Data Mining|缺省值补全实验
- 实验内容任务描述
利用sklearn完成缺省值补全,完成4种以上缺失值补全,并完整地进行模型训练与测试。
四种缺失值补全方法:众数插补、均值插补、K-邻近填充、迭代插补(极大似然估计)
采用模型:随机森林RandomForestClassifier( )
- 实验数据描述
数据集:sklearn的手写数字数据集sklearn.datasets.load_digits()
数据来源:这个数据集来源于美国国家标准与技术研究院(NIST)收集整理的手写数字数据库,经过了一定的预处理后被整合到 scikit-learn 库中。
数据条数:1797张手写数字图像
数据特征:64个(本质上就是将 8×8 像素的手写数字图像按行展开得到的)
在该 8×8 像素的手写数字图像中,不同手写数字在不同像素点会呈现出不同灰度值,因而我们可以通过不同手写数字具有的灰度值特征来进行预测。
说明:由于sklearn.datasets.load_digits() 中并没有缺省值,故在数据处理时人为随机制造缺失值。
- 方法描述
- 众数插补原理
众数是一组数据中出现次数最多的数值。众数插补的基本原理就是利用数据集中已有的完整数据信息,找到每个特征下出现频率最高的那个值,然后用这个众数来填补该特征对应的缺失值。
其背后的逻辑在于,众数在一定程度上反映了该特征最常出现、最具代表性的取值情况,所以当出现缺失值时,用众数来填补可以让数据整体在该特征维度上保持与大部分数据相似的特征表现,维持数据的基本分布结构和特征规律。
| from sklearn.impute import SimpleImputer #创建 SimpleImputer 并指定策略为众数插补 simple_imputer = SimpleImputer(strategy='most_frequent') df_imputed = simple_imputer.fit_transform(df) #对数据集进行拟合并转换(插补缺失值) print(df_imputed) |
众数插补方法简单直观,在很多情况下能有效地处理缺失值问题,不过它也有一定局限性,比如当数据分布较为均匀、不存在明显众数或者众数不能很好代表缺失值合理取值时,插补效果可能不太理想。
- 均值插补原理
均值是一组数据的平均水平的体现,通过计算某一特征所有非缺失值的平均值,用这个平均值来填补该特征对应的缺失值。
其核心思想在于认为数据整体在这个特征维度上具有一定的集中趋势,缺失值的出现只是偶然情况,使用均值进行填补可以让数据在该特征上恢复到整体的平均水平表现,使得数据分布在一定程度上保持相对完整和连贯,从而便于后续的数据分析。
