表的设计、聚合函数
目录
1、表的设计
1.1、一对一
1.2、一对多
1.3、多对多
2、插入查询结果
3、聚合查询
3.1、聚合函数
3.2、GROUP BY子句
1、表的设计
根据实际的需求场景,明确当前要创建几个表,每个表什么样子,这些表之间是否存在一定联系
1. 梳理清楚需求中的 “实体”
实体:需求中的关键性名词,就是前面说过的 “对象”;一般来说,每个实体,都需要安排一个表,表的列对应实体的各个属性
例如博客系统中的实体:用户,博客等
2. 再确定好实体之间的 “关系”
一对一、一对多、多对多
1.1、一对一
以教务系统为例:
一个学生只能拥有一个账号
一个账号也只能被一个学生拥有
两个实体:
学生(学生ID,姓名,……)-> student (studentld, name, ...)
账号(账号ID,用户名,密码,……)-> account (accountld, username, password,....)
建立一对一关系:
1. 学生(学生ID,姓名,账号ID,……)-> student (studentld, name, accountld, ...)
账号(账号ID,用户名,密码,……)-> account (accountld, username, password,....)
2. 学生(学生ID,姓名,……)-> student (studentld, name, accountld, ...)
账号(账号ID,用户名,密码,学生ID,……)-> account (accountld, username, password, studentld, ....)
3. 学生 - 账号(学生ID,姓名,用户名,密码,……)-> student-account (studentld, name, username, password, ....)
1.2、一对多
一个学生,只能在一个班级中
一个班级,可以包含多个学生
两个实体:
学生(学生ID,姓名,……)-> student (studentld, name, ...)
班级(班级ID,名称,……)-> class (id, name, ....)
建立一对多关系:
1. 学生(学生ID,姓名,……)-> student (studentld, name, ...)
班级(班级ID,名称,学生ID,……)-> class (id, name, studentld, ....)
由于mysql不支持数组类型,所以,使用mysql只能使用第二种方式来实现了。像redis这样的能够支持数组类型的数据库,就可以使用
2. 学生(学生ID,姓名,班级ID,……)-> student (studentld, name, classId...)
班级(班级ID,名称,……)-> class (id, name, ....)


1.3、多对多
一个学生,可以选择多门课程
