ReinboT:通过强化学习增强机器人视觉-语言操控能力
25年5月来自浙大和西湖大学的论文“ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning”。
视觉-语言-动作 (VLA) 模型通过模仿学习在一般机器人决策任务中展现出巨大潜力。然而,训练数据的质量参差不齐通常会限制这些模型的性能。另一方面,离线强化学习 (RL) 擅长从混合质量数据中学习稳健的策略模型。本文介绍强化的机器人 GPT (ReinboT),这是一种端到端 VLA 模型,它集成 RL 最大化累积奖励的原理。ReinboT 通过预测能够捕捉操作任务细微差别的密集回报,从而对数据质量分布有了更深入的理解。密集回报预测能力使机器人能够生成更稳健的决策动作,以最大化未来利益为导向。
近年来,针对机器人通用具身智能的视觉-语言-动作 (VLA) 模型研究蓬勃发展 (Brohan,2022;2023)。VLA 模型通常基于模仿学习范式,即使用预训练的视觉-语言模型,并利用下游机器人数据进行后训练 (Ding,2024;Zhao,2025b)。虽然通过大量的机器人训练数据,VLA 模型的语义泛化能力有所提升,但其在下游任务的操作精度方面仍然存在关键差距 (Brohan,2023;Black;Li,2024)。限制 VLA 模型性能的一个重要原因是训练数据源的质量通常参差不齐,即使它们来自成功的演示 (Hejna,2024)。尽管最近的模仿学习方法可以有效地复制演示的分布(Vuong,2023;Brohan,2023;Zhang,2025),但它们难以区分不均匀的数据质量和充分利用混合质量数据(Bai,2025)。另一方面,离线强化学习 (RL) 算法旨在利用先前收集的数据,而无需在线数据收集(Levine,2020)。尽管最初尝试将 VLA 与 RL 相结合(Mark,2024;Zhai,2024;Zhao,2025a;Guo,2025),但对于视觉-语言操作任务广泛适用密集奖励的设计以及将 RL 收益最大化概念融入 VLA 模型仍未得到充分探索。
基于序列建模的离线强化学习。自 Transformer (Vaswani,2017) 作为一种高效的序列建模模型出现以来,大量研究(Chen,2021;Yamagata,2022;Janner,2021;Zhuang,2024;Shafiullah,2022;Hu,2024)探索了序列模型作为智体策略在强化学习决策任务中的应用。Decision Transformer (Chen,2021) (DT) 通过监督学习范式在离线数据集上训练上下文条件策略模型,以历史观测值和 ReturnToGo 为条件,并输出策略模型应执行的操作。 Reinformer (Zhuang et al., 2024) 在 DT 的基础上进一步引入了最大化回报的概念。在训练过程中,Reinformer 不仅预测离线数据中以 ReturnToGo 为条件的动作,还预测策略模型后续在观察下可能获得的最大化 ReturnToGo。
