2024年 AI大模型我该买一张什么显卡?
有钱啥也不用说,买张最贵的就是了。对囊中羞涩的我还说,我该买张什么样的显卡呢?
我的旧显卡RTX1060 6G,满负荷消耗功率110多瓦,几乎达到设计最大TDP,周日时拿了朋友的RTX3060Ti 8G,发现是锁算力的,GPU使用率100%时,消耗功率也才 33% TDP,只有 65瓦,远没达到最大200瓦的设计TDP值(后来发现这个结论是错误的,可能与Pytorch2.5.0+cu124有关,消耗功率去到了158瓦),速度比RTX1060快了3倍左右。
看了文章《2024年 AI大模型显卡推荐 我该买一张什么卡》后,本来考虑买张RTX2080TI 22G魔改版或Tesla P40的,看了文章《NVIDIA Tesla GPU系列P40参数性能——不支持半精度(FP16)模型训练》发现 P40也不是那么合适,再看了视频《【捡显卡】二手城淘到2080Ti猛禽,六年前的旗舰还能有4070的几成功力?2080Ti猛禽清理、介绍、对比4070性能测试》也在犹豫要不要买RTX2080Ti 22G魔改版,还是买张原11G版?
从文章《2024年 AI大模型显卡推荐 我该买一张什么卡》中引用的《The Best GPUs for Deep Learning in 2023 — An In-depth Analysis》、《https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarks》先看看不同显卡的性能图:


(下面这张是根据柱形图片像素宽度标注的数值 )

参考上面文章数据,nVidia官方显卡数据,汇总了几张市面上有卖自己也勉强能买得起的显卡做了张表,比较下:

贴张chiphell上1080ti参数图(华硕Rog猛禽Gtx 1080ti200W到300W)

