FHE 之 面向小白的引导(Bootstrapping)
1. 引言
FHE初学者和工程师常会讨论的一个问题是;
- “什么是引导(bootstrapping)?”
从理论角度看,这个问题的答案很简单:
- 引导就是套用 Gentry 提出的思想——在加密状态下同态地执行解密操作,并使用其私钥的加密形式来实现。
但这个解释往往让人困惑,尤其是在面对如今各种 FHE(全同态加密)库所提供的不同加密方案时,这种说法并不能真正帮助理解什么是引导。
要理解引导,首先需要理解两个概念,它们适用于所有同态加密的密文:
- 密文的“等级”(level)
- 密文中的“噪声”(noise)
无论使用哪种底层加密方案(BGV、BFV、CKKS 或 TFHE),每个密文都有一个噪声值;而“等级”这个概念只适用于 BGV、BFV 和 CKKS 这类方案。
在这些方案中,每次执行同态乘法时,都会“消耗”一个等级:
- 也就是说,密文的等级值会减少 1 1 1;
- 同时,密文中的噪声也会增加。
经过一定数量的操作后(具体数量取决于所使用的加密方案),密文就无法再继续执行操作了。这通常是因为:
- 等级已经降到 0(执行了过多的乘法);
- 或 噪声增长过大(如执行了大量加法);
- 或者 两者同时发生。
在这个时候,就需要“引导(bootstrapping)”了:
- 引导的作用是将密文的等级恢复到更高的值,
- 并且(根据不同方案)可能还能减少噪声。
引导通常被认为是一个昂贵的操作(虽然目前的技术已经让它变得更快了),因此大家在实际使用中会尽量避免频繁执行引导操作。
为了让情况变得更复杂一些,常常会看到同一个加密方案的同一实现,其运行时间却各不相同。这是因为“运行时间”可以从以下四个角度来看待:
- 最直观的方式是延迟(latency):
也就是“执行一次引导操作需要多长时间?” - 第二个角度(适用于 BGV、BFV、CKKS)是密文打包(ciphertext packing)的概念:
在这些方案中,可以将多个明文打包进一个密文中,从而实现摊销(amortization)。
换句话说:每秒可以对多少个明文槽(slot)执行引导操作?
这衡量的是吞吐量(throughput),其计算方式大致为:
吞吐量 = 支持的槽位数 单次引导的延迟(秒) \text{吞吐量} = \frac{\text{支持的槽位数}}{\text{单次引导的延迟(秒)}} 吞吐量=单次引导的延迟(秒)支持的槽位数
这类摊销来自于纯粹的数学优化。 - 第三个角度是利用指令级并行带来的摊销:
比如使用切片策略、多线程、甚至 GPU 实现。
这类优化不是数学上的,而是工程实现上的优化。
它同样可以用“每秒可引导的明文槽位数”来衡量。 - 第四种衡量方式(在2021年论文Bootstrapping for HElib 中提出):
考虑的是:
引导操作提供的槽位数 × 可支持的乘法深度 执行一次引导所需时间 \frac{\text{引导操作提供的槽位数 × 可支持的乘法深度}}{\text{执行一次引导所需时间}} 执行一次引导所需时间引导操作提供的槽位数 × 可支持的乘法深度
本文不会深入讨论这种摊销方式。