| simple_imputer = SimpleImputer(strategy='mean') #与众数插补非常类似,只是SimpleImputer的策略发生了更改,变为“mean” |
但是,若数据中有异常值,会干扰均值的计算,进而影响插补效果,或者当数据本身分布差异较大时,就要使用其他方法。
- K-邻近填充原理
K - 邻近填充的核心原理是基于这样一个假设:在特征空间中,数据点之间的距离能够反映它们的相似性,距离相近的数据点往往具有相似的属性特征。
换言之,如果一个数据点的某些属性值是缺失的,那么可以通过寻找与其在特征空间中距离最近的K个完整数据点(非缺失值的数据点),利用这K个近邻点对应特征的取值情况来推测该缺失值。
| from sklearn.impute import KNNImputer #用 sklearn 库的 KNNImputer 类来实现K -邻近填充 knn_imputer = KNNImputer(n_neighbors=3) #n_neighbors的值可以调整 df_imputed = knn_imputer.fit_transform(df) # 对数据集进行拟合并转换(填充缺失值) print(df_imputed) |
K - 邻近填充要注意的是n_neighbors的取值,n_neighbors要选取合适的值,数据量一增大,模型对n_neighbors的取值就会变得敏感。可以使用网格搜索、K折交叉验证进行超参数调优,以找到合适的n_neighbors。
- 迭代插补(极大似然估计)原理
迭代插补的核心原理是通过构建一个预测模型,利用数据集中其他非缺失值的特征来预测含有缺失值的特征,并且这个过程会进行多次迭代,不断更新预测结果,使得填补的缺失值更加合理准确。它基于这样一种假设:数据集中的各个特征之间是存在相互关联和依赖关系的,通过挖掘这些关系,可以基于完整的数据部分对缺失部分进行合理推测。
| from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer # 创建IterativeImputer对象,指定基础预测模型以及迭代次数等参数 iterative_imputer = IterativeImputer( estimator=xxxxx, # 可以选择不同的合适的估计器 max_iter=xx, # 设置迭代次数,可根据数据情况调整 random_state=xx) # 设置随机数种子,常用42 df_imputed = iterative_imputer.fit_transform(df) # 对数据集进行拟合并转换 print(df_imputed) |