一门课程,也可以包含多个学生
两个实体:
学生(学生ID,姓名,……)-> student (studentld, name, ...)
课程(课程ID,名称,……)-> course (id, name, ....)
借助一个关联表,表示多对多关系:
学生 - 课程(学生ID,课程ID)


上述三种关系都无法套入进去,此时这样两个实体没关系,各自独立设计即可,不必考虑对方
1.4、三大范式
设计数据库时的三大范式:
1.第一范式:一行数据中每一列不可再分
关系型数据库必须要满足第一范式,设计表的时候,如果每一列都可以用SQL规定的数据类型描述,就天然满足第一范式
2.第二范式:在第一范式的基础上,消除了部分函数依赖
一个表中存在复合主键,当有一列只依赖复合主键中的某一个键,那就这种设计就不满足第二范式不满足第二范式时会出现一些问题:数据冗余,更新异常,插入异常,删除异常
如果一个表中的键只有一列时,那么这种设计就天然满足第二范式
3.第三范式:在第二范式的基础上,消除了传递依赖
2、插入查询结果
把查询语句的查询结果,作为插入的数值
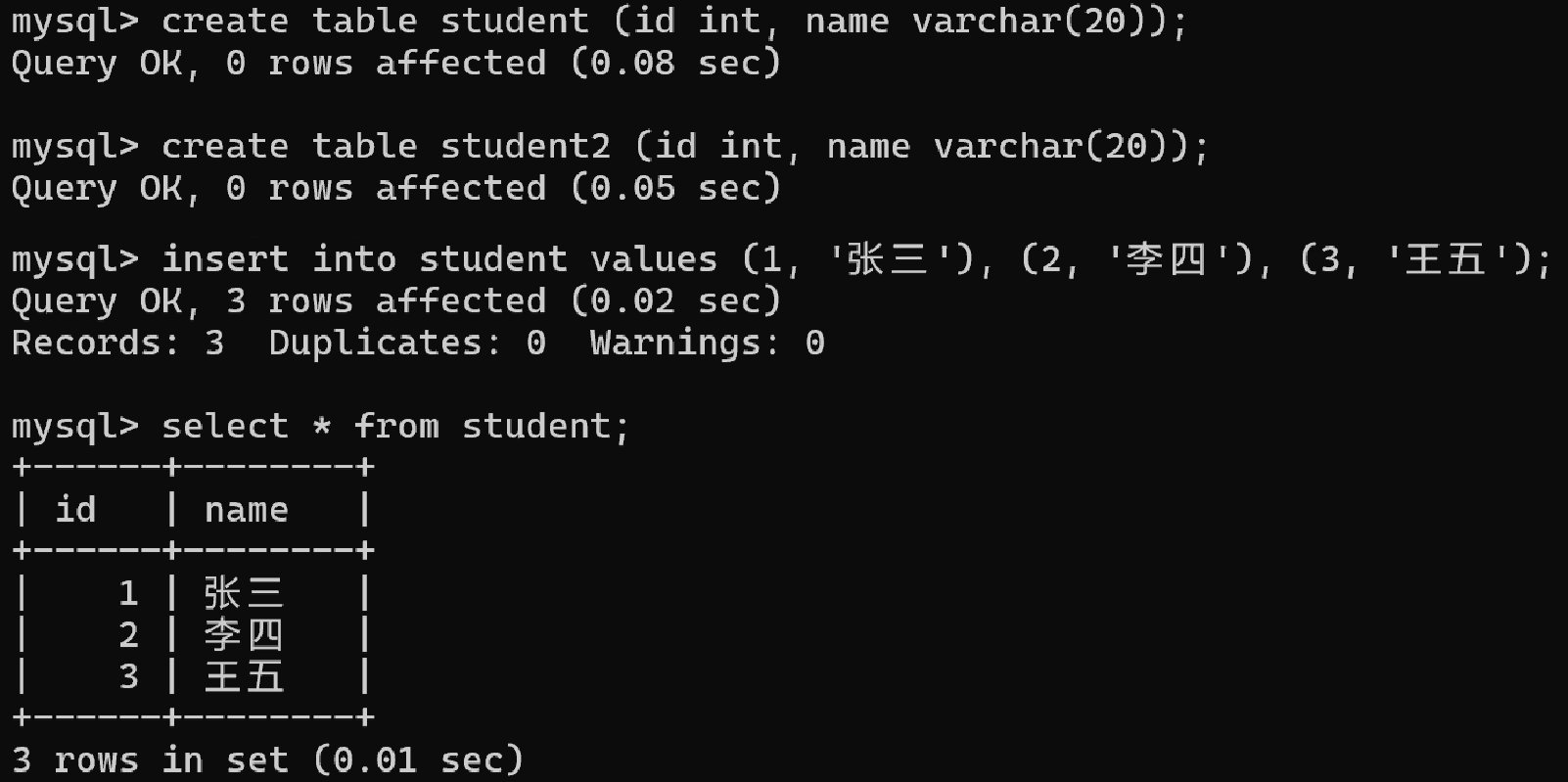
create table student (id int, name varchar(20));
create table student2 (id int, name varchar(20));
