《Python星球日记》 第64天:NLP 概述与文本预处理
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、NLP 简介
- 1. 什么是自然语言处理?
- NLP 的应用场景:
- 2. 文本数据的特点与挑战
- 二、文本预处理
- 1. 分词
- 2. 去停用词
- 3. 词干提取与词形还原
- 4. 特殊符号处理与正则表达式
- 三、工具库介绍
- 1. NLTK (Natural Language Toolkit)
- 2. spaCy
- 3. jieba(中文分词)
- 四、代码练习:文本预处理实战
- 1. 英文文本预处理
- 2. 中文文本预处理
- 3. 结合spaCy的高级预处理
- 五、小结与拓展
- 拓展学习方向
- 练习建议
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第63天:文本方向综合项目(新闻分类)
大家好,欢迎来到Python星球的第64天!🪐
一、NLP 简介
1. 什么是自然语言处理?
自然语言处理(Natural Language Processing,简称 NLP)是人工智能和计算语言学的交叉学科,致力于让计算机理解、解释和生成人类语言。简单来说,NLP 就是让计算机能够"读懂"和"说出"人类语言的技术。
想象一下,当你对手机说"今天天气怎么样",手机能回答你今天天气情况并给出建议;当你用中文写一段话,计算机能将其翻译成英文;当你发一条评论,系统能判断你的情感倾向——这些都是 NLP 的应用。
NLP 的应用场景:
- 机器翻译:将一种语言自动翻译成另一种语言(如 Google 翻译)
- 情感分析:判断文本表达的情感倾向(如社交媒体舆情监测)
- 问答系统:自动回答用户提出的问题(如 Siri、小度、ChatGPT)
- 文本摘要:自动生成长文本的简短摘要
- 语音识别:将语音转换为文本
- 文本生成:根据给定提示生成连贯文本
- 命名实体识别:识别文本中的人名、地名、组织名等专有名词

2. 文本数据的特点与挑战
处理文本数据与处理数值数据有很大不同,它具有以下特点与挑战:
- 非结构化:文本数据通常没有预定义的格式或结构
- 歧义性:同一句话可能有多种解释(“我看见河里的鳄鱼吃掉了一条船”——是谁吃了船?)
- 上下文依赖:词语含义依赖于上下文("苹果"可以是水果也可以是科技公司)
- 语言多样性:全球有数千种语言,每种都有其独特规则和结构
- 文化背景:理解需要文化背景知识(如俚语、谚语、文化典故)
- 噪声问题:网络文本常包含错别字、缩写和不规范表达
- 稀疏性:特征空间巨大但大多数特征在特定文本中不出现
处理这些挑战,我们需要一系列预处理技术来将原始文本转化为计算机可以理解和分析的形式。
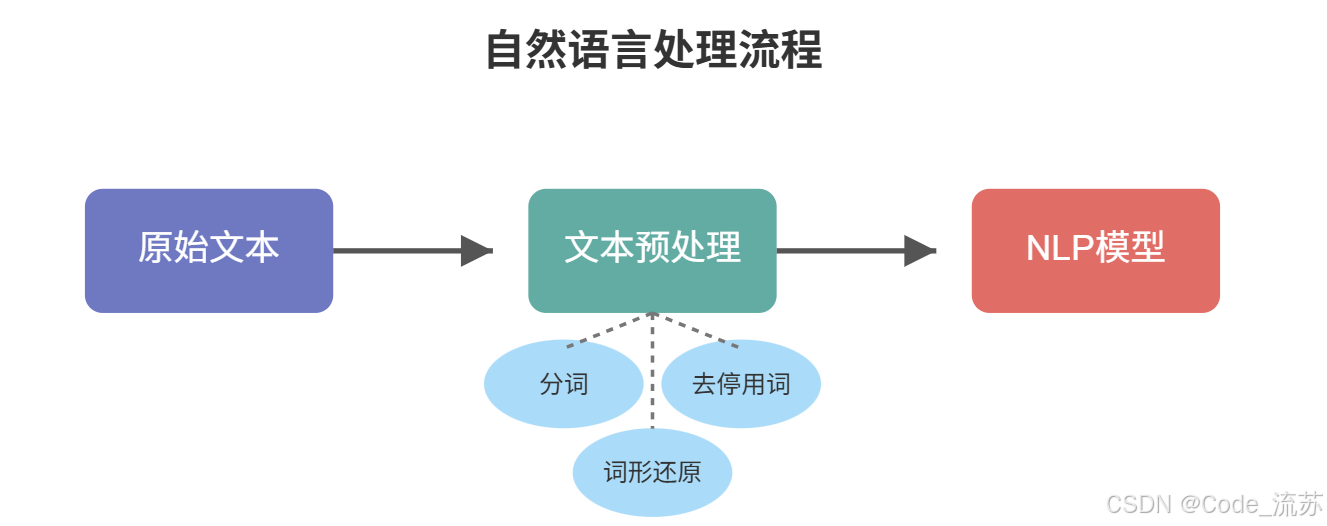
二、文本预处理
文本预处理是 NLP 任务的基础环节,它将原始文本转换为机器可以有效处理的形式。这一步做得好坏,直接影响后续分析的质量。
