课程11. 计算机视觉、自编码器和生成对抗网络 (GAN)
计算机视觉、自编码器和生成对抗网络(GAN)
- 自动编码器
- Vanilla自动编码器
- 使用 AE 生成新对象. 变分 AE (VAE)
- AE 条件
- GAN
- 理论
- 示例
- 下载并准备数据
- GAN模型
- 额外知识
课程计划:
- 自动编码器:
- 自动编码器结构;
- 使用自动编码器生成图像;
- 条件自动编码器;
- 生成对抗网络:
- 生成对抗网络结构;
- 练习:构建和训练生成对抗网络;
自动编码器
Autoencoders
Vanilla自动编码器
自动编码器是一种神经网络,它学习重建输入信息。换句话说,它试图产生与输入完全相同的输出:
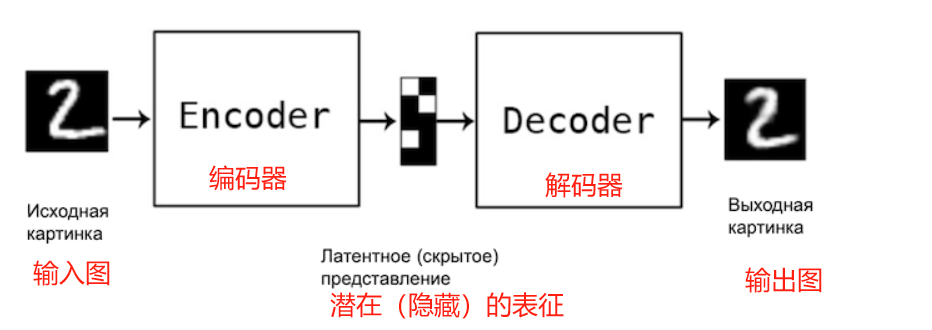
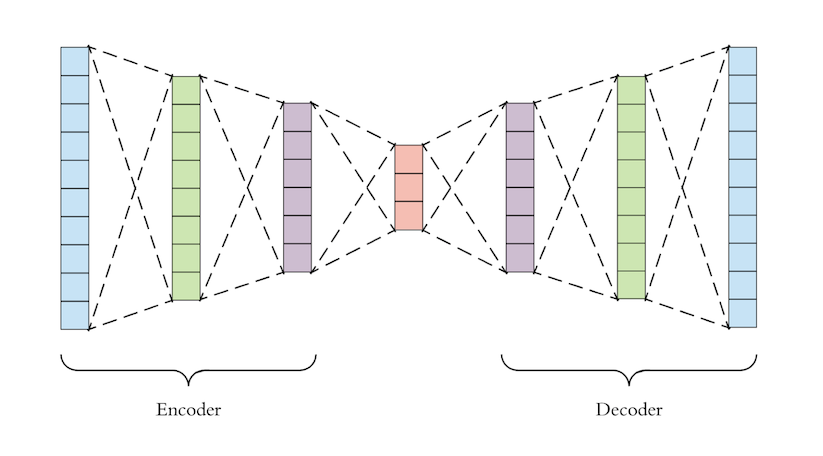
自动编码器通常设计为向中间逐渐变细,即中间层的神经元数量远小于网络前层的神经元数量。这样我们就得到了我们熟悉的编码器-解码器结构。
如果自动编码器中间层的神经元数量与输入层相同,那么在没有额外限制的情况下,自动编码器就毫无意义。它会学习id(身份)函数。
自动编码器的用途:
- 数据压缩和存储,特别是图像/视频压缩;
- 根据潜在表征对对象进行聚类;
- 查找相似对象(例如图像);
- 生成新对象(例如图像)。
- 查找数据中的异常;
- ……(可能还有更多 😃)。
自动编码器 (AE) 采用自监督学习模式进行训练。这意味着它无需数据标记即可进行训练。
例如,如果我们想在人脸图像数据集上训练 AE,那么在每次训练迭代中,我们会执行以下操作:
- 为 AE 输入一张图片;
- 将重建图像作为 AE 的输出;
- 计算重建图像与输入图像之间的 MSE/BCE 质量指标;
- 使用反向传播算法训练 AE。
与分类/检测/分割任务不同,AE 无需数据标记。
使用 AE 生成新对象. 变分 AE (VAE)