发现RTX2080Ti除了功耗大,只能买二手外,性能还是很强劲的,强大的性能伴随着高功耗好像又是必然的,剩下的缺点就是二手的东西,是否可靠的、以及居高的价钱是否能接受了。
AI能力主要是看Tensor Core能力,可惜nVidia直到40系列才标出Tensor Core指标数值,我们发现同为40系列的4060Ti与4070Ti,因为Tensor Core指标相差巨大,实测的AI能力也相差巨大,与Tensor Core指标成正比(见下图)。

除了显卡的算力,还需要考虑显存大小,然后就发现,黄老板对普通大众太不友好了,大显存的,都只能是高高在上的高端卡。
**研究到最后发现:**既然现在有朋友的RTX3060TI先用着,如果不买大内存22G的魔改版的话,实在没有要换显卡的冲动了(谁叫我穷呢),几时朋友要拿回再考虑了_
-----------------------------------------------------------------------------------------------------------------
忍不住冲动,还是买了张华硕猛禽2080ti魔改22G,性能比3060ti还是要强不少。
下载甜甜圈(furmark)测试软件ZIP版本(解压即用无需安装),测试:



用训练模型几乎占满显存测试了20多小时,一切正常,暂时来说,魔改的显存没什么问题:

另外还发现,内存也有影响,原来32G内存, 在 “Load Diffusion Model” 加载是会奔溃(没有错误信息的中断),内存增加到64G后,终于能跑通。加载期间,内存占用达到了50G多。
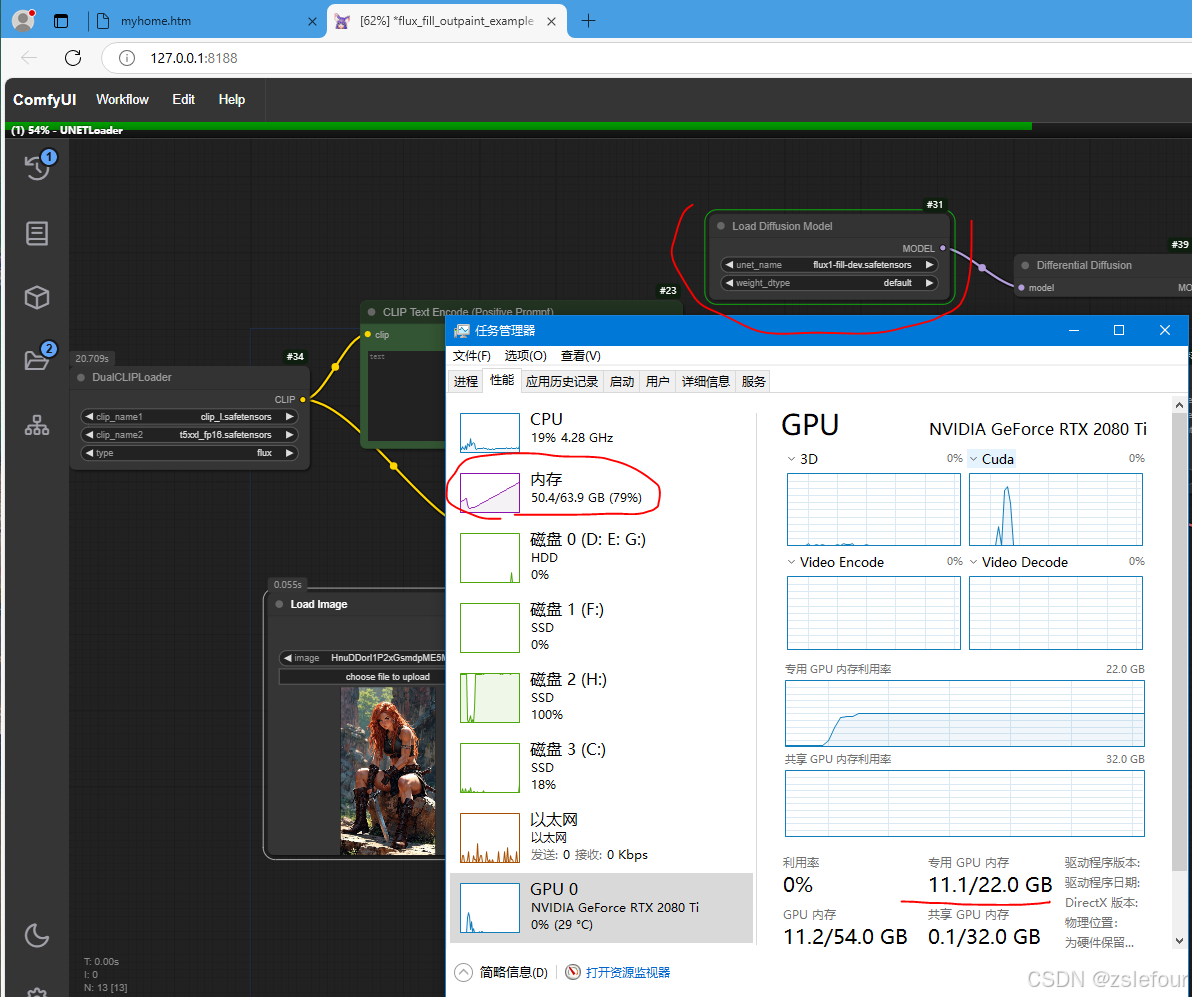
模型加载完后,内存占用就没那么高了:
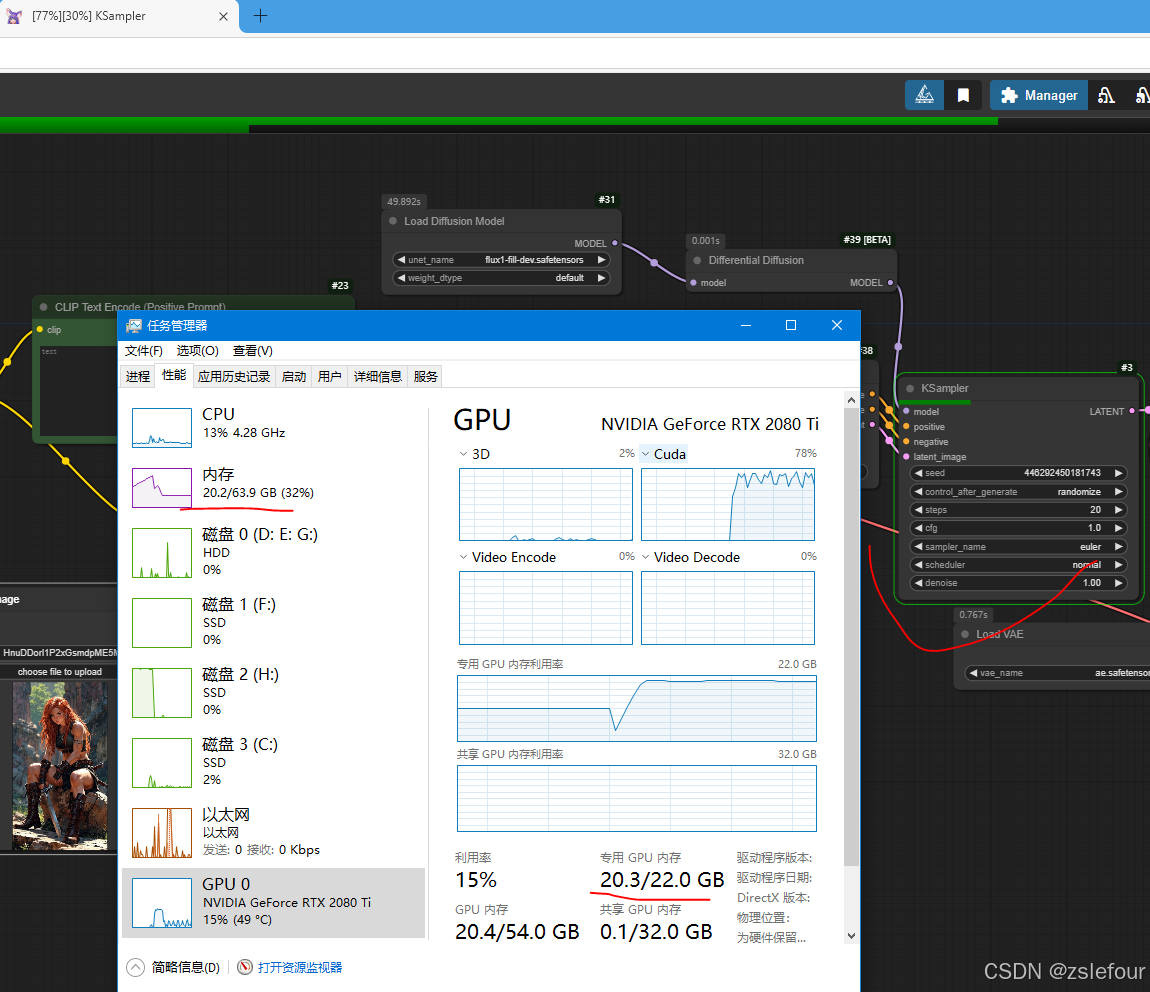
最后要注意的就是:2080ti不支持BF16,而有些AI应用可能会使用到BF16,所以还是要慎重考虑。
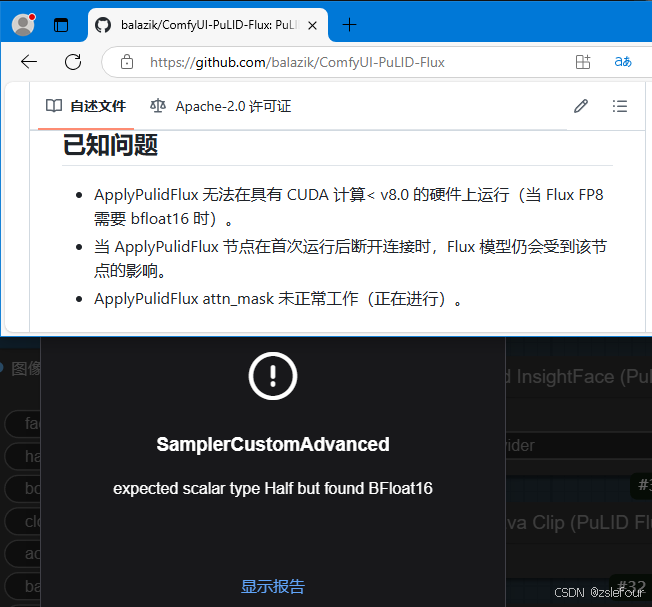
在我的文章(解决2080Ti使用节点ComfyUI-PuLID-Flux-Enhanced中遇到的问题)中,解决了上面节点类似的问题。
下面资料来自deep seek
bf16、fp16、fp32的差别与影响,以及对算力的要求差别
以下是BF16、FP16、FP32的详细对比,包括存储格式、数值范围、精度、计算效率以及对算力需求的影响:
1. 存储格式与数值特性
格式
位数
符号位 (S)
指数位 (E)
尾数位 (M)
数值范围 (approx)
最小精度 (2^-(M+1))
FP32
32
1
8
23
±1.2×103 ~ ±3.4×103
~1.2×10
FP16
16
1
5
10
±6.1×10 ~ ±6.6×10
~4.9×10
BF16
16
1
8
7
±1.2×103 ~ ±3.4×103
~7.8×103
关键区别
指数位:
BF16(8位)与FP32(8位)指数范围相同,能表示极大/极小值,适合深度学习(避免梯度下溢)。
FP16(5位)范围窄,容易溢出(如梯度爆炸)或下溢(如小梯度归零)。
尾数位:
FP32(23位)精度最高,适合科学计算。
FP16(10位)精度适中,但范围受限。
BF16(7位)精度最低,但指数范围广,更适合深度学习中的中间计算。
2. 对深度学习的影响
(1) 训练稳定性
格式
优势
风险
适用场景
FP32
高精度,数值稳定
计算慢,内存占用高
科学计算、高精度需求
FP16
速度快,显存节省
