【基础IO下】磁盘/软硬链接/动静态库
前言:
文件分为内存文件和磁盘文件。磁盘文件是一个特殊的存在,因为磁盘文件不属于冯·诺依曼体系,而是位于专门的存储设备中。因此,磁盘文件存在的意义是将文件更好的存储起来,一边后续对文件进行访问。在高效存储磁盘文件这件事上,前辈研究出了十分巧妙的管理手段及操作方法,而这些手段和方法共同构成了我们今天所谈的文件系统。
文件系统是操作系统中负责管理持久数据的子系统,简单点就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久的保存起来。
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,组织方式的不同,就会形成不同的文件系统。
1.认识磁盘
1.1 物理结构
磁盘属于外设,是一个机械结构,所以相对于CPU和内存而言,磁盘的速度非常慢。

如上图所示:
主轴和马达电机:在主轴上套着多张盘片,它们和轴相固定,通过马达电机来驱动这些盘片一起转动。
磁头:每一张盘片都有两个盘面,每一个盘面上都有一个磁头,该磁头是用来向磁盘中读写数据的。多个磁头也是叠放在一起的,它们是整体一起移动的。计算机在寻址时,不是一个磁头在一个盘面上寻找,而是一摞磁头在所有盘面上、同样的磁道上寻找。
音圈马达:该马达驱动磁头组进行摆动,它可以从盘片的内圈滑到外圈,再结合盘片自身的转动,从而向磁盘读写数据。
机械设备的控制是需要时间的,因此导致机械硬盘读写数据的速度相对于CPU和内存来说比较慢。
1.2 存储结构
1.2.1 数据存储
数据是以0和1的方式进行存储的,常见的存储介质有:强信号与弱信号、高电平与低电平、波峰与波谷、南极与北极等,而盘面上比较合适的是南极与北极。
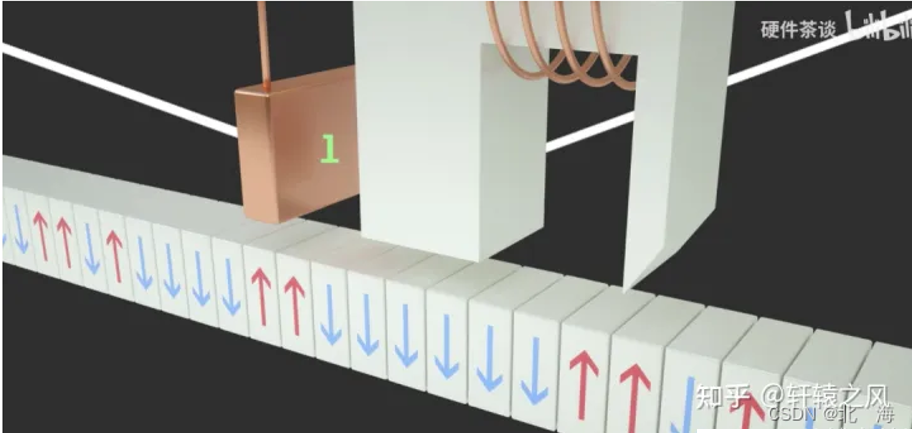
当磁头移动到指定位置时,向磁盘中写入数据:N->S,删除磁盘中的数据:S->N。磁盘中数据读写的本质:更改基本元素的南北极、读取南北极。
注意:磁头并非与盘面进行直接接触,而是以15纳米的超低距离进行磁场更改。
这个距离相当于一架民航客机距离地面1米左右的距离进行超低空飞行,所以如果磁头制作工艺不够精湛,可能会导致磁头在写入/读取数据时,与盘面发生摩擦(高度旋转)发热,从而导致磁场消失,该扇区失效,数据丢失。
所以机械硬盘不能进入灰尘,也不能在其运行时随意移动,因为角度的偏转也有可能导致发生摩擦,造成数据丢失,更不能用力拍打机械硬盘。
1.2.2 存储结构
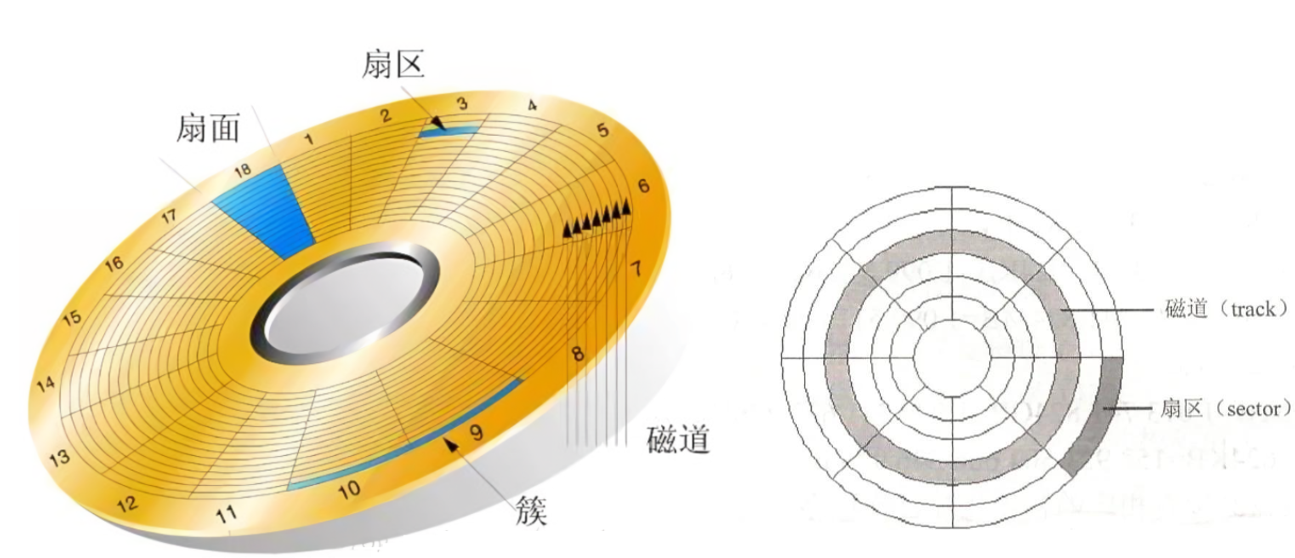
在磁盘的盘面上,磁盘被一个个的同心圆以及射线进行分割,从而出现了:磁道、扇面、扇区。
- 扇区:被一个个的同心圆以及射线分割出的一个个扇形区域。
- 扇面:两条相邻的射线之间夹的所有扇区构成的扇面。
- 磁道:盘面上半径相同的扇区构成一个磁道。
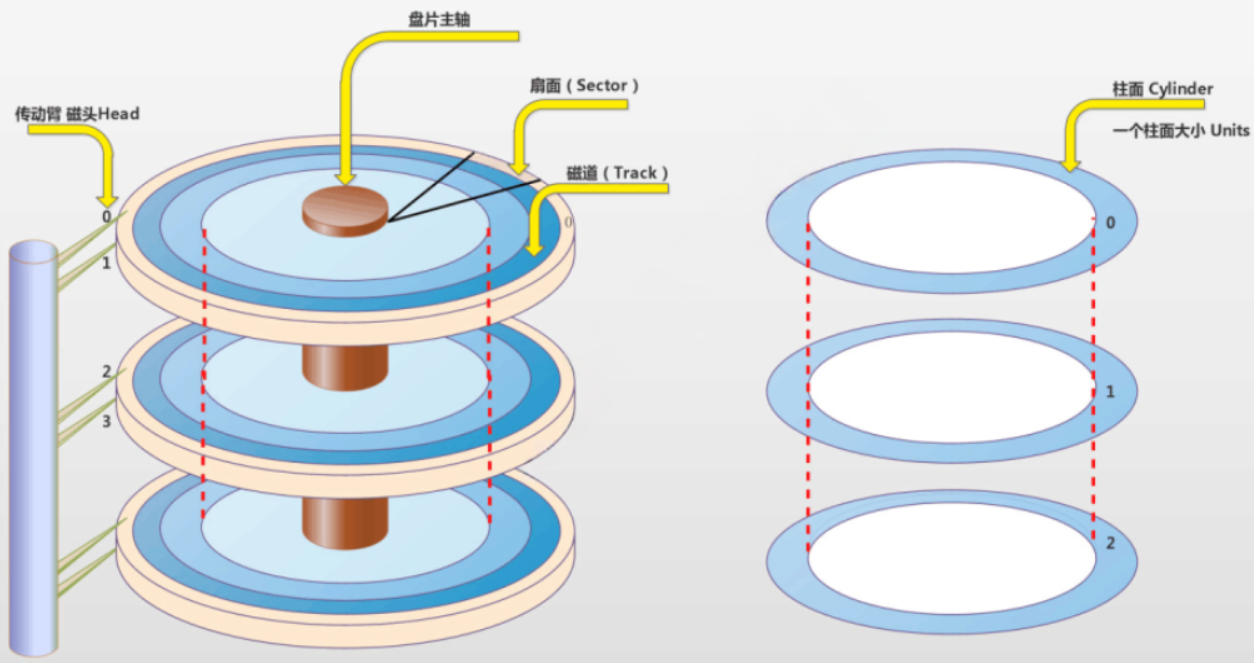
- 柱面:由于现实世界中磁盘的立体结构,所以把空间中所有半径相同的磁道定义为一个柱面。即磁盘的符时图中,所有同心的磁道叫做柱面。柱面等价于磁道。
磁盘寻址时,基本单位不是bit,也不是byte,而是扇区。每个扇区的大小都是512byte。由于扇区是最小的存储单元,所以在硬件的角度:一个文件(内容+属性)无非是占用一个或多个扇区进行数据的存储。
那么在硬件上磁盘是怎么定位一个扇区呢?----答案是CHS定位法!cylinder柱面、head磁头、sector扇区。
- 磁盘中的磁头是有编号的,我们首先根据扇区所在的盘面确定使用几号磁头。
- 每个扇区都有自己所在的磁道,根据扇区所在的磁道就可以确定磁头的偏移位置。
- 每个扇区所在的扇面上都已经被编好了号码,磁头最后根据扇面所在的号码确定扇区。
磁道的周长不一样(越靠近外圈,磁道越长),但是每个磁道存储的数据量是一样的。磁头来回摆动时, 就是确认在哪个磁道。盘片旋转时,就是让磁头定位所在的扇区。
我们既然能够通过CHS定位一个扇区,那么也能定位多个扇区,从而将文件能够从硬件的角度进行读取和写入。
1.3 磁盘的逻辑抽象
由上文的内容,我们知道能够通过CHS去定位一个文件的基本单元,但是操作系统是不是采用这种方式去定位磁盘中的数据呢?不是。
这主要有以下两点原因:
1、操作系统是软件,磁盘是硬件,硬件通过CHS定位扇区,操作系统如果采用和硬件一样的定位方式就会和硬件之间产生很大的耦合关系,如果我们的硬件变了(例如:机械磁盘变为固态硬盘),那么操作系统也要进行变化,这并不是一个好的情况。
2、扇区的大小是512byte,以扇区为单位进行IO时的数据量太小了,在进行大量IO时会极大的影响到运行的速度。
操作系统实际进行IO时,是以4kb为单位的(这个大小是可以调整的)4kb=512*8byte,因此将8个扇区定义为一个块,操作系统按照一个块的单位进行IO。
磁盘片的物理结构是一个圆环型结构,假设我们能够将每一个盘面按照磁道进行拉伸展开(就像使用胶带一样),那不就变成了一个线性结构了吗?如下图所示。
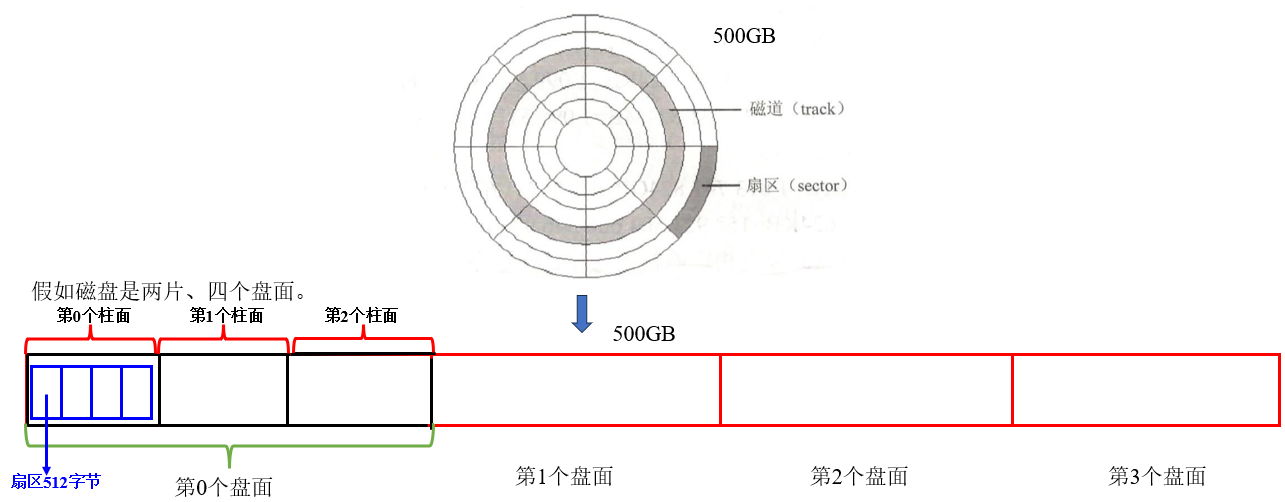
展开以后对应每一个磁道里面都有很多扇区,这些扇区组合起来便可以被抽象为一个数组。
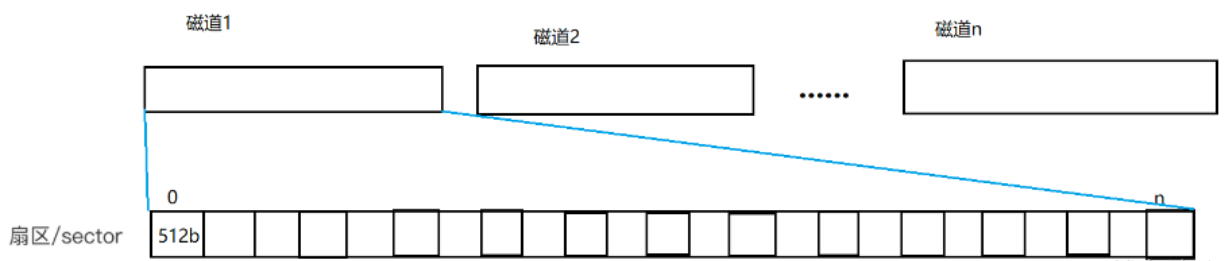
但是这个数组太大了,而且每一个单位的数据量有点太小了,我们还要对其进行抽象,我们将8个扇区组成一个块,这样数组的长度就缩短了8倍。经过这一层抽象后,由原来的扇区数组变成块数组。
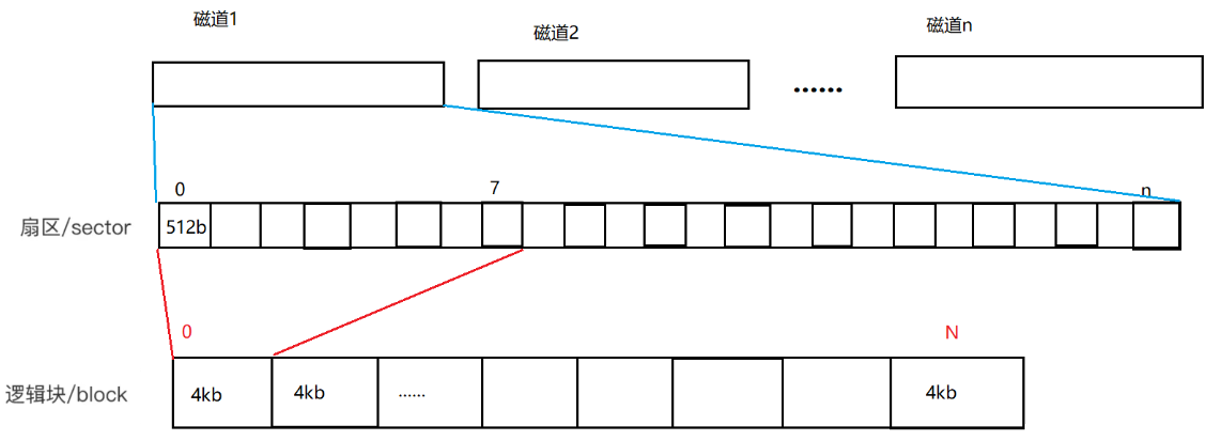
其中逻辑块的数组下标被定义为逻辑块地址(LAB地址),现在操作系统像访问具体的扇区时,只需要通过起始扇区的地址+偏移量就可以获取LBA地址,然后通过特定的手段转为CHS地址,交给外设进行访问即可。LBA和CHS的转换操作的原理类似于指针的解引用,具体可参考LBA和CHS的转换。
于是操作系统通过LBA地址进行访问存储的数据,这就是操作系统对磁盘等存储硬件的逻辑抽象。因此对于外设中文件的管理,经过先描述、再组织后,变成了对数组的管理,这个数据就是task_strcut中的struct block。
最后我们就能理解为什么IO的基本单位是4KB了,因为直接读取一个数据块(4KB),这样可以提高IO效率(内存对齐)。
2.磁盘信息
2.1 具体结构
经过上面的抽象我们操作系统便拿到了一个逻辑块的大数组,但是这个数组太大了,我们对于这个大数组的直接管理还是太过于困难了。操作系统可以对这个大数组进行分区管理(类似于windows的分盘),当我们管理好了一个分区,就可以将一个分区的管理方法复制到其他分区的管理中去,从而实现全局的数据管理。
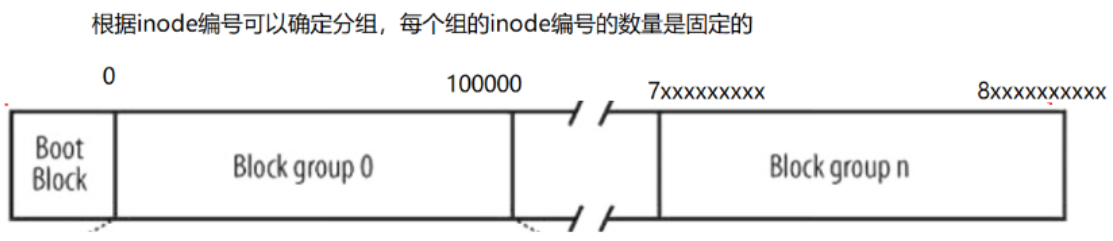
但是每个分区的数据还是太大了,操作系统还要对每一个分区进行分组,通过分组再次降低管理的难度,每个分区里面有很多分组,其中每个分区其内部的结构如下图:
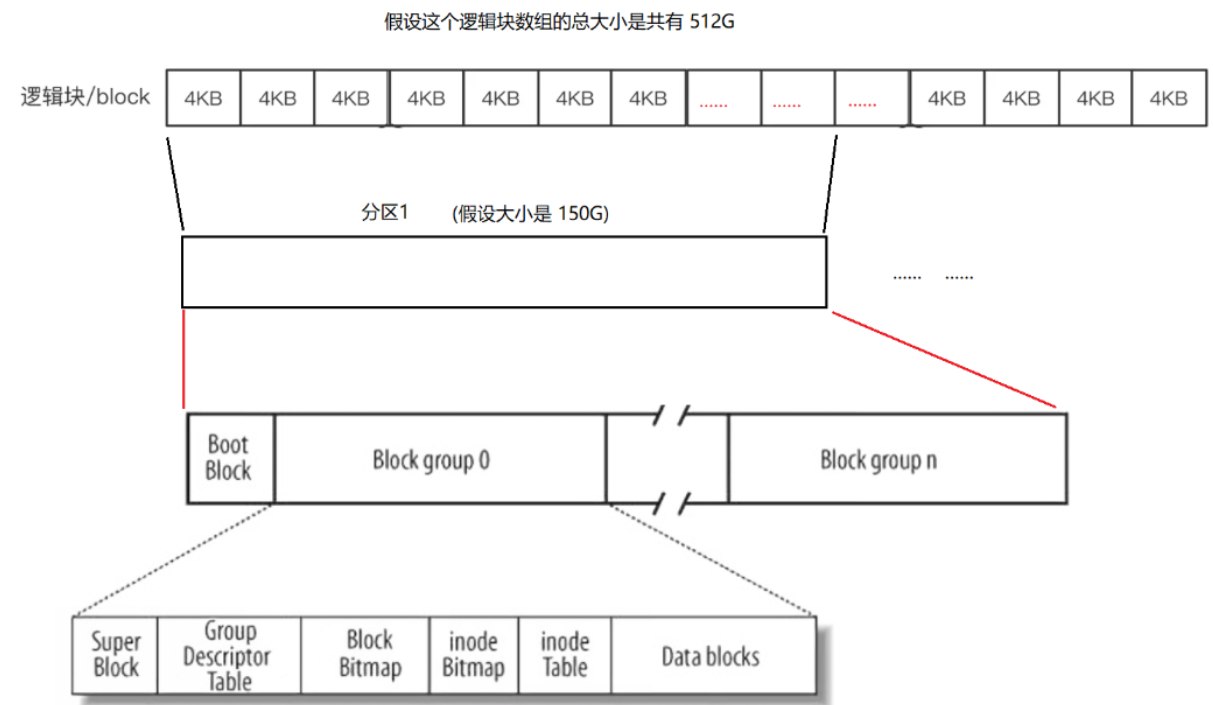
Boot Block:里面存放的是与操作系统启动相关的内容,诸如:分区表、操作系统镜像的地址等,一般这个区域被放在磁盘的0号磁头、0号磁道、1号扇区中,如果这个区域的内容受到破坏,那么操作系统将无法启动。
超级块(SuperBlock):SuperBlock超级块属于整个分区,那么超级块怎么放在了Block group 0的内部呢?在文件系统里可能会有一定比例的Block group是以Super Block开头的,即分组里Super Block不是必须的,可以不要它。Super group属于整个文件系统,正常情况应该放在Boot Block的位置,在整个分区的最开始的位置。那么为什么Super Block在多个分组中都存在呢?都存在意味着备份,Super Block被保存在了不同的分组里面,内容都是一样的。如果某个Super Block损坏了,再把其他分组的Super Block拷贝过来,至此就完成了文件的恢复。
超级块存放系统本身的结构信息,记录的信息主要有:block和inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
GDT(Group Descriptor Table):块组描述符,描述块组属性信息。比如:该分组一共有多少个inode、数据块以及被使用了多少。
块位图(Block Bitmap):Block Bitmap中记录着Data Blocks中哪个数据块已经被占用,哪个数据块没有被占用。假如Data Blocks中总共有10000个数据块,那么块位图中就对应有10000个比特位,两者之间是一一对应关系。哪个数据块被占用,那么块位图中对应的比特位就由0置为1;哪个数据块被释放,块位图中对应的比特位就由1置为0。比如:要创建一个文件,假如需要10个数据块,那么就在块位图中找到对应的比特位,并将0置为1,代表将该数据块给你了,那么就可以将数据往对应的数据块中存放了。
inode位图(inode Bitmap):每个比特位表示对应的inode是否空闲可用。
inode Table:一般来说,一个文件内部的所有属性被保存在一个inode节点中(一个inode节点的大小一般是128字节),一个分区会存在大量的文件,所以一个分区中会有大量的inode节点,每一个inode节点都有自己的编号,这个编号也属于文件属性。为了更好的管理inode节点,就要有一个专门的区域存放所有的inode节点,这个区域就是inode Table,其内部可以看成一个数组结构。
