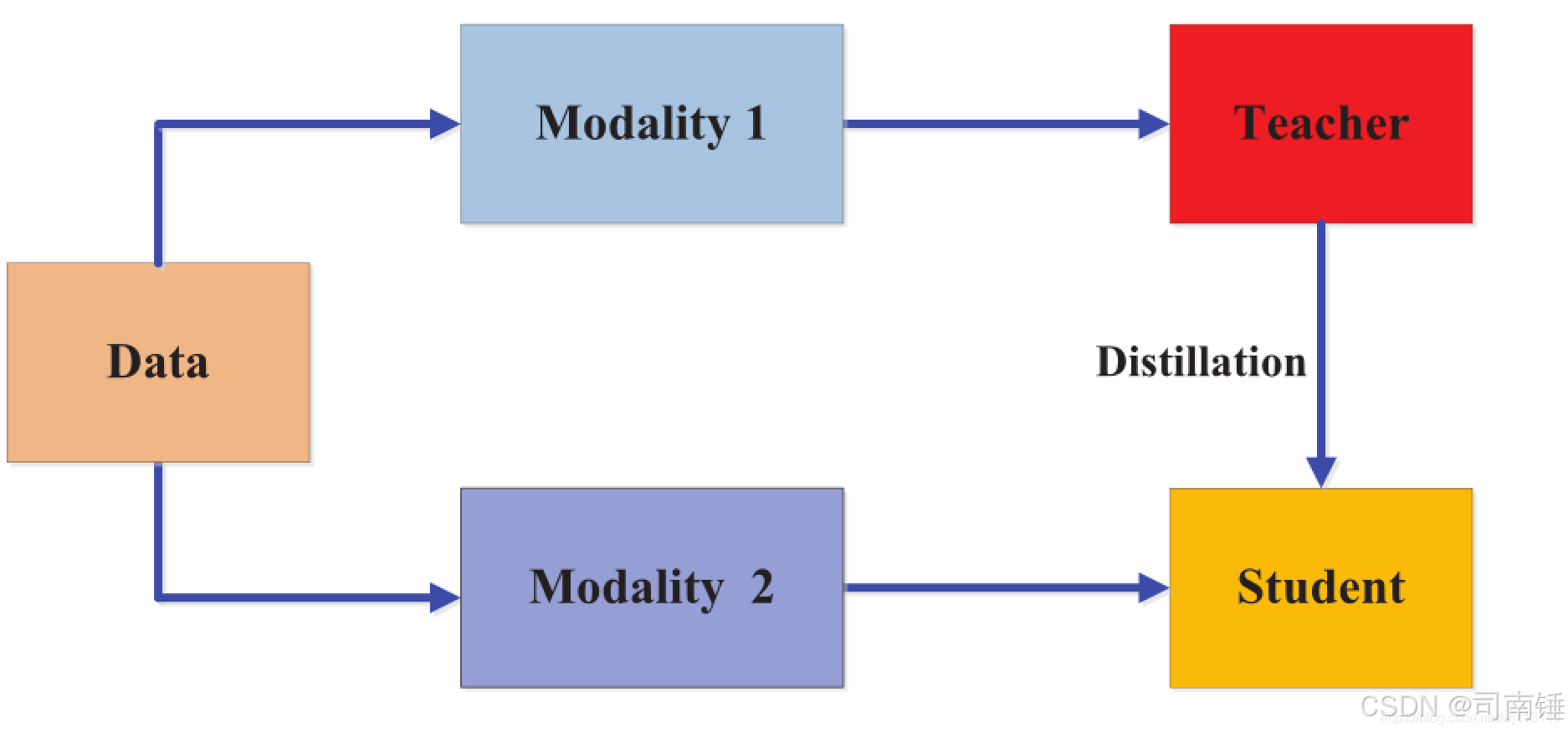
TensorFlow/Keras实现知识蒸馏案例
- 创建一个“教师”模型(一个稍微复杂点的网络)。
- 创建一个“学生”模型(一个更简单的网络)。
- 使用“软标签”(教师模型的输出概率)和“硬标签”(真实标签)来训练学生模型。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np# 0. 准备一些简单的数据 (例如 MNIST)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()# 数据预处理
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)# 将标签转换为独热编码
y_train_cat = keras.utils.to_categorical(y_train, num_classes=10)
y_test_cat = keras.utils.to_categorical(y_test, num_classes=10)# 1. 定义教师模型
teacher_model = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),layers.MaxPooling2D(pool_size=(2, 2)),layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),layers.MaxPooling2D(pool_size=(2, 2)),layers.Flatten(),layers.Dense(128, activation="relu"),layers.Dense(10, name="teacher_logits"), # 输出 logitslayers.Activation("softmax") # 输出概率,用于评估],name="teacher",
)
teacher_model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]
)
print("--- 训练教师模型 ---")
teacher_model.fit(x_train, y_train_cat, epochs=5, batch_size=128, validation_split=0.1, verbose=2)
loss, acc = teacher_model.evaluate(x_test, y_test_cat, verbose=0)
print(f"教师模型在测试集上的准确率: {acc:.4f}")# 2. 定义学生模型 (更小更简单)
student_model = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Flatten(),layers.Dense(32, activation="relu"),layers.Dense(10, name="student_logits"), # 输出 logitslayers.Activation("softmax") # 输出概率,用于评估],name="student",
)# 3. 定义蒸馏损失函数
class Distiller(keras.Model):def __init__(self, student, teacher):super().__init__()self.teacher = teacherself.student = studentself.student_loss_fn = keras.losses.CategoricalCrossentropy(from_logits=False) # 学生模型使用真实标签的损失self.distillation_loss_fn = keras.losses.KLDivergence() # KL散度作为蒸馏损失self.alpha = 0.1 # 蒸馏损失的权重self.temperature = 3 # 蒸馏温度,用于平滑教师模型的输出def compile(self,optimizer,metrics,student_loss_fn,distillation_loss_fn,alpha,temperature,):super().compile(optimizer=optimizer, metrics=metrics)self.student_loss_fn = student_loss_fnself.distillation_loss_fn = distillation_loss_fnself.alpha = alphaself.temperature = temperaturedef train_step(self, data):x, y = data # y 是真实标签 (硬标签)# 获取教师模型的软标签# 注意:我们通常使用教师模型的 logits (softmax之前的输出) 并应用温度# 但为了简化,这里直接使用教师模型的softmax输出,并在损失函数中处理温度# 更严谨的做法是在教师模型输出logits后,除以temperature再进行softmaxteacher_predictions_raw = self.teacher(x, training=False) # 教师模型不参与训练with tf.GradientTape() as tape:# 学生模型对输入的预测student_predictions_raw = self.student(x, training=True)# 计算学生损失 (使用硬标签)student_loss = self.student_loss_fn(y, student_predictions_raw)# 计算蒸馏损失 (使用教师的软标签)# 软化教师和学生的概率分布# 使用教师模型的 logits (如果可用) 并除以 temperature 会更好# 这里为了简化,我们假设 teacher_predictions_raw 是概率,学生也是# 实际上 KLDivergence 期望 y_true 和 y_pred 都是概率分布# KLDivergence(softmax(teacher_logits/T), softmax(student_logits/T))# 这里我们简化为直接使用softmax输出,并在KLDivergence内部处理# 注意:KLDivergence的输入应该是概率分布。