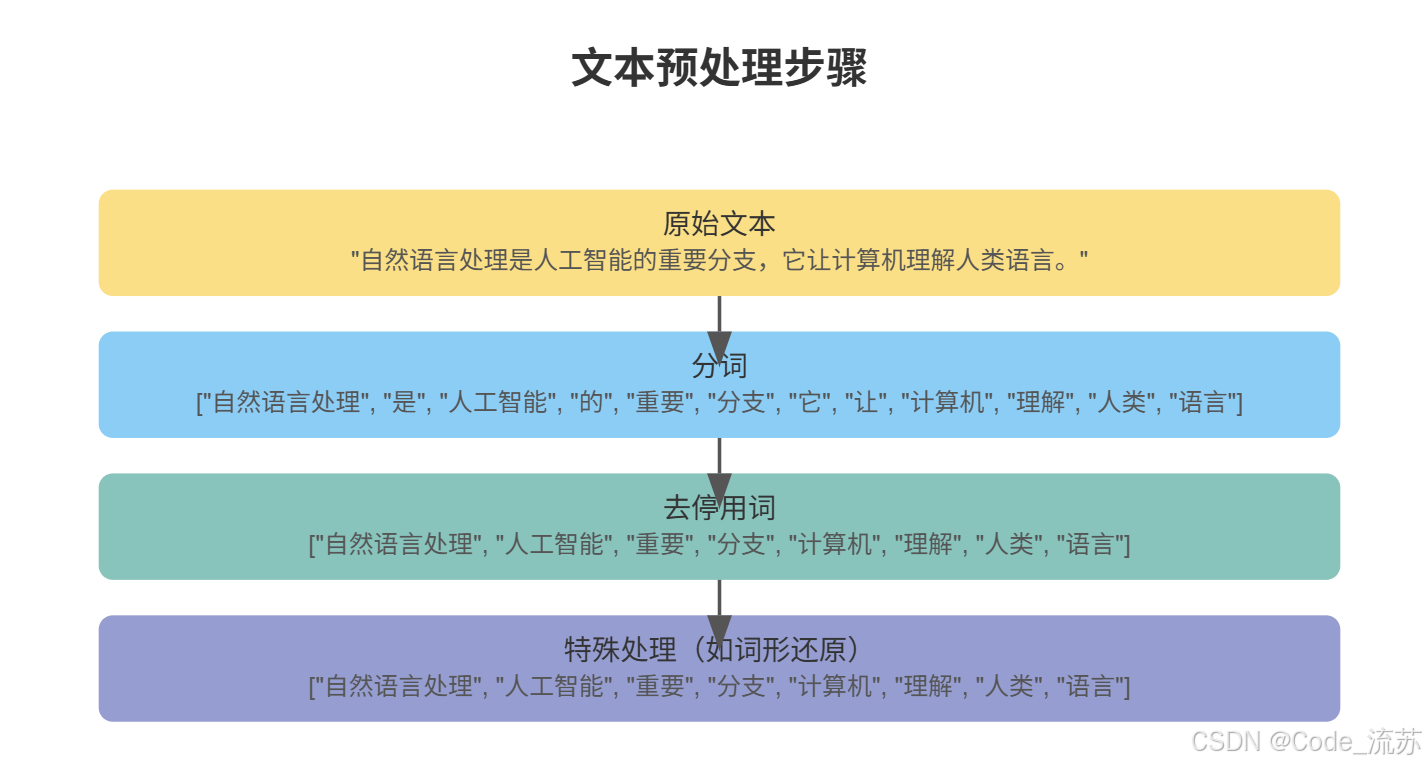
1. 分词
分词(Tokenization)是将文本分割成基本单位(词语、字符或子词)的过程。这看似简单,实际上因语言而异,难度各不相同。
-
英文分词:英文通常以空格和标点为界,相对简单
# 英文分词示例 sentence = "I love natural language processing!" tokens = sentence.split() # 简单方法 print(tokens) # ['I', 'love', 'natural', 'language', 'processing!'] -
中文分词:中文没有明显的词语边界,分词更具挑战性
# 中文分词需要专门的工具 import jieba sentence = "我爱自然语言处理" tokens = jieba.cut(sentence) print(list(tokens)) # ['我', '爱', '自然语言', '处理']
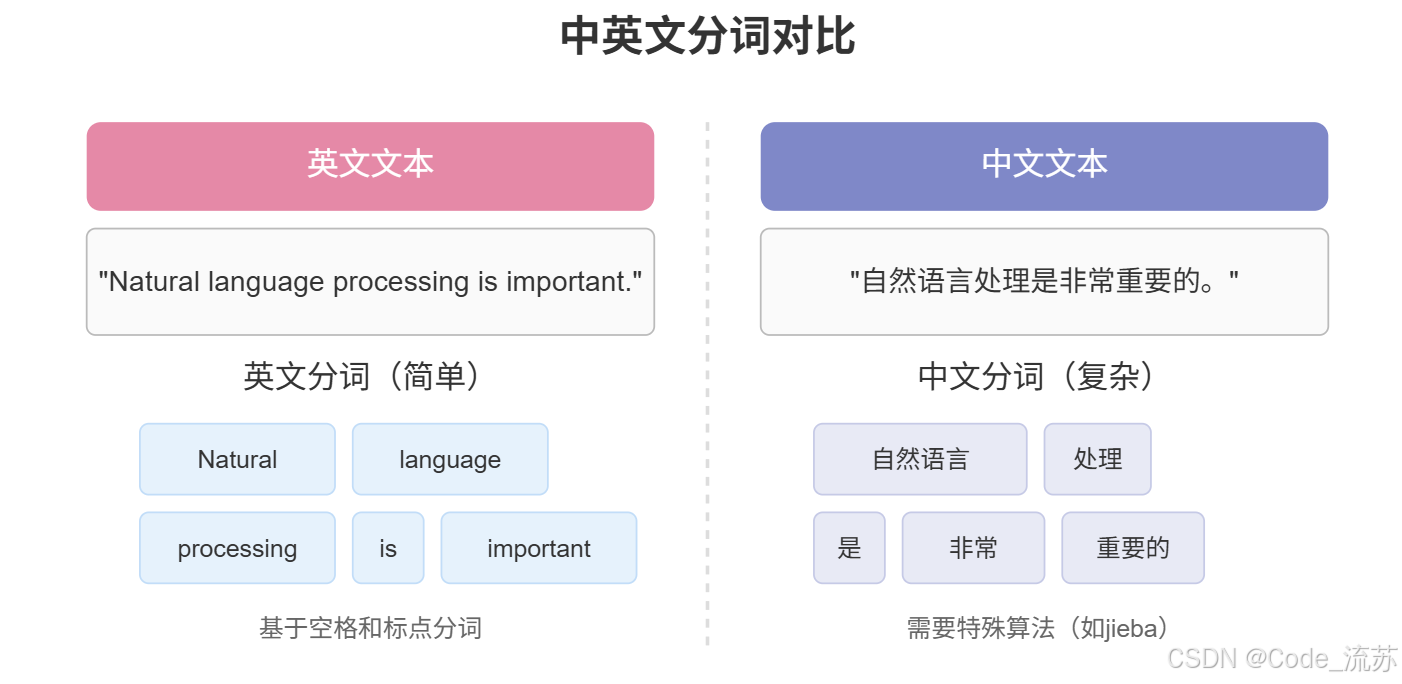
不同的分词方法会影响后续处理的效果。例如,将"自然语言处理"分为"自然/语言/处理"或"自然语言/处理"会带来不同的语义理解。
2. 去停用词
停用词(Stop Words)是在文本中频繁出现但对分析意义不大的词,如"的"、“是”、“在”(中文)或"the"、“is”、“and”(英文)。去除这些词可以减少噪声,提高分析效率。
# 英文去停用词示例
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenizesentence = "The quick brown fox jumps over the lazy dog"
tokens = word_tokenize(sentence.lower())
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word not in stop_words]
print(filtered_tokens) # ['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog']
3. 词干提取与词形还原
英文单词有各种变化形式(如动词时态、名词单复数),为了统一分析,我们需要将它们还原为基本形式。
-
词干提取(Stemming):通过删除词缀来获得词根,算法简单但可能产生非词汇单词
# 词干提取示例 from nltk.stem import PorterStemmerstemmer = PorterStemmer() words = ["jumping", "jumps", "jumped", "runner", "running"] stemmed = [stemmer.stem(word) for word in words] print(stemmed) # ['jump', 'jump', 'jump', 'runner', 'run'] -
词形还原(Lemmatization):将单词还原为其词典形式(词元),考虑语法规则,结果更准确