在创建文件时,需要有查找功能。比如查找哪个inode以及数据块有没有被占用。inode Bitmap是inode对应的位图结构,inode Table中的每一个inode都与位图中的比特位一一对应。位图中比特位的位置代表的是第几个inode,比特位为0代表该inode没有被占用,为1代表该inode被占用。假如inode Table中有1000个inode,那么inode Bitmap中就有1000个比特位,可使用该1000个比特位来表示哪些inode被占用、哪些inode没有被占用。我们创建文件时,首先就在inode Bitmap中寻找第一个不为1的比特位,找到之后,将该比特位由0置为1,再拿比特位的偏移位置,再在inode Table中找到对应的inode,再将文件属性填写进去。
数据区(Data blocks):里面是大量的数据块,每一个数据块都可以用来存放文件内容。
细节注意要点:
1、每一个块组都有Block Bitmap、inode Bitmap、inode Table、Data block,其他部分某些块组可能没有;
2、Super Block在每一个块组里都可能存在也可能不存在,但至少要有一个块组存在超级块!而且每一个存在超级块的块组里面的超级块是一样的,并且所有存在超级块的块组其里面的超级块是联动更新的;
3、超级块存在多份的意义是:万一其中一个超级块损坏,还有其他超级块可以使用,并且可用利用其他完好的超级块去修复以及损坏的超级块。不至于一个超级块损坏导致整个分区的文件系统直接损坏;
4、inode节点中有一个数组,这个数组里面存放了对应文件使用的数据块的编号;
5、inode编号不能跨分区使用,每一个inode编号在一个分区内唯一有效;
6、根据inode可用确定一个分区的分组。
假如我知道某个文件的inode编号,首先查找inode Bitmap,确认inode Bitmap的比特位是0还是1,是1说明该inode是有效的。然后查找inode Table,对比发现该文件的inode编号与inode Table中的编号是一样的,所以这个文件的属性就拿到了。
2.2 重新认识目录
在Linux的命令行中,我们可用使用ls -li命令查看文件的inode编号:
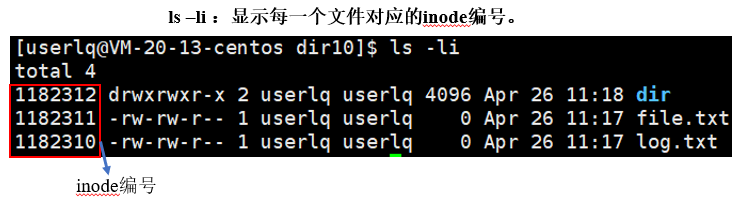
其实在Linux中,系统对于文件只认识inode编号,并不认识文件名,那么为什么我们平时一直使用的都是文件名,没有使用过inode编号,但是我们依旧可以操作文件呢?
这其实和目录有关,我们打开的任意一个文件都是在一个目录里面打开的,而且目录本身也是文件,目录也有inode编号,目录里面也有内容,也需要数据块,目录里面的内容是:该目录下文件名与该文件的inode映射关系。
因此当我们使用文件名时,目录会自动帮我们找到对应的inode编号,完成相应的要求。
例如我们在Linux下使用cat xxx.xx命令,其大致的执行过程是:
1、在目录下找到log.txt的inode编号;
2、利用inode编号在inode Table中找到inode;
3、根据inode找到xxx.xx文件使用的数据块的编号;
4、根据数据块的编号找到数据块,将内容提取出来并刷新到显示器上面。
注:如果xxx.xx文件使用的数据块的编号有4个,那么就有4个数据块,将该4个数据块进行组合,该文件的内容就找到了。
3.理解文件系统中的增删改查
查:见上一章节中的cat xxx.xx文件的例子。
删:
1、根据当前要删除的文件名到目录中找到对应的inode编号;
2、根据inode编号到inode Table中找到inode节点;
3、根据inode节点中的内容找到该文件对应的Block Bitmap,然后将对应的比特位进行置0表示内容的删除;
4、根据inode编号将inode bitmap对应的比特位置0表示属性的删除;
5、将当前目录中inode编号与文件名的映射关系进行删除。
在任意文件系统里,要删除一个文件,根本不需要将文件的属性和内容清空,而是采用惰性删除的方式,只要找到该文件的inode在inode Bitmap中的比特位,将该比特位由1置为0,文件就删除了。
增:(创建一个内容为空的文件)
1、操作系统在inode bitmap中从低向高依次扫描,将找到的第一个比特位为0的位置置为1;
2、然后在inode Table中的对应位置写入新的属性;
3、然后向当前目录中增加新的inode编号与文件名的映射关系。
改:
1、根据当前的文件名到目录中找到对应的inode编号;
2、根据inode编号到inode Table中找到inode节点;
3、计算需要的数据块的个数,在Block bitmap中找到未使用的数据块,并将相应的比特位由0置成1;
4、将分配给文件的数据块的编号填入inode中;
5、将数据写入到数据块中。
补充细节:
1、如果文件被误删了,该怎么办?数据应该怎么样被恢复?(我们在这里只讨论大致的原理)
答案是:最好什么都不要做,因为Block bitmap被置为0以后,相应的数据块就已经不受保护了,此时再创建新文件就有可能覆盖原来的文件。
2、数据恢复的原理是:Linux系统为我们提供了一个日志,这个日志里面的数据会根据时间定期刷新,所有被删除的文件的inode编号在这里都有记录,通过被删除文件的inode编号,先把inode bitmap相应位置的比特位由0置为1,然后根据inode编号到inode Table中找到对应的数据块编号,然后到Block bitmap中将相应位置的比特位由0置为1。
3、上面我们说的分区、分组,填写系统属性是谁在做?什么时候做呢?
答案是:是操作系统在做!是在格式化的时候做的。在我们操作系统分区完成以后,为了能让分区能够正常使用,需要对分区进行格式化,格式化的本质就是:操作系统向分区写入文件系统管理属性的信息。
4、inode里面只是用数组来与数据块进行单纯的一一映射吗?
答案:并不是。如果一个inode里面存放数据块编号的数组大小是15,如果只是单纯的一一映射的关系,那么一个文件只能存储15*4KB=60KB的内容,这显然是不合理的。
所以inode里面存放数据块编号的数组被规定它的前几个下标是直接索引,中间几个是二级索引,后面几个是三级索引,...
直接索引:直接指向数据块;
二级索引:指向一个数据块,这个数据块里面的内容是直接索引;
三级索引:指向一个数据块,这个数据块里面的内容是二级索引。
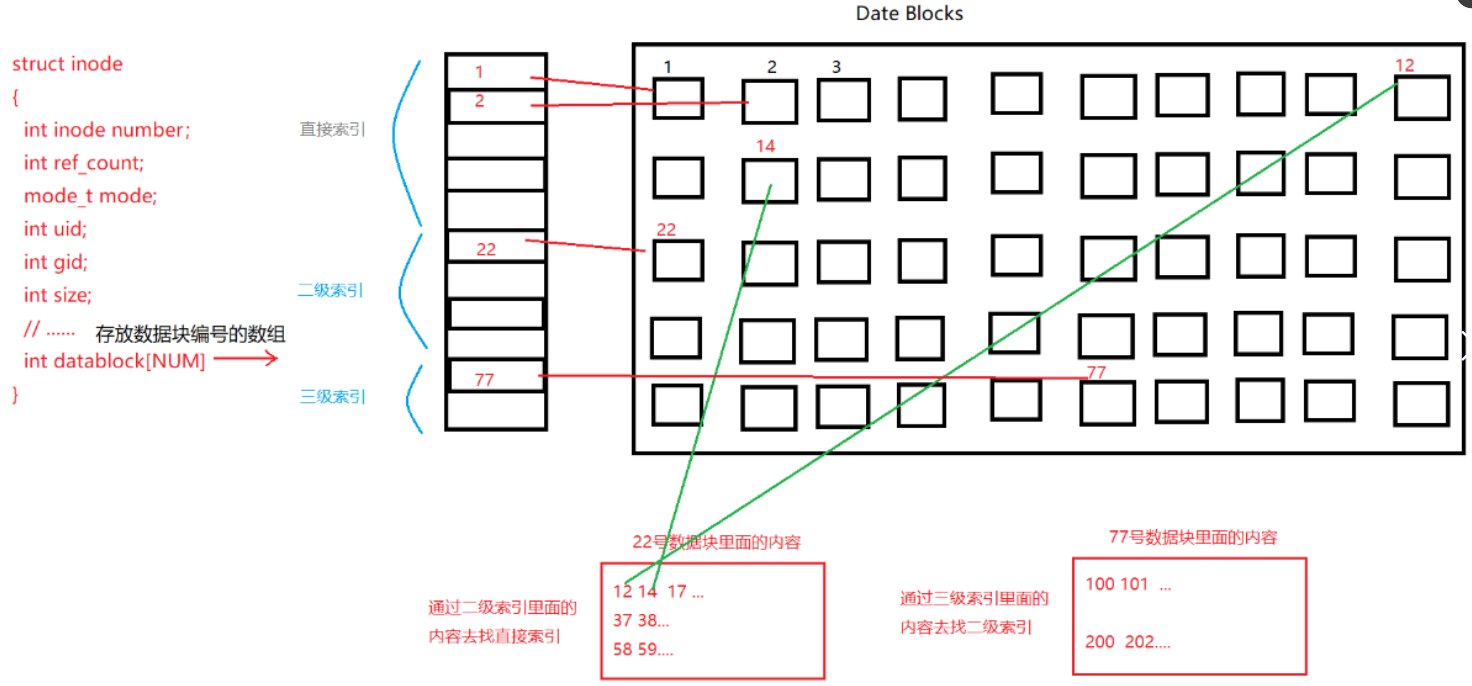
二级索引对应的数据量单位:4KB/4*4KB=4MB。
三级索引对应的数据单位:(4KB/4)^2*4KB=4G。
有没有一种可能,一个分组,数据块没用完,inode没了,或者inode没用完,数据块用完了?
答案:有可能的,如果我们一直创建空文件,就可能导致inode使用完了,而数据块没有使用完;如果我们将所有的内容都放在一个文件中,就可能导致inode没有使用完,而数据块使用完了。
4.软硬链接
4.1 软链接
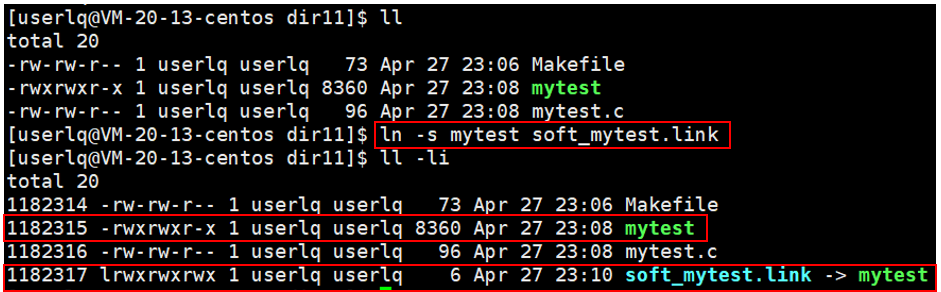
当有某个文件在一个很深的目录中时,我们要去使用这个文件时会很不方便。那么有没有一种方式能够让我们很轻松的找到这个文件并使用它呢?有的,那便是软链接。软链接非常类似于window中的快捷方式。
我们可以在当前目录中使用命令 ln -s 文件名 软链接名 建立一个软连接,其中软链接名可以自定义,如下图所示,mytest文件的软链接soft_mytest.link指向了文件mytest,文件类型为l,l即为链接文件。文件mytest的inode值为1182315,文件mytest的软链接soft_mytest.link的inode值为1182317,一个文件一个inode、一个inode一个文件,即soft_mytest.link有自己独立的inode,则是一个独立的文件。
那么软链接有什么用呢?
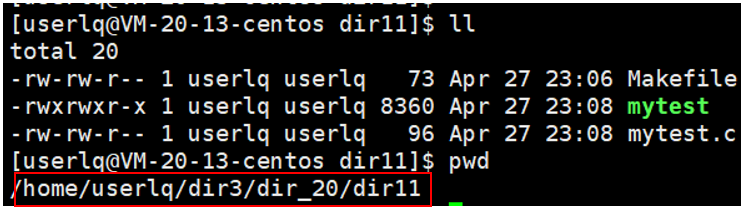
如上如所示,mytest文件的在路径 /home/userlq/dir3/dir_20/dir11下,如果我在目录userlq下该如何执行mytest可执行程序呢?如下图所示,可以通过该可执行程序的路径执行,但是该方式带了一长串的路径,如前文所述该可执行程序使用起来很不方便。
![]()
此外,创建一个软链接,可以直接在目录userlq下执行该可执行程序。
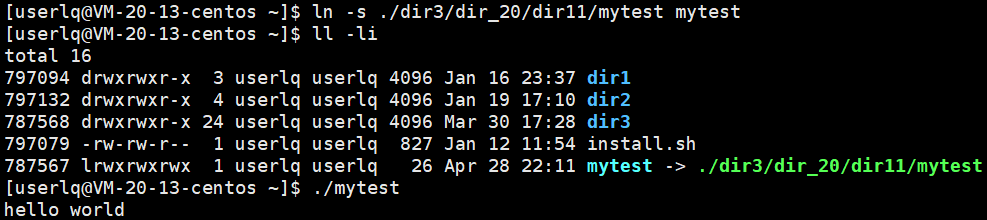
4.2 硬链接
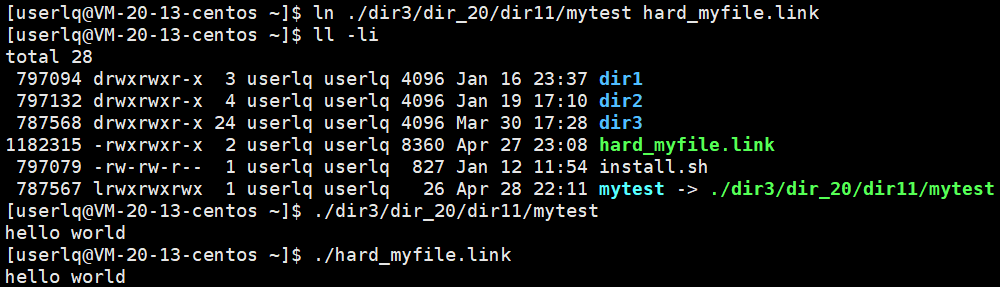
生成硬链接文件就更简单了,对文件mytest进行硬链接,生成硬链接文件hard_myfile.link,硬链接名可以自己定义。
ln 文件名 硬链接名 不带参数默认是硬链接
可以看到,执行硬链接与执行源可执行程序没有任何区别:
而且硬链接的inode、属性、拥有者、所属组、文件大小、时间与源文件一模一样。
如下图所示,给myfile.txt文件创建了一个软链接、一个硬链接,源文件与硬链接的文件大小等属性都一样,文件大小均为0,软链接的文件大小为10。当往myfile.txt文件中写入数据后,源文件与硬链接的文件大小均变为了13,软链接大小依然为10。
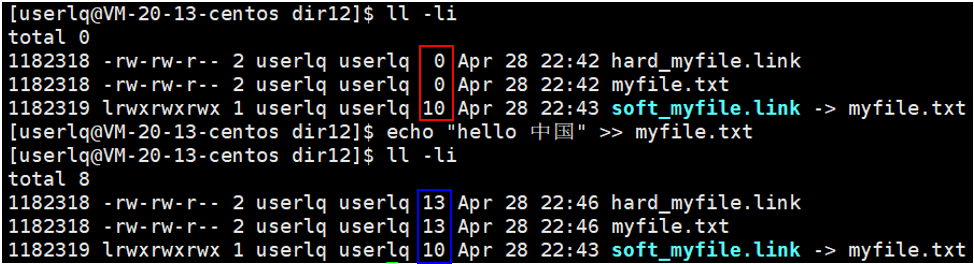

