YOLO v1:目标检测领域的革命性突破
引言
在计算机视觉领域,目标检测一直是一个核心任务,它不仅要识别图像中的物体类别,还要确定物体的精确位置。传统目标检测方法如R-CNN系列虽然准确率高,但计算复杂度高、速度慢。2016年,Joseph Redmon等人提出的YOLO(You Only Look Once)算法彻底改变了这一局面,将目标检测推向了一个新的高度。
YOLO v1的核心思想
YOLO v1的核心创新在于将目标检测问题重新定义为一个回归问题,通过单个神经网络直接从完整图像预测边界框和类别概率。这与传统的两阶段方法(如R-CNN系列)形成鲜明对比:

- One-stage检测器:YOLO属于单阶段检测器,直接预测边界框和类别
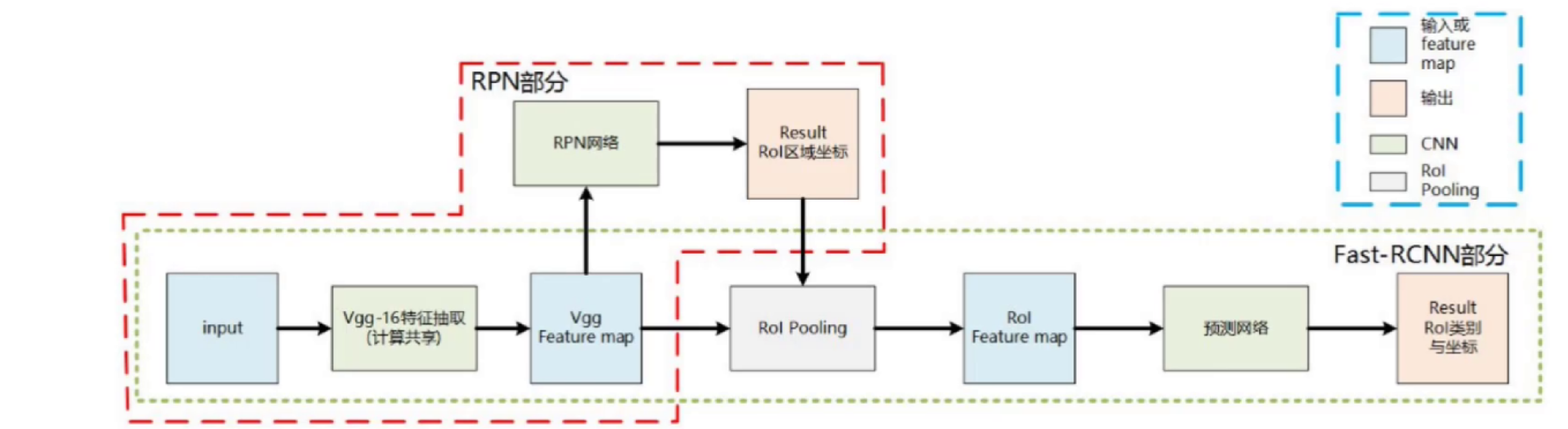
- Two-stage检测器:如Faster R-CNN,首先生成候选区域,然后对候选区域进行分类和回归