insert into student values (1, '张三'), (2, '李四'), (3, '王五');
select * from student;
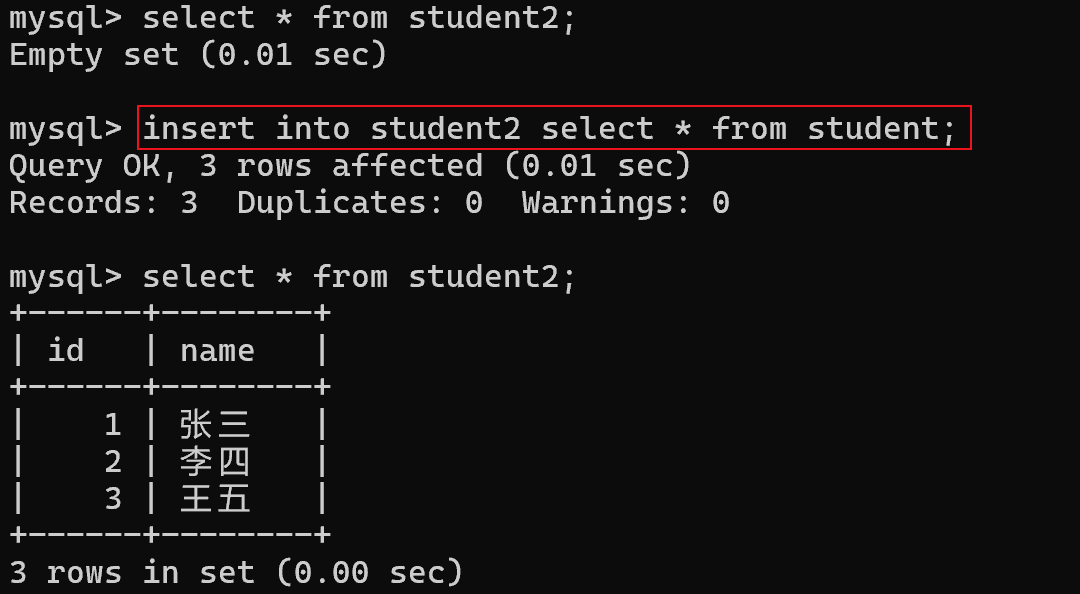
insert into student2 select * from student;
要求查询出来的结果集合,列数/类型 要和插入的表匹配
3、聚合查询
表达式查询,是针对列和列之间进行运算的;聚合查询,相当于是在行和行之间进行运算,sql中提供了一些 “聚合函数”,通过聚合函数来完成行之间的运算
3.1、聚合函数
常见的聚合函数有:【函数名和后面的 () 中间不能有空格】

补充:round(数值,小数点的位数) -- 格式化小数输出格式
以下述数据为例:
-- 创建考试成绩表
drop table if exists exam_result;
create table exam_result (id int,name varchar(20),chinese decimal(3,1),math decimal(3,1),english decimal(3,1)
);-- 插入测试数据
insert into exam_result (id,name, chinese, math, english) values(1,'唐三藏', 67, 98, 56),(2,'孙悟空', 