C++内存管理
C++内存管理
c++其实可以说是c语言的一个扩展版本, 所以在内存管理和内存区域划分方面两者是很相似的. 今天来给大家讲一下c++的内存管理.
这是程序内存区域划分的大概的样子 :
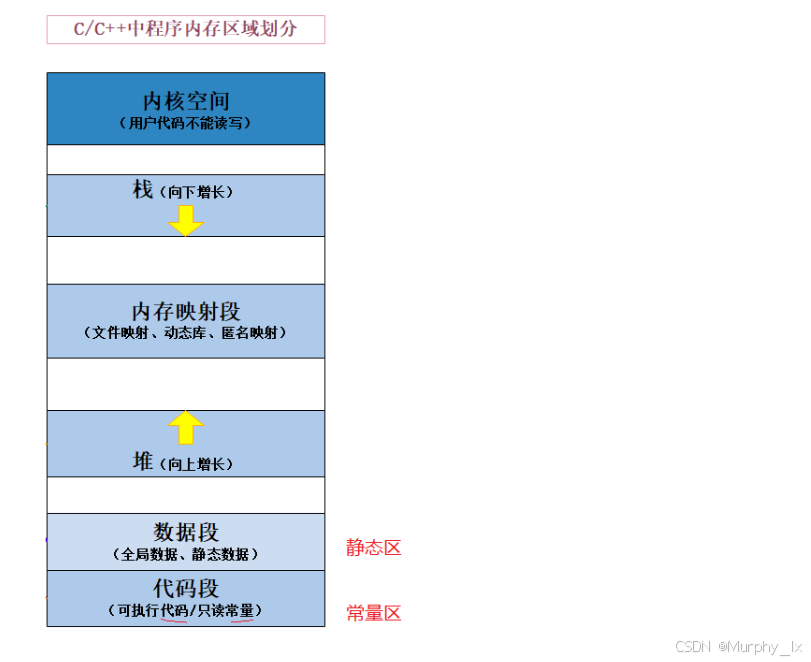
下面简单介绍一下我们目前需要了解的一些内存区域 :
1. 栈(Stack)
- 存储内容:
- 函数调用时的局部变量、参数、返回地址等。
- 函数调用上下文(栈帧),包括寄存器状态、栈指针等。
- 特点:
- 由编译器自动管理,入栈和出栈操作效率高(类似数据结构中的栈)。
- 内存空间连续,分配和释放速度快。
- 大小通常有限制(如几 MB 到几十 MB,取决于操作系统和编译器)。
- 作用:
- 快速存储临时数据,如函数内部的局部变量。
- 保证函数调用的上下文隔离(每个函数有独立的栈帧)。
2. 堆(Heap)
- 存储内容:
- 动态分配的内存(使用
new/delete或malloc/free)。
- 动态分配的内存(使用
- 特点:
- 手动管理,需要显式申请(
new)和释放(delete)。 - 内存空间不连续,可能产生碎片。
- 分配和释放开销较大(涉及系统调用)。
- 手动管理,需要显式申请(
- 作用:
- 灵活分配内存,适用于无法提前确定大小或生命周期的数据(如动态数组、对象)。
- 跨函数共享数据(返回堆内存的指针)。
3. 全局 / 静态存储区
- 存储内容:
- 已初始化的全局变量和静态变量(
static修饰)。 - 未初始化的全局变量和静态变量(BSS 段,Block Started by Symbol)。
- 已初始化的全局变量和静态变量(
- 特点:
- 程序启动时分配,结束时释放。
- 全局可见(外部链接)或文件可见(静态变量)。
- 作用:
- 存储程序整个生命周期内需要存在的数据(如配置参数、单例对象)。
- 共享数据(多个函数可访问同一全局变量)。
4. 常量存储区(只读数据段,ROData)
- 存储内容:
- 字符串字面量(如
"hello")。 const修饰的全局变量(如果编译器将其存储在只读区)。
- 字符串字面量(如
- 特点:
- 通常不可修改,修改会导致运行时错误(如段错误)。
- 可能被多个地方共享(如多个相同的字符串字面量指向同一地址)。
- 作用:
- 避免重复存储相同的常量,节省内存。
- 保证常量数据的安全性(防止意外修改)。
5. 代码区(文本段,Text)
- 存储内容:
- 程序的机器码(指令)。
- 常量表达式(如编译时常量)。
- 特点:
- 通常只读,防止程序意外修改自身指令。
- 可共享(多个进程运行同一程序时,代码段可共享)。
- 作用:
- 存储程序执行逻辑,确保指令的安全性和共享性。
那为什么要这样划分内存区域呢 ?
划分内存区域主要是因为, 不同类型数据, 有不同的存储需求, 比如函数里面的临时变量, 它只需要用一会, 出了函数作用域就销毁了, 所以它适合存在一个分配和释放空间快速的内存区域. 又比如静态变量, 它是全局可见的, 且生命周期覆盖了整个程序运行过程, 所以它就不适合和临时变量呆在一起.
其实也就是说, 我们把不同类型, 不同作用的数据, 分别存储, 这一类数据在这里, 另一类数据又在另一个适合它们的地方, 这样一来, 不仅方便管理数据, 另一方面也让这些数据的作用和功能可以更好的发挥. 否则, 你让全部类型的数据杂乱无章的堆在一起, 调用数据的时候就会很麻烦, 而且还会出现各种差错.
在这里我用上学时的书桌的抽屉来比成一整个内存区域, 如果你不把试卷分类, 不把练习册分类好, 全部杂乱无章的塞到抽屉里, 到时候你找东西就会繁琐, 不仅找的时间长, 还容易找不到, 而且, 你也就这么一点试卷.
你想想, 一个大型程序运行起来得会有多少数据, 成千上万都算少的, 你要是乱堆放, 就会出现上面说的情况, 所以, 内存区域划分和你抽屉合理的放置试卷和练习册一样, 这里虽然不是很严谨, 但是意思就是这么个意思.
当你把语文试卷放一堆, 数学试卷放一起, 找起来的时候就不会要全部试卷找一遍, 要语文试卷, 直接去语文区找, 要数学试卷就去数学区找. 差不多的道理.