VLA 模型与强化学习的融合。近期研究初步将 VLA 与 RL 相结合,旨在研究如何进一步提升 VLA 模型的操作精度和适应性,同时保留其在规模和泛化方面的最佳优势。在这些研究成果中,奖励信号的来源要么是目标是否达成的稀疏形式(Chebotar,2023;Nakamoto;Mark,2024),要么是达到目标所需的步数(Yang,2023),要么借助 LLM 模型和其他预训练视觉模型计算距离目标的距离(Zhang,2024)。然而,这些奖励设计要么面临强化学习中尚未完全解决的信用分配问题(Sutton,1984),要么受限于 LLM 的幻觉问题(Zhang,2023)。在与强化学习算法结合方面,这些工作主要对现有经过模仿学习的 VLA 模型进行微调,包括引入 Q 函数修正动作分布(Nakamoto, 2024)、筛选出高价值的动作微调策略(Mark et al.,2024;Zhang et al.,2024)以及根据人类的偏好进行微调(Chen et al.,2025)。此外,最近的一项工作(Chebotar et al.,2023)利用自回归 Q 函数来学习视觉语言操作,但其模型的序列长度和推理时间随着动作维度的增加而显著增加。
为此,本文提出强化的机器人 GPT(ReinboT),这是一种端到端 VLA 模型,用于实现 RL 最大化密集回报的概念。具体而言,高效且自动地将长视界操作任务轨迹分解为仅包含单个子目标的多个轨迹段,并设计一个能够捕捉操作任务特征的密集奖励。事实上,复杂的机器人操作任务需要考虑许多因素,例如跟踪目标、降低能耗以及保持灵活稳定的行为。因此,所提出的奖励密集化方法的设计原理基于这些考虑,并且广泛应用于各种操作任务。
VLA 模型的模仿学习
GR-1 (Wu et al. 2023) 是一个典型的 VLA 模仿学习模型,它证明视觉机器人操作可以显著受益于大规模视频生成预训练。得益于其灵活的设计,GR-1 可以在大规模视频数据集上进行预训练后,无缝地在机器人数据上进行微调。GR-1 是一个 GPT 风格的模型,以语言指令 l、历史图像观测值 o_t−h:t 和本体感觉 s_t−h:t 作为输入。它以端到端的方式预测机器人动作和未来图像 ⟨oˆ_t+1, aˆ_t⟩ = π(l, ⟨o, s⟩_t−h:t)。
最大回报序列建模
序列模型 DT (Chen,2021) 根据历史轨迹和 ReturnToGo 最大化动作的可能性,本质上将离线强化学习转化为监督序列建模。
Reinformer (Zhuang et al., 2024) 将最大化收益的目标融入序列模型。具体来说,Reinformer 预测当前状态在数据集所代表的数据分布中可能获得的最大收益,而不是当前轨迹的真实 ReturnToGo 收益。Reinformer 通过最小化预期回归损失隐式地实现了这一点。
相比于 DT,Reinformer 的一个优势在于推理时无需指定 ReturnToGo 的初始值以及环境返回的奖励,而是通过两种模型推理,自回归地预测下一步的最大ReturnToGo值和动作。
