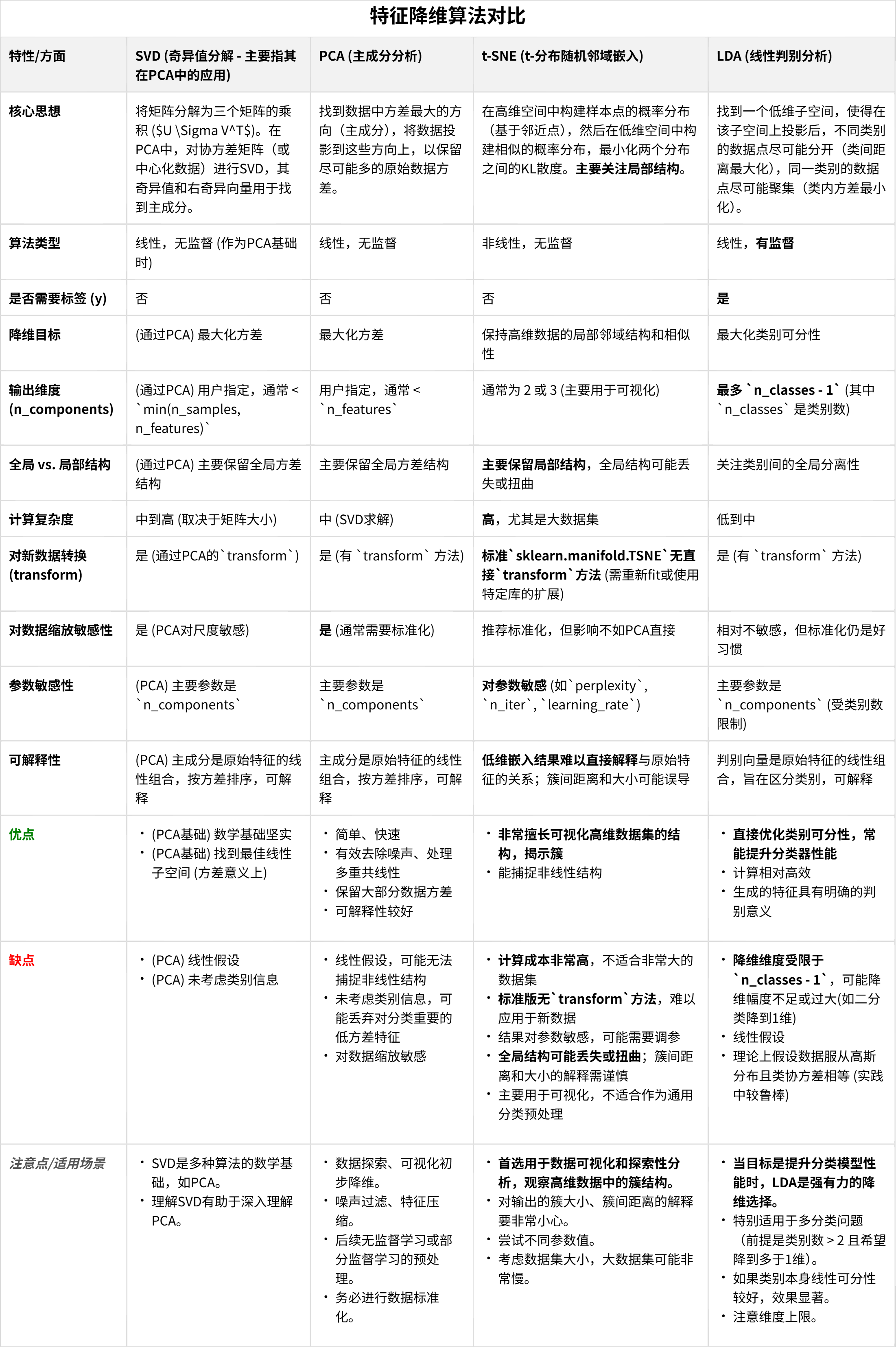
DAY 21 常见的降维算法
- LDA线性判别
- PCA主成分分析
- t-sne降维
还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说
作业:
自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可视化的区别。
什么时候用到降维
数据特征过多:当数据集中特征数量非常庞大时,可能会导致“维度灾难”,增加计算复杂度和训练时间,还可能引发过拟合问题。降维可以减少特征数量,降低计算成本,提高模型训练效率。
数据可视化困难:人类通常只能直观理解二维或三维的数据。当数据维度超过三维时,很难直接进行可视化分析。通过降维将数据映射到二维或三维空间,能帮助我们直观地观察数据分布、聚类情况等。
数据存在冗余特征:数据集中可能存在一些高度相关或冗余的特征,这些特征对模型的贡献有限,反而会增加计算负担。降维可以去除这些冗余特征,保留最具代表性的信息。
模型性能不佳:如果模型在训练过程中表现不佳,如训练时间过长、过拟合严重等,可能是因为数据维度太高。降维可以简化数据结构,提高模型的泛化能力和性能。
降维的主要应用
数据可视化:在生物信息学中,基因表达数据通常具有高维度。通过主成分分析(PCA)或 t - 分布随机邻域嵌入(t - SNE)等降维方法,将基因表达数据降维到二维或三维空间,研究人员可以直观地观察不同样本之间的关系,发现潜在的生物模式。
机器学习:在图像识别任务中,原始图像数据维度很高,降维可以减少计算量,提高模型训练速度和性能。例如,使用线性判别分析(LDA)对图像特征进行降维,然后输入到分类模型中进行训练和预测。
数据压缩:在存储和传输大量数据时,降维可以减少数据的存储空间和传输带宽。例如,在视频压缩中,通过降维技术去除视频帧中的冗余信息,实现数据的高效压缩。
特征选择:在数据分析和建模过程中,降维可以帮助我们筛选出最具代表性的特征,去除无关或冗余的特征。例如,在信用风险评估中,通过降维方法选择与信用风险相关性最高的特征,提高评估模型的准确性。
输入:
## 预处理流程回顾
#1. 导入库
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号#2. 读取数据查看数据信息--理解数据
data = pd.read_csv(r'heart.csv') #读取数据
print("数据基本信息:")
data.info()
print("\n数据前5行预览:")
print(data.head())#3. 缺失值处理
# 先筛选字符串变量
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
print("\n离散变量:")
print(discrete_features)
# 依次查看内容
for feature in discrete_features:print(f"\n{feature}的唯一值:")print(data[feature].value_counts())
#本数据集中不纯在离散变量
# thal 标签编码
thal_mapping = {1: 1,2: 2,3: 3,
}
data['thal'] = data['thal'].map(thal_mapping)
# slope的独热编码,记得需要将bool类型转换为数值
data = pd.get_dummies(data, columns=['slope'])
data2 = pd.read_csv(r"heart.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:
list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
print(list_final) # 打印出来的就是独热编码后的特征名
# 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵
print(data.isnull())
print(data.isnull().sum()) # 统计每一列缺失值的数量
#填补缺失值
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() #把筛选出来的列名转换成列表
print("\n连续变量:")
print(continuous_features)for feature in continuous_features:
mode_value = data[feature].mode()[0] #获取该列的众数。
data[feature] = data[feature].fillna(mode_value) #用众数填充该列的缺失值,inplace=True表示直接在原数据上修改。
print(data.isnull().sum()) # 统计每一列缺失值的数量
# 4. 异常值处理
#异常值一般不处理,或者结合对照试验处理和不处理都尝试下,但是论文中要写这个,作为个工作量
#此数据集无缺失值data.info() # 查看数据集的信息,包括数据类型和缺失值情况from sklearn.model_selection import train_test_split
X = data.drop('target', axis=1) # 特征
y = data['target'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 划分训练集和测试集,test_size表示测试集占比,random_state表示随机种子,保证每次划分结果一致。