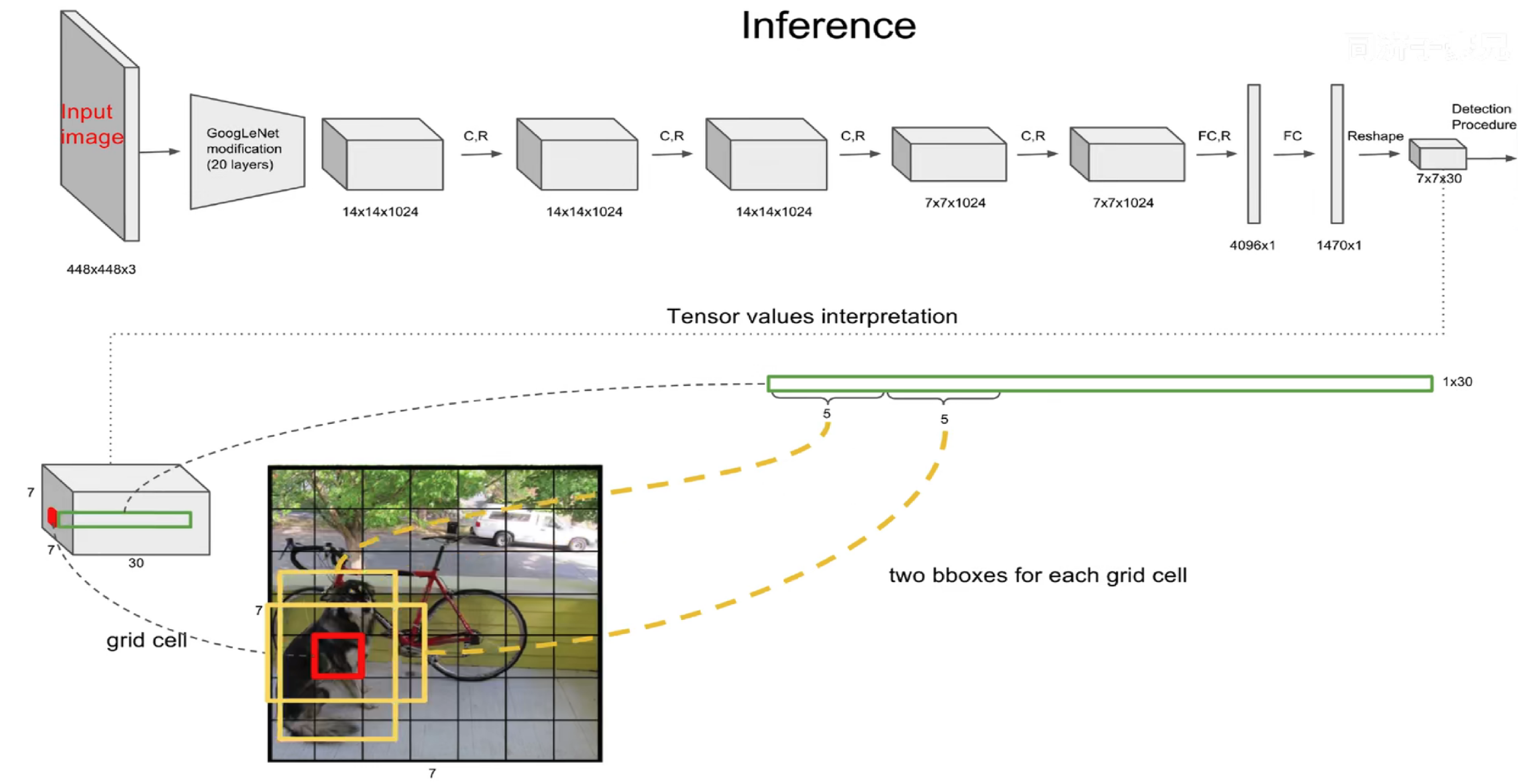
YOLO v1的网络架构
YOLO v1的网络结构借鉴了GoogLeNet的设计,包含:
- 24个卷积层
- 2个全连接层
- 使用1×1降维层后接3×3卷积层替代了GoogLeNet的Inception模块
网络最终输出为7×7×30的张量,其中:
- 7×7表示将输入图像划分为7×7的网格
- 30表示每个网格单元包含的信息:
- 2个预测框,每个框包含5个值(x, y, w, h, confidence)
- 20个类别概率(针对PASCAL VOC数据集的20个类别)
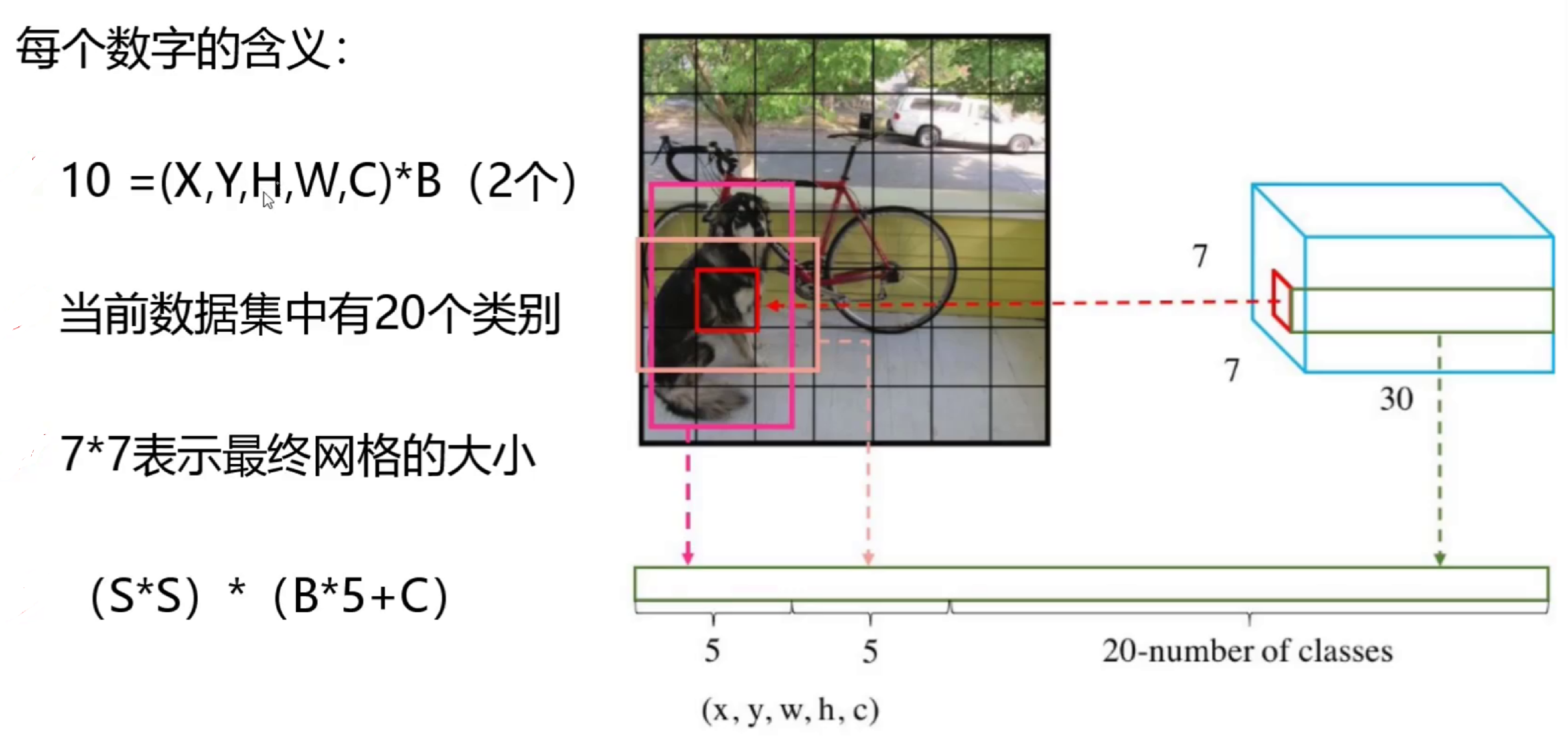
YOLO v1的工作原理
- 图像分割:将输入图像划分为S×S(7×7)的网格
- 目标分配:如果某个目标的中心落在某个网格内,则该网格负责预测该目标
- 边界框预测:每个网格预测B个边界框(YOLO v1中B=2)及其置信度