# 词形还原示例 from nltk.stem import WordNetLemmatizerlemmatizer = WordNetLemmatizer() words = ["better", "running", "ate", "children"] lemmatized = [lemmatizer.lemmatize(word) for word in words] print(lemmatized) # ['better', 'running', 'ate', 'child']# 指定词性可提高准确率 print(lemmatizer.lemmatize("better", pos='a')) # good print(lemmatizer.lemmatize("running", pos='v')) # run print(lemmatizer.lemmatize("ate", pos='v')) # eat
4. 特殊符号处理与正则表达式
文本中常包含各种特殊符号、HTML标签、URL等,这些通常需要清理。正则表达式是处理这类问题的强大工具。
# 使用正则表达式清理文本
import retext = "Please visit https://www.example.com! #NLP #Python"# 移除URL
text_no_url = re.sub(r'https?://\S+', '', text)
print(text_no_url) # "Please visit ! #NLP #Python"# 移除标点符号
text_no_punct = re.sub(r'[^\w\s]', '', text)
print(text_no_punct) # "Please visit httpswwwexamplecom NLP Python"# 移除数字
text_no_digits = re.sub(r'\d+', '', text)
print(text_no_digits) # "Please visit https://www.example.com! #NLP #Python"
常用的正则表达式模式:
\w- 匹配字母、数字、下划线\s- 匹配空白字符\d- 匹配数字[...]- 匹配方括号内的任意字符^- 在方括号内表示"非"+- 匹配前面的字符一次或多次*- 匹配前面的字符零次或多次

三、工具库介绍
在NLP实践中,我们不需要从零开始实现所有预处理功能,可以借助强大的工具库。下面介绍三个常用的NLP工具库:
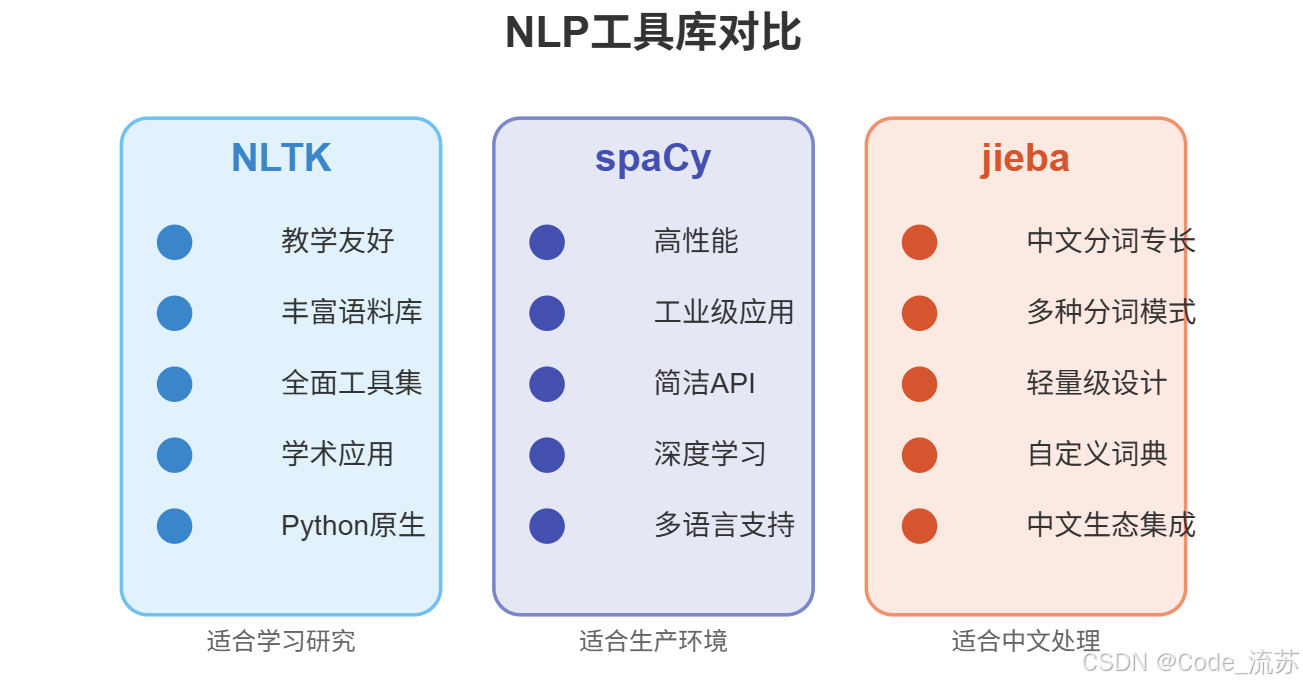
1. NLTK (Natural Language Toolkit)
NLTK是Python中最经典的NLP库,提供了丰富的语料库和预处理工具,特别适合教学和研究。
主要功能:
- 分词、词干提取、词形还原
- 词性标注、解析树