简单来说主要是以下几点 :
- 效率:
- 栈的自动管理和连续内存分配速度快。
- 堆的动态分配适合灵活需求。
- 安全性:
- 常量区和代码区的只读属性防止意外修改。
- 不同区域的生命周期管理减少内存泄漏风险。
- 组织性:
- 分离数据和指令(代码区),符合冯・诺伊曼架构。
- 全局 / 静态区和栈 / 堆的分离清晰界定了数据的作用域和生命周期。

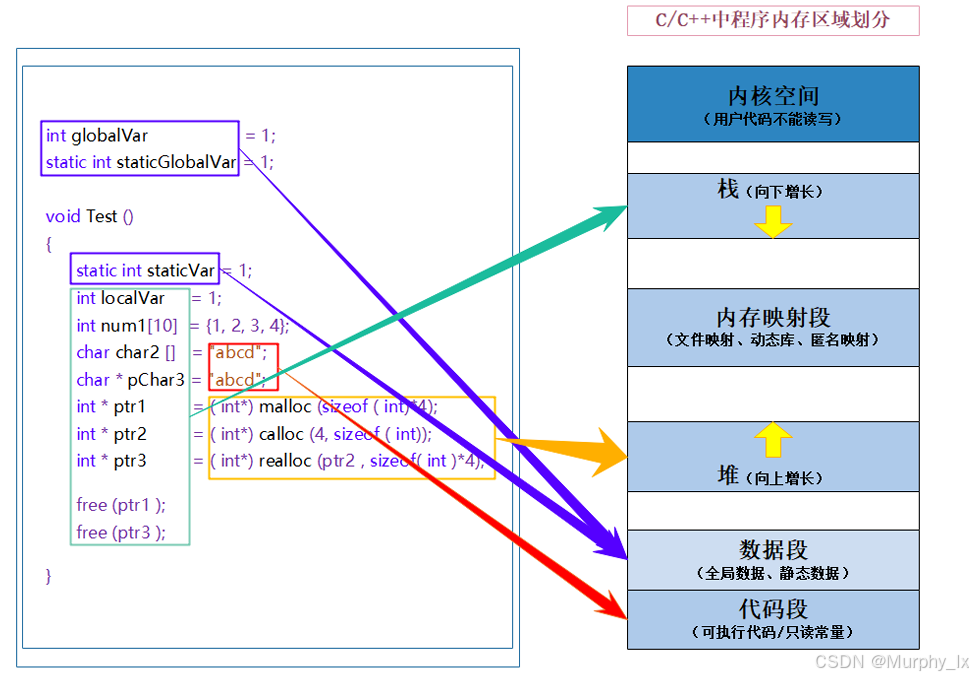
new和delete
在 C++ 中,new 和 delete 是用于动态内存管理的操作符,它们允许程序在运行时分配和释放堆内存。这与 C 语言的 malloc/free 功能类似,但 new 和 delete 提供了更高级的特性,特别是对类对象的支持。
1. new 的基本用法
1.1 分配基本类型
int* ptr = new int; // 分配一个int大小的内存空间
*ptr = 42; // 赋值// 分配并初始化
int* ptr2 = new int(100); // 分配并初始化为100// 动态数组
int* arr = new int[5]; // 分配包含5个int的数组
for (int i = 0; i < 5; i++) {arr[i] = i;
}int* arr1 = new int[5]{1,2,3} // 分配包含5个int的数组并初始化为1,2,3, 后面的数据自动初始化为0,0
// 所以arr1数组的情况是1,2,3,0,0
1.2 分配类对象
class MyClass {
private:int _a;
public:MyClass(int a = 0) { int _a = a;std::cout << "构造函数" << std::endl; }~MyClass() { std::cout << "析构函数" << std::endl; }
};MyClass* obj = new MyClass; // 自动调用默认构造函数//如果没有默认构造函数就会报错
MyClass* obj = new MyClass(100);// 也可以传参调用构造函数初始化
MyClass* obj = new MyClass[5];//分配包含5个MyClass的数组
MyClass* obj = new MyClass[2]{A(1),A(2)}; //也可以使用匿名对象初始化
MyClass* obj = new MyClass[2]{1,2};//甚至如果可以隐式类型转换, 还能这样初始化, 这里int隐式类型转换成了MyClass类型
2. delete 的基本用法
2.1 释放单个对象
delete ptr; // 释放int内存
delete obj; // 释放MyClass对象(自动调用析构函数)//先调用析构函数再释放空间
2.2 释放数组
delete[] arr; // 释放动态数组(必须用[])//这里必须要对应, 否则可能会有问题, 为了杜绝问题发生,所以一定要对应, 如果是释放数组,就要加上[]
注意:
- 使用
delete后,指针变为悬空指针,建议立即将其置为nullptr。 - 重复
delete同一指针会导致未定义行为(通常是程序崩溃)。
3. new 和 delete 的核心特性
3.1 自动调用构造 / 析构函数
new会 :- 分配内存(通过
operator new)。 - 调用对象的构造函数。
- 分配内存(通过
delete会:- 调用对象的析构函数。
- 释放内存(通过
operator delete)。
3.2 类型安全
new返回正确的指针类型,无需强制转换:
int* ptr = new int; // 直接返回int*,无需像malloc那样(void*)转int*
3.3 异常处理
- 若内存分配失败(如内存不足),
new通常抛出std::bad_alloc异常(可通过std::nothrow禁用):
int* ptr = new (std::nothrow) int; // 失败时返回nullptr而非抛异常
if (ptr == nullptr) {// 处理内存分配失败
}//不过我们一般都不使用std::nothrow, 有问题就抛异常就可以了, 不用像这里代码这样, 抛异常这里大家了解一下先, 现阶段还不能完全讲清楚
4. 数组的动态分配与释放
4.1 分配数组
int* arr = new int[10]; // 分配10个int的数组
double* matrix = new double[3][4]; // 二维数组(简化写法)
4.2 释放数组
delete[] arr; // 必须用[],否则仅释放第一个元素
delete[] matrix; // 对二维数组同样用[]
4.3 初始化数组
int* arr = new int[5]{1, 2, 3, 4, 5}; // C++11+初始化列表
6. 与 malloc/free 的对比
| 特性 | new/delete | malloc/free |
|---|---|---|
| 构造 / 析构函数 | 自动调用 | 不调用 |
| 类型安全 | 是(返回正确类型) | 否(返回 void*) |
| 内存分配失败 | 抛异常或(使用std::nothrow)返回 nullptr(一般不用后者) | 返回 NULL |
| 重载可能性 | 可重载 operator new/delete | 可通过替换库函数(不推荐) |
| C++ 标准库兼容性 | 兼容(如 std::vector) | 不兼容 |
大家看完以上内容, 其实就可以感觉的到, new和delete其实可以说是c++为了自定义类型(在c++中一般就是指类类型) 在malloc和free的基础上做的一个升级版. malloc和free的问题就是不能很好解决类类型初始化的问题嘛, malloc和free只能开空间和销毁空间, 无法解决类类型初始化问题, 所以就有了new和delete.
但是它们底层有什么很大的区别嘛? 没有.