让我们更详细地讨论如何使用自编码器生成新物体。为了简单起见,我们假设处理的是人脸图像(其他类型的物体也一样)。
使用 AE 生成新图像:
- 在我们的人脸数据集上训练 AE;
- 去掉编码器部分,只留下解码器部分;
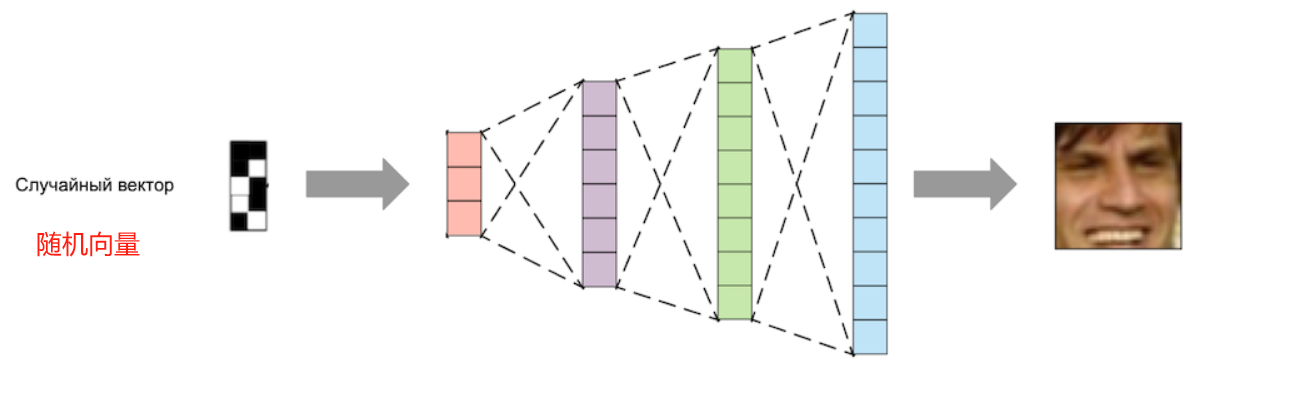
- 将所需大小的随机数字向量输入到解码器部分的输入中,在输出端,我们将得到一张从未见过的人脸新图像。
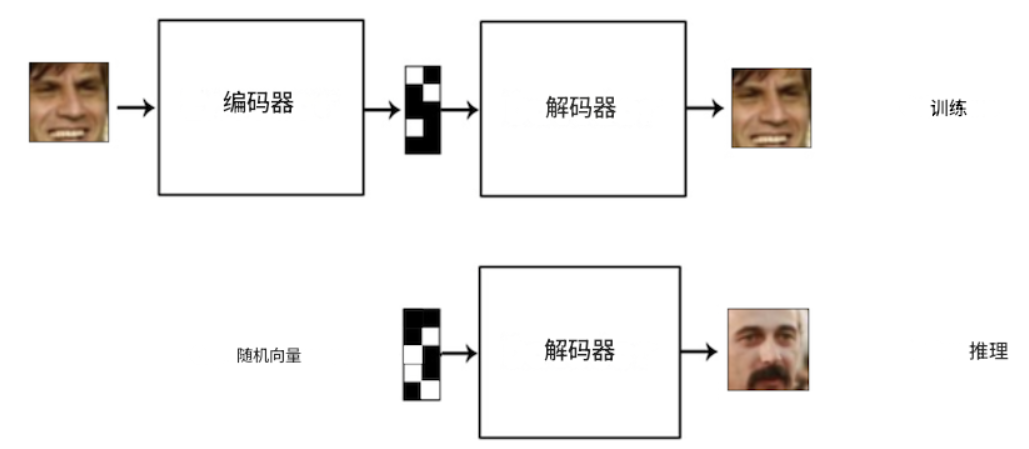
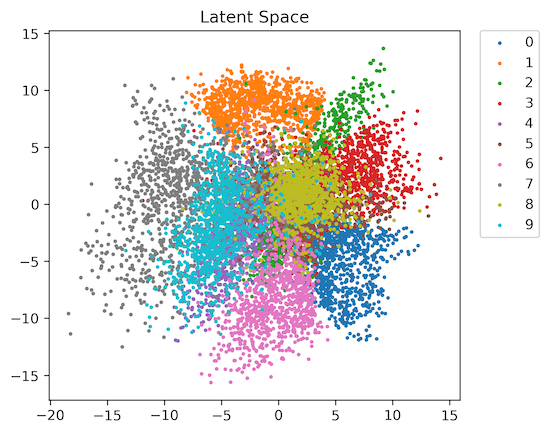
然而,常规(“原始”)AE 无法实现这样的效果。问题在于,它的潜在空间非常稀疏:并非空间中的每个点都对应一张真实的图片。
潜在空间看起来大致如下:

为了使自动编码器(AE)的潜在空间向量能够真正生成新的对象,我们需要强制自动编码器学习一个更连贯、更紧凑的潜在空间。
一种方法是指定潜在空间向量应该对应的分布。也就是说,对向量在潜在空间中的间距添加一个约束。
这种自动编码器被称为变分自动编码器(VAE)。它的潜在空间大致如下:
AE 条件
我们已经意识到 VAE 可以用来生成新对象。让我们来讨论一下如何生成不仅仅是任何新对象,而是具有给定属性的对象。
其思路是这样的:在训练过程中,解码器输入会输入一个编码属性以及潜在向量。例如,假设我们想要学习如何生成特定种族的人脸。假设我们只有 4 种种族类型。我们使用独热编码对它们进行编码:每种种族类型对应一个长度为 4 的向量,由 0 和 1 组成。解码器输入会输入一个潜在向量,该向量与该种族的独热向量连接在一起。
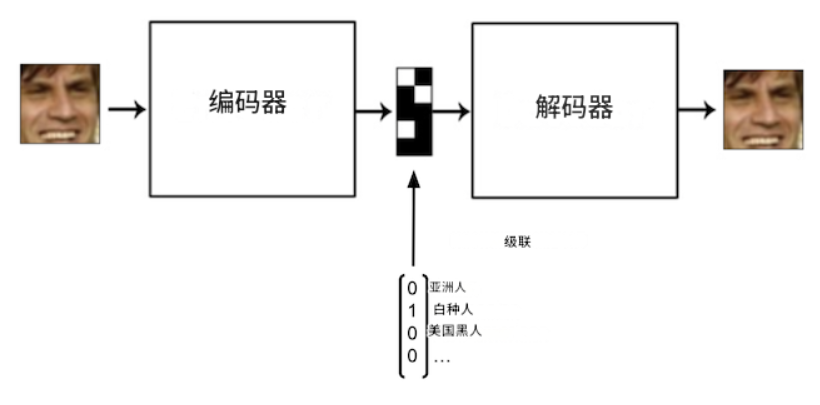
不仅可以将条件向量馈送到第一个解码器层的输入,还可以将其馈送到其所有层的输入。还可以将条件向量馈送到编码器层的输入。
问题:原始自动编码器用于什么任务的训练?