87.5, 78, 77),(3,'猪悟能', 88, 98, 90),(4,'曹孟德', 82, 84, 67),(5,'刘玄德', 55.5, 85, 45),(6,'孙权', 70, 73, 78.5),(7,'宋公明', 75, 65, 30);- count
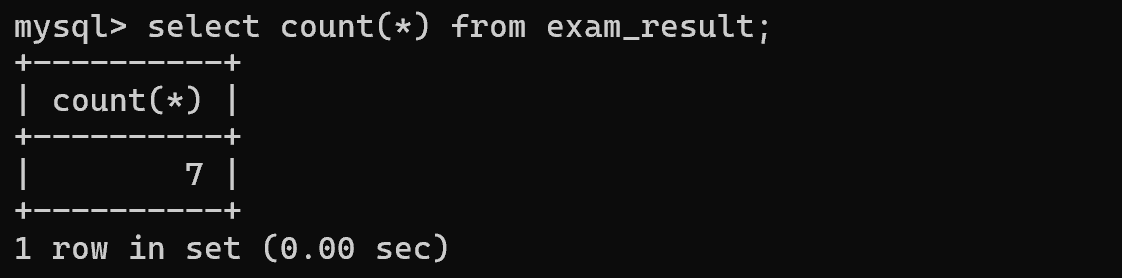
select count(*) from exam_result;
先执行select *,再针对结果集合进行统计(看看具体有几行)
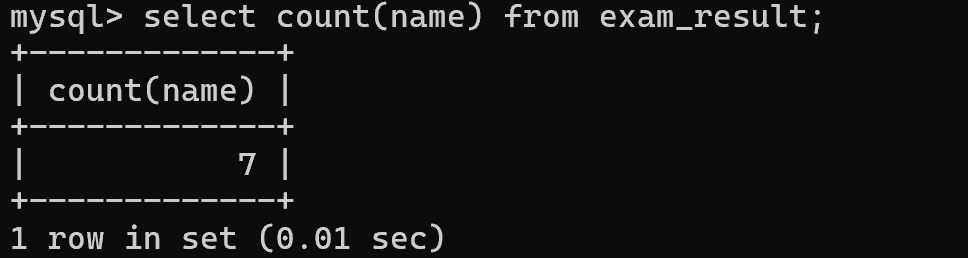
先执行select name,再针对结果集合进行统计
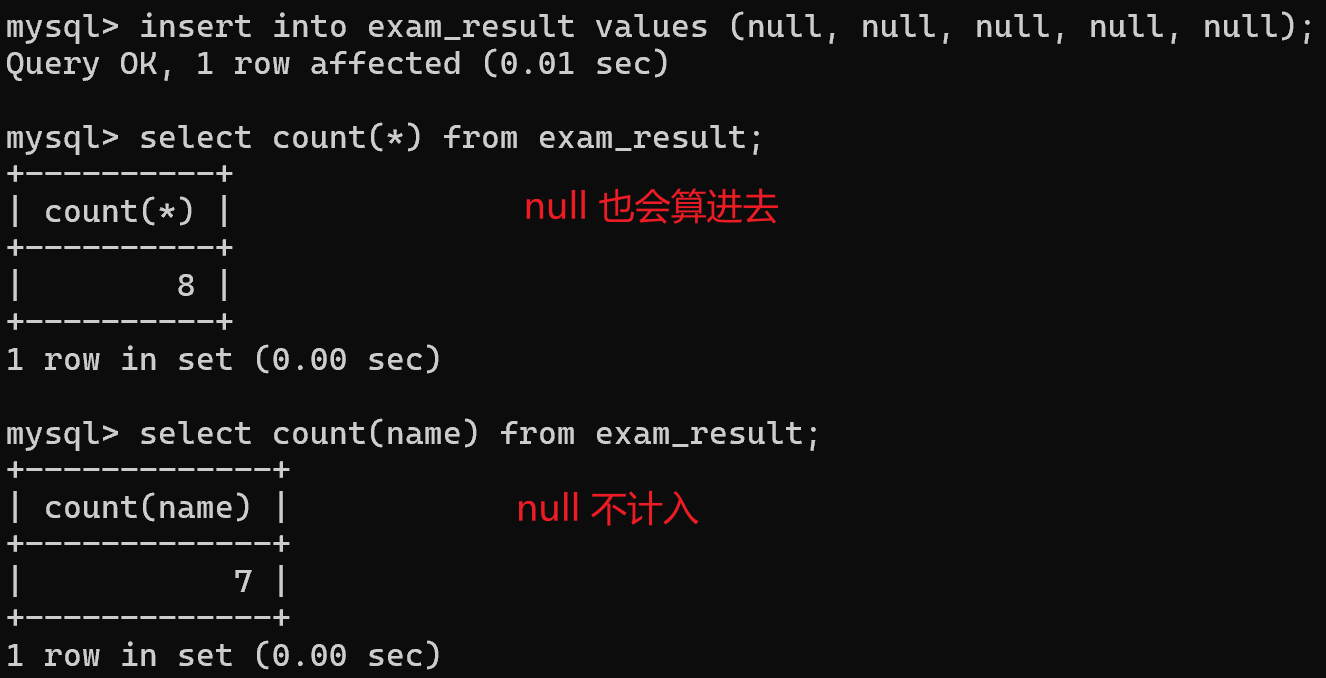
1. 如果当前的列里面有null,上述两种方式计算的 count 就不同了
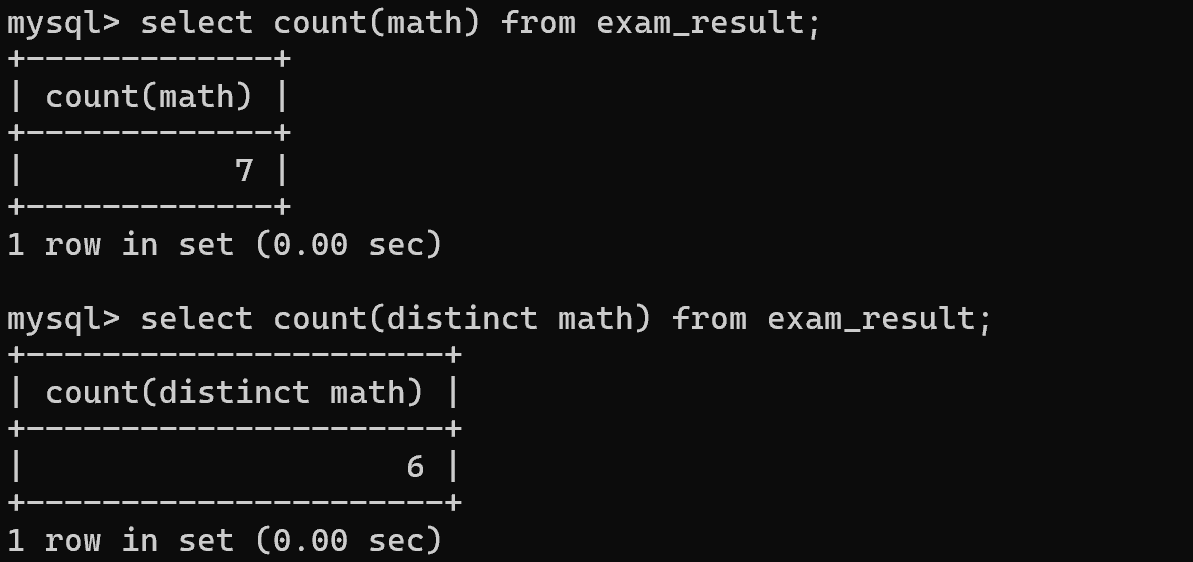
2. 指定具体列,可以去重
select count(distinct math) from exam_result;
不能 count(distinct *)

- sum
把这一列的若干行,进行求和(算术运算),只能针对数字类型使用
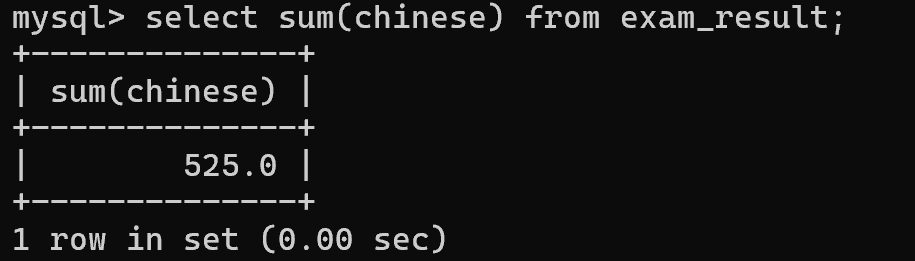
select sum(chinese) from exam_result;