可以说:
new的核心逻辑是 malloc + 构造函数调用,
delete的核心逻辑是 析构函数调用 + free。
可以简化理解为:
new ≈ malloc + 构造函数,
delete ≈ 析构函数 + free。
例如,对于内置类型(如int),new和delete几乎等价于malloc和free:(因为它们不涉及类类型初始化, 和类类型销毁, 所以就不需要什么自动调用构造函数和析构函数)
int* p1 = new int; // 类似 malloc(sizeof(int))
delete p1; // 类似 free(p1)
但对于自定义类型(如类对象),new/delete会自动处理构造 / 析构:
class MyClass {
public:MyClass() { /* 初始化资源 */ }~MyClass() { /* 释放资源 */ }
};MyClass* obj = new MyClass; // 1. malloc + 2. 调用MyClass::MyClass()
delete obj; // 1. 调用MyClass::~MyClass() + 2. free(obj)
异常处理
new默认在分配失败时抛std::bad_alloc异常,而malloc返回NULL:
try {int* p = new int[1000000000]; // 可能抛异常}
catch (const std::bad_alloc& e)
{cout << e.what() << endl;//打印"出啥问题"了
}
//这就是抛异常的一个写法
数组处理
new[]和delete[]需要额外记录数组长度,以便正确调用多次析构函数:
MyClass* arr = new MyClass[5]; // 可能在内存中隐藏存储"5"这个长度值
delete[] arr; // 自动调用5次析构函数
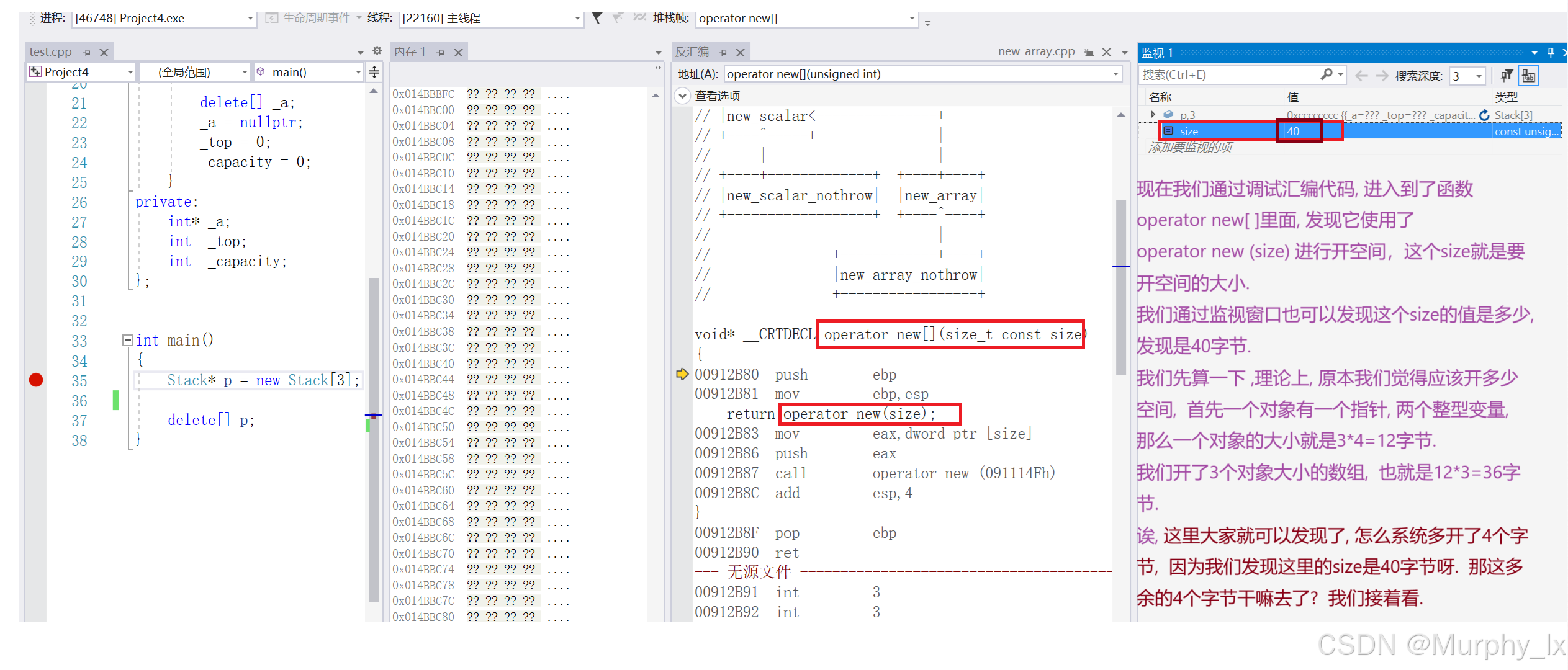
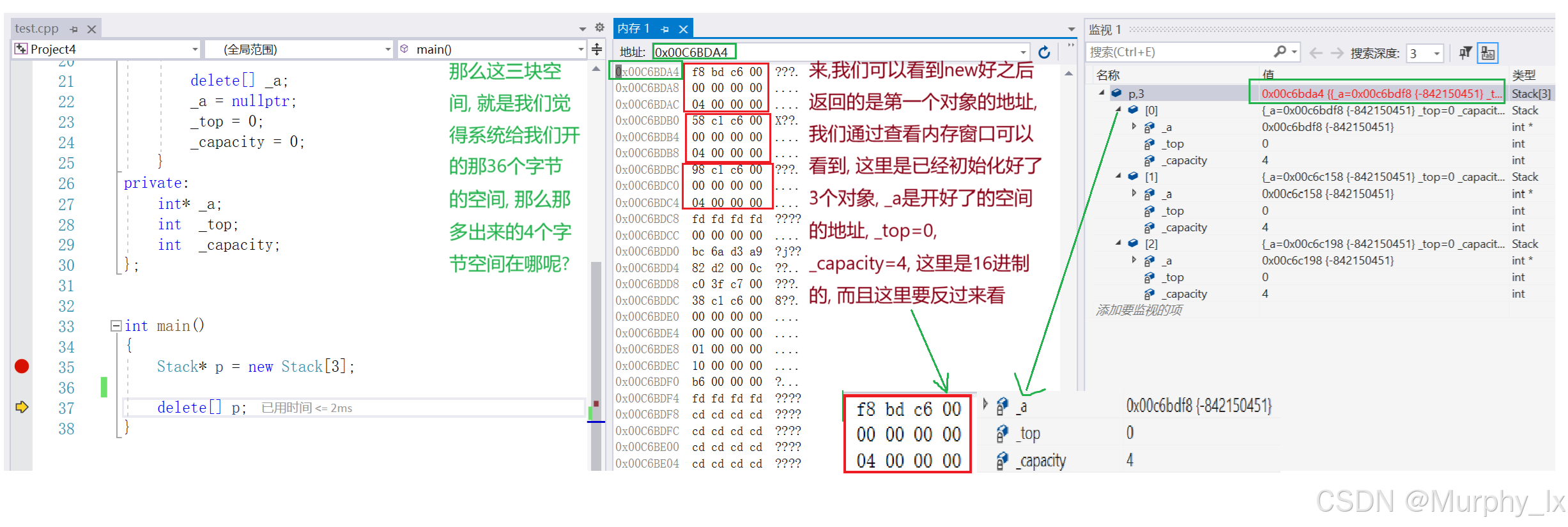
大家可以看到, delete[ ]它不需要在[ ]里面填数字, 它自己就知道需要调用几次析构函数, 为什么呢 ? 因为实际上, new开的空间, 不止是那5个MyClass类类型空间的大小, 它还额外多开了一个4字节的空间(也就是一个int类型大小嘛, 存数字), 存储有几个MyClass类类型的对象. 但是返回数组地址的时候是返回的第一个对象的地址, 这个后面讲底层的时候会给大家详细看看.
