Python爬虫第20节-使用 Selenium 爬取小米商城空调商品
目录
前言
一、 本文目标
二、环境准备
2.1 安装依赖
2.2 配置 ChromeDriver
三、小米商城页面结构分析
3.1 商品列表结构
3.2 分页结构
四、Selenium 自动化爬虫实现
4.1 脚本整体结构
4.2 代码实现
五、关键技术详解
5.1 Selenium 启动与配置
5.2 页面等待与异步加载
5.3 商品数据解析
5.4 分页处理
5.5 异常处理
5.6 可选:保存到 MongoDB
六、Headless 模式与浏览器兼容
七、常见问题与优化建议
7.1 反爬机制
7.2 页面结构变动
7.3 数据完整性
7.4 性能优化
八、总结

🎬 攻城狮7号:个人主页
🔥 个人专栏: 《python爬虫教程》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Selenium 的实战
📚 本期文章收录在《python爬虫教程》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在实际数据采集和电商分析中,很多网站采用了前端渲染和复杂的 Ajax 请求,直接分析接口变得困难。小米商城就是这样一个典型案例。与淘宝类似,小米商城的商品列表和分页都依赖于前端 JavaScript 动态渲染,Ajax 接口参数复杂且可能包含加密校验。对于这种页面,最直接、最稳定的抓取方式就是使用 Selenium 模拟真实用户操作。
本篇文章将以"空调"为例,详细讲解如何用 Selenium 自动化爬取小米商城的空调商品信息,包括商品名称、价格、图片链接、商品详情链接等,并实现自动翻页抓取。文章内容涵盖环境准备、页面结构分析、Selenium 脚本编写、数据解析、翻页处理、异常处理、可选的 MongoDB 存储、Headless 模式、常见问题与优化建议等,帮助你系统掌握电商前端动态页面的爬取方法。
一、 本文目标
- 利用 Selenium 自动化爬取小米商城空调商品信息
- 用 PyQuery 解析商品名称、价格、图片、链接等数据
- 实现自动翻页抓取多页商品
- 可选:将数据保存到 MongoDB
- 兼容 Headless(无界面)模式
- 具备异常处理和反爬优化思路
二、环境准备
2.1 安装依赖
- Chrome 浏览器(建议最新版)
- ChromeDriver(版本需与 Chrome 主版本一致)
- Python 3.7+
- Selenium
- PyQuery
- (可选)MongoDB
安装 Python 依赖:
pip install selenium pyquery# 可选:pip install pymongoChromeDriver 下载地址:( https://googlechromelabs.github.io/chrome-for-testing/ )
注意: ChromeDriver 版本必须和 Chrome 浏览器主版本号一致,否则 Selenium 启动会报错。
2.2 配置 ChromeDriver
- 将 chromedriver.exe 放到 PATH 路径下,或在代码中指定其绝对路径。
- 建议用 ChromeDriver 的"可分离"模式,便于调试。
三、小米商城页面结构分析