GAN
理论
GAN —— Generative adversarial Network —— 生成对抗网络。该架构于 2014 年发明,专门用于生成新图像(当然,GAN 不仅可以用来生成图像,还可以生成其他对象)。
让我们思考一下:如何训练神经网络生成新物体?
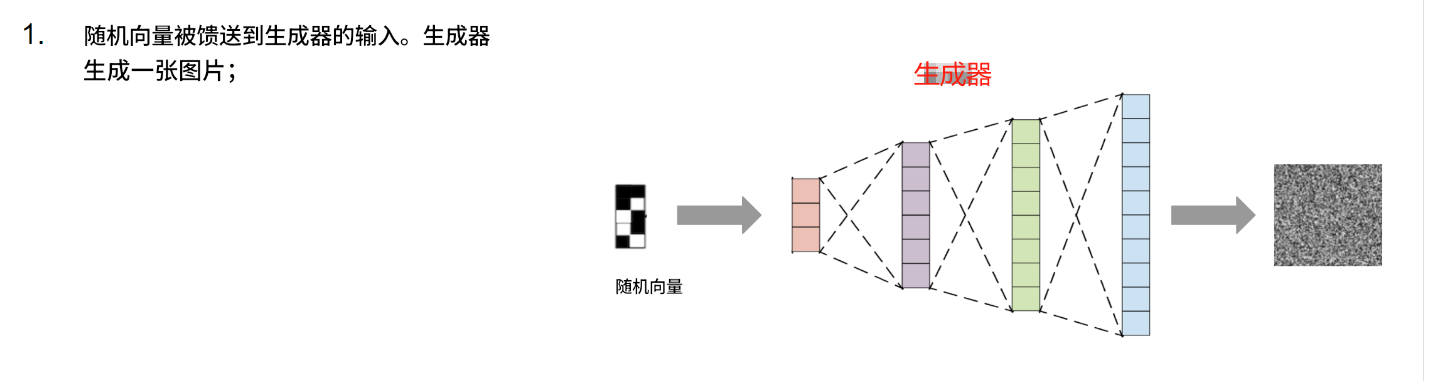
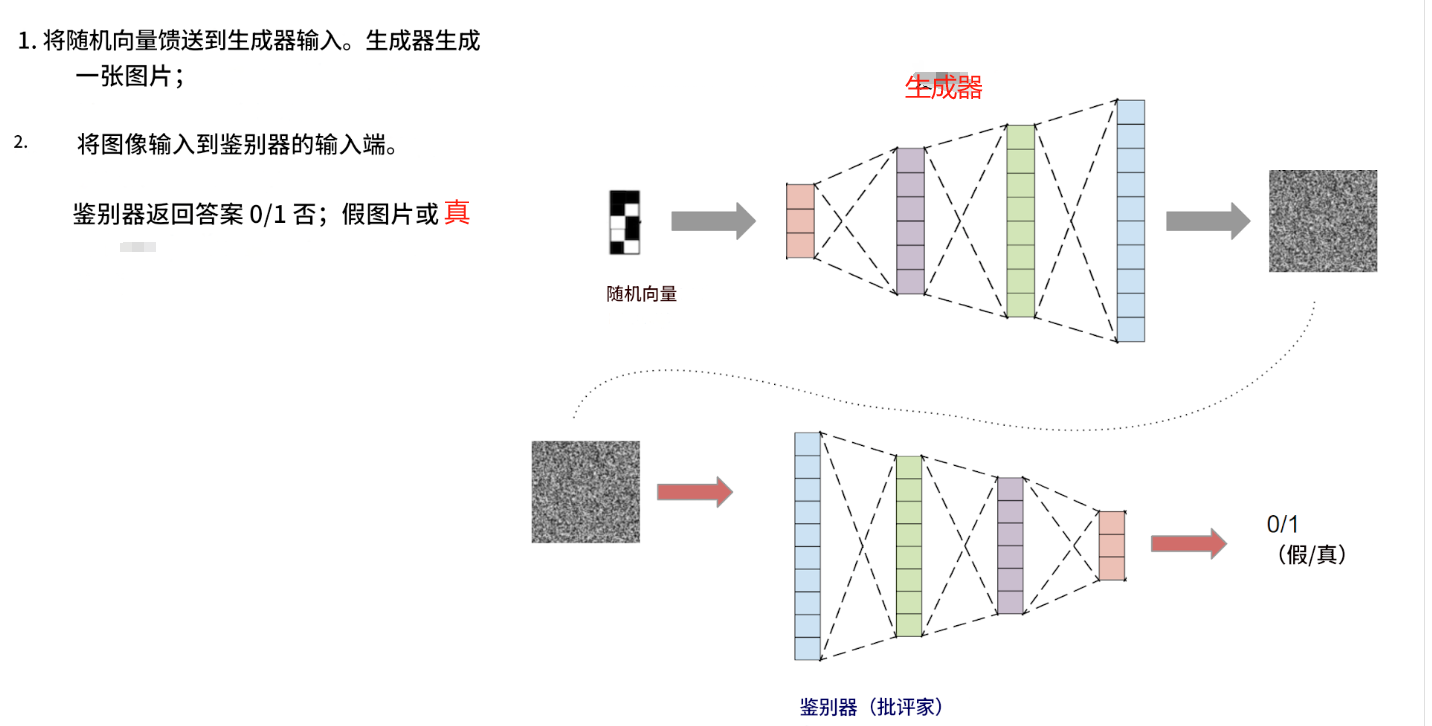
最简单的想法:创建一个神经网络,输入一个特定大小的随机向量,并输出一张生成的图像:
这个想法的问题在于如何训练这样的网络。如果你在训练过程中将随机向量输入到输入中,并将网络输出与训练数据集中的图片进行比较,这样的网络将学会只生成训练数据集中的图片。这几乎没什么用 =)