易溢出/下溢(需梯度缩放)
推理、混合精度训练
BF16
数值范围广,训练更稳定
精度较低(可能影响收敛)
大模型训练(如LLM)
FP16 的缺陷:
- 梯度值可能超出表示范围(如 <6e-5 或 >6e4),需配合Loss Scaling(如NVIDIA的AMP)。
BF16 的优势:
- 指数范围与FP32一致,避免溢出问题,适合大模型训练(如GPT、BERT)。
(2) 推理效率
FP16/BF16的吞吐量通常比FP32高2-8倍(依赖硬件支持)。
FP16在NVIDIA GPU(Tensor Core)上优化更好,但BF16在新型硬件(如TPUv4、Intel Sapphire Rapids)中更高效。
3. 算力需求对比
(1) 计算吞吐量(FLOPS)
格式
理论计算速度(示例:NVIDIA A100)
内存占用
带宽需求
FP32
~19.5 TFLOPS
4字节/数
高
FP16
~312 TFLOPS(Tensor Core加速)
2字节/数
中
BF16
~312 TFLOPS(同FP16)
2字节/数
中
FP16/BF16的算力需求约为FP32的1/2~1/4(因内存带宽减半,计算单元利用率更高)。
实际训练速度(混合精度):
FP16/BF16 + FP32主权重:比纯FP32快2-5倍。
纯BF16训练(如Google TPU):接近FP16速度,但更稳定。
(2) 硬件支持
NVIDIA GPU(Ampere+):
FP16/BF16均支持Tensor Core加速。
BF16在A100/H100中优化更好(如Transformer引擎)。
TPU/其他硬件:
Google TPUv4 优先优化BF16。
Intel/AMD CPU 新增BF16指令(AMX、AVX-512_BF16)。
4. 如何选择?