# 实际应用中,更常见的做法是先获取教师的logits,然后进行如下操作:# teacher_logits = self.teacher.get_layer('teacher_logits').output# soft_teacher_targets = tf.nn.softmax(teacher_logits / self.temperature)# soft_student_predictions = tf.nn.softmax(self.student.get_layer('student_logits').output / self.temperature)# dist_loss = self.distillation_loss_fn(soft_teacher_targets, soft_student_predictions) * (self.temperature ** 2)# 为了代码的简洁性,我们这里直接使用Keras内置的KLDivergence,它期望概率输入# 我们不显式地在这里应用temperature到softmax,而是理解为蒸馏目标本身就比较“软”# 实际上,更标准的蒸馏损失是 KL(softmax(teacher_logits/T) || softmax(student_logits/T))# Keras 的 KLDivergence(y_true, y_pred) 计算的是 sum(y_true * log(y_true / y_pred))# 当y_true是教师的软标签时,它已经是概率了。distillation_loss = self.distillation_loss_fn(tf.nn.softmax(teacher_predictions_raw / self.temperature), # 软化教师的预测tf.nn.softmax(student_predictions_raw / self.temperature) # 软化学生的预测)# KLDivergence 期望 y_true 和 y_pred 都是概率。# 如果教师输出的是logits,正确的软化方式是:# soft_teacher_labels = tf.nn.softmax(teacher_logits / self.temperature)# soft_student_probs = tf.nn.softmax(student_logits / self.temperature)# dist_loss = self.distillation_loss_fn(soft_teacher_labels, soft_student_probs)# Hinton论文中的蒸馏损失通常乘以 T^2# 但这里KLDivergence的实现可能有所不同,我们先简化# loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss # Hinton论文是这样# 或者,更常见的是:loss = (1 - self.alpha) * student_loss + self.alpha * (self.temperature**2) * distillation_loss# 计算梯度trainable_vars = self.student.trainable_variablesgradients = tape.gradient(loss, trainable_vars)# 更新学生模型的权重self.optimizer.apply_gradients(zip(gradients, trainable_vars))# 更新指标self.compiled_metrics.update_state(y, student_predictions_raw)results = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss, "distillation_loss": distillation_loss})return resultsdef test_step(self, data):x, y = datay_prediction = self.student(x, training=False)student_loss = self.student_loss_fn(y, y_prediction)self.compiled_metrics.update_state(y, y_prediction)results = {m.name: m.result() for m in self.metrics}results.update({"student_loss": student_loss})return results# 4. 初始化和编译蒸馏器
distiller = Distiller(student=student_model, teacher=teacher_model)
distiller.compile(optimizer=keras.optimizers.Adam(),metrics=["accuracy"],student_loss_fn=keras.losses.CategoricalCrossentropy(from_logits=False),distillation_loss_fn=keras.losses.KLDivergence(),alpha=0.2, # 蒸馏损失的权重 (原始学生损失权重为 1-alpha)temperature=5.0, # 蒸馏温度
