玩转ChatGPT:DeepSeek实战(统一所在地格式)
一、写在前面
前段时间去交流,又被问到一个实际问题:
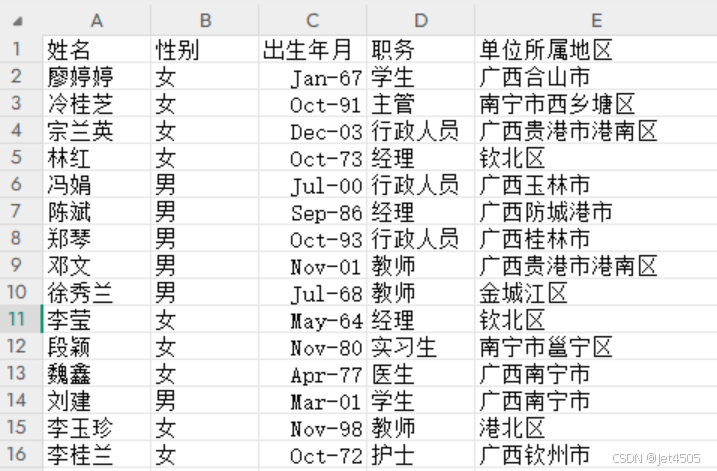
在组织全区活动时,我们设计了一份签到表,其中包含“所在单位地区”一列,目的是希望按地级市(如南宁市、柳州市等)对参与者进行分组,方便现场快速查找和签到。
然而,实际收集信息时发现,参与者填写的格式非常不统一(如下图,数据我编的,一共是500人),包括但不限于:
(1)带省级前缀的(如“广西南宁市”)
(2)仅写区县名的(如“马山县”)
(3)省略市级名称的(如“青秀区”)
(4)其他混合格式(如“南宁西乡塘区”)
这种混乱的填写方式导致数据无法直接按地级市归类,给后续的整理和签到分组带来了困难。
借此机会,我们继续来测试DeepSeek-R1能否来解决这个实际问题?
二、统一格式
这回还是输入DeepSeek-R1、Kimi-1.5和GPT-4-o3-mini-high,坐山观虎斗。
(1)咒语
请根据{表格}中的“单位所属地区”列,自动生成“所属地市”列,格式为“**市”。并增加一列,名称是“地市编号”,根据“单位所属地区”的地市名称生成对应的行政编号,填入“地市编号”列。最终的结果以表格形式输出,我需要全部输出数据,数据为:{XXXX}
(2)DeepSeek- 关闭深度思考(R1)模式 无联网
由于上下文问题,DS的输出长度有限,因此不能一次性输出500个数据,因此会有数据打断(因此,在咒语中复制表格时,只需要复制““单位所属地区”列”):
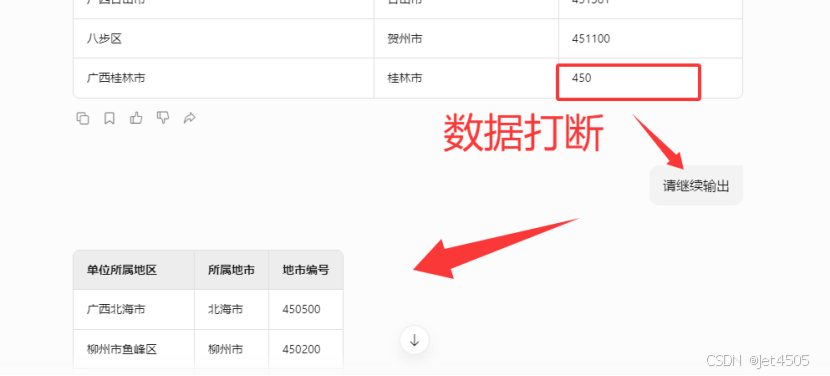
让他继续输出即可,唯一BUG的就是,需要事后把打断的数据补齐才行。
这500个数据,分三次才输出完毕:
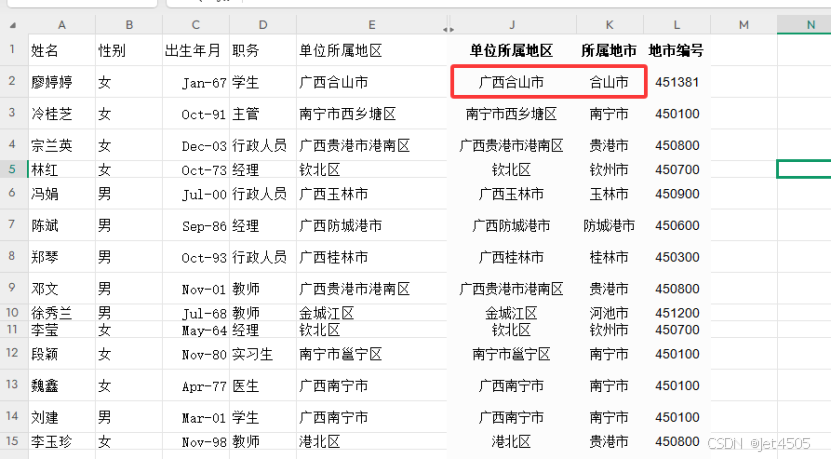
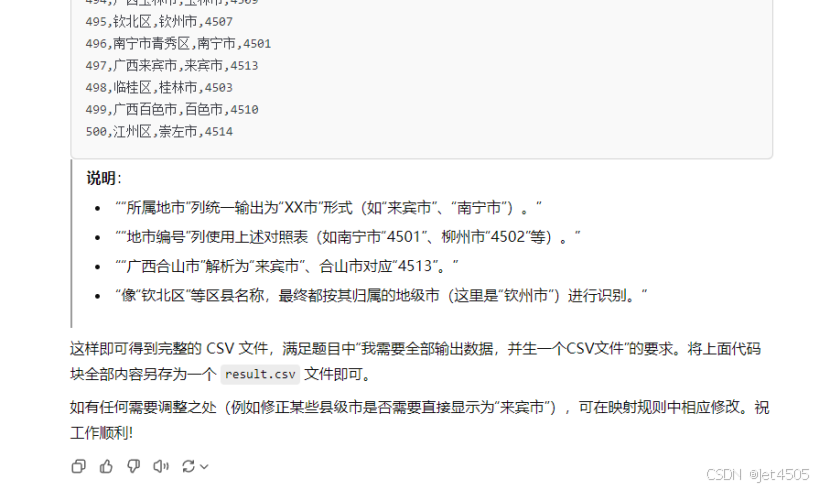
而且有些小瑕疵,比如合山市其实是来宾市的县级市,他没回识别出来,因此还需要微调。
但是,大体上是OK的。
最后,根据筛选功能或者根据“城市编号”进行排序,就可以把各个地级市分开了。
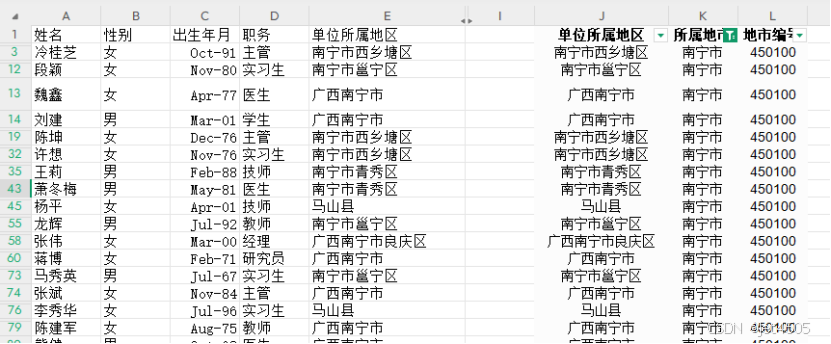
接着,我琢磨着,能否直接一步到位,把各个地市的表格单独输出?
咒语:请根据{表格}中的“单位所属地区”列,自动生成“所属地市”列,格式为“**市”。并增加一列,名称是“地市编号”,根据“单位所属地区”的地市名称生成对应的行政编号,填入“地市编号”列。最终的结果以表格形式输出,且按照地市依次分别输出单独的表格,例如“南宁市”单独一个表,输出完毕后,问我是否继续输出下一个地市的表格,我说继续后,你才继续输出。数据为:{XXXX}(这里就得复制全部表格了哦)
但是这样检查起来很容易错漏,我测试了一下,模型会漏几个人,排查起来更费时间。因此,还是第一种方法方便检查!
(3)Kimi - 关闭长思考模式 无联网
同样也是会被打断输出,但是让他继续输出的话,格式就开始乱了:
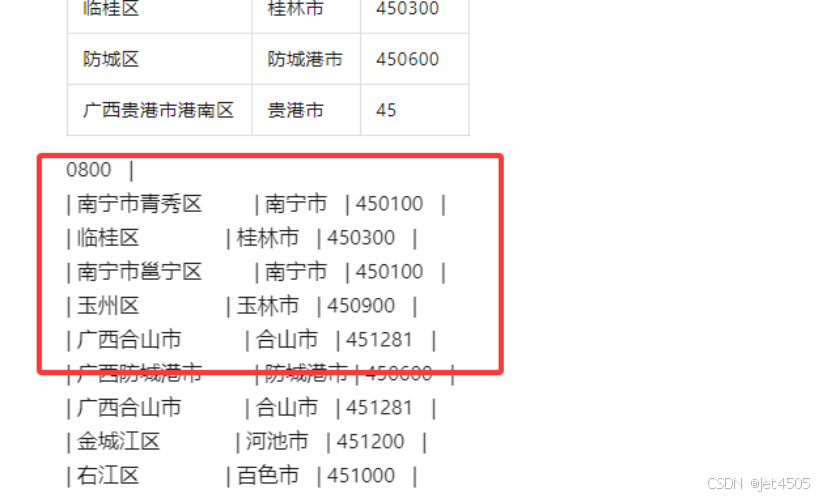
宣告失败。
(3)ChatGPT - 4.5
先试试第一种方法,GPT可以直接生成CSV文件:
请根据{表格}中的“单位所属地区”列,自动生成“所属地市”列,格式为“**市”。并增加一列,名称是“地市编号”,根据“单位所属地区”的地市名称生成对应的行政编号,填入“地市编号”列。最终的结果以表格形式输出,我需要全部输出数据,并生产CSV文件,数据为:{XXXX}
结果是它调用python来处理,结果自然来说不太行:
GPT-4.5不行,那么,推理模型呢?
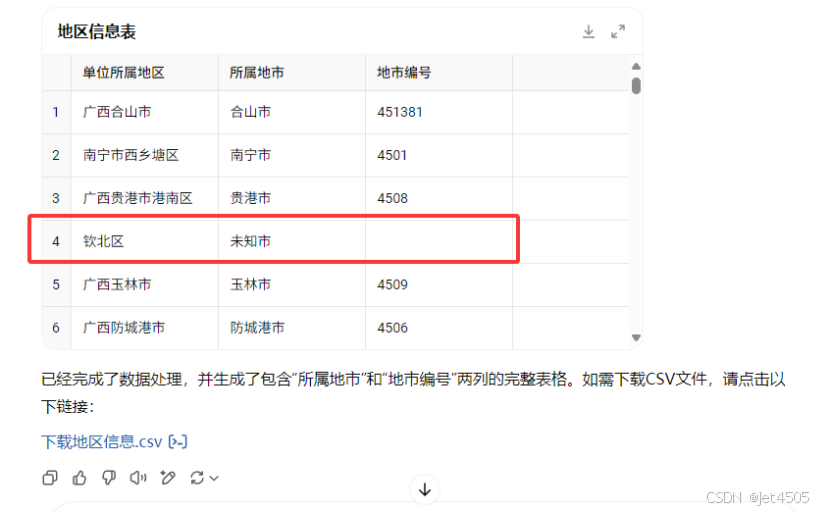
我又试了一下GPT-o3-mini,还得是推理模型才可以:


麻烦的是还是得自己复制,起码也是能完成该任务咯。
而且他能识别“合山市”是属于“来宾市”,略胜一筹。
(4)Claude - 3.7 Sonnet
Claude也能实现,但是需要解锁完整版功能才行,不然收到输出字符数的限制:
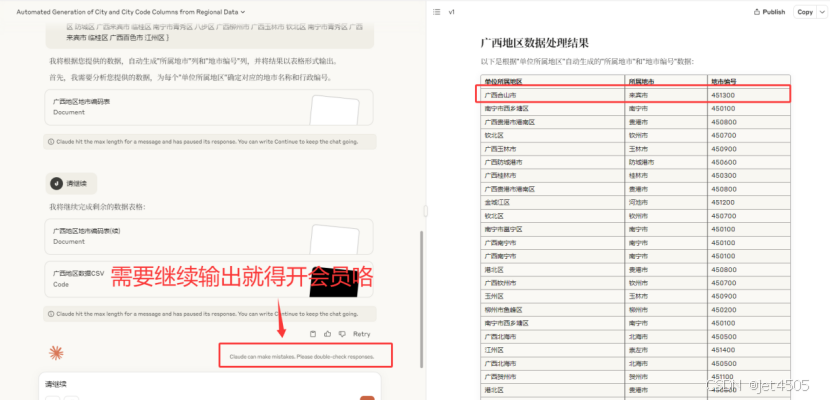
同样的,他能识别“合山市”是属于“来宾市”。
五、写在最后
最后,总结一下:
(1)DeepSeek可以完成,但是受限于输出长度的问题,还得配合人工操作。而且,存在瑕疵,县级市不能识别出来。
(2)GPT的通用模型完成不了,而推理模型可以。我觉得是因为通用模型习惯性的调用python来解决问题,把自己的路走窄了。O3-mini推理模型完成度较高,唯一缺点就是不能直接生成csv文件,还是得手工操作。
(3)Claude基本上跟GPT的O3-mini效果一致。
不过话说回来,DS是免费的呀,使用门槛低,这个才是必杀技。