自注意力机制(Self-Attention)前向传播手撕
题目
实现Transformer中自注意力机制的前向传播代码
思路与代码
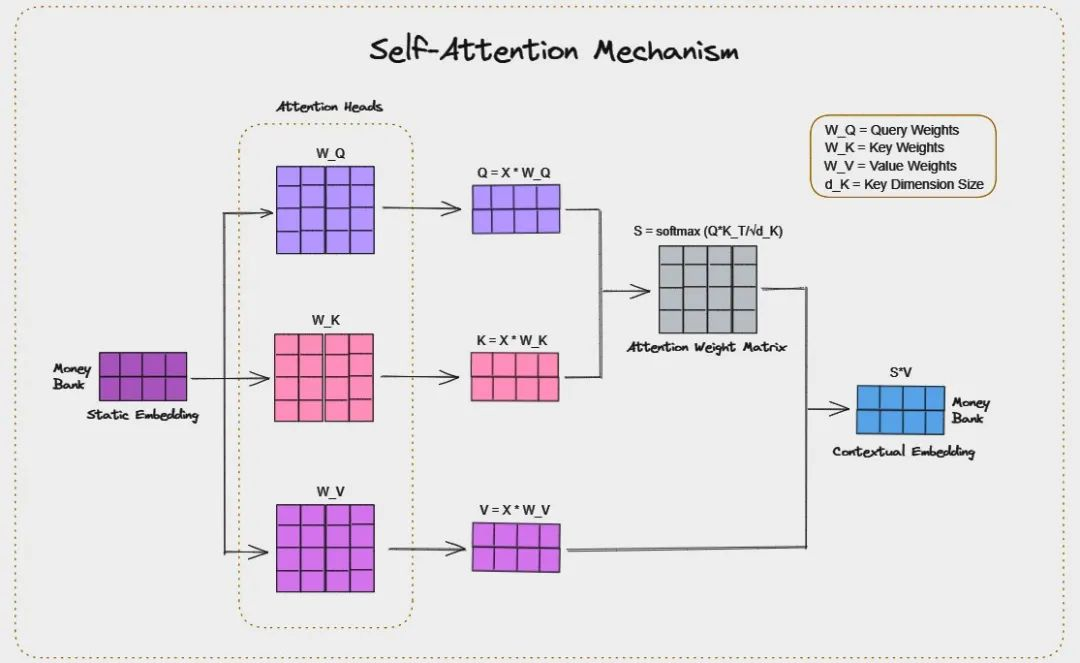
自注意力机制(Self-Attention)是自然语言处理和深度学习中的一种核心机制,最早在 Transformer 模型中被提出。它的核心思想是:让序列中的每个元素都能动态关注整个序列的信息,从而捕捉元素之间的长距离依赖关系。
自注意力机制的核心思想
-
动态权重分配
不同于传统RNN/CNN的固定模式,自注意力通过计算元素间的相关性权重,动态决定每个元素需要关注哪些其他元素。 -
全局视野
单次计算即可捕捉整个序列的依赖关系,彻底解决了RNN的长距离依赖问题。 -
并行计算友好
所有位置的注意力计算可同步完成,极大提升了计算效率。
自注意力机制的工作原理
输入与输出
-
输入:一个序列(如句子中的词向量),形状为
(batch_size, seq_len, embed_size) -
输出:新的序列表示(每个位置融合了全局信息),形状与输入相同
核心三步计算(以单个头为例)
-
生成Query/Key/Value
-
通过线性变换为每个元素生成三组向量:
-
Query(查询向量):表示“我要找什么”
-
Key(键向量):表示“我有什么特征”
-
Value(值向量):实际携带的信息内容
-
-
-
计算注意力分数
-
通过点积计算元素间的相关性:
分数 = (Q · K^T) / sqrt(d_k)
(d_k为向量维度,缩放防止梯度爆炸)
-
-
加权聚合Value
-
用Softmax归一化分数得到注意力权重
-
用权重对Value加权求和:
Output = Softmax(分数) · V
-
自注意力与传统注意力的比较
| 传统注意力 | 自注意力 | |
| 关注对象 | 关注外部序列(如编码器) | 关注输入序列自身 |
| 计算方式 | 单向(如编码器-解码器) | 双向(全序列互相关) |
| 主要用途 | 解决序列对齐问题 | 捕捉序列内部依赖关系 |
自注意力的优点
-
完美解决长距离依赖问题(无论距离多远,一步计算可达)
-
高度并行化计算(时间复杂度O(n²)但GPU加速效果极佳)
-
可解释性强(通过注意力权重观察模型关注点)
参考代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size):super(SelfAttention, self).__init__()self.embed_size = embed_size# 定义查询、键、值的线性变换层self.query = nn.Linear(embed_size, embed_size)self.key = nn.Linear(embed_size, embed_size)self.value = nn.Linear(embed_size, embed_size)def forward(self, x, mask=None):"""参数:x: 输入张量,形状为 (batch_size, seq_len, embed_size)mask: 可选的掩码张量,形状为 (batch_size, seq_len, seq_len)返回:output: 自注意力输出,形状同输入attention: 注意力权重"""batch_size, seq_len, _ = x.size()# 计算查询、键、值Q = self.query(x) # (batch_size, seq_len, embed_size)K = self.key(x) # (batch_size, seq_len, embed_size)V = self.value(x) # (batch_size, seq_len, embed_size)# 计算注意力分数 (缩放点积)scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.embed_size, dtype=torch.float32))# scores形状: (batch_size, seq_len, seq_len)# 应用掩码(如需要)if mask is not None:scores = scores.masked_fill(mask == 0, float("-1e20"))# 计算注意力权重attention = F.softmax(scores, dim=-1)# 加权求和output = torch.matmul(attention, V) # (batch_size, seq_len, embed_size)return output, attention# 示例用法
if __name__ == "__main__":# 参数设置batch_size = 2seq_len = 10 # 序列长度embed_size = 32# 创建自注意力层self_attn = SelfAttention(embed_size)# 随机生成输入数据x = torch.randn(batch_size, seq_len, embed_size)# 前向传播output, attention = self_attn(x)print("输入形状:", x.shape) # torch.Size([2, 10, 32])print("输出形状:", output.shape) # torch.Size([2, 10, 32])print("注意力矩阵形状:", attention.shape) # torch.Size([2, 10, 10])关键点说明
-
线性变换:通过三个独立的线性层分别生成查询(Q)、键(K)、值(V)
-
注意力计算:
-
通过矩阵乘法计算Q和K的点积
-
使用缩放因子(
)防止梯度消失
-
应用Softmax获取注意力权重
-
-
掩码机制:可选参数,可用于处理变长序列或防止关注非法位置
-
输出计算:使用注意力权重对V进行加权求和