[文献阅读] wav2vec: Unsupervised Pre-training for Speech Recognition
[文献信息]:[1904.05862] wav2vec: Unsupervised Pre-training for Speech Recognition 来自Facebook AI团队提出的word2vec模型结构,是用于语音数据的一种通用特征提取器。
摘要
当前用于语音识别的最新模型需要大量标记好的音频数据才能获得良好的性能。最近,在标注数据缺少的情况下,神经网络的预训练已经成为一种有效的技术。关键思想是先在有大量标记或未标记数据中进行general的训练,再在数据量受限的目标数据上fine-tune来提高下游任务的性能。对于需要大量工作来获取标记数据的任务(例如语音识别),这种预训练的方法尤其有效。
在本文中,作者提出了wav2vec模型,通过多层的卷积神经网络来提取音频的无监督语音特征。模型训练时的损失函数选取的是对比损失函数(contrastive loss),在训练时将正例间的距离拉近,负例间的距离拉远。
wav2vec
wav2vec是一个卷积神经网络,它将原始音频作为输入,并计算出一个可以输入到语音识别系统的通用表示。目标是需要将真实的未来音频样本与底片区分开的对比度损失。与以前的工作不同,wav2vec超越了逐帧音素分类,并应用学习到的表示来改进强监督ASR系统。wav2vec依赖于一种完全卷积的体系结构,与以前工作中使用的递归模型相比,该体系结构可以在现代硬件上随着时间的推移而容易地并行化。
该模型以原始音频信号为输入,采用两种网络结构。编码器网络将音频信号嵌入到潜在空间中,而上下文网络将编码器的多个时间步长组合起来,以获得上下文化表示。然后,两个网络都被用来计算目标函数。
整个模型分为两部分,encoder网络 f 和context网络 g ,分别得到浅层和深层的无监督语音特征,模型结构如图所示。
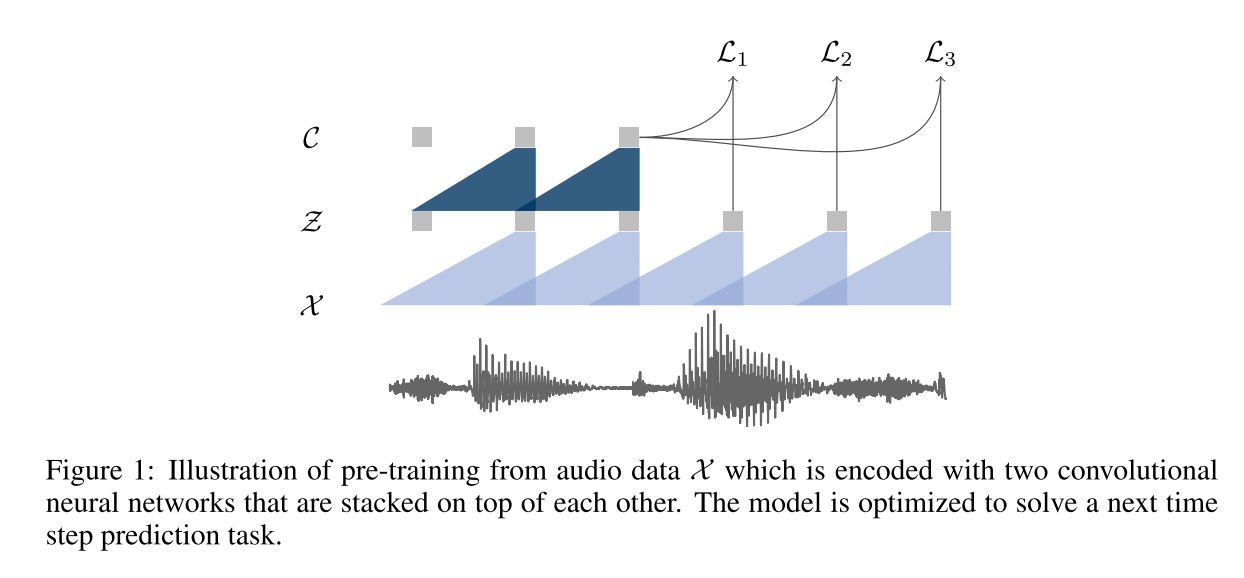
encoder网络 f : X → Z f:X→Z f:X→Z由5个卷积层组成,卷积核大小为10、8、4、4、4,步长为5、4、2、2、2。对于16kHZ采样率的音频,输出的特征 $z_i $编码的帧长为30ms,帧移为10ms。context网络 g : Z → C g:Z→C g:Z→C通过输入多帧浅层特征 z i z_i zi,得到基于上下文的深层语音特征 c i c_i ci。它由9个卷积层组成,卷积核大小为3,步长为1,最终的感受野为一帧210ms。
对于大型的数据集,作者在上述模型的基础上提出了wav2vec large模型。为了增强模型的特征提取能力,encoder网络 f 增加了两个线性层,context网络 g 增加为12个卷积层,卷积核大小为(2,3,…,13),同时加入了skip connection。