此时硬链接和源文件中的内容均相同。
那么建立硬链接究竟做了什么?
建立硬链接根本没有创建新文件!因为没有给硬链接分配独立的inode。既然建立硬链接没有创建文件,那么硬链接一定没有自己的属性和内容集合,硬链接使用的一定是源文件的inode和内容。如下图所示:
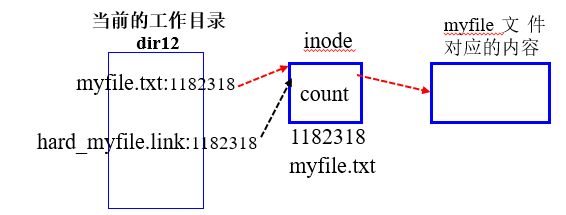
目录dir12中会保存文件名和inode之间的映射关系,myfile.txt指向的inode是1182318,所以我们就可以根据inode找到文件的内容。
创建硬链接时,只是在对应的目录下创建了硬链接文件名hard_myfile.link与文件myfile.txt的inode之间的映射关系。所以创建硬链接的本质就是在指定的路径下,新增文件名个inode编号的映射关系。
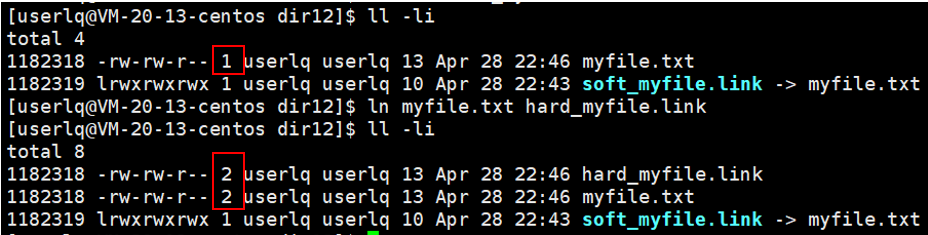
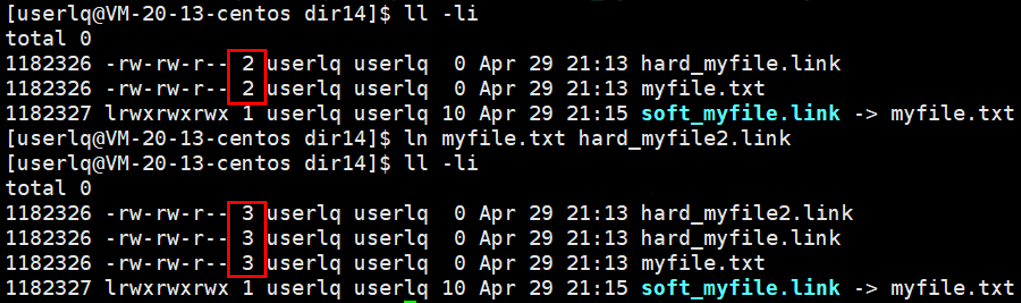
如上图所示,在未创建硬链接时,myfile文件的硬链接数为1,当创建硬链接后,myfile和hard_myfile.link文件的硬链接数变为2。
文件名在当前路径下是唯一的,新建了一组映射关系,相当于有了一个新的文件名指向了源文件的inode,所以inode可能会被多个文件指向。inode有自己的计数器cont,如果有一个文件名指向inode时,计数器会++,变成1,再有文件名指向inode时,计数器会++,变成2。count引用计数表征的是有多少文件名指向我,这个引用计数叫做硬链接数。

