关于深度学习的一些模型算法
GRU与LSTM
GRU
1.GRU介绍
GRU 是循环神经网络(RNN)的一种改进结构,它通过引入门控机制,解决了传统RNN在处理长序列时容易出现的梯度消失/爆炸问题,同时相比LSTM(长短期记忆网络)结构更简单,参数更少,计算效率更高。
GRU 的核心是两个门控单元:更新门(Update Gate)和重置门(Reset Gate)。这两个门控机制决定了当前时刻的隐藏状态如何保留或更新信息。
2.工作原理
- 更新门:控制隐藏状态需要保留多少旧信息(例如,如果句子中的主语未变,可以保留更多历史信息)。
- 重置门:控制是否忽略过去的信息(例如,遇到句子中的新主题时,可能需要重置历史状态)。
- 候选状态:基于当前输入和重置后的历史信息生成新状态。
- 最终隐藏状态:通过更新门合并旧状态和候选状态。
3.举个例子:预测温度序列
假设需要根据过去5天的温度预测明天的温度,用GRU处理时间序列数据:
- 输入序列:
[20°C, 22°C, 25°C, 23°C, 24°C] - 目标输出:预测第6天的温度。
步骤分析:
- 第1天(20°C)
- 重置门可能打开(因无历史数据),候选状态完全由当前输入决定。
- 第2天(22°C)
- 更新门决定保留部分第1天的信息,同时结合当前输入。
- 第5天(24°C)
- 若气温趋势稳定(如连续上升),更新门会保留更多历史信息;若突然变化(如突降),重置门会忽略部分旧状态。
通过门控机制,GRU能动态调整信息流,有效捕捉长期依赖关系。
LSTM
1.LSTM介绍
解决RNN的梯度消失/爆炸问题,增强对长序列数据的记忆能力,引入细胞状态(Cell State) 和门控机制,通过选择性记忆实现长期依赖的捕捉。
2.工作原理
- 细胞状态(C):像一个“传送带”,贯穿整个时间步,负责长期记忆。
- 遗忘门:类似于“选择性忘记”过去的事件,决定从细胞状态中丢弃哪些旧信息。(例如,当模型处理到句子的新段落时,可能需要遗忘前文的主语)。
- 输入门:类似于“选择性记住”当前事件,决定当前输入中有多少新信息存入细胞状态。(例如,记住句子中的新名词)。
- 细胞状态更新:结合遗忘门和输入门的结果,更新细胞状态。
- 输出门:决定当前时刻需要对外暴露哪些信息(例如,生成动词时需要主语的上下文)。
3.举个例子:文本生成任务
任务:根据输入句子“The cat sat on the”生成后续单词(例如“mat”)。
LSTM 的工作过程:
- 处理“The”:
- 输入门将“The”存入细胞状态(作为主语)。
- 处理“cat”:
- 输入门记住“cat”作为主语,遗忘门可能弱化之前的无关信息。
- 处理“sat”:
- 输出门决定需要传递“cat”作为动作的主体,生成“sat”。
- 处理“on the”:
- 细胞状态仍保留“cat”信息,输出门结合上下文生成“mat”。