本文旨在构建一个端到端 VLA 模型,将最大化密集奖励的原则融入机器人视觉运动控制中,如图所示。首先,在设计密集奖励时考虑四个主要因素,以捕捉机器人长视域操作任务的本质。然后,详细阐述了如何构建一个端到端强化学习 VLA 模型和测试执行流程。最后,讨论并分析所提出的 ReinboT 如何有机地整合强化学习最大化奖励的原则。
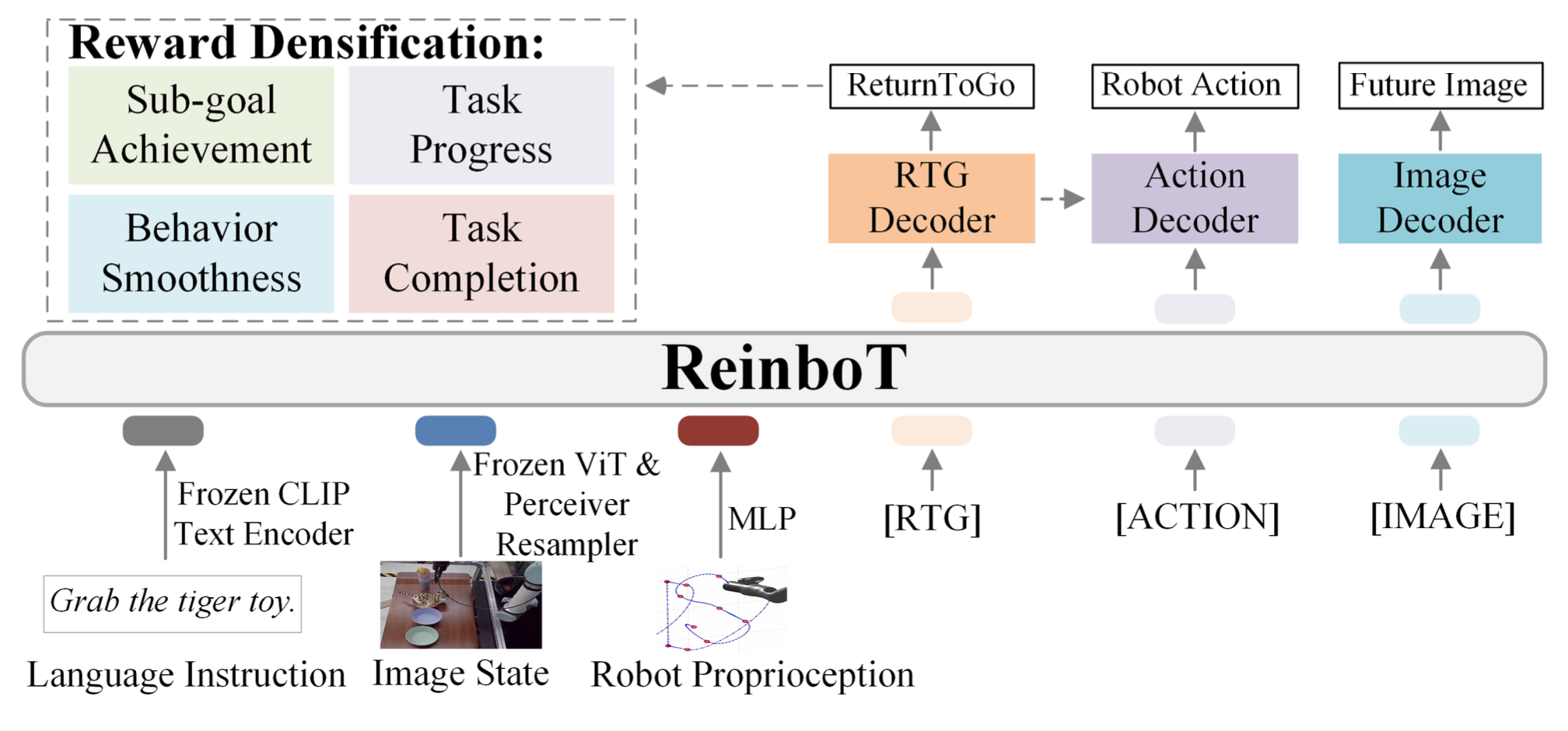
奖励密集化
对于长视域视觉-语言操作任务,VLA 模型通常需要在遵循目标的同时,以最小的能量成本保持鲁棒稳定的行为。因此,主要围绕这一原则设计一个广泛适用的密集奖励机制,以捕捉操作任务的本质。直观地讲,在机器人轨迹中,最小化状态距离的奖励是一种简单有效的方案,可以鼓励机器人直接移动到目标状态。然而,这种奖励仅限于任务仅包含一个目标的情况。对于需要操作具有多个子目标的长视域任务,这种奖励会引导机器人直接移动到最终目标状态,从而造成失败 (Zhao et al., 2024)。
因此,首先采用启发式方法 (James & Davison, 2022; Shridhar et al., 2023) 将长视域操作任务划分为多个子目标序列,并为每个序列设计一个密集奖励。启发式过程会迭代每个演示轨迹中的状态,并确定该状态是否应被视为临界状态。判断基于两个主要约束:关节速度接近于零以及夹持器状态的变化。直观地讲,临界状态发生在机器人达到预抓取姿势或转换到新任务阶段时,或者抓取或释放目标时。因此,将临界状态作为子目标是一个自然而合理的选择。
子目标达成。图像状态 o_t 和本体感知 s_t 都包含丰富的环境感知信息。因此,子目标达成奖励 r_1 涵盖本体感知跟踪、像素强度、图像视觉质量和图像特征点。
利用均方误差(MSE)计算图像状态o_t(以及本体感觉s_t)与子目标图像状态o∗_t(以及子目标本体感觉s∗_t)的直接差异,并利用结构相似度指数(SSIM)衡量图像的视觉质量。用于计算奖励的 Oriented FAST and Rotated BRIEF (ORB) (Rublee et al., 2011)算法专注于图像特征点的提取和匹配。具体而言,首先在当前图像状态和子目标图像状态上检测关键点,进行特征匹配和匹配点筛选,最后通过匹配点数量计算相似度。
任务进度。考虑到划分为多个子目标序列对整体轨迹的影响不同,后面的序列更接近最终目标状态,为了体现这一点,设计任务进度奖励r_2:r_2 = n(s_t) / |{s^∗}| 。子目标序列越接近最终目标状态,任务进度奖励越大。
行为平滑度。为了促进运动轨迹平滑自然,主要考虑抑制机械臂运动的关节速度 q̇ 和加速度 q̈ 以及动作 a_t 的变化率,从而惩罚过于剧烈僵硬的轨迹运动。行为平滑度奖励 r_3 为:
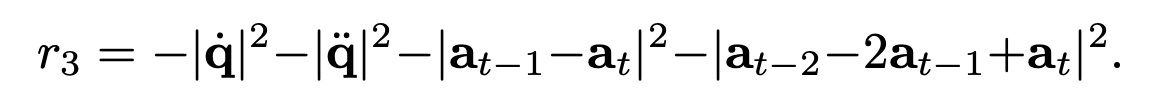
任务完成。对于视觉语言操作任务,语言指导被视为与机器人行为相匹配的目标。任务完成奖励 r_4 为: r_4 = 1 {τ is successful}.