我希望在训练数据集有限的情况下,教会神经网络生成不同的人脸,即使是神经网络在训练过程中没有识别的人脸(即不在训练数据中的人脸)。
如何做到这一点?其中一个想法是 GAN——生成对抗网络。
它的工作原理如下:
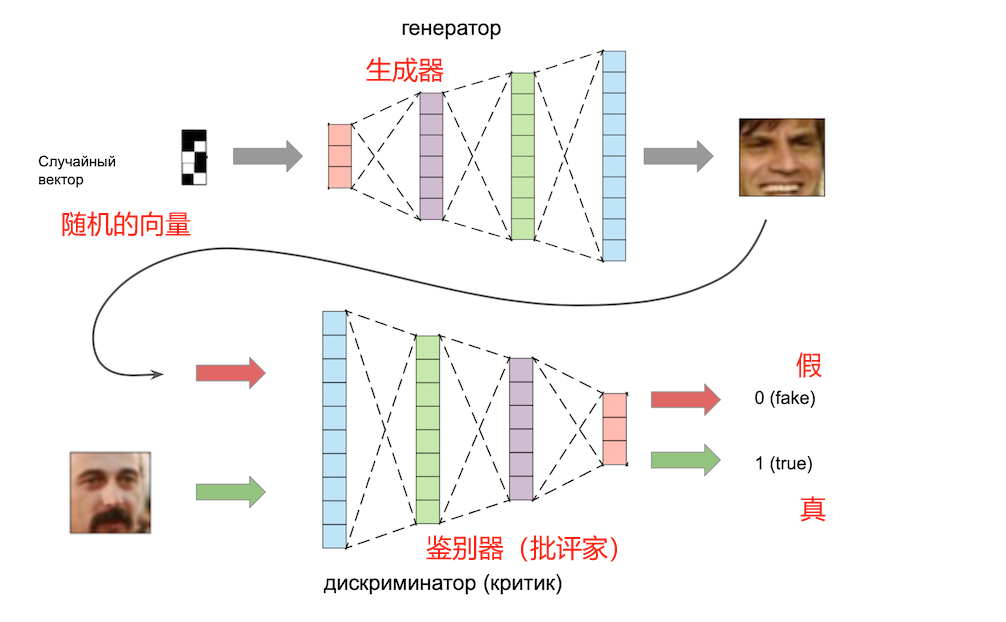
该模型由两个独立的神经网络组成:一个生成器和一个鉴别器。生成器以随机向量作为输入,输出一张图像。鉴别器以图像作为输入,输出一个答案:这张图片是真的还是假的(由生成器生成)。
生成器和鉴别器一起训练。鉴别器帮助生成器学习生成各种图像,而不仅仅是训练数据集中的图像。
 .
.