相加时,遇到 null 会被排除,因为 null 做任何运算的结果都是 null
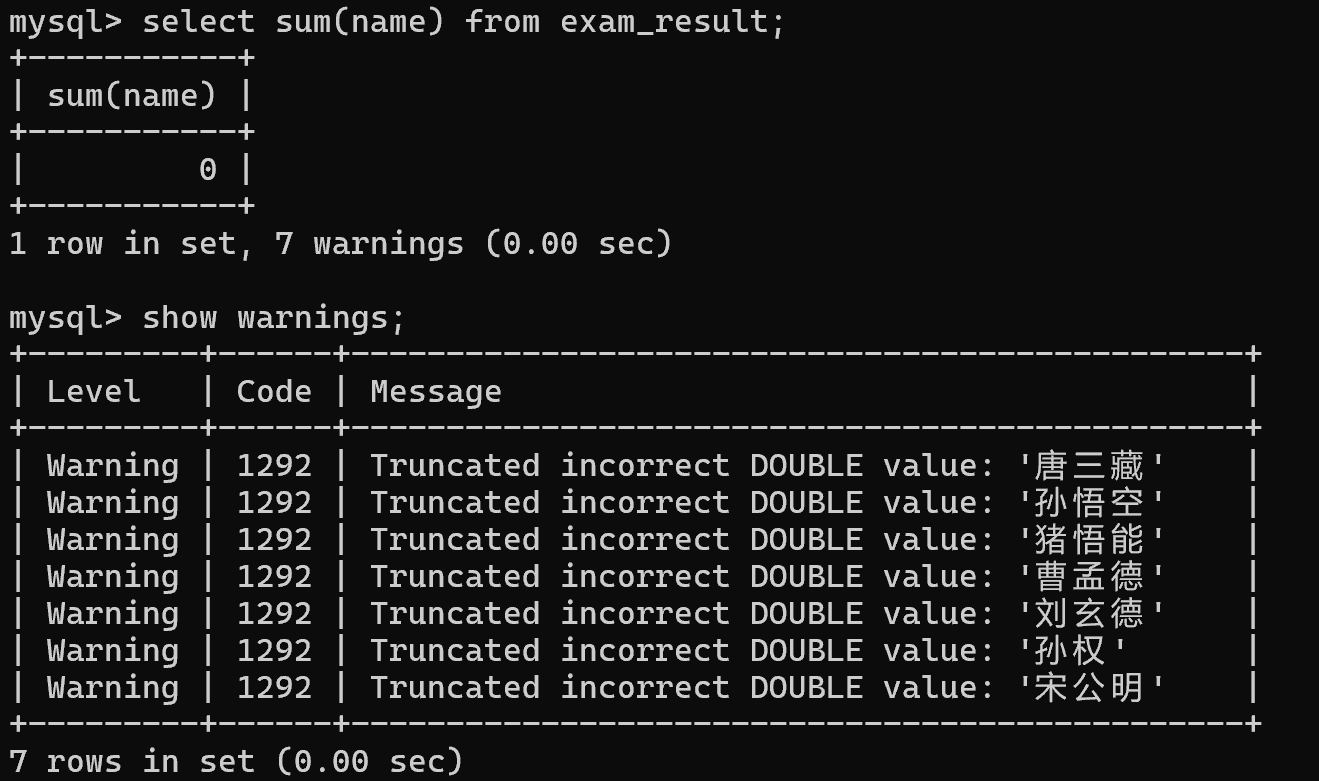
当相加的列是非数字类型的,mysql 会尝试把这一列给转成 double,如果转成了,就可以进行运算,如果没转成,就会报错
所以,遇到由数字组成的字符串,会被转成double,继续进行运算
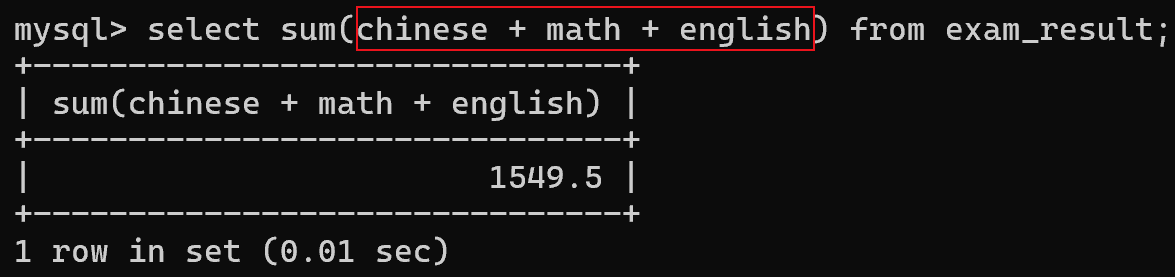
sum的括号中也可以是表达式
这行语句是分为两个阶段完成的:
1. select chinese + math + english from exam_result;(把对应的列相加,得到一个临时表)
2. 再把这个临时表的结果进行 行和行相加
avg、max、min 的用法和 sum 类似,就不过多赘述
通过上述内容不难看出,sql也是可以进行一些简单的统计操作的
3.2、GROUP BY子句
使用group by进行分组,针对每个分组,再分别进行聚合查询
具体过程:针对指定的列进行分组,把这一列中,值相同的行,分到一组中,得到若干个组后,再针对这些组,分别使用聚合函数
语法:select 要分组的列, 聚合函数(列名) from 表名 group by 要分组的列 having 对分组的结果进行过滤
以下表为例:
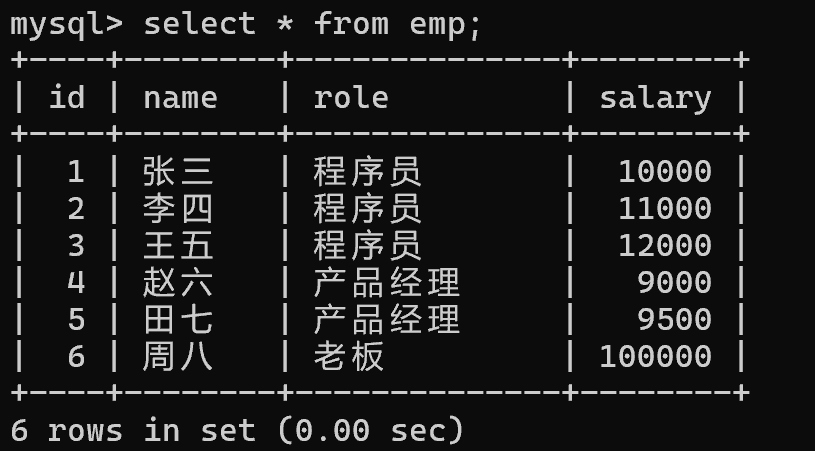