目标函数
模型的loss中自然要包含预测未来某个z的损失。然而仅仅有正例是不够的,因此作者利用了负采样技术,作者从一个概率分布pn中采样出负样本z~,最终模型的loss为区分正例和反例的对比损失contrastive loss:
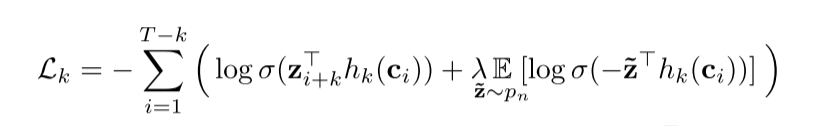
这里σ(⋅)是sigmoid函数。另外,上式中hk(ci)=Wkci+bk是一个step-specific的linear layer,即对每个k都有一个对应的linear layer。
我们把所有k对应的loss相加就得到了最终的loss;作者在实验中每次采样10个负例来估计它。训练完成之后我们就可以使用得到的特征来替换一些任务中原本使用的特征,这里作者在实验中使用了ASR,因此使用ci替换了在acoustic model中使用的log-mel filterbank特征。
正负例选取
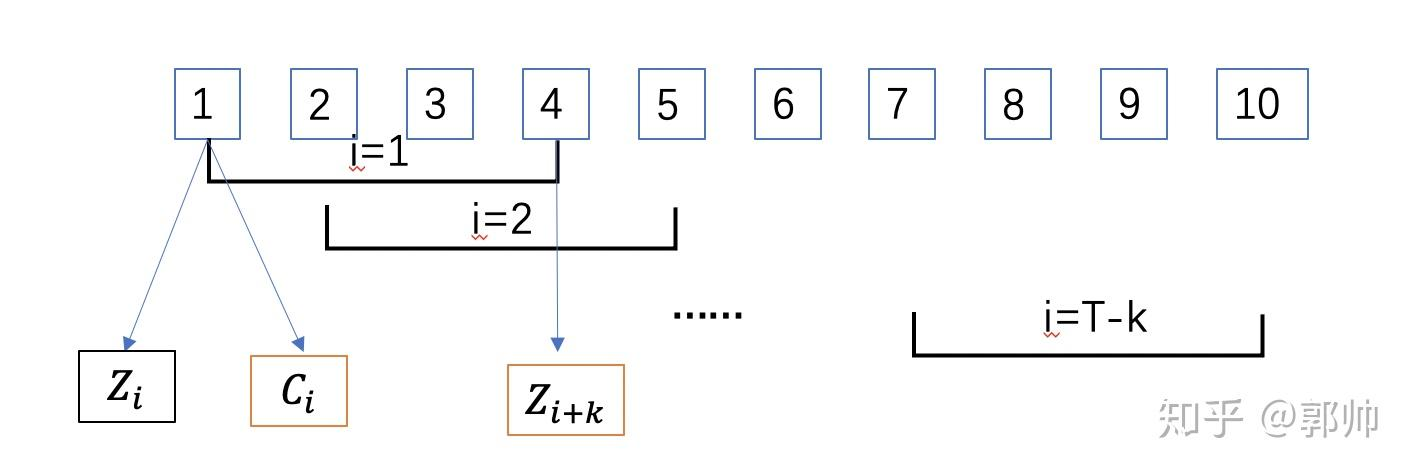
假设我们有一段10帧的音频sample,k(step)=3。当i=1时,anchori即为 第一帧的深层无监督特征 C 1 C_1 C1 ,正例 Z i + k Z_{i+k} Zi+k即为第4帧的浅层无监督特征 Z4 ,那么此时数据集中除了前面提到的anchor C 1 C_1 C1和正例 Z i + k Z_{i+k} Zi+k 外,其余的所有帧都是他们的负例。此时随机选取 λ 个负例进行对比损失函数的计算。其余k=1,…,K的情况与此类似,将所有步长的结果求和得到最后的损失值。
结果
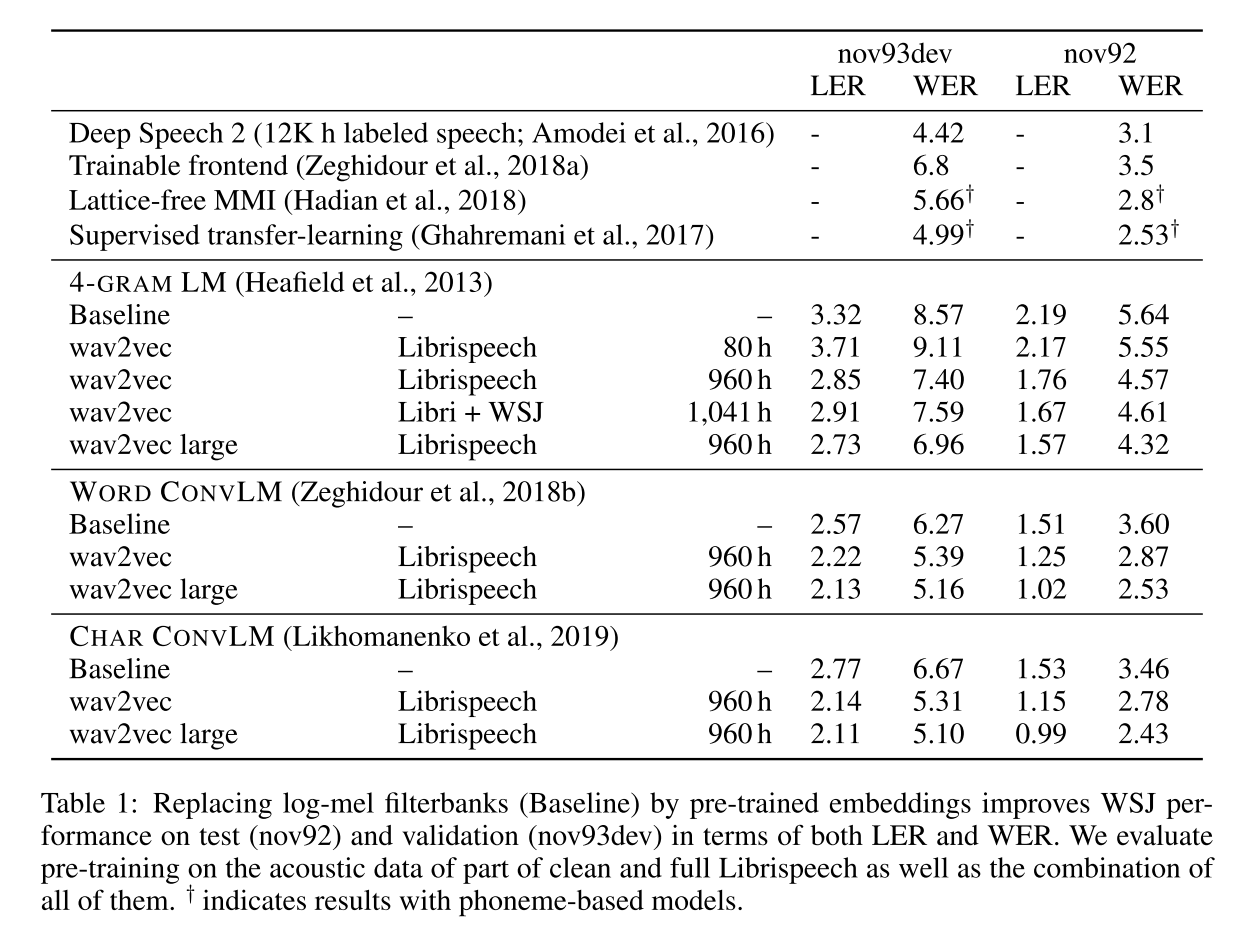
作者在 81小时标注完整的Wall Street Journal(WSJ)数据集上进行语音识别的测试,在其中的子集si284上进行下游任务的训练,nov93dev进行模型的验证,nov92上进行测试。在wav2vec模型预训练阶段,作者分别选用了完整的81小时WSJ数据集、80小时干净的Librispeech数据集、完整960小时Librispeech数据集、上述数据集的并集进行训练。Baseline的声学模型使用的是80维f-bank特征,其他模型使用的是不同数据集上训练的wav2vec深层无监督语音特征。从图4中可以看出,wav2vec的无监督特征的效果要优于传统f-bank特征,同时随着预训练数据量的增加,wav2vec的效果会越来越好,甚至能逼近或超过当时的SOTA模型。
实验
word2vec是通用的语音音频特征提取模型,这里以语音情感识别分类任务为例子。
import numpy as np