以( https://www.mi.com/shop/search?keyword=空调 ) 为例,打开开发者工具,分析商品列表和分页结构。
3.1 商品列表结构
点击网页元素,按鼠标右键的检查项,快速定位
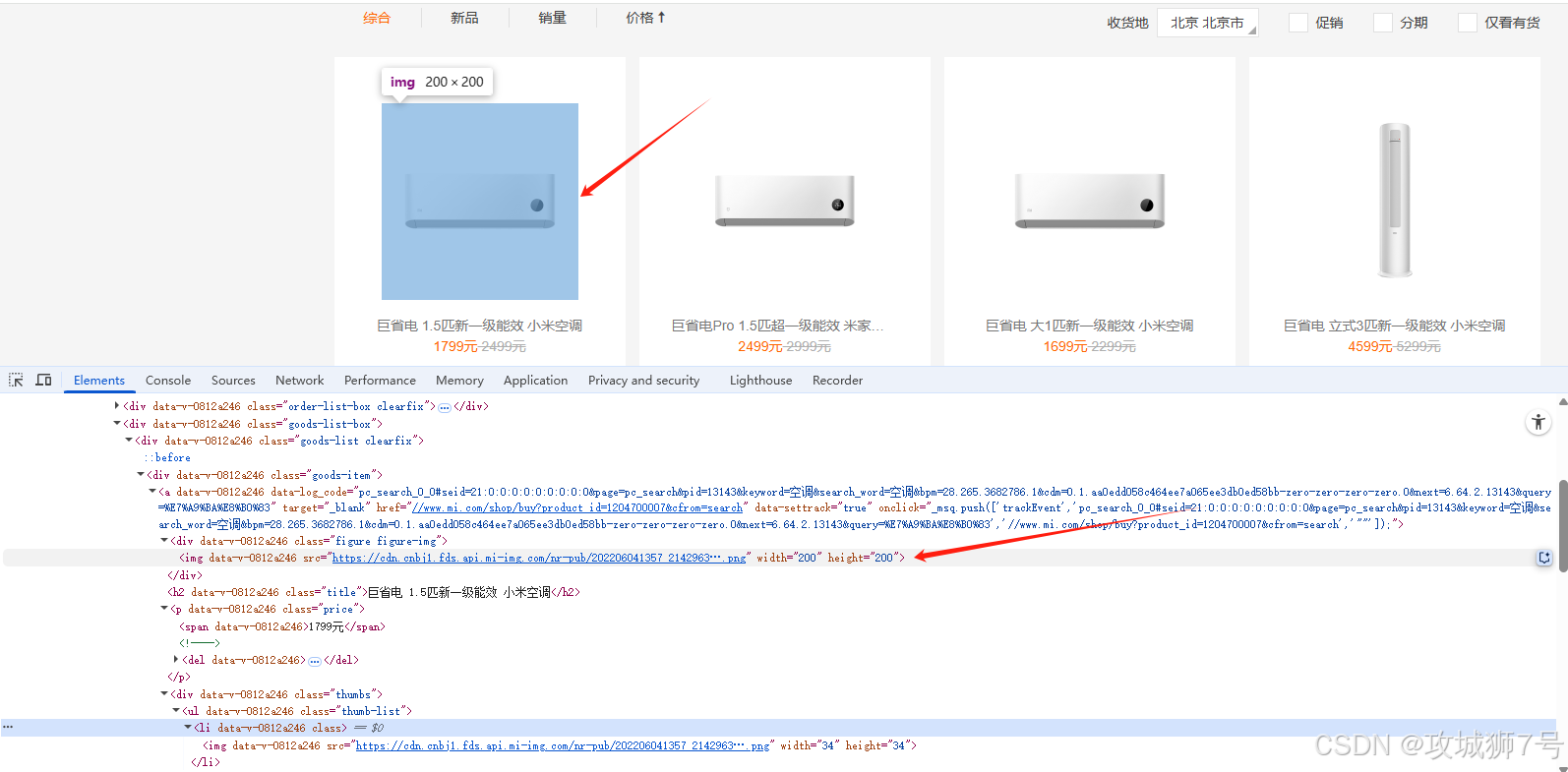
商品列表在如下结构下:
<ul class="goods-list"><li><a href="商品详情链接"><img src="图片链接" ...><div class="title">商品名称</div><div class="price">价格</div>...</a></li>...</ul>实际页面可能有多种 class,如 `.goods-list li`、`.product-list li`、`.goods-item` 等。需根据实际页面调整选择器。
3.2 分页结构
同样点击网页分页标签元素,按鼠标右键的检查项,快速定位分析
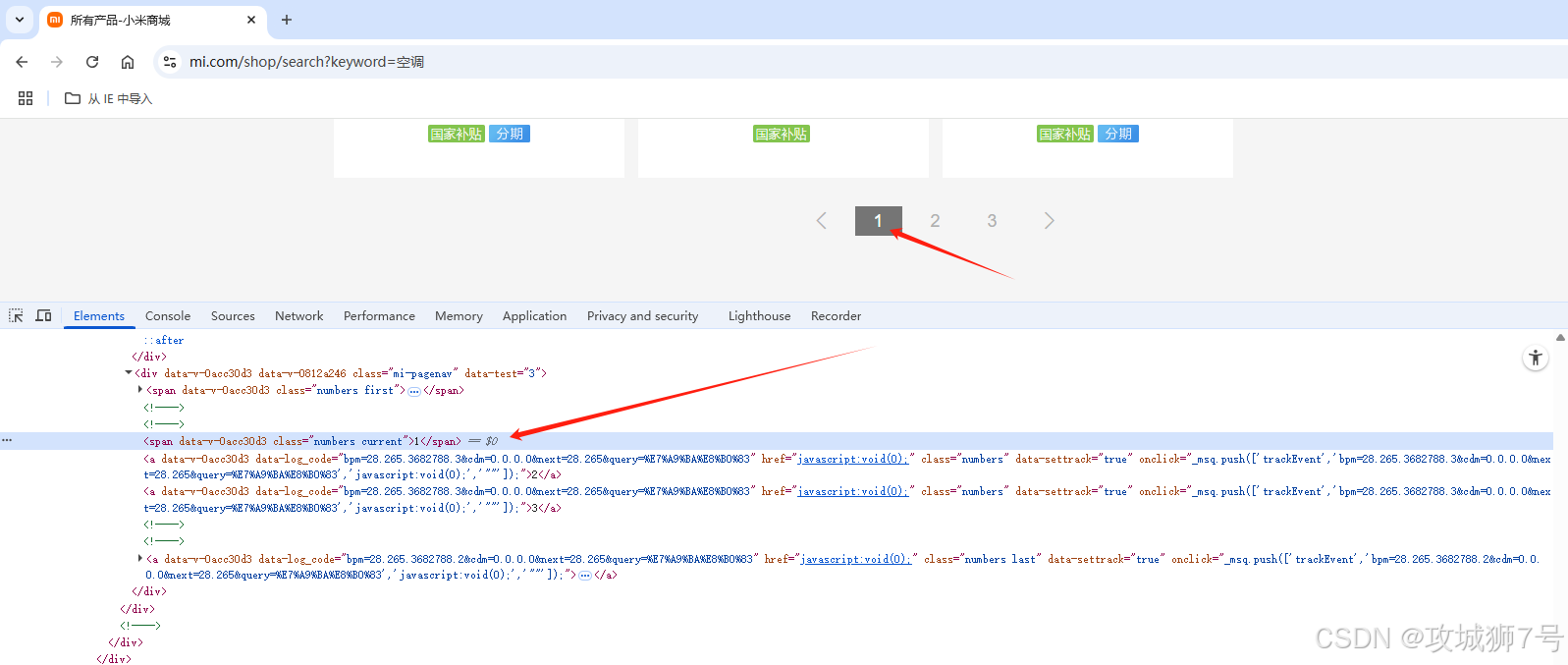
分页栏如下:
<div class="mi-pagenav"><span class="numbers current">1</span><a class="numbers">2</a><a class="numbers">3</a>...</div>- 当前页为 `<span class="numbers current">1</span>`
- 其它页为 `<a class="numbers">2</a>`
- 需用 Selenium 模拟点击 `<a class="numbers">2</a>` 实现翻页
四、Selenium 自动化爬虫实现
4.1 脚本整体结构
核心流程:
1. 启动 Selenium,打开小米商城空调搜索页
2. 解析当前页商品数据
3. 模拟点击分页按钮,依次抓取多页
4. 解析每页数据并输出
5. 关闭浏览器
4.2 代码实现
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom pyquery import PyQuery as pqimport timeKEYWORD = '空调'MAX_PAGE = 3chrome_options = Options()# chrome_options.add_argument('--headless') # 如需无头模式可取消注释chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_experimental_option("detach", True)service = Service()browser = webdriver.Chrome(service=service, options=chrome_options)wait = WebDriverWait(browser, 20)def get_products(page):html = browser.page_sourcedoc = pq(html)products = []for item in doc('.goods-list li, .product-list li, .list li, .goods-item, .product-item').items():title = item.find('.title, .name, .pro-title, .text').text()price = item.find('.price, .pro-price, .num').text()img = item.find('img').attr('src') or item.find('img').attr('data-src')link = item.find('a').attr('href')if title and ('空调' in title or '空调' in item.text()):products.append({'title': title,'price': price,'img': img,'link': link})if not products:for a in doc('a').items():text = a.text()if '空调' in text:img = a.find('img').attr('src') or a.find('img').attr('data-src')price = ''parent = a.parent()for p in parent.parents():price = p.find('.price, .pro-price, .num').text()if price:breakproducts.append({'title': text,'price': price,'img': img,'link': a.attr('href')})print(f'第{page}页空调商品:')for p in products:print(p)return productsdef main():browser.get(f'https://www.mi.com/shop/search?keyword={KEYWORD}')for page in range(1, MAX_PAGE + 1):wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body')))time.sleep(2)get_products(page)if page < MAX_PAGE:try:page_btn = browser.find_element(By.XPATH, f'//div[contains(@class,"mi-pagenav")]//a[@class="numbers" and text()="{page+1}"]')browser.execute_script("arguments[0].click();", page_btn)time.sleep(2)except Exception as e:print(f'点击第{page+1}页失败:', e)breakbrowser.quit()if __name__ == '__main__':main()运行爬取截图:

五、关键技术详解
5.1 Selenium 启动与配置
- 推荐用 Chrome 浏览器,需保证 ChromeDriver 版本匹配
- 可选用 Headless 模式,适合服务器环境
- `detach` 选项可让浏览器调试时不自动关闭
5.2 页面等待与异步加载