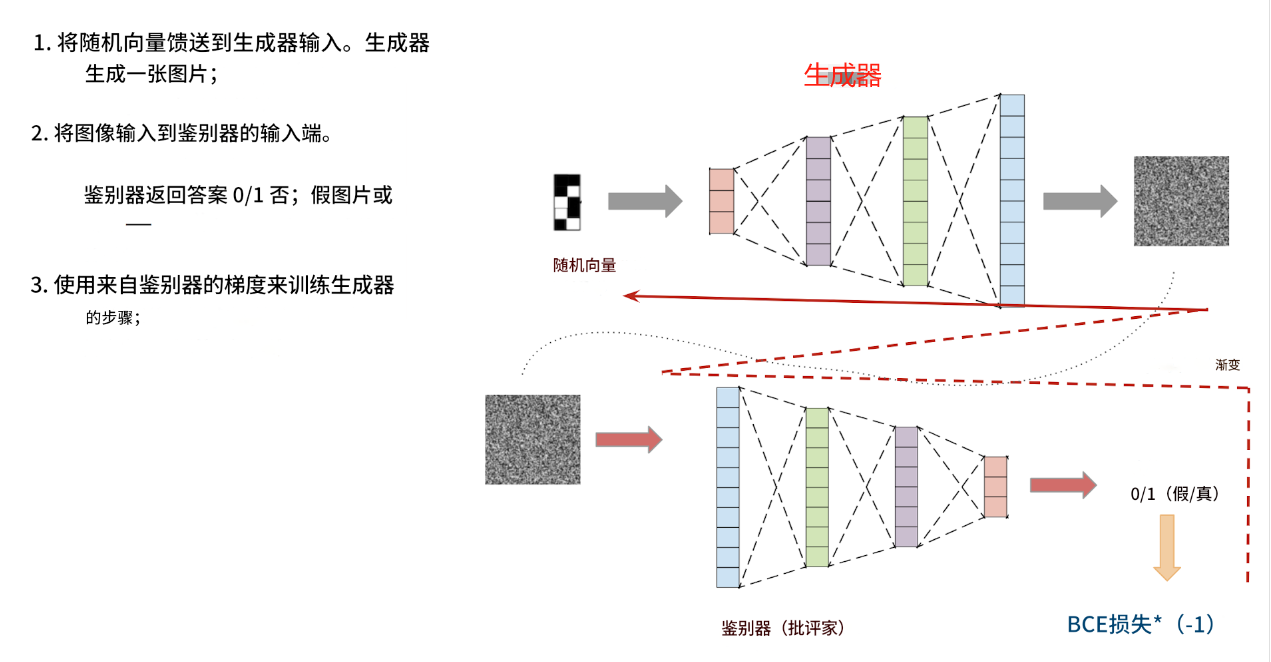
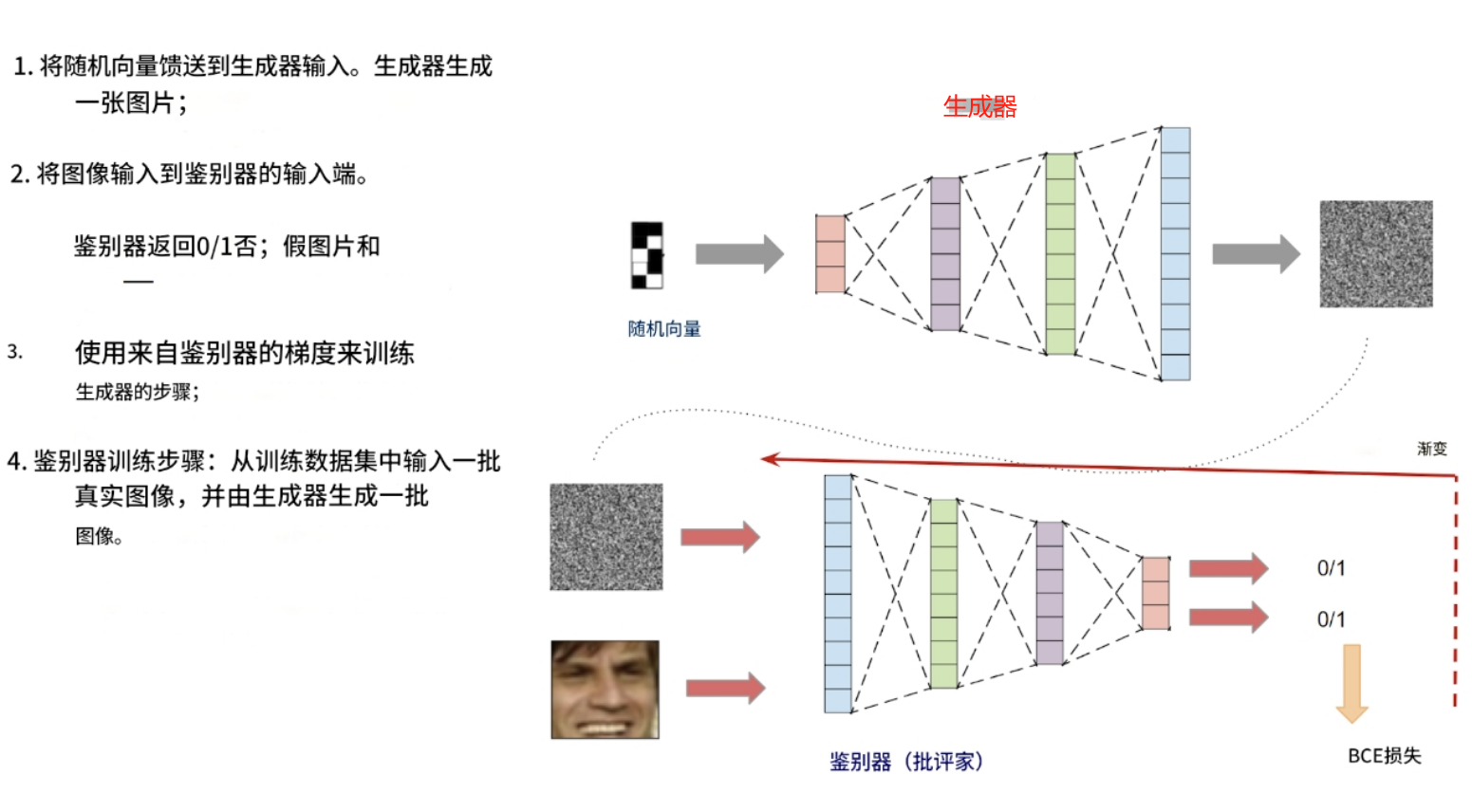
这一切的关键在于:鉴别器能够快速学会区分生成器生成的图片和真实图片(来自训练数据集)。之后,在生成器训练阶段,生成器会学习自适应,生成鉴别器无法再区分的图片。之后,鉴别器会学习区分生成器生成的新图片和真实图片。之后,生成器会再次学习生成更好的图片。如此反复。
这是生成器和鉴别器之间的对抗。
GAN 有一些缺点:
- GAN 训练起来相当困难。你需要选择合适的生成器和鉴别器架构:这样鉴别器就不会比生成器“聪明”太多(学会对图片进行分类的速度不会比生成器学会生成图片的速度快太多)。反之亦然:鉴别器也不应该比生成器“笨”太多,否则生成器将无法接收到良好的训练信号。
- 在 GAN 生成器中使用 BatchNorm 时应格外谨慎。BatchNorm 会均衡批次中所有元素的分布,因此同一批次中生成的所有图像可以具有相似的特征。
使用 BatchNorm 生成示例:

- GAN 通常存在一种崩溃模式:生成器开始针对任何随机输入向量生成大致相同的图像。有许多技术可以减少这种影响,并使生成器的生成更加多样化。崩溃模式的示例如下:

示例
让我们教 GAN 生成人脸。我们将使用 LFW 数据集
我们导入必要的库:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
from IPython.display import clear_outputimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
输出:
device(type=‘cuda’)
下文将介绍如何下载和准备数据。所有代码与上面 AE 练习中的代码类似。如果您之前未下载过此笔记本中的数据,则需要取消注释并运行本节中的单元格。
下载并准备数据
!pip install deeplake==3.0
import deeplake
ds = deeplake.load('hub://activeloop/lfw')
dataloader = ds.pytorch(num_workers = 1, batch_size=1, shuffle = False)
import tqdm
from tqdm.auto import tqdm as tqdm
import PIL
faces = []
for b in tqdm(dataloader):faces.append(PIL.Image.fromarray(b['images'][0].detach().numpy()))
输出:

class Faces(Dataset):def __init__(self, faces):self.data = facesself.transform = transforms.Compose([transforms.CenterCrop((90, 90)),transforms.Resize((64, 64)),transforms.ToTensor(),# transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])def __getitem__(self, index):x = self.data[index]return self.transform(x).float()def __len__(self):return len(self.data)
def plot_gallery(images, n_row=3, n_col=6, from_torch=False):"""Helper function to plot a gallery of portraits"""if from_torch:images = [x.data.numpy().transpose(1, 2, 0) for x in images]plt.figure(figsize=(1.5 * n_col, 1.7 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i])plt.xticks(())plt.yticks(())plt.show()
dataset = Faces(faces)# dataset[0] 是对 __getitem__(0) 方法的调用
img = dataset[0]print(img.shape)# 绘制图像及其分割蒙版
plot_gallery(dataset, from_torch=True)
输出:

train_size = int(len(dataset) * 0.8)
val_size = len(dataset) - train_sizeg_cpu = torch.Generator().manual_seed(8888)
