恢复到重启前的状态
- Redis 内存到硬盘的持久化
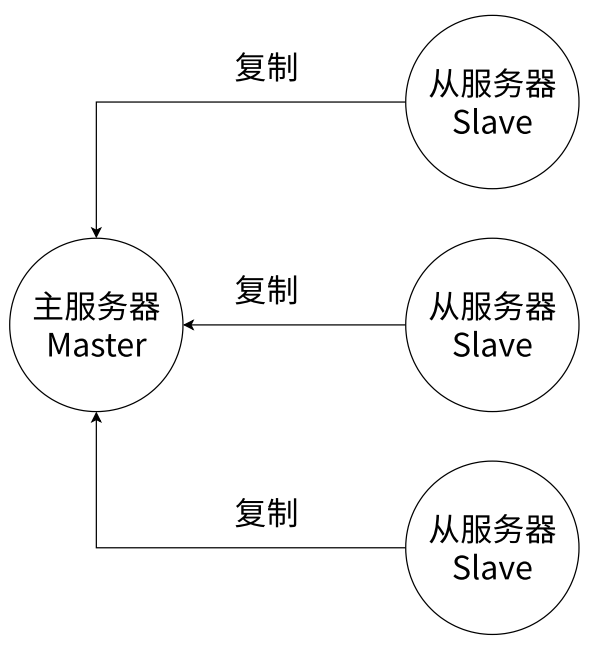
7、主从复制(Replication)
Redis 提供了复制功能,实现了多个相同数据的 Redis 副本(Replica),复制功能是分布式 Redis 的基础
Redis 主从复制架构:
8、高可用(High Availability)和分布式(Distributed)
Redis 提供了高可用实现的 Redis 哨兵(Redis Sentinel),能够保证 Redis 节点的故障发现和故障自动转移,也提供了 Redis 集群(Redis Cluster),是真正的分布式实现,提供了高可用、读写和容量的扩展性
Redis 自身也是支持 “主从” 结构的,从节点就相当于主节点的备份
9、可编程的 / 编程能力(Programmability)
针对 Redis 的操作,可以直接通过简单的交互式命令进行操作,也可以通过脚本的方式批量执行一些操作
10、集群(Clustering)
Redis 作为一个分布式系统的中间件,能够支持集群是非常关键的
这个水平扩展类似于 “分库分表”。一个 Redis 能够存储的数据是有限的(内存空间有限),如果想存储更多数据,就需要引入多个主机,部署多个 Redis 节点,每个 Redis 存储数据的一部分
四、主要应用场景
1、Redis 可以做什么
(1)缓存(Cache)& 会话(Session)
合理地使用缓存不仅可以加速数据的访问速度,还能够有效地降低后端数据源的压力。Redis 提供了键值过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策略。一个合理的缓存设计能够为一个网站的稳定保驾护航
之前 session 是存储在应用服务器上的,现在变成了分布式系统,引入了负载均衡
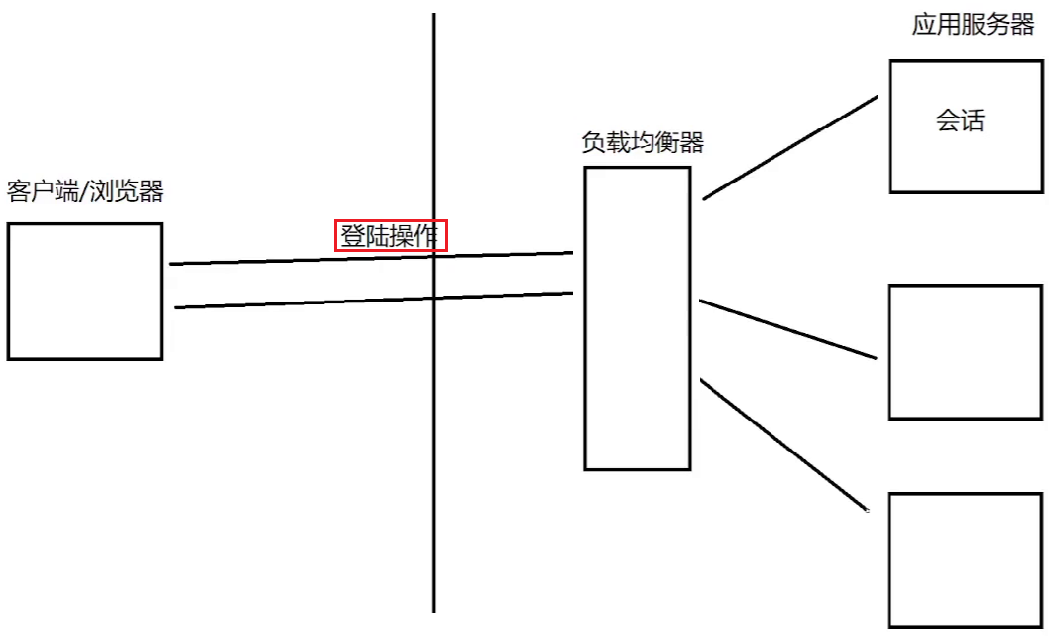
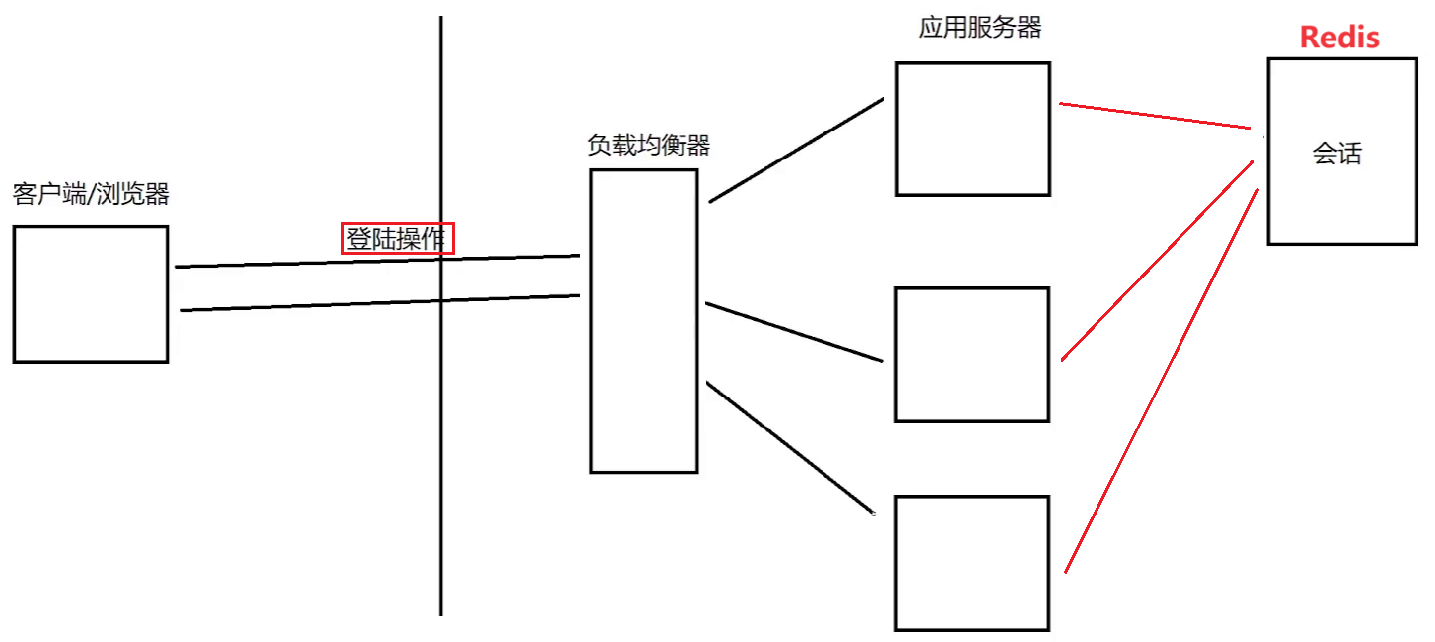
想办法让负载均衡器把同一个用户的请求始终打到同一个机器上,不能再采用轮询了,而是要通过 userId 之类的方式来分配机器
把会话数据单独拎出来,放到一组独立的机器上进行存储(Redis,把应用程序重启,会话也不会丢失,就算丢失了可以让用户重新登录)
(2)排行榜系统
例如按照热度排名的排行榜,按照发布时间的排行榜,按照各种复杂维度计算出的排行榜。Redis 提供了列表和有序集合的结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统
(3)计数器应用
计数器在网站中的作用至关重要
例如视频网站有播放数、浏览数,为了保证数据的实时性,每一次播放和浏览都要做 +1 的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis 天然支持计数功能,而且计数的性能也非常好,可以说是计数器系统的重要选择
(4)社交网络
由于社交网站访问量通常比较大,而且传统的关系型数据不太合适保存这种类型的数据,Redis 提供的数据结构可以相对比较容易地实现这些功能
(5)消息队列(服务器)系统(Streaming & Messaging)
消息队列系统可以说是⼀个大型网站的必备基础组件,因为其具有业务解耦、非实时业务削峰等特性。基于这个可以实现一个网络版本的生产者消费者模型。对于分布式系统来说,服务器和服务器之间有时也需要使用到生产者消费者模型
优势:
- 解耦合
- 削峰填谷
Redis 提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列比还不足够强大,但对于一般的消息队列功能基本可以满足
2、Redis 不可以做什么(可以站在数据规模和数据冷热的角度来进行分析)
- 站在数据规模的角度看,数据可以分为大规模数据和小规模数据。Redis 的数据是存放在内存中的,虽然现在内存已经足够便宜,但如果数据量非常大,使用 Redis 来存储的话,经济成本相当高
- 站在数据冷热的角度,数据分为热数据和冷数据。热数据通常是指需要频繁操作的数据,反之为冷数据。例如对于视频网站来说,视频基本信息基本上在各个业务线都是经常要操作的数据,而用户的观看记录不⼀定是经常需要访问的数据。这里暂且不讨论两者数据规模的差异,单纯站在数据冷热的角度上看,视频信息属于热数据,用户观看记录属于冷数据。如果将这些冷数据放在 Redis 上,基本上是对于内存的⼀种浪费,但是对于一些热数据可以放在 Redis 中加速读写,也可以减轻后端存储的负载,可以说是事半功倍
- 将热数据放在 Redis 中存储,而将冷数据用 MySQL 来存储
很多领域都涉及到 “二八原则”:20% 的热数据能满足 80% 访问需求(系统的复杂程度大大提升,如果数据发生修改,还会涉及到 Redis 和 MySQL 之间的数据同步问题)
五、Redis 客户端与服务端的交互过程
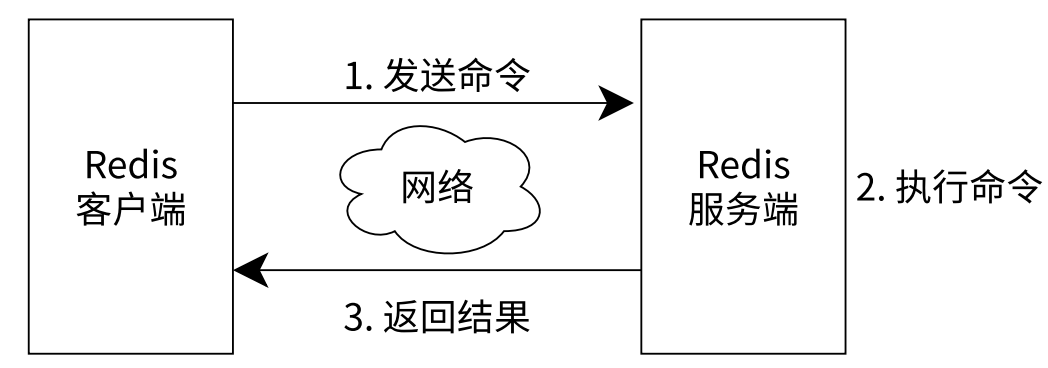
六、常见数据类型
1、最核心的两个命令
- Redis 是按照键值对的方式存储数据的
- get:根据 key 来取 value
- 如果当前的 key 不存在,会返回 nil
- nil 和 null / NULL 是一个意思
- 如果当前的 key 不存在,会返回 nil
- set:把 key 和 value 存储进去
- get:根据 key 来取 value
- key 和 value 本质上都是字符串
- key value 不需要加上引号就是代表字符串的类型,加上也是可以的(单引号或双引号)
2、基本全局命令
- Redis 有 5 种数据结构,都是键值对中的值,对于键来说有一些通用的命令(能够搭配任意一个数据结构来使用的命令),叫作全局命令
- KEYS
- 用来查询当前服务器上匹配的 key。通过一些特殊符号(通配符)来描述 key 的模样,匹配上述模样的 key 就能被查询出来
- 支持如下统配样式
- ? 匹配任意一个字符
- * 匹配 0 个或者多个任意字符
- h[ae]llo 匹配 hello 和 hallo 但不匹配 hillo(只能匹配到a、e,其它的不行,相当于给出固定选项)
- [^e] 排除 e,只有 e 匹配不了,其它的都能匹配
- [a-b] 匹配 a~b 这个范围内的字符,包含两侧边界
- 语法
- KEYS pattern
- pattern 表示包含特殊符号的字符串
- KEYS pattern
- 时间复杂度
- O(N)
- 在生产环境上,一般都会禁止使用 keys 命令,尤其是 keys *
- 生产环境上的 key 可能非常多,而 Redis 是一个单线程的服务器,那么执行 keys * 的时间非常长,就会使 Redis 服务器被阻塞了,而无法给其他客户端提供服务
- 返回值
- 返回所有满足样式的 key
- EXISTS
- 判断某个 key 是否存在,也可以一次判断多个
- Redis 支持很多数据结构,指的是这些键值对是通过哈希表的方式来组织的,具体的某个值又可以是一些数据结构
- 语法
- EXISTS key [key ...]
- 时间复杂度
- O(1)
- Redis 组织这些 key 是按照哈希表的方式组织的
- 返回值
- key 存在的个数
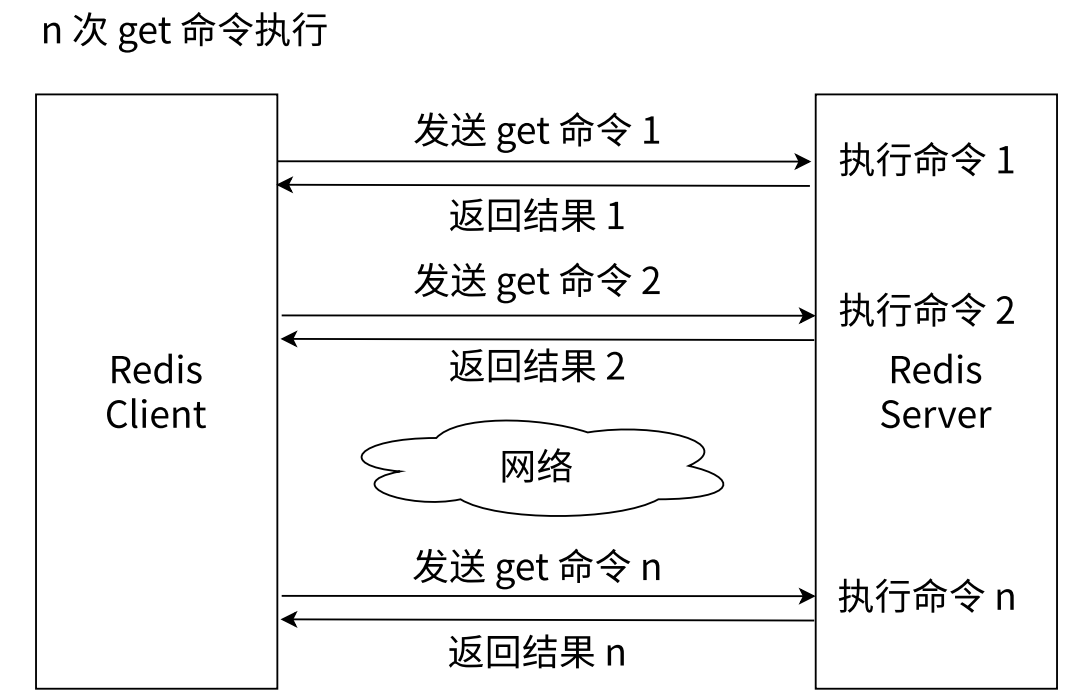
-

- Redis 是一个客户端服务器结构的程序,客户端和服务器之间通过网络来进行通信
- 蓝色框(一次请求和一次响应)
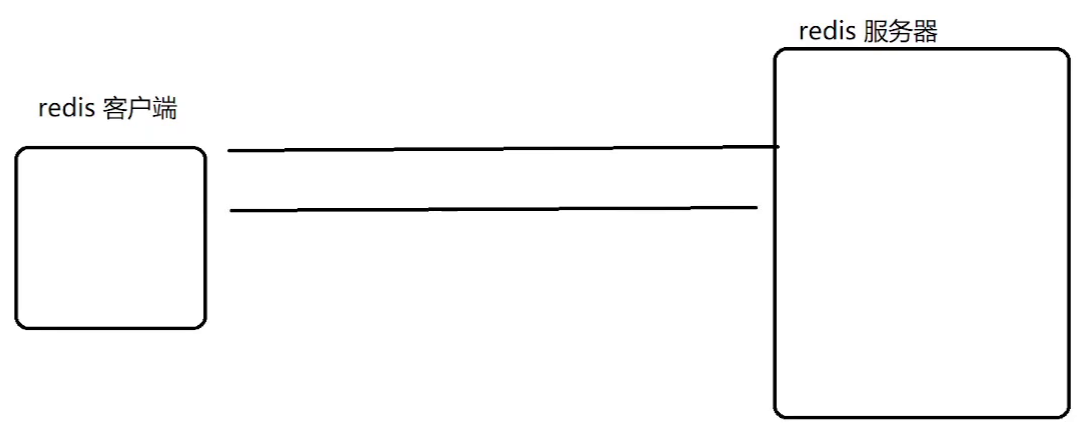
- 红色框(一次请求和一次响应 + 一次请求和一次响应,四次网络通信,即 2 个轮次)
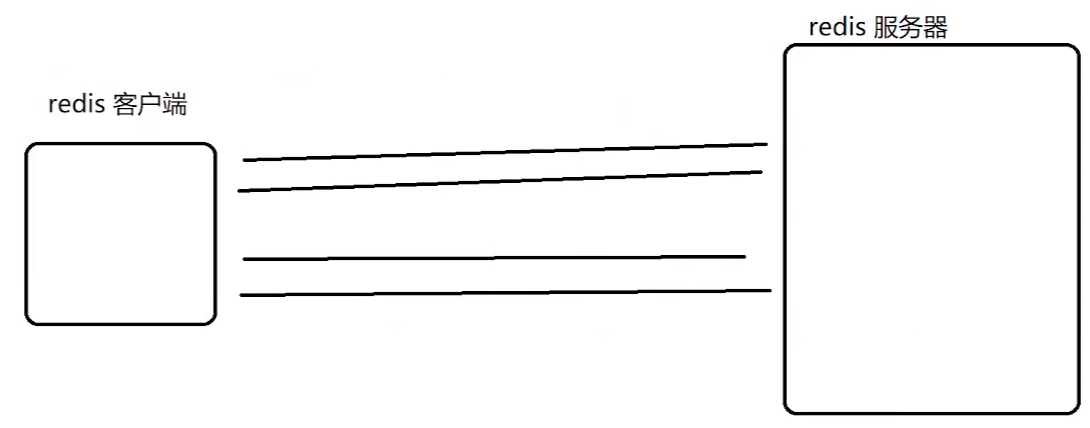
- 分开写会产生更多轮次的网络通信(效率低、成本高,和直接操作内存比)
- DEL
- 删除指定的 key
- 假设 Redis 存的只是一个热点数据,全量数据在 MySQL 中。此时如果删除了 Redis 的几个 key,一般问题不大,但如果把 Redis 中一大半甚至全部数据删了,那么影响就很大。所以相比之下,MySQL 误删了一个数据,可能影响就很大
- 如果把 Redis 作为数据库,此时误删数据的影响也很大
- 如果是把 Redis 作为消息队列 mq,此时误删数据的影响就应该根据具体问题来具体分析
- 语法
- DEL key [key ...]
- 时间复杂度
- O(1)
- 返回值
- 删除掉的 key 的个数
- EXPIRE
- 为指定的 key(key 已存在,否则设置失败)添加秒级的过期时间(Time To Live,TTL)
- PEXPIRE(毫秒级)
- key 的存活时间超出这个指定值就会被自动删除
- 业务场景举例
- 手机发送验证码(60s)
- 外卖优惠券(7天)
- 基于 Redis 实现的分布式锁(给 Redis 写一个特殊的 key value,删除就是解锁。为了避免出现不能正确解锁的情况,通常都会在加锁时设置过期时间)
- 业务场景举例
- 语法
- EXPIRE key seconds
- 时间复杂度
- O(1)
- 返回值
- 1 表示设置成功,0 表示设置失败
- TTL
- 获取指定 key 的过期时间,秒级
- IP 协议报头中有一个字段:TTL,但它是用次数来衡量过期的
- 语法
- TTL key
- 时间复杂度
- O(1)
- 返回值
- 剩余过期时间。-1 表示没有关联过期时间,-2 表示 key 不存在
- 键的过期机制
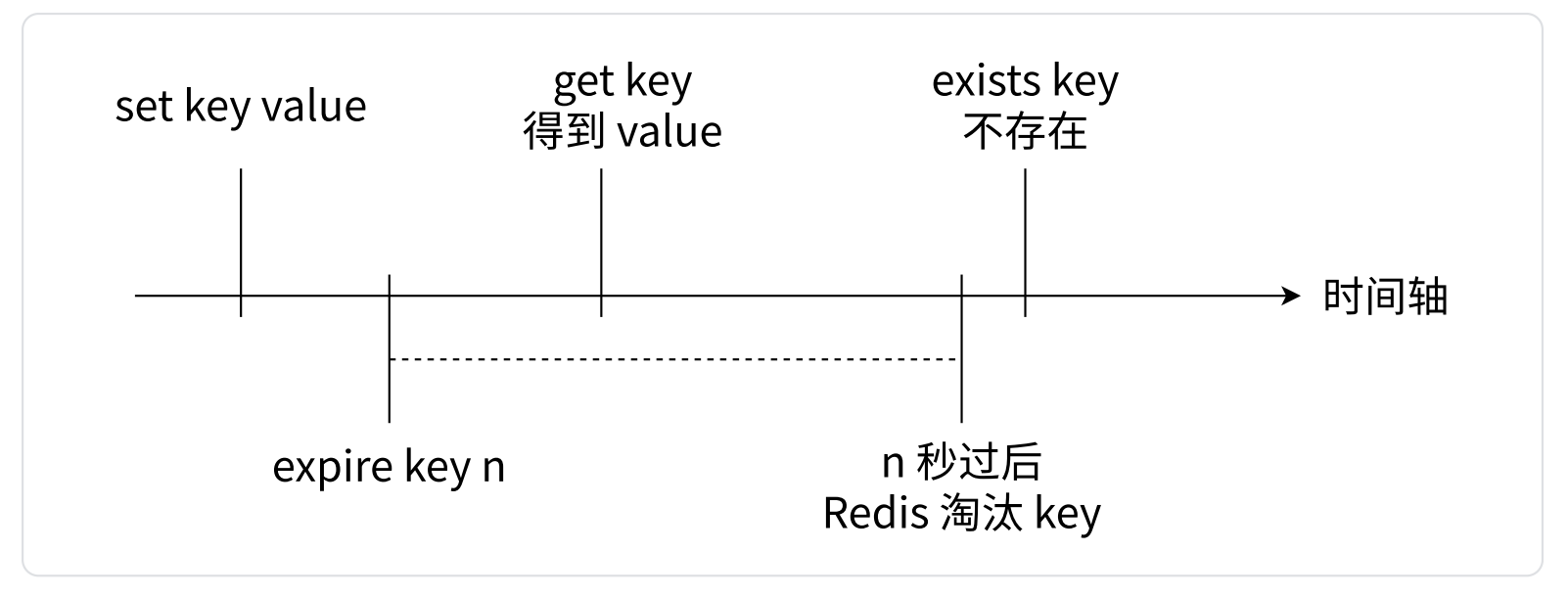
- EXPIRE 和 TTL 命令都有对应的支持毫秒为单位的版本:PEXPIRE 和 PTTL
- Redis 的 key 的过期策略是如何实现的?
- 一个 Redis 中可能同时存在很多 key,这些 key 中可能有很大一部分都有过期时间,那么此时 Redis 如何知道哪些 key 已经过期要被删除,哪些 key 还没过期呢?如果直接遍历所有 key 显然是不行的,效率非常低
- Redis 整体的策略
- 定期删除:每次抽取一部分进行验证过期时间,保证这个抽取检查的过程足够快
- 为什么这里对于定期删除的时间有明确的要求呢?
- 因为 Redis 是单线程程序,它的主要任务:处理每个命令的任务、扫描过期的 key 等等,如果扫描过期 key 消耗的时间太多,那么正常处理请求命令就被阻塞了(产生了类似于执行 keys * 这样的效果)
- 虽然有上面讲到的两种策略结合,但整体结果一般,仍然可能会有很多过期的 key 被残留,没有及时删除掉
- Redis 为了对上述进行补充,还提供了一系列的内存淘汰策略
- 如果有多个 key 过期,也可以通过一个定时器(基于优先级队列或者时间轮都可以实现比较高效的定时器)来高效 / 节省 CPU 的前提下来处理多个 key。但 Redis 并没有采取定时器的方式来实现过期 key 删除
- 可能是基于定时器实现,就需要引入多线程,但 Redis 的早起版本就奠定了单线程的基调,如果引入多线程就打破了初衷
- 定时器:在某个时间到达之后,执行指定的任务,它是基于优先级队列 / 堆的(一般的队列是先进先出,而优先级队列则是按照指定的优先级(自定义)先出)。在 Redis 过期 key 的场景中,就可以通过 “过期时间越早,就是优先级越高”。此时定时器只需要分配一个线程,不需要遍历所有的 key,只需要让这个线程去检查队首元素,看是否过期即可。如果队首元素还没过期,那么后续元素一定没过期。另外,在扫描线程检查队首元素过期时间时,也不能检查的太频繁,此时可以根据时刻和队首元素的过期时间设置一个等待,当时间差不多到了,系统再唤醒这个线程(可以节省 CPU 的开销)
- 万一在线程休眠时,来了一个新的任务呢?可以在新任务添加时,唤醒刚才的线程,重新检查一下队首元素,再根据时间差距重新调整阻塞时间即可
- 基于时间轮实现的定时器(把时间划分成很多小段,具体划分的粒度看实际需求)
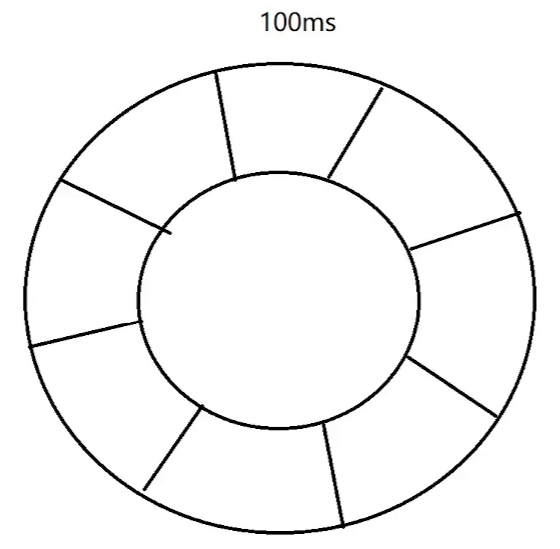
- 每个小段都挂着一个链表,每个链表都代表一个要执行的任务,相当于一个函数指针以及对应的参数
- 假设需要添加一个 key,这个 key 在 300ms 后过期。此时这个指针就会每隔固定的时间间隔(此处约定时 100ms)往后走一个,每次走到一个格子就会把这个格子上链表的任务尝试执行一下
- 对于时间轮来说,每个格子是多少时间,一共有多少个格子都是需要根据实际场景来灵活调配的
- 如果有多个 key 过期,也可以通过一个定时器(基于优先级队列或者时间轮都可以实现比较高效的定时器)来高效 / 节省 CPU 的前提下来处理多个 key。但 Redis 并没有采取定时器的方式来实现过期 key 删除
- 为什么这里对于定期删除的时间有明确的要求呢?