场景
推荐格式
理由
大模型训练
BF16 + FP32主权重
数值范围广,避免溢出,适合LLM(如GPT-4、PaLM)。
小模型训练
FP16 + Loss Scaling
硬件优化更好(NVIDIA),需梯度缩放。
高精度计算
FP32
科学计算、金融模拟等需要高精度的场景。
边缘推理
FP16/INT8(量化)
低延迟、低功耗,适合移动端/嵌入式设备。
5. 总结
维度
FP32
FP16
BF16
精度
高(23位尾数)
中(10位尾数)
低(7位尾数)
数值范围
广
窄(易溢出)
广(同FP32)
算力需求
高(基准)
低(2-8倍加速)
低(2-8倍加速)
适用场景
科学计算
推理/小模型训练
大模型训练
建议:
训练:优先尝试BF16(尤其大模型),次选FP16+AMP。
推理:FP16(NVIDIA)或BF16(TPU/Intel)。
兼容性:旧硬件可能仅支持FP16,需检查文档(如CUDA Compute Capability)。
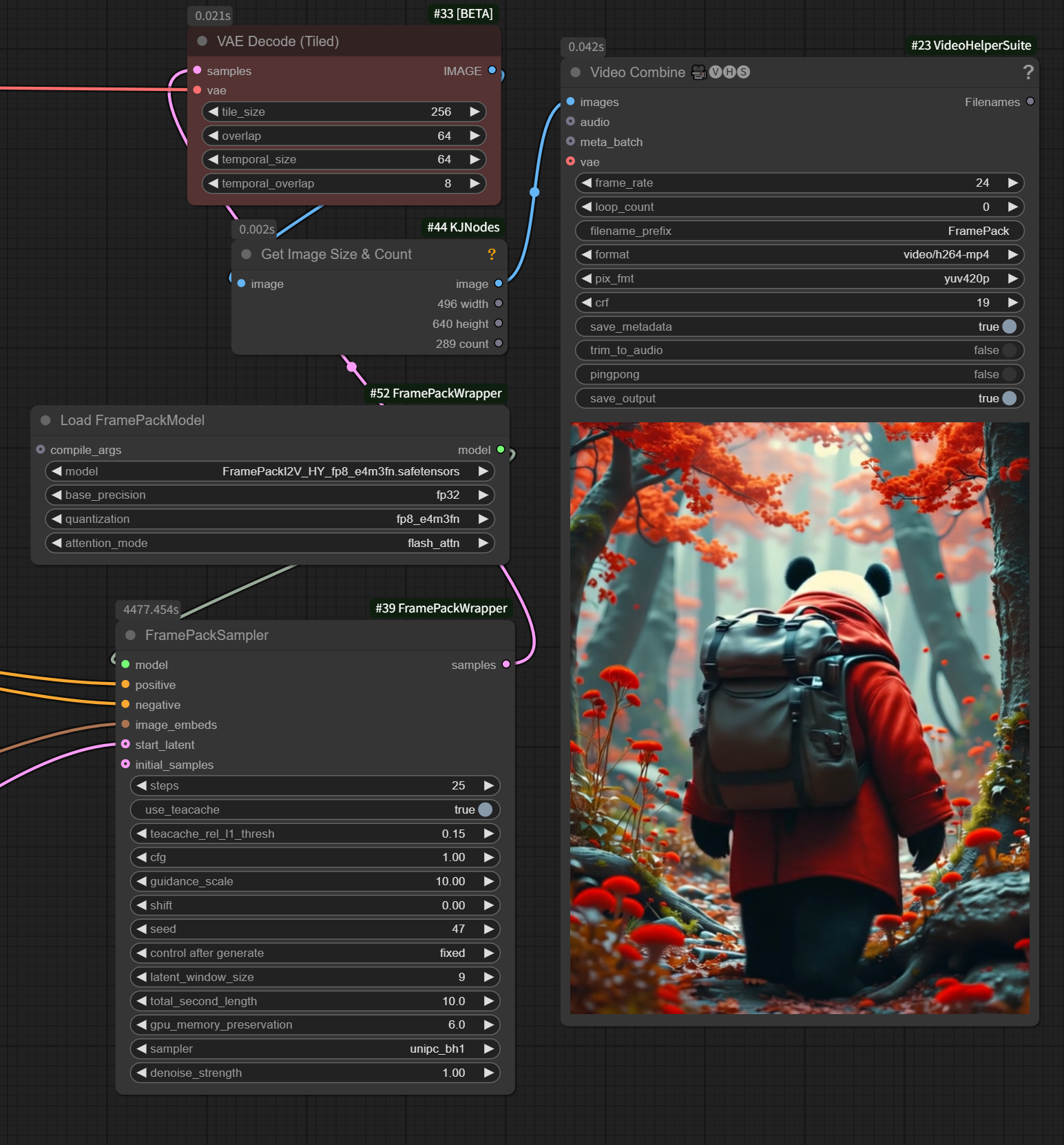
但貌似使用fp32代替bf16就可以了,而且同样的参数跑视频,速度比4060ti16g还要快(4990秒,还是跑的20步,而我是4477秒25步),看来也还没算买错。(2025.4.19测试数据)