基于这四个主要因素,一般密集奖励捕捉到长视界视觉-语言操作任务的本质。
通过利用设计的奖励信号,ReinboT 可以对训练数据的质量分布有更广泛、更深入的理解和识别,从而指导机器人执行更稳健、稳定的机器人决策动作。
端到端强化 VLA 模型
通过提出的密集奖励机制,可以得到用于长视域视觉语言操作任务的 ReturnToGo (RTG) g_t = sum(r_j)。
ReinboT 模型采用 GPT 风格的 Transformer (Radford, 2018) 作为骨干网络 π_θ,因为它可以灵活高效地使用不同类型的模态数据作为输入和输出。CLIP (Radford et al., 2021) 用于编码语言指令,ViT (Dosovitskiy et al., 2020; He et al., 2022)(以及感知器重采样器 (Jaegle et al., 2021))用于压缩和编码图像状态,MLP 用于编码本体感觉。
引入动作和图像 token 嵌入([ACTION] 和 [IMAGE]),并分别通过动作解码器 P_ω 和图像解码器 P_ν 预测机器人动作和未来图像状态。最重要的是,将 ReturnToGo 视为一种新的数据模态,并学习 ReturnToGo 预测 token 嵌入 [RTG]。通过 ReturnToGo 解码器 P_φ,根据语言指令 l、图像状态 o 和本体感觉 s 预测最大化回报。
ReinboT 模型的损失函数 L 包括 ReturnToGo 损失 L_RTG、手臂动作平滑 L1 损失 L_arm、夹持器动作交叉熵损失 L_gripper 和未来图像像素-级损失 L_image。
当设计如何利用包含 ReturnToGo 的特征信息预测动作 a 时,在 ReinboT 网络结构中做模块化设计。具体来说,首先将语言指令 l、图像状态 o_t−u+1:t 和本体感觉 s_t−u+1:t 输入到骨干网络 π_φ 中,得到 [RTG] 和 [ACTION] token 嵌入对应的特征 h^RTG_t:t+k−1 和 h^action_t:t+k−1:
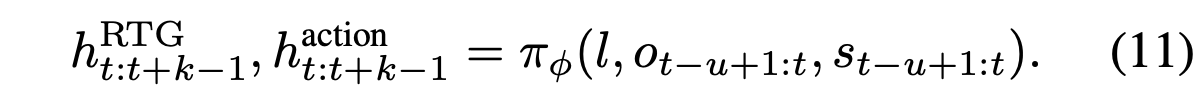
然后将特征 h^RTG_t:t+k−1 输入 ReturnToGo 解码器 P_φ,得到最后一层隐特征 gˆhidden_t:t+k−1:
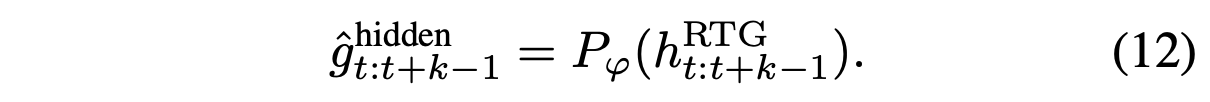
隐特征 gˆhidden_t:t+k−1 与动作特征 h^action_t:t+k−1 连接,并进一步输入动作解码器 P_ω,预测动作 aˆ_t:t+k−1:
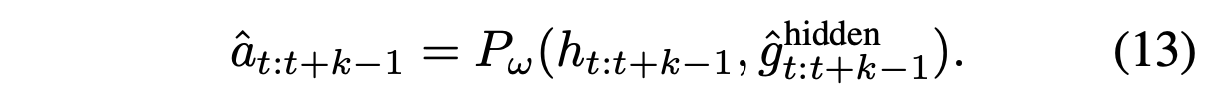
ReinboT 的模块化设计,只需单次模型推理即可获得机器人动作,从而比 Reinformer 模型具有更高的推理效率。这种设计更大的好处在于,在推理阶段,不需要像 DT 模型那样手动设置 ReturnToGo 的初始值。这对于实际部署至关重要,因为它大大减轻手动调整参数的繁琐性,并且实际部署环境在很大程度上无法直接获得奖励。ReinboT 推理流程已在如下算法 1 中进行总结。

ReinboT 的讨论与分析
与常见的端到端 VLA 模型相比,所提出的 ReinboT 最显著的特点是额外引入 ReturnToGo 损失,并且动作会受到 ReturnToGo tokens gˆhidden_t:t+k−1(13)的影响。随后将分析该框架如何实现强化学习的回报最大化,以及与经典强化学习中回报最大化的区别和优势。