import torch
import torch.nn as nn
from transformers import Wav2Vec2Processor
from transformers.models.wav2vec2.modeling_wav2vec2 import (Wav2Vec2Model,Wav2Vec2PreTrainedModel,
)class RegressionHead(nn.Module):r"""Classification head."""def __init__(self, config):super().__init__()self.dense = nn.Linear(config.hidden_size, config.hidden_size)self.dropout = nn.Dropout(config.final_dropout)self.out_proj = nn.Linear(config.hidden_size, config.num_labels)def forward(self, features, **kwargs):x = featuresx = self.dropout(x)x = self.dense(x)x = torch.tanh(x)x = self.dropout(x)x = self.out_proj(x)return xclass EmotionModel(Wav2Vec2PreTrainedModel):r"""Speech emotion classifier."""def __init__(self, config):super().__init__(config)self.config = configself.wav2vec2 = Wav2Vec2Model(config)self.classifier = RegressionHead(config)self.init_weights()def forward(self,input_values,):outputs = self.wav2vec2(input_values)hidden_states = outputs[0]hidden_states = torch.mean(hidden_states, dim=1)logits = self.classifier(hidden_states)return hidden_states, logits# load model from hub
device = 'cpu'
model_name = 'audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim'
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = EmotionModel.from_pretrained(model_name).to(device)# dummy signal
sampling_rate = 16000
signal = np.zeros((1, sampling_rate), dtype=np.float32)def process_func(x: np.ndarray,sampling_rate: int,embeddings: bool = False,
) -> np.ndarray:r"""Predict emotions or extract embeddings from raw audio signal."""# run through processor to normalize signal# always returns a batch, so we just get the first entry# then we put it on the devicey = processor(x, sampling_rate=sampling_rate)y = y['input_values'][0]y = y.reshape(1, -1)y = torch.from_numpy(y).to(device)# run through modelwith torch.no_grad():y = model(y)[0 if embeddings else 1]# convert to numpyy = y.detach().cpu().numpy()return yprint(process_func(signal, sampling_rate))
# Arousal dominance valence
# [[0.5460754 0.6062266 0.40431657]]print(process_func(signal, sampling_rate, embeddings=True))
# Pooled hidden states of last transformer layer
# [[-0.00752167 0.0065819 -0.00746342 ... 0.00663632 0.00848748
# 0.00599211]]总结
本文提出了全卷积神经网络wav2vec模型,这是无监督预训练技术在语音识别任务中的首次应用。作者在WSJ的测试集上实现了2.43%的WER,这一结果优于当时基于字符的语音识别系统的SOTA,同时使用的转录数据少了两个数量级。相关实验结果显示,随着数据量的增加,语音识别的效果也在稳步增加,缓解了语音任务中完全标注的数据量不足的问题。