MySQL8.x新特性:窗口函数(Window Functions)
MySQL8.x新特性
1.与mysql5.x的区别:MySQL8.x新特性:与mysql5.x的版本区别-CSDN博客
2.窗口函数(Window Functions):MySQL8.x新特性:窗口函数(Window Functions)-CSDN博客
引言
窗口函数(Windows Function),也被称为分析函数(Analytic Functions),在Oracle中使用已久,但直到MySQL8才开始引入。窗口函数非常强大,在工作中应用非常广泛,专门用于处理复杂的统计分析问题,例如移动平均、累计总和、百分比排名等,它可直接添加新的聚合字段,而不必在数据库应用程序级别编写额外的代码。
准备工作
一.环境准备
安装mysql8.x(本文使用mysql8.0.42进行操作)
查询版本语句
SHOW VARIABLES
WHERE variable_name LIKE 'version%';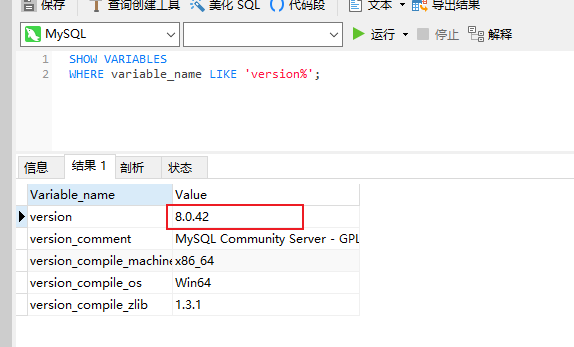
二.创建表
本文所有测试均使用下表进行
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '姓名',`class` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '班级',`number` int NULL DEFAULT NULL COMMENT '人气',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '漩涡鸣人', '火影班', 90);
INSERT INTO `student` VALUES (2, '宇智波佐助', '火影班', 87);
INSERT INTO `student` VALUES (3, '妮可罗宾', '海贼班', 75);
INSERT INTO `student` VALUES (4, '黑崎一护', '死神班', 90);
INSERT INTO `student` VALUES (5, '路飞', '海贼班', 90);
INSERT INTO `student` VALUES (6, '日向宁次', '火影班', 85);
INSERT INTO `student` VALUES (7, '蓝染', '死神班', 88);
INSERT INTO `student` VALUES (8, '迪达拉', '火影班', 96);
INSERT INTO `student` VALUES (9, '索隆', '海贼班', 99);
INSERT INTO `student` VALUES (10, '辉夜姬', '火影班', 59);1.概念
窗口的概念可以理解为记录集合;窗口函数也就是在满足某种条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种是静态窗口;有的函数则是不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
2.语法
2.1基本语法
SELECT
WINDOW_FUNCTION() OVER(
[PARTITION BY `字段1`, `字段2`, ...]
[ORDER BY `字段3`, `字段4`]
[FRAME_CLAUSE]
) [AS `别名`]
FROM `表名` ;
WINDOW_FUNCTION():就是窗口函数,下文3.简单使用-3.1分类中有详细说明
OVER:OVER关键字用于标识是否使用窗口函数,有两种用法:
OVER(),常规用法,窗口规范放在括号中。如窗口规范为空,表示没有窗口划分,默认所有数据为一组。
OVER window_name:由FROM后的WINDOW子句定义窗口规范,可重复使用。
PARTITION BY:用于将记录划分为不同的分区,窗口函数在每个分区上分别执行。可以使用多个字段进行分区。(我理解类似于group by,只不过group by是分组,partition by是分区)
FRAME_CLAUSE:框架子句,用于指定每个分区的数据范围,(当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用)。下文会详细说明。
2.2进阶语法
有时候多次重复定义或引用相同的窗口,很繁琐。为了避免重复定义,减少语句的繁琐,可以在WINDOW子句中定义并命名窗口,并在OVER中通过窗口名进行引用。一次定义,多次引用。
SELECT
WINDOW_FUNCTION() OVER `窗口名`|(`窗口名` ...)