- 主成分分析(PCA)
主成分分析目的在于对数据降维处理,在尽量保留原始数据中主要信息的前提下,将高维数据投影到低维空间中,使得新的数据表示更加简洁且易于分析和处理。
PCA 试图找到一组新的相互正交(线性无关)的坐标轴(主成分),这些坐标轴按照能够解释原始数据方差的大小进行排序,第一个主成分(轴)能解释原始数据最大的方差,第二个主成分在与第一个主成分正交的前提下,解释次大的方差,以此类推。通过选择前几个方差解释比例较大的主成分,就可以用它们来近似表示原始数据,从而实现降维。
PCA实现方法:可直接调用sklearn 库中的 PCA 类来对数据进行主成分分析。
- 数据可视化方法
本次实验使用了直方图、热力图、混淆矩阵。
均可使用matplotlib库的方法,直接呈现数据的分布特征、缺失值补全效果对比、分类器分类效果等。
- 实验结果

原始手写数字展示0~9
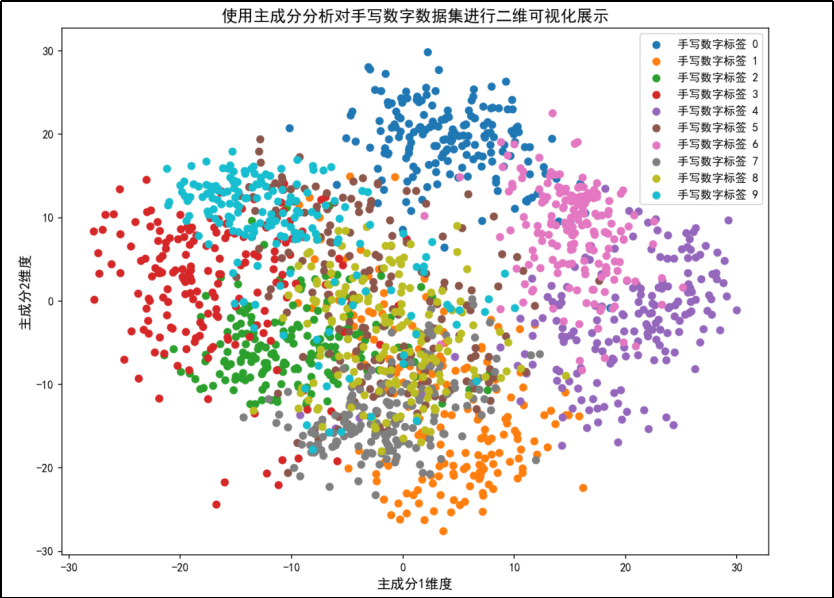
原手写数字数据集二维可视化
二维可视化结果来看:每个数字标签自形成一个聚类。表明不同手写数字标签的样本在主成分空间中有一定的聚集性。
·手写数字标签 0(蓝色)的样本主要集中在图的右上角,形成一个较为紧密的聚类。
·手写数字标签 1(橙色)的样本分布在图的左侧,形成一个相对分散的聚类。
·手写数字标签 2(绿色)的样本分布在图的中间偏左位置,形成一个较为分散的聚类。
·手写数字标签 3(红色)的样本分布在图的中间偏右位置,形成一个较为紧密的聚类。
·手写数字标签 4(紫色)的样本分布在图的中间偏下位置,形成一个较为分散的聚类。
·手写数字标签 5(青色)的样本分布在图的中间偏左位置,形成一个较为分散的聚类。
·手写数字标签 6(黄色)的样本分布在图的右下角,形成一个较为紧密的聚类。
·手写数字标签 7(灰色)的样本分布在图的中间偏上位置,形成一个较为分散的聚类。
·手写数字标签 8(浅绿色)的样本分布在图的右上角,与标签 0 的样本有一定的重叠。
·手写数字标签 9(深蓝色)的样本分布在图的右侧,形成一个较为紧密的聚类。
- 均值插补方法
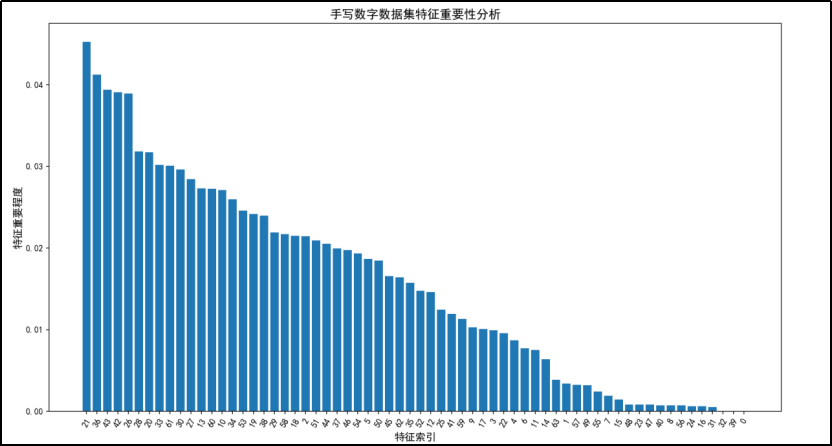
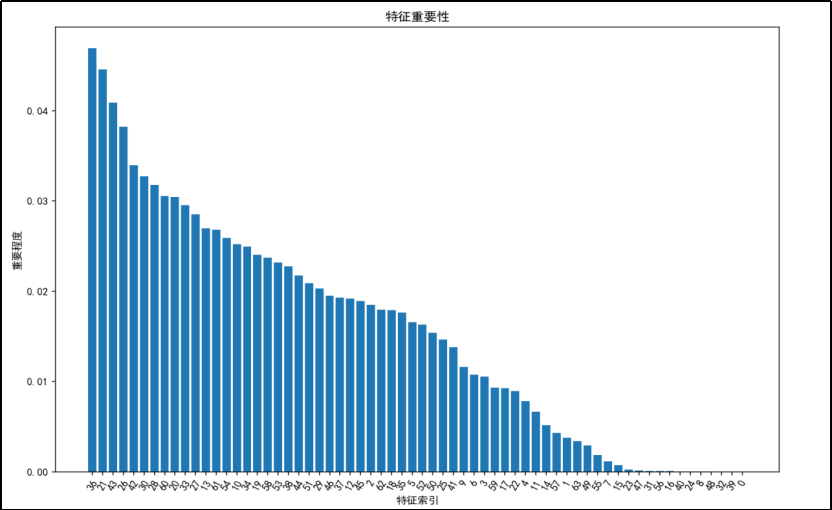
由特征重要性分析可得:
手写数字数据集的特征重要性呈现出明显的递减趋势,前几个特征对模型的贡献最大,而后面的特征重要性逐渐降低。对于手写数字数据集,如果要进行特征选择,可以优先考虑保留前几个特征,因为它们的重要性较高。对于特征重要性较低的特征(如特征索引大于 40 的特征),可以考虑舍弃,以减少模型的复杂度和计算量,同时避免过拟合。

原始手写数字集缺失值矩阵
可以看到在原始数据集中,存在较多的缺失值,黑色条纹较为明显且不规则,表明缺失值在各个特征维度上分布不均匀。

均值插补后的缺失值矩阵
均值插补前后对比表明:
均值插补方法在处理手写数字数据集中的缺失值方面非常有效。通过将缺失值替换为对应特征的均值,能够显著减少数据集中的缺失值数量,使数据更加完整,有助于提高数据分析和模型训练的准确性和可靠性。
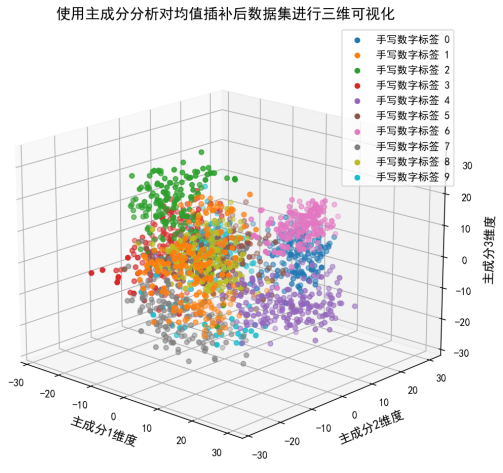
之前的均值插补分析表明,均值插补能够有效减少数据集中的缺失值,使数据更加完整。从三维图来看,经过均值插补后的数据可以进行有效的主成分分析,表明数据的完整性得到了保障,适合进行进一步的数据分析和可视化。
同时,不同手写数字标签之间存在一定的重叠,例如手写数字标签 0 和 8 有一定程度的重叠,这与之前二维可视化的结果一致,说明这些数字在特征空间中的相似性较高。
使用均值插补后的分类结果:
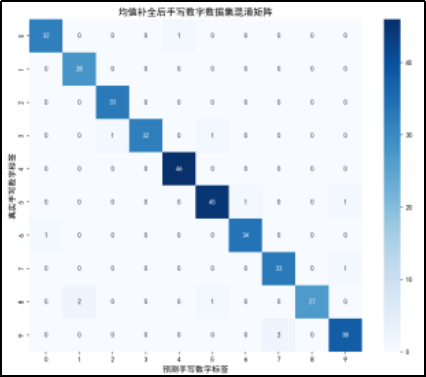
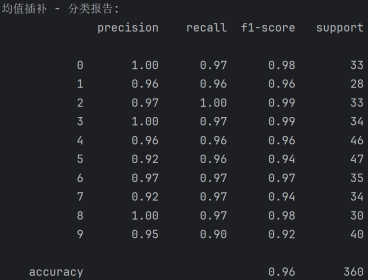
混淆矩阵分析
对角线元素:
·混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 23,以此类推。
·从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(23 个正确预测)和数字 9(38 个正确预测)。
非对角线元素:
·非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。
·可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 1.00,数字 1 的精确率为 0.96,数字 2 的精确率为 0.97,以此类推。
大部分数字的精确率较高,但数字 5(0.92)和数字 7(0.92)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 0.96,数字 2 的召回率为 1.00,以此类推。
数字 2 的召回率为 1.00,表示所有真实标签为 2 的样本都被正确预测。数字 9 的召回率为 0.90,相对较低。