- 强大的语料库资源
- 情感分析、文本分类工具
# NLTK基本使用示例
import nltk
# 首次使用需下载资源
# nltk.download('punkt')
# nltk.download('stopwords')
# nltk.download('wordnet')from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizertext = "Natural language processing helps computers communicate with humans!"# 分词
tokens = word_tokenize(text)
print("分词结果:", tokens)# 去停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
print("去停用词后:", filtered_tokens)# 词形还原
lemmatizer = WordNetLemmatizer()
lemmatized = [lemmatizer.lemmatize(word) for word in filtered_tokens]
print("词形还原后:", lemmatized)
2. spaCy
spaCy是一个现代化、高性能的NLP库,专为生产环境设计,处理速度快,API简洁。
主要功能:
- 高效的分词和语法分析
- 命名实体识别
- 词向量支持
- 多语言支持
- 易于集成的管道处理
# spaCy基本使用示例
import spacy# 加载英文模型(首次使用需下载:python -m spacy download en_core_web_sm)
nlp = spacy.load('en_core_web_sm')text = "Apple is looking at buying U.K. startup for $1 billion"
doc = nlp(text)# 分词和词性标注
for token in doc:print(f"{token.text}: {token.pos_} ({token.pos})")# 命名实体识别
print("\n命名实体:")
for ent in doc.ents:print(f"{ent.text}: {ent.label_}")
3. jieba(中文分词)
jieba是处理中文文本的首选工具,提供了精确、全模式和搜索引擎模式三种分词模式。
主要功能:
- 中文分词
- 关键词提取
- 词性标注
- 支持自定义词典
# jieba基本使用示例
import jieba
import jieba.posseg as psegtext = "我爱北京天安门,天安门上太阳升"# 精确模式分词
seg_list = jieba.cut(text, cut_all=False)
print("精确模式:", "/".join(seg_list))# 全模式分词
seg_list = jieba.cut(text, cut_all=True)