- 惰性删除:假设这个 key 已经到过期时间了,但暂时还没删除,key 还存在,紧接着后面又有一次访问,正好用到了这个 key,于是这次访问就会让 Redis 服务器触发删除 key 的操作,同时再返回一个 nil
- 定期删除:每次抽取一部分进行验证过期时间,保证这个抽取检查的过程足够快
- TYPE
- 返回 key 对应的数据类型
- Redis 所有的 key 都是 string,key 对应的 value 可能会存在多种类型
- 语法
- TYPE key
- 时间复杂度
- O(1)
- 返回值
- none,string,list,set,zset,hash,stream
- Redis 作为消息队列时,使用 stream 作为返回值类型
- type 命令实际返回的就是当前键的数据结构类型,Redis 的 5 种主要的数据类型分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构
-
3、数据结构和内部编码
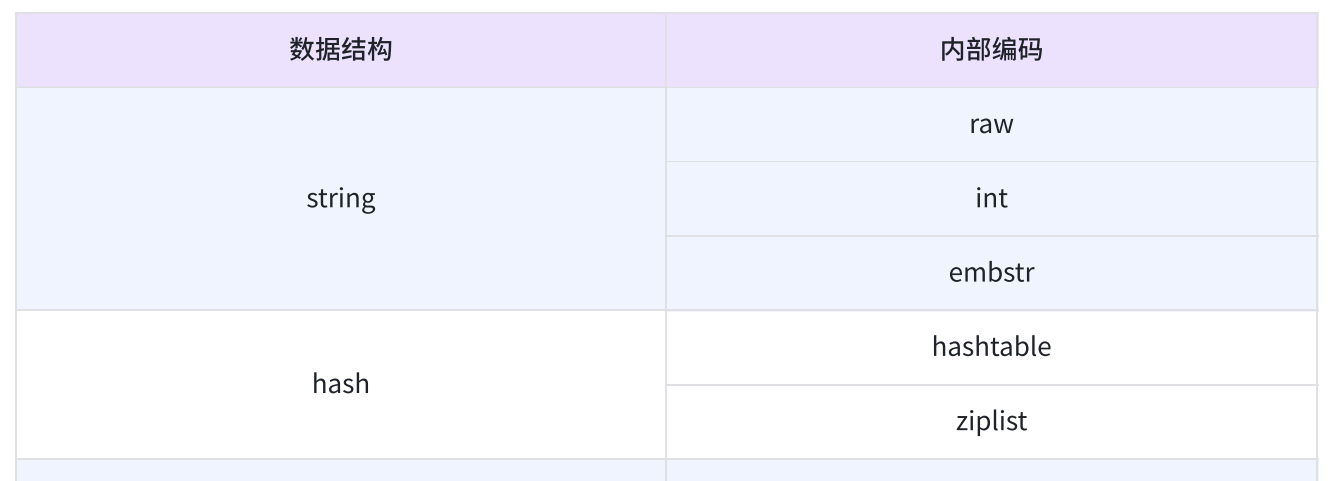
- Redis 底层在实现上述数据结构时,会在源码底层针对上述实现进行特定的优化(内部具体实现的数据结构(编码方式)还会有变数),来达到节省时间 / 空间的效果。实际上 Redis 针对每种数据结构都有自己的底层内部编码实现,且是多种实现,这样 Redis 会在合适的场景选择合适的内部编码
-
- list 后来引入了新的实现方式:quicklist,同时兼顾了 linkedlist 和 ziplist 的优点。quicklist 就是一个链表,每个元素又是一个 ziplist(空间和效率都折中兼顾到),类似于 C++ 中的 std::deque
- 可以看到每种数据结构都有至少 2 种以上的内部编码实现,比如 list 数据结构包含了 linkedlist 和 ziplist 两种内部编码。同时有些内部编码,比如 ziplist,可以作为多种数据结构的内部实现
- 通过 OBJECT ENCODING 命令查询内部编码
- 这样设计有 2 个好处
- 可以改进内部编码,而对外的数据结构和命令没有任何影响,一旦开发出更优秀的内部编码,无需改动外部数据结构和命令
- 多种内部编码实现可以在不同场景下发挥各自优势

4、单线程架构
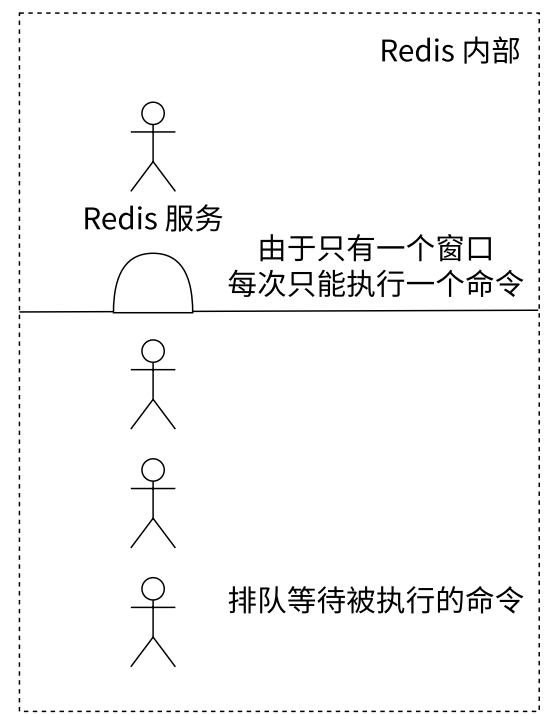
- Redis 使用了单线程架构来实现高性能的内存数据库服务,单线程模型是使用和运维 Redis 的关键
- Redis 只使用一个线程处理所有的命令请求,并不是说一个 Redis 服务器进程内部就只有一个线程,其实也有多个线程,不过是在处理网络 IO
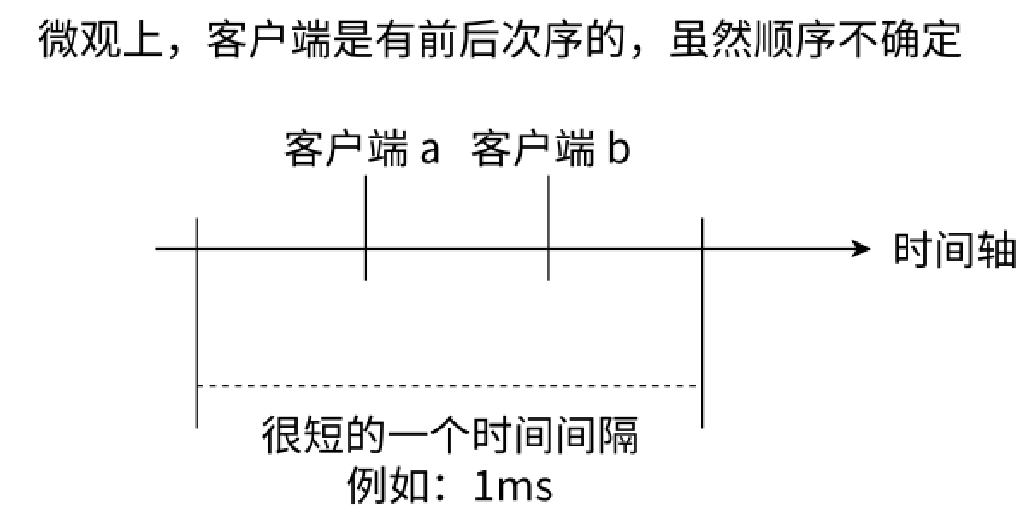
- 虽然多个客户端看起来是同时要求 Redis 去执行命令的,也相当于并发的发起请求。但从微观角度来看,Redis 是串行 / 顺序执行这多个命令的(采用线性方式执行),只是原则上命令的执行顺序是不确定的,但一定不会有多条命令被同步执行
-
- Redis 虽然是单线程模型,但其效率这么高,速度还能这么快的原因(与 MySQL、Oracle、Sql Server 做参照)
- Redis 是纯内存访问,而数据库是访问硬盘。Redis 将所有数据放在内存中,内存的响应时长大约为 100ns,这是 Redis 达到每秒万级别访问的重要基础
- Redis 的核心功能比数据库的核心功能更简单(数据库对于数据的增删改查都有更复杂的功能支持,这样的功能势必要花费更多开销,比如针对插入删除,数据库中的各种约束都会让数据库做额外工作)
- Redis 是单线程模型,避免了线程切换和竞态产生的消耗。Redis 的每个基本操作都是 “短平快” 的,就是简单操作一下内存数据,不是特别消耗 CPU 的操作。即使新增几个线程,提升也不大。单线程可以简化数据结构和算法的实现,让程序模型更简单,也避免了在线程竞争同一份共享数据时带来的切换和等待消耗
- 非阻塞 IO。Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在网络 I/O 上浪费过多时间
- 本质上就是一个线程可以管理多个 socket。针对 TCP 来说,服务器这边每次要服务一个客户端都需要给这个客户端安排一个 socket。假设一个服务器服务多个客户端,同时就会有很多个 socket,但这些 socket 并不是每时每刻都在传输数据,很多情况下,每个客户端和服务器之间的通信并没有那么频繁,此时很多 socket 大部分时间都是静默的,上面是没有数据需要传输的,即同一时刻只有少数 socket 是活跃的
- Redis 使用 I/O 多路复用模型
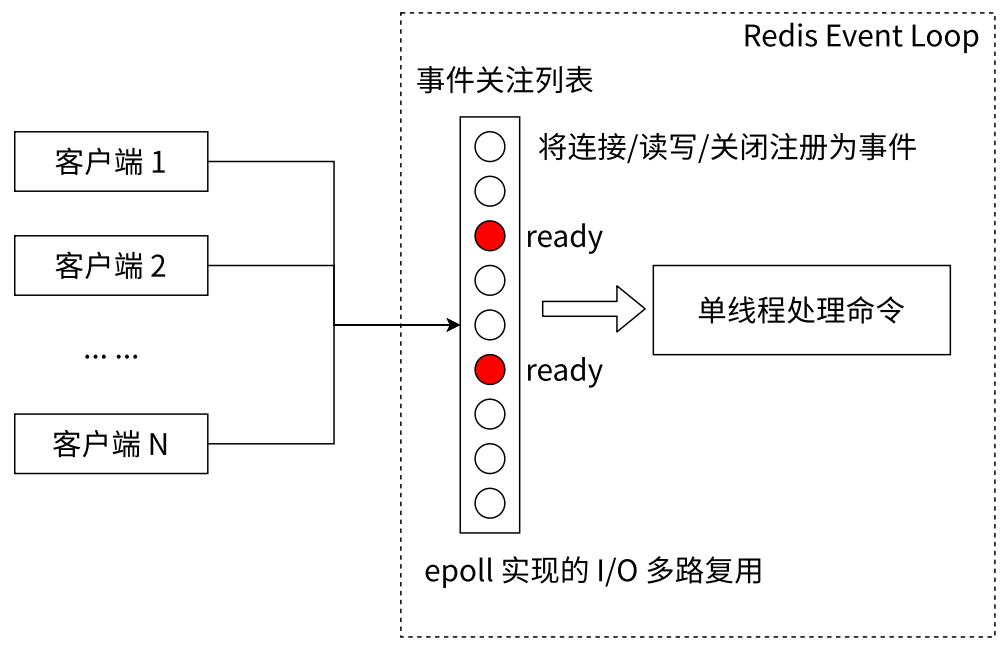
- 虽然单线程给 Redis 带来很多好处,但有一个致命问题:对单个命令的执行时间是有要求的。如果某个命令执行过长,会导致其它命令都处于等待队列中,迟迟等不到响应,从而造成客户端阻塞,对于 Redis 这种高性能的服务来说是非常严重的,所以 Redis 是面向快速执行场景的数据库
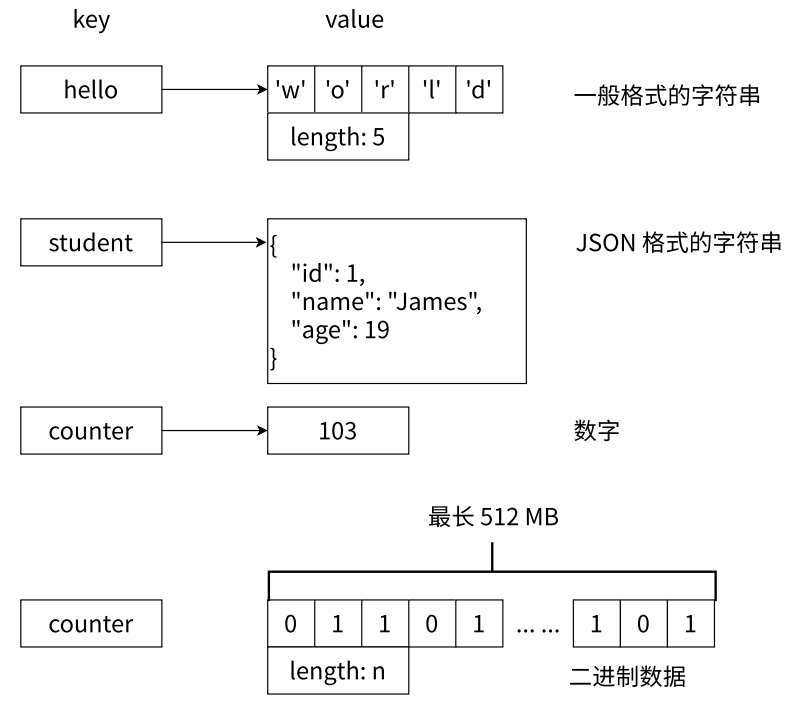
5、String 字符串
- Redis 中所有键的类型都是字符串类型,且其它几种数据结构也都是在字符串类似基础上构建的,例如列表和集合的元素类型是字符串类型
- 字符串类型的值可以是字符串,包含一般格式的字符串或者类似 JSON、XML 格式的字符串;数字可以是整型或者浮点型;甚至是二进制流数据,例如图片、⾳频、视频等。不过一个字符串的最大值不能超过 512 MB
- 由于 Redis 内部存储字符串完全是按照二进制流的形式保存的,所以 Redis 是不处理字符集编码问题的,客户端传入的命令中使用什么字符集编码,就存储什么字符集编码
- 字符串数据类型
-
- 常见命令
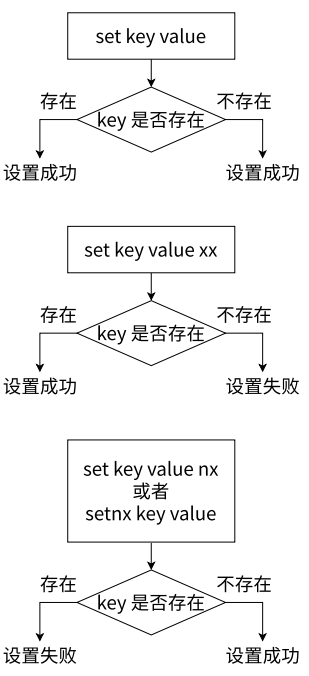
- SET
- 将 string 类型的 value 设置到 key 中。如果 key 之前存在则覆盖,无论原来的数据类型是什么,之前关于此 key 的 TTL 也全部失效
- 语法
- SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
- 时间复杂度
- O(1)
- SET 命令支持多种选项来影响它的行为(选项)
- EX seconds —— 使用秒作为单位设置 key 的过期时间
- PX milliseconds —— 使用毫秒作为单位设置 key 的过期时间
- NX —— 只在 key 不存在时才进行设置,创建新的键值对,即如果 key 之前已经存在,设置不执行
- XX —— 只在 key 存在时才进行设置,让新的 value 覆盖旧的 value,可能会改变原来的数据类型,即如果 key 之前不存在,设置不执行
- 返回值
- 如果设置成功,返回 OK
- 如果由于 SET 指定了 NX 或者 XX 但条件不满足,SET 不会执行,并返回 (nil)
- FLUSHALL:清空所有数据(类似于 MySQL 里的 drop database)
- GET
- 获取 key 对应的 value
- 只支持字符串类型的 value,如果是其它类型,那么使用 GET 获取就会出错
- 语法
- GET key
- 时间复杂度
- O(1)
- 返回值
- key 对应的 value,当 key 不存在则返回 nil
- MSET
- 一次性设置多个 key 的值
- 语法
- MSET key value [key value ...]
- 时间复杂度
- O(N),N 是 key 数量
- 返回值
- 永远是 OK
- MGET
- 一次性获取多个 key 的值。如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil
- 语法
- MGET key [key ...]
- 时间复杂度
- O(N) N 是 key 数量
- 返回值
- 对应 value 的列表
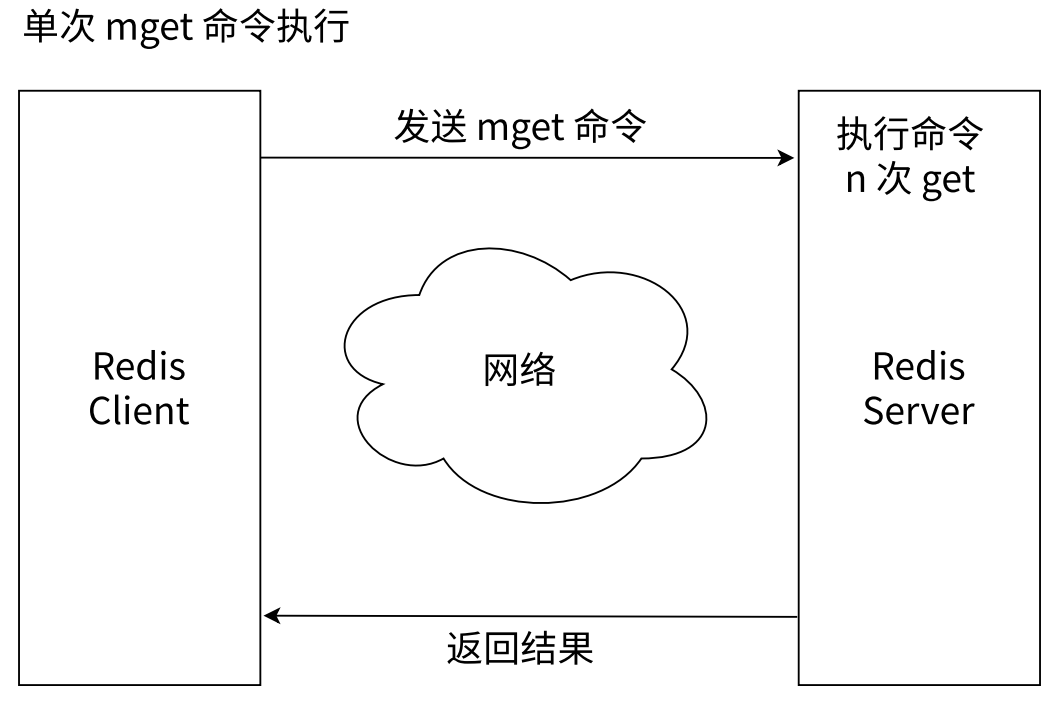
- 多次 get VS 单次 mget
-
- 使用 mget / mset 由于可以有效地减少了网络时间,所以性能相较更高
- 使用批量操作可以有效提高业务处理效率,但要注意每次批量操作所发送的键的数量不是无节制的,否则可能造成单一命令执行时间过长,导致 Redis 阻塞
- SETNX
- 设置 key-value,但只允许在 key 之前不存在的情况下
- 语法
- SETNX key value
- 时间复杂度
- O(1)
- 返回值
- 1 表示设置成功,0 表示没有设置
- SET、SET NX 和 SET XX 执行流程
-
- SET
- 计数命令
- INCR
- 将 key 对应的 string 表示的数字 +1。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型则报错
- 语法
- INCR key
- 时间复杂度
- O(1)
- 返回值
- integer 类型的加完后的数值
- INCRBY
- 将 key 对应的 string 表示的数字加上对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过 64 位有符号整型则报错
- 语法
- INCRBY key decrement
- 时间复杂度
- O(1)
- 返回值
- integer 类型加完后的数值
- DECR
- 将 key 对应的 string 表示的数字 -1。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型则报错,运算结果也是计算后的值
- 语法
- DECR key
- 时间复杂度
- O(1)
- 返回值
- integer 类型的减完后的数值
- DECYBY
- 将 key 对应的 string 表示的数字减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型则报错
- 语法
- DECRBY key decrement
- 时间复杂度
- O(1)
- 返回值
- integer 类型的减完后的数值
- INCRBYFLOAT
- 将 key 对应的 string 表示的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的不是 string,或者不是一个浮点数则报错。允许采用科学计数法表示浮点数
- 语法
- INCRBYFLOAT key increment
- 时间复杂度
- O(1)
- 返回值
- 加 / 减完后的数值
- 很多存储系统和编程语言内部使用 CAS 机制实现计数功能,会有一定的 CPU 开销,但在 Redis 中完全不存在这个问题,因为 Redis 是单线程架构,任何命令到了 Redis 服务端都要顺序执行
- INCR
- 其他命令
- APPEND
- 如果 key 已经存在且是⼀个 string,命令会将 value 追加到原有 string 的后边。如果 key 不存在,则效果等同于 SET 命令
- 语法
- APPEND KEY VALUE
- 时间复杂度
- O(1),追加的字符串一般长度较短,可以视为 O(1)
- 返回值
- 追加完成后 string 的长度
- append 的返回值长度的单位是字节,Redis 的字符串不会对字符编码做任何处理
- 当前 XShell 终端默认的字符编码是 utf-8,在终端中输入汉字后,也是按照 utf8 编码,一个汉字在 utf8 字符集中通常是 3 个字节
- 在启动 Redis 客户端时,加上 --raw 选项,可以使 Redis 客户端自动把二进制数据尝试翻译
- GETRANGE
- 返回 key 对应的 string 的子串,由 start 和 end 确定(左闭右闭)。可以使用负数表示倒数,-1 代表倒数第一个字符,即下标为 len-1 的元素,-2 代表倒数第二个。超过范围的偏移量会根据 string 的长度调整成正确的值
- 语法
- GETRANGE key start end
- 时间复杂度
- O(N),N 为 [start, end] 区间的长度,由于 string 通常比较短,可以视为是 O(1)
- 返回值
- string 类型的子串
- 如果字符串中保存的是汉字,此时进行子串切分很可能切出来的就不是完整的汉字
- SETRANGE
- 覆盖字符串的一部分,从指定的偏移开始
- 语法
- SETRANGE key offset value
- 时间复杂度
- O(N),N 为 value 的长度,由于一般的 value 比较短,通常视为 O(1)
- 返回值
- 替换后的 string 的长度
- 如果 value 是一个中文字符串,进行 setrange 可能会出问题
- 这里凭空生成了一个字节,这个字节里的内容就是 "0x00",aaa 就被追加到 "0x00" 后面了。setange 针对不存在的 key 也是可以操作的,不过会把 offset 之前的内容填充成 "0x00"
- STRLEN
- 获取 key 对应的 string 的长度。当 key 存放的类型不是 string 时报错
- 语法
- STRLEN key
- 时间复杂度
- O(1)
- 返回值
- string 的长度。如果 key 不存在则返回 0
- 单位是字节
- 在 MySQL 中,varchar(N) 的 N 的单位就是字符,MySQL 中的字符也是完整的汉字,这样的一个字符也可能是多个字节
- APPEND
- 命令小结
- 下表是字符串类型命令的效果、时间复杂度
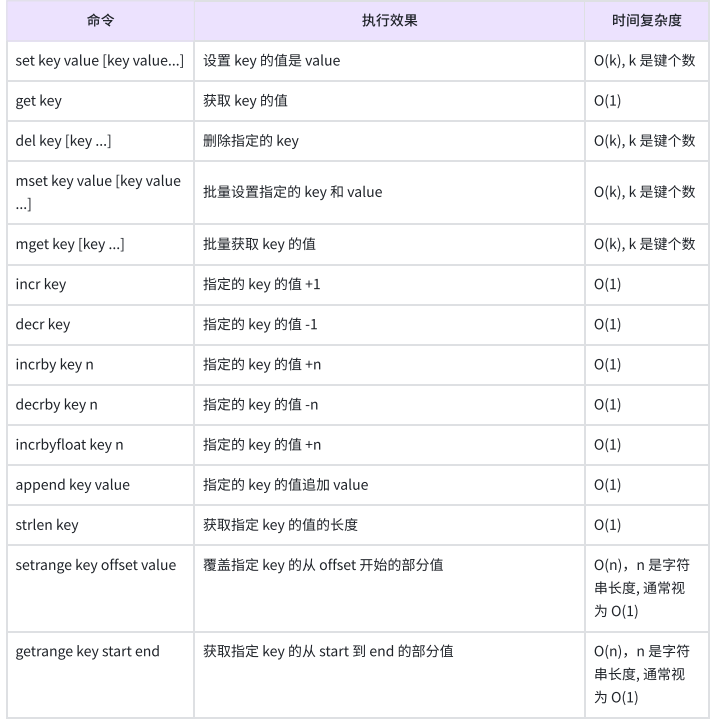
- 下表是字符串类型命令的效果、时间复杂度
- 内部编码
- 字符串类型的内部编码有 3 种
- int:64 位 / 8 个字节的长整型
- embstr:小于等于 39 个字节的字符串,压缩字符串,适用于表示比较短的字符串
- raw:大于 39 个字节的字符串,普通字符串,适用于表示更长的字符串,只是单纯的持有字节数组
- Redis 会根据当前值的类型和长度动态决定使用哪种内部编码实现
- Redis 存储小数,本质上还是当作字符串来存储,这和整数相比差别很大。整数直接使用 int 来存储(准确来说是一个 long long)比较方便进行算术运算。小数则是使用字符串来存储,意味着每次进行算术运算都需要把字符串转成小数来进行运算,然后结果再转回字符串保存
- 字符串类型的内部编码有 3 种
- 典型使用场景
- 缓存(Cache)
- Redis + MySQL 组成的缓存存储架构
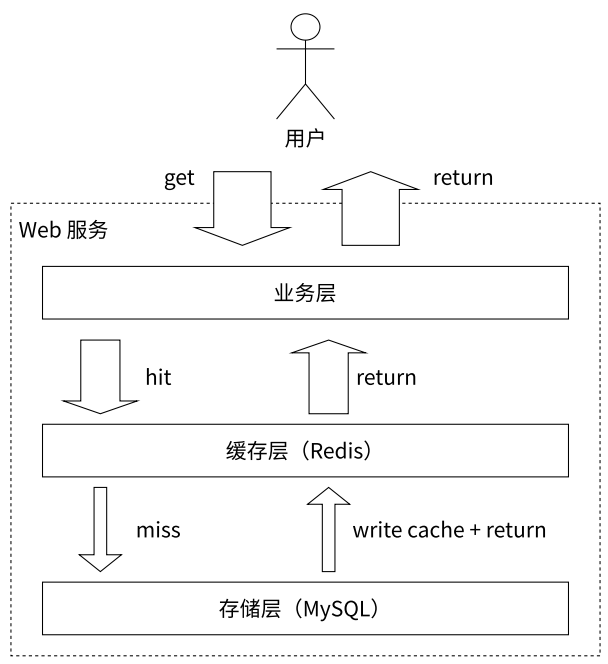
- 其中 Redis 作为缓冲层,MySQL 作为存储层,绝大部分请求数据都是从 Redis 中获取。由于 Redis 具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用
- 整体思路:应用服务器访问数据时,先查询 Redis。如果 Redis 上数据存在,就直接从 Redis 中取出数据交给应用服务器,不继续访问数据库了。如果 Redis 上数据不存在,那么此时再读取 MySQL,把读到的结果返回给应用服务器,同时把这个数据也写入到 Redis 中
- 上述策略存在一个明显问题:随着时间推移,会有越来越多 key 在 Redis 上访问不到,从而从 MySQL 中读取并写入 Redis 了,此时 Redis 中的数据不是会越来越多吗?
- 在把数据写给 Redis 的同时,给这个 key 设置一个过期时间
- Redis 也在内存不足时,提供了淘汰策略
- 通过增加缓存功能,在理想情况下,每个用户信息一个小时期间只会有一次 MySQL 查询,极大提高了查询效率,也降低了 MySQL 的访问数
- 与 MySQL 等关系型数据库不同的是,Redis 没有表、字段这种命名空间,而且也没有对键名有强制要求,除了不能使用一些特殊字符。但设计合理的键名,有利于防止键冲突和项目的可维护性,推荐使用 "业务名:对象名:唯一标识:属性" 作为键名。例如:MySQL 的数据库名为 vs,用户表名为 user_info,那么对应的键可以使用 "vs:user_info:6379"、"vs:user_info:6379:name" 来表示,如果当前 Redis 只会被一个业务使用,则可以省略业务名。如果键名过长,则可以使用团队内部都认同的缩写替代。毕竟键名过长会导致 Redis 的性能明显下降
- Redis + MySQL 组成的缓存存储架构
- 计数(Counter)
- 许多应用都会使用 Redis 作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或落地到其它数据源
- 记录视频播放次数
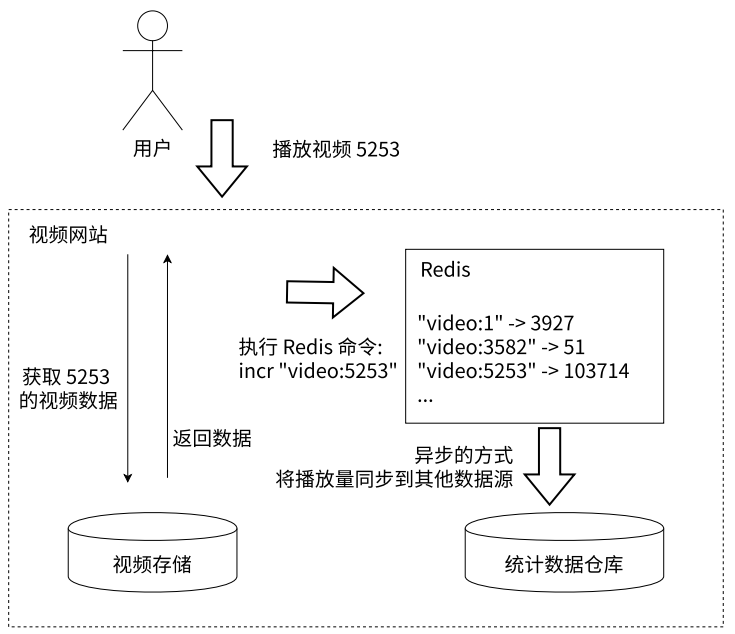
- 写入统计数据仓库(可能是 MySQL,或者是 HDFS)的步骤往往是异步的,所以并不是说来一个播放请求,就必须立马写一个数据
- 共享会话(Session)
- Session 分散存储
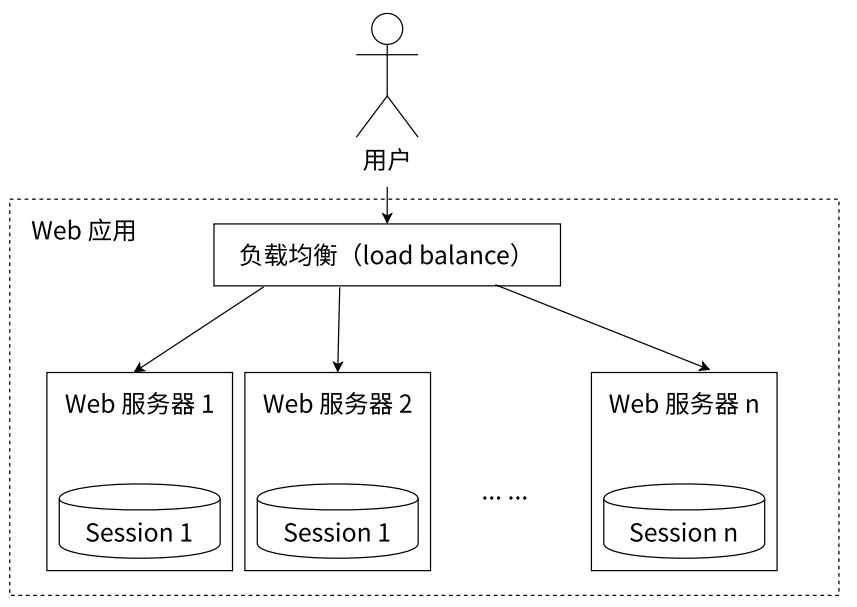
- 一个分布式 Web 服务将用户的 Session 信息(比如用户登录信息)保存在各自的服务器中,但会造成一个问题:出于负载均衡的考虑,分布式服务会将用户的访问请求均衡到不同的服务器上,且通常无法保证用户每次请求都会被均衡到同一台服务器上,当用户刷新一次访问可能需要重新登录,这是用户无法容忍的
- Redis 集中管理 Session
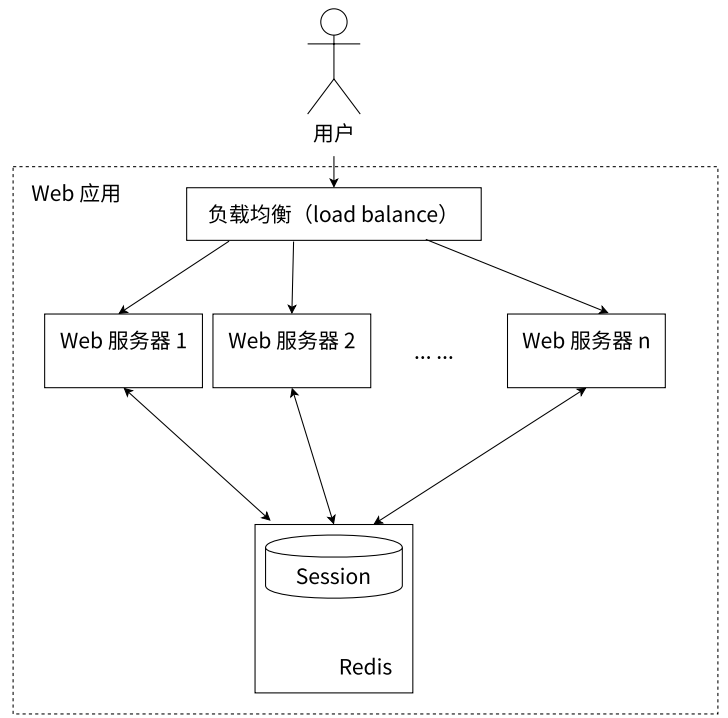
- Session 分散存储
- 缓存(Cache)
6、哈希
- 几乎所有的主流编程语言都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射。在 Redis 中,哈希类型是指值本身又是⼀个键值对结构,形如 key = "key",value = { { field1, value1 }, ..., { fieldN, valueN } }
- Redis 键值对和哈希类型二者的关系
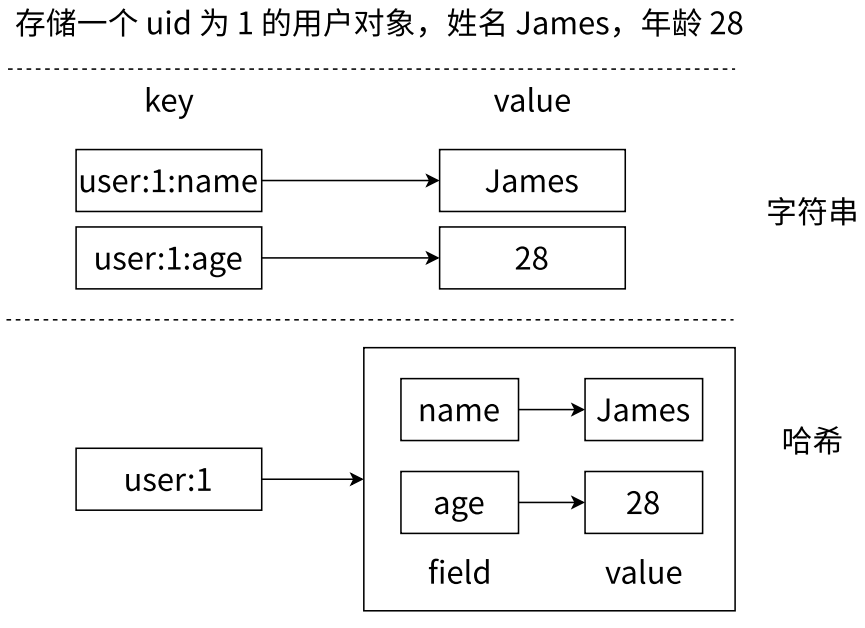
- 哈希类型中的映射关系通常称为 field-value,用于区分 Redis 整体的键值对(key-value),注意这里的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下文的作用
- 命令
- HSET
- 设置 hash 中指定的字段(field)的值(value)
- 语法
- HSET key field value [field value ...]
- 时间复杂度
- 插⼊一组 field 为 O(1),插⼊ N 组 field 为 O(N)
- 返回值
- 添加的字段的个数,也就是设置成功的键值对的个数
- HGET
- 获取 hash 中指定字段的值
- 语法
- HGET key field
- 时间复杂度
- O(1)
- 返回值
- 字段对应的值或者 nil
- HEXISTS
- 判断 hash 中是否有指定的字段
- 语法
- HEXISTS key field
- 时间复杂度
- O(1)
- 返回值
- 1 表示存在,0 表示不存在
- HDEL
- 删除 hash 中指定的字段
- 语法
- HDEL key field [field ...]
- 时间复杂度
- 删除一个元素为 O(1),删除 N 个元素为 O(N)
- 返回值
- 本次操作删除的字段个数
- HKEYS
- 获取 hash 中的所有字段
- 语法
- HKEYS key
- 时间复杂度
- O(N),N 为 field 的个数,当前的 O(N) 可以说成是 O(1)
- 返回值
- 字段列表
- HVALS
- 获取 hash 中的所有的值
- 语法
- HVALS key
- 时间复杂度
- O(N),N 为 field 的个数
- 如果 field(哈希)非常大,那么这个操作就可能导致 Redis 服务器被阻塞住
- 返回值
- 所有的值
- HGETALL
- 获取 hash 中的所有字段以及对应的值
- 这个操作的风险比较大,但多数情况下,不需要查询所有的 field,可能只查其中几个 field
- 语法
- HGETALL key
- 时间复杂度
- O(N),N 为 field 的个数
- 返回值
- 字段和对应的值
- hash 类型没有下标的概念
- HMGET
- 一次获取 hash 中多个字段的值
- 语法
- HMGET key field [field ...]
