阿里端到端多模态语音对话开源模型论文速读:Qwen2.5-Omni
Qwen2.5-Omni 技术报告
1. 介绍
Qwen2.5-Omni 技术报告介绍了一个先进的端到端多模态模型 Qwen2.5-Omni,该模型能够感知包括文本、图像、音频和视频在内的多种模态,并能同时以流式方式生成文本和自然语音响应。该模型解决了统一不同理解模态、管理不同模态输出之间的潜在干扰以及实现实时理解和高效音频输出流的挑战。
2. 关键特性
报告突出了 Qwen2.5-Omni 的几个关键特性:
-
多模态感知与生成:Qwen2.5-Omni 可以处理多种模态,并以流式方式同时生成文本和语音。
-
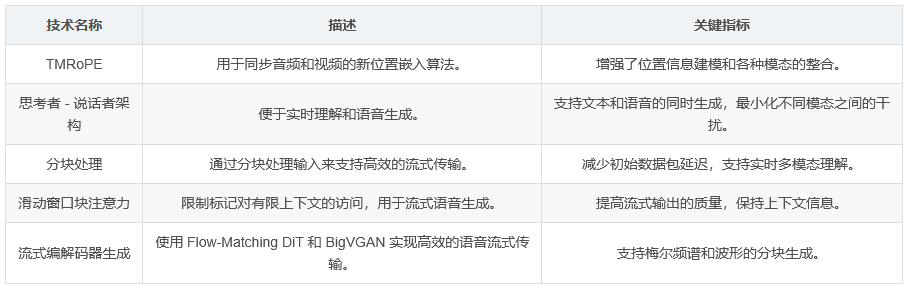
TMRoPE 位置嵌入:一种新颖的位置嵌入算法,用于同步音频和视频的时间信息。
-
思考者 - 说话者架构:该架构便于实时理解和语音生成,其中思考者负责文本生成,说话者负责生成流式语音标记。
-
流式能力:Qwen2.5-Omni 被设计为减少初始数据包延迟,并支持实时理解多模态信息。
3. 架构
Qwen2.5-Omni 采用思考者 - 说话者架构。思考者相当于大脑,负责处理来自文本、音频和视频模态的输入,生成高级表示和相应文本。说话者则像人类的嘴巴一样,以流式方式接收思考者生成的高级表示和文本,并流畅地输出离散的语音标记。
4. 感知与生成
Qwen2.5-Omni 处理各种输入信号,将它们转换为一系列隐藏表示。对于文本,它使用 Qwen 的标记器。音频输入被重新采样并转换为梅尔频谱图。视觉编码器处理图像和视频输入。模型还引入了 TMRoPE,它对多模态输入的三维位置信息进行编码。
5. 流式设计
为了支持流式交互,Qwen2.5-Omni 实现了几种设计:
-
分块处理:音频和视觉编码器被修改为支持沿时间维度的分块注意力。
-
滑动窗口块注意力:限制当前标记对有限上下文的访问,以提高流式输出的质量。
6. 预训练和微调
Qwen2.5-Omni 经历了三个阶段的预训练:
-
使用大量的音频 - 文本和图像 - 文本对训练视觉和音频编码器。
-
解冻所有参数并使用更广泛的多模态数据进行训练。
-
使用长度为 32k 的序列数据来增强模型理解复杂长序列数据的能力。
微调涉及使用指令遵循数据进行微调,并对说话者进行三阶段训练过程,以同时生成文本和语音响应。
7. 评估
报告对 Qwen2.5-Omni 在各种任务上的性能进行了全面评估,包括文本→文本、音频→文本、图像→文本、视频→文本和多模态→文本。还评估了 Qwen2.5-Omni 在零样本文本和单说话人场景下的语音生成能力。
8. 结论
Qwen2.5-Omni 代表了向通用人工智能(AGI)迈进的重要进展。该模型在复杂的视听交互和语音对话的情感上下文中表现出色。报告得出结论,Qwen2.5-Omni 在性能上超越了同样大小的单模态模型,并在多模态任务中取得了最先进的成果。
核心技术汇总