GRU与LSTM对比
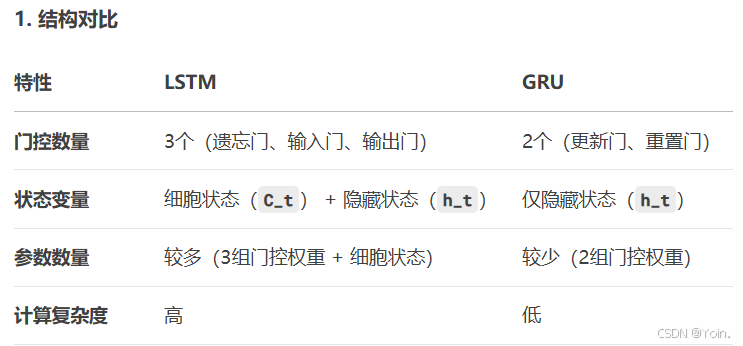
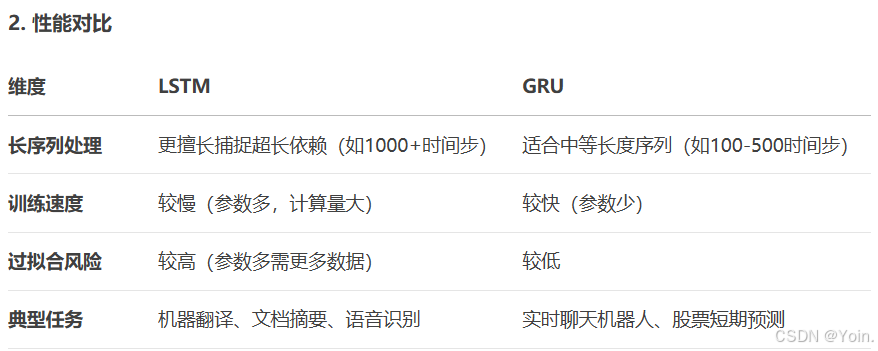
3.举个例子
场景设定
假设某用户的历史购物记录如下(按时间顺序):
- 手机
- 手机壳
- 耳机
- 咖啡机
- 咖啡豆
任务:预测用户下一次可能购买的商品(例如“咖啡杯”)。
我们用 LSTM 和 GRU 分别建模这一过程,对比它们如何捕捉用户兴趣的长期和短期依赖。
LSTM 的工作原理与示例
步骤分析
1.购买“手机”
·输入门:记录“手机”为当前兴趣(存入细胞状态 C_t)。
·细胞状态:C_t = [手机]
·输出门:生成隐藏状态 h_t,可能关联“手机配件”(如预测下一步买手机壳)。
2.购买“手机壳”
·遗忘门:保留“手机”信息(因手机壳是相关配件)。
·输入门:加入“手机壳”到细胞状态。
·细胞状态:C_t = [手机 + 手机壳]
·输出门:预测下一步可能买“耳机”(同为手机配件)。
3.购买“耳机”
·细胞状态:继续积累电子产品信息。
·输出门:预测“充电宝”或其他配件。
4.购买“咖啡机”
·遗忘门:弱化之前的“手机”类信息(兴趣转向厨房用品)。
·输入门:新增“咖啡机”到细胞状态。
·细胞状态:C_t = [咖啡机]
·输出门:预测“咖啡豆”(相关商品)。
5.购买“咖啡豆”
·输入门:强化厨房用品兴趣。
·细胞状态:C_t = [咖啡机 + 咖啡豆]
·输出门:结合长期兴趣(厨房用品),预测“咖啡杯”。
GRU 的工作原理与示例
1.购买“手机”
·更新门:完全接受新信息(z_t≈1),隐藏状态 h_t = [手机]。
·预测:手机壳(短期关联)。
2.购买“手机壳”
·重置门:保留“手机”信息(r_t≈1)。
·候选状态:手机 + 手机壳 → 耳机。
·更新门:部分保留旧状态(z_t=0.5),隐藏状态混合新旧信息。
3.购买“耳机”
·候选状态:继续积累电子产品信息。
·预测:充电宝。
4.购买“咖啡机”
·重置门:r_t≈0,丢弃之前的电子产品信息(因兴趣突然切换)。
·候选状态:仅基于“咖啡机”生成新状态。
·更新门:z_t≈1,隐藏状态直接更新为厨房用品。
5.购买“咖啡豆”
·候选状态:结合“咖啡机”和“咖啡豆”(r_t≈1)。
·预测:咖啡杯(短期关联性更强)。
再举一个极端例子
假设用户行为序列为:
[手机 → 手机壳 → 手机贴膜 → 咖啡机 → 咖啡豆 → 咖啡杯 → 手机支架]
- LSTM:
可能通过细胞状态保留“手机”长期兴趣,即使中途购买了咖啡用品,最终仍预测“手机支架”。 - GRU:
可能在购买咖啡机时重置历史状态,后续更关注厨房用品,但若更新门保留部分旧状态,仍可能预测“手机支架”。
4.如何选择 LSTM 或 GRU?