接下来, 我们先看一个需要注意的东西:
//大家先看一下这个类, 其实就是一个简单的栈嘛
class Stack
{
public:Stack(int capacity = 4){cout << "Stack(int capacity = 4)" << endl;_a = new int[capacity];_top = 0;_capacity = capacity;}~Stack(){cout << "~Stack()" << endl;delete[] _a;_a = nullptr;_top = 0;_capacity = 0;}
private:int* _a;int _top;int _capacity;
};
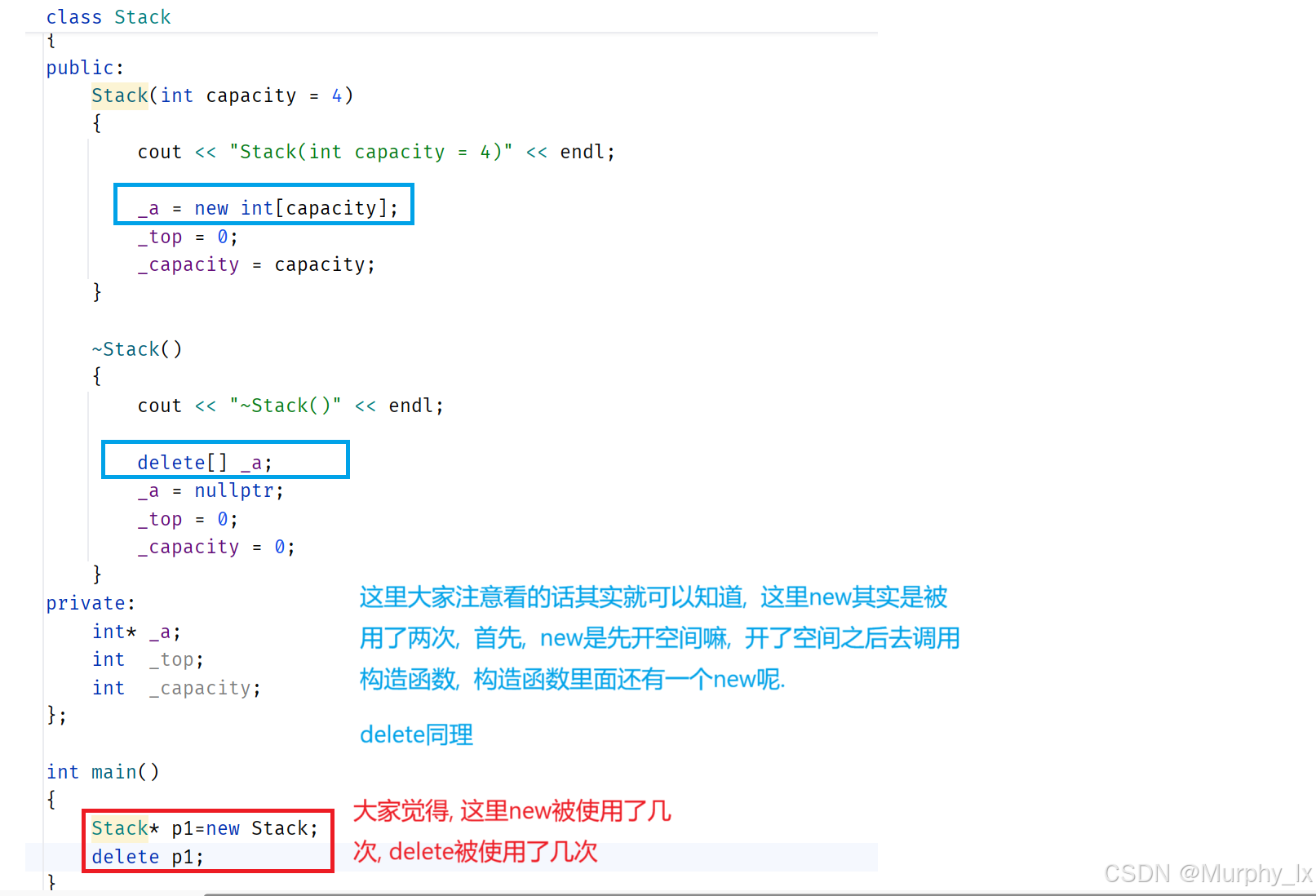
接下来就是讲new和delete的底层了, 这里的底层是让大家更了解new和delete到底是一个什么成分的东西, 让大家更了解new和delete的一个运作的逻辑 .