·Accuracy(准确率)
整体准确率为 0.96,表示在所有样本中,被正确预测的样本比例为 96%。这表明模型在均值补全后的手写数字数据集上有较好的分类性能。
- 众数插补方法
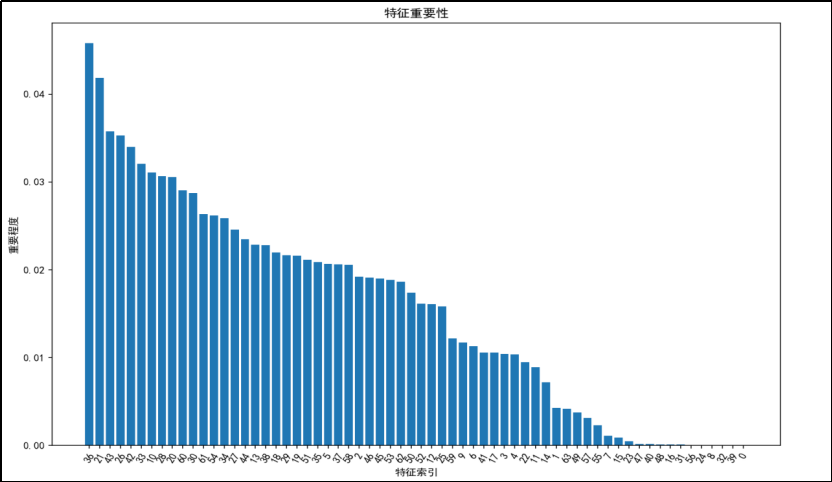
说明:由于不同方法是在不同py文件中实现的,同时缺省值是由random随机产生,所以不同缺省值处理方法所对应的特征重要性直方图有所不同。


众数插补前后对比表明:
黑色条纹几乎消失,表明在众数插补后,数据集中的缺失值得到了很好的填充。众数插补通过计算每个特征的众数,并将缺失值替换为该众数,使得数据集中的缺失值大幅减少,数据的完整性得到了极大提升,有助于提高数据分析和模型训练的准确性和可靠性。
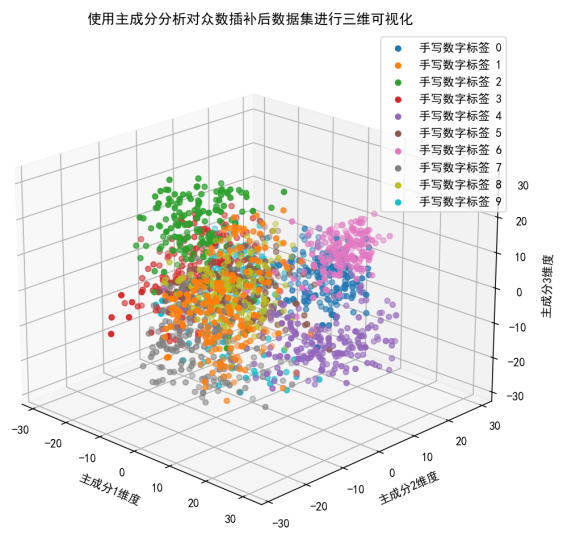
图中不同颜色的点在三维空间中形成了多个聚类,这与之前的均值插补后的可视化结果类似。每个聚类代表一个手写数字标签,说明不同数字在主成分空间中有一定的区分度。
手写数字标签 0(蓝色)的样本主要集中在图的右上角,手写数字标签 1(橙色)的样本分布在图的左侧,手写数字标签 2(绿色)的样本分布在图的中间偏左位置,以此类推。这种分布特征与之前的可视化结果相呼应,进一步验证了数据的内在结构。
使用众数插补后的分类结果:
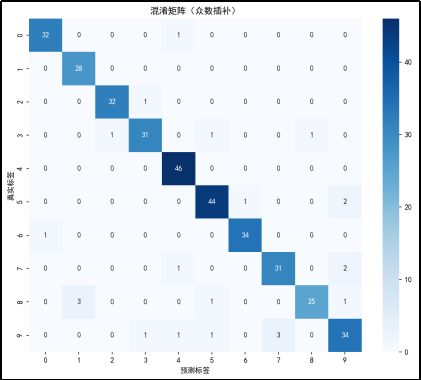
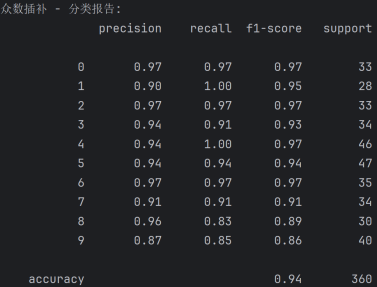
混淆矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。
从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(28 个正确预测)和数字 9(34 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。
可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 0.97,数字 1 的精确率为 0.90,数字 2 的精确率为 0.97,以此类推。
大部分数字的精确率较高,但数字 1(0.90)和数字 9(0.87)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 0.97,以此类推。
数字 1 的召回率为 1.00,表示所有真实标签为 1 的样本都被正确预测。数字 8 的召回率为 0.83,相对较低。
·Accuracy(准确率)