选择 LSTM 的情况:
- 任务依赖极长序列(如整篇文档的理解)。
- 需要精细控制信息流动(如每个时间步需明确遗忘和记忆的内容)。
- 计算资源充足,允许较长的训练时间。
选择 GRU 的情况:
- 任务对实时性要求高(如在线聊天机器人)。
- 数据量较小,需避免过拟合。
- 序列长度中等且模型需要快速迭代。
GAT
1.GAT的核心思想
图注意力网络(Graph Attention Network, GAT)是图神经网络(GNN)的扩展,通过引入注意力机制动态分配邻居节点的重要性权重,从而更灵活地捕捉图结构中的复杂关系。与传统图卷积网络(GCN)对所有邻居节点平等加权不同,GAT允许模型在聚合信息时聚焦关键节点,提升特征表达能力。
核心特点:
-
动态权重分配:通过注意力系数衡量节点间交互的重要性。
-
无需全局图结构:仅依赖局部邻域信息,适用于归纳式学习(如处理未见过的图)。
-
多头注意力机制:并行计算多组注意力权重,增强鲁棒性和表达能力
2. GAT 的核心步骤
GAT 的核心是通过注意力机制聚合邻居信息,分为以下步骤:
步骤 1:计算注意力系数

步骤 2:归一化注意力系数

步骤 3:加权聚合邻居信息

步骤 4:多头注意力(可选)
为增强模型稳定性,可并行使用多个独立的注意力头(Multi-Head),每组注意力头独立学习不同的权重模式,并将结果拼接或平均:
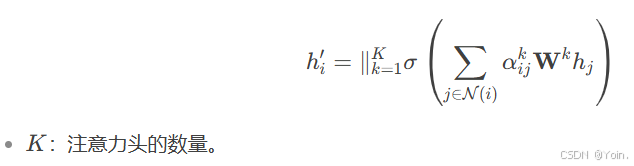
3.举个例子:社交网络用户推荐
任务:在社交网络中预测用户可能感兴趣的内容。
图结构:节点为用户,边为关注关系,节点特征为用户兴趣标签(如“科技”“美食”)。
示例数据
- 用户A(兴趣:科技、编程)
- 用户B(兴趣:科技、游戏)
- 用户C(兴趣:美食、旅游)
用户A关注了用户B和用户C,需聚合邻居信息更新A的表示。
GAT 计算过程
- 计算注意力系数:
- A与B的相似性:科技兴趣重叠 → 高注意力系数。
- A与C的相似性:兴趣差异大 → 低注意力系数。
假设归一化后权重为:αAB=0.8, αAC=0.2。
- 加权聚合:
- 用户A的新特征 = 0.8×用户B特征+0.2×用户C特征。
结果更接近用户B,反映A对科技内容的兴趣。
- 用户A的新特征 = 0.8×用户B特征+0.2×用户C特征。
- 预测推荐:
根据更新后的特征,向A推荐科技类内容(如编程课程),而非美食类。
4.GAT vs GCN(图卷积神经网络) 的对比
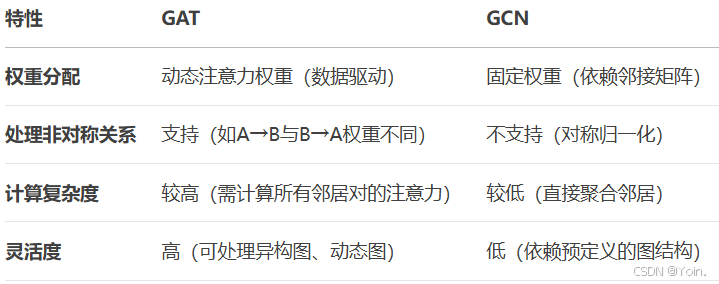
VAE
1.VAE 核心思想
VAE(变分自编码器)是一种结合了深度学习和概率模型的生成模型,其核心思想是通过学习数据的潜在分布来生成新样本。与传统自编码器(AE)不同,VAE的潜在空间是概率分布的(如高斯分布),而非固定编码,这使得它能生成多样化的数据。
核心思想:
- 编码器:将输入数据映射到潜在空间的概率分布(用均值和方差表示)。
- 重参数化采样:从分布中采样潜在变量(解决不可导问题)。
- 解码器:将潜在变量重构为原始数据。
2.VAE数学模型
VAE 的目标是最大化输入数据 x 的边际似然 pθ*(*x),其中 θ 是解码器参数。由于直接计算困难,引入变分推断,优化其下界(ELBO)。


3.VAE网络结构
VAE 分为编码器(Encoder)和解码器(Decoder)两部分:
编码器(Encoder)
- 结构:多层神经网络(如全连接层或卷积层)。
- 输出:潜在变量的均值(μ)和方差(σ²)。
- 实例:输入一张28×28的手写数字图片,编码器输出一个128维的潜在分布参数