- 时间复杂度
- 只查询⼀个元素为 O(1),查询多个元素为 O(N) N 为查询元素个数
- 返回值
- 字段对应的值或者 nil
- 多个 value 的顺序和 field 的顺序是匹配的
- 在使用命令 HKEYS,HVALS,HGETALL 完成所有的遍历操作时,都是存在一定风险的,如果 hash 的元素个数太多,执行的耗时就比较长,那么就会存在阻塞 Redis 的可能
- 如果只需要获取部分 field,可以使用 HMGET,如果一定要获取全部 field,可以尝试使用 HSCAN 命令,该命令采用渐进式遍历哈希类型(敲一次命令,遍历一小部分,时间是可控的,连续执行多次就可以完成整个遍历过程)
- 也有 hmset 一次设置多个 field 和 value,但是并不需要使用,因为 hset 已经支持一次设置多个 field 和 value 了
- HLEN
- 获取 hash 中的所有字段的个数
- 语法
- HLEN key
- 时间复杂度
- O(1)
- 返回值
- 字段个数
- HSETNX
- 在字段不存在的情况下,设置 hash 中的字段和值
- 语法
- HSETNX key field value
- 时间复杂度
- O(1)
- 返回值
- 1 表示设置成功,0 表示失败
- HINCRBY
- 将 hash 中字段对应的数值添加指定的值
- 语法
- HINCRBY key field increment
- 时间复杂度
- O(1)
- 返回值
- 该字段变化之后的值
- HINCRBYFLOAT
- HINCRBY 的浮点数版本
- 语法
- HINCRBYFLOAT key field increment
- 时间复杂度
- O(1)
- 返回值
- 该字段变化之后的值
- 小结
- 哈希类型命令的效果、时间复杂度
-
- 哈希类型命令的效果、时间复杂度
- HSET
- 内部编码
- 哈希的内部编码有 2 种
- ziplist(压缩列表)
- 当哈希类型元素个数小于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都小于 hash-max-ziplist-value 配置(默认 64 字节)时(这两个配置项是可以写到 redis.conf 文件中的),Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀
- hashtable(哈希表)
- 当哈希类型无法满足 ziplist 的条件时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为 O(1)
- ziplist(压缩列表)
- 哈希的内部编码有 2 种
- 使用场景
- 关系型数据表保存用户信息
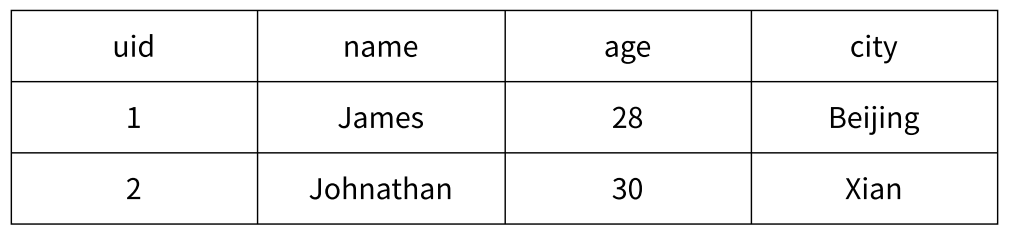
- 用户的属性表现为表的列,每条用户信息表现为行
- 映射关系表示用户信息
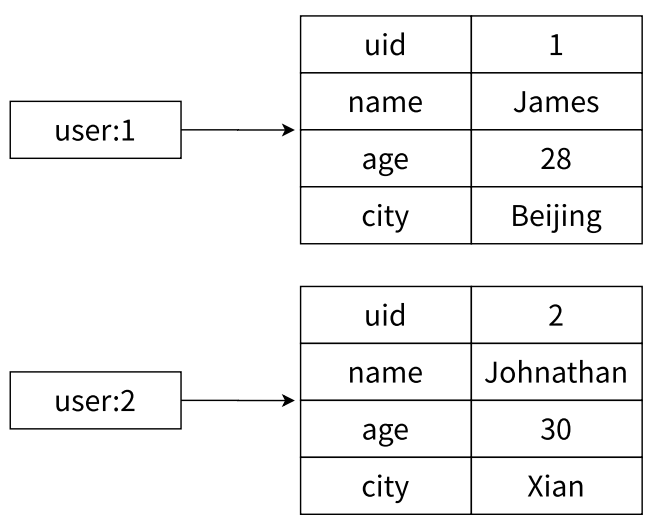
- 哈希类型和关系型数据库有 2 点不同之处
- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,而关系型数据库一旦添加新的列,所有行都要为其设置值,即使为 null
- 关系数据库可以做复杂的关系查询,而 Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本高
- 关系型数据库稀疏性
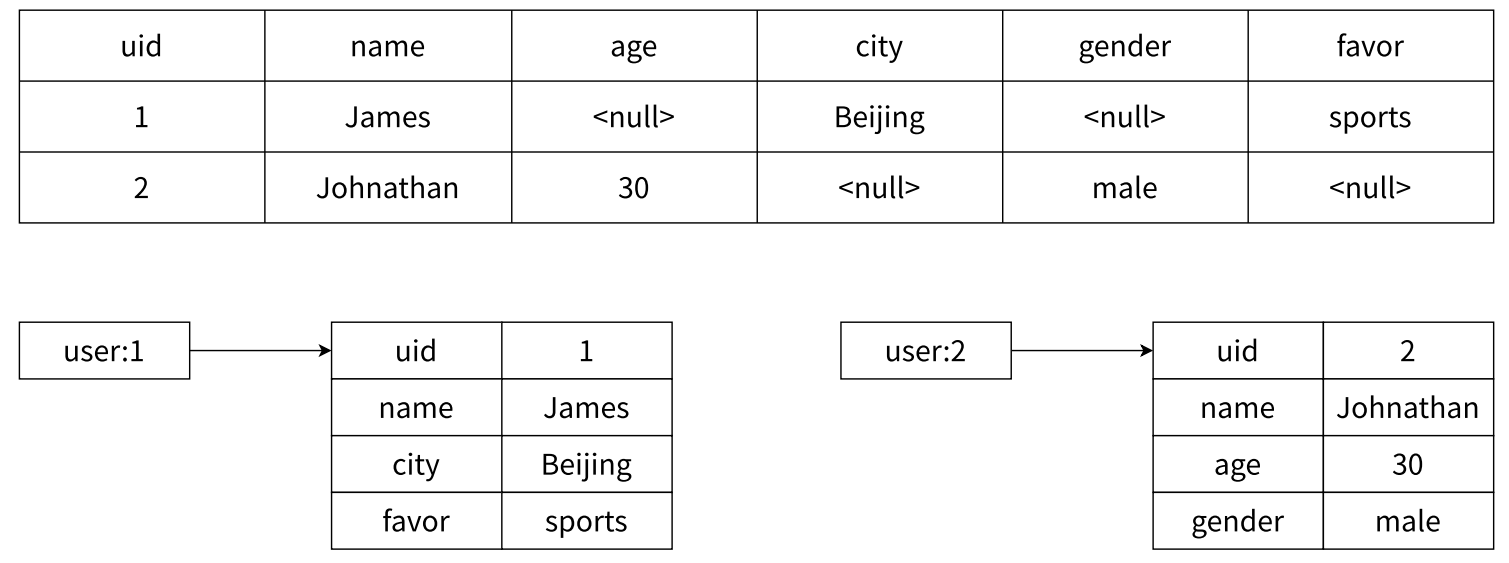
- 关系型数据表保存用户信息
- 缓存方式对比
- 使用字符串类型,每个属性一个键
- 优点:实现简单,针对个别属性变更也很灵活
- 缺点:占用过多的键,内存占用量较大,同时用户信息在 Redis 中比较分散,缺少内聚性,所以这种方案基本没有实用性
- 序列化字符串类型,例如 JSON 格式
- 优点:针对总是以整体作为操作的信息比较合适,编程也简单。同时,如果序列化方案选择合适,内存的使用效率很高
- 缺点:本身序列化和反序列需要一定开销,同时如果总是操作个别属性则非常不灵活
- 哈希类型
- 优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作
- 缺点:需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较大消耗
- 使用字符串类型,每个属性一个键
- List 列表
- 列表两端插入和弹出操作
-
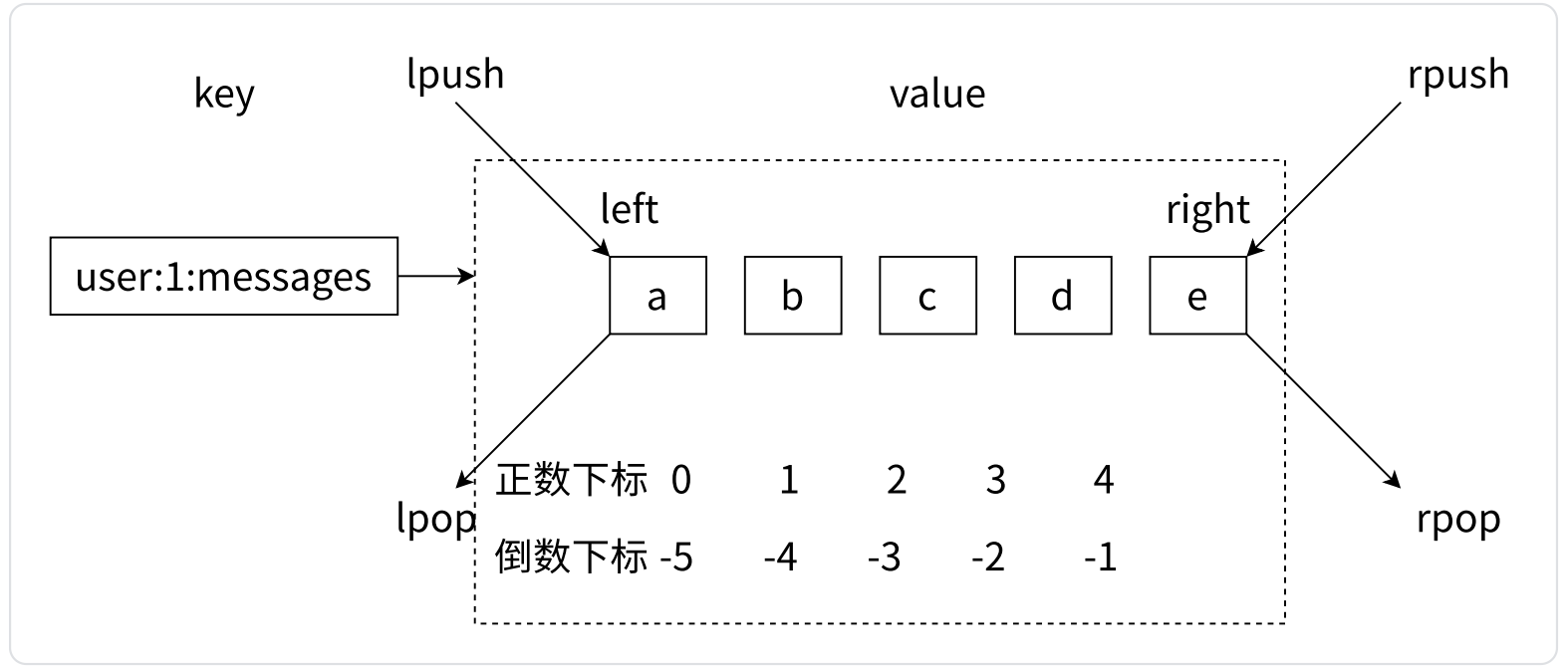
- 列表类型是用来存储多个有序的字符串
- 在 Redis 中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等
- 列表的获取、删除等操作
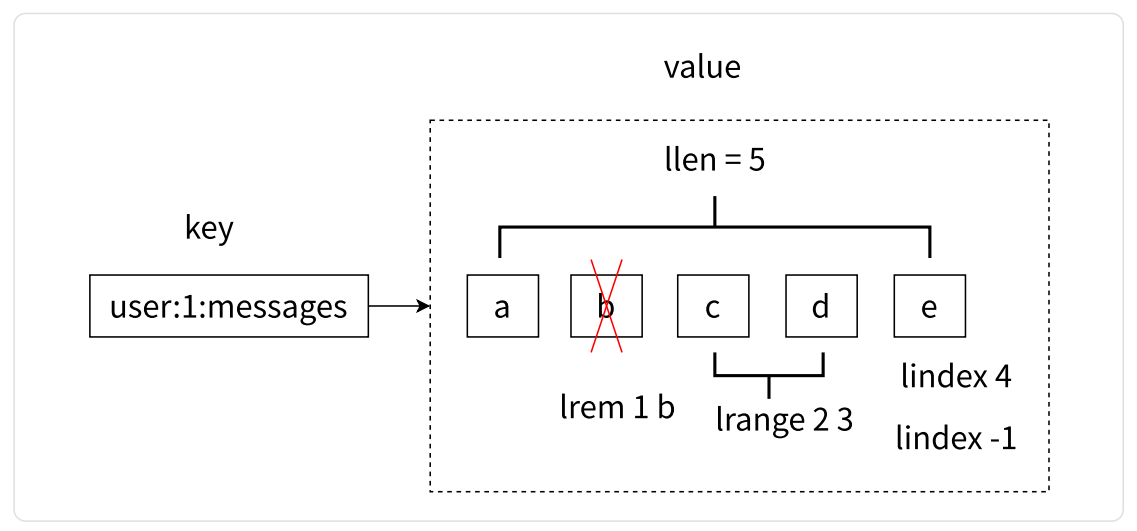
- 列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景
- 特点
- 列表中的元素是有序的(指的是顺序很关键,不是指升序 / 降序),这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,例如要获取第 5 个元素,可以执行 lindex user:1:messages 4 或者倒数第 1 个元素 lindex user:1:messages -1
- 列表中的元素允许重复
- 列表的获取、删除等操作
-
- 命令
- LPUSH
- 将一个或多个元素从左侧放入(头插)到 list 中
- 语法
- LPUSH key element [element ...]
- 时间复杂度
- 只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数
- 返回值
- 插入后 list 的长度
- LPUSHX
- 当 key 存在时,将一个或多个元素从左侧放入(头插)到 list 中。不存在则直接返回
- LPUSHX 指的是:left push exists
- 语法
- LPUSHX key element [element ...]
- 时间复杂度
- 只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数
- 返回值
- 插入后 list 的长度
- RPUSH
- 将一个或者多个元素从右侧放入(尾插)到 list 中
- 语法
- RPUSH key element [element ...]
- 时间复杂度
- 只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数
- 返回值
- 插入后 list 的长度
- RPUSHX
- 在 key 存在时,将一个或者多个元素从右侧放入(尾插)到 list 中
- 语法
- RPUSHX key element [element ...]
- 时间复杂度
- 只插入一个元素为 O(1),插入多个元素为 O(N),N 为插入元素个数
- 返回值
- 插入后 list 的长度
- LRANGE
- 获取从 start 到 end 区间的所有元素,左闭右闭(闭区间),下标支持负数
- LRANGE 指的是:list range
- 语法
- LRANGE key start stop
- 时间复杂度
- O(N)
- 返回值
- 指定区间的元素
- 尽可能的获取到给定区间范围内的元素,如果给定区间非法,就会尽可能的获取对应的内容
- LPOP
- 从 list 左侧取出元素,即头删
- 语法
- LPOP key
- Redis 后续新增了一个 count 参数,用来描述要删除几个元素
- 时间复杂度
- O(1)
- 返回值
- 取出的元素或者 nil
- RPOP
- 从 list 右侧取出元素,即尾删
- 语法
- RPOP key
- 时间复杂度
- O(1)
- 返回值
- 取出的元素或者 nil
- 搭配使用 rpush 和 lpop 就相当于队列
- 搭配使用 rpush 和 rpop 就相当于栈
- LINDEX
- 获取从左数第 index 位置的元素
- LINDEX 指的是:list index
- 语法
- LINDEX key index
- 时间复杂度
- O(N)
- 返回值
- 取出的元素或者 nil
- LINSERT
- 在特定位置插入元素
- 语法
- LINSERT key <BEFORE | AFTER> pivot element
- 时间复杂度
- O(N),N 表示列表长度
- 返回值
- 插入后的 list 长度
- 要根据基准值找到对应的位置,从左往右找,找到第一个符合基准值的位置即可
- LLEN
- 获取 list 长度
- 语法
- LLEN key
- 时间复杂度
- O(1)
- 返回值
- list 的长度
- LREM
- 根据参数 count 的值,移除列表中与参数 element 相等的元素
- count > 0:从表头开始向表尾搜索,移除与 element 相等的元素,数量为 count
- count < 0:从表尾开始向表头搜索,移除与 element 相等的元素,数量为 count 的绝对值
- count = 0:移除表中所有与 element 相等的值
- 语法
- LREM key count element
- 时间复杂度
- O(N)
- 返回值
- 被移除元素的数量。 列表不存在时返回 0
- 根据参数 count 的值,移除列表中与参数 element 相等的元素
- LTRIM
- 对一个列表进行修剪(trim),即让列表只保留 start 和 stop 区间内(闭区间)的元素,不在区间之内的元素都将被直接删除
- 语法
- LTRIM key start stop
- 时间复杂度
- O(N)
- 返回值
- 命令执行成功时,返回 OK
- LSET
- 通过索引来设置元素的值。当索引参数超出范围,或对一个空列表进行 LSET 时,返回一个错误
- 语法
- LSET key index element
- 时间复杂度
- O(N)
- 返回值
- 操作成功返回 OK,否则返回错误信息
- lindex 可以很好的处理下标越界的情况,直接返回 nil
- lset 则会报错,不会直接在 10 下标新增一个元素
- LPUSH
- 阻塞版本命令
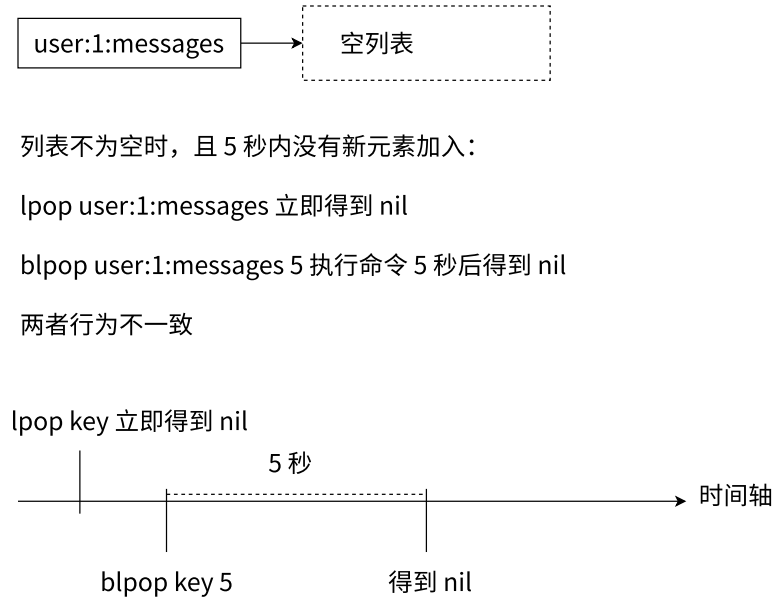
- blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作用基本一致,除了几点
- 在列表有元素的情况下,阻塞和非阻塞表现是一致的。但如果列表中没有元素,非阻塞版本会直接返回 nil,但阻塞版本会根据 timeout 阻塞⼀段时间(可以显示设置阻塞时间的),期间 Redis 可以执行其他命令(此处的 blpop 和 brpop 看起来好像耗时很长,但实际上并不会对 Redis 服务器产生负面影响),但要求执行该命令的客户端会表现为阻塞状态
- 如果命令中设置了多个键 key,那么会从左向右遍历键,一旦有一个键对应的列表中可以弹出元素,立即返回命令
- 如果多个客户端同时执行 pop,则最先执行命令的客户端会得到弹出的元素
- 阻塞版本的 blpop 和非阻塞版本 lpop 的区别
-
- BLPOP
- LPOP 的阻塞版本
- 语法
- BLPOP key [key ...] timeout
- 可以指定超时时间,单位是秒(Redis 后来超时时间允许设定成小数)
- 时间复杂度
- O(1)
- 返回值
- 取出的元素或者 nil
- BRPOP
- RPOP 的阻塞版本。效果和 BLPOP 类似,但这里是头删
- 语法
- BRPOP key [key ...] timeout
- 时间复杂度
- O(1)
- 返回值
- 取出的元素或者 nil
- BLPOP 和 BRPOP 这两个阻塞命令的用途主要是用来作为消息队列。虽然这两个命令在一定程度上可以满足消息队列的需求,但整体功能还是比较有限
- blpop 和 brpop 是 lpop 和 rpop 的阻塞版本,和对应非阻塞版本的作用基本一致,除了几点
- 小结
- 列表命令
-
- 列表命令
- 内部编码
- quicklist
- 相当于是链表和压缩列表的结合,整体还是一个链表,链表的每个节点是一个压缩列表。每个压缩列表都不让它太大,同时再把多个压缩列表通过链式结构连起来
- quicklist
- 使用场景
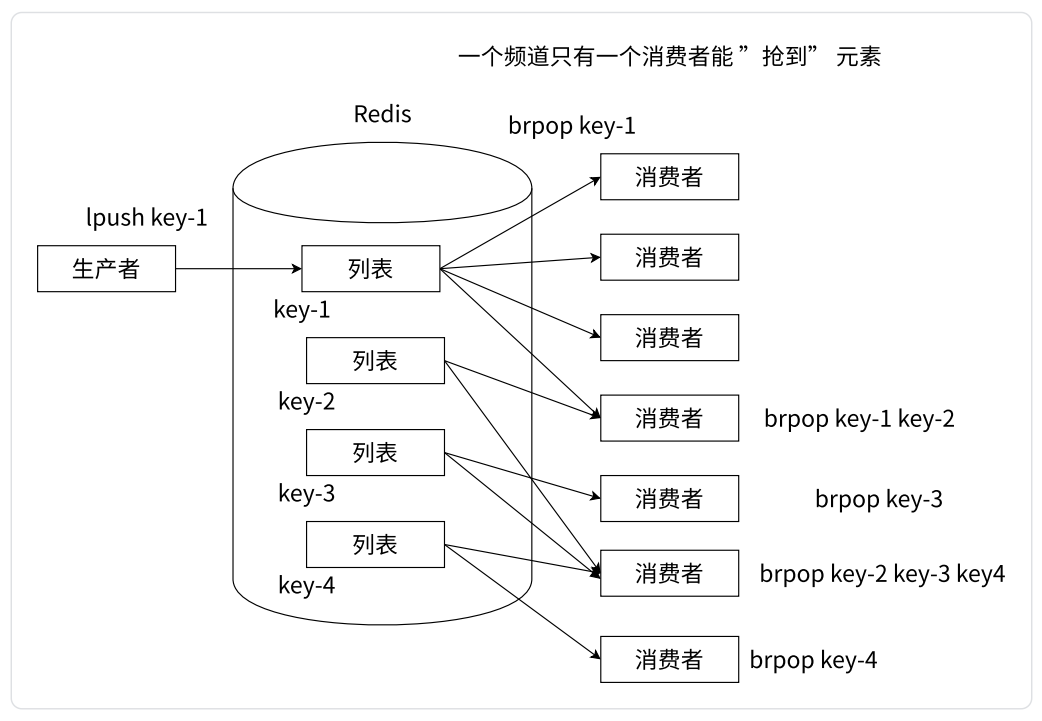
- 消息队列
- 可以使用 lpush + brpop 组合实现经典的阻塞式生产者-消费者模型队列,生产者客户端使用 lpush 从列表左侧插入元素,多个消费者客户端使用 brpop 命令阻塞式地从队列中争抢队首元素。通过多个客户端来保证消费的负载均衡和高可用性
- 阻塞消息队列模型
-
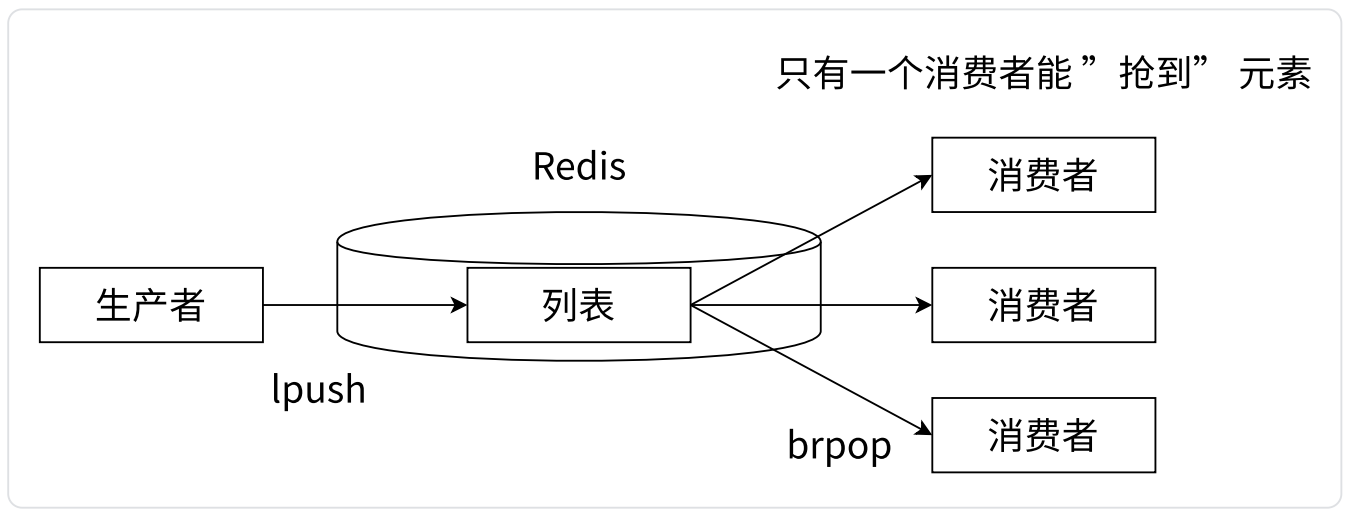
- brpop 是阻塞操作,当列表为空时,brpop 就会阻塞等待,一直等到其它客户端 push 元素为止。当新元素到达后,首先是第一个消费者拿到元素,从 brpop 中返回。如果第一个消费者还想继续消费,则需要重新执行 brpop,排在最后。此时再来一个新元素,就是第二个消费者拿到该元素
-
- 分频道的消息队列
- 同样使用 lpush + brpop 命令,但通过不同的键模拟频道的概念,不同的消费者可以通过 brpop 不同的键值,实现订阅不同频道的理念
- Redis 分频道阻塞消息队列模型
-
- 多个列表(channel)/ 频道(topic)的场景很常见,像日常使用的一些程序,比如抖音。有一个通道用来传输短视频数据,还可以有一个通道来传输弹幕,一个通道来传输点赞、转发、收藏数据,一个通道来传输评论数据等。弄成多个频道就可以在某种数据发生问题时,不会对其他数据造成影响,即解耦合
- 微博 Timeline
- 每个用户都有属于自己的 Timeline(微博列表),现需要分页展示文章列表。可以考虑使用列表,因为列表不但是有序的,同时支持按照索引范围获取元素
- 消息队列
- 列表两端插入和弹出操作




7、Set 集合
- 集合类型是保存多个字符串类型的元素的,可以使用 json 格式让 string 也能存储结构化数据,与列表类型有一些不同
- 集合中,元素之间是无序的,此处的无序是和 list 的有序相对应的
- 集合中,元素不允许重复
- 集合类型
-
- 除了支持集合内的增删查改操作,还支持多个集合取交集、并集、差集
- list:[1, 2, 3] 和 [2, 1, 3] 是两个不同的 list
- set:[1, 2, 3] 和 [2, 1, 3] 是同一个集合
-
- 普通命令
- SADD
- 将⼀个/多个元素添加到 set 中
- 重复的元素无法添加到 set 中
- 语法
- SADD key member [member ...]
- 时间复杂度
- O(1)
- 返回值
- 本次添加成功的元素个数
- SMEMBERS
- 获取一个 set 中的所有元素
- 语法
- SMEMBERS key
- 时间复杂度
- O(N),N 是集合中的元素个数
- 返回值
- 所有元素的列表
- SISMEMBER
- 判断一个元素在不在 set 中
- 语法
- SISMEMBER key member
- 时间复杂度
- O(1)
- 返回值
- 1 表示元素在 set 中,0 表示元素不在 set 中或 key 不存在
- SCARD
- 获取一个 set 的基数(cardinality),即 set 中的元素个数
- 语法
- SCARD key
- 时间复杂度
- O(1)
- 返回值
- set 内的元素个数
- SPOP
- 从 set 中删除并返回一个或多个元素
- 由于 set 内的元素是无序的,所以取出哪个元素实际是未定义行为,即可以看作是随机的
- 语法
- SPOP key [count]
- 时间复杂度
- O(N),N 是 count
- 返回值
- 取出的元素
- SMOVE
- 将一个元素从源 set 取出并放入目标 set 中
- 语法
- SMOVE source destination member
- 时间复杂度
- O(1)
- 返回值
- 1 表示移动成功,0 表示失败
- SREM
- 将指定的元素从 set 中删除
- 语法
- SREM key member [member ...]
- 时间复杂度
- O(N),N 是要删除的元素个数
- 返回值
- 本次操作删除的元素个数
- SADD
- 集合间操作
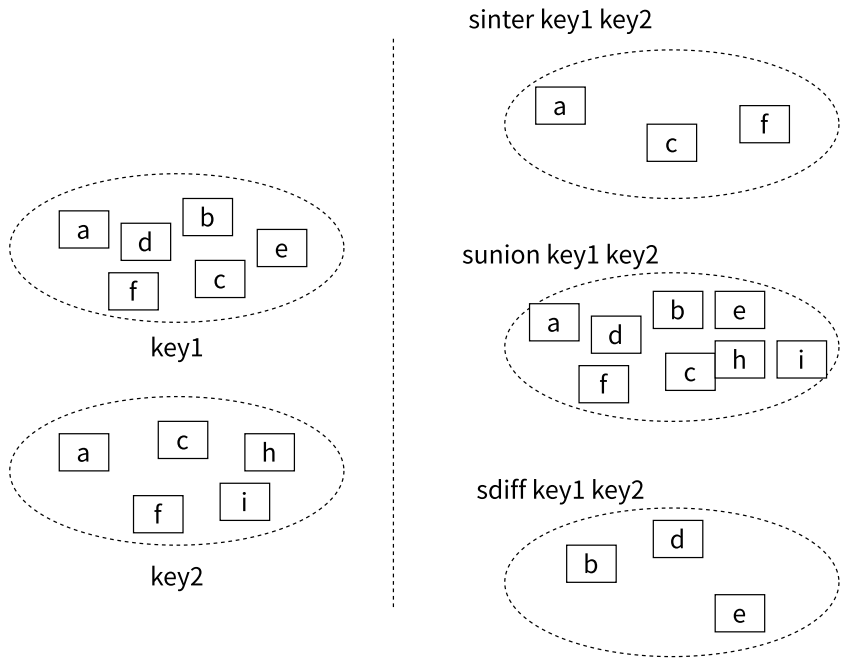
- 集合求交集(inter)、并集(union)、差集(diff)的概念
-
- SINTER
- 获取给定 set 的交集中的元素
- 语法
- SINTER key [key ...]
- 时间复杂度
- O(N * M),N 是最小的集合元素个数,M 是最大的集合元素个数
- 返回值
- 交集的元素
- SINTERSTORE
- 获取给定 set 的交集中的元素并保存到目标 set 中
- 想知道交集的内容,直接按照集合的方式访问目标 set 这个 key 即可
- 语法
- SINTERSTORE destination key [key ...]
- 时间复杂度
- O(N * M),N 是最小的集合元素个数,M 是最大的集合元素个数
- 返回值
- 交集的元素个数
- SUNION
- 获取给定 set 的并集中的元素
- 语法
- SUNION key [key ...]
- 时间复杂度
- O(N),N 给定的所有集合的总的元素个数
- 返回值
- 并集的元素
- SUNIONSTORE
- 获取给定 set 的并集中的元素并保存到目标 set 中
- 语法
- SUNIONSTORE destination key [key ...]
- 时间复杂度
- O(N),N 给定的所有集合的总的元素个数
- 返回值
- 并集的元素个数
- SDIFF
- 获取给定 set 的差集中的元素
- 语法
- SDIFF key [key ...]
- 时间复杂度
- O(N),N 给定的所有集合的总的元素个数
- 返回值
- 差集的元素
- SDIFFSTORE
- 获取给定 set 的差集中的元素并保存到目标 set 中
- 语法
- SDIFFSTORE destination key [key ...]