print("全模式:", "/".join(seg_list))# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
print("搜索引擎模式:", "/".join(seg_list))# 词性标注
words = pseg.cut(text)
for word, flag in words:print(f"{word}: {flag}")
四、代码练习:文本预处理实战
让我们通过一个完整的实例,将前面学习的内容应用到实践中,分别处理英文和中文文本。
1. 英文文本预处理
下面是一个英文文本预处理的完整示例,包含了分词、去停用词、词形还原和简单的数据分析:
import nltk
import re
import matplotlib.pyplot as plt
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from collections import Counter# 确保下载必要的NLTK资源
# nltk.download('punkt')
# nltk.download('stopwords')
# nltk.download('wordnet')def preprocess_english_text(text):"""对英文文本进行预处理"""# 转为小写text = text.lower()# 清理特殊字符和数字text = re.sub(r'[^a-zA-Z\s]', '', text)# 分词tokens = word_tokenize(text)# 去停用词stop_words = set(stopwords.words('english'))filtered_tokens = [word for word in tokens if word not in stop_words]# 词形还原lemmatizer = WordNetLemmatizer()lemmatized = [lemmatizer.lemmatize(word) for word in filtered_tokens]return lemmatized# 示例英文文本
english_text = """
Natural Language Processing (NLP) is a field of artificial intelligence that focuses on the interaction
between computers and humans through natural language. The ultimate objective of NLP is to read,
decipher, understand, and make sense of human languages in a valuable way. NLP combines computational