如上图所示,当我们删除文件myfile.txt时,myfile.txt文件的硬链接hard_myfile.link的硬链接数变为了1。那么一个文件怎么样才算被真正删除呢?当一个文件的硬链接数变为0时,这个文件才算真正被删除。如下图所示,硬链接的内容依然还是 hello 中国,则证明文件myfile.txt没有被删除。

4.3 软链接和硬链接之间的区别
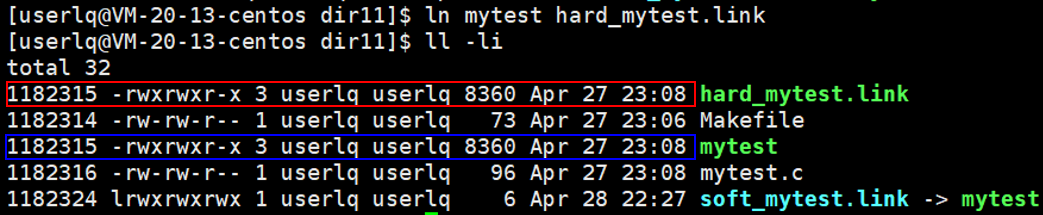
当我们创建一个文件时,在文件权限后面会有一个数字,这个数字就是硬链接数。我们查看一下它们的inode编号:
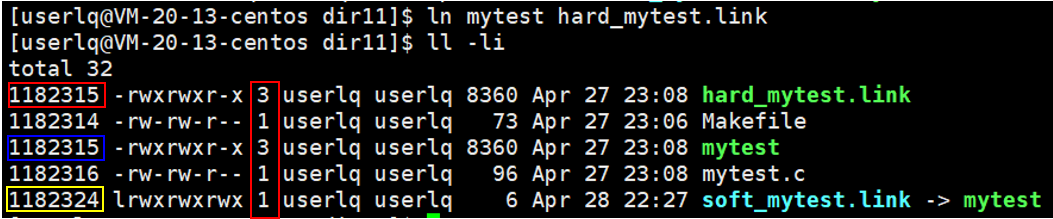
我们发现它们的编号并不相同,源程序的编号与硬链接编号一样,但是软链接就不一样。
区别一:
1、软链接文件的inode编号与源文件不同(独立存在),软链接文件比源文件小得多,软链接的内容就是自己所指向的文件的路径;
2、硬链接文件与源文件共用一个inode编号(源文件的别名),硬链接文件与源文件一样大,并且硬链接文件与源文件的链接数变成了2。
我们再给myfile文件创建一个硬链接,并且可以发现文件的硬链接数+1了,由2变成了3,再次证明了硬链接与源文件inode一样。
实现原理:
为什么源文件的inode编号与硬链接inode一样,并且源文件硬链接数会+1呢?与实现原理有关:
当我们创建硬链接时,操作系统在当前目录里面建立新的映射关系,操作系统把源文件的inode编号与硬链接建立映射关系,此时一个inode编号就有了两个文件名,同时inode节点中会有一个引用计数的变量ref_count。当我们建立一个硬链接时,这个引用计数的变量就会自增一下,表示硬链接数目+1:

软链接又称为符号链接,它是一个单独存在的文件,拥有属于自己的inode属性及相应的文件内容,不过在软链接的Data block中存放的是源文件的地址,因此软链接很小,并且非常依赖于源文件。
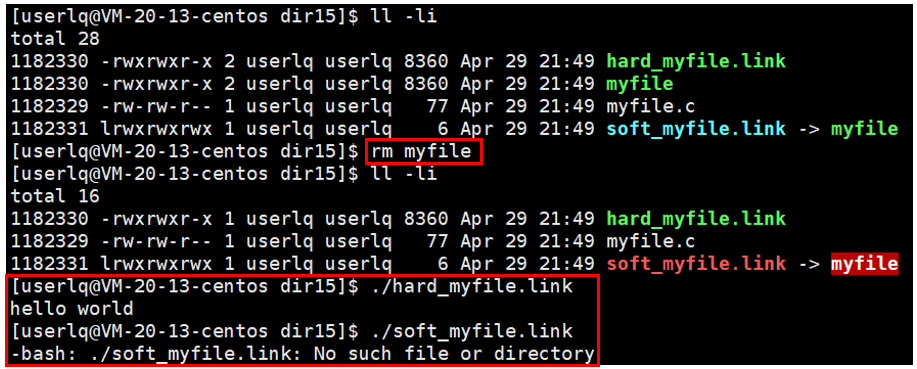
删除源文件,观察软硬链接有什么区别:
区别二:
1、当我们将源文件删除后,软链接失效,因为软链接文件依赖于源文件;
2、当我们将源文件删除后,硬链接仍然有效,因为硬链接文件是源文件的别名。
原理:
此时,我们发现1182330还存在,但是硬链接数变成1了。证明我们刚刚删除了一组映射关系,则引用计数就变成1了。
一个文件怎么样才能算被真正删除呢?当一个文件的硬链接数变成0时,这个文件才算是被真正删除。
删除myfile文件时,此时由于软链接所指向的文件被删除了,所以软链接失效了。执行./soft_myfile.link时,报错该文件不存在。实际上该文件还存在,软链接标定一个文件时,不是使用目标文件的inode标定的,而使用的是目标文件的文件名来标定的。软链接是一个独立的文件,有自己独立的inode和对应的文件内容。将文件myfile删除之后,软链接就找不到了,说明软链接有查找目标文件的方式。在树状结构中,是通过路径查找文件的。软链接是一个独立的文件,有自己的数据块,该数据块保存的是软链接所指向的目标文件的路径。删除软链接不会影响源文件,软链接相当于windows系统下的快捷方式。
当删除一个文件时,目录会正常帮我们删除文件名与inode的映射关系,但是操作系统不一定会帮我们删除该文件。操作系统会将该文件对应的inode节点中的引用计算变量自减一下,如果减完之后等于0就删除文件,否则只是修改了引用计数变量。
这也就解释了为什么删除源文件后,硬链接文件不受任何影响,仅仅只是硬链接数-1。同理,删除硬链接文件,也不会影响源文件。
为什么新建目录的硬链接数为2?

如上图所示,为什么新建目录的链接数为2,而新建的普通文件的链接数为1?
因为一个普通文件本身就有一个文件名和自己的inode,两者具有一个映射关系,所以默认的链接数就是1。

进入到empty目录里,里面有 . 和 .. 两个目录。empty目录的inode是1182334,. 目录的inode值也是1182334。. 目录叫做当前目录,即empty目录。. 目录就是empty目录的硬链接。
因为有两组文件名,即目录empty和 . 目录去映射inode,故empty目录的硬链接数为2。
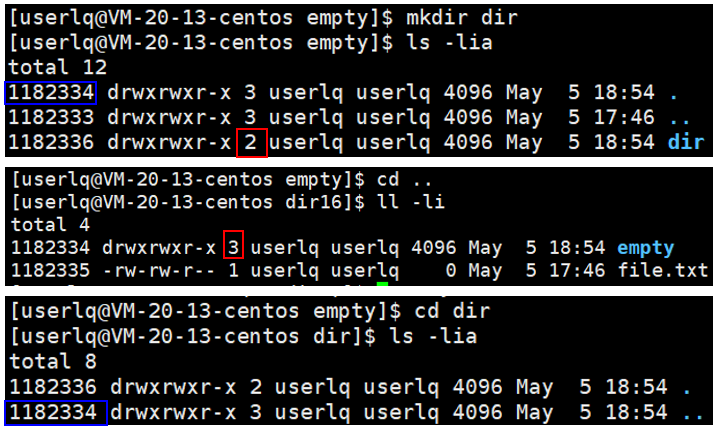
我们在empty文件中创建了一个目录dir,我们发现目录dir的硬链接数是2,但是目录empty的硬链接数变成3了。
empty目录的inode是1182334,进入到empty目录下,该目录下的 . 目录的inode也是1182334。在empty目录下有个dir目录,该目录下有个 .. 目录,该目录的inode也是1182334。所以empty目录的硬链接数为3。
cd .. 称为回到上级目录,那么cd .. 为什么能够回到上级目录呢?因为dir目录下的 .. 指向的dir目录的上级目录empty。
在一个树状结构中,每个目录里面都有 . 目录和 .. 目录,其中 . 目录指向该目录自己,.. 目录指向的是该目录的上级目录。这就是为什么新建目录,在该新建目录下再新建目录,该目录的硬链接数会发生变化的原因。
Linux中的目录结构为多叉树,即当前节点(目录)需要与父节点(上级目录)、子节点(下级目录)建立链接关系,并且还得知道当前目录的地址,否则就会导致切换目录时出现错误。
![]()
由上图所示,操作系统拒绝了指令,操作系统不允许给一个目录建立硬链接,因为给目录建立硬链接可能导致环路路径问题。
为了避免因为用户的误操作而导致的目录环状问题,规定用户不能手动给目录建立硬链接关系,只能由操作系统自动建立硬链接。比如建立新目录后,默认上级目录和当前目录建立硬链接文件,在当前目录下创建新目录后,当前目录的硬链接数+1。
4.4 取消链接
取消链接的方式有两种:
1、直接删除链接文件;
2、通过unlink命令取消链接关系。
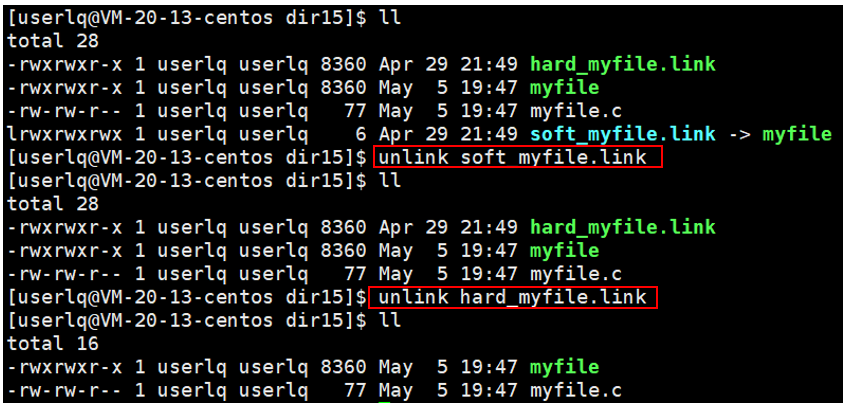
5.ACM时间
每个文件都有三个时间:访问Access、修改属性Change、修改内容Modify,简称ACM时间。可以通过stat查看指定文件的ACM时间信息。
可以通过stat指令查看指定文件的ACM时间信息。
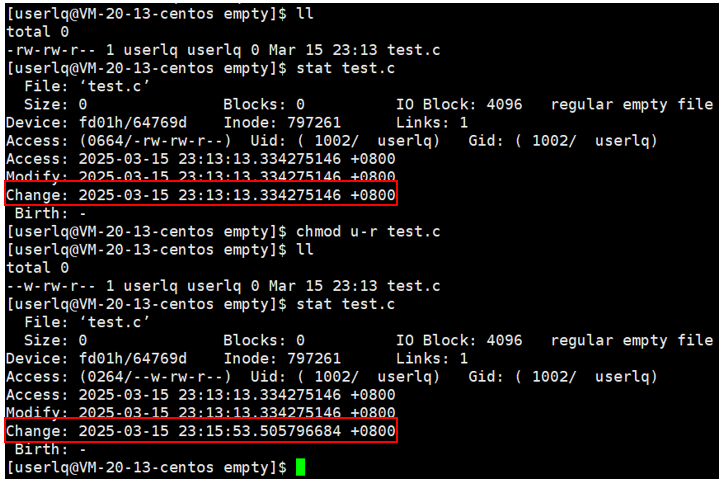
这三个时间的刷新策略如下:
Access:最近一次查看文件内容的时间,具体实现取决于操作系统;
Change:最近一次修改文件属性的时间;
Modify:最近依次修改文件内容的时间(文件内容修改后,属性也会跟着修改)。
Access是高频操作,如果每次查看都更新的话,会导致IO效率变低,因此实际变化取决于刷新策略:查看N次后刷新。
注意:修改文件内容一定会导致文件的属性时间被修改,但不一定会导致访问时间被修改。因为可以在不打开文件的前提下,对文件进行操作。比如直接重定向到文件:echo "..." xxx.xx。

6.动静态库
6.1 什么是库
简单来说:库是一些可重定向的二进制文件,这些文件在链接时可以与其他的可重定向的二进制文件一起链接形成可执行程序。
一般来说库被分为静态库和动态库,它们是由不同的后缀来进行区分的。

