解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-强化学习算法
解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-强化学习算法
现在我们的核心问题是有一些同学会知道要才能强化学习。为什么才能强化学习?是实现AGI。例如从这个其实你从第一阶段开始以后,就是chatbot,这个阶段开始以后,后续的这每个阶段的核心都是强化学习。为什么是这样?
好,先让大家看一个视频。我们我们来播放一个视频。IT seems to be happening that h IT is uh running a social process in the space, the exchange, trying to the which presses the work Better up with and in the process of creating program, the all is that to know. And so I think in fact one is is Jimmy breath through interest and easy adapt to novelty

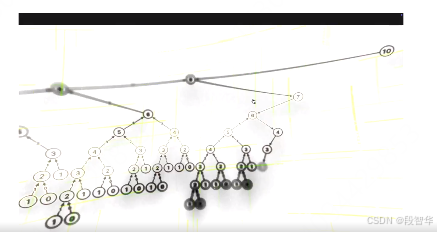
这里面有很重要的,我不知道大家有没有特别注意到。例如说这个地方有可视化的一个部分,就是他自己在执行或者生成的整个trajectory,或者是这个token sequence的过程中,他会有考虑不同的情况。当然这个情况我们后面再讲强化学习的的时候,都会跟大家透彻的去讲。例如说你可能采用传统的蒙特卡罗搜索的方式等等之类。然后你有这些不同的情况,你显然也会评价他的哪个更好,哪个不是太好。这就会涉及到test time compute。这里面所有的东西其实都是强化学习的内容。
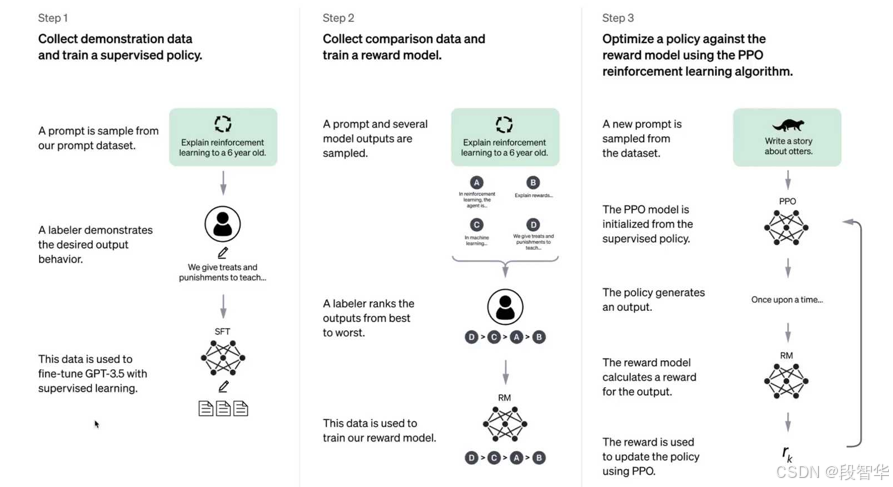
而我们如果要说这个强化学习的内容,我让大家看这个图。如果大家关注ChatGPT的话,就是chat ChatGPT发布的时候就给了这样一幅图,这幅图后面的部分主要就是强化学习本身的算法,以PPO为核心的强化学习这个算法。但我们现在知道无论说是OpenAI还是说google还是说llama还是说DeepSeek等等,大家都十分看重强化学习,尤其在我们现在说的这个test time的阶段。那为什么强化学习可以做的更好,什么做的更好?就是回到我们前面的问题,做这个AGI的五大阶段,为什么?首先这个问题肯定是一个非常关键的一个问题。
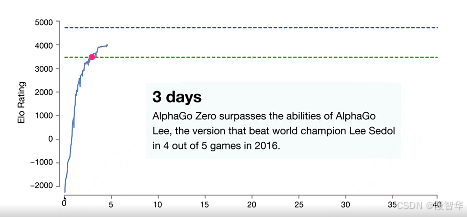
大家看这边是alphago zero的训练过程。