整体准确率为 0.94,表示在所有样本中,被正确预测的样本比例为 94%。这表明模型在众数插补后的手写数字数据集上有较好的分类性能,但略低于均值插补后的准确率(0.96)。
- K-邻近填充方法
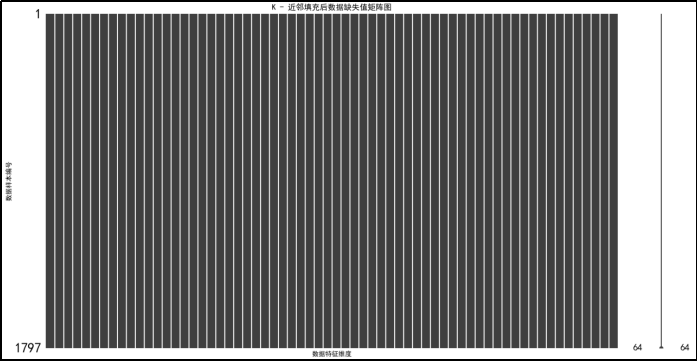
直方图呈现该情况与前两种原因相同,不再赘述。

K-邻近填充前后对比表明:
右侧的黑色条纹几乎消失,表明在 K - 邻近填充后,数据集中的缺失值得到了很好的填充。K - 邻近填充通过寻找每个缺失值的 K 个最近邻,并根据这些近邻的值来填充缺失值,使得数据集中的缺失值大幅减少,整体数据变得更加完整。
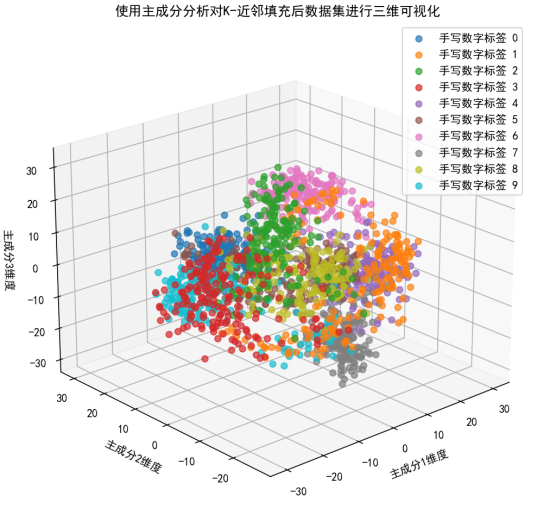
图中不同颜色的点在三维空间中形成了多个聚类,这与之前其他插补方法(如均值插补、众数插补)后的可视化结果类似。每个聚类代表一个手写数字标签,说明不同数字在主成分空间中有一定的区分度。主成分分析能够在三维空间中较好地展示不同手写数字标签的数据分布特征,尽管存在一定的重叠,但总体上能够区分不同的数字。
使用K-邻近填充后的分类结果:
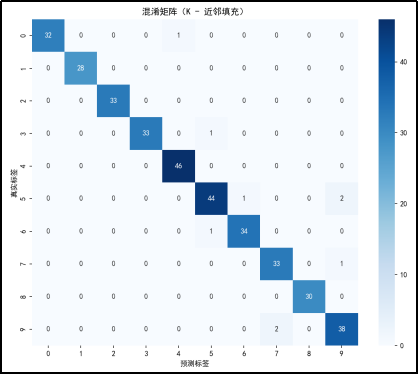
混淆矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 9(38 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
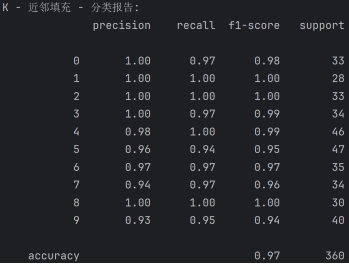
分类报告分析
·Precision(精确率)
精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 1.00,数字 1 的精确率为 1.00,数字 2 的精确率为 1.00,以此类推。
大部分数字的精确率较高,但数字 9(0.93)的精确率相对较低。
·Recall(召回率)
召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 1.00,以此类推。
数字 1、2 和 8 的召回率为 1.00,表示所有真实标签为 1、2 和 8 的样本都被正确预测。数字 9 的召回率为 0.95,相对较低。
·Accuracy(准确率)
整体准确率为 0.97,表示在所有样本中,被正确预测的样本比例为 97%。这表明模型在 K - 近邻填充后的手写数字数据集上有较好的分类性能,且比均值插补(0.96)和众数插补(0.94)后的准确率更高。
- 迭代插补方法