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")from sklearn.ensemble import RandomForestClassifier #随机森林分类器from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))import time
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler # 特征缩放
from sklearn.decomposition import PCA # 主成分分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
# UMAP 需要单独安装: pip install umap-learn
import umap # 如果安装了 umap-learn,可以这样导入from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import warnings
warnings.filterwarnings("ignore") # 忽略所有警告信息# 假设 X_train, X_test, y_train, y_test 已经准备好了print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")
# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
pca_expl.fit(X_train_scaled_pca)
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")# 我们测试下降低到10维的效果
pca = PCA(n_components=10, random_state=42)
X_train_pca = pca.fit_transform(X_train_scaled_pca)
X_test_pca = pca.transform(X_test_scaled_pca) # 使用训练集上的PCA模型# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train) # 在降维后的训练集上训练
rf_pred_pca = rf_model_pca.predict(X_test_pca) # 在降维后的测试集上预测print("\nPCA降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca))
print("PCA降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca))# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢
from sklearn.manifold import TSNE # 新增导入 TSNE 类
# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,
perplexity=30, # 常用的困惑度值
n_iter=1000, # 足够的迭代次数
init='pca', # 使用PCA初始化,通常更稳定
learning_rate='auto', # 自动学习率 (sklearn >= 1.2)
random_state=42, # 保证结果可复现
n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,
perplexity=30,
n_iter=1000,
init='pca',
learning_rate='auto',
random_state=42, # 保持参数一致,但数据不同,结果也不同
n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train) # 在降维后的训练集上训练
rf_pred_tsne = rf_model_tsne.predict(X_test_tsne) # 在降维后的测试集上预测print("\nt-SNE降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne))
print("t-SNE降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne))# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Arrayprint(f"\n--- 4. LDA 降维 + 随机森林 ---")
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 再次导入# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):
n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):
n_classes = len(np.unique(y_train))
else:
n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes}) 太少,无法产生至少1个判别组件。")
X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征
X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征
actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)
actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")
X_train_lda = X_train_scaled_lda.copy()
X_test_lda = X_test_scaled_lda.copy()
actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。") lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')
X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)
X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train) # 在降维后的训练集上训练
rf_pred_lda = rf_model_lda.predict(X_test_lda) # 在降维后的测试集上预测print("\nLDA降维 + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda))
print("LDA降维 + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda))
输出:
Data columns (total 16 columns):# Column Non-Null Count Dtype
--- ------ -------------- -----0 age 303 non-null int641 sex 303 non-null int642 cp 303 non-null int643 trestbps 303 non-null int644 chol 303 non-null int645 fbs 303 non-null int646 restecg 303 non-null int647 thalach 303 non-null int648 exang 303 non-null int649 oldpeak 303 non-null float6410 ca 303 non-null int6411 thal 303 non-null float6412 target 303 non-null int6413 slope_0 303 non-null int6414 slope_1 303 non-null int6415 slope_2 303 non-null int64
dtypes: float64(2), int64(14)
memory usage: 38.0 KB
训练集形状: (242, 15)
测试集形状: (61, 15)
--- 1. 默认参数随机森林 (训练集 -> 测试集) ---
训练与预测耗时: 0.0828 秒默认随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.89 0.83 0.86 291 0.85 0.91 0.88 32 accuracy 0.87 61
macro avg 0.87 0.87 0.87 61
weighted avg 0.87 0.87 0.87 61默认随机森林 在测试集上的混淆矩阵:
[[24 5][ 3 29]]--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---
为了保留95%的方差,需要的主成分数量: 13PCA降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.84 0.93 0.89 291 0.93 0.84 0.89 32 accuracy 0.89 61
macro avg 0.89 0.89 0.89 61
weighted avg 0.89 0.89 0.89 61PCA降维 + 随机森林 在测试集上的混淆矩阵:
[[27 2][ 5 27]]--- 3. t-SNE 降维 + 随机森林 ---
标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。
正在对训练集进行 t-SNE fit_transform...
训练集 t-SNE fit_transform 完成,耗时: 1.83 秒
正在对测试集进行 t-SNE fit_transform...
测试集 t-SNE fit_transform 完成,耗时: 0.18 秒t-SNE降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.67 0.21 0.32 291 0.56 0.91 0.69 32 accuracy 0.57 61
macro avg 0.61 0.56 0.50 61
weighted avg 0.61 0.57 0.51 61t-SNE降维 + 随机森林 在测试集上的混淆矩阵:
[[ 6 23][ 3 29]]--- 4. LDA 降维 + 随机森林 ---
原始特征数: 15, 类别数: 2
LDA 最多可降至 1 维。
目标降维维度: 10 维。
本次 LDA 将实际降至 1 维。
LDA降维后,训练集形状: (242, 1), 测试集形状: (61, 1)LDA降维 + 随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.76 0.90 0.83 291 0.89 0.75 0.81 32 accuracy 0.82 61
macro avg 0.83 0.82 0.82 61
weighted avg 0.83 0.82 0.82 61LDA降维 + 随机森林 在测试集上的混淆矩阵:
[[26 3][ 8 24]]