我们使用下面这段代码 :(这里我使用vs2019来给大家展示, 不同编译器的底层会略有不同, 因为有些逻辑会被编译器优化, 特别是新编译器, 或者说不同公司的编译器实现部分逻辑会略有不同, 不过大体是类似的) (还有就是汇编代码不用全部看懂, 理解我讲解的东西就好了, 大概知道一下什么意思)
#include <iostream>
using std::cout;
using std::endl;class Stack
{
public:Stack(int capacity = 4){cout << "Stack(int capacity = 4)" << endl;_a = new int[capacity];_top = 0;_capacity = capacity;}~Stack(){cout << "~Stack()" << endl;delete[] _a;_a = nullptr;_top = 0;_capacity = 0;}
private:int* _a;int _top;int _capacity;
};int main()
{Stack* p1=new Stack;delete p1;
}

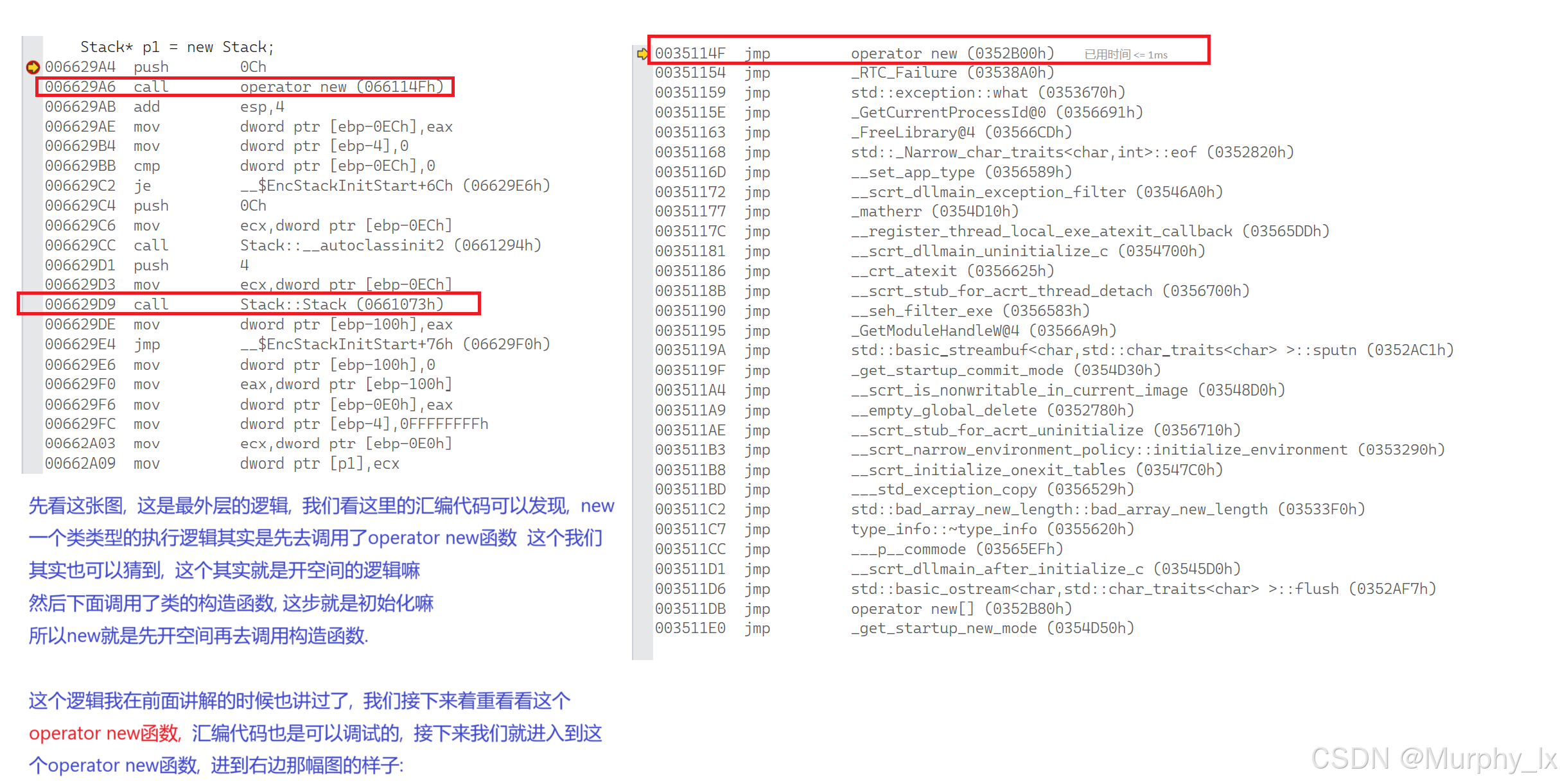
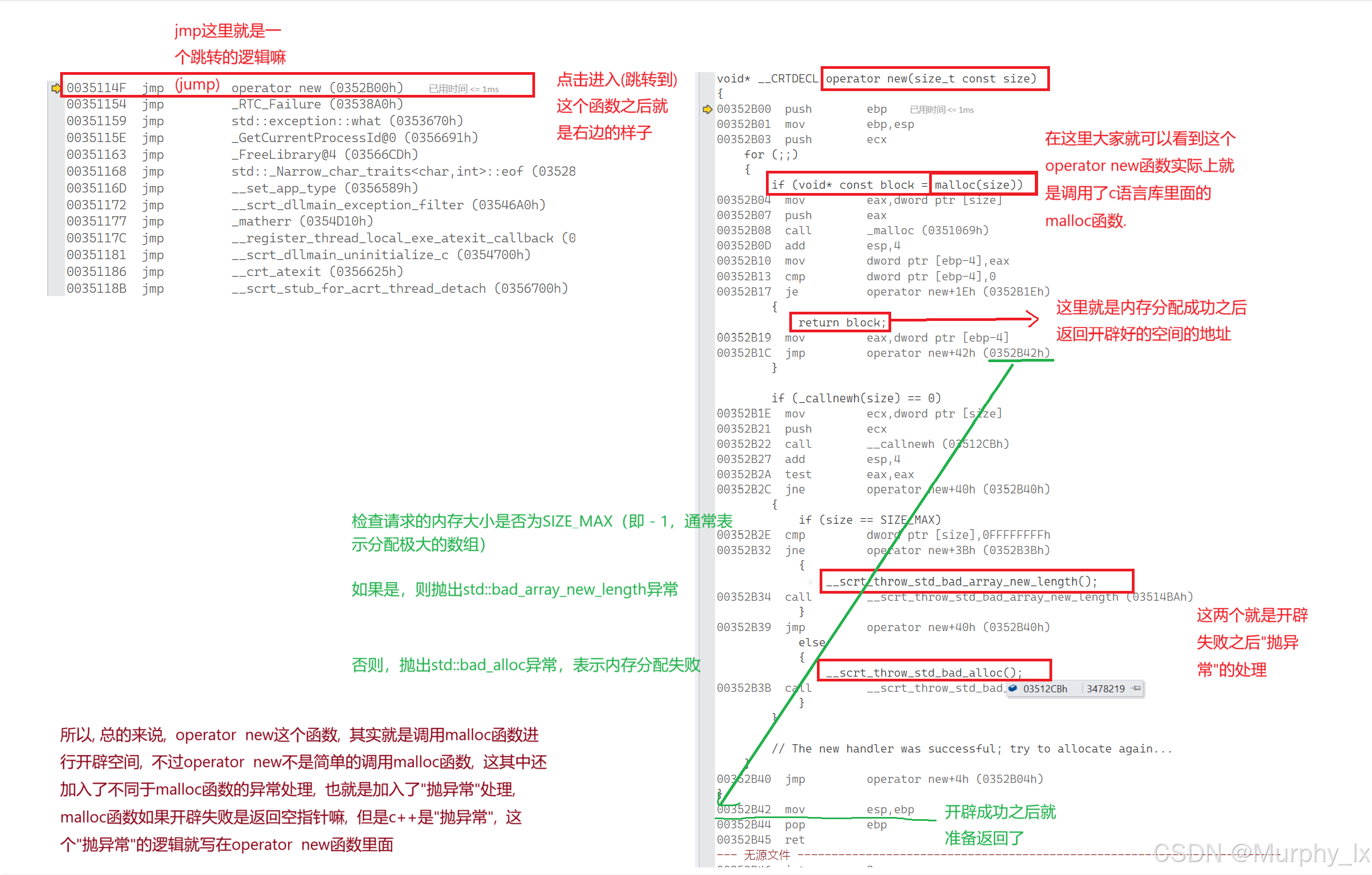
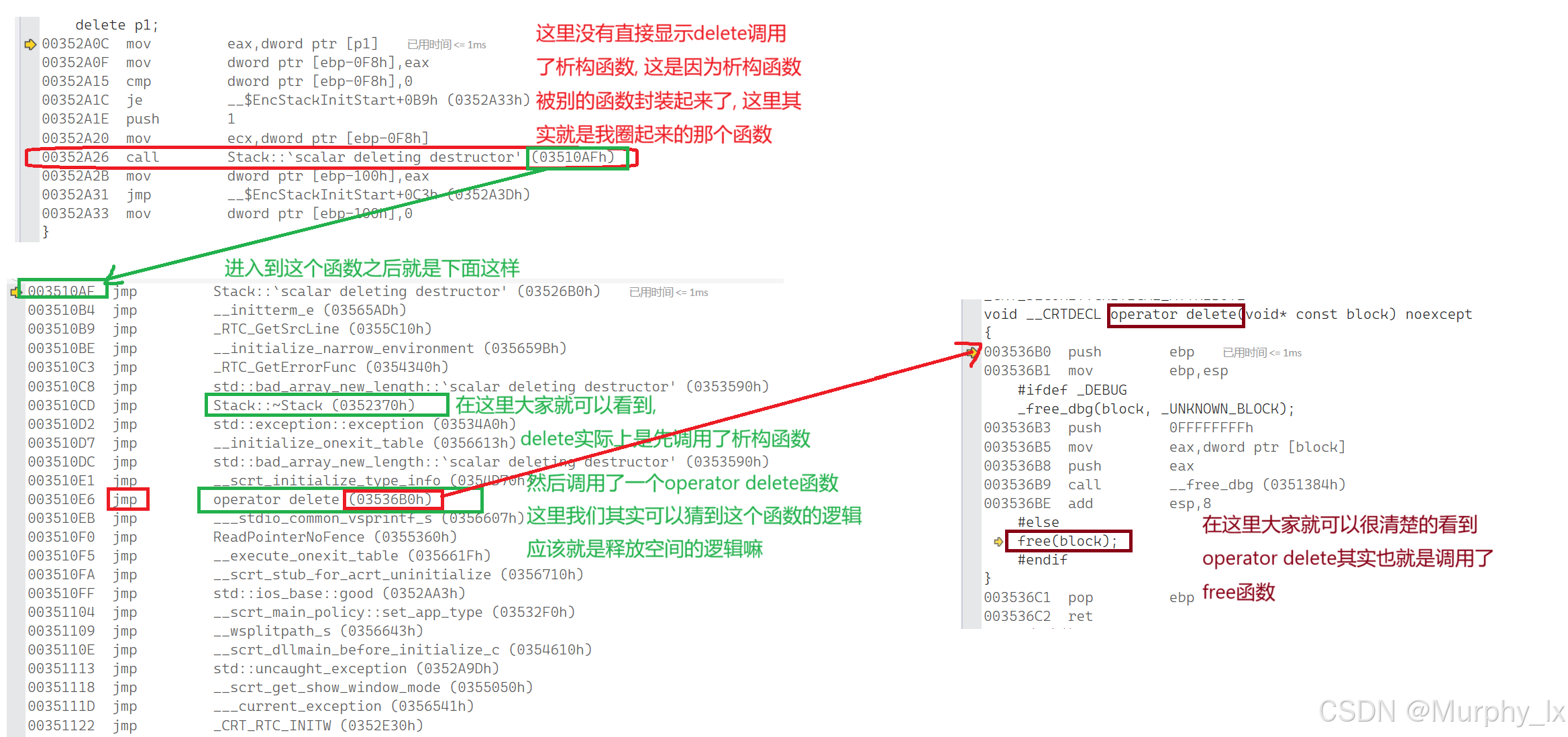
接着我们来看看delete的逻辑 :
好, 我们已经通过调试汇编代码, 看清了new和delete的底层逻辑 :
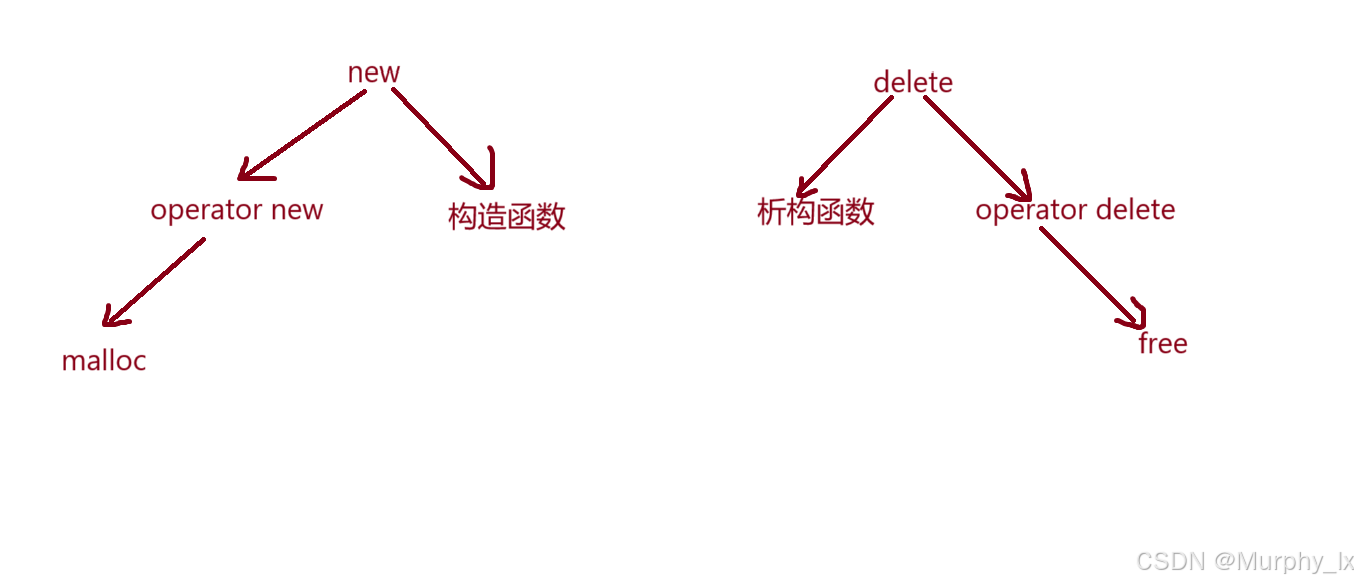
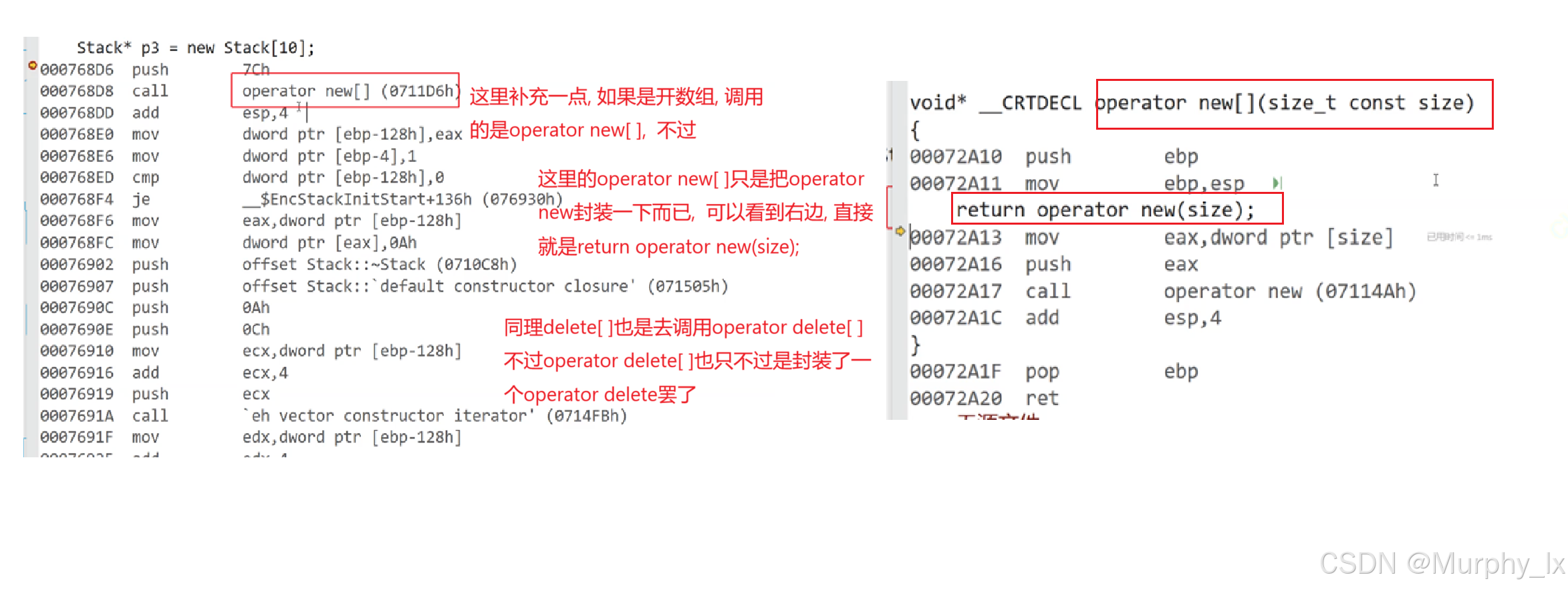
new其实是先调用了一个名为operator new的函数, operator new函数其实就是一个封装了malloc函数的函数, 并且operator new函数里面也写有独属于c++的空间开辟异常处理逻辑. 这部分就是用来开空间的嘛
开完空间之后就是调用构造函数进行初始化处理.