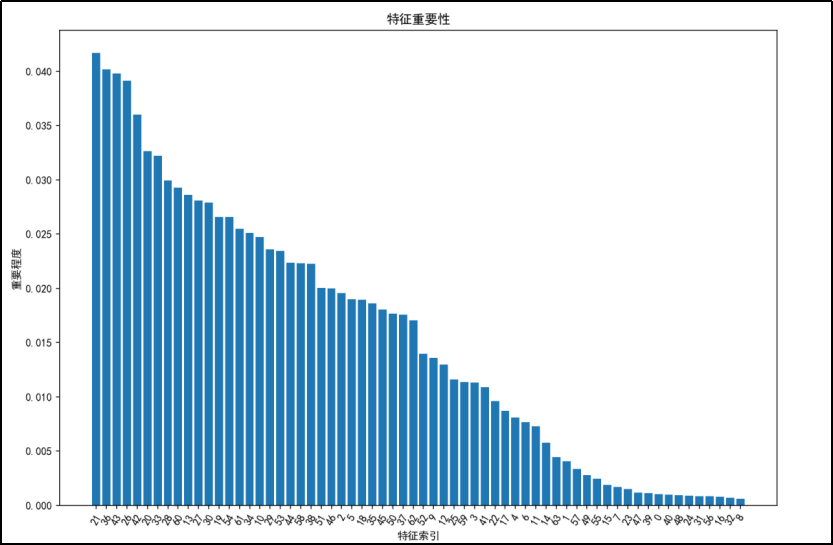
直方图呈现该情况与前两种原因相同,不再赘述。

迭代插补前后对比表明:
迭代插补方法在处理该数据集中的缺失值方面非常有效。通过多次迭代和预测,能够显著减少数据集中的缺失值数量,数据的完整性得到了极大提升,有助于提高数据分析和模型训练的准确性和可靠性。
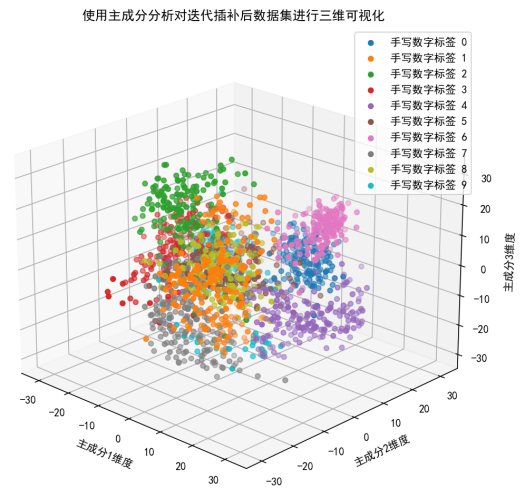
使用迭代插补后的结果:
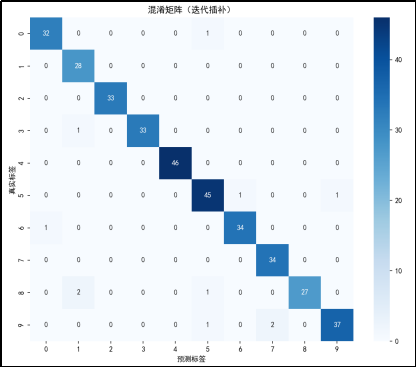
矩阵分析
对角线元素:混淆矩阵的对角线元素表示预测正确的样本数量。例如,真实标签为 0 且预测标签也为 0 的样本数量是 32,真实标签为 1 且预测标签也为 1 的样本数量是 28,以此类推。从对角线元素来看,大部分数字的预测准确率较高,但也有一些数字的预测准确率较低,如数字 1(28 个正确预测)和数字 9(37 个正确预测)。
非对角线元素:非对角线元素表示预测错误的样本数量。例如,真实标签为 0 但被预测为 1 的样本数量是 0,真实标签为 0 但被预测为 2 的样本数量是 0,以此类推。可以看到一些数字之间存在混淆。例如,数字 4 有 46 个样本被正确预测,但有部分样本被错误预测为其他数字,数字 5 有 47 个样本被正确预测,但也有部分样本被错误预测为其他数字。
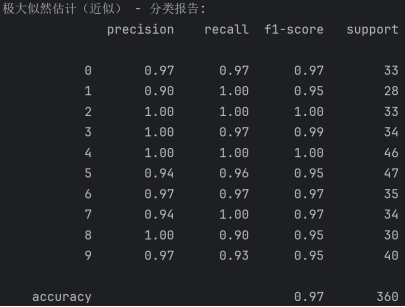
分类报告分析
·Precision(精确率):精确率表示在所有预测为正的样本中,真正为正的样本比例。例如,数字 0 的精确率为 0.97,数字 1 的精确率为 0.90,数字 2 的精确率为 1.00,以此类推。大部分数字的精确率较高,但数字 1(0.90)和数字 9(0.97)的精确率相对较低。
·Recall(召回率):召回率表示在所有真正为正的样本中,被预测为正的样本比例。例如,数字 0 的召回率为 0.97,数字 1 的召回率为 1.00,数字 2 的召回率为 1.00,以此类推。数字 2 和 4 的召回率为 1.00,表示所有真实标签为 2 和 4 的样本都被正确预测。数字 8 的召回率为 0.90,相对较低。
·Accuracy(准确率):整体准确率为 0.97,表示在所有样本中,被正确预测的样本比例为 97%。这表明模型在迭代插补后的手写数字数据集上有较好的分类性能,与 K - 近邻填充后的准确率相同。
- 实验结果分析与结论
(一)四种缺失值处理方法的回顾
1、均值插补