linguistics—rule-based modeling of human language—with statistical, machine learning, and deep learning models.
"""# 应用预处理
processed_tokens = preprocess_english_text(english_text)
print("处理后的标记:", processed_tokens[:20])# 统计词频
word_freq = Counter(processed_tokens)
print("\n最常见的10个词:")
for word, count in word_freq.most_common(10):print(f"{word}: {count}")# 可视化词频(如果在Jupyter Notebook中运行)
plt.figure(figsize=(10, 6))
common_words = [word for word, count in word_freq.most_common(10)]
word_counts = [count for word, count in word_freq.most_common(10)]
plt.bar(common_words, word_counts)
plt.title('最常见的10个词')
plt.xlabel('词语')
plt.ylabel('频率')
plt.xticks(rotation=45)
plt.tight_layout()
# plt.show() # 在Jupyter中取消注释
2. 中文文本预处理
下面是一个中文文本预处理的示例,使用jieba分词库:
import jieba
import re
from collections import Counter
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef preprocess_chinese_text(text):"""对中文文本进行预处理"""# 清理特殊字符text = re.sub(r'[^\u4e00-\u9fa5]', '', text) # 仅保留中文字符# 分词seg_list = jieba.cut(text, cut_all=False)# 去停用词 (这里使用一个简单的停用词列表示例)stop_words = {'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这'}filtered_tokens = [word for word in seg_list if word not in stop_words and len(word) > 1] # 过滤单字词return filtered_tokens# 示例中文文本
chinese_text = """
自然语言处理(NLP)是计算机科学、人工智能和语言学的交叉学科,致力于使计算机能够理解、处理和生成人类语言。
