大语言模型 08 - 从0开始训练GPT 0.25B参数量 - MiniMind 单机多卡 torchrun deepspeed
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。

训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)
数据收集与预处理
- 数据来源:收集海量文本(书籍、网页、新闻、百科、代码等),例如GPT-3使用了近45TB的原始文本。
- 数据清洗:去除噪声(HTML标签、重复文本、低质量内容)。过滤敏感或有害信息。
- 分词(Tokenization):使用子词分词方法(如Byte Pair Encoding, BPE)将文本切分为Token(例如GPT-3的词表大小约5万)。将文本分割为固定长度的序列(如512个Token的段落)。
无监督学习:无需人工标注,直接从原始文本学习。
- 规模化(Scaling Law):模型性能随数据量、参数规模、计算资源的增加而显著提升。
- 通用性:捕捉语法、语义、常识等广泛知识。
单机多卡
torchrun
项目官方备注:所有训练脚本均为Pytorch原生框架,均支持多卡加速。单机N卡启动训练方式 (DDP, 支持多机多卡集群)
torchrun 是 PyTorch 自带的分布式训练启动工具,用于在多 GPU 或多节点上并行运行你的训练脚本。
torchrun --nproc_per_node N train_xxx.py
比如你在当前机器上有两张 GPU,那么可以这么执行:
torchrun --nproc_per_node=2 train_pretrain.py
deepspeed
DeepSpeed 则是一个专注于大规模深度学习训练优化的库,提供了额外的功能和优化技术。
- torchrun:主要用于启动分布式训练进程,并依托 PyTorch 自身的分布式通信框架。它适用于普通的多 GPU 分布式训练任务。
- DeepSpeed:除了支持分布式训练外,还集成了许多高级优化特性,比如 ZeRO(Zero Redundancy Optimizer)技术,用于显存优化、梯度累积、模型并行和流水线并行等,可以大幅提升大模型的训练效率和扩展性。
相比较而言:
- torchrun:配置简单,适合直接利用 PyTorch 的分布式能力进行快速部署。
- DeepSpeed:虽然集成了很多强大的功能,但相应的配置和使用上也会更加复杂,需要根据需求调整配置文件和代码实现。
我们可以通过如下的指令来启动 deepspeed:
deepspeed --master_port 29500 --num_gpus=N train_xxx.py
同样的,假设你有两块GPU,那么可以执行如下的代码:
deepspeed --master_port 29500 --num_gpus=2 train_pretrain.py
wandb