解码器(Decoder)
- 结构:与编码器对称的神经网络。
- 输出:从潜在变量重建的原始数据。
- 实例:将采样后的潜在变量z映射回28×28的生成图像
损失函数(见上面的数学模型)
- 重构损失(如均方误差):衡量生成数据与原始数据的差异。
- KL散度:约束潜在变量分布接近标准正态分布(防止过拟合)。
- 实例:若输入图像为“3”,重构误差确保生成图像接近“3”,而KL散度让潜在变量分布更平滑
重参数化技巧(解决不可导问题):由于直接从分布中采样无法求导,VAE通过引入噪声ε(来自标准正态分布)将采样过程改写为可导形式。
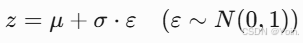
若采样得到的z为[0.5, -0.3],解码器可能生成一张介于“3”和“8”之间的过渡图像,体现潜在空间的连续性。
4.举个例子:生成手写数字
以手写数字生成(如MNIST数据集)为例:
- 输入:一张手写数字图片(如数字“3”)。
- 编码器:输出该图片对应的潜在变量分布(如均值μ=[0.2, -0.1],方差σ²=[0.3, 0.2])。
- 采样:从该分布 N(μ,σ2)中随机采样一个潜在变量z(如z=μ + εσ,其中ε为标准正态噪声)。
- 解码器:将z解码为一张新的手写数字图片(可能是“3”或介于“3”和“8”之间的过渡形态),或生成新数字(如调整 z的值生成“5”)。
潜在空间的可视化:若潜在空间为 2 维,不同区域对应不同数字,
扩散模型
1.扩散模型的思想
扩散模型是一种生成模型,灵感来源于物理学中的扩散现象。其核心思想是通过两个过程学习数据分布:
- 正向扩散过程(Forward Process):逐步向数据中添加噪声,直到数据变成纯噪声(一张清晰的数字“3”图像,经过300步加噪后变成一张类似雪花屏的纯噪声图像)。
- 反向去噪过程(Reverse Process):学习从噪声中逐步恢复原始数据(神经网络从纯噪声出发,通过预测每一步的噪声,逐步还原出清晰的“3”或其他数字)。
2.扩散模型的数学框架



3.举个例子:生成猫咪图片
任务:从随机噪声生成一张猫咪图片。
步骤分析
(1)正向扩散(训练阶段):
- 输入一张真实的猫咪图片 x0。
- 逐步添加噪声,经过 T=1000步后,得到纯噪声 x1000。
- 神经网络学习每一步中噪声的添加模式。
(2)反向去噪(生成阶段):
- 从随机噪声x1000开始。
- 通过训练好的神经网络预测每一步的噪声 ϵθ,逐步去噪。
- 经过T步去噪后,得到清晰的猫咪图片x0
生成对抗网络GAN
1.GAN的基本思想
GAN 由两个神经网络组成,通过“对抗”的方式共同提升:
- 生成器(Generator):生成假数据(如图像、文本),目标是欺骗判别器。
- 判别器(Discriminator):区分真实数据和生成器生成的假数据,目标是提高鉴别能力。
- 对抗过程:生成器试图欺骗判别器,判别器则不断提升鉴别能力,最终达到平衡(生成数据与真实数据难以区分)。
类比理解:
- 生成器:假币制造者,不断改进假币质量以骗过警察。
- 判别器:警察,不断学习识别假币的特征。
- 最终目标:假币质量足够高,警察无法区分真假。
2.GAN的训练过程

训练步骤:
固定生成器,训练判别器:
- 输入真实数据和生成数据,计算判别损失(二元交叉熵)。
- 更新判别器参数,最大化判别器对真实数据和假数据的区分能力。
固定判别器,训练生成器:
- 生成数据输入判别器,计算生成损失(欺骗判别器的能力)。
- 更新生成器参数,最小化判别器对假数据的识别能力。
4.举个例子:生成手写数字
任务:生成与 MNIST 数据集类似的逼真手写数字。
步骤分析
(1)初始化:
- 生成器接收随机噪声 z(如100维向量),输出一张“假数字”图像(初始阶段是乱码)。
- 判别器接收真实图像和假图像,输出判别概率(初始准确率接近50%)。
(2)训练判别器:
- 输入真实图像(标签1)和生成器的假图像(标签0)。
- 判别器通过反向传播学习区分两者。
- 结果:判别器准确率提高。
(3)训练生成器:
- 生成器生成新的假图像,目标是让判别器误判为真实(标签1)。
- 生成器通过反向传播调整参数,生成更逼真的图像。
- 结果:假图像逐渐接近真实手写数字。
(4)平衡状态:
- 理想情况下,生成器生成的图像与真实数据分布一致,判别器无法区分(输出概率恒为0.5)。
图神经网络
图神经网络(Graph Neural Networks, GNNs)是一种特殊的神经网络架构,用于处理图结构数据。与传统的神经网络处理一维序列(如文本)或二维网格(如图像)不同,GNNs能够处理具有任意连接关系的数据,如社交网络、化学分子结构、网页链接等。
定义
图神经网络是一种深度学习模型,它在图结构数据上进行操作。在图中,节点(Vertices 或 Nodes)表示实体,边(Edges)表示实体之间的关系。GNNs通过迭代地更新节点的表示来捕捉图中的局部结构信息,从而进行图级别的任务,如节点分类、边预测、图分类等。
关键概念
- 节点特征:每个节点都可以有一个特征向量,这些特征向量可以用来表示节点的属性。
- 邻居聚合:GNNs通过聚合节点的邻居信息来更新节点的表示。这个过程通常涉及将邻居的特征向量进行加权求和或其他类型的聚合操作。
- 消息传递机制:在迭代过程中,节点通过与邻居交换信息来更新自身的状态,这个过程被称为消息传递。
基本工作原理
- 初始化:为每个节点分配一个初始特征向量。
- 消息传递:节点通过与其邻居交换信息来更新自己的状态。这个过程通常涉及聚合邻居的特征向量,并将聚合结果与当前节点的特征向量结合。
- 更新节点表示:基于聚合的信息更新节点的特征向量。
- 重复迭代:上述过程通常会重复多次,直到达到预定的迭代次数或满足某些终止条件。
- 读出层:最后,通过一个读出层(Readout Layer)将节点级别的表示整合为图级别的表示,以完成图级别的任务。
自编码器
自编码器(Autoencoder, AE)是一种无监督学习方法,最初用于特征学习和数据压缩。自编码器由两部分组成:编码器(Encoder)和解码器(Decoder)。其目的是学习数据的紧凑表示,同时能够重构原始输入数据。自编码器的基本思想是通过一个瓶颈层(中间层)来迫使模型学习输入数据的重要特征。
定义
自编码器是一种神经网络架构,它由以下几个主要部分构成:
- 编码器(Encoder):将输入数据映射到一个较低维度的隐空间(latent space)中,生成一个紧凑的表示(编码)。
- 解码器(Decoder):将隐空间中的表示映射回原始数据空间,试图重构输入数据。
- 损失函数(Loss Function):通常使用重构误差(如均方误差或交叉熵)作为损失函数,衡量重构数据与原始输入之间的差异。
工作原理
- 编码阶段:输入数据 x 通过编码器生成一个隐空间表示h=f(x)
- 解码阶段:隐空间表示 h 通过解码器生成重构数据 X^ = g(h)
- 训练目标:最小化重构误差L(x, x^) ,即尽可能使重构数据 x ^接近原始输入数据x。
类型
- 标准自编码器(Standard Autoencoder):最基本的自编码器形式,目标是最小化重构误差。
- 稀疏自编码器(Sparse Autoencoder):通过正则化约束,使得隐层单元的激活值接近于零,从而学习到更稀疏的特征表示。
- 去噪自编码器(Denoising Autoencoder):在编码器输入前加入噪声,目标是重构干净的原始输入数据。
- 变分自编码器(Variational Autoencoder, VAE):在编码器中引入概率分布,使得隐空间表示符合某种先验分布(如高斯分布),从而具备生成新样本的能力。
- 卷积自编码器(Convolutional Autoencoder):使用卷积层和反卷积层代替全连接层,适用于图像数据的特征学习和重构。
- 递归自编码器(Recursive Autoencoder):用于处理树形结构数据,如句子的句法树。
循环神经网络
循环神经网络(Recurrent Neural Network, RNN)是一种专为处理序列数据设计的神经网络架构。与传统的前馈神经网络不同,RNN能够处理具有时间依赖性的数据,因为它们具有记忆功能,可以记住之前输入的信息,并在后续时刻使用这些信息。
结构
RNN的基本单元可以表示如下:
- 输入层(Input Layer):接收当前时刻的输入数据。
- 隐藏层(Hidden Layer):处理当前时刻的输入数据,并将隐藏状态传递给下一时刻。
- 输出层(Output Layer):生成当前时刻的输出。
RNN的隐藏层具有递归连接,这意味着隐藏状态会在时间上向前传递。RNN的更新公式可以简单表示为:

变体
RNN有一些常见的变体,以解决长序列中的梯度消失或梯度爆炸问题:
- 长短期记忆网络(Long Short-Term Memory, LSTM):引入了门控机制(如输入门、遗忘门、输出门),使得模型能够记住长期依赖信息。
- 门控循环单元(Gated Recurrent Unit, GRU):是LSTM的一种简化版本,通过合并遗忘门和输入门为一个单一的更新门来减少参数量。
GPT
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的预训练语言模型,最初由OpenAI提出。GPT模型通过在大量未标注的文本数据上进行无监督预训练,学习到了丰富的语言表示,之后可以通过微调来适应各种下游任务。
定义
GPT模型的核心创新在于使用了Transformer架构,这是一种完全基于注意力机制(Attention Mechanism)的模型。与传统的RNN相比,Transformer在处理长序列数据时更为高效,并且可以并行化计算。GPT模型通过在大规模文本数据上进行预训练,学习到了语言的通用表示,然后可以被微调以适应特定的任务。
工作原理
- 预训练(Pre-training):在大规模未标注的文本数据上进行无监督学习,通过语言建模任务(如预测下一个词)来学习语言表示。
- 微调(Fine-tuning):将预训练得到的模型应用于特定的任务,通过少量标注数据进行微调,以适应特定任务的需求。
关键组件
- Transformer架构:包含多头注意力机制(Multi-head Attention)和位置编码(Positional Encoding),能够捕捉长距离依赖关系。
- 自回归训练(Autoregressive Training):通过预测序列中的下一个词来训练模型。
- 大规模预训练:使用数十亿甚至万亿级别的文本数据进行预训练,以获得强大的语言理解能力。
BERT
BERT是一种基于Transformer架构的预训练语言模型。BERT的最大特点是其双向编码机制,它能够理解文本中词汇的上下文意义,并且在多种自然语言处理任务中取得了显著的成绩。BERT的推出标志着自然语言处理领域的一次重大飞跃,开启了预训练模型大规模应用的新时代。
定义
BERT是一种用于自然语言处理的深度学习模型,其核心特点是通过双向Transformer编码器来学习词的上下文表示。与其他语言模型(如GPT)不同,BERT在预训练阶段并不依赖于单向的自回归机制,而是通过掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)任务来训练模型。
关键特点
- 双向编码:BERT通过双向Transformer编码器来学习词的上下文表示,这意味着它可以同时考虑一个词的前后文信息。
- 掩码语言模型(MLM):在预训练阶段,BERT会对输入文本中的部分词进行随机掩码(即用特殊标记[MASK]替换),然后尝试根据上下文恢复这些掩码词。这种方法使BERT能够学习到词的上下文依赖性。
- 下一句预测(NSP):BERT还通过预测两个句子是否连续来训练模型,这有助于模型理解句子之间的关系。
训练过程
- 预训练(Pre-training):在大规模未标注文本数据上进行无监督学习,通过掩码语言模型(MLM)和下一句预测(NSP)任务来训练模型。
- 微调(Fine-tuning):将预训练好的模型应用于特定的下游任务,通过少量标注数据进行微调,以适应特定任务的需求。
模型架构
BERT模型主要包括以下几部分:
- 嵌入层(Embedding Layer):将输入的词汇映射到高维向量空间。
- 位置嵌入(Positional Embeddings):为每个位置的词汇添加位置信息。
- 段落嵌入(Segment Embeddings):标记句子A和句子B的不同。
- 多头注意力机制(Multi-head Attention):通过多个注意力头来捕捉不同的上下文信息。
- 前馈神经网络(Feed-forward Neural Networks):用于对注意力机制的输出进行进一步处理。
聚类
聚类(Clustering)是一种无监督学习方法,其目标是将数据集中的样本分成不同的组或簇(Clusters),使得同一簇内的样本彼此相似,而不同簇的样本之间差异较大。聚类技术广泛应用于数据挖掘、机器学习和统计分析中,用于探索数据的内在结构和模式。
定义
聚类是一种数据分析技术,它将数据集中的元素划分为若干个组或簇,使得每个簇内的数据点之间相似度较高,而簇间相似度较低。聚类属于无监督学习,因为聚类算法在执行时并不需要已知的标签信息。
聚类算法
常见的聚类算法包括但不限于:
- K-means:一种基于距离的聚类算法,将数据点划分到最近的簇中心所在的簇中。
- 层次聚类(Hierarchical Clustering):构建一个树状结构来表示数据点之间的关系,可以是凝聚型(Agglomerative)或分裂型(Divisive)。
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类算法,可以发现任意形状的簇,并能识别噪声点。
- 谱聚类(Spectral Clustering):利用图论中的谱方法进行聚类,适用于复杂的数据集。
- Mean Shift:一种基于密度的聚类算法,通过寻找数据点密度的峰值来确定簇的中心。
- Gaussian Mixture Models (GMM):基于概率分布的聚类方法,假设数据点服从高斯分布。
聚类的步骤
- 选择聚类算法:根据数据的特点和需求选择合适的聚类算法。
- 初始化:设置初始参数,如簇的数量(如果是K-means)。
- 迭代优化:不断地调整簇的边界或中心,直到达到某个停止条件(如收敛或达到最大迭代次数)。
- 评估聚类结果:使用适当的指标来评估聚类的质量,如轮廓系数(Silhouette Coefficient)、Calinski-Harabasz指数等。