NLP技术被广泛应用于机器翻译、情感分析、智能客服、文本摘要等领域。随着深度学习的发展,自然语言处理技术取得了
巨大进步,特别是预训练模型如BERT和GPT的出现,使计算机对人类语言的理解能力大幅提升。
"""# 应用预处理
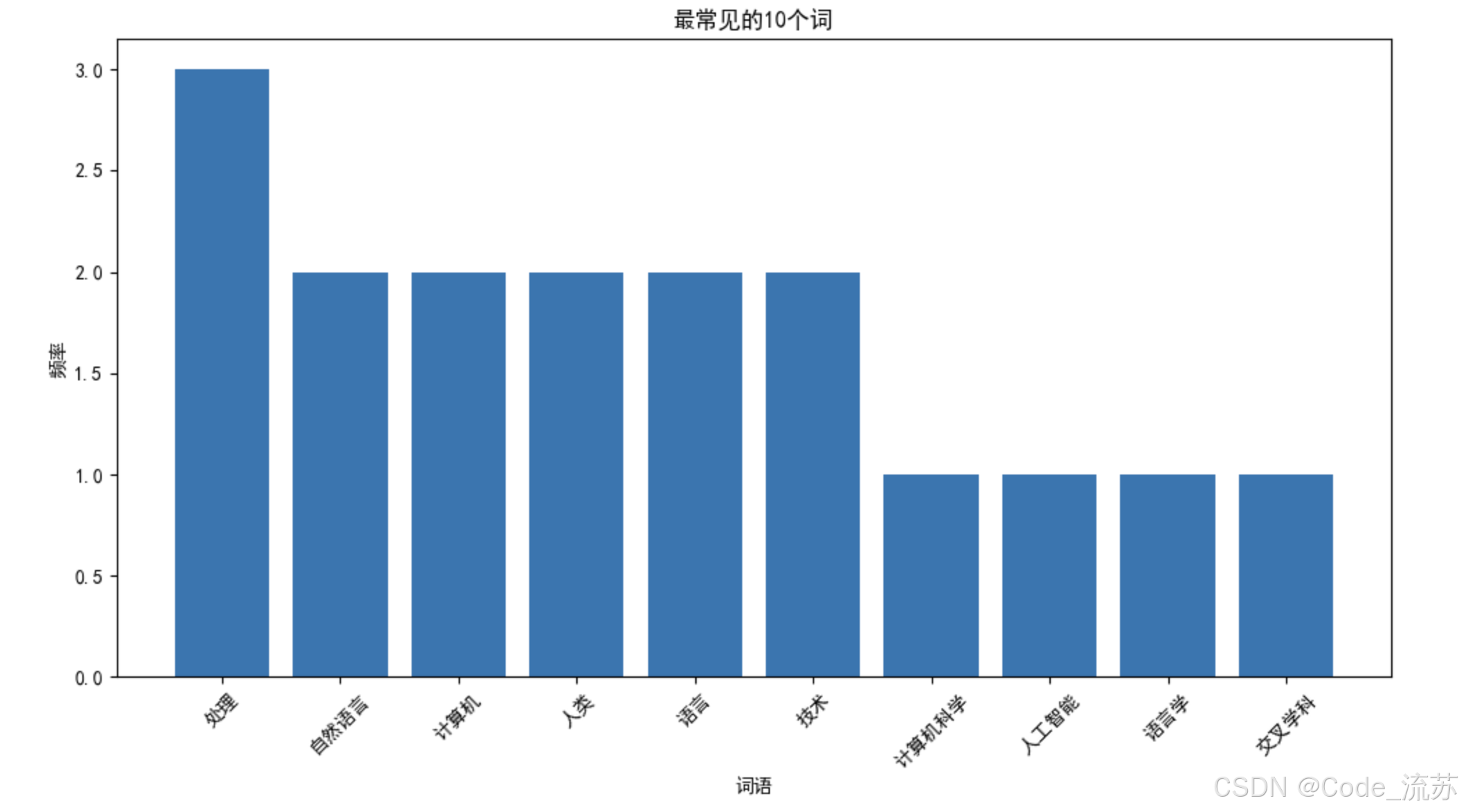
processed_tokens = preprocess_chinese_text(chinese_text)
print("处理后的标记:", processed_tokens)# 统计词频
word_freq = Counter(processed_tokens)
print("\n最常见的10个词:")
for word, count in word_freq.most_common(10):print(f"{word}: {count}")# 可视化词频
plt.figure(figsize=(10, 6))
common_words = [word for word, count in word_freq.most_common(10)]
word_counts = [count for word, count in word_freq.most_common(10)]
plt.bar(common_words, word_counts)
plt.title('最常见的10个词')
plt.xlabel('词语')
plt.ylabel('频率')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()

3. 结合spaCy的高级预处理
spaCy提供了更强大的预处理能力,特别是在命名实体识别和句法分析方面:
import spacy
from collections import Counter
import matplotlib.pyplot as plt# 加载spaCy英文模型
# 首次使用需下载模型:python -m spacy download en_core_web_sm
nlp = spacy.load('en_core_web_sm')def preprocess_with_spacy(text):"""使用spaCy进行文本预处理"""doc = nlp(text)# 提取词语(去除停用词和标点符号)tokens = [token.lemma_ for token in doc if not token.is_stop and not token.is_punct]# 提取命名实体entities = [(ent.text, ent.label_) for ent in doc.ents]# 提取名词短语noun_phrases = [chunk.text for chunk in doc.noun_chunks]return {'tokens': tokens,'entities': entities,'noun_phrases': noun_phrases}# 示例文本
text = """