train_data, val_data = torch.utils.data.random_split(dataset, [train_size, val_size], generator=g_cpu)train_loader = torch.utils.data.DataLoader(train_data, batch_size=16, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=16, shuffle=False)
GAN模型
让我们分别声明鉴别器和生成器模型。
鉴别器模型是一个用于图像二分类的常规卷积网络:
class Discriminator(nn.Module):def __init__(self):super().__init__()# in: 3 x 64 x 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.conv2 = nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.conv3 = nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.conv4 = nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.conv5 = nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=0, bias=False)# out: 1 x 1 x 1self.flatten = nn.Flatten()self.sigmoid = nn.Sigmoid()def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))x = F.relu(self.bn4(self.conv4(x)))x = self.conv5(x)x = self.flatten(x)x = self.sigmoid(x)return x
生成器模型也是一个卷积神经网络,其输出必须与数据集中的图像具有相同的维度:
class Generator(nn.Module):def __init__(self, latent_size):super().__init__()# in: latent_size x 1 x 1self.convT1 = nn.ConvTranspose2d(latent_size, 512, kernel_size=4, stride=1, padding=0, bias=False)self.bn1 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.convT2 = nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.convT3 = nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.convT4 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.convT5 = nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1, bias=False)self.tanh = nn.Tanh()# out: 3 x 64 x 64def forward(self, x):x = F.relu(self.bn1(self.convT1(x)))x = F.relu(self.bn2(self.convT2(x)))x = F.relu(self.bn3(self.convT3(x)))x = F.relu(self.bn4(self.convT4(x)))x = self.convT5(x)x = self.tanh(x)return x
我们将输入生成器以生成图像的随机向量的大小设置为 128:
latent_size = 128
让我们引入一个固定的噪声向量,以便在网络训练过程中我们可以跟踪生成器输出在这个固定向量上的变化:
fixed_latent = torch.randn(64, latent_size, 1, 1, device=device)
现在让我们开始训练 GAN. 训练算法如下:
-
训练鉴别器:
- 拍摄真实图像并赋予其标签 1
- 使用生成器生成图像并赋予其标签 0
- 将分类器训练成两类
-
训练生成器:
- 使用生成器生成图像并赋予其标签 0
- 使用鉴别器预测图像是否真实
from IPython.display import clear_output
from torchvision.utils import make_grid# 用于对图像进行反规范化的函数
stats = (0.5, 0.5, 0.5), (0.5, 0.5, 0.5)