- 时间复杂度
- O(N),N 给定的所有集合的总的元素个数
- 返回值
- 差集的元素个数
- 集合求交集(inter)、并集(union)、差集(diff)的概念
- 命令小结
- 集合类型命令
-
- 集合类型命令
- 内部编码
- 集合类型的内部编码有 2 种
- intset(整数集合):当集合中的元素都是整数且元素个数小于 set-max-intset-entries 配置时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用
- 当元素个数较少并且都为整数时,内部编码为 intset
- hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现
- 当元素个数超过 512 个,内部编码为 hashtable
- 当存在元素不是整数时,内部编码为 hashtable
- intset(整数集合):当集合中的元素都是整数且元素个数小于 set-max-intset-entries 配置时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用
- 集合类型的内部编码有 2 种
- 使用场景
- 集合类型比较典型的使用场景是标签(tag)。例如 A 用户对娱乐、体育板块比较感兴趣,B 用户对历史、新闻比较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于增强用户体验和用户黏度都非常有帮助。例如一个电子商务网站会对不同标签的用户做不同的产品推荐
- 通过集合类型来实现标签的若干功能
- 给用户添加标签
- 给标签添加用户
- 删除用户下的标签
- 删除标签下的用户
- 通过集合类型来实现标签的若干功能
- 可以使用 Set 来计算用户之间的共同好友(基于集合求交集),基于此还可以做一些好友推荐
- 一个互联网产品衡量用户量、用户规模,其主要的指标有 2 点
- PV(Page View),用户每次访问该服务器都会产生一个 pv
- UV(User View),每个用户访问服务器都会产生一个 uv,但同一个用户多次访问并不会使 uv 增加。uv 需要按照用户进行去重,去重的过程就可以使用 Set 来实现
- 集合类型比较典型的使用场景是标签(tag)。例如 A 用户对娱乐、体育板块比较感兴趣,B 用户对历史、新闻比较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于增强用户体验和用户黏度都非常有帮助。例如一个电子商务网站会对不同标签的用户做不同的产品推荐
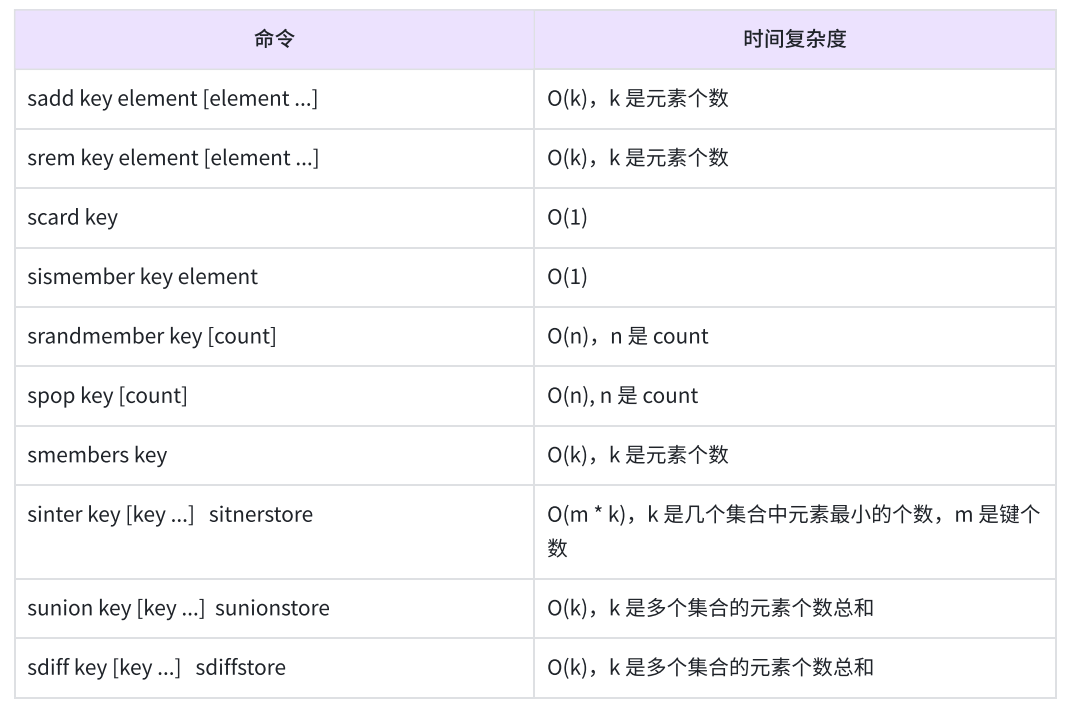
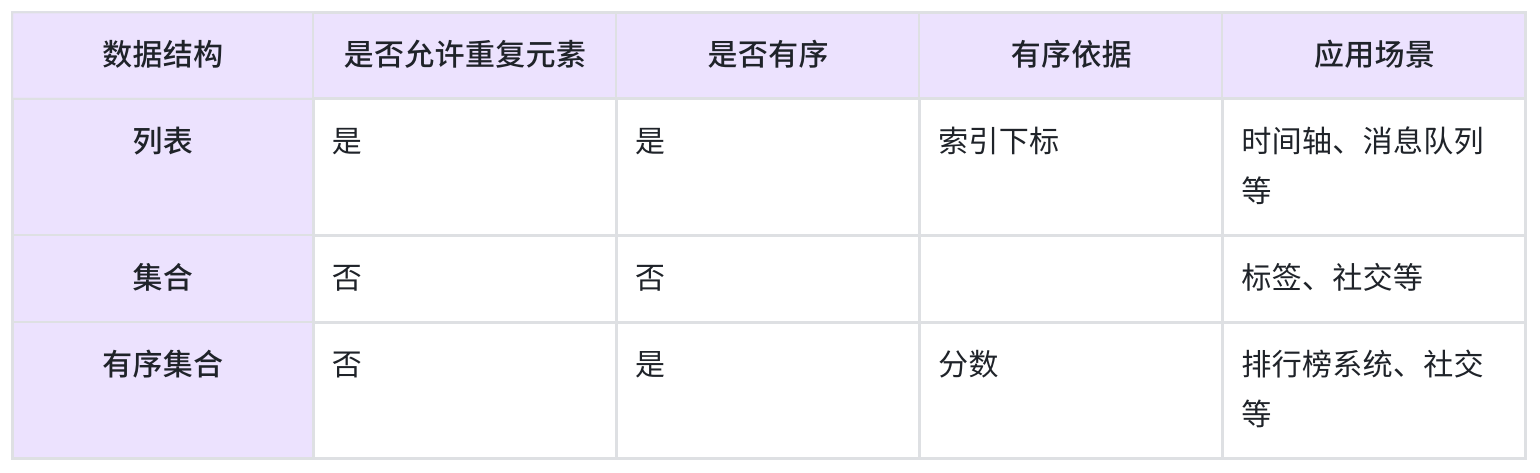
8、Zset 有序集合
- 保留了集合不能有重复成员的特点,但有序集合中的每个元素都有一个唯一的浮点类型的分数(score)与之关联,这使得有序集合中的元素是可以维护有序性的,但这个有序不是用下标作为排序依据而是用这个分数
- Zset 的内部数据结构是跳表
- 有序集合
-
- 有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能
- 有序集合中的元素是不能重复的,但分数允许重复。类比于一次考试之后,每个人一定有一个唯一的分数,但分数允许相同
-
- 列表、集合、有序集合三者的异同点
-
- 普通命令
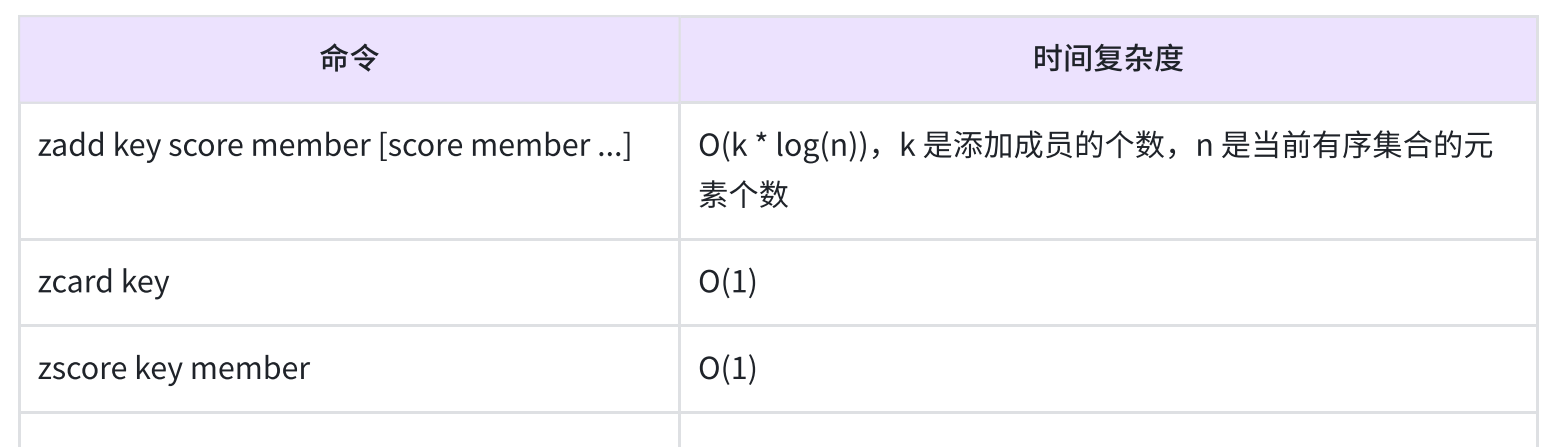
- ZADD
- 添加或更新指定的元素以及关联的分数到 zset 中,分数应该符合 double 类型,+inf/-inf 作为正负极限也是合法的(负无穷大不是无穷小,负无穷大的绝对值和无穷大是一样的)
- ZADD 的相关选项
- XX:仅仅用于更新已经存在的元素,不会添加新元素
- NX:仅用于添加新元素,不会更新已经存在的元素
- LT:仅当新分数小于当前分数时才更新现有元素,不会阻止添加新元素
- GT:仅当新分数大于当前分数时才更新现有元素,不会阻止添加新元素
- CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数
- INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和分数
- 语法
- ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
- member 和 score 称为是一个 pair,类似于 C++ 里的 std::pair。不要理解成键值对(key - value pair),键值对中是有明确的角色区分,一定是根据键 -> 值。而对于有序集合来说,既可以通过 member 找到对应的 score,也可以通过 score 找到匹配的 member
- 时间复杂度
- O(log(N))
- 返回值
- 返回新增成功的元素个数
- ZCARD
- 获取一个 zset 的基数(cardinality),即 zset 中的元素个数
- 语法
- ZCARD key
- 时间复杂度
- O(1)
- 返回值
- zset 内的元素个数
- ZCOUNT
- 返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,如果不想要边界值,可以通过在边界值前加上 '(' 来排除
- 语法
- ZCOUNT key min max
- 时间复杂度
- O(log(N))
- 先根据 min 找到对应的元素,再根据 max 找到对应的元素,两次都是 O(log(N))。Zset 内部会记录每个元素当前的排行 / 次序,查询到元素就直接知道了元素所在的次序(下标),就可以直接把 max 对应的元素次序和 min 对应的元素次序做减法即可
- 返回值
- 满足条件的元素列表个数
- ZRANGE
- 返回指定区间里的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回
- 语法
- ZRANGE key start stop [WITHSCORES]
- 此处的 [start, stop] 为下标构成的区间,从 0 开始,支持负数
- 时间复杂度
- O(log(N)+M),N 是整个有序集合的元素个数,M 是 start - stop 区间内的元素个数
- 返回值
- 区间内的元素列表
- Redis 内部存储数据是按照二进制的方式存储的,意味着 Redis 服务器是不负责字符编码的,所以要把二进制对回到汉字需要客户端支持
- ZREVRANGE
- 返回指定区间里的元素,分数按照降序,带上 WITHSCORES 可以把分数也返回
- 这个命令可能在 6.2.0 之后废弃,且功能合并到 ZRANGE 中
- 语法
- ZREVRANGE key start stop [WITHSCORES]
- 时间复杂度
- O(log(N)+M)
- 返回值
- 区间内的元素列表
- ZPOPMAX
- 删除并返回分数最高的 count 个元素
- 语法
- ZPOPMAX key [count]
- 时间复杂度
- O(log(N) * M),N 是有序集合的元素个数,M 表示 count,要删除的元素个数
- 返回值
- 分数和元素列表
- 如果存在多个元素分数相同(分数是主要因素,相同的情况下会按照 member 字符串的字典序来决定先后顺序),同时为最大值,那么 zpopmax 删除最大元素时,仍然只会删除其中一个元素
- BZPOPMAX
- ZPOPMAX 的阻塞版本。可以同时读多个有序集合
- 语法
- BZPOPMAX key [key ...] timeout
- timeout 单位是 s,支持小数形式
- 时间复杂度
- O(log(N)),删除最大值花费的时间
- 如果当前 BZPOPMAX 同时监听多个 key,假设 key 是 M 个,那么此时时间复杂度是 O(log(N)*M) 吗?
- 每个这样的 key 上面都删除一次元素才需要 *M,而这里是从这若干个 key 中只删除一次
- 返回值
- 元素列表
- ZPOPMIN
- 删除并返回分数最低的 count 个元素
- 语法
- ZPOPMIN key [count]
- 时间复杂度
- O(log(N)*M)
- 返回值
- 分数和元素列表
- BZPOPMIN
- ZPOPMIN 的阻塞版本
- 语法
- BZPOPMIN key [key ...] timeout
- 时间复杂度
- O(log(N))
- 返回值
- 元素列表
- ZRANK
- 返回指定元素的排名,升序
- 语法
- ZRANK key member
- 时间复杂度
- O(log(N))
- ZRANK 查找元素的过程和 ZCOUNT 是一样的
- 返回值
- 排名
- ZREVRANK
- 返回指定元素的排名,降序
- 语法
- ZREVRANK key member
- 时间复杂度
- O(log(N))
- 返回值
- 排名
- ZSCORE
- 返回指定元素的分数
- 语法
- ZSCORE key member
- 时间复杂度
- O(1)
- 此处相当于 Redis 对于这样的查询操作做了特殊优化,付出了额外的空间代价
- 返回值
- 分数
- ZREM
- 删除指定的元素
- 语法
- ZREM key member [member ...]
- 时间复杂度
- O(M*log(N))
- 返回值
- 本次操作删除的元素个数
- ZREMRANGEBYRANK
- 按照排序,升序删除指定范围的元素,左闭右闭
- 语法
- ZREMRANGEBYRANK key start stop
- 时间复杂度
- O(log(N)+M)
- 返回值
- 本次操作删除的元素个数
- ZREMRANGEBYSCORE
- 按照分数删除指定范围的元素,左闭右闭,也可以使用 '(' 来排除边界值
- 语法
- ZREMRANGEBYSCORE key min max
- 时间复杂度
- O(log(N)+M)
- 返回值
- 本次操作删除的元素个数
- ZINCRBY
- 为指定的元素的关联分数添加指定的分数值
- 语法
- ZINCRBY key increment member
- 时间复杂度
- O(log(N))
- 返回值
- 增加后元素的分数
- 不光会修改分数内容,还能同时移动元素位置,保证整个有序集合仍然是升序的
- ZADD
- 集合间操作
- 有序集合的交集操作
-
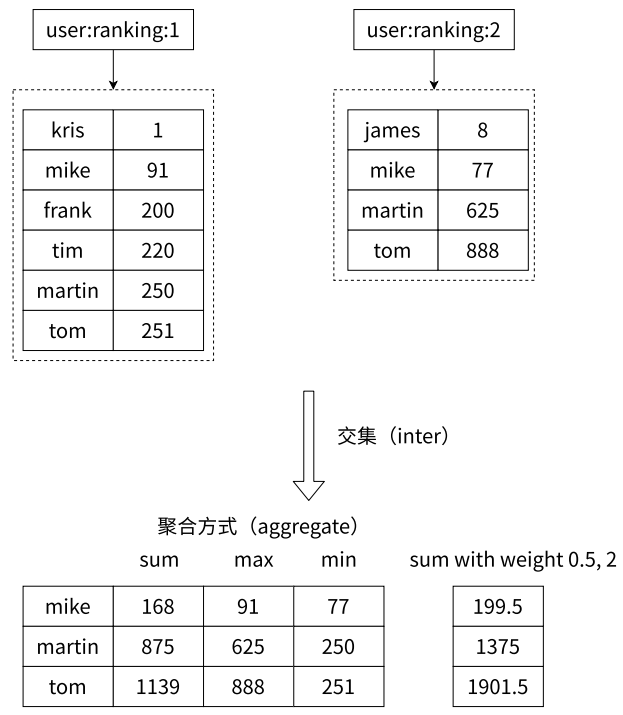
- ZINTERSTORE
- 求出给定有序集合中元素的交集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
- 在有序集合中,member 是元素的本体,score 只是辅助排序的工具人。因此,在进行比较相同时,只要 member 相同即可。如果 member 相同,score 不同,进行交集合并之后的最终分数看 AGGREGATE 后面的属性
- 语法
- ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
- numkeys 是一个整数,用来描述后续有几个 key 参与交集运算
- 时间复杂度
- O(N*K)+O(M*log(M)),N 是输入的有序集合中,最小的有序集合的元素个数;K 是输入了几个有序集合;M 是最终结果的有序集合的元素个数
- 返回值
- 目标集合中的元素个数
-
- 有序集合的并集操作
-
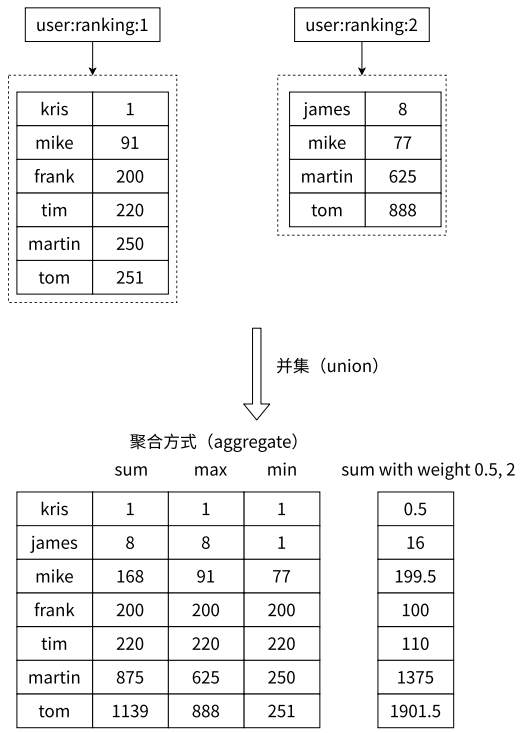
- ZUNIONSTORE
- 求出给定有序集合中元素的并集并保存进目标有序集合中,在合并过程中以元素为单位进行合并,元素对应的分数按照不同的聚合方式和权重得到新的分数
- 语法
- ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
- 时间复杂度
- O(N)+O(M*log(M)) N 是输入的有序集合总的元素个数,M 是最终结果的有序集合的元素个数
- 返回值
- 目标集合中的元素个数
-
- 有序集合的交集操作
- 命令小结
- 有序集合命令
-
- 有序集合命令
- 内部编码
- 有序集合类型的内部编码有 2 种
- ziplist(压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个),同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用
- 当元素个数较少且每个元素较小时,内部编码为 ziplist
- skiplist(跳表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的操作效率会下降
- 当元素个数超过 128 个,内部编码 skiplist
- 当某个元素大于 64 字节时,内部编码 skiplist
- ziplist(压缩列表):当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个),同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用
- 简单来说,跳表是一个复杂链表,查询元素的时间复杂度是 O(logN)。相比于树形结构,更适合按照范围获取元素
- 有序集合类型的内部编码有 2 种
- 使用场景
- 排行榜系统。例如常见网站上的热榜信息,榜单的维度可能是多方面的:按照时间、按照阅读量、按照点赞量。本例中我们使用点赞数这个维度,维护每天的热榜

9、渐进式遍历
- Redis 使用 scan 命令进行渐进式遍历键,进而解决直接使用 keys 获取键时可能出现的阻塞问题。不是一个命令将所有 key 都拿到,而是每执行一次命令,只获取其中一小部分,就可以保证当前这一次操作不会太卡。每次 scan 命令的时间复杂度是 O(1),但要完整完成所有键的遍历,需要执行多次 scan。渐进式遍历其实是一组命令,这一组命令的使用方法是一样的
- scan 命令渐进式遍历

- 首次 scan 从 0 开始
- 当 scan 返回的下次位置为 0 时,遍历结束
- 返回值的前半部分 1) 是说明下次继续遍历的光标(当作一个字符串即可)要从哪里开始,第二部分 2) 是真正遍历到的 key 的内容
- SCAN
- 以渐进式的方式进行键的遍历
- 渐进式遍历再遍历过程中不会在服务器这边存储任何的状态信息,此处的遍历是随时可以终止的,不会对服务器产生任何的副作用
- 语法
- SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
- count 是限制此次遍历能获取到多少个元素,默认是 10
- 此处的 count(给 Redis 服务器一个提示 / 建议,写入的 count 和实际返回的 key 的个数不一定完全相同,但是不会差很多)和 MySQL 的 limit 不一样
- 时间复杂度
- O(1)
- 返回值
- 下一次 scan 的游标(cursor)以及本次得到的键
- 除了 scan 以外,Redis 面向哈希类型、集合类型、有序集合类型分别提供了 hscan、sscan、zscan 命令,用法和 scan 基本类似
- 渐进性遍历 scan 虽然解决了阻塞问题,但如果在遍历期间键有所变化,比如增删查改,可能会导致遍历时键的重复遍历或者遗漏
10、数据库管理
- 几个面向 Redis 数据库的操作,分别是命令:dbsize、select、flushdb、flushall
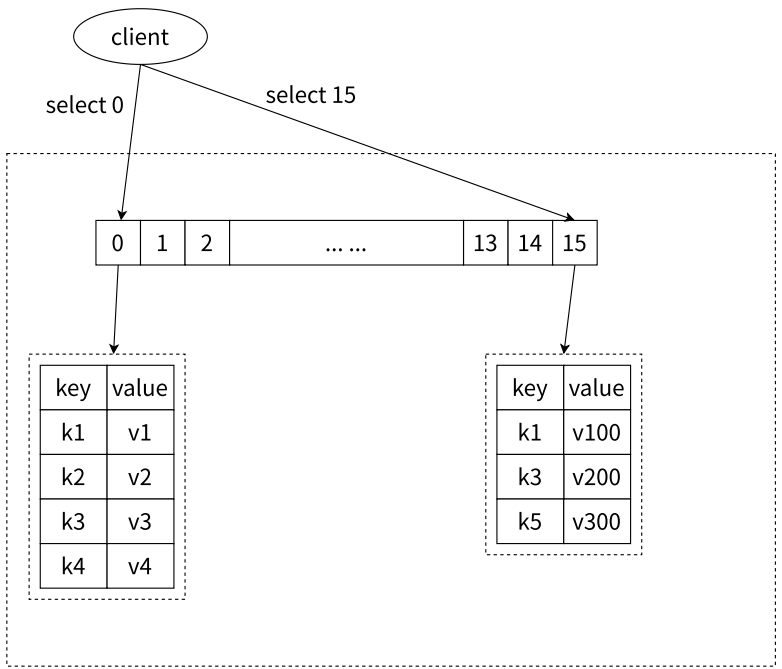
- 切换数据库
- select dbIndex
- 许多关系型数据库,例如 MySQL 支持在一个实例下有多个数据库存在的,但是与关系型数据库用字符来区分不同数据库名,Redis 只是用数字作为多个数据库的实现。Redis 默认配置中是有 16 个数据库,不能创建新的数据库,也不能删除已有的数据库,数据库中的数据是隔离的
- 默认情况下处于数据库 0
- select 0 操作会切换到第⼀个数据库,select 15 会切换到最后⼀个数据库。0 号数据库和 15 号数据库有各自的键值对
-
- 虽然支持多数据库,但随着版本的升级,不建议使用多数据库特性。如果真的需要完全隔离的两套键值对,建议维护多个 Redis 实例,而不是在一个 Redis 实例中维护多数据库。因为 Redis 并没有为多数据库提供太多的特性,其次无论是否有多个数据库,Redis 都是使用单线程模型,所以彼此之间还是需要排队等待命令的执行。同时多数据库还会让开发、调试和运维工作变得复杂,所以始终使用数据库 0 其实是⼀个很好的选择
- 清除数据库
- flushdb / flushall 命令用于清除数据库
- flushdb:只清除当前数据库
- flushall:清除所有数据库
- 语法
- FLUSHDB [ASYNC | SYNC]
- FLUSHALL [ASYNC | SYNC]
- ASYNC:异步
- SYNC:同步
- flushdb / flushall 命令用于清除数据库
11、6379 是 Redis 服务器的默认端口
七、持久化
Redis 持久化 和 MySQL 里的持久性是一回事,把数据存储在硬盘上,重启进程 / 主机后数据仍然存在;把数据存储在内存上,重启进程 / 主机后数据消失 —— 不持久。持久化功能有效避免因进程退出造成数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复
Redis 为了保证速度快,数据肯定还得存储在内存中。但为了持久化,数据还得想办法存储在硬盘上。所以最后决定在内存中和硬盘上都存储数据,这样的两份数据在理论上是完全相同的。当要插入一个新的数据时,就需要把这个数据同时写入到内存和硬盘。当查询某个数据时,直接从内存中读取,硬盘的数据只是在 Redis 重启时,用来恢复内存中的数据。代价就是消耗了更多的空间,同一份数据存储两遍,但毕竟硬盘价格便宜,开销不会带来太大的成本,而且实际上具体怎么写硬盘还有不同的策略,是可以保证整体的效率足够高的
1、RDB
- RDB(Redis DataBase)持久化是把定期的将当前的进程数据生成快照保存到硬盘的过程,触发 RDB 持久化过程分为手动触发和自动触发
- 触发机制
- 手动触发分别对应 save 和 bgsave 命令
- save 命令:阻塞当前 Redis 服务器,直到 RDB 过程完成为止,对于内存比较大的实例造成长时间阻塞,一般不建议使用
- bgsave(background save)命令:Redis 进程执行 fork 操作创建子进程,RDB 持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork 阶段,一般时间很短。不会影响 Redis 服务器处理其他客户端的请求和命令
- 此处 Redis 使用的是 “多进程” 的方式来实现 bgsave
- Redis 内部的所有涉及 RDB 的操作都采用类似 bgsave 的方式
- 如果插入新的 key,而此时不手动执行 bgsave,直接重新启动 Redis 服务器,那么刚刚插入的数据在重启之后仍然存在。所以,Redis 生成快照操作不仅仅是手动执行命令才触发,也可以自动触发
- 除了手动触发之外,Redis 运行自动触发 RDB 持久化机制
- 使用 save 配置,比如 "save m n" 表示 m 秒内数据集发生了 n 次修改,自动 RDB 持久化
- 从节点进行全量复制(主从复制)操作时,主节点自动进行 RDB 持久化生成快照,随后将 RDB 快照文件内容发送给从节点
- 如果执行 shutdown 命令(service redis-server restart,正常关闭)关闭 Redis 时,或者通过正常流程重新启动 Redis 服务器,那么此时 Redis 服务器会在退出时自动执行 RDB 持久化。但如果是异常重启(kill -9 或者服务器掉电),那么此时 Redis 服务器来不及生成 rdb,内存中尚未保存到快照中的数据,就会随着重启而丢失
- 并不是说 Redis 客户端这边插入了数据,rdb 文件中的数据就会立即更新。插入几个键值对后,没有运行手动触发的命令,达不到自动触发的条件,那么就不会更新
- 对于 Redis 来说,配置文件发生修改后,一定要重新启动服务器才能生效。如果想要立即生效,也可以通过命令的方式进行修改
- 如果把 rdb 文件故意改坏会怎么样?
- 手动把 rdb 文件内容改坏,如果是通过 service redis-server restart 重启,就会在 Redis 服务器退出时重新生成 rdb 快照,那么刚才改坏的文件就会被替换掉
- 通过 kill 进程的方式再重新启动 Redis 服务器,此时 rdb 文件还是错的,但看起来 Redis 好像没受到什么影响,还是能正常启动,正确获取到 key。是因为刚才修改的位置应该正好是文件的末尾,对前面的内容没有什么影响,但如果修改了中间位置的内容,那么 Redis 服务器就启动不了了
- 此时 Redis 服务器挂了,可以看看 Redis 日志。Redis 也提供了 rdb 文件的检查工具,可以先通过检查工具来检查 rdb 文件格式是否符合要求
- 检查工具和 Redis 服务器是同一个可执行程序,可以在运行时加入不同的选项,使用其中不同的功能,运行时加入 rdb 文件作为命令行参数,那么此时就是以检查工具的方式来运行,不会真的启动 Redis 服务器
- 手动触发分别对应 save 和 bgsave 命令
- 流程说明
- bgsave 是主流的 RDB 持久化方式
- bgsave 命令的运作流程
-
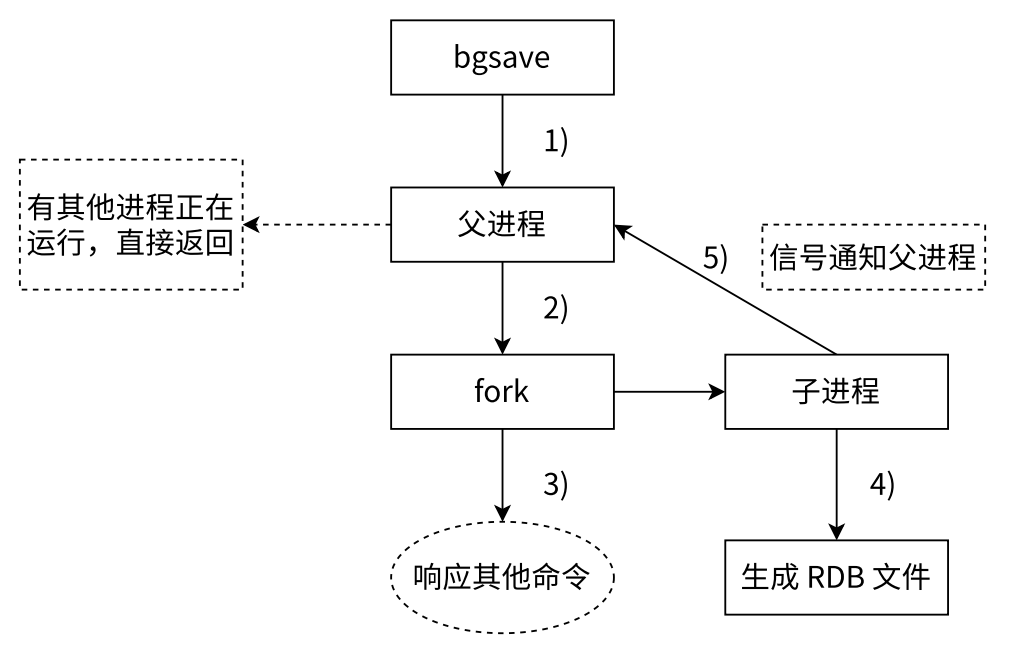
- 执行 bgsave 命令,Redis 父进程(Redis 服务器)判断当前进程是否存在其他正在执行的子进程,比如 RDB / AOF 子进程,如果存在 bgsave 命令直接返回
- 如果没有其它工作子进程,父进程通过执行 fork 系统调用来创建一个子进程(该场景中的绝大部分内存数据是不需要改变的,所以在短时间内父进程中不会有大批的内存数据变化,因此子进程的 “写时拷贝” 并不会触发很多次),fork 过程中父进程会阻塞
- 父进程 fork 完成后,bgsave 命令返回 "Background saving started" 信息,并不再阻塞父进程,可以继续响应其他命令
- 子进程创建 RDB 文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换
- 进程发送信号给父进程表示完成,父进程更新统计信息,子进程就可以结束销毁了
- bgsave 操作流程是创建子进程,子进程完成持久化操作(持久化速度太快了,难以观察到子进程,因为数据少),持久化会把数据写入到新的文件中,然后使用新的文件替换旧的文件
- 可以通过 Linux 的 stat 命令来查看文件的 inode 编号
- 这两个文件不再是同一个文件了,只不过文件内容是一样的。inode 编号就相当于文件的身份标识。如果是直接使用 save 命令,那么此时是不会触发子进程和文件替换逻辑的,会直接在当前进程中往同一文件中写入数据
- 文件系统典型的组织方式(ext4)主要是把整个文件系统分成三个大的部分
- 超级块(存放一些管理信息)
- inode 区(存放 inode 节点,每个文件都会分配一个 inode 数据结构,包含文件的各种元数据)
- block 区(存放文件的数据内容)
-
- RDB 文件的处理
- 保存:RDB 文件(把内存中的数据以压缩的形式保存到这个二进制文件中,需要消耗一定的 CPU 资源,但是能节省存储空间)保存在 dir 配置指定的目录下,文件名通过 dbfilename 配置(默认 dump.rdb)指定
- 压缩:Redis 默认采用 LZF 算法对生成的 RDB 文件做压缩处理,压缩后的文件远远小于内存大小,默认开启
- 虽然压缩 RDB 会消耗 CPU,但可以大幅降低文件的体积,方便保存到硬盘或通过网络发送到从节点
- 校验:如果 Redis 启动时加载到损坏的 RDB 文件会拒绝启动,这时可以使用 Redis 提供的 redis-check-dump 工具检测 RDB 文件并获取对应的错误报告
- 当执行生成 rdb 镜像操作时,此时就会把要生成的快照数据先保存到一个临时文件中,当这个快照生成完毕后,再删除之前的 rdb 文件,把新生成的临时 rdb 文件名改成刚才的 dump.rdb,也就保证了 rdb 文件自始至终只有一个
- 执行 flushall 命令会自动清空 rdb 文件
- RDB 的优缺点
- 优点
- RDB 是⼀个紧凑压缩的二进制文件,代表 Redis 在某个时间点上的数据快照。非常适用于备份,全量复制等场景。比如每 6 小时执行 bgsave 备份,并把 RDB 文件复制到远程机器或者文件系统中(如 hdfs)用于灾备
- Redis 加载 RDB 恢复数据远远快于 AOF 的方式。 (二进制的方式则直接将数据读取到内存中,按照字节的格式取出来放到结构体 / 对象即可,文本方式组织数据则需要进行一系列的字符串切分操作)
- 缺点
- 数据没法做到实时持久化 / 秒级持久化(在两次生成快照之间,实时数据可能会随着重启而丢失),这就导致快照里的数据和当前实时的数据情况可能存在偏差,因为 bgsave 每次运行都要执行 fork 创建子进程,属于重量级操作,频繁执行成本过高
- RDB 文件使用特定二进制格式保存,Redis 版本演进过程中有多个 RDB 版本,兼容性可能有风险,旧版本的 Redis 的 rdb 文件放到新版本的 Redis 中不一定能实现。但一般来说,实际工作中 Redis 版本都是统一的,实在不行也可以通过写一个程序的方式来直接遍历旧的 Redis 中的所有 key,把数据取出来插入到新的 Redis 服务器中即可
- 优点
2、AOF
- AOF(Append Only File)持久化(类似于 MySQL 中的 binlog,会把用户的每个操作都记录到文件中):以独立日志的方式记录每次写命令,重启时再重新执行 AOF 文件中的命令达到恢复数据的目的。AOF 的主要作用是解决数据持久化的实时性,目前已经是 Redis 持久化的主流方式
- Redis 重新启动时,又读 RDB、又读 AOF,到底以哪个为准呢?
- 当开启 AOF 时,rdb 就不生效了,启动时就不再读取 rdb 文件内容
- 使用 AOF
- 开启 AOF 功能需要设置配置:appendonly yes,默认是关闭状态。AOF 文件名通过 appendfilename 配置(默认是 appendonly.aof)设置
- 保存目录同 RDB 持久化方式一致,通过 dir 配置指定。AOF 的工作流程操作:命令写入(append)、文件同步(sync)、文件重写(rewrite)、重启加载(load)
- AOF 工作流程
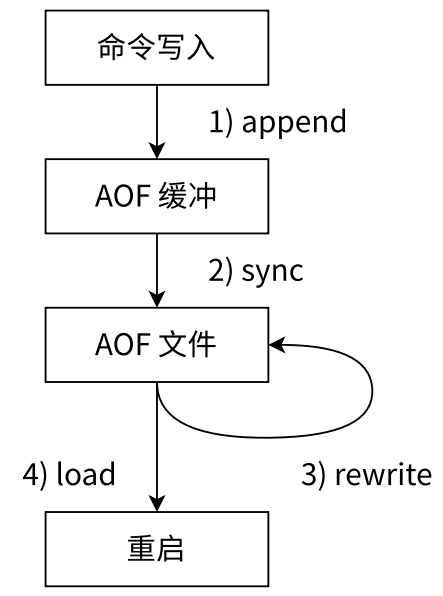
- 所有的写入命令会追加到 aof_buf(内存中的缓冲区,大大降低了写硬盘的次数)
- AOF 缓冲区根据对应的策略向硬盘做同步操作
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,以达到压缩的目的
- 当 Redis 服务器启动时,可以加载 AOF 文件进行数据恢复
- 写硬盘时,写入数据的多少对于性能的影响不是很大,但写入次数影响很大
- 硬盘上读写数据,顺序读写的速度还是比较快的,但还是比内存要慢很多,随机访问则速度比较慢。AOF 是每次将新的数据写入到原有文件的末尾,属于顺序写入
- AOF 工作流程
- 命令写入
- AOF 命令写入的内容是文本协议格式
- Redis 选择文本协议可能的原因
- 文本协议具备较好的兼容性
- 实现简单
- 具备可读性
- Redis 选择文本协议可能的原因
- 每次进行的操作都会被记录到文本文件中,通过一些特殊符号作为分隔符,来对命令的细节做出区分
- 为什么需要 aof_buf 这个缓冲区?