不过,在大多数应用场景中,人们关注的重点并不是高吞吐量,而是低延迟——
也就是说,更希望快速完成一次函数评估,而不是慢慢完成很多次函数评估。
因此,在许多实际应用中,引导性能的关键指标是:
- 延迟。
要更深入理解这个问题,就必须结合具体加密方案来研究引导操作对等级、噪声和性能的影响。
而这恰恰是引发混淆的地方:
- 一种加密方案中的引导行为,通常无法直觉性地迁移到另一种方案中去理解。
现在,来总结目前主流加密库中提供的三大类 FHE(全同态加密)方案在执行引导(bootstrapping)时的行为差异:
- BGV / BFV
- CKKS
- TFHE
其中:
- [1] 指:2021年论文Bootstrapping for HElib
- [3] 指:2021年论文Sine Series Approximation of the Mod Function for Bootstrapping of Approximate HE
- [4]指:Zama团队2022年7月6日博客Announcing Concrete-core v1.0.0-gamma with GPU acceleration
2. BGV / BFV
在BGV / BFV这些方案中,引导操作的作用是:
- 增加密文的等级(level);
- 同时减少噪声(noise)。
引导前后的密文加密的是相同的明文消息(即明文内容不发生变化)。
一个 BGV/BFV 计算通常是由一系列加法和乘法组成的:
- 目标是尽量减少乘法的深度(multiplicative depth);
- 乘法深度越高,所需引导次数也越多。
- BGV/BFV 的引导操作通常非常耗时(延迟高);
- 但由于支持密文打包(ciphertext packing),可以实现较好的摊销效果。
3. CKKS
在 CKKS 中,明文本身就带有一定的噪声,因为它们表示的是实数的近似值。
- 引导操作不会减少噪声,它只是提升密文的等级。
因此,CKKS引导前后的密文并不加密完全相同的明文:
- 它们分别是对同一个实数的不同近似值。
不过,随着每次操作(包括引导),明文近似值的误差也会不断增大。
- 所以,如果要计算一个很深的电路,就必须使用非常大的参数;
- 仍然需要关注长运算序列中误差的积累问题。
总体而言,CKKS 的引导延迟与 BGV/BFV 相近。
4. TFHE
在 TFHE 中,引导操作在某种程度上类似于 BGV/BFV 方案的引导 —— 它能够减少噪声。但由于 TFHE 没有“等级(level)”的概念,无需考虑与等级相关的问题。
然而,TFHE 的引导具有两个重要的区别:
- 延迟非常低
引导操作的延迟极小,每秒可以执行成千上万次引导,如果使用 GPU 加速,性能还会更高。 - 支持“可编程引导(Programmable Bootstrapping)”
在引导过程中,可以同态地评估一个查找表(LUT)函数,且几乎没有额外开销。
如,假设一个密文加密的是一个 4 4 4-bit 的值,即取值范围为 [ 0 , … , 15 ] [0, \ldots, 15] [0,…,15] 的整数,那么在引导的同时,可以“免费”地评估任何一个将 4 4 4-bit 输入 映射为 4-bit 输出 的函数。