def denorm(img_tensors):return img_tensors * stats[1][0] + stats[0][0]# 用于绘制图像生成器生成结果的函数
# 在我们的固定噪声向量上
def show_samples(latent_tensors):fake_images = generator(latent_tensors)fig, ax = plt.subplots(figsize=(8, 8))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(denorm(fake_images[:64].cpu().detach()), nrow=8).permute(1, 2, 0))plt.show()# GAN的直接学习函数
def train(models, opts, loss_fns, epochs, train_loader, val_loader, batch_size=64):# Losses & scoreslosses_g = []losses_d = []real_scores = []fake_scores = []for epoch in range(epochs):# 打印当前epochprint('* Epoch %d/%d' % (epoch+1, epochs))# 使用来自 train_loader 的图像来训练网络models["discriminator"].train()models["generator"].train()# 用于存储损失值和准确率指标的数组# 网络训练期间的鉴别器loss_d_per_epoch = []loss_g_per_epoch = []real_score_per_epoch = []fake_score_per_epoch = []for i, X_batch in enumerate(train_loader):X_batch = X_batch.to(device)# 1. 鉴别器训练步骤。# 清除鉴别器梯度opts["discriminator"].zero_grad()# 1.1 真实图片出现亏损# 我们将批次 X_batch 中的真实图像输入到鉴别器的输入中real_preds = models["discriminator"](X_batch)# 鉴别器对这些图像的正确响应应该是一个由 1 组成的向量real_targets = torch.ones(X_batch.size(0), 1, device=device)# 我们在一批真实图像上计算鉴别器损失值real_loss = loss_fns["discriminator"](real_preds, real_targets)cur_real_score = torch.mean(real_preds).item()# 1.2 因假图片而蒙受损失# 让我们生成虚假图像。为此,我们生成一个大小为 (batch_size, latent_size, 1, 1) 的随机噪声向量,并将其输入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我们得到一批随机向量的生成器输出fake_images = models["generator"](latent)# 我们将来自批次 X_batch 的假图像输入到鉴别器的输入中fake_preds = models["discriminator"](fake_images)# 鉴别器对这些图像的正确响应应该是一个零向量fake_targets = torch.zeros(fake_images.size(0), 1, device=device)# 计算一批假图像上的鉴别器损失值fake_loss = loss_fns["discriminator"](fake_preds, fake_targets)cur_fake_score = torch.mean(fake_preds).item()real_score_per_epoch.append(cur_real_score)fake_score_per_epoch.append(cur_fake_score)# 1.3 更新鉴别器权重:执行梯度下降步骤loss_d = real_loss + fake_lossloss_d.backward()opts["discriminator"].step()loss_d_per_epoch.append(loss_d.item())# 2. 生成器训练步骤# 清理生成器梯度opts["generator"].zero_grad()# 让我们生成虚假图像。