- Redis 虽然是使用单线程响应命令,但速度很快,因为它只是操作内存。引入 AOF 后,又要写内存,又要写硬盘,同时还要保持之前的速度,实际上这并没有影响到 Redis 处理请求的速度
- AOF 机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一波之后再统一写入。如果每次写 AOF 文件都直接同步硬盘,性能从内存的读写变成 IO 读写,必然会下降。先写入缓冲区可以有效减少 IO 次数,同时,Redis 还可以提供多种缓冲区同步(刷新)策略,让用户根据自己的实际情况和需求来做出合理的平衡
- 把数据写入到缓冲区中的本质还是在内存中,万一此时进程突然挂了或者主机掉点了,那缓冲区中没来得及写入硬盘的数据也就丢了
- 缓冲区刷新频率越高,性能影响就越大,同时数据的可靠性就越高
- 缓冲区刷新频率越低,性能影响就越小,同时数据的可靠性就越低
- AOF 命令写入的内容是文本协议格式
- 文件同步
- Redis 提供了多种 AOF 缓冲区同步文件策略,由参数 appendfsync 控制
- AOF 缓冲区同步文件策略
-
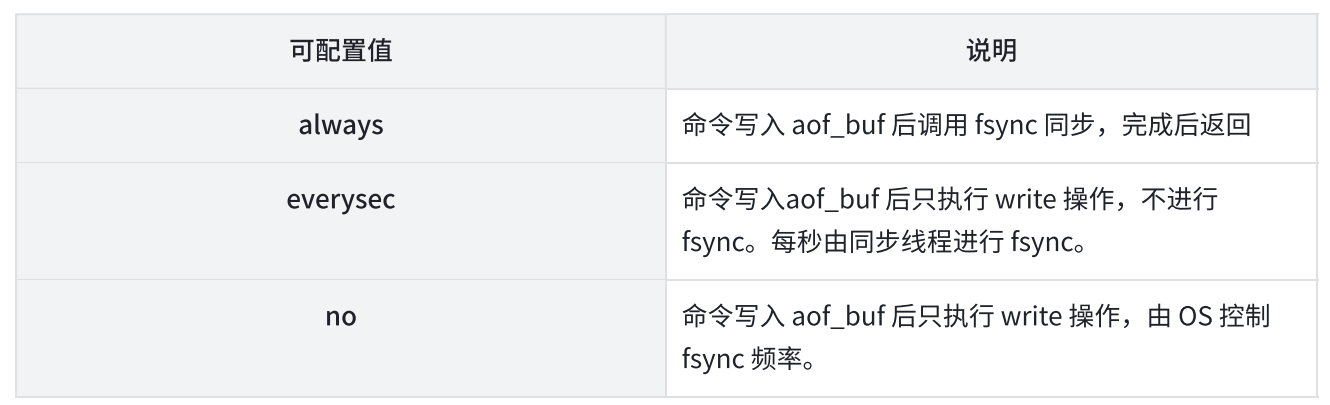
- 默认采用 everysec 配置
- 系统调用 write 和 fsync 说明
- write 操作会触发延迟写(delayed write)机制。Linux 在内核提供页缓冲区来提供硬盘 IO 性能,write 操作在写入系统缓冲区后立即返回。同步硬盘操作依赖于系统调度机制,例如缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失
- fsync 针对单个文件操作,做强制硬盘同步,将阻塞直到数据写入到硬盘
- 配置为 always 时,每次写入都要同步 AOF 文件,性能很差,在⼀般的 SATA 硬盘上,只能⽀持大约几百 TPS 写入。除非是非常重要的数据,否则不建议配置
- 配置为 no 时,由于操作系统同步策略不可控,虽然提高了性能,但数据丢失风险大增,除非数据重要程度很低,一般不建议配置
- 配置为 everysec,是默认配置,也是推荐配置,兼顾了数据安全性和性能,理论上最多丢失 1s 的数据
-
- 重写机制
- 随着命令不断写入 AOF,文件持续增长,会影响到 Redis 下次的启动时间(Redis 在启动时需要读取 AOF 文件内容,该文件记录了中间过程,但实际上 Redis 在重启时只关注最终结果)。为了解决这个问题,引入 AOF 重写机制(能够针对 AOF 文件进行整理操作,剔除其中的冗余操作并合并一些操作)压缩文件体积
- AOF 文件重写是把 Redis 进程内的数据转化为写命令,同步到新的 AOF 文件
- 重写后的 AOF 为什么可以变小?
- 进程内已超时的数据不再写入文件
- 旧的 AOF 中的无效命令,例如 del、hdel、srem 等重写后将会删除,只需要保留数据的最终版本
- 多条写操作合并为⼀条,例如 lpush list a、lpush list b、lpush list c 可以合并为 lpush list a b c
-
- 较小的 AOF 文件一方面降低了硬盘空间占用,另一方面可以提升启动 Redis 时数据恢复的速度
- AOF 重写过程可以手动触发和自动触发
- 手动触发:调用 bgrewriteaof 命令
- 如果在执行 bgrewriteaof 时,发现当前 Redis 已经正在进行 AOF 重写了,此时不会再次执行 AOF 重写,而是直接返回
- 如果在执行 bgrewriteaof 时,发现当前 Redis 在生成 rdb 文件的快照,此时 AOF 重写操作就会等待 rdb 快照生成完毕之后再进行执行 AOF 重写
- 自动触发:根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定自动触发时机
- auto-aof-rewrite-min-size:表示触发重写时 AOF 的最小文件大小,默认为 64MB
- auto-aof-rewrite-percentage:代表当前 AOF 占用大小相比较上次重写时增加的比例
- 手动触发:调用 bgrewriteaof 命令
- AOF 重写流程
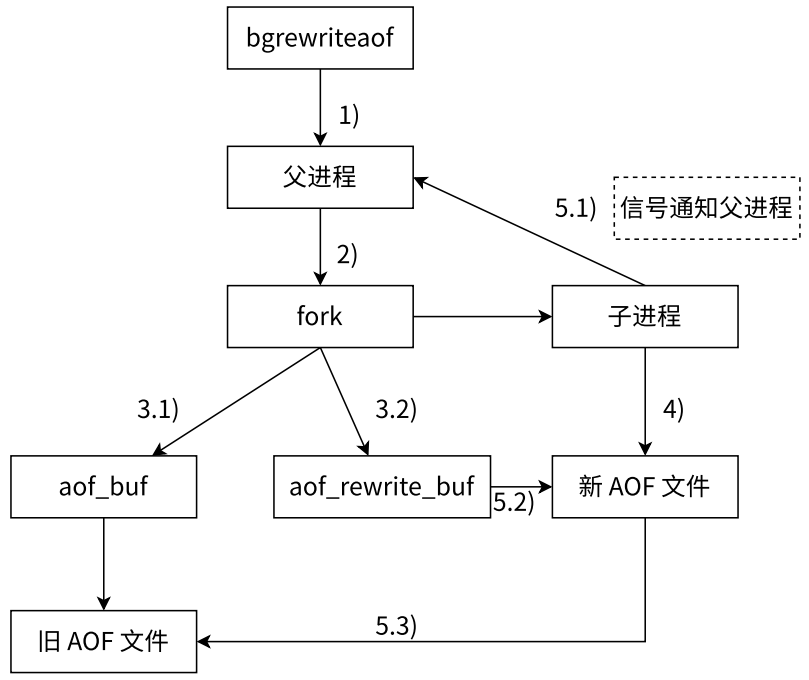
- 执行 AOF 重写请求。如果当前进程正在执行 AOF 重写,请求不执行。如果当前进程正在执行 bgsave 操作,重写命令延迟到 bgsave 完成后再执行
- 父进程执行 fork 创建子进程
- 重写
- 父进程 fork 之后,继续响应其它命令,仍然负责接收客户端的新请求。父进程还是会把这些请求产生的 AOF 数据先写入到缓冲区,并根据 appendfsync 策略同步到硬盘,保证旧 AOF 文件机制正确
- 子进程只有 fork 之前的所有内存信息,父进程中需要将 fork 之后这段时间的修改操作写入 AOF 重写缓冲区中。重写的时候不关心 AOF 文件中原来有什么,只关心内存中最终的数据状态
- 在创建子进程的一瞬间,子进程就根据内存快照,将命令合并到新的 AOF 文件中,也就是继承了当前父进程的内存状态。因此,子进程里的内存数据是父进程 fork 之前的状态。fork 后新来的请求对内存造成的修改是子进程感知不到的,父进程这里又准备了一个 aof_rewrite_buf 缓冲区,专门用来存放 fork 后收到的数据
- 子进程完成重写
- 子进程这边把 AOF 新文件数据写入完成后,子进程会通过发送信号通知父进程
- 父进程再把 aof_rewrite_buf 缓冲区中的内容也追加到新 AOF 文件里
- 用新 AOF 文件代替旧 AOF 文件
- 此处子进程写数据的过程非常类似于 RDB 生成一个镜像快照,只不过 RDB 是按照二进制的方式来生成的,而 AOF 重写则是按照 AOF 要求的文本格式来生成的,二者目的都是把当前内存中的所有数据状态记录到文件中
- 为什么 RDB 对于 fork 之后的新数据就直接置之不理了,而不选择采用和 AOF 一样的处理机制呢?
- RDB 本身的设计理念就是用来 “定期备份” 的,只要是定期备份就难以和最新数据保持一致
- 实时备份不一定就比定期备份更好,具体还是要看实际场景需求。现在系统中的系统资源一般都是比较充裕的,AOF 的开销并不大,所以一般 AOF 的适用场景更多一些
- RDB 本身的设计理念就是用来 “定期备份” 的,只要是定期备份就难以和最新数据保持一致
- 父进程 fork 完毕之后,就已经让子进程写新的 AOF 文件了,并且随着时间的推移,子进程很快就写完了新文件,要让新的 AOF 文件代替旧的 AOF 文件,父进程此时还在继续写这个即将消亡的旧 AOF 文件是否还有意义呢?
- 需要考虑到极端情况:假设在重写的过程中服务器突然挂了,此时子进程内存的数据就会丢失,新 AOF 文件内容还不完整,所以如果父进程不坚持写旧的 AOF 文件,那么重启就无法保证数据的完整性
- AOF 本来是按照文本的方式来写入文件的,但后续加载成本较高,所以 Redis 就引入了 “混合持久化” 的方式,结合了 rdb 和 aof 的特点。按照 aof 的方式,将每一个请求 / 操作都记录到文件中。在触发 aof 重写之后,就会把当前内存的状态按照 rdb 的二进制格式写入到新的 aof 文件中,后续再进行的操作仍然是按照 aof 文本的方式追加到文件后面
- 随着命令不断写入 AOF,文件持续增长,会影响到 Redis 下次的启动时间(Redis 在启动时需要读取 AOF 文件内容,该文件记录了中间过程,但实际上 Redis 在重启时只关注最终结果)。为了解决这个问题,引入 AOF 重写机制(能够针对 AOF 文件进行整理操作,剔除其中的冗余操作并合并一些操作)压缩文件体积
- 启动时数据恢复
- 当 Redis 启动时,会根据 RDB 和 AOF 文件的内容,进行数据恢复
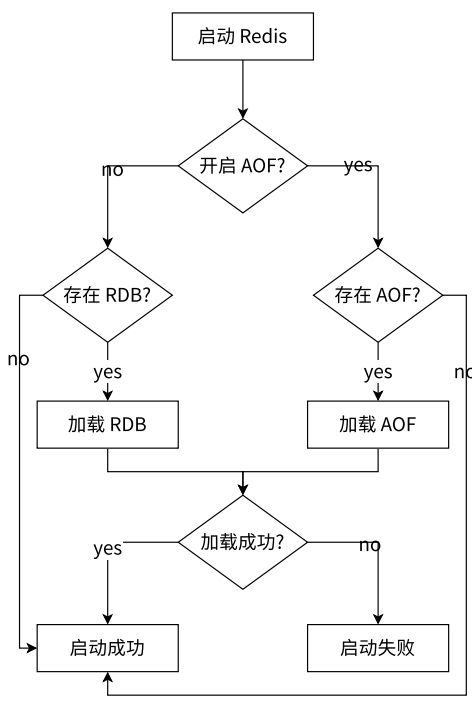
- 当 Redis 启动时,会根据 RDB 和 AOF 文件的内容,进行数据恢复
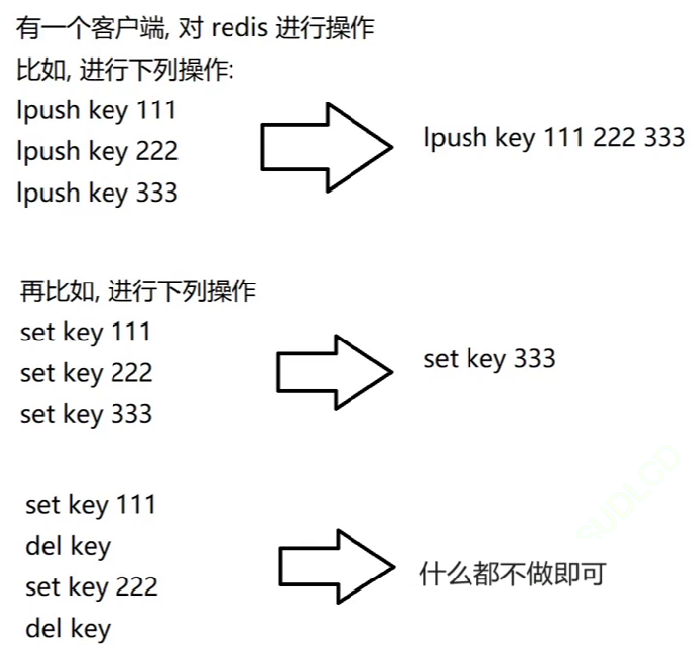
3、RDB 和 AOF 的区别和联系
- RDB 视为内存的快照,产生的内容更为紧凑,占用空间较小,恢复时速度更快。但产生 RDB 的开销较大,不适合进行实时持久化,一般用于冷备和主从复制
- AOF 视为对修改命令保存,在恢复时需要重放命令,并且有重写机制来定期压缩 AOF 文件
- RDB 和 AOF 都使用 fork 创建子进程,利用 Linux 子进程拥有父进程内存快照的特点进行持久化,尽可能不影响主进程继续处理后续命令
八、事务
- Redis 的事务和 MySQL 的事务概念上是类似的,都是把一系列操作绑定成一组,让这一组能够批量执行
- Redis 的事务和 MySQL 事务的区别
- MySQL 事务
- 原子性:把多个操作打包成一个整体(要么全都做,要么都不做)
- ⼀致性:事务执行前和执行后,数据得保持相同
- 隔离性:事务并发执行涉及到的一些问题(脏读、幻读等)
- 持久性:事务中做出的修改都会存储到硬盘中
- Redis 的事务
- 弱化的原子性:redis 没有 “回滚机制”,只能 “批量执行” 这些操作 ,不能做到 “一个失败就恢复到初始状态”,也就是无法保证执行成功(网上有的说 Redis 事务有原子性(只是打包一起执行),有的说没有原子性(打包一起执行 + 带有回滚 —— 打包一起正确执行))
- 不保证一致性:不涉及 “约束”,也没有回滚(MySQL 的一致性体现的是运行事务前和运行后,结果都是合理有效的,不会出现中间非法状态)。如果事务在执行过程中某个修改操作出现失败,就可能引起不一致的情况
- 不需要隔离性:没有隔离级别,因为不会并发执行事务(Redis 是一个单线程模型的服务器程序,所有的请求 / 事务都是 “串行” 执行的)
- 不需要持久性:Redis 本身就是内存数据库。虽然 Redis 也有持久化机制,但是否开启持久化是 redis-server 的事,和事务无关
- Redis 事务本质上是在服务器上搞了⼀个 “事务队列”,每次客户端在事务中进行一个操作,都会把命令先发给服务器,放到 “事务队列” 中,但并不会立即执行,而是在收到 EXEC 命令后,才按照顺序依次执行队列中的所有操作(在 Redis 主线程中完成的,主线程会把事务中的操作都执行完,再处理别的客户端)。因此,Redis 的事务功能相比于 MySQL 来说,是弱化很多的,只能保证事务中的这几个操作是 “连续的”,不会被别的客户端 “加塞”,仅此而已
- 为什么 Redis 不设计成和 MySQL 一样强大呢?
- MySQL 的事务付出了很大代价
- 在空间上需要花费更多的空间来存储更多的数据
- 在时间上也有更大的执行开销
- 正是因为 Redis 简单、高效的特点,才能够在分布式系统中弥补一些 MySQL 不擅长的场景
- MySQL 的事务付出了很大代价
- 什么时候需要使用到 Redis 事务呢?
- 如果需要把多个操作打包进行,使用事务是比较合适的。之前在多线程中是通过加锁的方式来避免 “插队” 的,而在 Redis 中直接使用事务即可
-
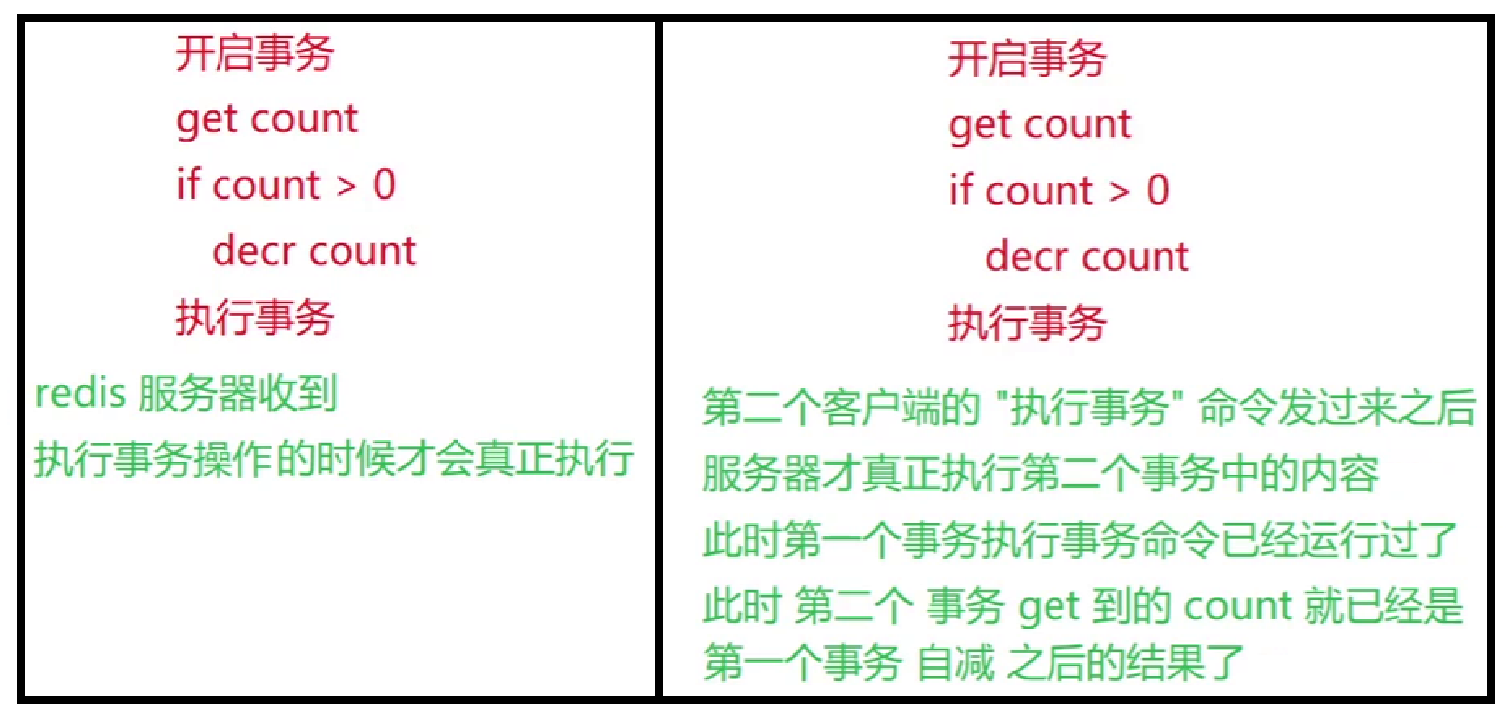
- 在上面这个场景没有加锁也能解决问题
- Redis 原生命令中确实没有类似这种条件判断,但 Redis 支持 lua 脚本,通过 lua 脚本就可以实现上述的条件判定,并且和事务一样也是打包批量执行的(lua 脚本的实现方式是 Redis 事务的进阶版本)
- 如果 Redis 是按照集群模式部署的话,是不支持事务的
- MySQL 事务
- 事务操作
- MULTI
- 开启一个事务,执行成功返回 OK
- EXEC
- 真正执行事务
- 每次添加一个操作,都会提示 "QUEUED",说明命令已经进入客户端的事务队列中。此时如果另外开一个客户端,再尝试查询这几个 key 对应的数据,是没有结果的。只有当真正执行 EXEC 时,客户端才会真正把上述操作发送给服务器,此时就可以获取到上述 key 的值了
- DISCARD
- 放弃当前事务,此时直接清空事务队列,之前的操作都不会真正执行到
- 当开启事务并给服务器发送若干个命令之后,服务器重启,此时效果就等同于 discard
- WATCH
- 在执行事务时,如果某个事务中修改的值被别的客户端修改了,此时就容易出现数据不一致的问题
- watch 在该客户端上监控一组具体的 key,看看这个 key 在事务的 multi 和 exec 之间,set key 之后,是否在外部被其它客户端修改了
- 当开启事务时,如果对 watch 的 key 进行修改,就会记录当前 key 的 “版本号”(版本号可以理解成一个整数,每次修改都会使版本变大,服务器来维护每个 key 的版本号情况)
- 在真正提交事务时,如果发现当前服务器上的 key 的版本号已经超过了事务开始时的版本号,就会让事务执行失败(事务中的所有操作都不执行)
- watch 本质上是给 exec 加一个判定条件
- exec 在执行上述事务中的命令时,此处就会做出判定。对比版本发现客户端的 key 的版本号是 0,服务器上的版本号是 1,版本不一致,说明有其他客户端在事务中间修改了 key,说明事务被取消了,于是执行 set 命令时就没有真正执行
- watch 的实现原理
- watch 的实现类似于一个 “乐观锁”
- 乐观锁(成本低):加锁之前就有一个心理预期,预期接下来锁冲突的概率比较低
- 悲观锁(成本高):加锁之前就有一个心理预期,预期接下来锁冲突(两个线程针对同一个锁加锁,一个能加锁成功,另一个就得阻塞等待)的概率比较高
- 锁冲突概率高和冲突概率低,意味着接下来要做的工作是不一样的
- C++ Linux 中涉及到的锁 mutex / std::mutex 都是悲观锁,Java synchronized 则是可以在悲观和乐观之间自适应
- watch 的实现类似于一个 “乐观锁”
- UNWATCH
- 取消对 key 的监控,相当于 WATCH 的逆操作
- MULTI
九、主从复制(重点理解流程和原理)
- 在分布式系统中为了解决单点问题(某个服务器程序只有一个节点(只用一个物理服务器来部署这个服务器程序)可用性不高:如果这个机器挂了意味着服务中断了;支持的并发量比较有限),通常会把数据复制多个副本部署到其它服务器,满足故障恢复和负载均衡等需求。在分布式系统中,往往希望有多个服务器来部署 Redis 服务,从而构成一个 Redis 集群,此时就可以让这个集群给整个分布式系统中的其他服务提供更稳定、更高效的数据存储功能
- 存在几种 Redis 的部署方式
- 主从模式
- 从节点上的数据要随着主节点变化,和主节点保持一致。从节点是主节点的副本,在该模式中,从节点上的数据不允许修改,只能读取数据。后续如果有客户端来读取数据,就可以从所有节点中随机挑选一个节点,给这个客户端提供读取数据的服务
- 引入更多的计算资源,那么能够支撑的并发量也就大幅提高了。如果是挂掉了某个从节点是没有什么影响的,此时继续从主节点(如果是主节点挂掉了,那还是有一定影响的,因为从节点只能读数据,如果需要写数据就没得写了)或者其它的从节点读取数据,得到的效果是完全相同的
- 主从模式主要是针对 “读操作” 进行并发量和可用性的提高,而写操作无论是可用性还是并发都是非常依赖主节点的,但主节点又不能设置多个。在实际业务场景中,读操作往往是比写操作更频繁的
- 主从结构是分布式系统中比较经典的一种结构。不仅是 Redis 支持,MySQL 等其它的常用组件也是支持的
- 主从复制的特点
- Redis 通过复制功能实现主节点的多个副本
- 主节点用来写,从节点用来读,这样做可以降低主节点的访问压力
- 复制支持多种拓扑结构,可以在适当的场景选择合适的拓扑结构
- 复制分为全量复制,部分复制和实时复制
- 主从节点之间通过心跳机制保证主从节点通信正常和数据⼀致性
- 主从 + 哨兵模式
- 集群模式
- 主从模式
- Redis 提供了复制的功能,实现了相同数据的多个 Redis 副本。复制功能是高可用 Redis 的基础,哨兵和集群都是在复制的基础上构建的
- 配置
- 建立复制
- 如何在一个云服务器上实现分布式呢?
- 可以在一个云服务器主机上运行多个 redis-server 进程,此处需要保证多个 redis-server 的端口是不相同的
- 如何去指定 redis-server 的端口呢?
- 在启动程序时,通过命令行来指定端口号,--port 选项
- 直接在配置文件中来设定端口
- 将 redis.conf 配置文件复制两份:slave1.conf 和 slave2.conf(准备一个主节点和两个从节点)
- 以 6379 为主节点,6380 和 6381 为从节点
- 修改配置主要是修改从机的配置,主机配置不变
- 通过命令行启动上述两个 Redis 实例作为从 Redis,并且通过 ps aux | grep redis 确保两个 Redis 均已正确启动
- 当前这几个节点并没有构成主从结构,而是各自为政。要想成为主从结构,还需要进一步的进行配置
- 通过 redis-cli 可以连接主 Redis 实例,通过 redis-cli -p 6380 连接从 Redis,观察复制关系
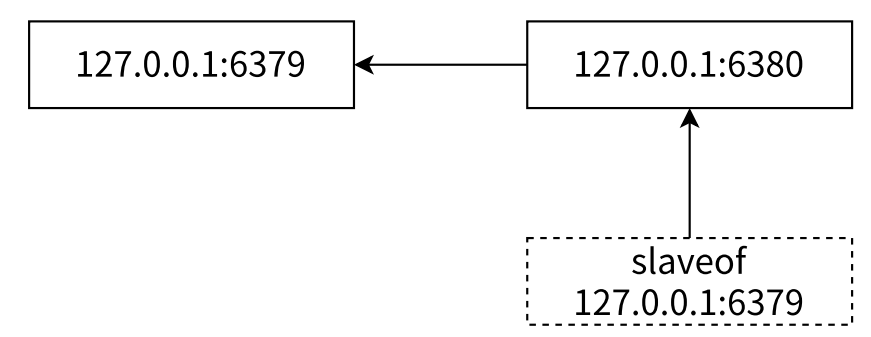
- 参与复制的 Redis 实例划分为主节点和从节点。每个从节点只能有⼀个主节点,而一个主节点可以同时具有多个从节点。复制的数据流是单向的,只能由主节点到从节点。配置复制的方式有 3 种
- 在配置文件中加入 slaveof {masterHost} {masterPort} 随 Redis 启动生效
- 在 redis-server 启动命令时加入 --slaveof {masterHost} {masterPort} 生效
- 直接使用 redis 命令:slaveof {masterHost} {masterPort} 生效
- 通过 kill -9 进程的方式来停止 redis-server 是和通过直接运行 redis-server 命令的方式搭配使用的,而如果是使用 service redis-server start 这种方式启动的,就必须使用 service redis-server stop 来进行停止,此时如果使用 kill -9 的方式停止,那么在 kill 掉之后,这个 redis-server 进程还能自动启动
- 服务器就是要稳定性和高可用,但服务器上的某些程序也难以避免出现挂了的情况。如果服务进程挂了后能自动重启进程,那么对于整体的服务不会产生严重影响
- 复制已经工作后,针对主节点 6379 这边数据产生的任何修改,从节点都能立即感知到并同步,就是那些 tcp 连接产生的效果。其次,从节点不能写入数据
- Redis 主从节点复制过程
-
- 可以通过 info replication 命令查看复制相关状态
- 主节点 6379 复制状态信息
- 主节点上会源源不断地收到 “修改数据” 请求,从节点就需要从主节点这里同步这些修改请求。从节点和主节点之间的数据同步不是瞬间完成的,offset 就相当于是从节点和主节点之间同步数据的进度,lag 表示延迟情况
- 从节点 6380 复制状态信息
- repl_backlog:挤压缓冲区,支持部分同步机制的实现
- 主节点 6379 复制状态信息
-
- 如何在一个云服务器上实现分布式呢?