这意味着在 TFHE 中,同态计算变成了 一系列的加法、乘法和查找表函数的评估。因此:
- 引导的速度比其他方案快了若干个数量级;
- 计算可以用更丰富的语言表达;
- 实现复杂函数所需的操作次数更少;
- 无需像 CKKS 那样通过增加参数规模来支持深层电路。
5. 总结
引导(Bootstrapping)技术使得同态计算可以持续不断地进行下去。它的实现依赖于修改密文关联的“等级(level)”与“噪声(noise)”。具体如何修改、其延迟(latency)和吞吐量(throughput)等性能指标,都取决于所采用的具体 FHE 加密方案。
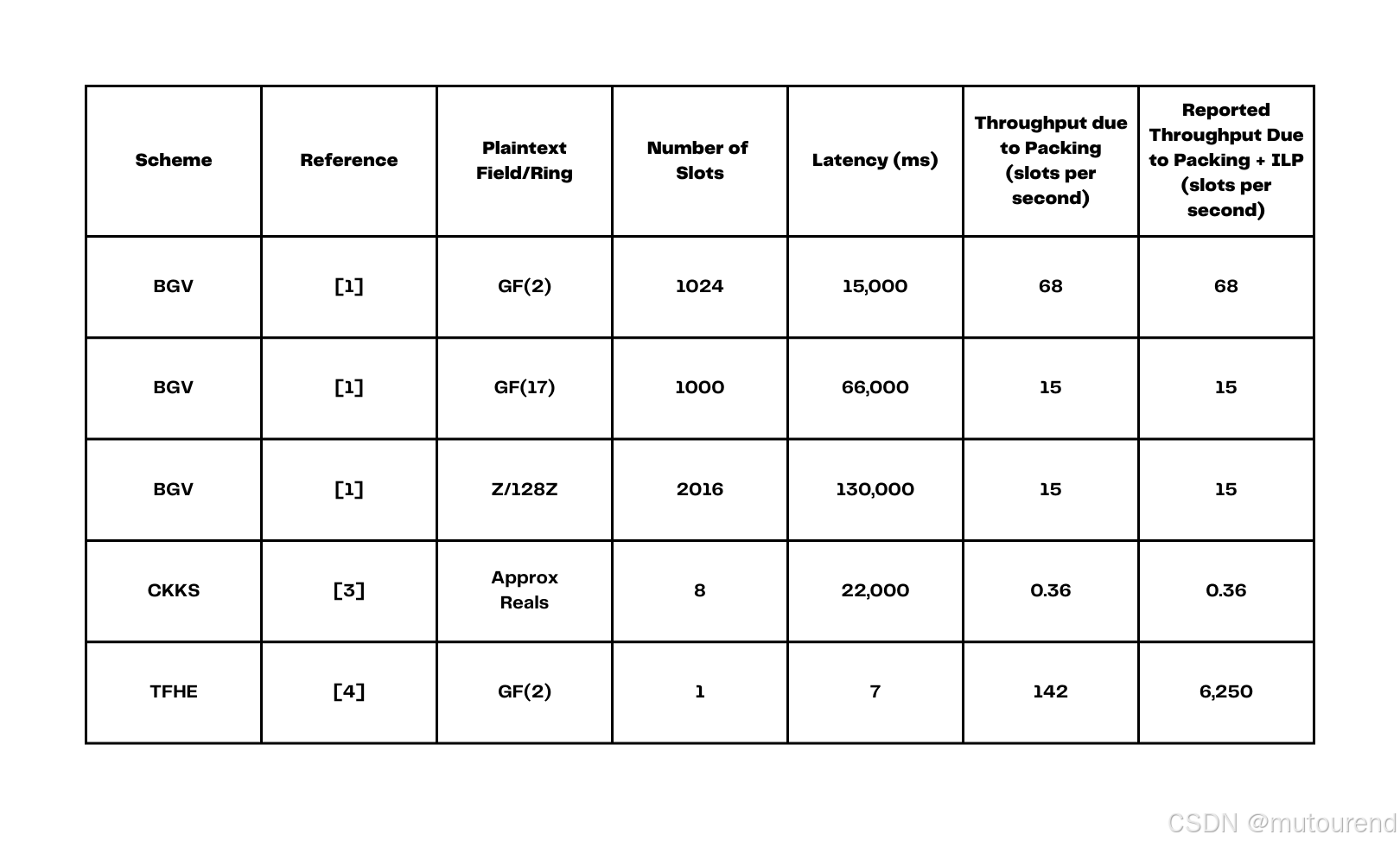
为了总结各种方案下引导的表现,以下我提供了一张对比表,内容摘自目前(2022年11月)所知的相关研究论文。
其中:
- [1] 指:2021年论文Bootstrapping for HElib
- [3] 指:2021年论文Sine Series Approximation of the Mod Function for Bootstrapping of Approximate HE
- [4]指:Zama团队2022年7月6日博客Announcing Concrete-core v1.0.0-gamma with GPU acceleration
对于表中 BGV 的时间数据(来源于2021年论文Bootstrapping for HElib),使用了 thin-bootstrapping 的计时方式:也就是说,假设每个明文槽(plaintext slot)仅包含一个基本域/环上的元素,而不是扩展域/环的元素。这种形式在实际应用中最具相关性。
需要注意的是,对于 BGV,还可以考虑第四种性能度量方式:
- 即引导的摊销成本,涵盖所有明文槽以及未来可以“免费”执行的乘法次数(即无需再次引导)。
- 在以上表格中未纳入这一项,但可以粗略理解为:将原始吞吐量乘上 15 到 30 的系数,具体取决于使用的参数集合。
2022年论文BASALISC: Flexible Asynchronous Hardware Accelerator for Fully Homomorphic Encryption 中 提出了一种用于 BGV 的硬件加速器设计,它在明文空间为 Z / ( 12 7 3 ) Z Z/(127^3)Z Z/(1273)Z、并具有 64 个明文槽的情况下,实现了 40 毫秒的引导延迟。预计如果为其他同态加密方案也设计专用硬件,加速效果也将达到3 个数量级的提升。
至于 CKKS 的引导时间,采用2021年论文Sine Series Approximation of the Mod Function for Bootstrapping of Approximate HE 中的实验数据,其引导误差为 2 − 25 2^{-25} 2−25。
参考资料
[1] Zama团队2022年11月16日博客 Bootstrapping for Dummies