Google and Microsoft are investing billions in AI research. The CEO of OpenAI, Sam Altman,
announced a new partnership with Apple in San Francisco last week. Natural language processing
technology is transforming how we interact with computers.
"""# 应用spaCy预处理
results = preprocess_with_spacy(text)# 打印结果
print("词语:", results['tokens'])
print("\n命名实体:")
for entity, label in results['entities']:print(f"{entity}: {label}")
print("\n名词短语:", results['noun_phrases'])# 分析依存关系(可以帮助理解句法结构)
doc = nlp(text)
print("\n依存关系分析:")
for token in list(doc)[:10]: # 仅显示前10个词的依存关系print(f"{token.text} --({token.dep_})--> {token.head.text}")
五、小结与拓展
今天我们学习了自然语言处理的基础概念和文本预处理技术,包括分词、去停用词、词干提取、词形还原以及特殊符号处理等。我们还介绍了三个常用的NLP工具库:NLTK、spaCy和jieba,并通过代码示例展示了如何处理英文和中文文本。
文本预处理只是NLP的第一步,但它是至关重要的一步。高质量的预处理可以显著提升后续NLP任务的性能。在实际应用中,预处理步骤通常需要根据具体任务和数据特点进行调整。
拓展学习方向
如果你对NLP感兴趣,可以继续探索以下方向:
- 文本特征提取:TF-IDF、词袋模型、N-gram等
- 词向量:Word2Vec、GloVe、FastText等词嵌入技术
- 深度学习在NLP中的应用:RNN、LSTM、Transformer架构等
- 预训练语言模型:BERT、GPT、ERNIE等模型的使用与微调
- 应用实践:情感分析、文本分类、命名实体识别等具体任务
练习建议
- 尝试对自己收集的英文或中文文本进行预处理,观察不同预处理步骤的效果
- 比较NLTK、spaCy和jieba在处理相同任务时的表现差异
- 将预处理后的文本用于简单的NLP任务,如文本分类或情感分析
- 尝试使用正则表达式解决实际文本清洗问题,如提取电子邮件、清理HTML标签等
随着学习的深入,你会发现NLP是一个既广阔又深邃的领域,今天所学的预处理技术是你探索这个领域的重要基石。继续前进,下一步我们将学习如何从预处理后的文本中提取有意义的特征,并应用于更高级的NLP任务中。
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!