- 断开复制
- slaveof 命令不仅可以建立复制,还可以在从节点执行 slaveof no one 来断开与主节点复制关系
- 断开复制主要流程
- 断开与主节点复制关系
- 从节点晋升为主节点
- 从节点断开复制后,它就不再从属于其它节点了,但并不会抛弃原有数据,后续主节点如果针对数据做出修改,从节点无法再自动获取主节点上的数据变化
- 通过 slaveof 命令还可以实现切主操作,将当前从节点的数据源切换到另⼀个主节点。执行 slaveof {newMasterIp} {newMasterPort} 命令即可
- 切主操作主要流程
- 断开与旧主节点复制关系
- 与新主节点建立复制关系
- 删除从节点当前所有数据
- 从新主节点行复制操作
- 切主操作主要流程
-
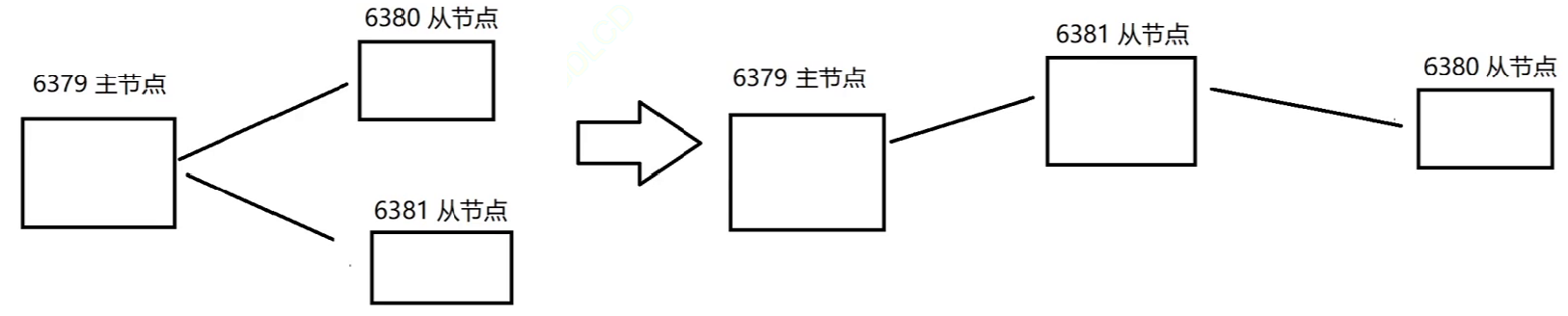
- 此时的 6381 只是看起来像是个主节点,但实际上并不是,它仍然是个从节点,只是作为 6380 同步数据的来源,自身仍然是不能修改数据的
- 前面是通过 salveof 修改了主从结构,这个修改是临时性的。如果重新启动 Redis 服务器,仍然会按照最初在配置文件中设置的内容来建立主从关系
- 安全性
- 对于数据比较重要的节点,主节点会通过设置 requirepass 参数进行密码验证,这时所有的客户端访问必须使用 auth 命令实行校验。从节点与主节点的复制连接是通过⼀个特殊标识的客户端来完成,因此需要配置从节点的 masterauth 参数与主节点密码保持一致,这样从节点才可以正确地连接到主节点并发起复制流程
- 只读
- 默认情况下,从节点使用 slave-read-only=yes 配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不⼀致,所以建议线上不要修改从节点的只读模式
- 传输延迟
- 主节点和从节点之间通过网络来传输(TCP),TCP 内部支持 nagle 算法(默认开启),开启后会增加 tcp 的传输延迟,节省网络带宽;关闭就会减少 tcp 的传输延迟,增加网络带宽,从节点能够更快速的和主节点进行同步,其目的和 tcp 的捎带应答是一样的,针对小的 tcp 数据报进行合并,减少包的个数。主从节点一般部署在不同机器上,复制时的网络延迟就成为需要考虑的问题
- 当关闭时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗,适用于主从之间的网络环境良好的场景,如同机房部署
- 当开启时,主节点会合并较小的 TCP 数据包从而节省带宽。默认发送时间间隔取决于 Linux 的内核,一般默认为 40 毫秒。这种配置节省了带宽但增大主从之间的延迟,适用于主从网络环境复杂的场景,如跨机房部署
- 主节点和从节点之间通过网络来传输(TCP),TCP 内部支持 nagle 算法(默认开启),开启后会增加 tcp 的传输延迟,节省网络带宽;关闭就会减少 tcp 的传输延迟,增加网络带宽,从节点能够更快速的和主节点进行同步,其目的和 tcp 的捎带应答是一样的,针对小的 tcp 数据报进行合并,减少包的个数。主从节点一般部署在不同机器上,复制时的网络延迟就成为需要考虑的问题
- 建立复制
- 拓扑
- Redis 的复制拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为 3 种
- 一主一从结构
- 一主一从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持
-
- 当应用写命令并发量较高且需要持久化时,此时也是会给主节点造成一定压力,那么可以只在从节点上开启 AOF,这样既可以保证数据安全性,同时也避免了持久化对主节点的性能干扰。但这种设定方式有一个严重缺陷:当主节点关闭持久化功能时,如果主节点宕机要避免自动重启操作,否则就会丢失数据,进一步的主从同步也会把从节点的数据也给删了
- 改进办法:当主节点挂了后,需要让主节点从从节点这里获取 AOF 文件,再重新启动
- 一主一从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持
- 一主多从结构
- 在实际开发中,读请求往往远超过写请求,所以一般会选择一主多从结构
- 一主多从结构(星形结构)使得应用端可以利用多个从节点实现读写分离
-
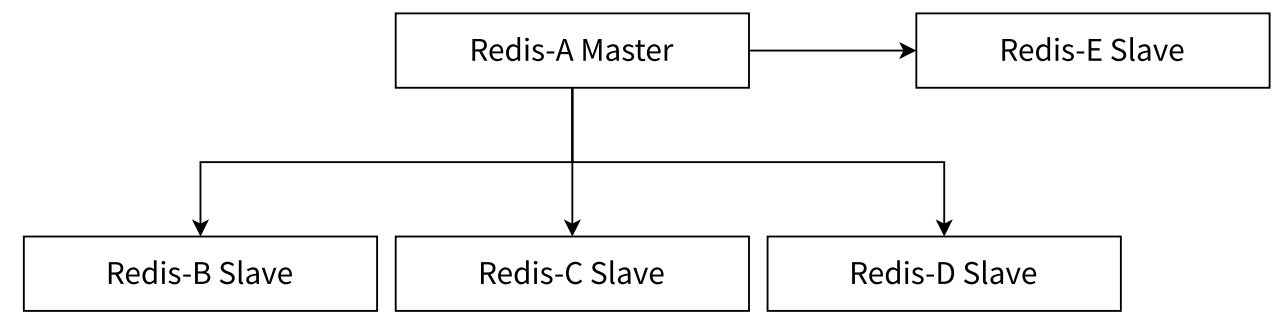
- 主节点上的数据发生改变时,就会把改变的数据同时同步给所有的从节点
- 对于读比重较大的场景,可以把读命令负载均衡到不同的从节点上来分担压力。同时一些耗时的读命令可以指定一台专门的从节点执行,避免破坏整体的稳定性
- 对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从而加重主节点的负载
- 树形主从结构
- 树形主从结构(分层结构)使得从节点不仅可以复制主节点数据,同时可以作为其它从节点的主节点继续向下层复制。通过引入复制中间层,可以有效降低主节点按负载和需要传送给从节点的数据量
-
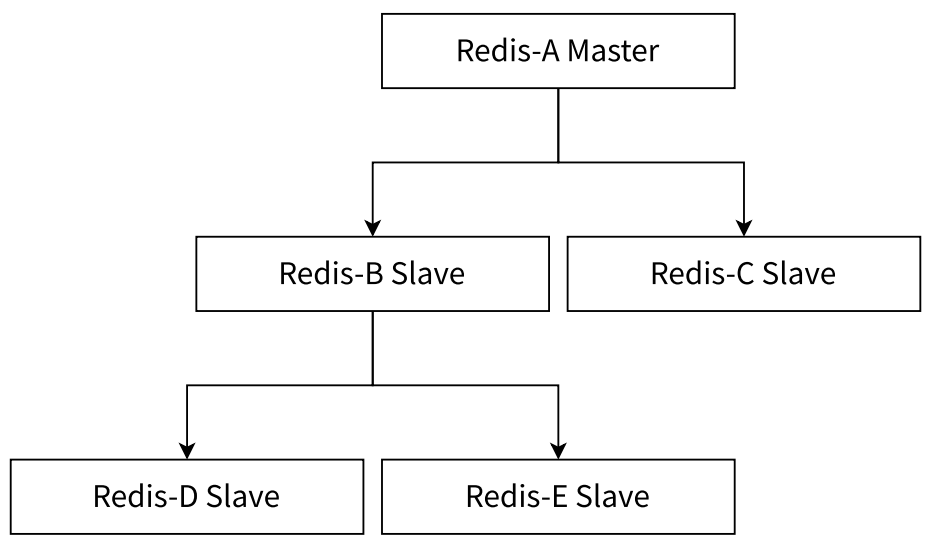
- 数据写如节点 A 之后会同步给 B 和 C 节点,B 节点进一步把数据同步给 D 和 E 节点。当主节点需要挂载等多个从节点时,为了避免对主节点的性能干扰,可以采用这种拓扑结构。此时,主节点就不需要很高的网卡带宽了,但一旦数据进行修改,同步的延时比之前的结构更长
- 一主一从结构
- Redis 的复制拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为 3 种
- 原理
- 复制过程
- 主从节点建立复制过程大致分为 6 个过程
-
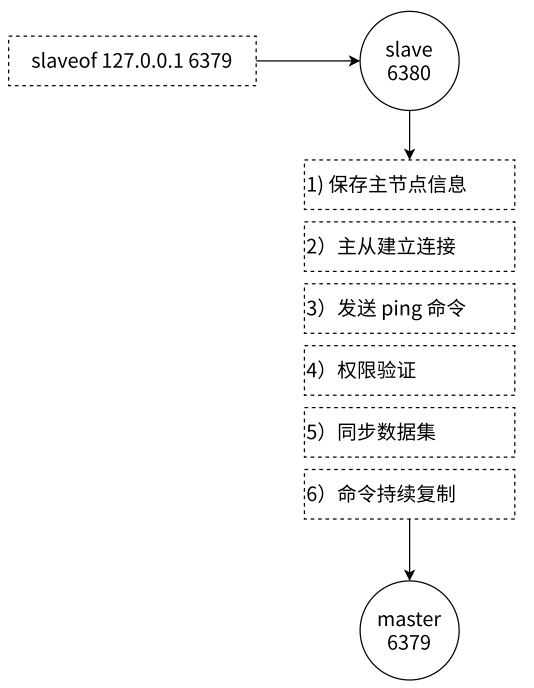
- 保存主节点(master)的信息
- 开始配置主从同步关系之后,从节点只保存主节点的地址信息,此时建立复制流程还没有开始,在从节点 6380 执行 info replication
- 主节点的 ip 和 port 被保存下来,但是主节点的连接状态是下线状态
- 从节点内部通过每秒运行的定时任务维护复制相关逻辑
- 当定时任务发现存在新的主节点后,会尝试与主节点建立基于 TCP 的网络连接(三次握手,是为了验证(系统层面)通信双方是否能够正确读写数据)。如果从节点无法建立连接,定时任务会无限重试直到连接成功或者用户停止主从复制
- 发送 ping 命令
- 连接建立成功之后,从节点通过 ping 命令确认主节点在应用层上是否能够正常工作。如果 ping 命令的结果 pong 回复超时,从节点会断开 TCP 连接,等待定时任务下次重新建立连接
- 权限验证
- 如果主节点设置了 requirepass 参数,则需要密码验证,从节点通过配置 masterauth 参数来设置密码。如果验证失败,则从节点的复制将会停止
- 同步数据集
- 对于首次建立复制的场景,主节点会把当前持有的所有数据全部发送给从节点,这步操作基本是耗时最长的,所以又划分称两种情况:全量同步和部分同步
- 命令持续复制
- 当从节点复制了主节点的所有数据后,针对之后的修改命令,主节点会持续把命令发送给从节点,从节点执行修改命令,保证主从数据的一致性
-
- 主从节点建立复制过程大致分为 6 个过程
- 数据同步 psync
- Redis 使用 psync 命令(不需要手动执行,Redis 服务器会在建立好主从同步关系之后自动执行。从节点负责执行 psync,从节点从主节点这边拉取数据)完成主从数据同步,同步过程分为:全量复制和部分复制
- 全量复制:一般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点。因为补发的数据远小于全量数据,可以有效避免全量复制的过高开销
- PSYNC 的语法格式
- PSYNC replicationid offset
- 如果 replicationid 设为 ? 并且 offset 设为 -1,就是在尝试进行全量复制
- 如果 replicationid offset 设置为具体数值,就是在尝试进行部分复制
- replicationid / replid(复制 id)
- 主节点的复制 id。主节点重新启动或者从节点晋级成主节点都会生成⼀个 replicationid(同一个节点每次重启生成的 replicationid 都是不同的)
- 从节点在和主节点建立复制关系之后,就会获取到主节点的 replicationid
- 通过 info replication 即可看到 replicationid
- replication id VS run id
- 在一个 Redis 服务器上,replication id 和 run id 都是存在的
- 每个节点的 run id 都不相同,而具有主从关系的节点的 replid 是相同的
- replid + offset 共同标识了一个数据集合,这个结构体包含了 Redis 服务器各自重要的数据,标识一次 Redis 的 “运行”
- runid 主要是用在支撑实现 Redis 哨兵这个功能的,和主从复制没什么关系
- 在一个 Redis 服务器上,replication id 和 run id 都是存在的
- master_replid 和 master_replid2
- 每个节点需要记录两组 master_replid
- 假设有一个主节点 A 和一个从节点 B,从节点 B 获取到 A 的 replid。如果 A 和 B 在通信过程中出现了一些网络抖动,那么 B 可能会以为 A 挂了,B 自己就会成为主节点,于是 B 给自己生成一个 master_replid,此时 B 也会记得旧的 replid,也就是会使用 master_replid2 来保存之前 A 的 master_replid。后续如果网络恢复稳定了,B 就可以根据 master_replid2 找回之前的主节点(该过程要么手动干预,要么通过哨兵机制可以自动完成这个过程)。后续如果网络没有恢复,B 就按照新的 master_replid 自成一派,继续处理后续的数据
- offset(偏移量)
- 参与复制的主从节点都会维护自身复制偏移量。主节点在处理完写入命令后,会把命令的字节长度做累加记录。从节点在接受到主节点发送的命令后,也会累加记录自身的偏移量
- 从节点每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量
- 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致
- 复制偏移量维护
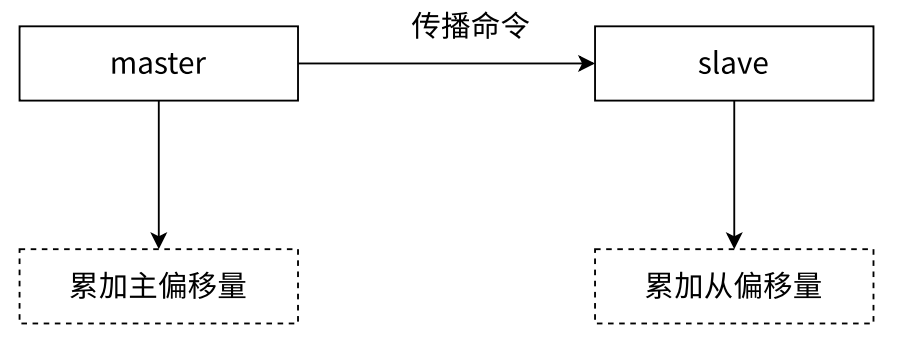
- replid + offset 共同标识了⼀个 “数据集”。如果两个节点的 replid 和 offset 都相同,则这两个节点上持有的数据一定相同
- psync 运行流程
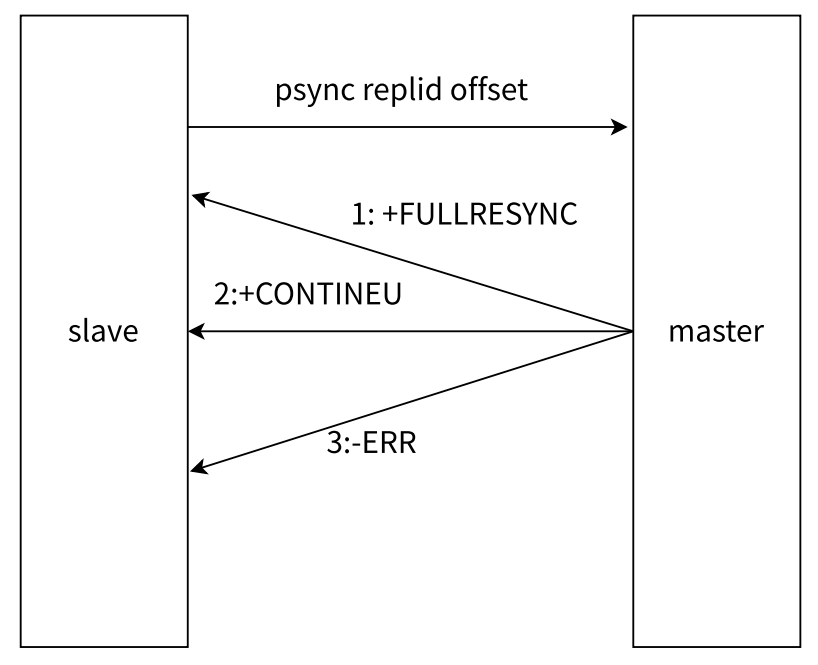
- 从节点发送 psync 命令给主节点,replid 和 offset 的默认值分别是 ? 和 -1
- 并不是说从节点索要哪一部分,主节点就一定给哪一部分,而是主节点根据 psync 参数和自身数据情况决定响应结果
- 如果回复 +FULLRESYNC replid offset,则从节点需要进行全量复制流程
- 如果回复 +CONTINEU,从节点进行部分复制流程
- 如果回复 -ERR,说明 Redis 主节点版本过低,不支持 psync 命令(可以使用 sync 代替),从节点可以使用 sync 命令进行全量复制
- psync 一般不需要手动执行,Redis 会在主从复制模式下自动调用执行
- sync 会阻塞 redis server 处理其他请求,psync 则不会
- 复制偏移量维护
- Redis 使用 psync 命令(不需要手动执行,Redis 服务器会在建立好主从同步关系之后自动执行。从节点负责执行 psync,从节点从主节点这边拉取数据)完成主从数据同步,同步过程分为:全量复制和部分复制
- 全量复制
- 全量复制是 Redis 最早支持的复制方式,也是主从第一次建立复制时必须经历的阶段
- 进行全量复制的时间点
- 首次和主节点进行数据同步
- 主节点不方便进行部分复制时
- 全量复制的运行流程
-
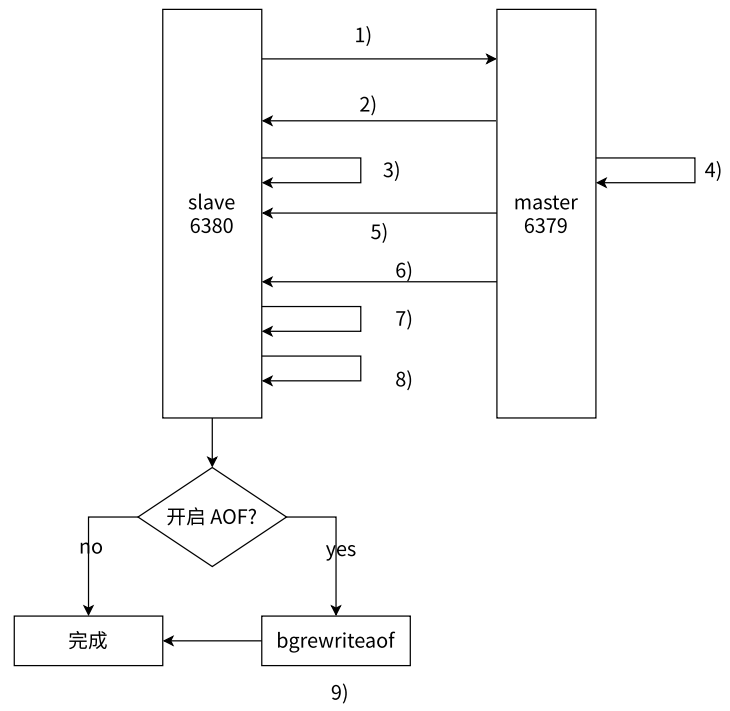
- 从节点发送 psync 命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的运行 ID 和复制偏移量,所以发送 psync ? -1
- 主节点根据命令解析出要进行全量复制,回复 +FULLRESYNC 响应
- 从节点接收主节点的运行信息进行保存
- 主节点执行 bgsave 进行 RDB 文件的持久化(不能使用已有的 RDB 文件,而是要重新生成,因为已有的 RDB 文件可能和当前最新数据存在较大差异)
- 主节点发送 RDB 文件给从节点,从节点保存 RDB 数据到本地硬盘(RDB 文件更节省空间)
- 主节点将从生成 RDB 到接收完成期间执行的写命令写入缓冲区中,等从节点保存完 RDB 文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照 RDB 的二进制格式追加写入到收到的 RDB 文件中,保持主从一致性
- 从节点清空自身原有旧数据,加载 RDB 文件得到与主节点一致的数据
- 如果从节点加载 RDB 完成后,开启了 AOF 持久化功能,那么在前面加载数据的过程中,从节点就会产生很多 AOF 日志。由于当前收到大批量数据,此时产生的 AOF 日志可能会存在一定的冗余信息,因此针对 AOF 日志进行 bgrewrite 操作,得到最近的 AOF 文件也是必要的过程
-
- 通过分析全量复制的所有流程,会发现全量复制是一件高成本的操作:主节点 bgsave 的时间,RDB 在网络传输的时间,从节点清空旧数据的时间,从节点加载 RDB 的时间等,所以应该尽可能避免对已经有大量数据集的 Redis 进行全量复制
- 有磁盘复制 VS 无磁盘复制(diskless)
- 进行全量复制需要主节点生成 RDB 文件到主节点的磁盘中,再把磁盘上的 RDB 文件发送给从节点
- 主节点在执行 RDB 生成流程时,不会生成 RDB 文件到磁盘中了,而是直接把生成的 RDB 数据通过网络发送给从节点,节省了⼀系列的写硬盘和读硬盘的操作开销
- 从节点之前也是先把收到的 RDB 数据写入到硬盘中,再进行加载,现在也可以省略这个过程,直接把收到的数据进行加载
- 即使引入了无硬盘模式,整个操作仍然是比较重量、耗时的,网络传输(大规模数据全量复制)的过程是没有办法省的。相比于网络传输来说,读写硬盘的开销是很小的
- 部分复制
- 需要部分复制的时刻
- 从节点之前已经从主节点上复制过数据了。因为网络抖动或者从节点重启,从节点需要重新从主节点这边同步数据,此时看看是否能够只同步一小部分,因为大部分数据都是一致的
- 部分复制主要是 Redis 针对全量复制的过高开销做出的一种优化措施,使用 psync replicationId offset 命令实现。当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区存在数据则直接发送给从节点,就可以保持主从节点复制的一致性。补发的这部分数据一般远远小于全量数据,所以开销很小
- 部分复制过程
-
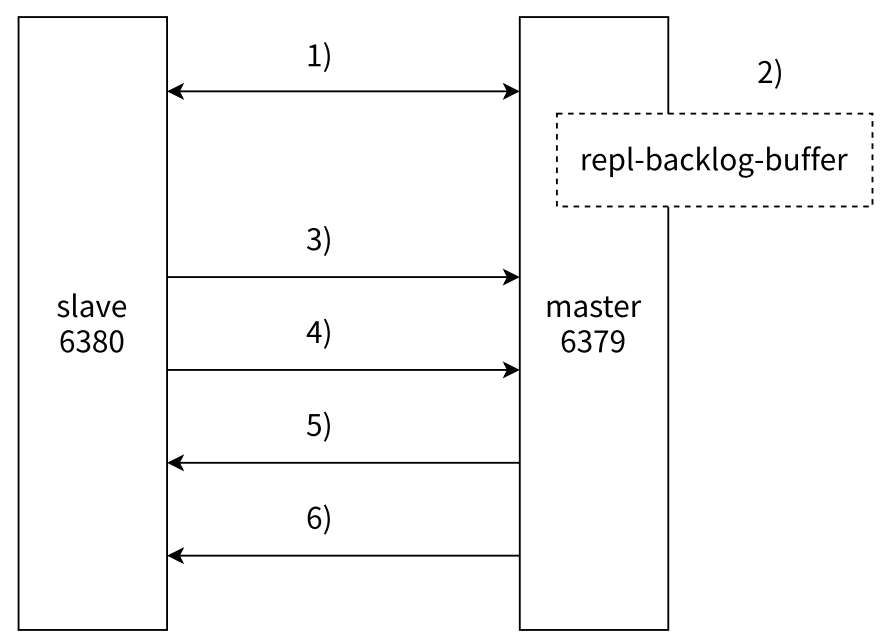
- 当主从节点之间出现网络中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并终端复制连接
- 主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区(一个内存中简单的队列,会记录最近一段时间修改的数据,因为总量有限,随着时间推移就会把之前的旧数据逐渐删除)中
- 当主从节点网络恢复后,从节点再次连上主节点
- 从节点将之前保存的 replicationId 和 复制偏移量(offset,主节点看这个进度来判断它是否在当前的积压缓冲区内,如果是则可以直接进行部分复制)作为 psync 的参数发送给主节点,请求进行部分复制
- 主节点接到 psync 请求后,进行必要的验证,随后根据 offset 去复制积压缓冲区查找合适的数据,并响应 +CONTINUE 给从节点
- 主节点将需要从节点同步的数据发送给从节点,最终完成一致性
-
- 复制积压缓冲区
- 复制积压缓冲区是保存在主节点上的一个固定长度的队列,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区
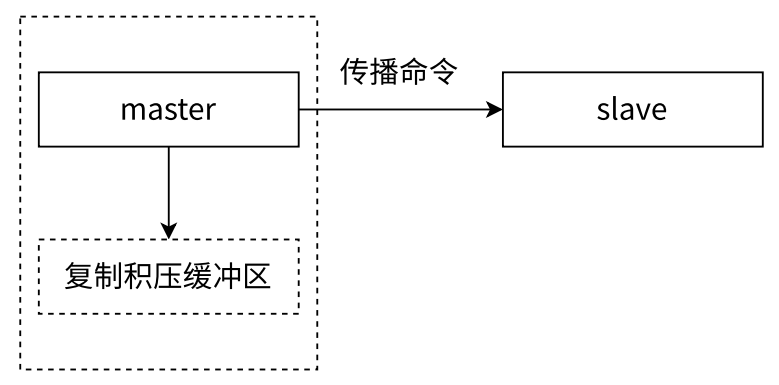
- 由于缓冲区本质上是定长队列,所以能实现保存最近已复制数据的功能,用于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息可以通过主节点的 info replication 查看
- 如果当前从节点需要的数据已经超出了主节点的积压缓冲区范围,则无法进行部分复制,只能进行全量复制
- 复制积压缓冲区是保存在主节点上的一个固定长度的队列,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区
- 需要部分复制的时刻
- 实时复制
- 主从节点在建立复制连接后,主节点会把自己收到的修改操作,通过 tcp 长连接的方式,源源不断的传输给从节点,从节点会根据这些请求来同时修改自身数据,从而保持和主节点数据的一致性。在进行实时复制时需要保证连接处于可用状态,所以这样的长连接需要通过心跳包的方式来维护连接状态(这里的心跳是指应用层自己实现的心跳,而不是 TCP 自带的心跳)
- 主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信
- 主节点默认每隔 10 秒对从节点发送 ping 命令,从节点收到就返回 pong,以此来判断从节点的存活性和连接状态
- 从节点默认每隔 1 秒向主节点发送一个 replconf ack {offset} 命令,给主节点上报自身当前的复制偏移量
- 如果主节点发现从节点通信延迟超过 repl-timeout 配置的值,则判定从节点下线,断开复制客户端连接。从节点恢复连接后,心跳机制继续进行
- 主从节点在建立复制连接后,主节点会把自己收到的修改操作,通过 tcp 长连接的方式,源源不断的传输给从节点,从节点会根据这些请求来同时修改自身数据,从而保持和主节点数据的一致性。在进行实时复制时需要保证连接处于可用状态,所以这样的长连接需要通过心跳包的方式来维护连接状态(这里的心跳是指应用层自己实现的心跳,而不是 TCP 自带的心跳)
- 复制过程
- 关于从节点何时晋升成主节点的问题
- 从节点和主节点之间断开连接有 2 种情况
- 从节点主动和主节点断开连接:slaveof no one(此时,从节点就能够晋升成主节点),意味着要主动修改 Redis 的组成结构
- 主节点挂了(此时从节点不会晋升成主节点的,必须通过人工干预的方式来恢复主节点)。这种是脱离掌控的,是一个高可用的典型问题
- 从节点和主节点之间断开连接有 2 种情况
- 关于 redis 主节点无法重启的问题
- 从节点是通过手动启动的方式运行的,此时在 root 用户下启动 redis 服务器,于是生成的 aof 文件也就是 root 用户的文件
- 通过 service redis-server start 启动的 redis 服务器是通过一个 redis 用户来启动的,主要是担心通过 root 启动 redis 权限太高,一旦 redis 被黑客攻破,后果比较严重。所以,redis server 需要安装可读可写的方式打开这个 aof 文件,而这个文件对于 root 之外的用户只有读权限
- 解决方案:将多个 Redis 服务器生成的文件给区分开,也就是把这多个 Redis 的工作目录给区分开:修改配置文件中的 dir 选项
- 停止之前的 Redis 服务器
- 删除之前工作目录下已经生成的 aof 文件或者通过 chown 命令修改 aof 文件所属的用户
- 给从节点创建出新的目录,作为从节点的工作目录,并且修改从节点的配置文件,设定新的目录为工作目录
- 启动 redis 服务器,从节点有了自己的 rdb 文件和 aof 文件
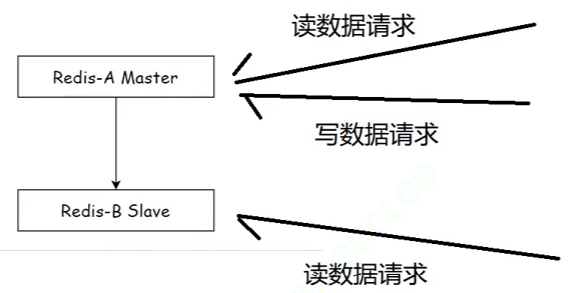