对于C/C++来说,其库的名称也是有规范要求的,例如在Linux下:一般要求是 lib+库的真实名称+(版本号) + .so / .a + (版本号),版本号是可以省略不写的。 比如:
- libstdc++.so.6,去掉前缀和后缀,最终库名为stdc++。
- libc-2.17.so,去掉前缀和后缀,最终库名为c。
有了上面的一点基础知识,我们就能够去见一见库了,Linux系统安装时已经为我们预装C&C++的头文件和库文件。
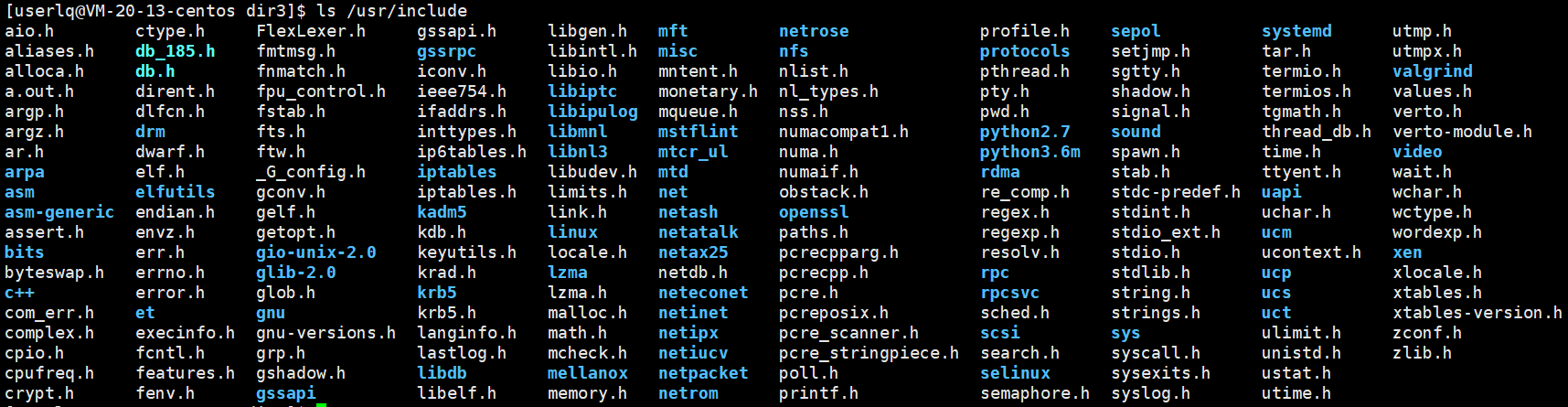
对于C/C++头文件,在Linux操作系统中一般在/usr/include目录下面存放C/C++头文件:
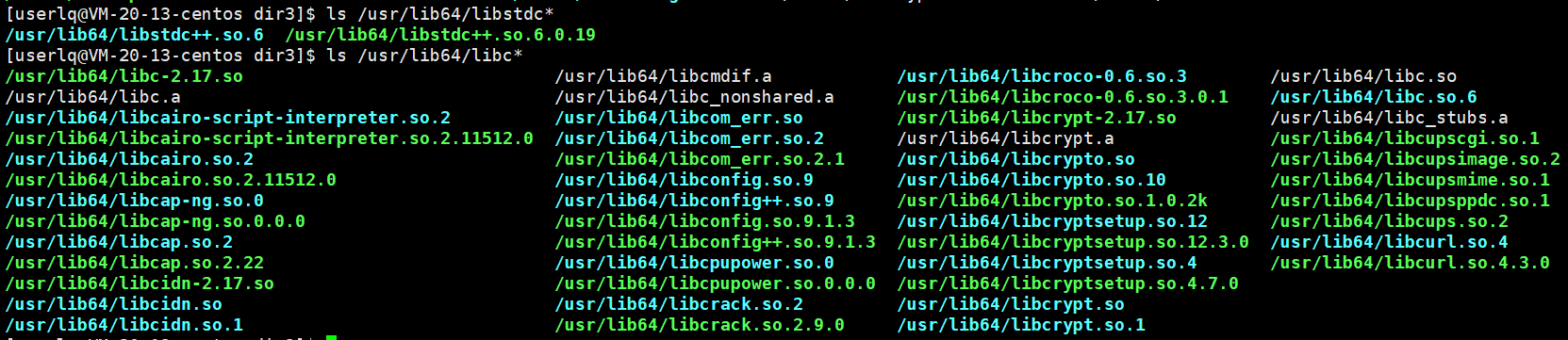
对于C/C++的库文件,一般在/usr/lib64和/lib64里面,/lib64里面给的是root和内核所需so或者a之类的库文件,而/usr/lib64是普通用户能够使用的。

6.2 库的作用
提高开发效率。
系统已经预装了C/C++的头文件和库文件,头文件提供说明,库文件提供方法的实现。
1、头文件提供方法说明,库提供方法的实现,头和库是有对应关系的,是要组合在一起使用的;
2、头文件是在预处理阶段就引入的,程序在链接时链接的本质就是链接库。
如果没有库文件,那么在开发时,需要自己手动将printf等高频函数编写出来,因此库文件可以提高我们的开发效率。比如python中就有很多现成的库函数可以使用,效率很高。
1、我们在使用像VS2019这样的编译器时要下载并安装开发环境,这其中是在下载什么?安装编译器软件,安装要开发的语言配套的库和头文件。
2、我们在使用编译器,都会有语法的自动提醒功能,但是都需要先包含头文件,这是为什么?
语法提醒的本质是编译器或者编辑器,它会自动的将用户输入的内容,不断的在被包含的头文件中进行搜索,自动提醒功能是依赖头文件而来的。
3、我们在写代码时,我们的环境怎么知道我们的代码中有哪些地方有语法报错?哪些地方定义变量有问题?
编译器有命令行的模式,还有其他自动化的模式,编辑器或集成开发环境可以在后台不断的帮我们调用编译器检查语法而不生成可执行文件,从而达到语法检查的效果。
6.3 制作一个静态库
库的使用能够提高我们的开发效率,接下来我们制作一个库。
//my_add.h
#pragma once
int my_add(int x, int y);//my_add.c
#include "my_add.h"
int my_add(int x int y)
{return x + y;
}//my_sub.h
#pragma once
int my_sub(int x, int y);//my_sub.c
#include "my_sub.h"
int my_sub(int x, int y)
{return x - y;
}//main.c
#include <stdio.h>
#include "my_add.h"
#include "my_sub.h"int main()
{int a = 10, b = 20;printf("%d + %d = %d\n", a, b, my_add(a, b));printf("%d - %d = %d\n", a, b, my_sub(a, b));return 0;
}程序经过预处理、编译、汇编、链接,等过程形成可执行程序。快速形成对应的文件,选项叫做esc。其中-c属于第三步,形成二进制文件,这个二进制文件无法执行,因为缺少链接的过程,.o文件为可重定位目标二进制文件。如下图所示。