- 类别预测:每个网格还预测该网格内目标属于各个类别的概率
置信度(confidence)定义为:Pr(Object) × IOUᵗʳᵘᵗʰₚᵣₑₔ,表示预测框包含目标的可能性以及预测框的准确度。
YOLO v1的损失函数
YOLO的损失函数设计非常关键,它需要平衡三个方面的误差:
- 位置误差:边界框中心坐标(x,y)和宽高(w,h)的误差
- 置信度误差:预测框是否包含目标的置信度误差
- 分类误差:目标类别的预测误差
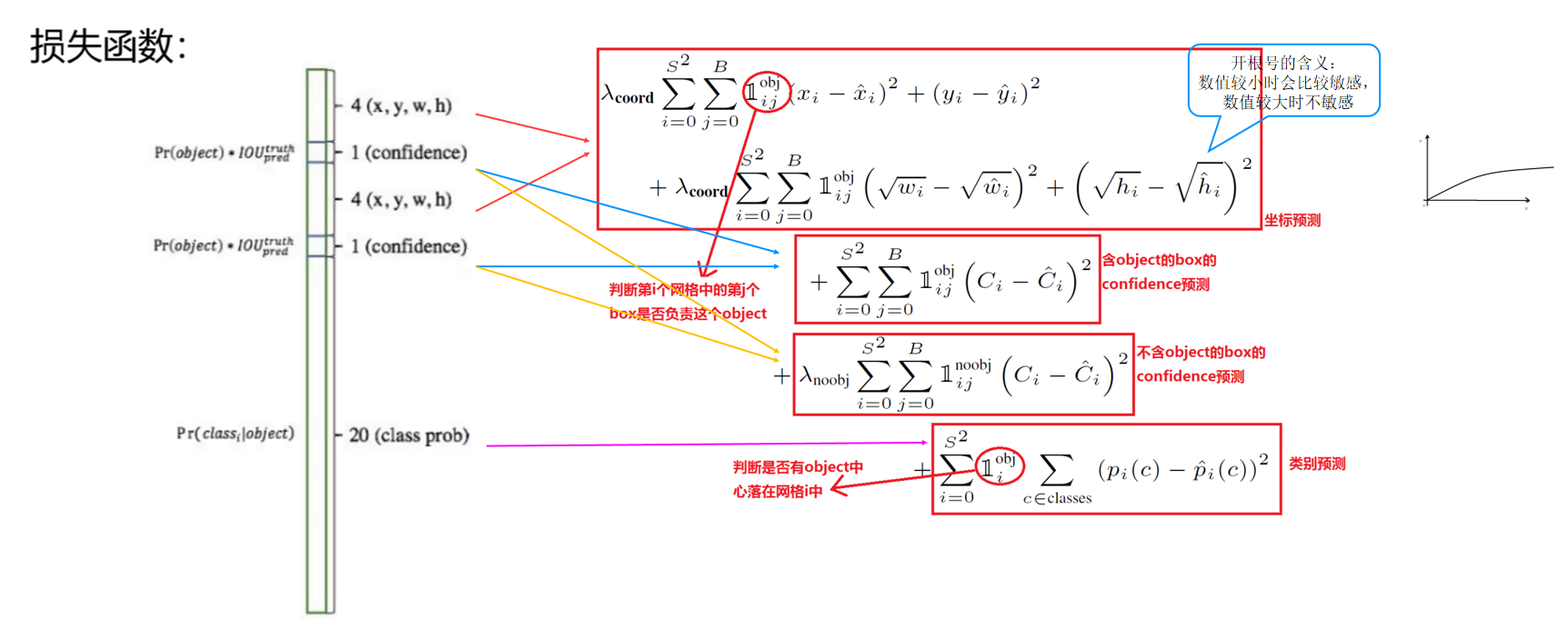
特别值得注意的是,YOLO对宽高误差使用了平方根处理,这使得模型对小框的误差更敏感,因为相同的位置偏差对小框的影响比大框更大。
YOLO v1的优势与局限性
优势
- 速度快:能够达到45FPS,适合实时应用
- 全局推理:一次性查看整个图像,减少背景误检
- 简单直接:端到端训练,无需复杂流程
局限性
- 网格限制:每个网格只能预测一个类别,难以处理重叠目标
- 小物体检测:对小物体检测效果一般
- 长宽比单一:预测框的长宽比选择有限
性能指标
YOLO v1使用mAP(Mean Average Precision)作为主要评估指标:
- mAP50:IoU阈值为0.5时的平均精度
- mAP50-95:IoU阈值从0.5到0.95(步长0.05)的平均精度
虽然YOLO v1的准确率略低于当时最先进的两阶段检测器(如Faster R-CNN),但其速度优势使其成为实时应用的理想选择。
应用领域
得益于其高效的检测速度,YOLO v1在以下领域得到广泛应用:
- 实时视频分析
- 自动驾驶
- 安防监控
- 无人机检测
结语
YOLO v1开创了单阶段目标检测的新范式,其"You Only Look Once"的理念深刻影响了后续的目标检测算法发展。虽然它有一些局限性,但其简洁高效的设计思想仍然值得我们学习和借鉴。在后续的YOLO系列版本中,许多v1的问题得到了改进和优化,但v1作为开创者,其历史地位不可撼动。