十、哨兵 Sentinel(重点理解流程和原理)
- Redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工进行主从切换,同时大量的客户端需要被通知切换到新的主节点上,对于上了一定规模的应用来说,这种方案是无法接受的,于是 Sentinel(哨兵)来解决这个问题
- 基本概念
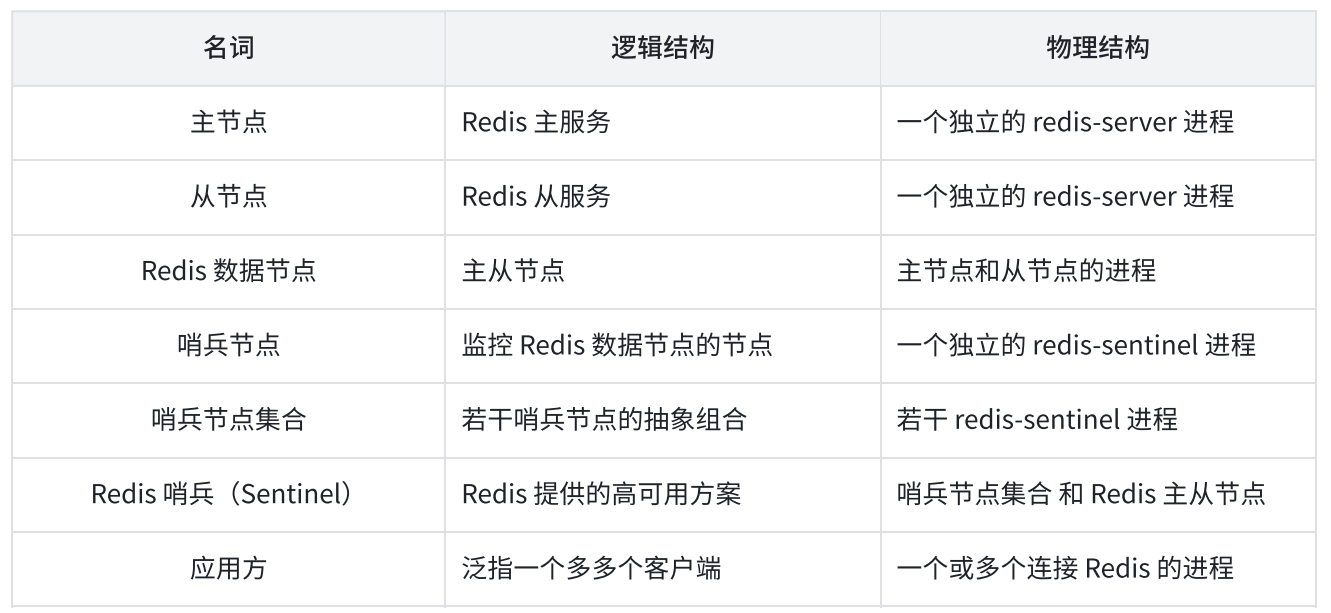
- Redis Sentinel 相关名词解释
-
- Redis Sentinel 是 Redis 的高可用实现方案,在实际的生产环境中,对提高整个系统的高可用是非常有帮助的
- 主从复制的问题
- Redis 的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到 2 个作用
- 作为主节点的⼀个备份,⼀旦主节点出了故障不可达的情况,从节点可以作为后备顶上来,并保证数据尽量不丢失(主从复制表现为最终一致性)
- 从节点可以分担主节点上的读压力,让主节点只承担写请求的处理,将所有的读请求负载均衡到各个从节点上
- 但主从复制模式并不是万能的,它同样遗留下几个问题
- 主节点发生故障时,进行主备切换的过程是复杂的,需要完全的人工参与,导致故障恢复时间无法保障
- 高可用问题,即 Redis 哨兵主要解决的问题
- 人工恢复主节点故障
- Redis 主节点故障后需要进行的操作
-
- 实际开发过程中,对于服务器后端开发,监控程序是非常重要的。服务器要求要有比较高的可用性,而服务器长期运行总会出现一些意外,但也没法全靠人工来盯着这些服务器运行。此时就可以写一个程序,用程序来盯着服务器的运行状态(监控程序,往往还需要搭配报警程序来发现服务器的运行出现状态异常)
-
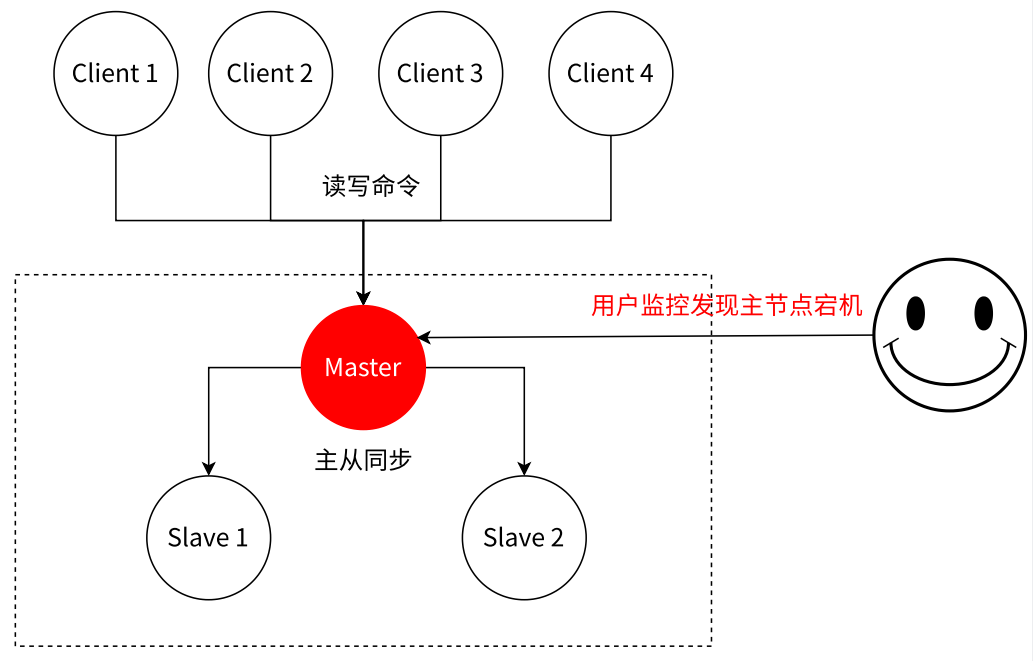
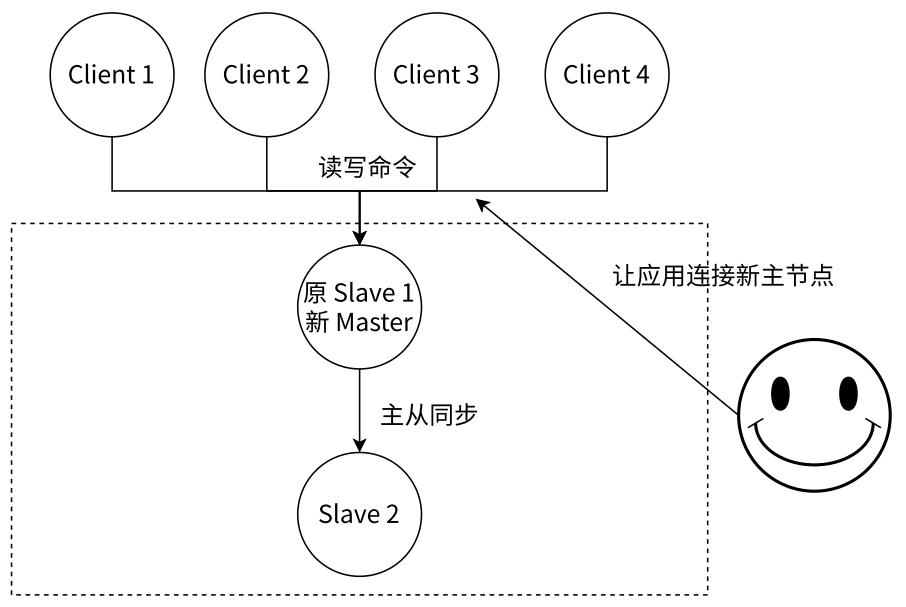
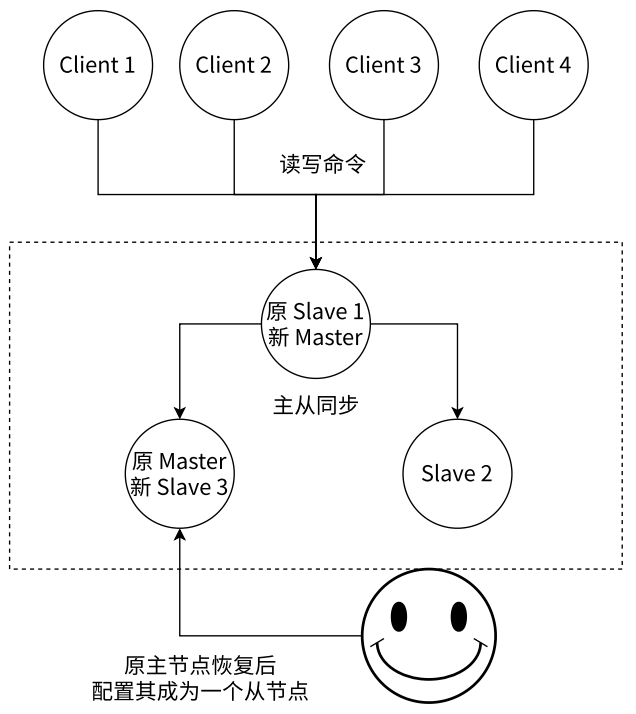
- 从所有节点中选择⼀个(此处选择了 slave 1)执行 slaveof no one,使其作为新的主节点
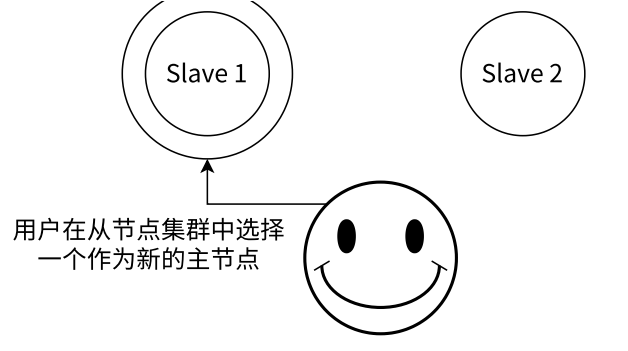
- 让剩余从节点(此处为 slave 2)执行 slaveof {newMasterIp} {newMasterPort},连上新的主节点,从新的主节点开始数据同步
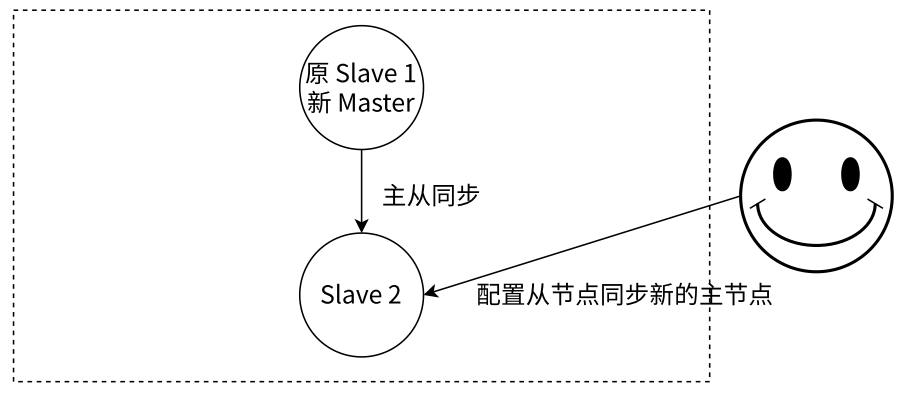
- 告知客户端(修改客户端配置),让客户端能够连接新的主节点,用来完成修改数据的操作,需要更新应用方连接的主节点信息到 {newMasterIp} {newMasterPort}
- 如果原来挂了的主节点恢复,执行 slaveof {newMasterIp} {newMasterPort},让其成为⼀个从节点,挂到这组机器中
- 上述过程基本需要人工介入,无法被认为架构是高可用的,而这就是 Redis Sentinel 所要做的
-
- Redis 主节点故障后需要进行的操作
- 主节点可以将读压力分散出去,但写压力 / 存储压力是无法被分担的,还是受到单机的限制
- 存储分布式的问题,留给 Redis 集群去解决
- 主节点发生故障时,进行主备切换的过程是复杂的,需要完全的人工参与,导致故障恢复时间无法保障
- Redis 的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到 2 个作用
- 哨兵自动恢复主节点故障
- 当主节点出现故障时,Redis Sentinel 能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用
- Redis Sentinel 是一个分布式架构,其中包含若干个 Sentinel 节点和 Redis 数据节点,每个 Sentinel 节点会对数据节点和其余 Sentinel 节点进行监控,当它发现节点不可达时,会对节点做下线表示。如果下线的是主节点,它还会和其他的 Sentinel 节点进行协商,当大多数 Sentinel 节点对主节点不可达这个结论达成共识,它们会在内部选举出一个领导节点来完成自动故障转移的工作,同时将这个变化实时通知给 Redis 应用方(整个过程是完全自动的,不需要人工介入)
- 这里的分布式架构是指:Redis 数据节点、Sentinel 节点集合、客户端分布在多个物理节点上,不要与 Redis Cluster 分布式混淆
- Redis Sentinel 架构
-
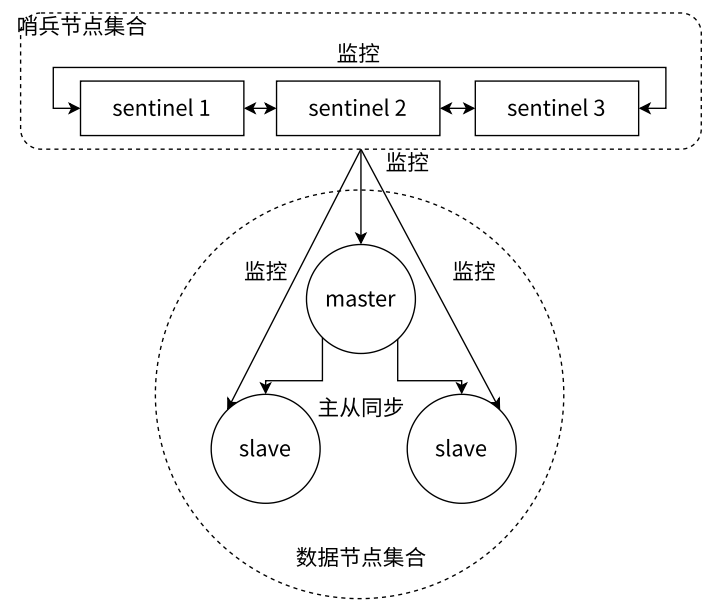
- Redis Sentinel 相比于主从复制模式多了若干单独的(建议保持奇数,最少应该是 3 个)Sentinel 节点用于实现监控数据节点,哨兵节点会定期监控(这些进程之间会建立 tcp 长连接,定期发送心跳包)所有节点(包含数据节点和其他哨兵节点)
- 针对主节点故障的情况,故障转移流程
- 主节点故障,从节点同步连接中断,主从复制停止
- 哨兵节点通过定期监控发现主节点出现故障。哨兵节点与其他哨兵节点进行协商,达成多数认同主节点故障的共识。这步主要是防止:出故障的不是主节点,而是发现故障的哨兵节点,该情况经常发生于哨兵节点的网络被孤立的场景下
- 哨兵节点之间使用 Raft 算法选举出⼀个 leader(领导角色),由该节点负责后续的故障转移工作
- 哨兵领导者开始执行故障转移:leader 从节点中选择⼀个作为新的主节点,挑选出新的主节点之后,哨兵节点就会自动控制这个被选中的节点,执行 slaveof no one,并且控制其他从节点,修改 slaveof 到新的主节点上,哨兵节点会自动通知客户端程序,告知新的主节点是谁,并且后续客户端再进行写操作,就会针对新的节点进行操作
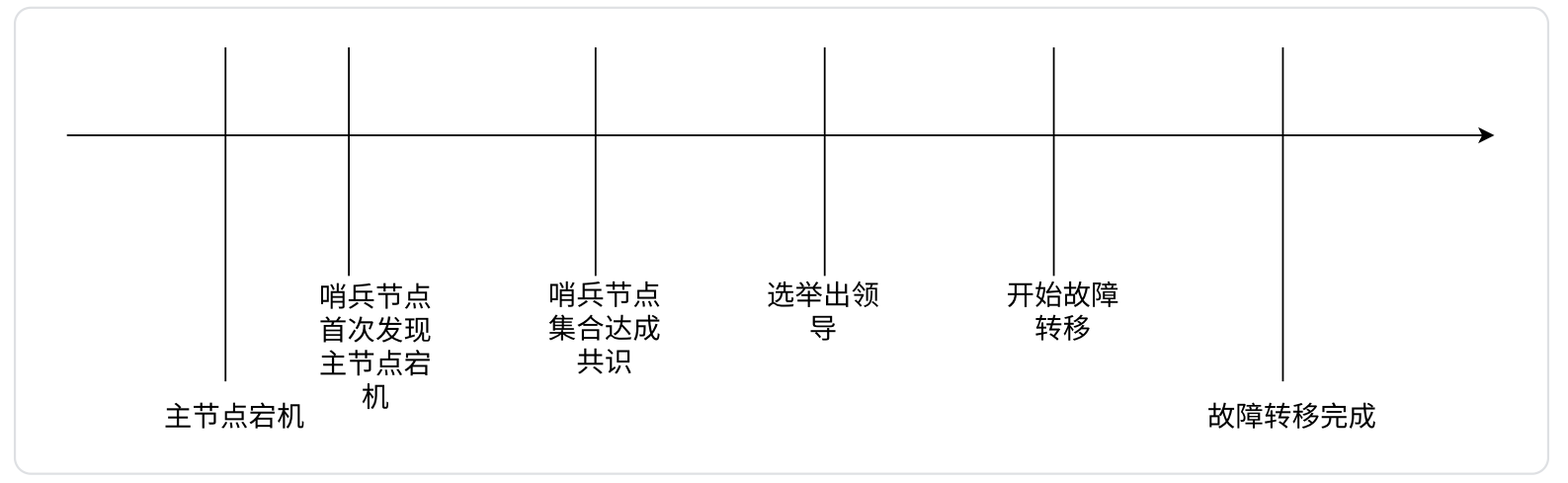
- 可以看出 Redis Sentinel 具有以下几个功能
- 监控:Sentinel 节点会定期检测 Redis 数据节点、其余哨兵节点是否可达
- 故障转移:实现从节点晋升为主节点,并维护后续正确的主从关系
- 通知:Sentinel 节点会将故障转移的结果通知给应用方
- 可以看出 Redis Sentinel 具有以下几个功能
- 只有一个 Redis 哨兵节点也是可以的,但万一这个哨兵节点挂了,后续 Redis 节点也挂了,就无法进行自动回复的过程,而且出现误判的概率也比较高,毕竟网络传输数据容易出现抖动、延迟或者丢包等情况,只有一个哨兵节点出现上述情况影响较大
- 基本原则:在分布式系统中,应该避免使用 单点
-
- Redis Sentinel 相关名词解释
- 重新选举
- 哨兵存在的意义:能够在 Redis 主从结构出现问题时,比如主节点挂了,哨兵节点自动重新选出一个主节点来代替之前挂了的节点,保证整个 Redis 仍然是可用状态
- redis-master 宕机之后
- 手动把 redis-master 干掉
- 当主节点挂了后,哨兵节点就开始工作了
- 可以看到哨兵发现了主节点 sdown,进一步的由于主节点宕机得票达到 3/2,达到法定得票,于是 master 被判定为 odown
- 主观下线(Subjectively Down,SDown):哨兵感知到主节点没心跳了,判定为主观下线
- 客观下线(Objectively Down,ODown):多个哨兵达成一致意见,才能认为 master 确实下线了
- 接下来,哨兵们挑选出了⼀个新的 master
- 可以看到哨兵发现了主节点 sdown,进一步的由于主节点宕机得票达到 3/2,达到法定得票,于是 master 被判定为 odown
- redis-master 重启之后
- 手动把 redis-master 启动起来
- 观察哨兵日志,可以看到刚才新启动的 redis-master 被当成了 slave,使用 redis-cli 也可以进⼀步的验证这⼀点
- Redis 主节点如果宕机,哨兵会把其中一个从节点提拔成主节点
- 当之前的 Redis 主节点重启之后,这个主节点被加入到哨兵的监控中,但只会被作为从节点使用
- 选举原理
- 假定当前环境为三个哨兵(sentenal1、sentenal2、sentenal3),一个主节点(redis-master),两个从节点(redis-slave1、redis-slave2)
- 当主节点出现故障,就会触发重新一系列过程
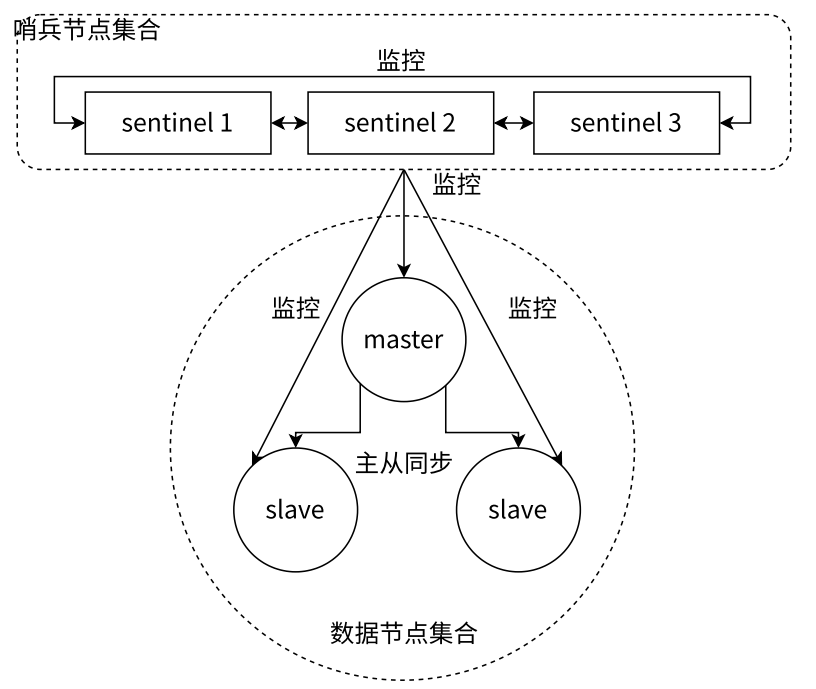
- 主观下线
- 哨兵节点通过心跳包来判断 Redis 服务器是否正常工作。当 redis-master 宕机,此时 redis-master 和三个哨兵之间的心跳包就没有了。站在三个哨兵的角度来看,redis-master 出现严重故障,此时还不能排除网络波动的影响,因此三个哨兵均会把 redis-master 判定为主观这个 Redis 节点下线
- 客观下线
- 哨兵 sentenal1、sentenal2、sentenal3 均会对主节点故障这件事情进行投票。当故障得票数 >= 配置的法定票数之后,客观判定这个 Redis 节点下线
- 有可能出现非常严重的网络波动而导致所有的哨兵都联系不上 Redis 主节点,从而被误判为挂了
- 如果出现这个情况,那么用户的客户端也连不上 Redis 主节点了,此时这个主节点基本无法正常工作了
- 挂了不一定是进程崩了,只要是无法访问,都可以被视为是挂了
- 选举出哨兵的 leader
- 接下来需要哨兵从剩余的 slave 中挑选出一个新的 master,这个工作不需要所有的哨兵都参与,只需要选出个代表,由 leader 负责进行 slave 升级到 master 的提拔过程,这个选举的过程涉及到 Raft 算法
- 假定一共三个哨兵节点:S1、S2、S3
- 每个哨兵节点都给其他所有哨兵节点,发起⼀个拉票请求
- 收到拉票请求的节点,会回复一个投票响应。响应的结果有 2 种可能:投 / 不投。比如 S1 给 S2 发了个投票请求,S2 就会给 S1 返回投票响应。到底 S2 是否要投 S1,取决于 S2 是否给别⼈投过票了,因为每个哨兵只有一票。如果 S2 没有给别⼈投过票,且 S1 是第一个向 S2 拉票的,那么 S2 就会投 S1,否则就不投
- ⼀轮投票完成之后, 发现得票超过半数的节点,自动成为 leader。如果出现平票的情况,就重新再投一次,这也是为什么建议哨兵节点设置成奇数个的原因
- leader 节点负责挑选一个 slave 成为新的 master,当其他的 sentenal 发现新的 master 出现了,说明选举结束了
- Raft 算法的核心就是 “先下手为强”。谁率先发出了拉票请求,谁就有更大的概率成为 leader。这里的决定因素成了网络延时,网络延时本身就带有一定随机性
- 具体选出的哪个节点是 leader 并不重要,能选出一个节点即可
- leader 挑选出合适的 slave 成为新的 master
- 挑选规则
- 比较优先级。优先级高(数值小)的上位,优先级是配置文件中的配置项(slave-priority 或者 replica-priority)
- 比较 replication offset 谁复制的数据多,高的上位
- 比较 run id,谁的 id 小,谁上位
- 当某个 slave 节点被指定为 master 之后,leader 指定该节点执行 slave no one,成为 master,leader 指定剩余的 slave 节点,都依附于这个新 master
- 挑选规则
- 主观下线
- 上述过程都是 “无人值守”,Redis 自动完成的,这样做解决了主节点宕机之后需要人工干预的问题,提高了系统的稳定性和可用性
- 注意事项
- 哨兵节点不能只有一个,否则哨兵节点挂了也会影响系统可用性
- 哨兵节点最好是奇数个,方便选举 leader,得票更容易超过半数
- 哨兵节点不负责存储数据,仍然是 redis 主从节点负责存储
- 哨兵 + 主从复制解决的问题是提高可用性,不能解决数据在极端情况下写丢失的问题
- 哨兵 + 主从复制不能提高数据的存储容量,当需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了
- 为了能存储更多的数据,就引入了集群
- 哨兵 + 主从复制不能提高数据的存储容量,当需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了
十一、集群(重点理解流程和原理)
1、基本原理
- 哨兵模式提高了系统的可用性,但真正用来存储数据的还是 master 和 slave 节点,所有数据都需要存储在单个 master 和 slave 节点中。如果数据量很大,接近超出了 master / slave 所在机器的物理内存,就可能出现严重问题
- 如何获取更大的空间?
- 加机器即可,所谓大数据的核心就是一台机器搞不定,用多台机器来解决
- Redis 的集群就是在上述思路之下,引入多组 Master / Slave,每⼀组 Master / Slave 存储数据全集的一部分,从而构成一个更大的整体,称为 Redis 集群(Cluster)
- 广义的 “集群”:只要是多个机器构成了分布式系统,都可以称为是一个集群
- 主从结构、哨兵模式,也可以称为广义的集群
- 狭义的 “集群”:Redis 提供的集群模式,在这个集群模式之下,主要是解决存储空间不足的问题(扩展存储空间)
- 广义的 “集群”:只要是多个机器构成了分布式系统,都可以称为是一个集群
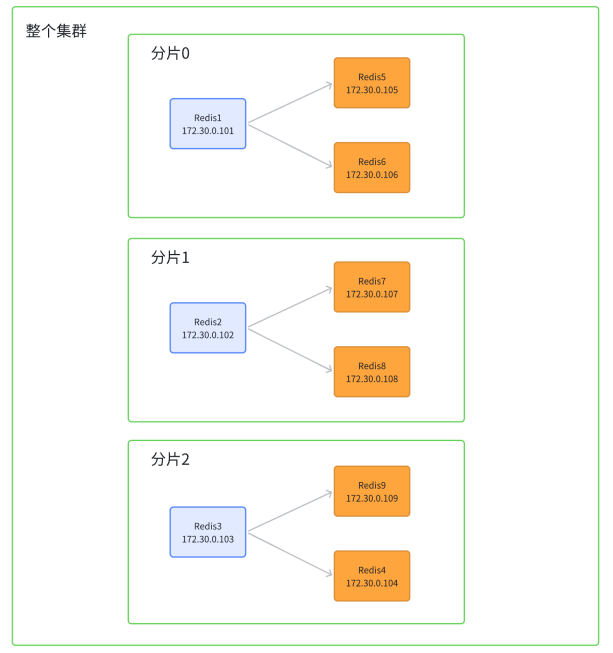
- 假定整个数据全集是 1 TB,引入三组 Master / Slave 来存储,那么每⼀组机器只需要存储整个数据全集的 1/3 即可
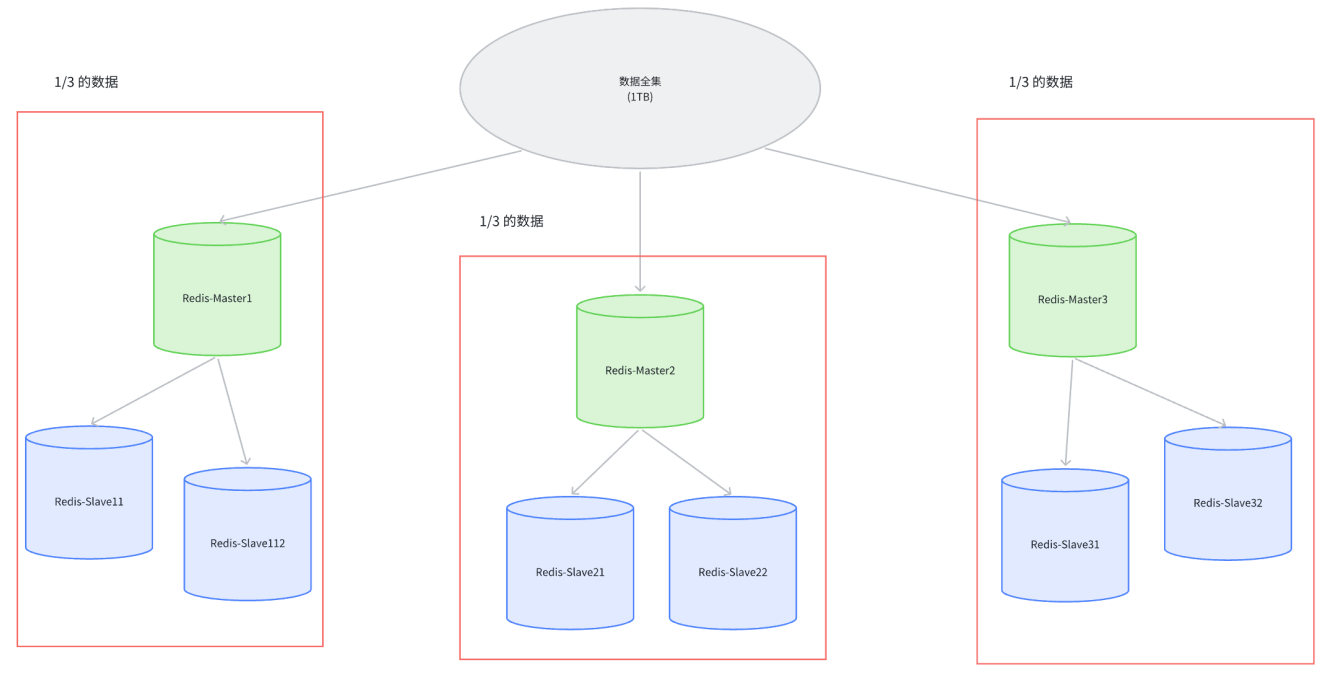
- Master1 和 Slave11 和 Slave12 保存的是同样的数据,占总数据的 1/3;Master2 和 Slave21 和 Slave22 保存的是同样的数据,占总数据的 1/3;Master3 和 Slave31 和 Slave32 保存的是同样的数据,占总数据的 1/3
- 这三组机器存储的数据都是不同的,每个 Slave 都是对应 Master 的备份(当 Master 挂了,对应的 Slave 会补位成 Master)。每个红框部分都可以称为是一个分片(Sharding),如果全量数据进一步增加,只要再增加更多的分片即可
- 数据量多了,使用硬盘来保存可以吗?硬盘只是存储空间大了,但是访问速度是比内存慢很多的。但实际上还存在很多应用场景:既希望存储较多的数据,又希望有非常高的读写速度
- 比如搜索引擎
2、数据分片算法
- Redis cluster 的核心思路是用多组机器来存数据的每个部分
- 给定一个数据(一个具体的 key),那么这个数据应该存储在哪个分片上?读取时又应该去哪个分片读取呢?
- 哈希求余
- 借鉴哈希表的基本思想:借助 hash 函数把一个 key 映射到整数,再针对数组的长度进行求余,就可以得到一个数组下标
- 设有 N 个分片,使用 [0, N-1] 这样序号进行编号。针对某个给定的 key,先计算 hash 值,再将得到的结果 %N,得到的结果即为分片编号。例如 N 为 3,给定的 key 为 "hello",对 "hello" 计算 hash 值
- 特点:md5 计算结果是定长的,其计算结果是分散的且不可逆的
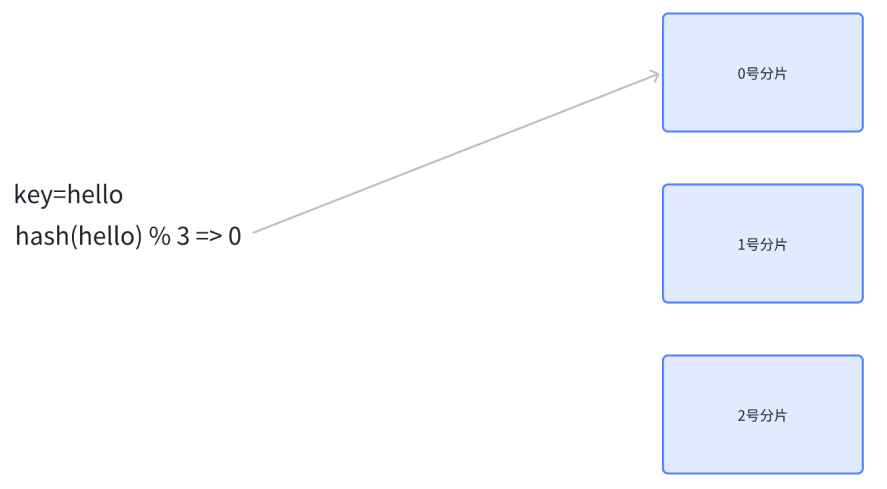
- 实际工作中涉及到的系统,计算 hash 的方式不一定是 md5,但思想是一致的
- 特点:md5 计算结果是定长的,其计算结果是分散的且不可逆的
- 如果要取某个 key 的记录,也是针对 key 计算 hash , 再对 N 求余,就可以找到对应的分片编号了
- 优点:简单高效,数据分配均匀
- 缺点:一旦需要进行扩容,N 发生了改变,那么原有的映射规则被破坏,就需要让节点之间的数据相互传输,重新排列,以满足新的映射规则,此时需要搬运的数据量比较多,开销较大
- N 为 3 时,[100, 120] 这 21 个 hash 值的分布
- (此处假定计算出的 hash 值是一个简单的整数,方便肉眼观察)当引入一个新的分片,N 从 3 => 4 时,大量的 key 需要重新映射

- (此处假定计算出的 hash 值是一个简单的整数,方便肉眼观察)当引入一个新的分片,N 从 3 => 4 时,大量的 key 需要重新映射
- 一致性哈希算法
- 交替出现导致搬运成本高,为了降低上述的搬运开销,能够更高效扩容,业界提出了 “一致性哈希算法”(key 映射到分片序号的过程不再是简单求余了)
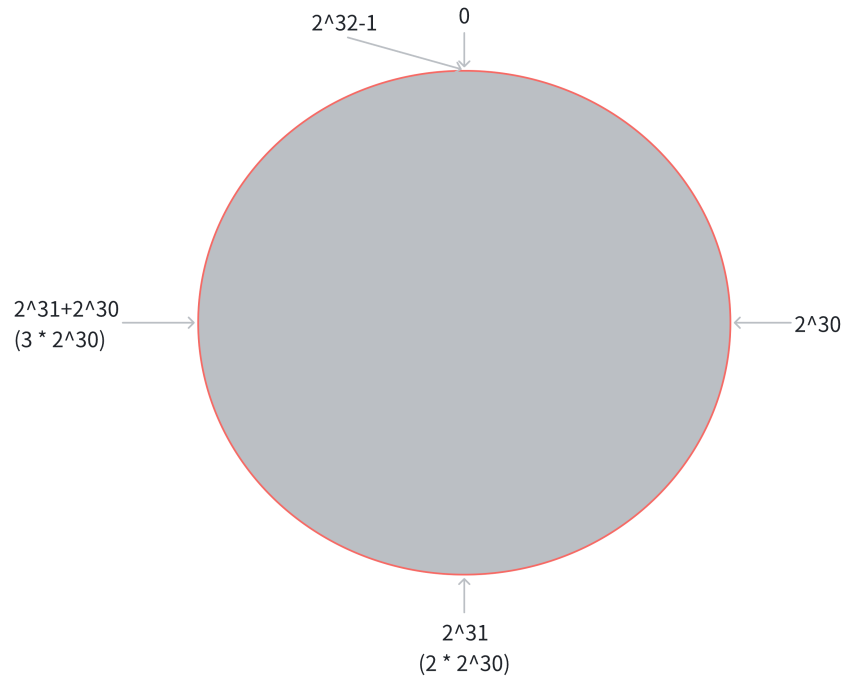
- 把 0 -> 2^32-1 这个数据空间映射到一个圆环上,数据按照顺时针方向增长
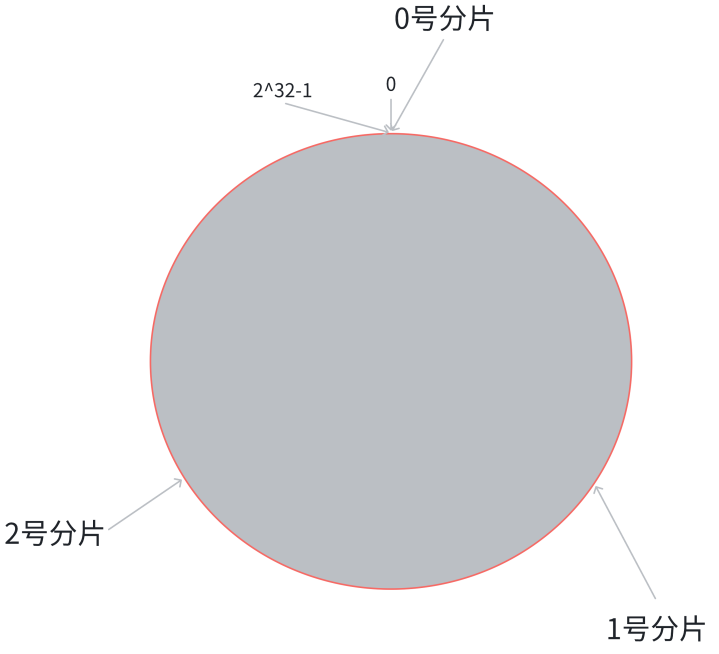
- 假设当前存在三个分片,就把分片放到圆环的某个位置上
- 假定有一个 key,计算得到 hash 值 H,从 H 所在位置顺时针往下找,找到的第一个分片,即为该 key 所从属的分片
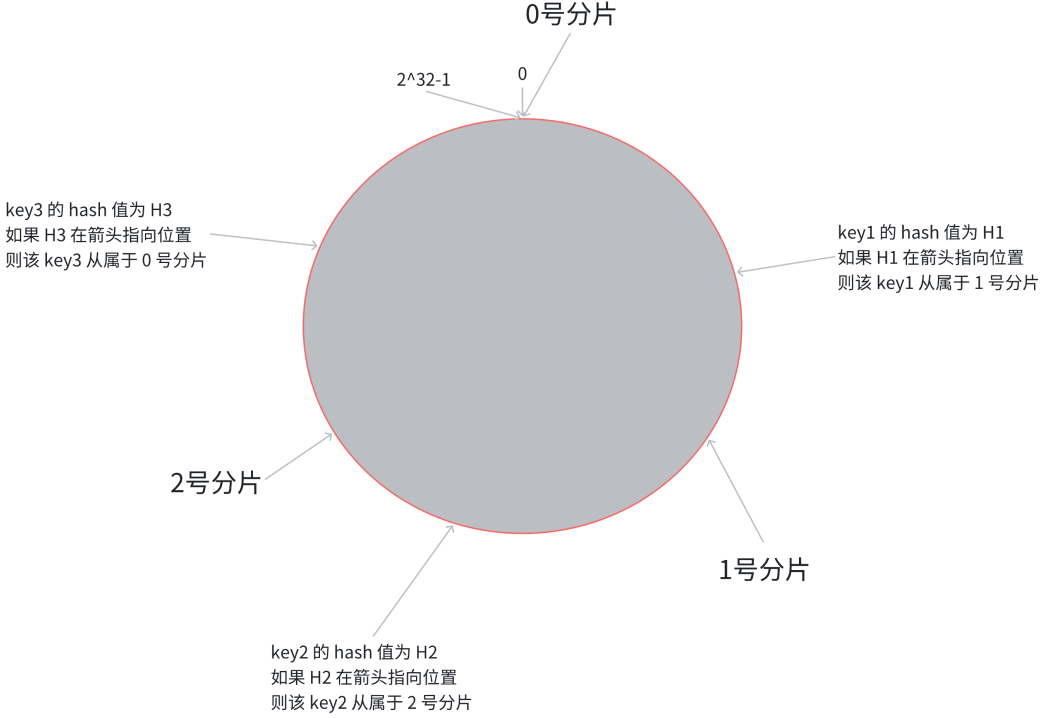
- 相当于 N 个分片的位置把整个圆环分成了 N 个管辖区间,Key 的 hash 值落在某个区间内,就归对应区间管理
- 把 0 -> 2^32-1 这个数据空间映射到一个圆环上,数据按照顺时针方向增长
- 如果扩容一个分片,则原有分片在环上的位置不动,只要在环上新安排一个分片位置即可

- 这里只需要把 0 号分片上的部分数据搬运给 3 号分片即可,而 1 号和 2 号分片管理的区间是不变的
- 优点:大大降低了扩容时数据搬运的规模,提高了扩容操作的效率
- 缺点:数据分配不均匀,出现数据倾斜
- 交替出现导致搬运成本高,为了降低上述的搬运开销,能够更高效扩容,业界提出了 “一致性哈希算法”(key 映射到分片序号的过程不再是简单求余了)
- 哈希槽分区算法(Redis 使用)
- 为了解决搬运成本高和数据分配不均匀的问题,Redis cluster 引入了哈希槽(hash slots)算法
- hash_slot = crc16(key) % 16384
- crc16 也是一种 hash 算法
- 16384(16*1024,即 2^14=16k),相当于是把整个哈希值映射到 16384 个槽位上,即 [0, 16383],再把这些槽位比较均匀的分配给每个分片,每个分片的节点都需要记录自己持有哪些分片
- 假设当前有三个分片,一种可能的分配方式
- 0 号分片:[0, 5461],共 5462 个槽位
- 1 号分片:[5462, 10923],共 5462 个槽位
- 2 号分片:[10924, 16383],共 5460 个槽位
- 这里的分片规则很灵活,虽然每个分片持有的槽位也不一定连续,但此时这三个分片上的数据比较均匀了。每个分片的节点使用位图来表示自己持有哪些槽位。对于 16384 个槽位来说,需要 2048 个字节(2KB)大小的内存空间表示
- 如果需要进行扩容,比如新增一个 3 号分片,就可以针对原有的槽位进行重新分配,可以把之前每个分片持有的槽位各拿出一点,分给新分片
- 一种可能的分配方式
- 0 号分片:[0, 4095],共 4096 个槽位
- 1 号分片:[5462, 9557],共 4096 个槽位
- 2 号分片:[10924, 15019],共 4096 个槽位
- 3 号分片:[4096, 5461] + [9558, 10923] + [15019, 16383],共 4096 个槽位
- 在上述过程中,只有被移动的槽位所对应的数据才需要搬运
- 在实际使用 Redis 集群分片时,不需要手动指定哪些槽位分配给某个分片,只需要告诉某个分片应该持有多少个槽位即可,Redis 会自动完成后续的槽位分配,以及对应的 key 搬运的工作
- hash_slot = crc16(key) % 16384
- Redis 集群是最多有 16384 个分片吗?
- 并非如此,如果一个分片只有一个槽位,key 是要先映射到槽位,再映射到分片的,这对于集群的数据均匀其实是难以保证的。实际上建议集群分片数不应该超过 1000,而且 16000 这么大规模的集群,其本身的可用性也是一个大问题。一个系统越复杂,出现故障的概率是越高的
- 为什么是 16384 个槽位?