create table emp(id int primary key auto_increment, name varchar(20),role varchar(20),salary int);
insert into emp values (null, '张三', '程序员', 10000);
insert into emp values (null, '李四', '程序员', 11000);
insert into emp values (null, '王五', '程序员', 12000);
insert into emp values (null, '赵六', '产品经理', 9000);
insert into emp values (null, '田七', '产品经理', 9500);
insert into emp values (null, '周八', '老板', 100000);根据岗位这一列分组,对每组进行avg操作
select role, avg(salary) from emp group by role;
如果在针对列分组之后,不使用聚合函数,此时查询的结果就是 每一组中的某个代表数据(不一定第一个数据)
除了查询类似 role 这一列数据,能查询出所有岗位。大部分情况往往还是要搭配聚合函数使用,否则查询结果没有意义
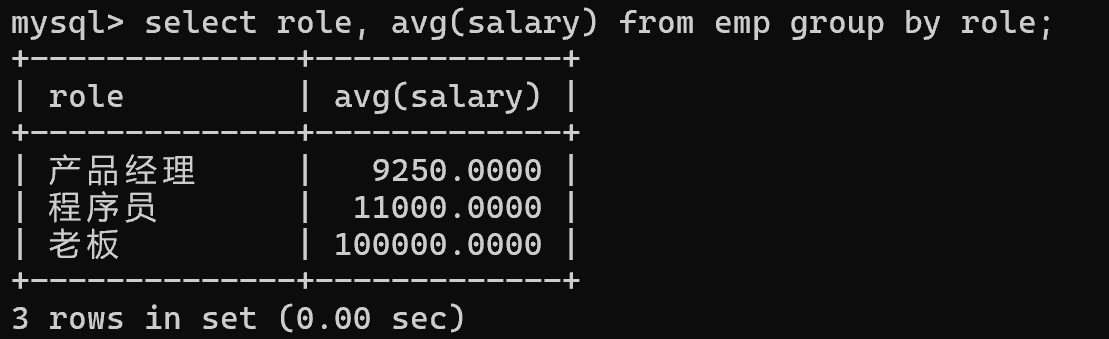