)# 5. 训练学生模型 (通过蒸馏器)
print("\n--- 训练学生模型 (蒸馏) ---")
distiller.fit(x_train, y_train_cat, epochs=10, batch_size=256, validation_split=0.1, verbose=2)# 评估蒸馏后的学生模型
loss, acc = student_model.evaluate(x_test, y_test_cat, verbose=0)
print(f"蒸馏后的学生模型在测试集上的准确率: {acc:.4f}")# (可选) 单独训练一个没有蒸馏的学生模型作为对比
print("\n--- 训练学生模型 (无蒸馏) ---")
student_model_scratch = keras.Sequential([keras.Input(shape=(28, 28, 1)),layers.Flatten(),layers.Dense(32, activation="relu"),layers.Dense(10, activation="softmax"),],name="student_scratch",
)
student_model_scratch.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]
)
student_model_scratch.fit(x_train, y_train_cat, epochs=10, batch_size=256, validation_split=0.1, verbose=2)
loss_scratch, acc_scratch = student_model_scratch.evaluate(x_test, y_test_cat, verbose=0)
print(f"从零开始训练的学生模型在测试集上的准确率: {acc_scratch:.4f}")代码解释:
- 数据准备: 使用了经典的 MNIST 数据集。
- 教师模型 (
teacher_model): 一个包含两个卷积层和一个全连接层的简单卷积神经网络。它首先在数据集上进行正常的训练。 - 学生模型 (
student_model): 一个非常简单的模型,只有一个全连接层。我们的目标是让这个小模型通过蒸馏学习到教师模型的部分能力。 Distiller类:__init__: 初始化时接收教师模型和学生模型。compile: 配置优化器、指标,以及两个关键的损失函数:student_loss_fn(学生模型直接与真实标签计算损失) 和distillation_loss_fn(学生模型与教师模型的软标签计算损失)。alpha用于平衡这两种损失,temperature用于平滑教师模型的输出概率,使其更“软”,包含更多类别间的信息。train_step: 这是自定义训练的核心。- 首先,获取教师模型对当前批次数据的预测 (
teacher_predictions_raw)。教师模型设置为training=False,因为我们不希望在蒸馏过程中更新教师模型的权重。 - 然后,在
tf.GradientTape上下文中,获取学生模型的预测 (student_predictions_raw)。 - 学生损失 (
student_loss): 学生模型的预测与真实标签 (y) 之间的交叉熵损失。 - 蒸馏损失 (
distillation_loss):- 我们使用
tf.nn.softmax(predictions / self.temperature)来软化教师和学生的预测。温度T越大,概率分布越平滑,类别之间的差异信息越能被学生模型学习到。 - 然后使用
KLDivergence计算软化的学生预测与软化的教师预测之间的KL散度。KL散度衡量两个概率分布之间的差异。 - Hinton 等人的原始论文中,蒸馏损失项通常还会乘以
temperature**2来保持梯度的大小与不使用温度时的梯度大小相当。
- 我们使用
- 总损失 (
loss): 学生损失和蒸馏损失的加权和。alpha控制蒸馏损失的贡献程度。常见的组合是(1 - alpha) * student_loss + alpha * scaled_distillation_loss。 - 最后,计算梯度并更新学生模型的权重。
- 首先,获取教师模型对当前批次数据的预测 (
test_step: 在评估阶段,我们只关心学生模型在真实标签上的表现。
- 训练和评估:
- 创建
Distiller实例。 - 编译
Distiller,传入必要的参数。 - 调用
distiller.fit()来训练学生模型。 - 最后,评估蒸馏后的学生模型的性能。
- 创建
- 对比: (可选) 我们还训练了一个同样结构但没有经过蒸馏的学生模型 (
student_model_scratch),以便对比蒸馏带来的效果。通常情况下,蒸馏后的学生模型性能会优于从零开始训练的同结构小模型,尤其是在复杂任务或小模型容量有限时。
关键概念:
- 软标签 (Soft Labels): 教师模型输出的概率分布(经过温度平滑)。与硬标签(one-hot 编码的真实类别)相比,软标签包含了更多关于类别之间相似性的信息。例如,教师模型可能认为一张图片是数字 “7” 的概率是 0.7,是数字 “1” 的概率是 0.2,是其他数字的概率很小。这种信息对学生模型很有价值。
- 温度 (Temperature, T): 一个超参数,用于在计算 softmax 时平滑概率分布。较高的温度会产生更软的概率分布(熵更高),使非目标类别的概率也相对提高,从而让学生模型学习到更多类别间的细微差别。
- KL 散度 (Kullback-Leibler Divergence): 用于衡量两个概率分布之间差异的指标。在蒸馏中,我们希望最小化学生模型的软输出与教师模型的软输出之间的KL散度。
- 损失函数组合: 总损失函数通常是学生模型在真实标签上的标准损失(如交叉熵)和蒸馏损失(如KL散度)的加权和。