为此,我们生成一个大小为 (batch_size, latent_size, 1, 1) 的随机噪声向量,并将其输入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我们得到一批随机向量的生成器输出fake_images = models["generator"](latent)# 我们将来自批次 X_batch 的假图像输入到鉴别器的输入中preds = models["discriminator"](fake_images)# 我们将这些图片的“正确”答案向量设置为 1 的向量targets = torch.ones(batch_size, 1, device=device)# 计算预测和目标之间的损失loss_g = loss_fns["generator"](preds, targets)# 更新生成器权重loss_g.backward()opts["generator"].step()loss_g_per_epoch.append(loss_g.item())# 每 100 次训练迭代,我们将输出指标的当前值# 并绘制图像生成器生成的结果# 来自固定的随机向量if i%100 == 0:# Record losses & scoreslosses_g.append(np.mean(loss_g_per_epoch))losses_d.append(np.mean(loss_d_per_epoch))real_scores.append(np.mean(real_score_per_epoch))fake_scores.append(np.mean(fake_score_per_epoch))# Log losses & scores (last batch)print("Epoch [{}/{}], loss_g: {:.4f}, loss_d: {:.4f}, real_score: {:.4f}, fake_score: {:.4f}".format(epoch+1, epochs,losses_g[-1], losses_d[-1], real_scores[-1], fake_scores[-1]))# Show generated imagesclear_output(wait=True)show_samples(fixed_latent)return losses_g, losses_d, real_scores, fake_scores
最后,我们将声明模型、优化器、损失并训练模型:
generator = Generator(latent_size).to(device)
discriminator = Discriminator().to(device)models = {'generator': generator,'discriminator': discriminator
}criterions = {"discriminator": nn.BCELoss(),"generator": nn.BCELoss()
}lr = 0.0002
optimizers = {"discriminator": torch.optim.Adam(models["discriminator"].parameters(),lr=lr, betas=(0.5, 0.999)),"generator": torch.optim.Adam(models["generator"].parameters(),lr=lr, betas=(0.5, 0.999))}losses_g, losses_d, real_scores, fake_scores = train(models, optimizers, criterions, 10, train_loader, val_loader)
输出:

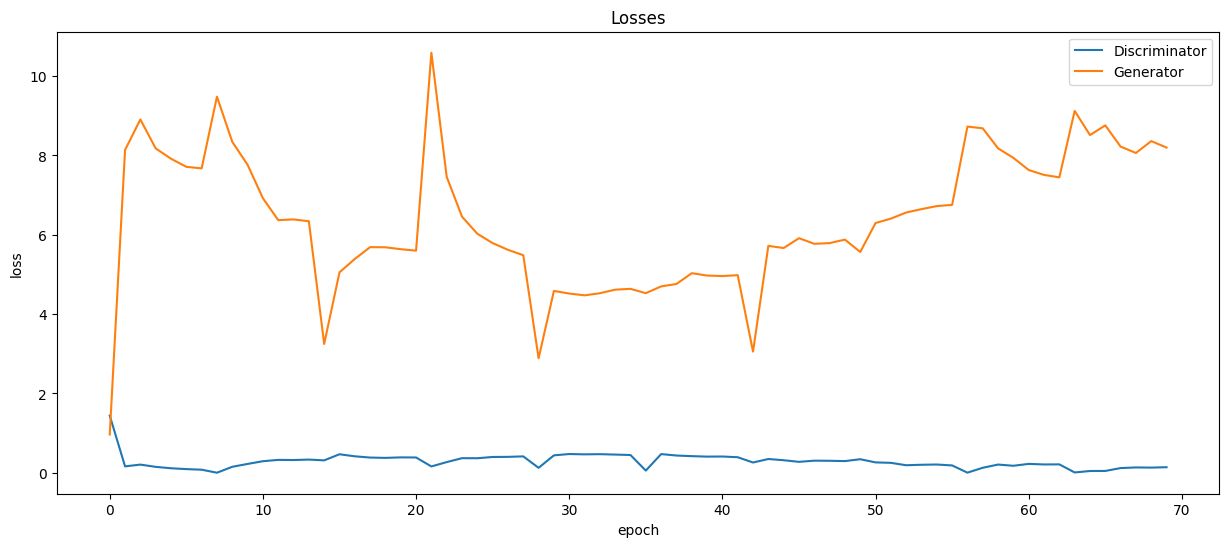
让我们直观地看到网络训练期间生成器的损失和准确度指标的变化图:
plt.figure(figsize=(15, 6))
plt.plot(losses_d, '-')
plt.plot(losses_g, '-')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Discriminator', 'Generator'])
plt.title('Losses');
输出:
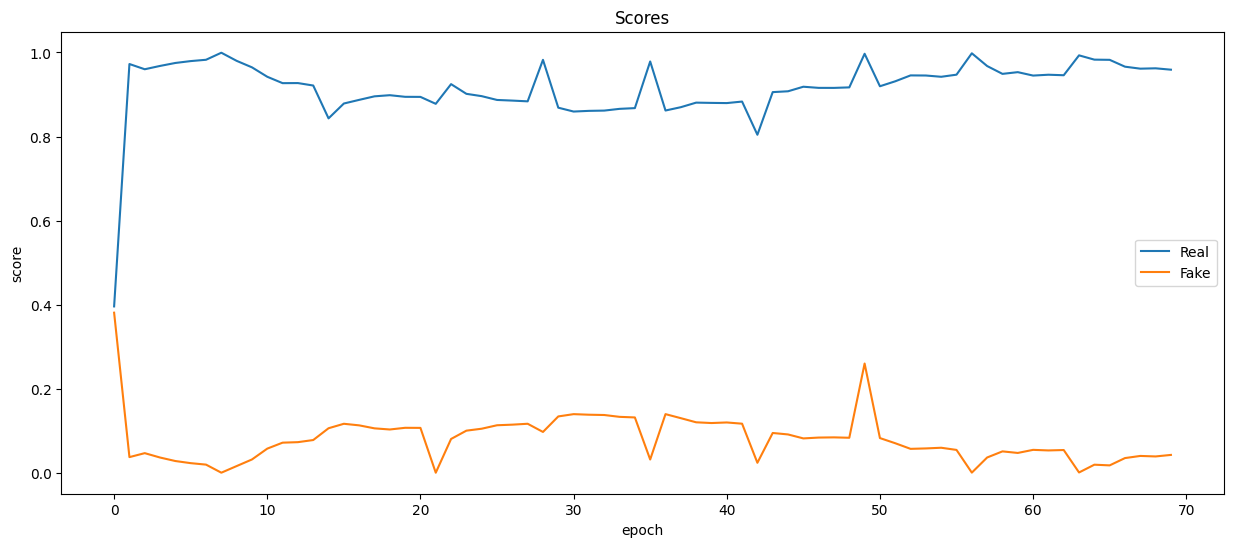
plt.figure(figsize=(15, 6))plt.plot(real_scores, '-')
plt.plot(fake_scores, '-')
plt.xlabel('epoch')
plt.ylabel('score')
plt.legend(['Real', 'Fake'])
plt.title('Scores');
输出:
额外知识
-
深度学习学校的一系列关于自动编码器的课程:
-
讲座:生成模型和自动编码器;
-
研讨会:自动编码器;
-
研讨会:VAE;
-
深度学习学校的一系列关于生成对抗网络的课程:
-
讲座:生成模型。生成对抗网络;
-
研讨会:GAN
-
已完成关于不同类型自编码器(Vanilla AE、VAE、条件 VAE)的笔记 及相关解释
-
关于 VAE 的英文文章,其中包含对相关工作思路和数学公式的详细解释