delete也是类似, 不过delete是先调用析构函数函数, 然后再去调用operator delete函数,
operator delete函数封装了free函数, 进行空间的销毁.
operator new 和operator delete是系统提供的两个全局函数, 而且我们是可以显示的去调用这两个函数的.
这两个函数是特殊的运算符重载.
#include<iostream>
using namespace std;class A
{
public:A(int a = 0): _a(a){cout << "A():" << this << endl;}~A(){cout << "~A():" << this << endl;}private:int _a;
};
int main()
{//不过单独使用operator new就只能用来开空间,它不会调用构造函数去初始化p1A* p1 = (A*)operator new(sizeof(A));//对于内置类型来说,operator new就和malloc几乎没有任何区别了,因为//内置类型不需要构造函数初始化int* a1=(int*)operator new(sizeof(int));//operator delete同理p1->~A();//这里大家还得知道的就是析构函数是可以单独拿出来使用的//但是构造函数是不能单独拿出来用的//也就是说//p1->A();这样是不可以的, 会报错//不过有另一种办法可以显示的调用构造函数,//也就是定位new,这个等会说operator delete(p1);//这里做的就是单纯的释放空间了operator delete(a1);//这里和free其实几乎就没区别了,内置类型嘛return 0;
}
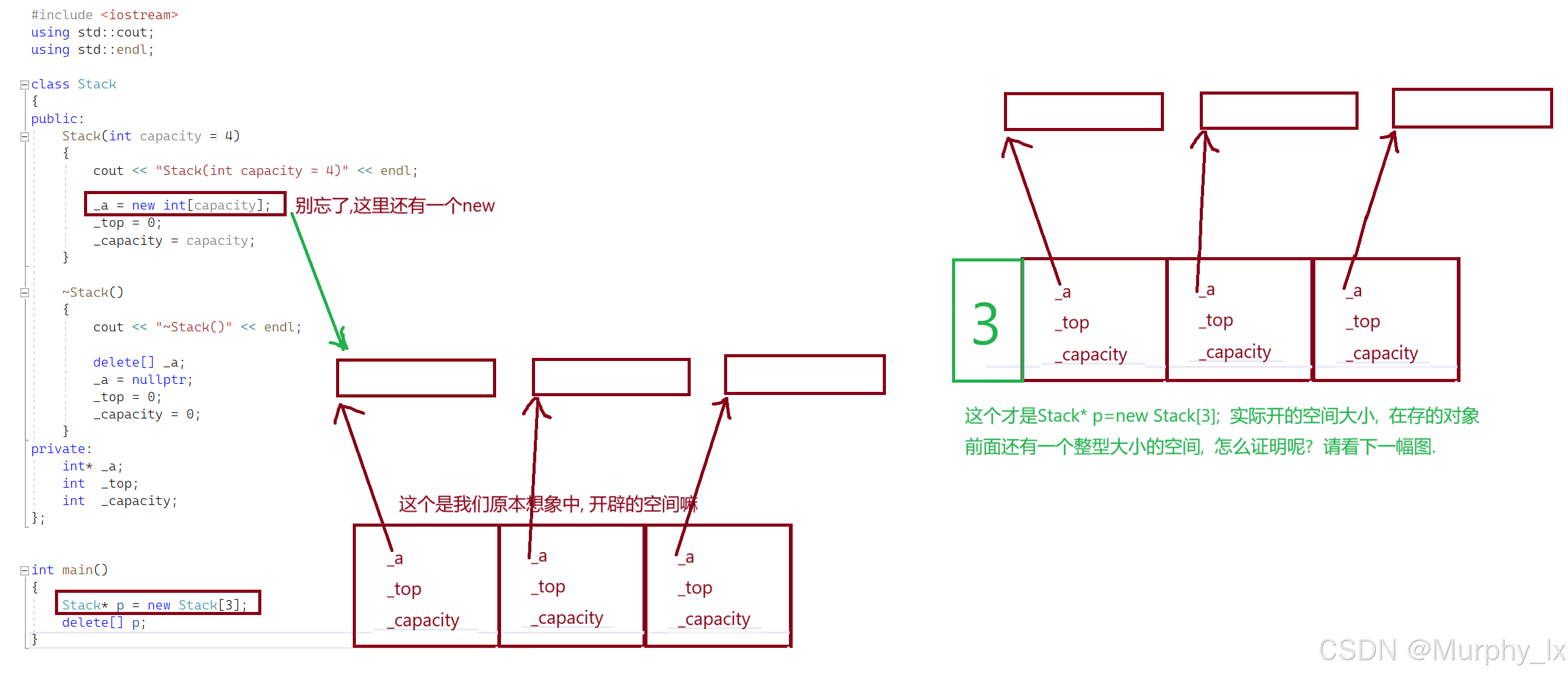
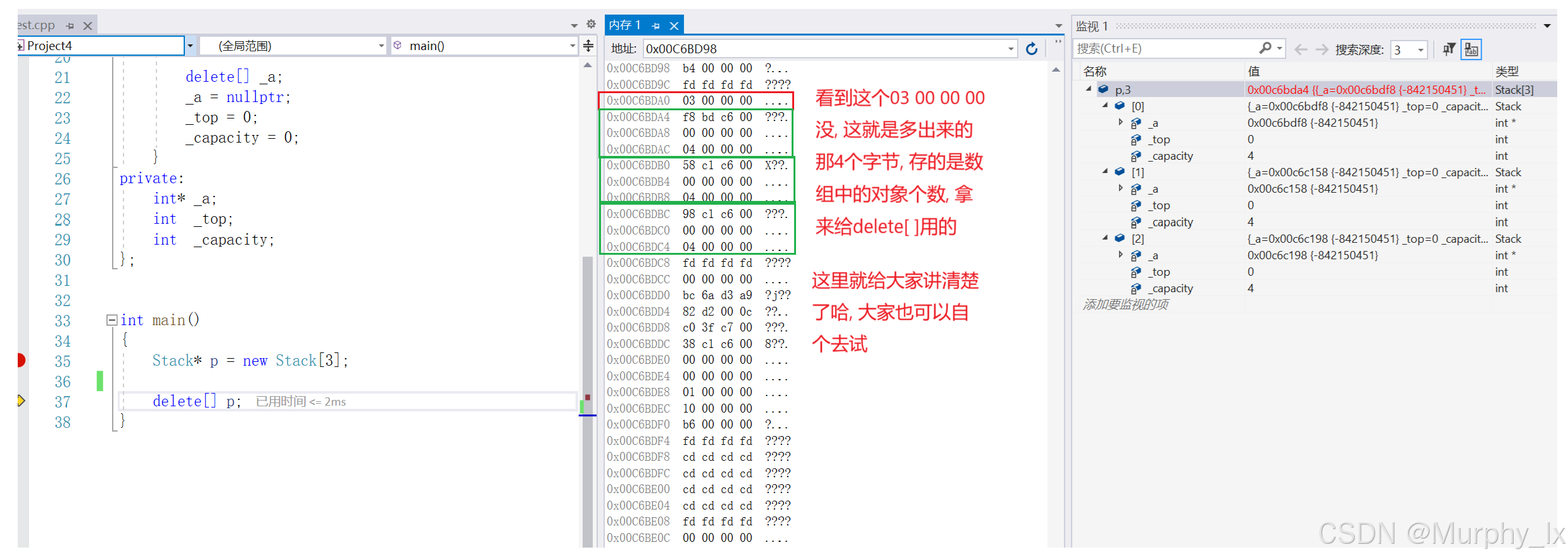
在讲定位new之前, 还有一个东西得给大家看看, 也就是new实际开的空间大小, 我前面不是给大家讲了new开的空间大小, 并不是我们想象中的只会开相应个数的对象的大小嘛, 它还会偷偷的开一个int整型的大小的空间用来存对象个数.