通过-o命令,将所有的.o文件链接起来,形成一个可执行程序mymath。
gcc -o mymath main.c my_add.c my_sub.c 将所有的.c文件形成.o文件之后,再将.o文件链接起来。该命令的.c文件都是独立编译的,形成.o文件之后再链接。
gcc -o mymath main.o my_sub.o my_add.o 是直接将.o文件链接起来。两者是没有区别的。其中,gcc -o mymath main.o my_sub.o my_add.o 是 gcc -o mymath main.c my_add.c my_sub.c 的最后一步。如下图所示,成功执行。
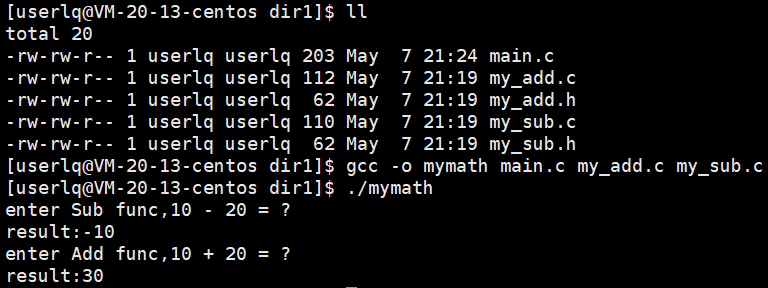
我们将main.c、my_add.o、my_sub.o文件放在同一个文件夹中,my_add.h、my_sub.h两个头文件放在另外的一个文件夹中。
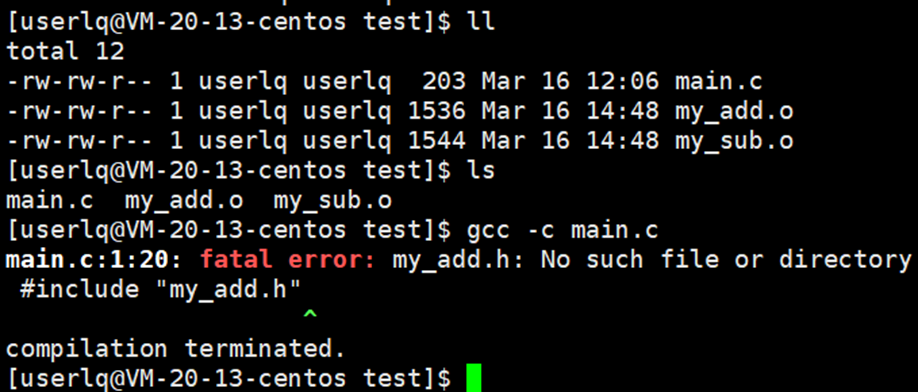
把main.c文件编译形成main.o文件,再将main.o与my_add.o、my_sub.o文件链接起来,形成可执行程序。此时,我们发现直接执行gcc -c main.c 指令时出错了,并提示我们找不到头文件。
编译文件时的第一步是预处理,要进行头文件的展开。main.c文件中的代码中包含了my_sub.h和my_add.h头文件,所以就使用了my_sub.c和my_add.c中的方法。由于main.c编译时,需要将my_sub.h和my_add.h头文件在main.c的源代码中展开,才能编译通过。而此时,只有my_add.o、my_sub.o文件,所以 gcc -c main.c 编译不通过。所以将头文件拷贝到test目录中,此时链接形成可执行程序mymath,并成功执行。如下图所示。
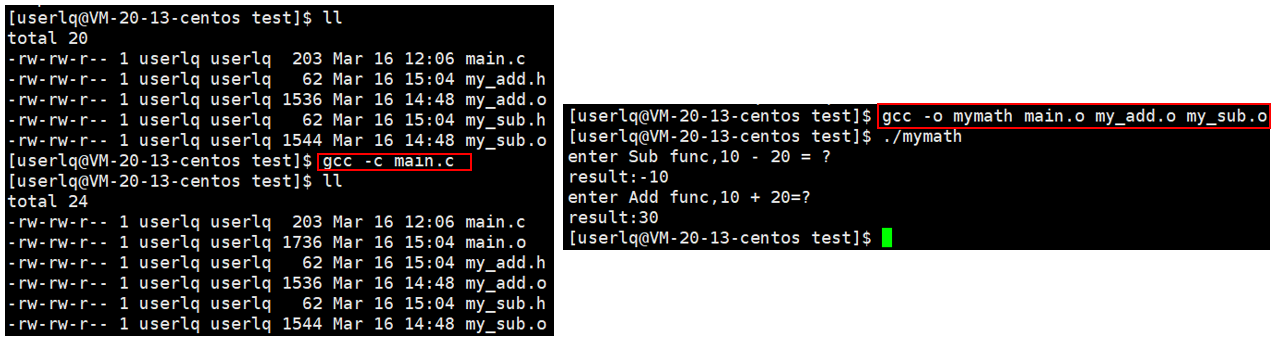
结论:如果我们想让其他人调用自己程序的一些功能,但是不想把源代码交给其他人,则可以把自己的程序经过预处理、编译、汇编,生成.o文件,即可重定位目标二进制文件,交给别人使用。
未来我们可以给对方提供.o文件(方法的实现)、.h文件(方法的声明),对方就可以进行编译了。我们可以尝试将所有的 ".o文件" 打一个包,将 ".o文件" 打好的包叫做库文件,我们给对方提供一个库文件即可。
打包就是将多个.o文件合并形成一个文件,这个文件就称为库。在打包时,根据采用的打包工具和打包方式的不同,就有了对应的动态库和静态库,库的本质就是.o文件的集合。
上面整个过程就是我们制作静态库的基本流程,当然这样的制作其实还是有缺陷的,当我们的项目文件过于庞大时,我们要给一个.c文件十几个这样的.o文件,而且文件过于分散了,不利于管理。于是我们就需要将多个这样的.o文件打成一个包,我们将这个包直接给别人,别人就能直接使用了。
打包的命令是:ar -rc [lib库名.a] [*.o]
ar:该命令用于建立或修改备存文件,或是从备存文件中抽取文件。可集合许多文件,成为单一的备存文件,在备存文件中,所有成员文件皆保有原来的属性与权限。
r:如果打包好的xxx.a库中没有xxx.o那么就会把模块xxx.o添加到库的末尾,如果有的话就会替换之(位置还是原来的位置)。
c:建立备存文件。
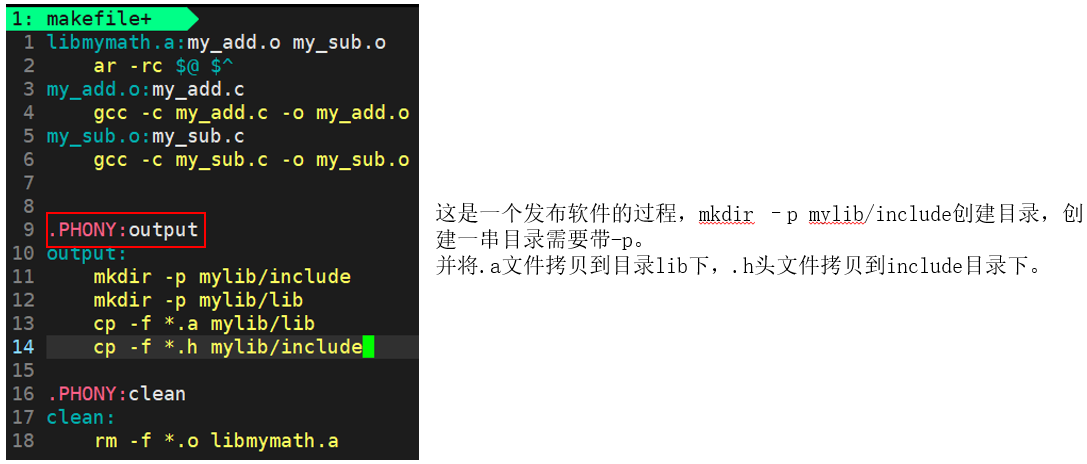
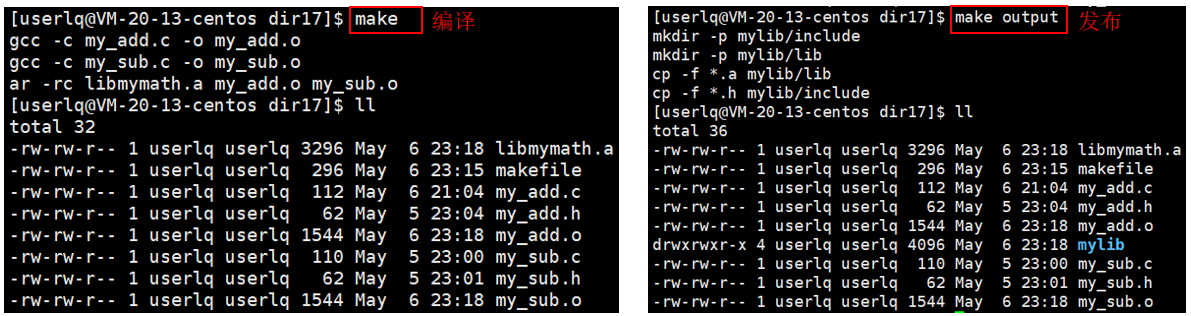
成功编译并成功发布。
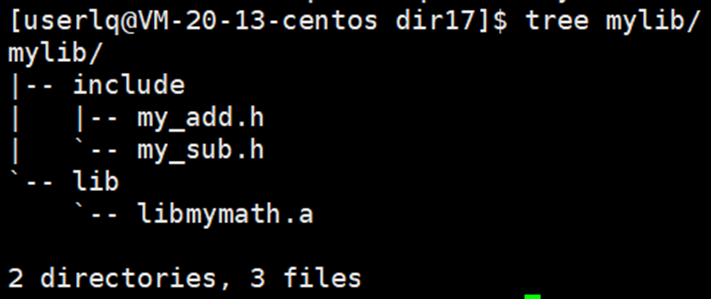
编译通过,并成功发布。此时,头文件中包含了两个.h文件,库文件中包含了.a文件。此时,就将库成功发布了。
但是,库发布出来之后,怎么才能让用户去使用呢?
使用 tar czf mylib.tgz mylib 命令将mylib文件打个包形成文件 mylib.tgz,然后将该库放到yum资源中,用户就可以使用yum来下载该库并使用了。
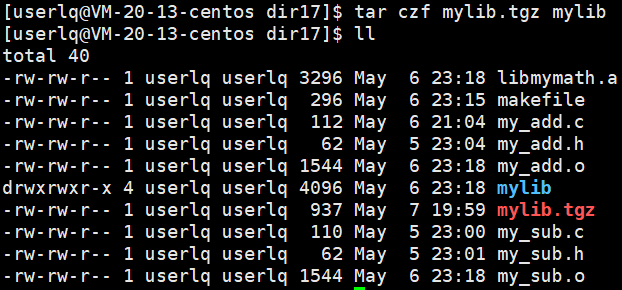
用户将 mylib.tgz 下载并解压,此时就有了mylib库了,就可以使用了。
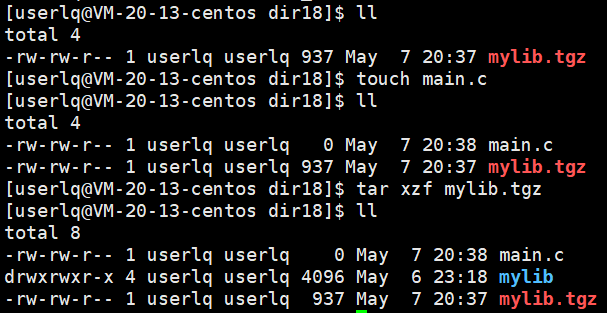
6.4 静态库的使用
6.4.1 通过指定路径使用静态库
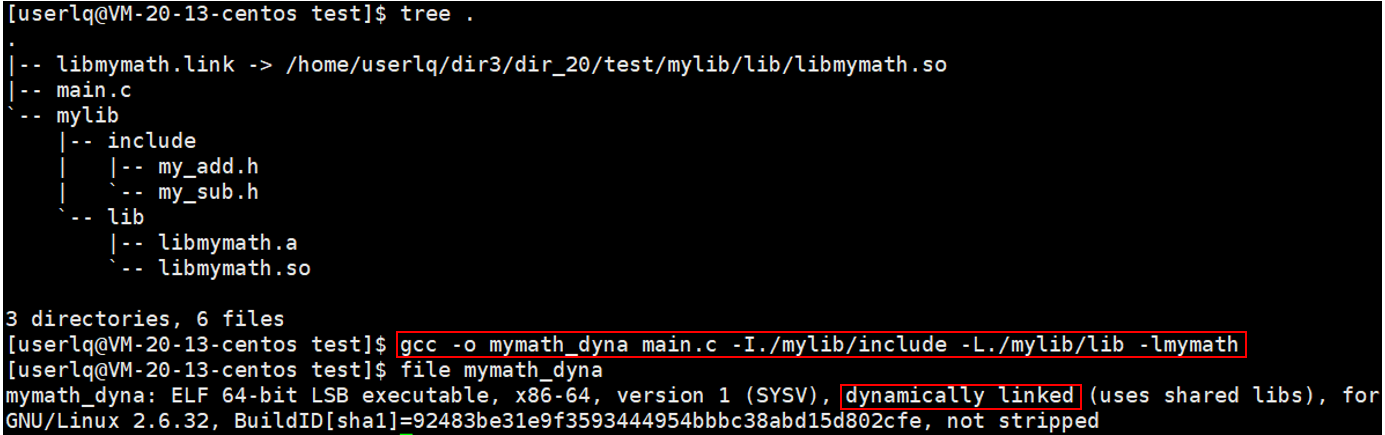
在我们实际使用库时,我们一般将头文件放在一个目录里面,将库放到另外一个文件里面,这样便于我们进行分类管理。我们也按照这种标准化的做法,来整理一些我们的目录结构,如下图所示。
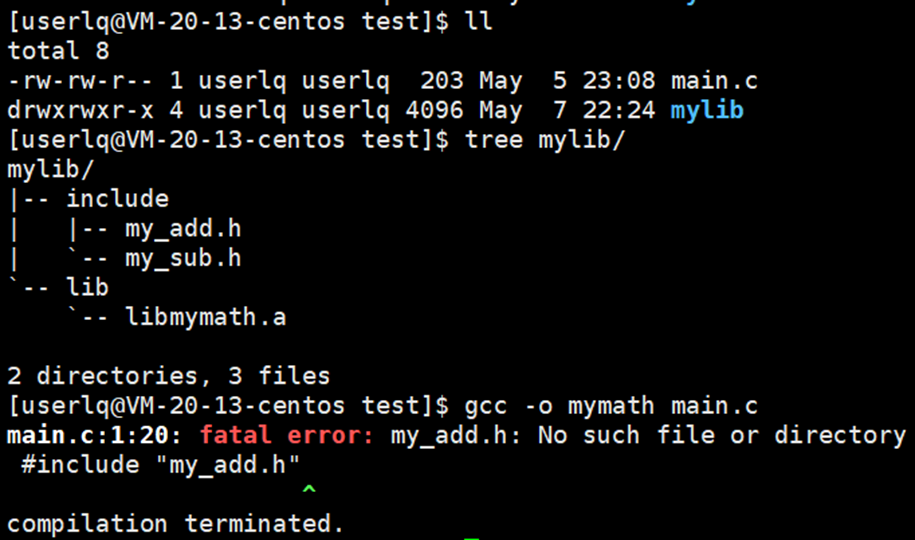
此时,我要编译文件main.c时,发现找不到头文件。为什么呢?因为gcc也是一款编译器,编译器在搜索头文件时,默认 ①在当前目录下搜索;②在系统默认的指定路径下搜索。当前路径就是和源代码在同级的路径下,而这里的头文件在当前目录的mylib目录下,此时编译器找不到对应的头文件,在系统的头文件中也找不到。
此时,可以给gcc指定搜索路径,-I 后面的路径包括所有的.h头文件。后面依然报错,而且是链接报错。出链接报错就说明已经完成了预处理、编译和汇编的过程。头文件已经找到了,但是库文件并没有找到。在形成可执行程序时,要使用库文件时,要告诉我要使用的库文件所在的路径。

-L ./mylib/lib 告诉gcc编译器,库文件在 ./mylib/lib 路径下。这里依然会报错, 如果要链接第三方的库,必须指明库名称。就是你得告诉编译器我要链接的是哪个路径下的哪个库。比如:./mylib/lib 路径下的 libmymath.a。我们以前写代码时,从来没有指明过库名称。这是因为我们以前写的代码没有使用过任何的第三方库,用的只是C和C++语言提供的标准库。gcc和g++默认就能确定你要链接的是哪个路径下的哪个库(C/C++提供的库)。
即,别人提供的第三方库,我们在使用时,不仅要指定路径,还要指明库的名称。C/C++语言提供的库我们不需要指明名称就可以编译。


-l 库文件名(这里的库文件名指真实名称),库文件名为 mymath。去掉前缀lib和后缀.a,剩余的就是库文件名。

这串命令可以带空格,也可以不带空格,如上图所示。但是一般情况下,不带空格。
形成一个可执行程序,可能不仅仅依赖一个库。假如形成一个可执行程序要依赖100个库,其中70个是动态库、30个是静态库。请问怎么链接?
gcc默认是动态链接的(gcc的建议行为),对于一个特定的库,究竟是动态链接、还是静态链接,取决于你提供的是动态库还是静态库。假如给gcc提供一个静态库,那么gcc只能将该静态库拷贝到对应的可执行程序中。假如动、静态库都提供呢?那么选择权就在gcc上了,gcc想怎么链接就怎么链接。
假如在链接时,既有动态库、又有静态库。只要有一个动态库,我们的软件就是动态链接的。
6.4.2 将头文件和静态库文件安装至系统目录中
除了这种比较麻烦的指定路径编译外,我们还可以将头文件与动态库文件直接安装在系统目录中,直接使用,无需指定路径。(需要指定静态库名)
所谓的安装软件,就是将自己的文件安装到系统目录下。
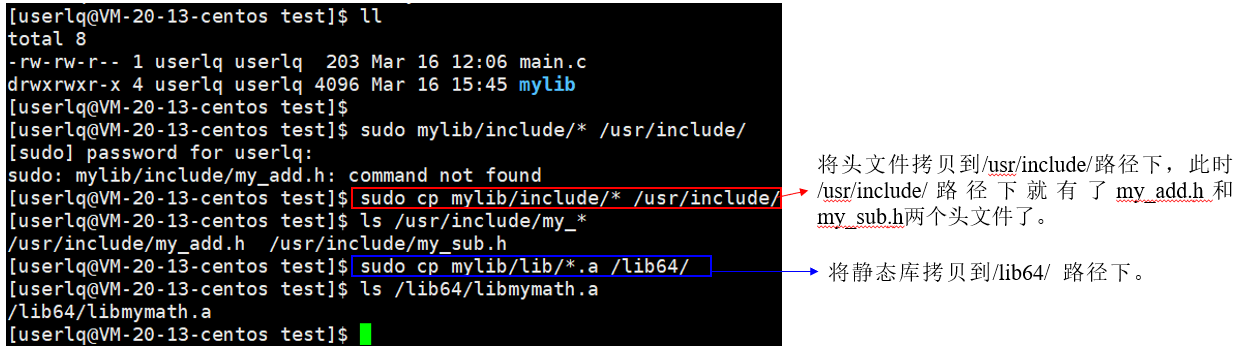
以上操作就叫做安装,安装的本质就是拷贝。
注意:将自己写的文件安装到系统目录下是一件危险的事(会导致系统环境被污染),用完记得手动删除。
总结:第三方库的使用
1、需要指定的头文件和库文件。
2、如果没有默认安装到系统gcc、g++默认的搜索路径下,用户必须指明对应的选项,告知编译器:①头文件在哪里;②库文件在哪里;③库文件具体是谁。
3、将我们下载下来的库文件和头文件拷贝到系统默认路径下,在Linux下就是安装库。对于任何软件而言,安装的本质就是拷贝到系统特定的路径下。
4、如果我们安装的是第三方的库,我们要正常使用,即便是已经全部安装到了系统默认路径下,gcc、g++必须用 -l 指明具体库的名称。
5、无论我们是从网络中直接下载的库,还是源代码(编译方法)。都会提供一个make install安装的命令,这个命令所做的就是安装到系统中的工作。我们安装大部分指令、库等等都是需要sudo提权的。
6.5 制作一个动态库
动态库:动态库不同于静态库,动态库中的函数代码不需要加载到源文件中,而是通过 与位置无关码,对指定函数进行链接使用。程序在运行时才会去链接动态库的代码,多个程序共享使用库的代码。
动态库的打包也同样分为两步:
①编译源文件,生成二进制可链接文件,即将所有的源代码变成.o文件。与形成静态库的.o文件相比,此时需要加上 -fPIC ,-fPIC的含义是在形成.o文件时,生成与位置无关码。
②形成.o文件后,再将其打包。静态库就是通过ar归档工具,将.o文件进行归档。
1、将源码文件编译形成.o二进制文件,此时需要带上 -fPIC 与位置无关码
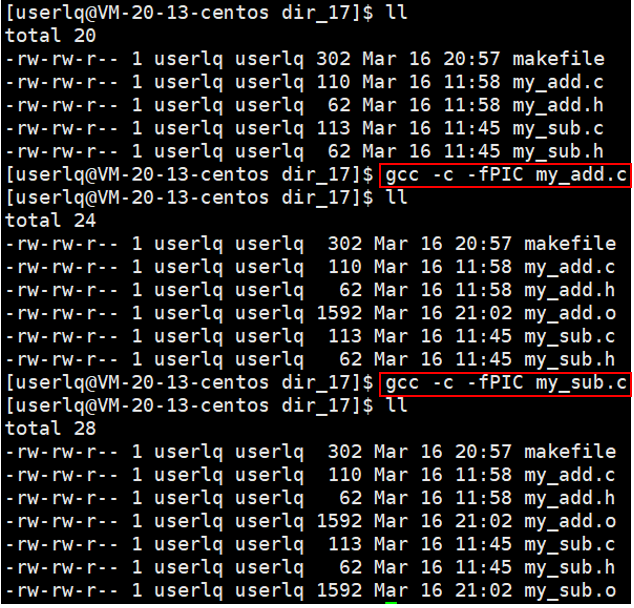
2、借助gcc/g++,将所有的.o文件打包为动态库