wandb 是 “Weights and Biases” 的缩写。
https://wandb.ai/site/
官方的全称, 它是一个流行的机器学习实验管理与可视化平台,主要用于记录、追踪和分析训练过程中的各种指标和超参数。:

wandb的功能:
● 实时监控与可视化:你可以在 web 仪表盘上实时查看训练过程中的各种指标(如 loss、准确率等),更直观地了解模型表现。
● 实验管理:方便对比多个实验的参数和结果,帮助你系统地管理和复现实验过程,追踪模型版本。
● 协作与共享:支持团队协作,可以轻松与团队成员分享实验结果、图表和报告,提升协作效率。
● 自动化记录:通过集成代码,可以自动记录超参数、模型结构、训练指标等,无需手动整理日志。
● 集成框架:支持 PyTorch、TensorFlow 等主流深度学习框架,可以无缝对接现有的训练流程。
安装配置
pip install wandb
对应的结果如下所示:
需要登录:
wandb login
会提示需要一个key,在官方的位置,会提供给你:
这里我们的使用方式就变成了 --use_wandb,通过这种方式来将数据传给 wandb:
torchrun --nproc_per_node N train_xxx.py --use_wandb
或者这样也可以:
python train_xxx.py --use_wandb
项目官方的备注:通过添加–use_wandb参数,可以记录训练过程,训练完成后,可以在wandb网站上查看训练过程。通过修改wandb_project 和wandb_run_name参数,可以指定项目名称和运行名称。
wandb官方也给了一个例子(只参考就行,不需要写):
import wandb
import random# start a new wandb run to track this script
wandb.init(# set the wandb project where this run will be loggedproject="my-awesome-project",# track hyperparameters and run metadataconfig={"learning_rate": 0.02,"architecture": "CNN","dataset": "CIFAR-100","epochs": 10,}
)# simulate training
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):acc = 1 - 2 ** -epoch - random.random() / epoch - offsetloss = 2 ** -epoch + random.random() / epoch + offset# log metrics to wandbwandb.log({"acc": acc, "loss": loss})# [optional] finish the wandb run, necessary in notebooks