FROM `表名`
WINDOW `窗口名` AS ()
WINDOW子句中的括号内的部分就是原OVER子句后的窗口定义。使用OVER关键字调用窗口时,可直接引用窗口名,或者可对窗口进行进一步的加工,使用括号括起来并在其中使用其他的窗口规范。
一个命名窗口的定义本身也可以以一个窗口名开头。这样可以实现窗口之间的引用,但不能形成循环。
3.简单使用
3.1分类
在使用之前,先说明一下窗口函数都有哪些:
序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()。
分布函数:PERCENT_RANK()、CUME_DIST()。
前后函数:LAG(expr,n)、LEAD(expr,n)。
头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)。
聚合函数:用于计算窗口内的某个字段的聚合值,例如 SUM(),AVG(),MIN(),MAX() 等。
其它函数:NTH_VALUE(expr, n)、NTILE(n)。
3.2基本语法示例
SELECT*,rank() over(PARTITION BY `class` ORDER BY `number` DESC) AS rk
FROM`student`;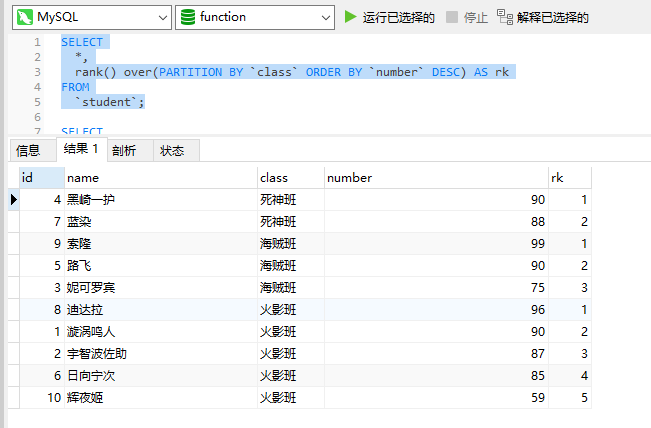
通过示例,由class进行分区,number进行倒叙排序的输出。也是over关键字的第一种方式
3.3进阶语法示例
SELECT*,rank() over w1 AS rk
FROM`student` window w1 AS ( PARTITION BY `class` ORDER BY `number` DESC );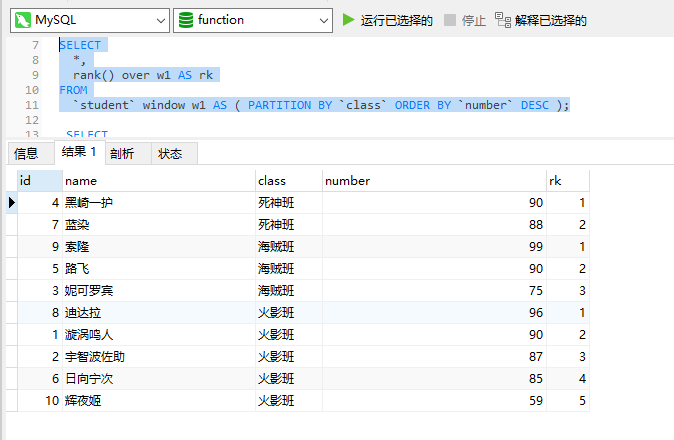
这种写法是over关键字的第二种方式,也是进阶语法。
4.窗口函数
接下来详细说明每一个窗口函数的使用
4.1序号函数
SELECT*,RANK() over ( ORDER BY `number` DESC ) AS `rank` ,DENSE_RANK() over ( ORDER BY `number` DESC ) AS `dense_rank` ,ROW_NUMBER() over ( ORDER BY `number` DESC ) AS `row_number` FROM`student`;不使用partition by对class进行分区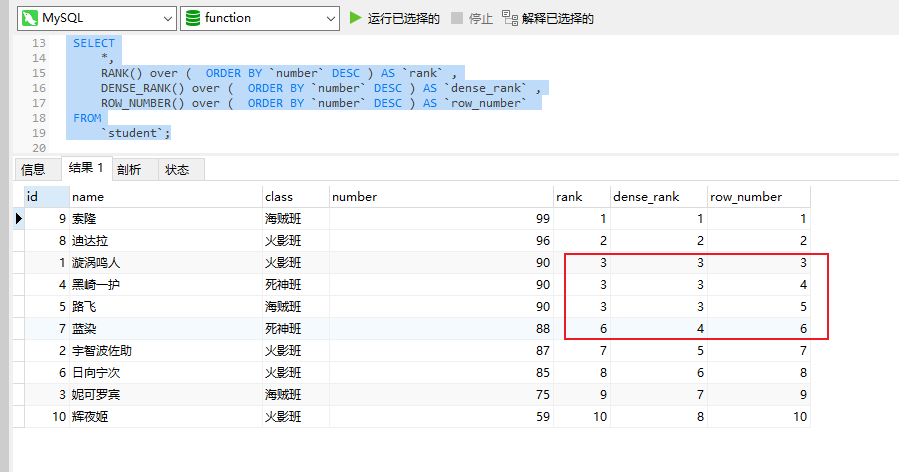
由测试结果可以看出:
RANK():并列排序,跳过重复序号
DENSE_RANK():并列排序,不跳过重复序号
ROW_NUMBER():顺序排序
4.2分布函数
4.2.1PERCENT_RANK()
百分比排序,返回当前行在分组内的百分比位置,返回值范围为[0, 1],第1行的百分比位置是0%。
计算公式:(rank-1)/(rows-1),rank为RANK函数返回的序号,rows为组内总行数
SELECT*,RANK() OVER w AS rankNo,PERCENT_RANK() OVER w AS percent_rankNo FROM`student` WINDOW w AS ( ORDER BY `number` DESC );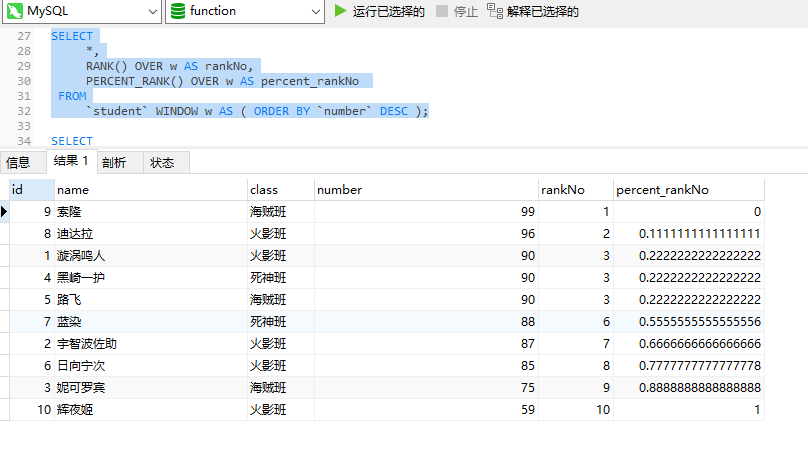
例如:路飞,percent_rankNo = (rank - 1) / (rows - 1) =(3 - 1) / (10 - 1) =0.22222222……
4.2.2CUME_DIST()
累积分布(cumulative distribution),返回分组中值的累积分布,数据分布从0到1。
计算公式:(值小于等于当前行的行数)/分组内总行数。(注意:正序是小于,倒叙是大于)
SELECT*,CUME_DIST() OVER w AS cdt FROM`student` WINDOW w AS ( ORDER BY `number` DESC );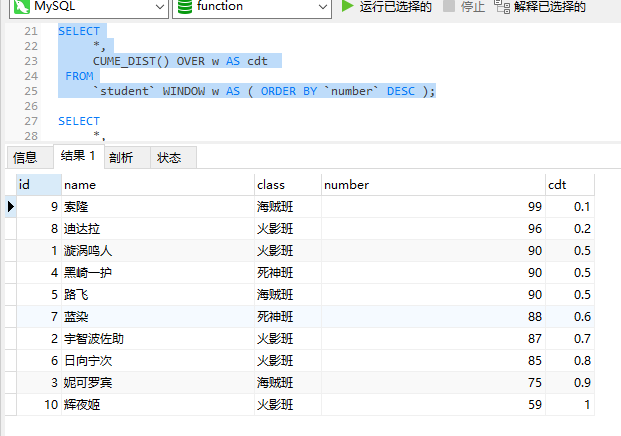
说明:上述示例中使用的是倒叙,所以大于等于索隆的只有索隆自己,所以1/10=0.1
再拿路飞举例:大于等于路飞的有5个,所以5/10=0.5
4.3前后函数
SELECT*,LAG( `number`, 1 ) OVER w AS `我的前面一名人气`,# 取前面第一行的人气值LEAD( `number`, 1 ) OVER w AS `后面一名人气` # 取后面第一行的人气值FROM`student` WINDOW w AS ( ORDER BY `number` DESC ) ;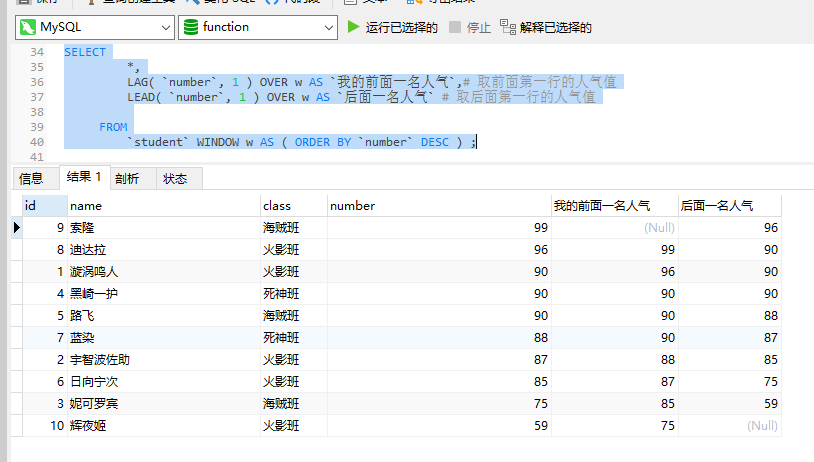
LAG(expr [, offset [, default]]):返回当前框架内当前行之前的某一行的值。参数expr为要检索的列或表达式,参数offset为要返回的行数,如果不指定,默认为1,即上一行。参数default为当指定的行数超出结果集范围时,返回的默认值。
LEAD(expr [, offset [, default]]):返回当前框架内当前行之后的某一行的值。参数expr为要检索的列或表达式,参数offset为要返回的行数,如果不指定,默认为1,即下一行。参数default为当指定的行数超出结果集范围时,返回的默认值。
4.4头尾函数
SELECT*,sum( `number` ) OVER ( ORDER BY `number` DESC ) AS `当前第一人气值`,LAST_VALUE( `number` ) OVER w AS `当前倒数第一人气值` FROM`student` WINDOW w AS ( ORDER BY `number` DESC );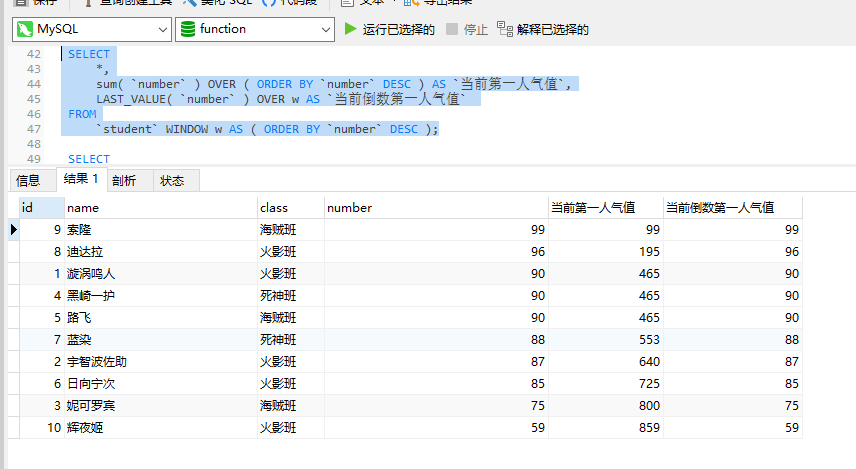
FIRST_VALUE(offset):返回当前框架对应参数第一行的值,参数expr为要检索的列或表达式,根据排序定义不同而变化。
LAST_VALUE(offset):返回当前框架对应参数最后一行的值,参数expr为要检索的列或表达式,根据排序定义不同而变化。