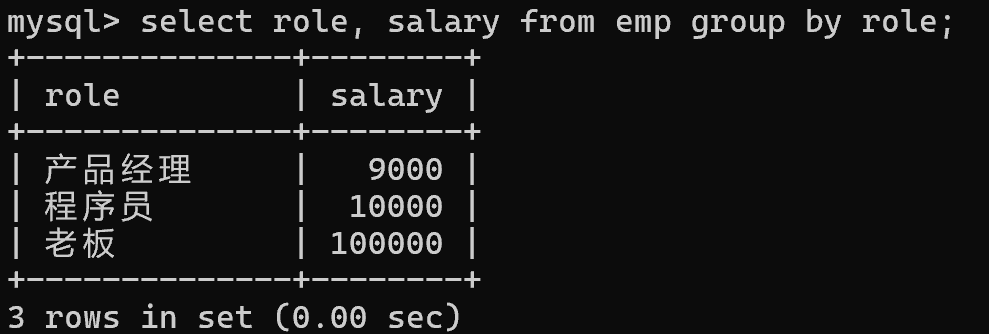
group by 还可以搭配条件
需要区分清楚,该条件是分组之前的条件,还是分组之后的条件
1. 查询每个岗位的平均工资,但是排除张三(分组之前)
直接使用 where 即可,where子句一般写在group by的前面
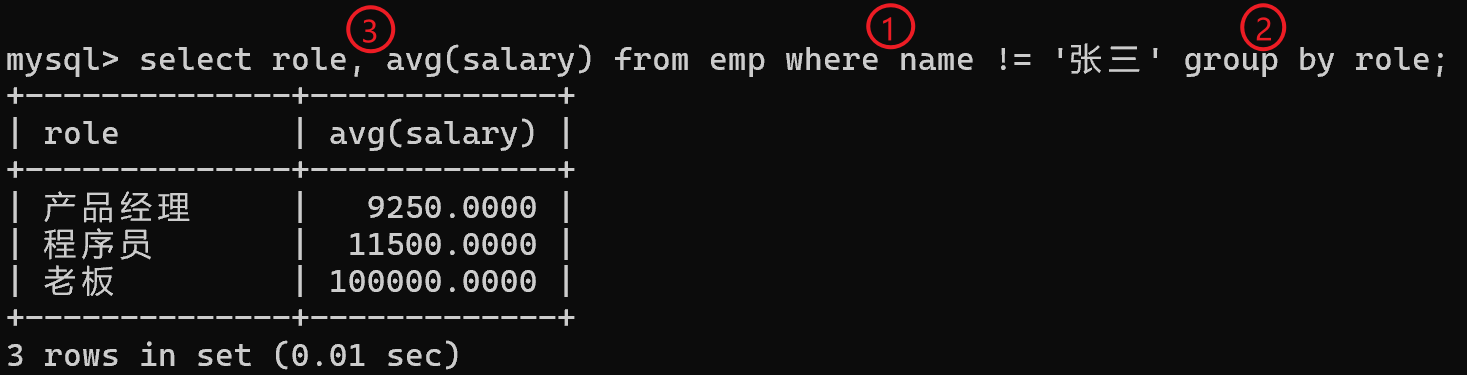
select role, avg(salary) from emp where name != '张三' group by role;
2. 查询每个岗位的平均薪资,但是排除平均薪资超过2w的结果(分组之后)
使用 having 描述条件,having子句一般写在group by的后面
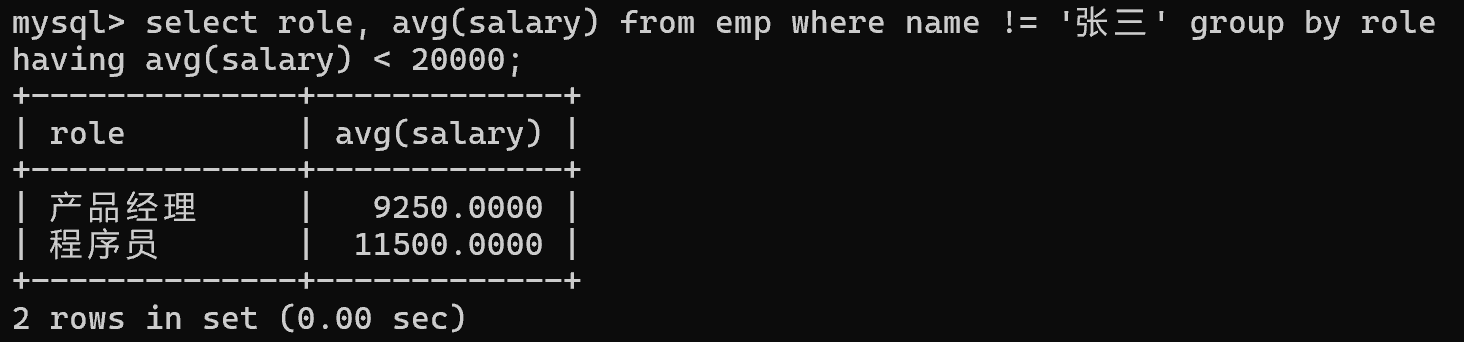
select role, avg(salary) from emp group by role having avg(salary) < 20000;
3. 查询每个岗位的平均薪资,不算张三,并且保留平均值 < 2w 的结果
一个 sql 同时完成这两类条件的筛选
select role, avg(salary) from emp where name != '张三' group by role having avg(salary) < 20000;