缺失值矩阵对比:原始数据集中存在较多且不均匀分布的缺失值,经过均值插补后,数据集中的缺失值得到了很好的填充,右侧的黑色条纹(代表缺失值)几乎消失。
分类结果:整体准确率达到 96%。不同数字的精确率、召回率和 F1 - score 有一定差异,但整体表现较好。
2、众数插补
缺失值矩阵对比:原始数据集中有较多缺失值,众数插补后数据集中的缺失值大幅减少,黑色条纹几乎消失。
分类结果:整体准确率为 94%。部分数字的精确率、召回率或 F1 - score 相对较低。
3、K - 邻近填充
缺失值矩阵对比:原始数据集存在较多缺失值,K - 邻近填充后缺失值得到很好填充,黑色条纹几乎消失。
分类结果:整体准确率为 97%。在所有插补方法中准确率最高,但数字 9 的精确率、召回率或 F1 - score 相对较低。
4、迭代插补
缺失值矩阵对比:原始数据集缺失值较多且分布不均匀,迭代插补后缺失值大幅减少,黑色条纹几乎消失。
分类结果:整体准确率为 97%,与 K - 邻近填充相同。部分数字(如 1、8、9)的精确率、召回率或 F1 - score 相对较低。
(二)综合结论
缺失值处理效果;
四种方法(均值插补、众数插补、K - 邻近填充、迭代插补)在处理手写数字数据集中的缺失值时,都能有效地减少缺失值数量,从缺失值矩阵图来看,原始数据集中明显的缺失值在处理后都得到了很好的填充,数据完整性得到了显著提升。
对分类准确率的影响;
K - 邻近填充和迭代插补:这两种方法在分类准确率上表现最佳,整体准确率都达到了 97%。它们能够更好地利用数据的内在结构来填充缺失值,进而在后续的分类任务中取得较好的结果。
均值插补:其整体准确率为 96%,略低于 K - 邻近填充和迭代插补,但仍然是一种有效的缺失值处理方法,计算成本相对较低。
众数插补:整体准确率为 94%,在四种方法中最低。虽然它能处理缺失值,但可能由于众数不能很好地代表某些特征的中心趋势,导致在分类任务中的表现相对较弱。
不同数字的分类表现:
在所有方法中,都存在部分数字(如数字 9)的精确率、召回率或 F1 - score 相对较低的情况。这表明这些数字在特征空间中的区分难度较大,无论采用哪种缺失值处理方法,都需要进一步优化模型或者进行针对性的数据增强来提高对这些数字的分类能力。
计算成本和复杂度:
均值插补和众数插补:计算简单,复杂度低,适合大规模数据和对计算资源有限的场景。
K - 邻近填充和迭代插补:计算相对复杂,尤其是在处理大规模数据集时,可能会消耗较多的计算资源和时间。它们通常需要对一些参数(如 K - 邻近填充中的 K 值、迭代插补中的迭代次数等)进行调优,以达到最佳的填充和分类效果。