gcc加上-shared默认帮我们形成动态库,加上-shared表示我们不想形成可执行程序,而是想形成动态库。
6.6 动态库的使用
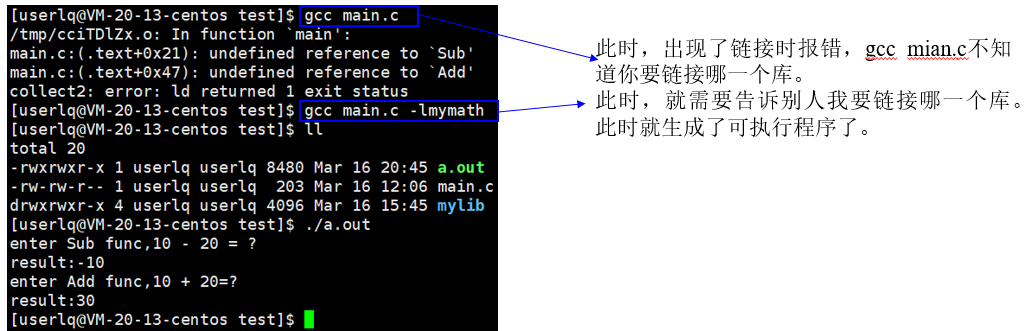
下面我们尝试用动态库去链接形成可执行程序:
注意:我们自己写的库是属于第三方库,我们编译时要指明:头文件路径、库文件路径、库文件名(真实名称)。


在运行mymath可执行程序时,发生了错误。系统提示我们程序运行时,没有办法找到动态库,这是为什么呢?
这就和动态库的特性有关了,由于采用动态库的程序在运行时才去链接动态库的代码。多个程序共享使用库的代码,所以运行的程序必须要知道去哪里链接我们的库。对于动态库,在编译期间我们要告诉编译器去哪里链接库进行编译,在运行期间我们要告诉操作系统去哪里链接库进行运行。所以,在编译期间不仅要告诉编译器gcc库在哪里,保证编译链接能够形成可执行程序。同时,在运行时也要告诉操作系统库在哪里。
静态库不需要链接是因为:静态库在编译链接期间将用户使用的二进制代码直接拷贝到目标可执行程序中,编译后的程序是一个完成的程序,不需要在运行时再使用静态库了。
操作系统查找动态库的方法有三种:
①设置环境变量:LD_LIBRARY_PATH;
②在系统指定路径下建立软链接,指向对应的库;
③配置文件。
1、设置环境变量
在Linux操作系统下有一个环境变量:LD_LIBRARY_PATH,操作系统会去该环境变量下的路径中搜索动态库,我们可以将我们自己写的第三方库的路径添加到这个环境变量中,然后我们再运行mymath可执行程序时,就能运行成功了。
![]()
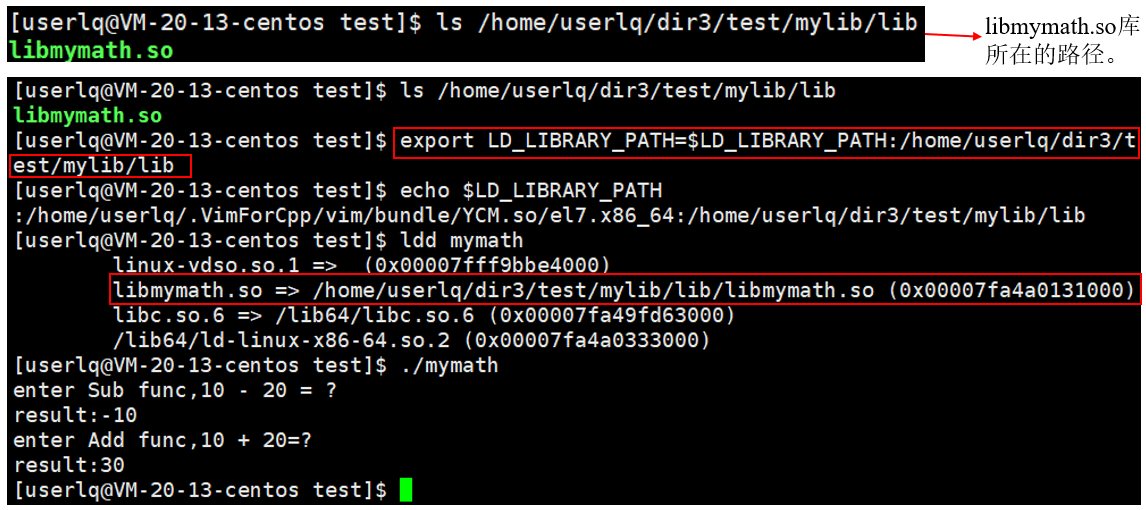
将 libmymath.so 库所在的路/home/userlq/dir3/test/mylib/lib添加到环境变量LD_LIBRARY_PATH中。
这种将库路径添加到环境变量的方法,临时用来做测试没有问题。但是当重新登陆操纵系统后,该路径就失效了,需要重新添加路径才能成功执行。
2、更改配置文件
在Linux操作系统中有一个配置文件目录/etc/ld.so.conf.d,在这个目录中我们可以任意创建一个配置文件,并将动态库libmymath.so 的路径写进该配置文件中,这样操作系统就能在该路径下搜索到动态库。

现在我们在 /etc/ld.so.conf.d/路径下创建一个配置文件100.conf,并在该配置文件内写入所需库的路径,如下图所示。
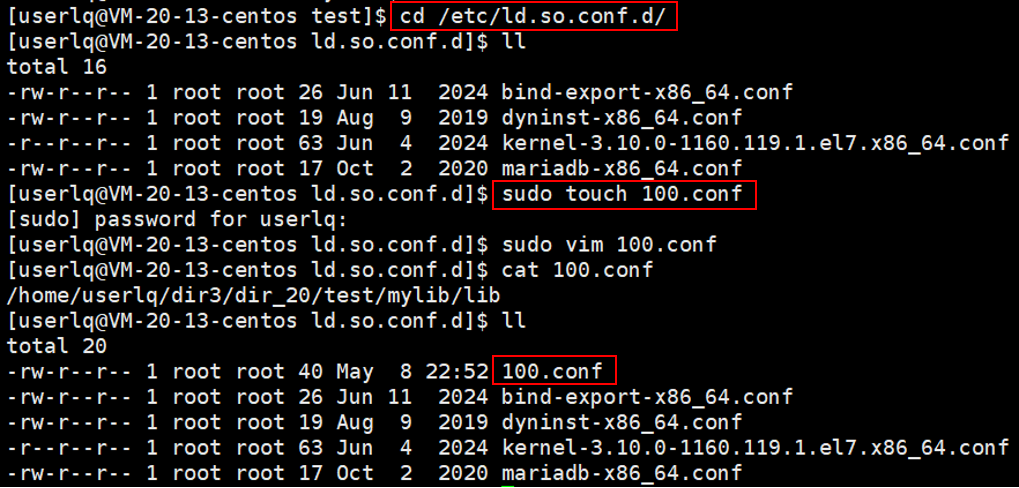
![]()
更改完配置文件后,我们发现依然无法执行mymath可执行程序,而且依然找不到libmymath.so动态库,如下图所示:
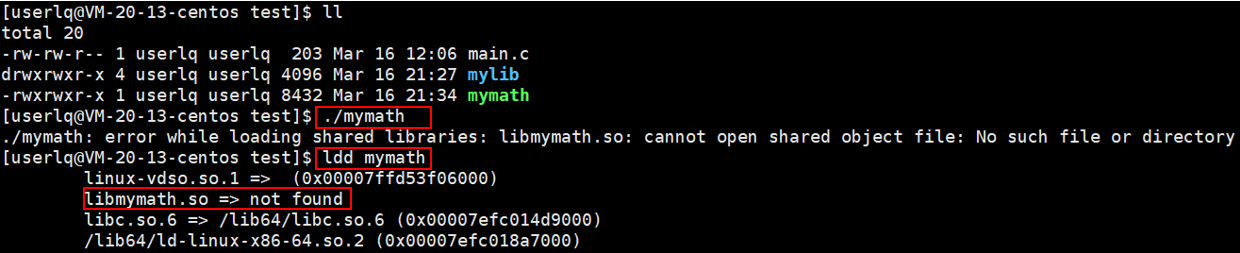
其实,在更改完配置文件后,需要让该配置文件生效,使用指令ldconfig命令更新一下缓存。此时,能够正常执行mymath可执行程序了。
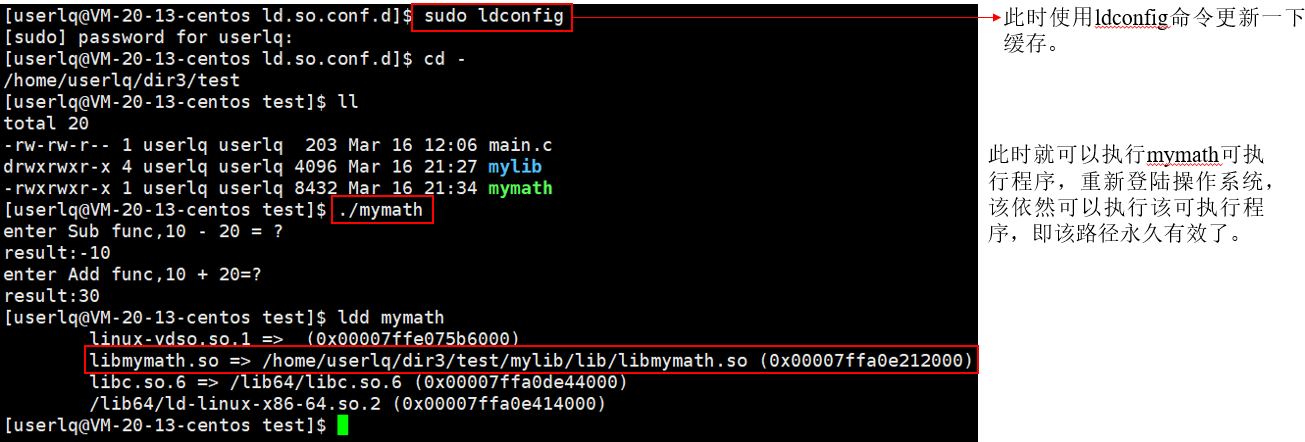
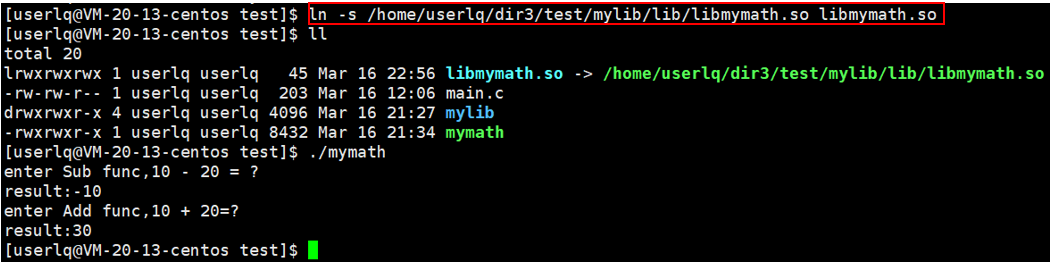
3、建立软链接
操作系统在搜索动态库时,默认直接能够在当前路径下搜索。所以我们可以通过在当前路径下建立我们要使用的动态库libmymath.so的软链接,让操作系统能够找到对应的libmymath.so动态库。
如果我们不想在当前目录下建立软链接,那么可以将软链接建立在对应的系统路径下。我们知道Linux操作系统中,C/C++的默认路径是/usr/lib64或者lib64,这也是系统搜索库的默认路径,我们可以将我们的第三方库在以上任意一个路径中建立一个软链接(不推荐直接将第三方库拷贝到默认库路径/usr/lib64或者/lib64下面),这样我们也能够正常使用了。
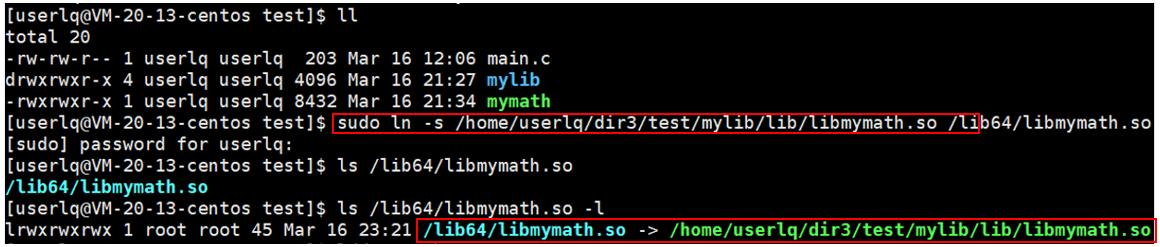
通过ldd查看程序链接情况:

因为软链接是一个正常的文件,永远保存在磁盘上,所以我们退出后再次登录时,程序依然可以正常运行。
注意:后两种方式都可以做到永久生效(因为存入了系统目录中),但是方法2在使用完后最好删除新创建的配置文件100.conf,避免污染系统环境。
6.7 动静态库的加载
6.7.1 静态库的加载
在形成可执行程序的链接期间,静态库中的代码会被直接拷贝一份进入程序内。在程序运行期间,就不再依赖于该静态库了,所以在程序运行期间静态库可以理解为不会被加载,或者说静态库和程序一起被加载。
假如多个进程都要调度printf函数,都要将printf函数的代码拷贝进来,并加载到内存。此时,在内存中会存在大量的重复代码,导致内存资源的浪费。
将静态库中的代码拷贝到我自己写的程序中,是拷贝到哪里呢?答案:是将静态库中的代码展开,拷贝至程序的代码区。
静态库中的printf函数的代码拷贝到我们自己写的代码里面,链接形成可执行程序时,会拷贝到哪里呢?我们自己写的程序在编译时,就已经以虚拟地址的方式帮我们把我们自己写的程序编译好了。即我们自己写的程序,在没有被加载到内存时,已经有了代码段、初始化数据区、未初始化数据区等区域。
每个进程都有自己独立的进程地址空间,实际上形成的可执行程序,也要按照进程地址空间的规则来排布它的代码和数据,即有相应的代码区、初始化数据区、未初始化数据等。所以将静态库中的代码拷贝到我们自己写的程序中时,就是将静态库中的代码展开拷贝至我们自己写的程序的代码区。
那么将静态库的代码拷贝至我们自己写的程序的代码区,所以未来静态库中printf函数的实现在加载到内存时,在进行进程映射时,只能够映射到当前进程的代码区?答案:是的。未来从静态库中加载进来的printf函数的实现,必须通过相对确定的地址位置来进行访问。当这部分加载到内存形成地址空间,玩不程序访问时,只能在代码区中找到对应的printf函数的实现。加载到我们自己写的程序中的静态库的代码和我们自己写的代码和数据的编码方式是一样的。
从静态库中拷贝到我们自己写的程序中的代码,必须通过相对确定的地址位置来进行访问。静态库的函数的代码拷贝到我们自己写的程序中,这个函数的入口地址就必须按照我们自己写的程序一样,从0000到FFFF这种地址的方式来进行编译。编译之后,printf函数在什么位置必须确定,这就是绝对编址的方案。
6.7.2 动态库的加载
1.加载的过程
当使用动态库编译形成了一个可执行文件后,该可执行文件存储在磁盘中,并在运行时加载到内存中。如下图:
那么动态库和可执行程序之间是什么关系呢?
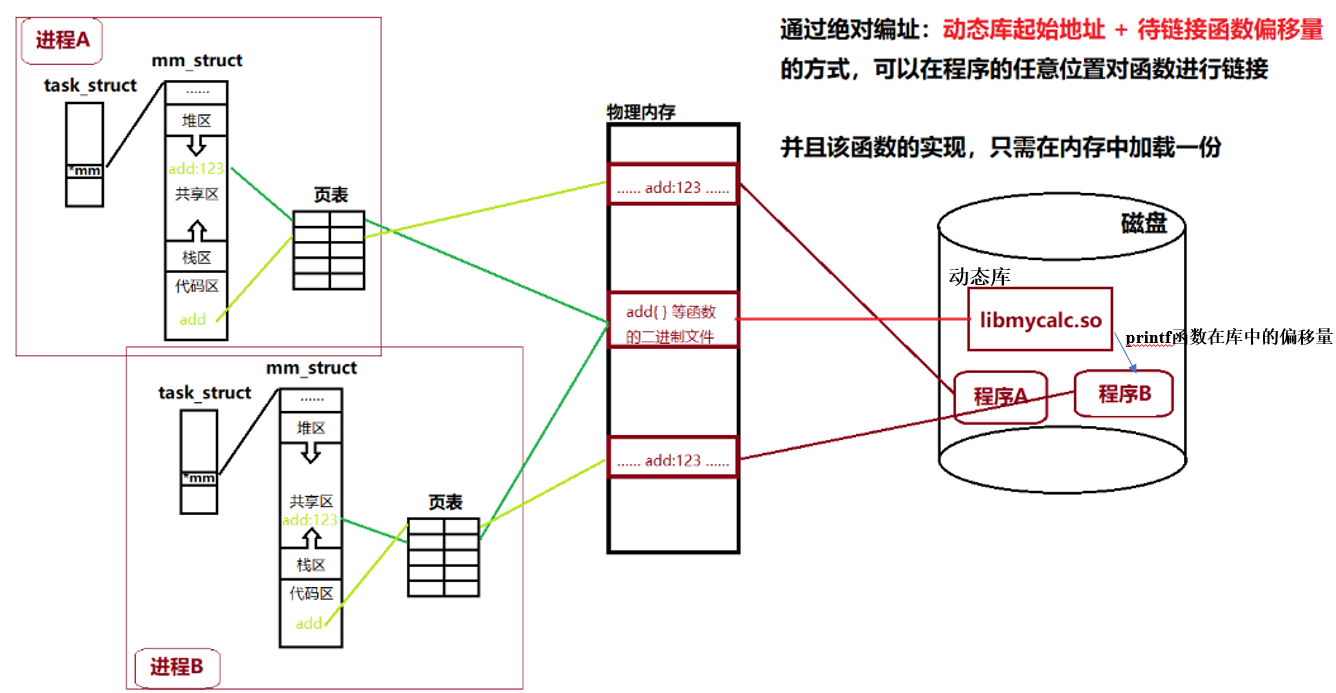
动态链接并没有把动态库中的printf函数的实现拷贝到可执行程序里,而是将printf函数的地址,写入到可执行程序中。
动态库中的特定函数在编址时,采用的start+偏移地址的方式(start:偏移地址),start不确定。将动态库中的printf函数的地址写到可执行程序里,start可以相当于动态库的名称,偏移量就相当于相对编址。 printf函数相对于动态库的起始位置就可以视为printf函数的偏移量。将动态库中函数的地址填到可执行程序中,填写的就是该函数的偏移量。
程序被加载到内存后就变成了进程,操作系统会在内存中创建对应的task_struct、mm_struct、页表。在执行程序中自己写的代码时,正常执行。当需要执行动态库中的代码时,操作系统会先在内存中搜寻动态库是否存在,如果存在就直接将动态库通过页表映射到进程的进程地址空间中的共享区中。否则就会将磁盘中的动态库加载到内存中,然后再通过页表映射到虚拟地址空间的共享区中。详细步骤如下。
通过页表读取时,发现可执行程序中printf函数的代码实现并不存在,只有printf的函数地址。编译时在可执行程序中标识清楚了,这个地址属于外部地址。我们需要访问动态库来拿到该函数的代码,此时就识别到了要访问的库了。此时操作系统就停止执行程序,而是将动态库加载进来,并将动态库中的内容经过页表映射到进程的共享区中。映射到共享区之后,就确定了这个库在虚拟地址中的起始地址,就有了虚拟地址。
在链接时,可执行程序中已经填写好了printf函数在库中的偏移量。当调用printf函数时,动态库一旦完成动态加载、映射的过程之后,我们就可以在进行地址空间的共享区找到库的起始地址,并结合链接时形成的printf函数在库中的偏移量,就找到了printf函数在动态库(共享库)中的位置,并调用该函数,调用完成之后,再返回代码区继续向后执行。至此,我们就完成了动态库的加载与访问的过程。
换句话说,只要把库加载到内存,映射到进程的地址空间后,进程执行库中的方法,就依旧还是在自己的地址空间内进行函数跳转即可。
2.动态库的理解
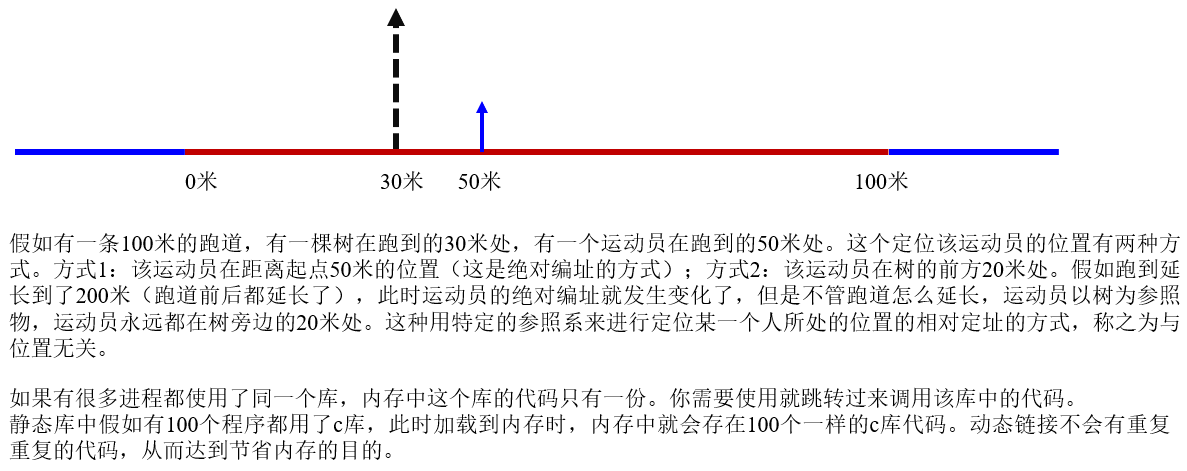
在程序编译链接形成可执行程序时,可执行程序内部就已经有地址了,地址一共有两类,分别是绝对地址与相对地址。我们知道被编译好的程序内部是有地址的。动态库内部的地址并不是绝对地址,而是偏移量!(相对地址)
动态库必定面临一个问题:不同的进程,运行程度不同,需要使用的第三方库是不同的,这就注定了每一个进程的共享区中的空闲位置是不确定的。如果采用了绝对编址,在一个进程使用了多个库时就有可能造成地址冲突!因此,动态库中函数的地址,绝对不能使用绝对编址,动态库中的所有地址都是偏移量,默认从0开始。简单来说,库中的函数只需要记录自己在该库中的偏移量,即相对地址就可以了。
当一个库真正的被映射到进程地址空间时,它的起始位置才能够真正的确定,并且被操作系统管理起来。操作系统本身管理库,所以操作系统知道我们调用库中函数时,使用的是哪一个库,这个库的地址是什么。当需要执行库中的函数时,只需要拿到库的起始地址,加上对应函数在该库中的偏移量,就能够调用对应的函数了。
借助函数在库中的相对地址,无论库被加载到了共享区的哪一个位置,都不影响我们准确的找到对应函数,也不会与其他库产生冲突了。所以这种库被称为动态库,动态库中地址偏移量被称为与位置无关码。
3.理解与位置无关码
6.8 动态库知识补充
当同时拥有静态库和动态库时,默认采用动态链接。
如果想要使用静态链接,则需要在编译时加上-static命令选项。

如果只有静态库,但又不指定静态链接,会发生什么?
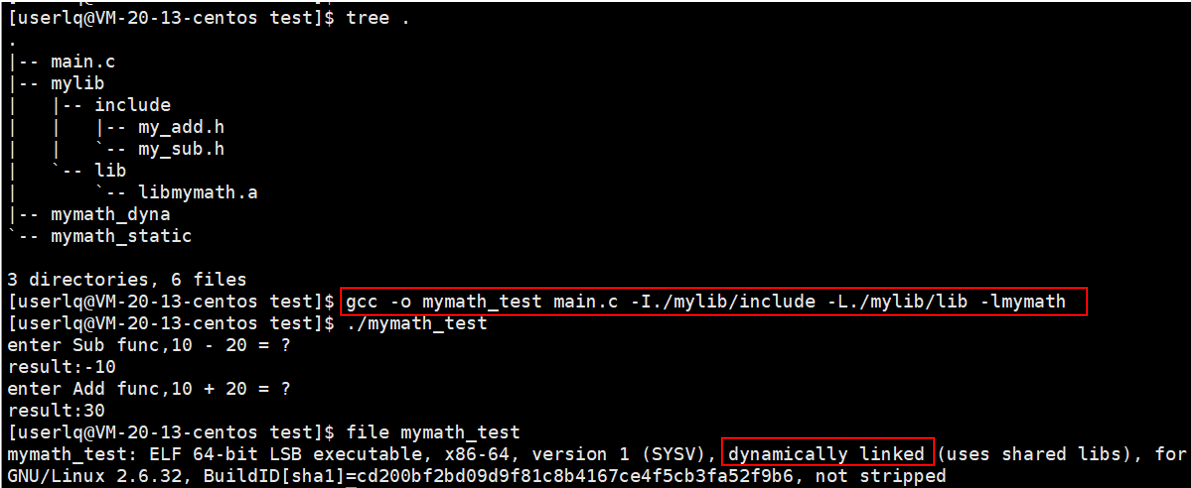
会默认使用动态链接,而对于C语言库等,也是默认使用动态链接。
可以看看以上三种方式生成的可执行程序的大小:

静态链接生成的程序比动态链接大得多,并且内含静态库的动态链接程序,也比纯粹的动态链接程序大,说明程序不是 非静即动 ,可以同时使用动态库与静态库。
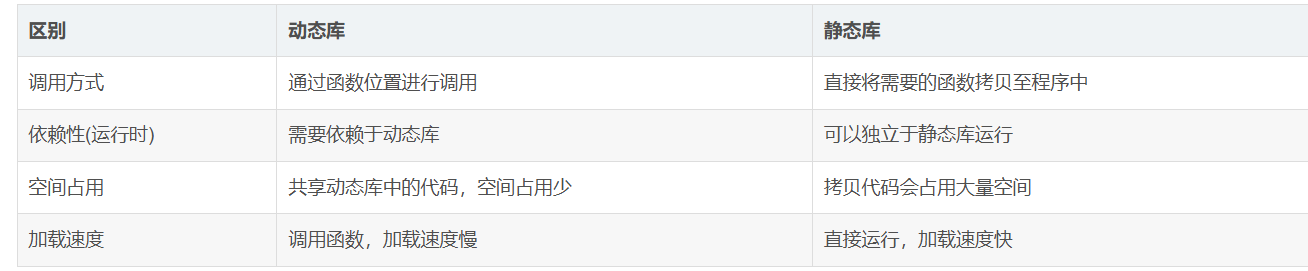
6.9 总结
关于动静态库的优缺点可以看看下面的表格。