- 小米商城商品列表为异步渲染,需用 WebDriverWait 等待元素加载
- `time.sleep()` 可适当延迟,确保页面渲染完成
5.3 商品数据解析
- 用 PyQuery 解析 HTML,支持 jQuery 风格选择器
- 兼容多种商品卡片结构,适应页面变动
- 兜底方案:遍历所有 a 标签,抓取带"空调"字样的商品
5.4 分页处理
- 不能直接拼接 URL 翻页,需模拟点击分页按钮
- 用 XPath 精确定位 `<a class="numbers">`,并用 JS 执行点击,兼容前端事件绑定
- 每次翻页后需等待页面刷新再抓取数据
5.5 异常处理
- 分页点击失败时自动中断,避免死循环
- 可根据实际需求增加重试机制
5.6 可选:保存到 MongoDB
如需将数据保存到 MongoDB,可参考如下代码:
import pymongoMONGO_URL = 'localhost'MONGO_DB = 'xiaomi'MONGO_COLLECTION = 'ac_products'client = pymongo.MongoClient(MONGO_URL)db = client[MONGO_DB]def save_to_mongo(result):try:if db[MONGO_COLLECTION].insert_one(result):print('存储到 MongoDB 成功')except Exception:print('存储到 MongoDB 失败')在 `get_products` 中调用 `save_to_mongo(product)` 即可。
六、Headless 模式与浏览器兼容
- Headless 模式适合服务器、云主机等无桌面环境
- 启用方式:
chrome_options.add_argument('--headless')- 也可用 Firefox、Edge 等浏览器,Selenium 语法基本一致
七、常见问题与优化建议
7.1 反爬机制
- 有些网站如频繁访问可能弹出验证码
- 有些网站需要登录才能进行下一步数据获取,如果有登录步骤,就需要自己通过Selenium自行实现
- 建议适当延迟、降低抓取频率
- 可用代理池、账号池等方式进一步优化
7.2 页面结构变动
- 商品卡片 class 可能变动,需定期检查并调整选择器
- 建议用多种选择器兜底,提升健壮性
7.3 数据完整性
- 某些商品可能缺少价格、图片等字段,需容错处理
- 可用 try/except 或默认值兜底
7.4 性能优化
- Headless 模式+禁用图片加载可提升速度
- 可用多进程/多线程并发抓取不同关键词
八、总结
本文系统讲解了如何用 Selenium 自动化爬取小米商城空调商品信息,涵盖了环境准备、页面结构分析、自动化脚本实现、数据解析、翻页处理、异常处理、可选的 MongoDB 存储、Headless 模式、常见问题与优化建议等内容。通过这种"可见即可爬"的方式,可以高效应对前端动态渲染和复杂 Ajax 的电商页面,极大提升数据采集的灵活性和稳定性。
你可以根据实际需求,扩展脚本支持更多商品类型、更多字段、并发抓取、数据存储等功能,打造属于自己的电商数据采集工具。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!