这个存起来的对象个数, 会在delete[ ]的时候用到, 前面我也说过了, 我们不用在[]里面填参数, 但是delete知道要去调用几次析构函数去处理数组中的对象, 这就是new偷偷开的空间存的对象个数的作用.
下面大家详细看看 :
这是展示使用的代码:
#include <iostream>
using std::cout;
using std::endl;class Stack
{
public:Stack(int capacity = 4){cout << "Stack(int capacity = 4)" << endl;_a = new int[capacity];_top = 0;_capacity = capacity;}~Stack(){cout << "~Stack()" << endl;delete[] _a;_a = nullptr;_top = 0;_capacity = 0;}
private:int* _a;int _top;int _capacity;
};int main()
{Stack* p=new Stack[3];delete[] p;
}
那么接下来我们简单聊聊定位new
定位new
在 C++ 里,定位 new(placement new)属于一种特殊的 new 表达式。它的作用是在已经分配好的内存区域上构建对象,而不是重新去申请内存。
class A
{
public:A(int a = 0): _a(a){cout << "A():" << this << endl;}~A(){cout << "~A():" << this << endl;}private:int _a;
};int main()
{Stack* p = new Stack[3];//我们先用operator new开一个A类空间A* p1 = (A*)operator new(sizeof(A));//然后我们就可以使用new显示调用构造函数初始化了//这是一个new的作用//不过这个大家了解一下就行, 知道有这个东西就好//我们平时直接使用A* p1 = new A(1);就ok了//这个只做了解new(p1)A(1);delete[] p;
}
我先给大家讲一下定位new这个东西主要是拿来干嘛的 :
首先呢, 定位new这个东西主要是用来处理 **“当我们需要频繁使用new去向系统申请小空间的时候”**由于系统当中不只是有我们一个程序在运行, 是有很多个程序或者说进程在一起运行的, 要是每一个进程都频繁的向系统索要空间, 而且每次就一点, 这样其实就很麻烦. 给大家举个例子 :
假设呢, 你是一个家长, 你有7个孩子, 孩子上学了, 需要零用钱, 一开始你为了防止他们有大花销, 决定一天给一次零用, 孩子算好每一天需要的钱, 然后找你要. 可是久而久之你就发现, 他们总是不太够用, 比如说出去玩要花钱, 出去打球要花钱, 等等, 很多即时娱乐都是不能提前预知的, 或者一些活动, 这样他们7个人, 除了每天找你要必要的零用之余, 一天之中还可能一个小时找你要一次钱, 你觉得"我c了", 我直接干脆给你一个月的花销, 你自己先拿去用着吧, 用不够了再来找我.
这个时候, 你的7个孩子, 一天的花销用完之后就不会去找你继续要钱了, 因为他们有一个月的预算呀, 他们就接着从卡里取出钱, 当做第二天的零用或者活动开销.
好, 那么这里的**“孩子频繁的找你要小钱, 要零用"就是"我们需要频繁使用new去向系统申请小空间”, 这样其实对于系统来说是一件很繁琐的事情, 所以我们为了让系统减轻一下负担, 我们就根据实际情况直接一次性申请多一些空间, 这个一次性申请一个大的空间, 这个空间就叫内存池** .
我们日常使用new是直接向系统申请空间, 但是当我们有一个内存池, 我们就不用去找系统开空间了, 我们直接去内存池去使用里面的空间, 这个时候我们就要使用到定位new, 定位到这个内存池的空间, 在里面使用空间去创建对象.
大概就是这样. 目前我们还没有接触到内存池的详细使用, 后面遇到我会给大家讲, 大家先做一个基础的了解先.
基本语法
#include <new> // 必须包含这个头文件void* memory = /* 指向已分配内存的指针 */;
new (memory) Type(/* 构造函数参数 */);
关键特性
- 不进行内存分配:定位 new 不会去调用
operator new来申请内存,而是直接在传入的内存地址上创建对象。 - 手动管理内存:使用定位 new 时,内存的分配和释放都需要手动处理。对象析构时,要手动调用其析构函数,但无需释放内存。
- 内存来源多样:可以使用栈内存、堆内存或者共享内存等作为定位 new 的内存来源。
应用场景
- 内存池技术:借助内存池预先分配内存,再用定位 new 在其中构建对象,这样能减少动态内存分配带来的开销。
- 嵌入式系统开发:在嵌入式系统中,需要将对象固定存放在特定的内存地址,此时就可以使用定位 new。
- 高性能场景:在对性能要求极高的场景下,避免频繁进行内存分配和释放操作。
使用示例
#include <iostream>
#include <new>class MyClass {
public:MyClass(int value) : data(value) {std::cout << "构造函数被调用,data = " << data << std::endl;}~MyClass() {std::cout << "析构函数被调用,data = " << data << std::endl;}void print() {std::cout << "data = " << data << std::endl;}private:int data;
};int main() {// 1. 分配内存(这里使用堆内存)char* buffer = new char[sizeof(MyClass)];// 2. 使用定位new在已分配的内存上构造对象MyClass* obj = new (buffer) MyClass(42);// 3. 使用对象obj->print();// 4. 手动调用析构函数obj->~MyClass();// 5. 释放内存delete[] buffer;return 0;
}
注意要点
- 析构函数的调用:对象生命周期结束时,必须手动调用析构函数,否则资源无法被正确释放。
- 内存对齐问题:分配的内存必须满足对象类型的对齐要求。通常可以使用
alignas来确保对齐。 - 内存重复使用:在同一内存区域重复使用定位 new 时,要保证之前的对象已经被正确析构。