- 节点之间通过心跳包通信,心跳包中包含了该节点持有的 slots,这个是使用位图数据结构表示的,表示 16384(16k)个 slots,需要的位图大小是 2KB。如果给定的 slots 数更多,比如 65536 个,那么此时就需要消耗更多的空间:8 KB 位图。虽然 8 KB 对于内存来说不算什么,但在频繁的网络心跳包中还是一个不小的开销
- Redis 集群一般不建议超过 1000 个分片,所以 16k 对于最大 1000 个分片来说是足够用的,同时也会使对应的槽位配置位图体积不至于很大
- 为了解决搬运成本高和数据分配不均匀的问题,Redis cluster 引入了哈希槽(hash slots)算法
- 哈希求余
3、集群搭建(基于 Docker)
- 基于 docker 搭建一个集群,每个节点都是一个容器
- 拓扑结构
-
- 在 Linux 上,以 .sh 后缀结尾的文件称为 “shell 脚本”。使用 Linux 时,是通过一些命令来进行操作的,非常适合把命令写到一个文件中,批量化进行,同时还能加入条件、循环、函数等机制,因此便可以基于这些来完成更复杂的工作
- 需要创建多个 redis 节点,这些 redis 的配置文件内容大同小异,此时就可以使用脚本来批量生成
- shell 中 { } 用来表示变量,而不是代码块
- \ 是续行符,把下一行的内容和当前行合并成一行。在 shell 默认情况下,要求把所有的代码都写到一行里,使用续行符来换行
- shell 中拼接字符串是直接写到一起,不需要使用 +
4、主节点宕机
- 如果集群中的从节点挂了,是没有什么影响的,但如果挂了的节点是主节点,此时就会产生影响了。因为主节点才能处理写操作,从节点是不能写的
- 处理流程
- 故障判定
- 集群中所有节点都会周期性的使用心跳包进行通信
- 节点 A 给节点 B 发送 ping 包,B 就会给 A 返回⼀个 pong 包。ping 和 pong 除了 message type 属性外,其它部分都是一样的
- 这里包含了集群的配置信息:该节点的 id,该节点从属于哪个分片,是主节点还是从节点,从属于谁,持有哪些 slots 的位图等
- 每个节点每秒钟都会给一些随机的节点发起 ping 包,而不是全发一遍,这样设定是为了避免在节点很多时,心跳包也非常多
- 比如有 9 个节点,如果全发,就是 9*8 有 72 组心跳了(按照 N^2 这样的级别增长的)
- 当节点 A 给节点 B 发起 ping 包,B 不能如期回应时,此时 A 会尝试重置和 B 的 TCP 连接,看能否连接成功。如果仍然连接失败,A 就会把 B 设为 PFAIL 状态,相当于主观下线。A 判定 B 为 PFAIL 之后,会通过 redis 内置的 Gossip 协议和其他节点进行沟通,向其它节点确认 B 的状态
- 每个节点都会维护一个自己的下线列表,由于视角不同,每个节点的下线列表也不一定相同
- 当 A 发现其它很多节点也认为 B 为 PFAIL,且数目超过总集群个数的一半,那么 A 就会把 B 标记成 FAIL,相当于客观下线,并且把这个消息同步给其它节点。其它节点收到后,也会把 B 标记成 FAIL。至此,B 就彻底被判定为故障节点了
- 节点 A 给节点 B 发送 ping 包,B 就会给 A 返回⼀个 pong 包。ping 和 pong 除了 message type 属性外,其它部分都是一样的
- 某个或者某些节点宕机,有时候会引起整个集群都宕机(fail 状态)
- 这三种情况会出现集群宕机
- 某个分片,所有的主节点和从节点都挂了(该分片就无法提供数据服务了)
- 某个分片,主节点挂了,但是没有从节点(该分片就无法提供数据服务了)
- 超过半数的 master 节点都挂了(情况严重)
- 核心原则是保证每个 slots 都能正常工作(存取数据)
- 集群中所有节点都会周期性的使用心跳包进行通信
- 故障迁移
- B 故障且 A 把 B FAIL 的消息告知集群中的其他节点
- 如果 B 是从节点,那么不需要进行故障迁移
- 如果 B 是主节点,那么会由 B 的从节点触发故障迁移了
- 故障迁移就是指把从节点提拔成主节点,继续给整个 redis 集群提供支持
- 具体流程
- 从节点判定自己是否具有参选资格。如果从节点和主节点已经太久没通信(此时认为从节点的数据和主节点差异太大了),时间超过阈值则失去竞选资格
- 具有资格的节点,比如 C 和 D 就会先休眠一定时间,休眠时间 = 500ms 基础时间 + [0, 500ms] 随机时间 + 排名*1000ms
- offset 的值越大,则排名越靠前(越小)
- 比如 C 的休眠时间到了,C 就会给其他所有集群中的节点,进行拉票操作,但只有主节点才有投票资格
- 主节点就会把自己的票投给 C(每个主节点只有 1 票)
- 当 C 收到的票数超过主节点数目的一半,C 就会晋升成主节点(C 自己负责执行 slaveof no one,并且让 D 执行 slaveof C)
- 同时 C 还会把自己成为主节点的消息同步给其它集群的节点,其它节点也都会更新自己保存的集群结构信息
- 上述选举的过程称为 Raft 算法,是一种在分布式系统中广泛使用的算法。在随机休眠时间的加持下,基本上就是谁先唤醒,谁就能竞选成功
- B 故障且 A 把 B FAIL 的消息告知集群中的其他节点
- 故障判定
5、集群扩容
- 集群扩容操作(风险高、成本大)是一个在开发中比较常遇到的场景。随着业务的发展,现有集群很可能无法容纳日益增长的数据,此时给集群中加入更多新机器,就可以使存储的空间更大
- 分布式的本质就是使用更多的机器来引入更多的硬件资源
- 把新的主节点加入到集群
- add-node 后的第一组地址是新节点的地址,第二组地址是集群中的任意节点地址
- 重新分配 slots
- reshard 后的地址是集群中的任意节点地址
- 如果在搬运 slots / key 的过程中,此时客户端能否访问 redis 集群呢?
- 在搬运 key 的过程中,大部分的 key 是不用搬运的,针对这些未搬运的 key,此时是可以正常访问的。但针对正在搬运的 key,进行访问就可能会出现短暂的访问错误的情况(key 的位置出现了变化)。随着搬运的完成,这样的错误自然就恢复了
- 如果想要追求更高的可用性,让扩容对于用户的影响更小,那么就需要搞一组新的机器,重新搭建集群,并且把数据导入过来,使用新集群代替旧集群,但成本高
- 给新的主节点添加从节点
- 有主节点了,此时扩容的目标已经初步达成,但为了保证集群的可用性,还需要给这个新的主节点添加从节点,保证该主节点宕机之后有从节点能够顶上
十二、Redis 典型应用
1、缓存(cache)
- 缓存(cache)的核心思路就是把一些常用的数据放到触手可及(访问速度更快)的地方,方便随时读取
- 对于硬件的访问速度来说,通常情况下,CPU 寄存器 > 内存 > 硬盘 > 网络
- 对于计算机硬件来说,往往访问速度越快的设备成本越高,存储空间越小。缓存是更快,但空间上往往是不足的,因此大部分时候,缓存只放一些热点数据(访问频繁的数据)就非常有用了
- “二八定律”:20% 的热点数据能够应对 80% 的访问场景
- 只需要把少量的热点数据缓存起来就可以应对大多数场景,从而在整体上有明显的性能提升
- 使用 Redis 作为缓存
- 在一个网站中,经常会使用关系型数据库(比如 MySQL)来存储数据。关系型数据库虽然功能强大,但有一个大缺陷:性能不高(换而言之,进行一次查询操作消耗的系统资源较多)
- 数据库把数据存储在硬盘上,硬盘的 IO 速度并不快,尤其是随机访问
- 如果查询不能命中索引,就需要进行表的遍历,会大大增加硬盘 IO 次数
- 关系型数据库对于 SQL 的执行会做一系列的解析、校验、优化工作
- 如果是⼀些复杂查询,比如联合查询,需要进行笛卡尔积操作,效率更是降低很多
- 如果访问数据库的并发量比较高,对于数据库的压力是很大的,很容易就会使数据库服务器宕机
- 服务器每次处理一个请求都是需要消耗一定的硬件资源的
- 所谓的硬件资源包括不限于 CPU、内存、硬盘、网络带宽...
- ⼀个服务器的硬件资源是有限的,一个请求消耗一份资源,请求多了自然把资源就耗尽了。后续的请求没有资源可用,就无法正确处理,更严重还会导致服务器程序的代码出现崩溃
- 服务器每次处理一个请求都是需要消耗一定的硬件资源的
- 如何让数据库能够承担更大的并发量呢?
- 核心思路主要有 2 个
- 开源:引入更多的机器,部署更多的数据库实例,构成数据库集群(主从复制、分库分表等)
- 节流:引入缓存,使用其它方式保存热点数据,从而降低直接访问数据库的请求数量
- 实际开发中,这两种方案往往是会搭配使用的
- 核心思路主要有 2 个
- Redis 是一个作为数据库缓存的常见方案
- Redis 访问速度比 MySQL 快很多,或者说处理同⼀个访问请求,Redis 消耗的系统资源比 MySQL 少很多,因此 Redis 能支持的并发量更大
- Redis 数据在内存中,访问内存比硬盘快很多
- Redis 只是支持简单的 key-value 存储,不涉及复杂查询的那么多限制规则
- Redis 访问速度比 MySQL 快很多,或者说处理同⼀个访问请求,Redis 消耗的系统资源比 MySQL 少很多,因此 Redis 能支持的并发量更大
- Redis 就像一个护盾一样,把 MySQL 给罩住了
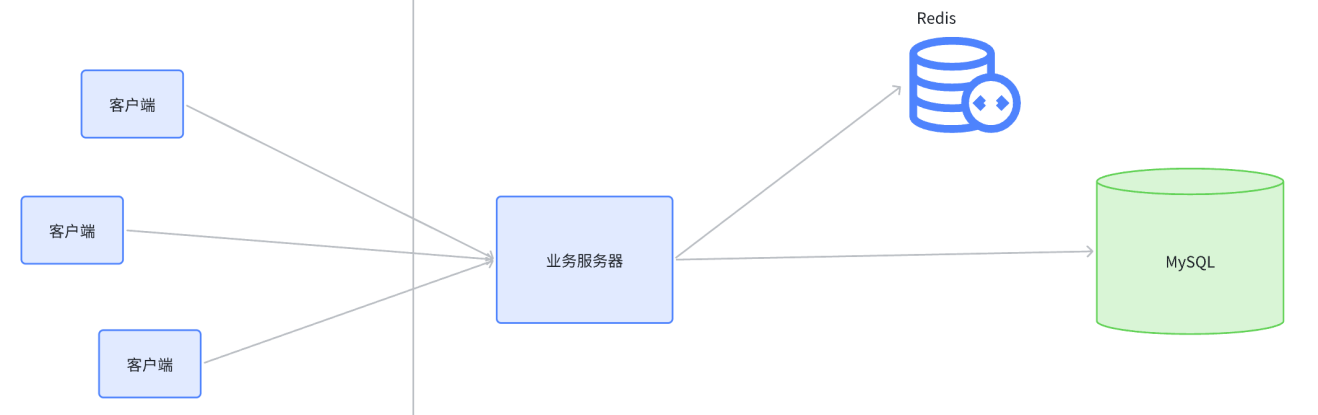
- 客户端访问业务服务器,发起查询请求
- 业务服务器先查询 Redis,看想要的数据是否在 Redis 中存在
- 如果已经在 Redis 中存在就直接返回,此时不必访问 MySQL 了。如果不存在,再查询 MySQL
- 按照 “二八定律”,只需要在 Redis 中放 20% 的热点数据就可以使 80% 的请求不再真正查询数据库了。当然,实践中究竟是 “二八”,还是 “一九”,或是 “三七”,这个情况可能会根据业务场景的不同存在差异,但至少绝大多数情况下,使用缓存都能够大大提升整体的访问效率,降低数据库的压力
- 缓存是用来加快 “读操作” 的速度的,如果是 “写操作”,还是要老老实实写数据库,缓存并不能提高性能
- 在一个网站中,经常会使用关系型数据库(比如 MySQL)来存储数据。关系型数据库虽然功能强大,但有一个大缺陷:性能不高(换而言之,进行一次查询操作消耗的系统资源较多)
- 缓存的更新策略
- 定期生成
- 每隔一定周期,对于访问的数据频次进行统计,挑选出访问频次最高的前 N% 的数据
- 搜索引擎的服务器会把哪个用户在什么时间搜了什么词,都通过日志的方式记录下来,然后每隔一段时间对这期间的搜索结果进行统计(日志的数量可能非常巨大,这个统计的过程可能需要使用 hadoop 或者 spark 等方式完成),从而就可以得到 “高频词表”
- 实时生成
- 先给缓存设定容量上限,接下来用户每次查询
- 在 Redis 查到了,就直接返回
- 如果 Redis 中不存在,就查数据库,把查到的结果同时也写入 Redis(经过一段时间的动态平衡,redis 中的 key 就逐渐成了热点数据)
- 如果缓存已经满了,即达到上限,就触发缓存淘汰策略,把⼀些相对不那么热门的数据淘汰掉,按照上述过程持续一段时间后,Redis 的内部数据自然就是热门数据了
- 通用的淘汰策略主要有几种(并非局限于 Redis,其他缓存也可以按这些策略展开)
- FIFO(First In First Out)先进先出
- 把缓存中存在时间最久的(也就是先来的数据)淘汰掉
- LRU(Least Recently Used)淘汰最久未使用的
- 记录每个 key 的最近访问时间,把最近访问时间最老的 key 淘汰掉
- LFU(Least Frequently Used)淘汰访问次数最少的
- 记录每个 key 最近⼀段时间的访问次数,把访问次数最少的淘汰掉
- Random 随机淘汰
- 从所有的 key 中随机抽取并淘汰掉
- 这里的淘汰策略可以自己实现,也可以直接使用 Redis 提供的内置的淘汰策略
- volatile-lru 当内存不足以容纳新写入数据时,从设置了过期时间的 key 中使用 LRU 算法进行淘汰
- allkeys-lru 当内存不足以容纳新写入数据时,从所有 key 中使用 LRU 算法进行淘汰
- volatile-lfu 4.0 版本新增,当内存不足以容纳新写入数据时,在过期的 key 中,使用 LFU 算法进行删除 key
- allkeys-lfu 4.0 版本新增,当内存不足以容纳新写入数据时,从所有 key 中使用 LFU 算法进行淘汰
- volatile-random 当内存不足以容纳新写入数据时,从设置了过期时间的 key 中,随机淘汰数据
- allkeys-random 当内存不足以容纳新写入数据时,从所有key中随机淘汰数据
- volatile-ttl 在设置了过期时间的 key 中,根据过期时间进行淘汰,越早过期的优先被淘汰(相当于 FIFO,只不过是局限于过期的 key)
- noeviction 默认策略,当内存不足以容纳新写入数据时,新写入操作会报错
- Redis 提供的策略和上述介绍的通用策略是基本一致的,只不过 Redis 会针对过期 key 和全部 key 分别做处理
- FIFO(First In First Out)先进先出
- 先给缓存设定容量上限,接下来用户每次查询
- 定期生成
- 缓存预热(Cache preheating)
- 使用 Redis 作为 MySQL 的缓存时,当 Redis 刚刚启动或者 Redis 大批 key 失效之后,此时由于 Redis 服务器是没有什么缓存数据的,那么所有的请求都会打给 MySQL,MySQL 就可能直接被访问到,从而造成较大的压力。随着时间的推移,Redis 上的数据积累的越来越多,MySQL 承担的压力也就越来越小,因此就需要提前把热点数据准备好,直接写入到 Redis 中,使 Redis 可以尽快为 MySQL 撑起保护伞
- 热点数据不一定准确,只要能帮助 MySQL 抵挡大部分请求即可。随着程序运行的推移,缓存的热点数据会逐渐自动调整,来更适应当前情况
- 缓存穿透(Cache penetration)
- 访问的 key 在 Redis 和 数据库中都不存在,此时这样的 key 不会被放到缓存上,后续如果仍然在访问该 key,依然会访问到数据库,这就会导致数据库承担的请求太多,压力很大,这种情况称为缓存穿透
- 产生缓存穿透的原因
- 业务设计不合理
- 比如缺少必要的参数校验环节,导致非法的 key 也被查询了
- 开发 / 运维误操作
- 把数据库中的部分数据误删了
- 黑客恶意攻击
- 业务设计不合理
- 解决缓存穿透的方法
- 针对要查询的参数进行严格的合法性校验,比如要查询的 key 是用户的手机号,那么就需要校验当前 key 是否满足⼀个合法的手机号的格式
- 针对数据库上也不存在的 key , 也存储到 Redis 中,比如 value 就设成 "",避免后续频繁访问数据库
- 可以通过引入布隆过滤器,在每次查询 redis / mysql 之前都先判定一下 key 是否在布隆过滤器上存在(把所有的 key 都插入到布隆过滤器中)。布隆过滤器本质上是结合了 hash + bitmap 的思想,以较少的空间开销,比较快的时间速度,判定 key 是否存在
- 缓存雪崩(Cache avalanche)
- 短时间内大量 key 在缓存上失效,导致数据库压力骤增,甚至直接宕机
- 产生缓存雪崩的原因
- 大规模 key 失效,其可能性主要有 2 种
- Redis 挂了
- Redis 上的大量的 key 同时过期
- 大规模 key 失效,其可能性主要有 2 种
- 出现大量的 key 同时过期的原因
- 可能是短时间内在 Redis 上缓存了大量的 key,并且设定了相同的过期时间
- 解决缓存雪崩的方法
- 部署高可用的 Redis 集群,并完善监控报警体系
- 不给 key 设置过期时间或者设置过期时间时添加随机时间因子
- 缓存击穿(Cache breakdown)
- 把 breakdown 翻译成 “瘫痪” / “崩溃” 也许更合适一些
- 相当于缓存雪崩的特殊情况,针对热点 key 突然过期,导致大量的请求直接访问到数据库上,甚至引起数据库宕机
- 解决缓存击穿的方法
- 基于统计的方式发现热点 key,并设置永不过期
- 进行必要的服务降级。例如访问数据库时使用分布式锁,限制同时请求数据库的并发数
2、分布式锁
- 在一个分布式的系统中,也会涉及到多个节点访问同一个公共资源的情况,此时就需要通过锁来做互斥控制,避免出现类似于线程安全的问题
- Java 的 synchronized 或者 C++ 的 std::mutex 都是只能在当前进程中生效,在分布式的这种多个进程多个主机的场景下就无能为力了,此时就需要使用到分布式锁
- 本质就是使用一个公共的服务器来记录加锁状态
- 这个公共的服务器可以是 Redis,也可以是其它组件(比如 MySQL 或者 ZooKeeper 等),还可以是自己写的一个服务
- 分布式锁的基础实现
- 本质:通过一个键值对来标识锁的状态
-
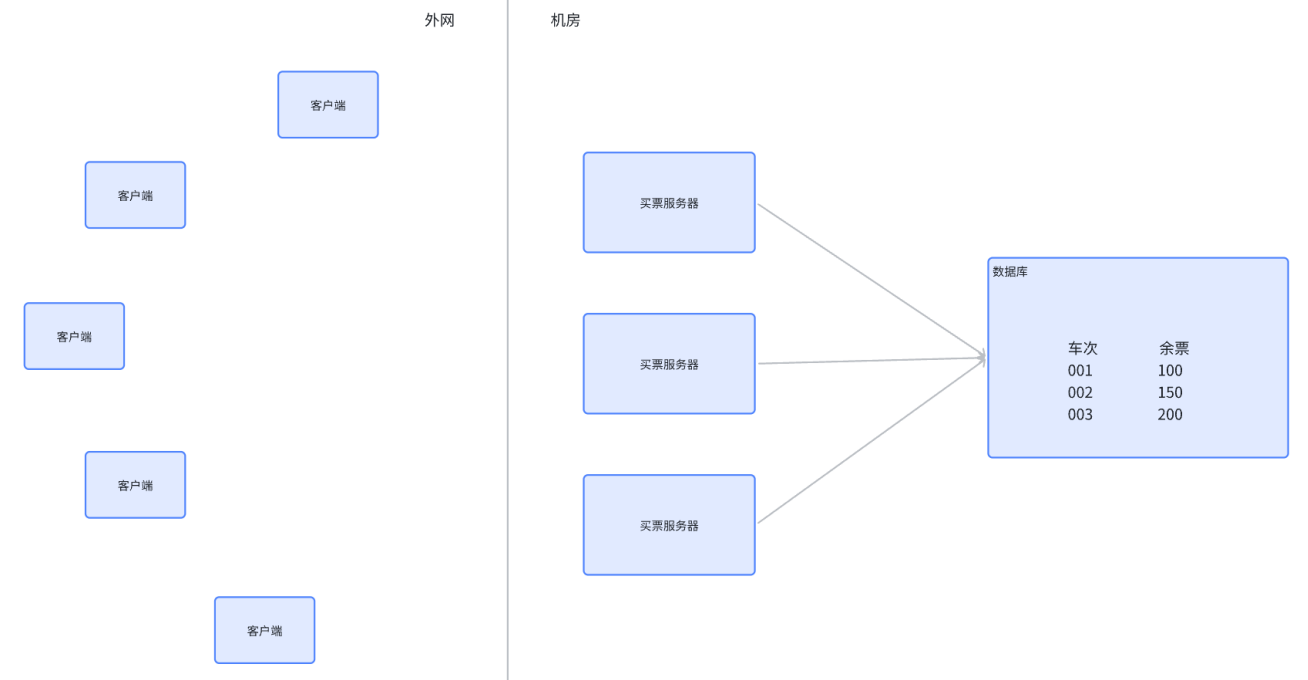
- 上述场景存在线程安全问题,需要使用锁来控制,否则可能出现超卖的情况
- 加锁的方式
- 可以在上述架构中引入一个 Redis 来作为分布式锁的管理器
- 分布式锁也是一个 / 组单独的服务器程序,给其它服务器提供加锁这样的服务(Redis 是一种典型的可以用来实现分布式锁的方案,但不是唯一方案,也可能使用 mysql / zookeeper 这样的组件来实现分布式锁的效果)
-
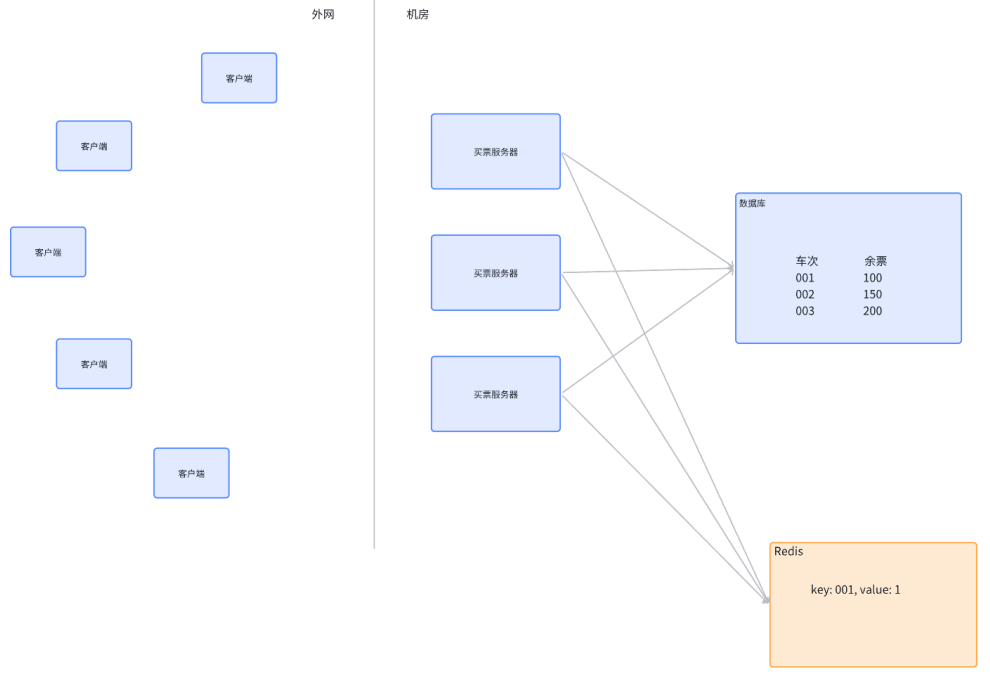
- 如果买票服务器 1 尝试买票,就需要先访问 Redis,在 Redis 上设置一个键值对,比如 key 就是车次,value 随便设置个值,比如 1
- 如果这个操作设置成功,就视为当前没有节点对该 001 车次加锁,往 redis 上设置一个特殊的键值对就可以进行数据库的读写操作,操作完成后,再删除刚才这个键值对
- 如果在买票服务器 1 操作数据库的过程中,买票服务器 2 也想买票,也会去尝试给 Redis 上写一个键值对,key 同样是车次。但如果此时设置时发现该车次的 key 已经存在,则认为已经有其他服务器正在持有锁,此时服务器 2 就需要等待或暂时放弃,就可以保证服务器 1 执行查询 -> 更新的过程中,服务器 2 不会执行查询,也就解决了超卖问题
- 前面买票场景使用 mysql 的事务也可以批量执行查询+修改操作,但在分布式系统中,要访问的共享资源不一定是 mysql,也可能是其它存储介质
- 如果 key 不存在就设置,存在则直接失败。但假设某个服务器加锁(setnx)成功了,但在执行后续逻辑的过程中挂了,没有执行到解锁(del)命令,所以上述场景并不完整
- 过期时间
- 当服务器 1 加锁后,开始处理买票的过程中,如果服务器 1 意外宕机了,就会导致解锁操作(删除该 key)不能执行,就可能引起其它服务器始终无法获取到锁的情况
- 可以在设置 key 的同时引入过期时间,即这个锁最多持有多久,就应该被释放
- 可以使用 set ex nx 的方式,在设置锁的同时设置过期时间
- 此处的过期时间只能使用一个命令的方式设置,因为 Redis 上多个命令之间无法保证原子性
- 如果分开多个操作,比如 set nx 之后再来一个单独的 expire,由于 Redis 的多个指令之间不存在关联,并且即使使用了事务也不能保证这两个操作都一定成功,因此就可能出现 set nx 成功,但是 expire 失败的情况,此时仍然会出现无法正确释放锁的问题
- 当服务器 1 加锁后,开始处理买票的过程中,如果服务器 1 意外宕机了,就会导致解锁操作(删除该 key)不能执行,就可能引起其它服务器始终无法获取到锁的情况
- 校验 id
- 对于 Redis 中写入的加锁键值对,其它节点也是可以删除的。比如服务器 1 写入一个 "001":1 这样的键值对,服务器 2 是完全可以把 "001" 给删除掉的,虽然说服务器 2 不会进行这样恶意删除的操作,但不能保证因为一些 Bug 而导致服务器 2 把锁误删除
- 可以引入一个校验 id。可以把设置的键值对的值不再是简单的设为⼀个 1,而是设成服务器的编号,形如 "001": "服务器 1",这样就可以在删除 key(解锁)时,先校验当前删除 key 的服务器是不是当初加锁的服务器,如果是才能真正删除,如果不是则不能删除
- 对于 Redis 中写入的加锁键值对,其它节点也是可以删除的。比如服务器 1 写入一个 "001":1 这样的键值对,服务器 2 是完全可以把 "001" 给删除掉的,虽然说服务器 2 不会进行这样恶意删除的操作,但不能保证因为一些 Bug 而导致服务器 2 把锁误删除
- lua
- 为了解锁操作原子,可以使用 Redis 内嵌的 Lua 脚本功能
- Lua 的语法类似于 JS,是一个动态弱类型的语言,Lua 的解释器一般使用 C 语言实现。Lua 语法简单精炼,执行速度快,解释器也比较轻量。redis 执行 lua 脚本的过程也是原子的,相当于执行一条命令一样(实际上 lua 中可以写多条命令)
- watch dog(看门狗)
- 上述方案仍然存在一个重要问题:当设置了 key 过期时间后,就可能当任务在业务逻辑还没执行完,key 就先过期(释放锁)了,从而导致锁提前失效
- 把这个过期时间设置的足够长,是否能够解决上述这个问题呢?
- 设置多长时间合适是无止境的。即使设置的时间再长,也不能完全保证就没有提前失效的情况,而且如果设置的时间太长了,万一对应的服务器挂了(锁释放不及时),此时其他服务器也不能及时获取锁,因此相比于设置一个固定长时间,不如动态调整时间更合适
- watch dog 本质就是加锁的服务器上的一个单独线程,通过这个线程来对锁的过期时间进行动态续约
- 这个线程是业务服务器上的,不是 Redis 服务器的
- 假设初始情况下设置过期时间为 10s,同时设定看门狗线程每隔 3s 检测一次,那么当 3s 到时,看门狗就会判定当前任务是否完成
- 如果任务已经完成,则直接通过 lua 脚本的方式,释放锁(删除 key)
- 如果任务未完成,则把过期时间重写设置为 10s,即续约
- 这样就不用担心锁提前失效的问题了,而且如果该服务器挂了,看门狗线程也就随之挂了,此时无人续约,这个 key 自然就可以迅速过期,让其它服务器获取到锁了
- Redlock 算法
- 实践中的 Redis 一般是以集群的方式部署的(至少是主从的形式,而不是单机),那么就可能出现比较极端的情况
- 服务器 1 向 master 节点进行加锁操作,这个写入 key 的过程刚刚完成,master 就挂了,此时 slave 节点升级成了新的 master 节点。但由于刚才写入的 key 还没来得及同步给 slave,就相当于服务器 1 的加锁操作形同虚设,服务器 2 仍然可以进行加锁,即给新的 master 写入 key,因为新的 master 不包含刚才的 key
- 可以引入一组 Redis 节点,其中每一组 Redis 节点都包含一个主节点和若干从节点,并且组和组之间存储的数据都是一致的,相互之间是备份关系,而并非是数据集合的一部分,这点有别于 Redis cluster
- 加锁时按照一定的顺序针对这些组 redis 都进行加锁操作,在写锁时需要设定操作的超时时间,如果 setnx 操作超过了超时时间还没有成功,就视为加锁失败
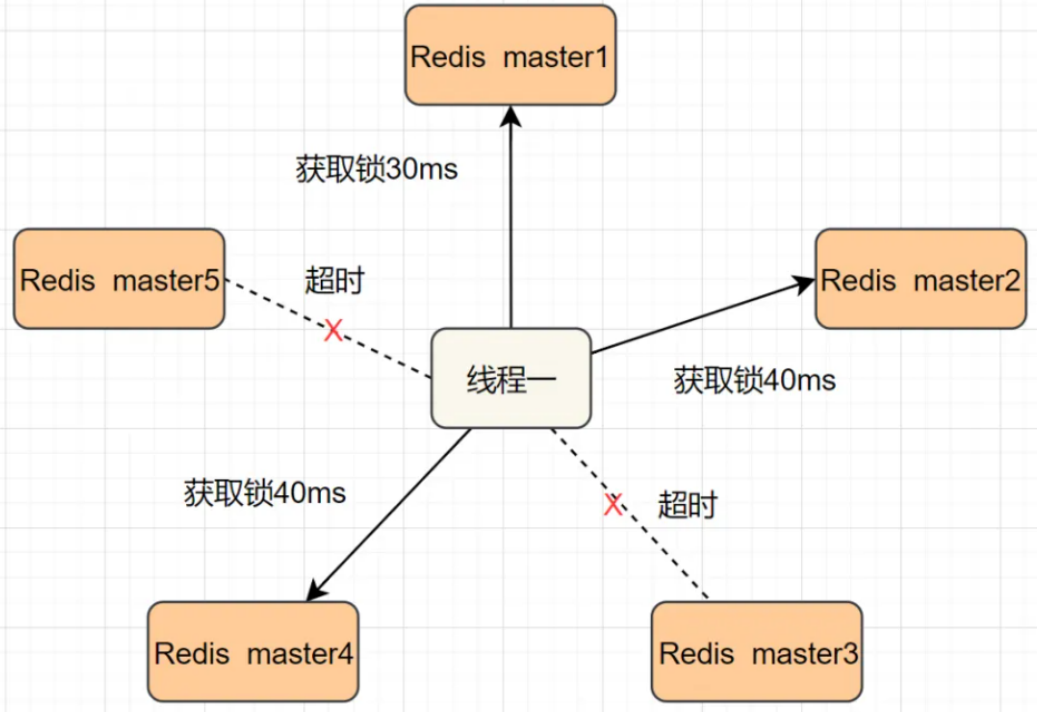
- 如果给某个节点加锁失败,则立即尝试下一个节点。当加锁成功(写入 key)的节点数超过总节点数的一半,就视为加锁成功。即使有某些节点挂了,也不影响锁的正确性
- 是否可能出现上述节点都同时遇到大冤种的情况呢?
- 理论上这件事是有可能发生的,但概率很小,可以忽略不计
- 释放锁时也需要把所有节点都进行解锁操作,即使是之前的超时节点,也要尝试解锁,尽量保证逻辑严密
- 服务器 1 向 master 节点进行加锁操作,这个写入 key 的过程刚刚完成,master 就挂了,此时 slave 节点升级成了新的 master 节点。但由于刚才写入的 key 还没来得及同步给 slave,就相当于服务器 1 的加锁操作形同虚设,服务器 2 仍然可以进行加锁,即给新的 master 写入 key,因为新的 master 不包含刚才的 key
- Redlock 算法核心:加锁操作不能只写给一个 Redis 节点,而要写多个。分布式系统中任何一个节点都是不可靠的,最终加锁成功的结论:少数服从多数,引入最多的冗余来提高 Redis 作为分布式锁的可读性。因为一个分布式系统不至于大部分节点同时出现故障,所以这样的可靠性要比单个节点来说靠谱
- 实践中的 Redis 一般是以集群的方式部署的(至少是主从的形式,而不是单机),那么就可能出现比较极端的情况
- 其他功能
- 上述锁只是一个简单的互斥锁,但实际上在⼀些特定场景中,还有一些其他特殊的锁
- 可重入锁
- 公平锁(遵守先来后到原则)
- 读写锁
- 基于 Redis 的分布式锁,也可以实现上述特性,只不过对应的实现逻辑也会更复杂
- 在实际开发中并不会自己去实现一个分布式锁,因为已经有很多现成的库封装好了,直接使用即可(比如:C++ 中的 redis-plus-plus、Java 中的 Redisson)
- 上述锁只是一个简单的互斥锁,但实际上在⼀些特定场景中,还有一些其他特殊的锁