4.5聚合函数
SELECT*,sum( `number` ) over w1 AS current_sum,avg( `number` ) over w1 AS current_avg,count( `number` ) over w1 AS current_count,max( `number` ) over w1 AS current_max,min( `number` ) over w1 AS current_min
FROM`student` WINDOW w1 AS ( ORDER BY `number` desc);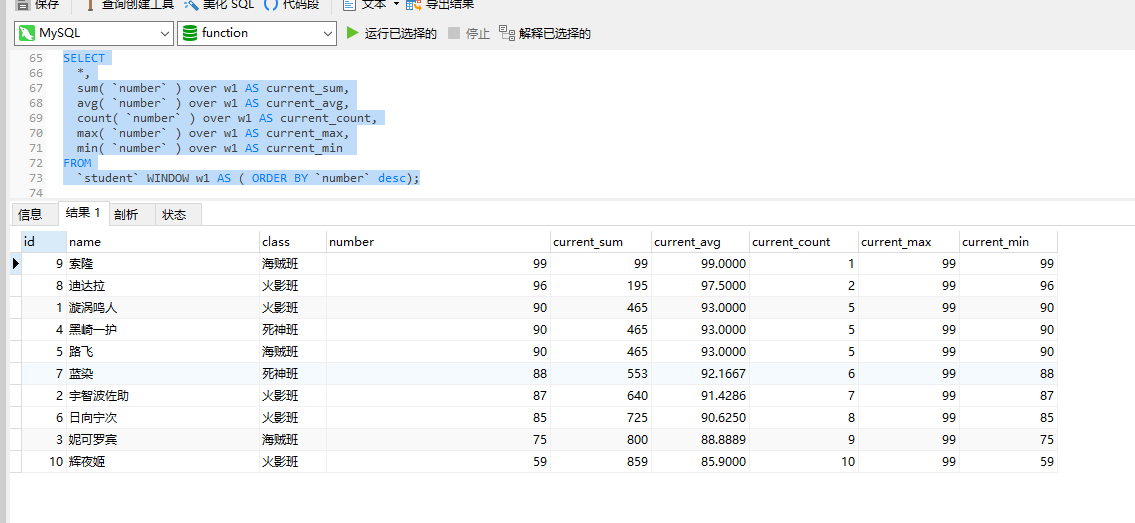
4.6其他函数
4.6.1NTH_VALUE(expr, n)
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。
例:截至当前人气,显示每个人物的人气中排名第2、第4、第6的人气值
SELECT*,NTH_VALUE( `number`, 2 ) OVER w AS `第二人气值`,NTH_VALUE( `number`, 4 ) OVER w AS `第四人气值`,NTH_VALUE( `number`, 6 ) OVER w AS `第六人气值` FROM`student` WINDOW w AS ( ORDER BY `number` DESC );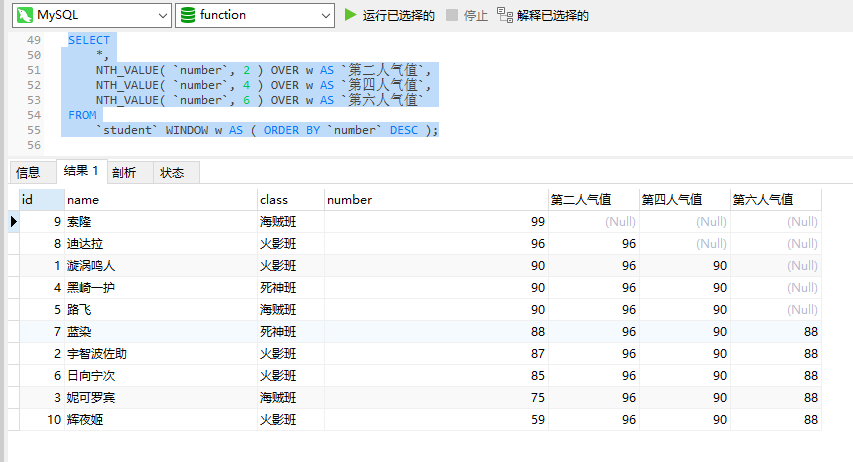
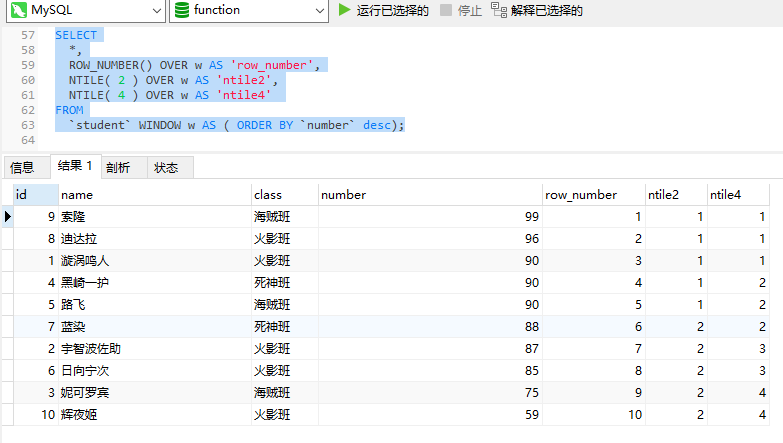
4.6.2NTILE(n)
用途:将分区中的有序数据分为n个等级,记录等级数
SELECT*,ROW_NUMBER() OVER w AS 'row_number',NTILE( 2 ) OVER w AS 'ntile2',NTILE( 4 ) OVER w AS 'ntile4'
FROM`student` WINDOW w AS ( ORDER BY `number` desc);