wandb.finish()
预训练
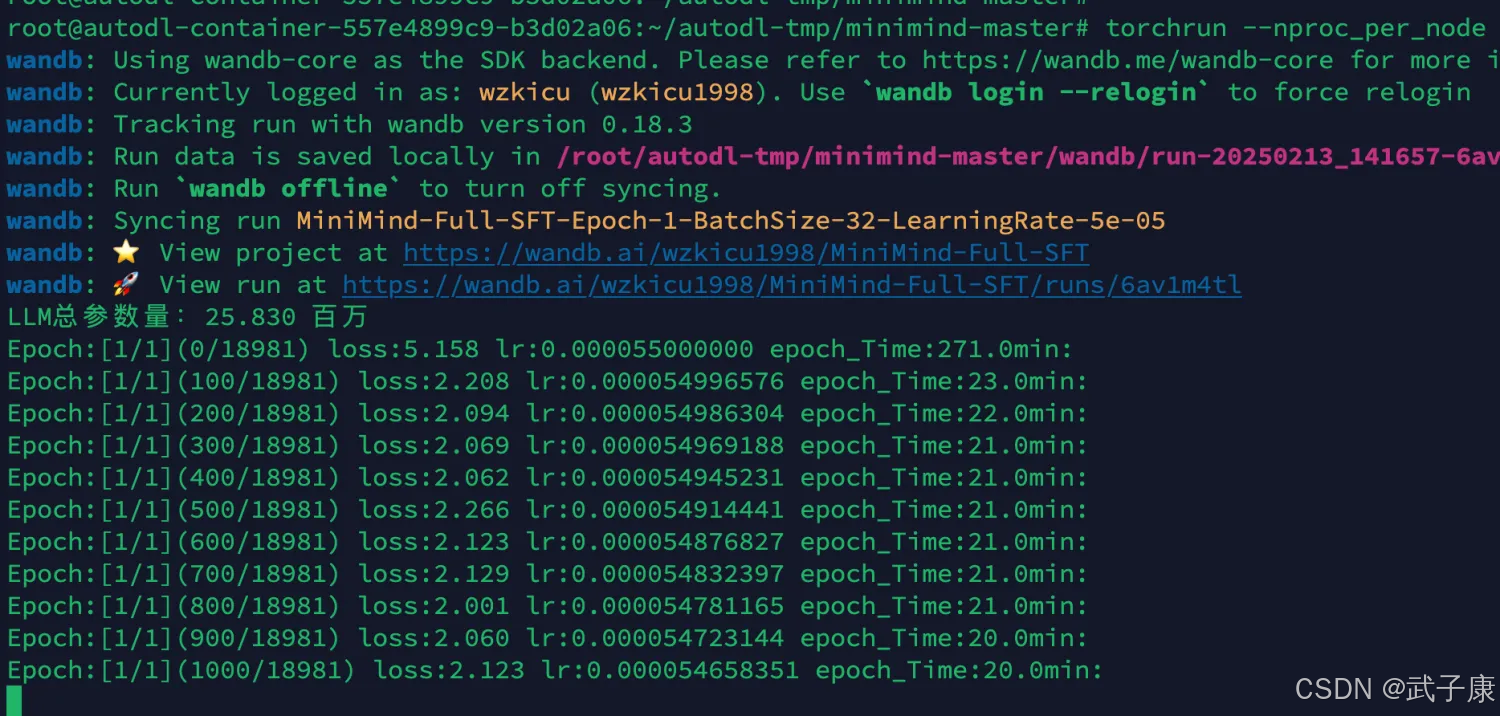
这里将采用 torchrun + wandb 的方式,我这里是 单机 * 2张4090。
使用下面命令进行训练:
torchrun --nproc_per_node 2 train_pretrain.py --use_wandb
可以看到速度大幅度提升,同样是LLM总参数量:25.830 百万,但是速度快了一倍:
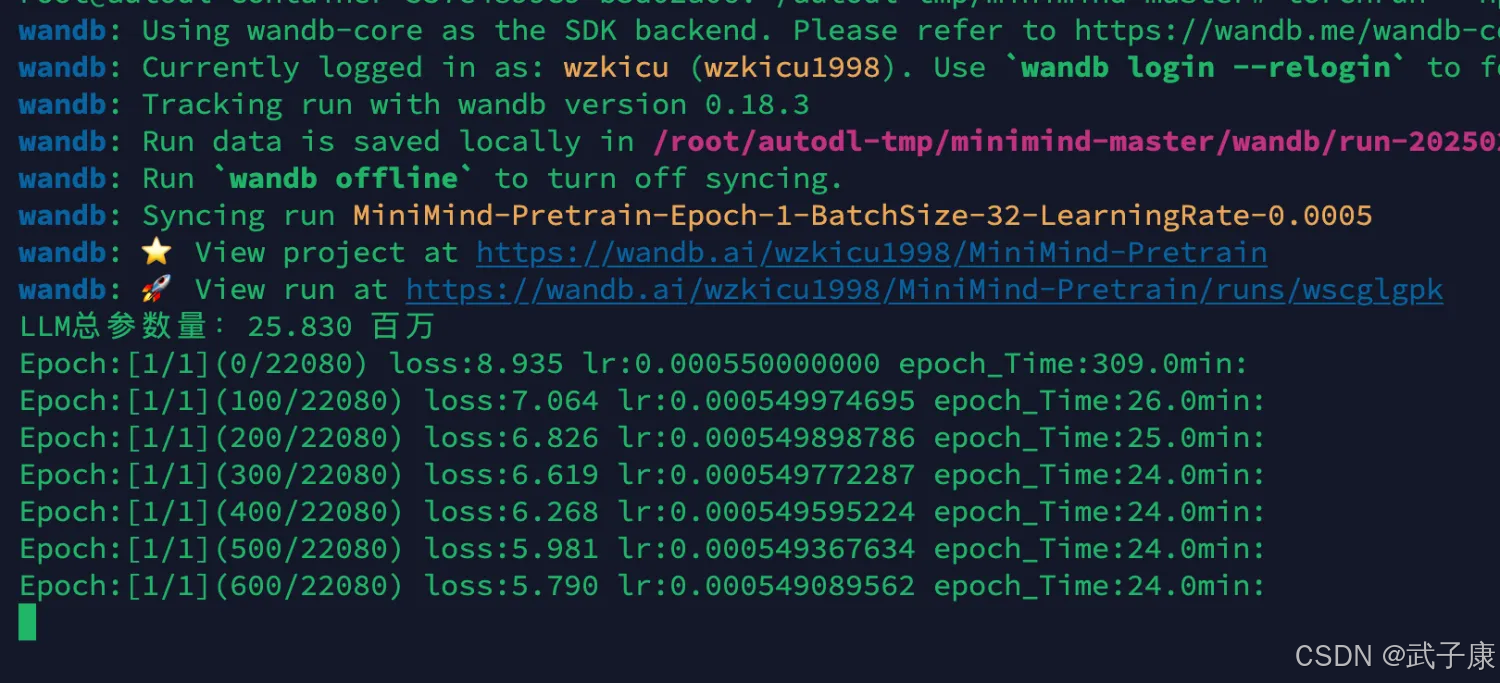
此时跟着提示的URL,我们可以看到项目的训练情况:
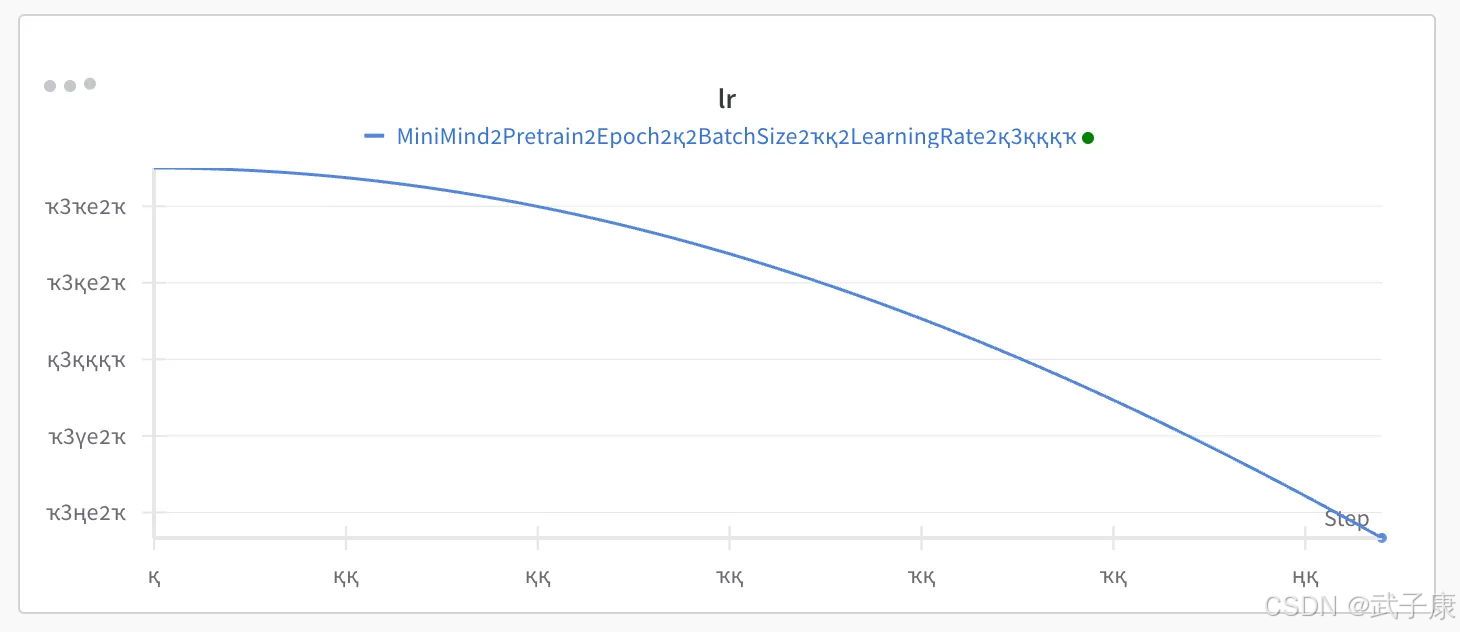
LR:
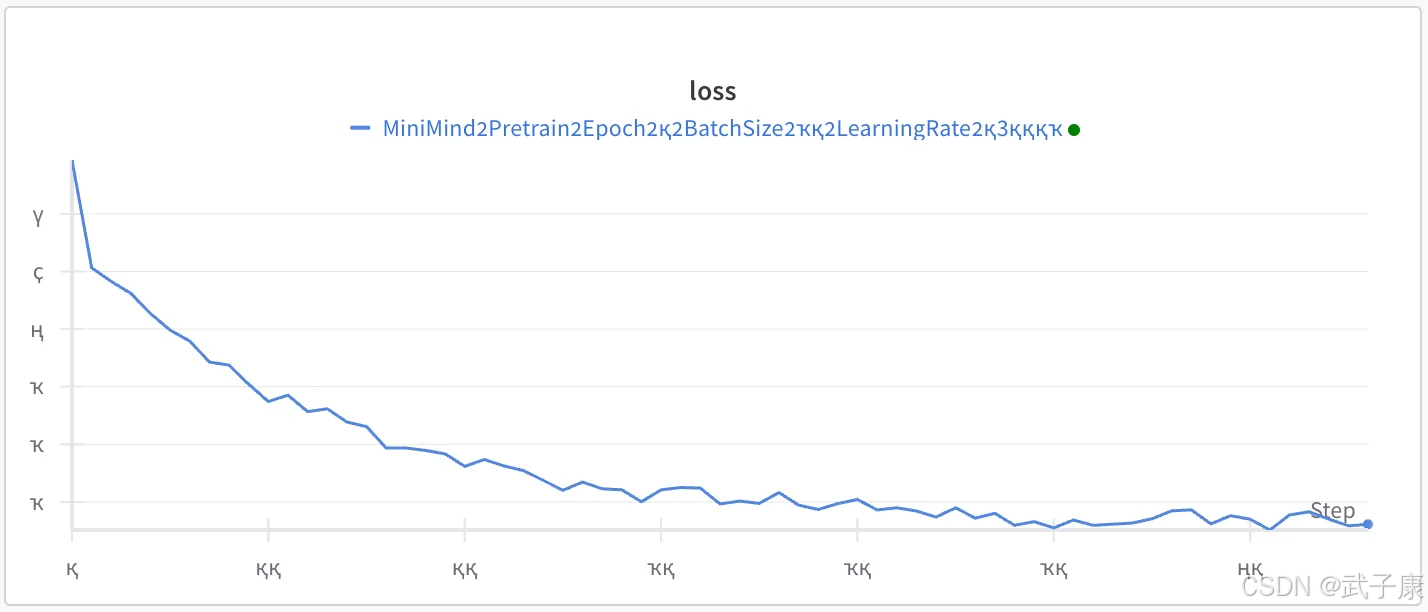
LOSS:
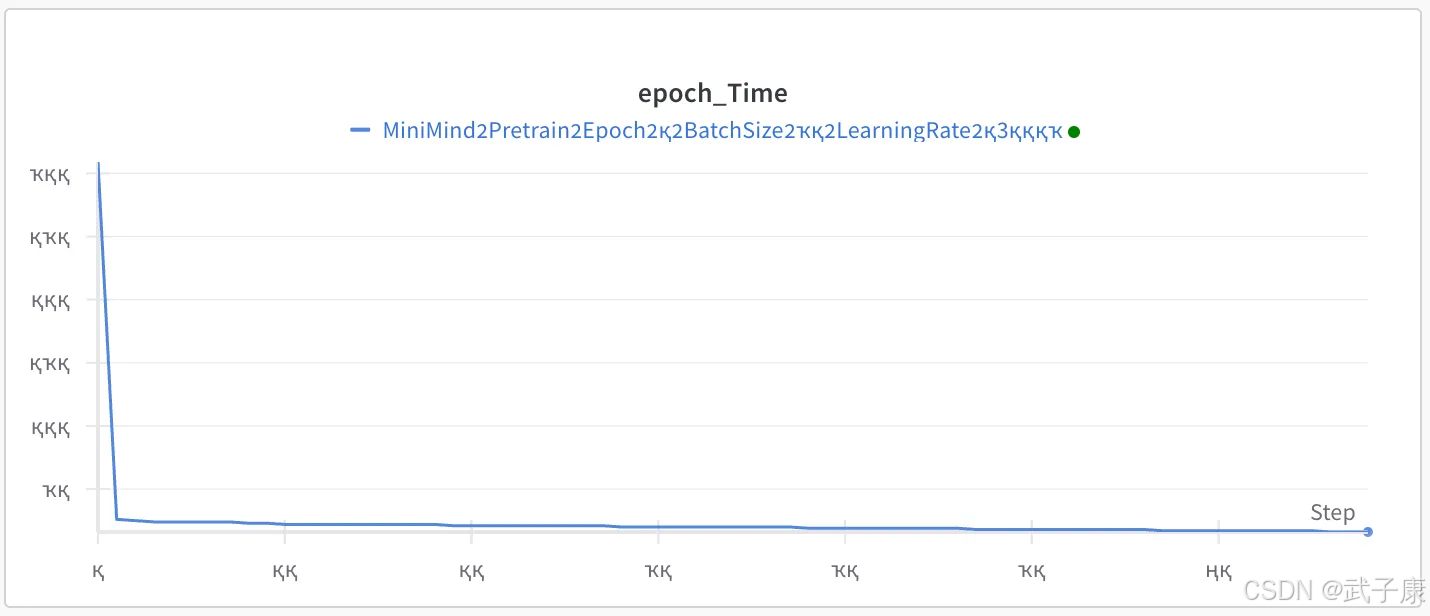
EPOCH_TIME:
训练结束:
监督微调
这里将采用 torchrun + wandb 的方式,我这里是 单机 * 2张4090。
torchrun --nproc_per_node 2 train_full_sft.py --use_wandb
可以看到双卡的情况下,训练的速度大幅度提升: