提示工程实战指南:Google白皮书关键内容一文讲清
You don’t need to be a data scientist or a machine learning engineer – everyone can writea prompt.
一、概述
Google于2025年2月发布的《Prompt Engineering》白皮书系统阐述了提示工程的核心技术、实践方法及挑战应对策略。该文档由Lee Boonstra主编,多位Google工程师与研究人员参与编写,旨在为开发者提供可操作的提示设计框架。文档内容涵盖提示工程基础理论、主流提示技术(如零样本/少样本提示、思维链、自洽性、思维树等)、输出参数配置(温度、Top-K、Top-P等)、最佳实践及生成式AI的局限性分析。文档强调通过结构化迭代、自动化工具与跨团队协作提升提示工程效率,并提供了多场景应用案例。
二、提示工程基础
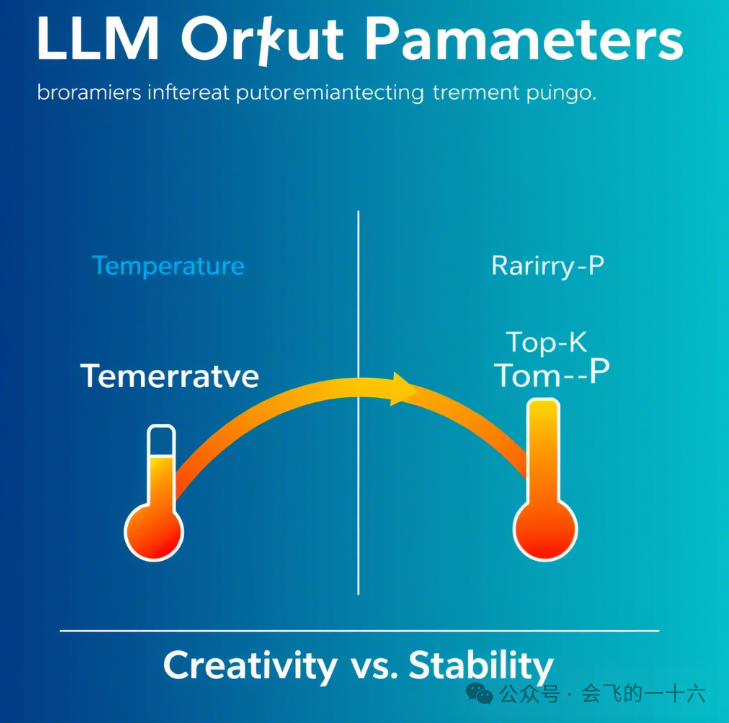
1. LLM输出配置参数
-
输出长度:控制生成文本的token数量,需根据任务需求平衡信息完整性和效率。例如,摘要任务可能需要较短输出,而复杂推理需更长文本。
-
采样控制:
-
温度(Temperature):值越低(如0.1),输出越确定性;值越高(如1.0),输出更随机。推荐对需要稳定结果的任务(如代码生成)设为0。
-
Top-K与Top-P:Top-K从概率最高的K个token中采样,Top-P(核采样)则累积概率超过P时停止。两者结合可平衡多样性与相关性。
-
-
注意事项:过高自由度可能导致冗余或“重复循环”问题(如生成重复短语)。需通过实验调整参数。
2. 提示设计原则
-
简洁性:避免复杂语言与冗余信息。例如,将“我带两个3岁孩子去纽约度假,想找适合的地方”简化为“为带3岁儿童的游客推荐纽约曼哈顿景点”。
-
明确指令:使用动词引导(如“分类”“生成”“总结”),指定输出格式(如JSON、列表)。
-
避免约束:优先使用正向指令(如“仅讨论以下内容”)而非负面限制(如“不要涉及X”)。
三、核心提示技术
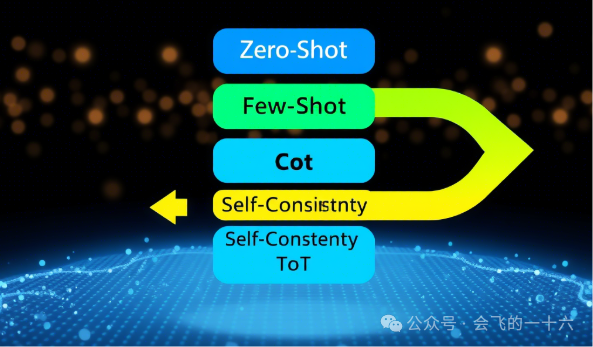
1. 零样本与少样本提示(Zero-Shot/Few-Shot Prompting)
-
零样本:直接请求任务,无需示例。例如:“将电影评论分类为正面、中性或负面。”
-
少样本:通过少量示例引导模型。例如:
输入:评论1: “这部电影太棒了!” → 正面 输入:评论2: “剧情拖沓,演员表现平庸。” → 负面 输入:新评论: “导演手法独特,但节奏过慢。” → ?
-
优化策略:分类任务中混合不同类别示例,避免模型偏好单一标签。
2. 系统提示与角色提示(System/Role Prompting)
-
系统提示:定义模型行为边界(如伦理准则、专业领域限制)。
-
角色提示:赋予模型特定身份(如医生、历史学家),影响其输出风格。例如:“作为营养师,请分析该食谱的健康价值。”
3. 上下文提示(Contextual Prompting)
-
步骤回退(Step-Back Prompting):先抽象问题再深入细节。例如,解决数学题时先要求总结解题思路。
-
思维链(Chain of Thought, CoT):强制模型分步推理后给出答案。例如:
问题:小明有5个苹果,吃掉2个后又买了3个,现在有多少? 推理:初始5个→吃掉2→剩3→买3→共6个。 答案:6。
-
CoT最佳实践:设置温度为0以确保推理路径稳定;需能从输出中提取独立答案。
-
-
自洽性(Self-Consistency):生成多组推理路径,取最一致的答案。例如,多次询问同一问题,汇总结果以提高准确性。
-
思维树(Tree of Thoughts, ToT):允许模型探索多条推理路径并评估最优解,适用于复杂决策(如创意写作或战略规划)。
4. ReAct提示(Reasoning + Acting)
结合推理(Reasoning)与行动(Acting),用于交互式任务(如网页导航或游戏策略)。例如:
推理:需要购买咖啡豆→行动:搜索“有机咖啡豆”→推理:选择评分最高产品→行动:加入购物车。
四、提示工程实践方法
1. 文档化与迭代管理
-
模板化记录:使用表格追踪提示版本、参数、输出结果及反馈(表1)。例如:
版本 提示内容 输出 反馈 v1.0 分类电影评论 POSITIVE 准确 v1.1 同上+要求JSON输出 {"sentiment": "POSITIVE"} 格式正确 -
工具支持:在Vertex AI Studio中保存提示并记录链接,便于复用与复现。
2. 自动化与代码生成
-
代码转换:利用LLM将Bash脚本转为Python应用,提升可维护性。
-
调试辅助:通过提示请求模型修复代码错误),如识别未定义函数问题。
3. 检索增强生成(RAG)集成
-
动态内容插入:在提示中嵌入检索结果(如知识库片段),需记录检索参数(查询词、分块策略)以分析影响。
五、挑战与应对策略
1. 生成质量控制
-
常见问题:
-
重复循环:因参数设置不当导致冗余输出。
-
无关响应:自由度过高使生成偏离任务目标。
-
-
解决方案:严格调参(如降低温度)、强化指令明确性。
2. 模型更新适配
-
迭代测试:模型版本升级后需重新验证提示效果,如分类任务准确率变化。
3. 安全与偏见缓解
-
系统提示限制:通过规则过滤有害内容(如仇恨言论、虚假信息)。
六、最佳实践
-
提供示例:少样本提示中示例需覆盖多样场景。
-
简化设计:避免复杂句式,直接指定任务目标。
-
输出结构化:要求JSON、XML等格式以利后续处理。
-
参数实验:对比不同温度、Top-K组合的效果差异。
-
跨团队协作:多工程师并行设计提示,通过A/B测试筛选最优方案。
-
CoT专项优化:确保推理与答案分离,便于自洽性验证。
七、实战案例
适合复杂任务的处理,帮助用户逐步推理、系统地拆解任务,以获得准确的输出
-
明确意图:确保你清楚地表达任务的核心目标,传达最重要的信息
-
提供上下文:提供必要的背景信息和任务相关的背景说明
-
限制输出范围:给模型设定边界,确保生成的内容和指令紧密相关
-
分解任务:将复杂的任务拆解成多个小任务,使其更易执行
-
逐步思考:对于复杂的任务,引导模型按步骤执行,逐步进行推理

Web应用漏洞分析案例
-
明确意图
-
分析目标Web应用是否存在反射型跨站脚本漏洞,并给出修复建议
-
-
提供上下文
-
目标Web应用为企业内部使用的金融管理系统,包含多个用户输入点,登录页面存在潜在安全风险
-
-
限制输出范围
-
仅分析登录模块,不涉及其他功能模块
-
-
分解任务
-
第一步:检查登录页面是否有未过滤的用户输入;第二步:模拟常见的跨站脚本攻击,验证是否存在漏洞;第三步:给出修复建议,如输入验证和编码处理
-
-
逐步思考
-
请从登录模块的输入点开始,逐步分析,确保每一步的推理逻辑清晰
-
七、结论
Google的提示工程框架强调系统化、数据驱动的方法,通过技术组合(如CoT+自洽性)与流程管理(如文档化迭代)最大化LLM效能。文档提供的模板、代码案例及参数指南为从业者提供了可直接应用的工具。
Google强调,提示工程并非一劳永逸的技巧,而是一个动态迭代的过程。随着模型能力的进化,提示设计也需持续优化。未来,随着模型能力的演进,提示工程将继续在生成式AI应用中扮演核心角色,推动从任务自动化到复杂决策支持的广泛落地。
参考资料:Google《Prompt Engineering_V7》白皮书(2025年2月版)
需要书籍的评论区留言:Prompt Engineering
往期精彩
SQL 筛选优化 | LEFT SEMI JOIN 与 LEFT ANTI JOIN 高效数据筛选的利器
数据治理路径之辩:从“先治后用”到“边用边治”,企业如何选择最优路径?
HiveSQL 专家级技巧:如何将增量表的变更优雅的合并到全量表中?
王炸vs某互联网公司:数仓中什么情况下需要进行数据回溯?需要注意什么?
闭坑记录:Hive中ROW_NUMBER()排序不稳定性分析与解决方案
面试提问:你设计的模型是通用的吗?如何量化?| 通用模型 vs 自定义模型