以某个日期点(l, ⟨o, s⟩_t−h+1 , g_t, a_t)为例。ReturnToGo 的损失基于预期回归实现,其关键参数为 m。当 m = 0.5 时,预期回归退化为 MSE,预测的 ReturnToGo tokens gˆ_t 趋近于真实值 g_t。此时,ReinboT 退化为模仿学习的范式,也就是常见的带有 ReturnToGo token 预测的端到端 VLA 模型。当 m > 0.5 时,预期回归会预测 gˆ_t 大于 g_t,这被称为收益最大化。这种最大化的收益引导 ReinboT 预测更优的行为。然而,盲目增加 m 会导致模型对训练数据分布中可实现的最大收益做出过于乐观的估计。相关理论分析参见 Reinformer (Zhuang et al., 2024)。
在经典的强化学习算法中,最大化 Q 值被用来实现最佳策略模型。这意味着在 VLA 中应用强化学习需要引入额外的强化学习损失函数。这样的添加可能会对 Transformer 等模型的学习过程造成障碍 (Mishra,2018;Parisotto,2020;Davis,2021)。相比之下,本文回报条件最大化避免纳入 RL 特定损失的需要。
首先构建一个基于 CALVIN (Mees et al., 2022) 的混合质量数据集,其中包含长期操控任务,以检查所提出的 ReinboT 和基线算法的性能。该数据集包含少量带有 CALVIN A/B/C 语言指令的数据(每个任务约 50 条轨迹)和大量不带有语言指令的自主数据。除了 CALVIN 中人类遥控操作在没有语言指令的情况下收集的原始数据(超过 20,000 条轨迹)之外,自主数据还包含由训练的 VLA 行为策略 RoboFlamingo (Li et al., b) 与环境 CALVIN D(超过 10,000 条轨迹)交互产生的失败数据。为了促进数据多样性,在交互过程中向 RoboFlamingo 策略模型的动作添加不同程度的高斯噪声(0.05、0.1 和 0.15)。其研究在此混合质量数据上进行训练,然后用语言指令对少量数据进行微调,最后在 CALVIN D 上测试泛化性能。
为了全面评估所提出的 ReinboT 模型的有效性,考虑了一些具有代表性的基线算法和奖励设计方法,包括 RoboFlamingo (Li et al., b)、GR-1 (Wu et al.)、PIDM (Tian et al., 2024)(三种模仿学习类型)、GR-MG (Li et al., 2025)(分层模仿学习类型)和 RWR (Peters & Schaal, 2007)(离线 RL 类型)。“带注释的数据”意味着该模型仅在少量带有文本注释的数据上进行训练(每个任务约 50 条轨迹)。“稀疏”意味着利用稀疏奖励,即成功轨迹的最后三步的奖励为 1,其余为 0(Nakamoto et al.)。 “sub-goal, sparse”表示使用稀疏奖励,即成功轨迹的最后三步和子目标状态的奖励为 1,其余为 0。“dense, single” 表示使用本文提出的密集奖励,在计算 ReturnToGo 损失时使用最终计算出的单维标量回报。“dense, full” 表示使用本文提出的密集奖励,预测的 ReturnToGo 是一个包含计算的单维标量回报和每个回报分量的向量。
对现实世界的任务进行评估,以检验所提出的 ReinboT 是否可以在现实场景中执行有效的少样本学习和泛化。具体来说,考虑在机械臂 UR5 上拾取和放置杯子、碗和毛绒玩具等物体的任务。收集的成功轨迹总数约为 530,并且首先在这些数据上训练模型。对于少样本学习评估,考虑三个物体抓取和放置任务。每个任务仅包含 30 条成功轨迹,并且模型在这三个任务上进行微调。对于 OOD 泛化评估,考虑具有未见过的指令、背景、干扰项和被操纵物体的场景。如图所示:
