22、近端策略优化算法(PPO)论文笔记
近端策略优化算法(PPO)论文笔记
- 一、研究背景与目标
- 二、**方法**
- **3.1 策略梯度基础**
- **3.2 信任区域方法(TRPO)**
- **3.3 剪切代理目标函数(LCLIP)**
- **3.4 自适应KL惩罚系数**
- **3.5 算法实现**
- 三、 L CLIP L_{\text{CLIP}} LCLIP 图解
- 1、策略梯度知识点回顾
- 策略梯度公式推导
- **1. 目标函数定义**
- **2. 梯度计算**
- **3. 对数概率的引入**
- **4. 轨迹概率分解**
- **5. 策略梯度定理**
- **6. 优势函数与方差降低**
- **七、改进方法**
- 2、ppo原理推导
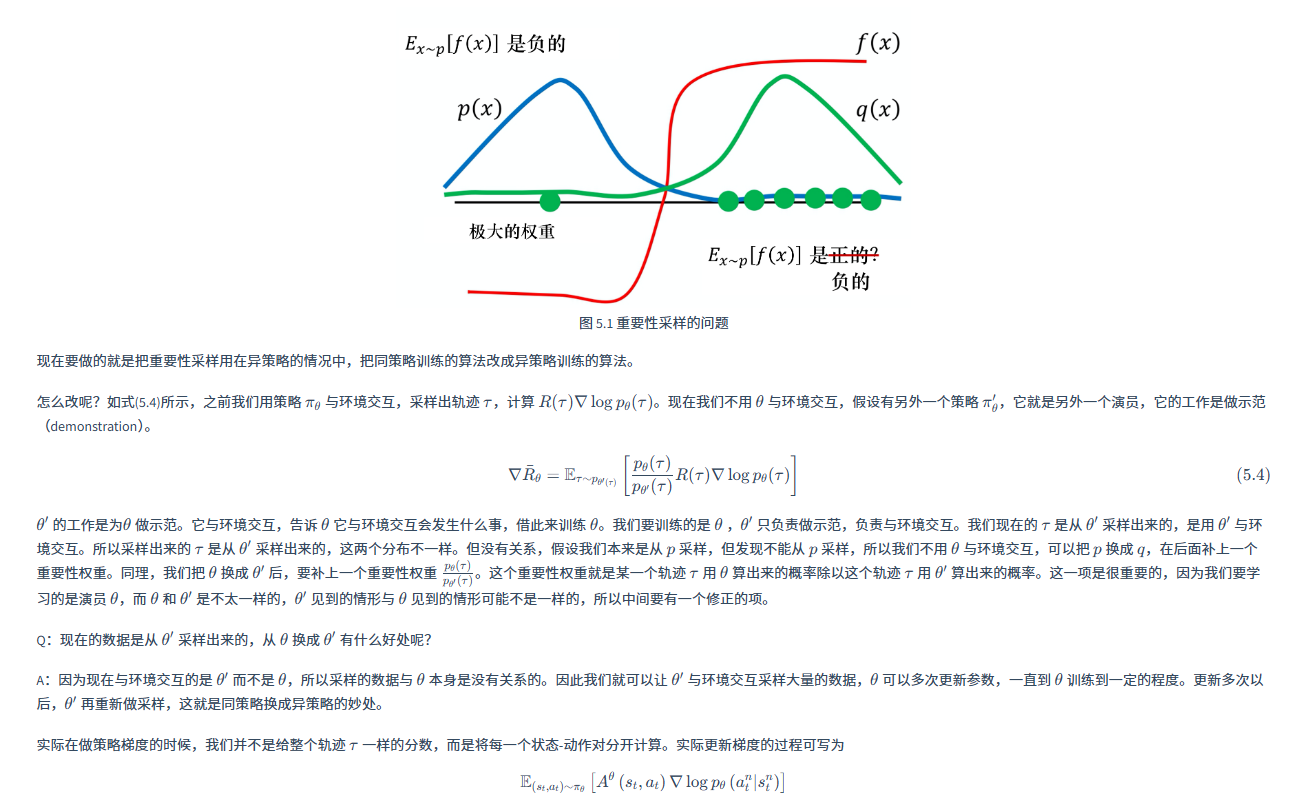
- 1、 重要性采样
- 2、根据梯度反推目标函数
- 示例1:重采样
- 示例2:策略梯度
- 3、PPO算法
- 3、新旧策略如何更新?
- 1.多次使用采样
- 一、新旧策略的采样机制
- 二、多次使用采样的核心机制
- 1. **重要性采样(Importance Sampling)**
- 2. **数据复用的具体实现**
- 3. **稳定性保障**
- 2.是同策略还是异策略?
- 一、同策略的本质:数据生成与优化的一致性
- 1. **策略更新的基准依赖**
- 2. **策略连续性要求**
- 3. **同策略的理论定位**
- 二、异策略技巧的引入:数据复用与稳定性平衡
- 1. **重要性采样的应用**
- 2. **数据复用的局限性**
- 3. **混合特性的实际意义**
- 三、关键对比:同策略与异策略的本质区别
- 四、实际应用中的表现与验证
- 1. **多智能体环境中的实证**
- 2. **RLHF中的应用**
- 五、总结
- 4、策略梯度优化(优势估计)
- 一、优势函数的定义与作用
- 1. **优势函数(Advantage Function)**
- **2. 优势估计的作用**
- 二、优势估计的核心方法
- 1. **蒙特卡洛(Monte Carlo, MC)估计**
- 2. **时间差分(Temporal Difference, TD)估计**
- 3. **广义优势估计(Generalized Advantage Estimation, GAE)**
- 4. **截断重要性采样(Truncated Importance Sampling)**
- 三、优势估计在算法中的应用
- 1. **策略梯度中的优势加权**
- 2. **PPO中的优势处理**
- 3. **价值函数的同步训练**
- 四、关键挑战与改进方向
- 1. **价值函数的偏差**
- 2. **超参数敏感性**
- 3. **高维/连续动作空间**
- 4. **离线强化学习中的挑战**
- 五、总结
一、研究背景与目标
-
现有强化学习方法的不足
- DQN:在离散动作空间(如Atari)有效,但在连续控制任务(如OpenAI Gym)中表现不佳。
- 策略梯度(Vanilla PG):数据效率低、鲁棒性差,直接多次优化易导致策略破坏性更新。
- 信任区域策略优化(TRPO):稳定性和数据效率好,但实现复杂,不兼容含噪声架构(如Dropout)或参数共享场景。
-
PPO的目标
提出一种结合TRPO数据效率和鲁棒性,同时仅用一阶优化(如SGD)、更简单通用的策略梯度方法,适用于大规模模型和并行实现。
二、方法
3.1 策略梯度基础
- 策略梯度估计:通过计算策略梯度并用随机梯度上升优化,公式为:
g ^ = E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] \hat{g} = \mathbb{E}_t\left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] g^=Et[∇θlogπθ(at∣st)A^t]
其中 A ^ t \hat{A}_t A^t 是优势函数估计值。 - 问题:多次更新同一轨迹可能导致策略更新过大,破坏稳定性。
3.2 信任区域方法(TRPO)
- 目标函数:最大化代理目标函数,同时约束策略更新的KL散度:
max θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A ^ t ] s.t. E t [ KL [ π θ old ( ⋅ ∣ s t ) , π θ ( ⋅ ∣ s t ) ] ] ≤ δ \max_{\theta} \mathbb{E}_t\left[ \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t \right] \quad \text{s.t.} \quad \mathbb{E}_t\left[ \text{KL}[\pi_{\theta_{\text{old}}}(\cdot | s_t), \pi_\theta(\cdot | s_t)] \right] \leq \delta θmaxEt[πθold(at∣st)πθ(at∣st)A^t]s.t.Et[KL[πθold(⋅∣st),πθ(⋅∣st)]]≤δ - 实现挑战:需共轭梯度法求解,且难以处理复杂架构。
3.3 剪切代理目标函数(LCLIP)
- 核心思想:通过裁剪概率比 r t ( θ ) r_t(\theta) rt(θ),限制策略更新幅度,公式为:
L CLIP ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ε , 1 + ε ) A ^ t ) ] L_{\text{CLIP}}(\theta) = \mathbb{E}_t\left[ \min\left(r_t(\theta)\hat{A}_t, \text{clip}(r_t(\theta), 1-\varepsilon, 1+\varepsilon)\hat{A}_t \right) \right] LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ε,1+ε)A^t)]- 动机:防止 r t ( θ ) r_t(\theta) rt(θ) 偏离1过远,避免过度更新。
- 优势:提供代理目标的下界(悲观估计),确保策略改进的单调性。
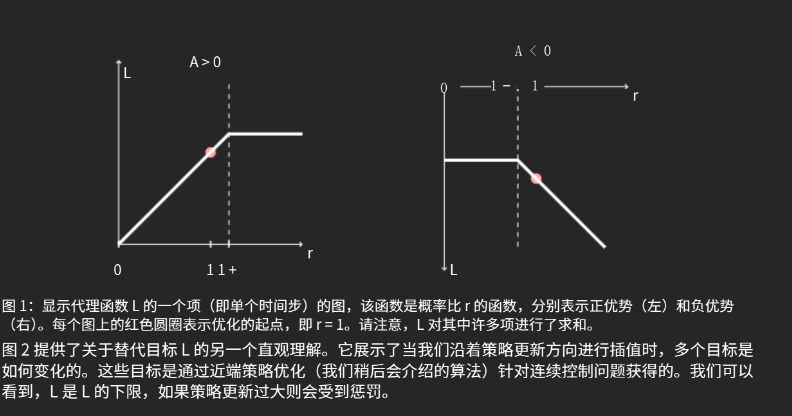
- 可视化:图1展示了不同优势符号下剪切函数的行为;图2表明 L CLIP L_{\text{CLIP}} LCLIP 是 L CPI L_{\text{CPI}} LCPI 的保守下界。
3.4 自适应KL惩罚系数
- 替代方案:通过调整KL散度惩罚系数 β \beta β,维持目标KL值 d targ d_{\text{targ}} dtarg。
- 调整规则:若当前KL值 d < d targ / 1.5 d < d_{\text{targ}}/1.5 d<dtarg/1.5,则 β ← β / 2 \beta \leftarrow \beta/2 β←β/2;若 d > d targ × 1.5 d > d_{\text{targ}} \times 1.5 d>dtarg×1.5,则 β ← β × 2 \beta \leftarrow \beta \times 2 β←β×2。
- 实验结果:剪切方法 L CLIP L_{\text{CLIP}} LCLIP 表现优于KL惩罚方法。
3.5 算法实现
目标函数组合:结合策略损失、价值函数误差(均方损失)和熵奖励(鼓励探索)
- 目标函数:结合策略梯度、价值函数误差和熵奖励:
L CLIP + V + S ( θ ) = E t [ L CLIP ( θ ) − c 1 L VF ( θ ) + c 2 S [ π θ ] ( s t ) ] L_{\text{CLIP}+V+S}(\theta) = \mathbb{E}_t\left[ L_{\text{CLIP}}(\theta) - c_1 L_{\text{VF}}(\theta) + c_2 S[\pi_\theta](s_t) \right] LCLIP+V+S(θ)=Et[LCLIP(θ)−c1LVF(θ)+c2S[πθ](st)]- 价值函数误差:均方误差 ( V θ ( s t ) − V targ ( s t ) ) 2 (V_\theta(s_t) - V_{\text{targ}}(s_t))^2 (Vθ(st)−Vtarg(st))2。
- 熵奖励:鼓励探索。
- 训练流程:
- 并行采集轨迹数据(固定长度 T T T 步)。
- 使用小批量SGD(或Adam)优化目标函数 K K K 轮。
- 更新策略参数 θ old ← θ \theta_{\text{old}} \leftarrow \theta θold←θ。
算法流程
- 采样阶段:N个并行智能体各采集T步数据,计算优势函数估计(如广义优势估计GAE)。
- 优化阶段:对采样数据进行K个epoch的小批量SGD(或Adam),目标函数结合裁剪替代目标、价值函数误差和熵正则化,支持策略与价值函数参数共享。
三、 L CLIP L_{\text{CLIP}} LCLIP 图解
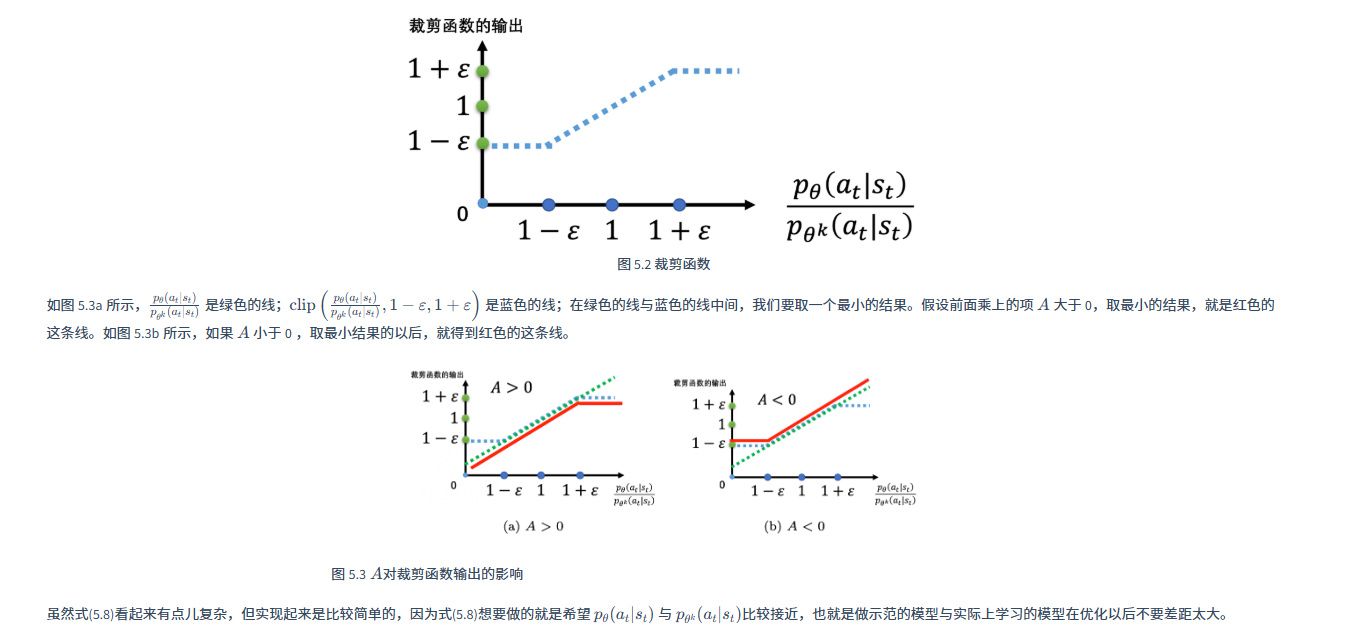
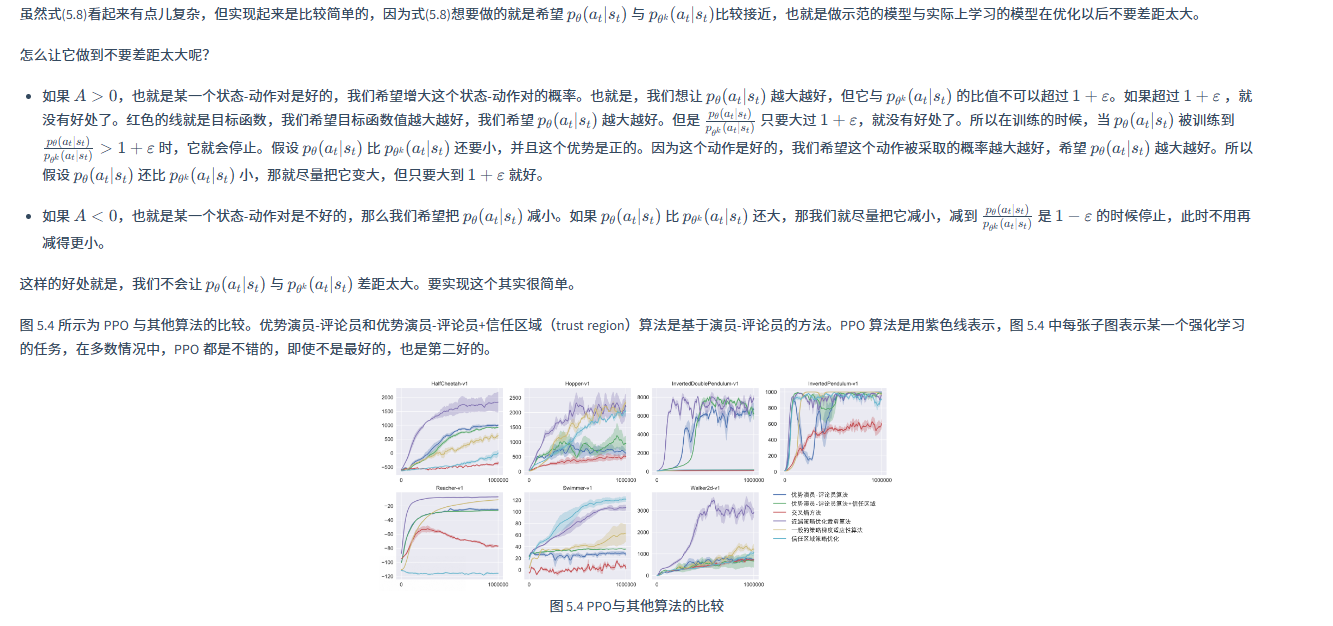
如图5.3a所示, p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) \frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)} pθ′(at∣st)pθ(at∣st) 是绿色的线; c l i p ( p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) , 1 − ε , 1 + ε ) clip\left(\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}, 1 - \varepsilon, 1 + \varepsilon\right) clip(pθ′(at∣st)pθ(at∣st),1−ε,1+ε) 是蓝色的线; ∑ ( s t , a t ) min ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) , c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ε , 1 + ε ) A θ k ( s t , a t ) ) \sum_{(s_t, a_t)} \min \left( \frac{p_\theta(a_t | s_t)}{p_{\theta^k}(a_t | s_t)} A^{\theta^k}(s_t, a_t), \ clip \left( \frac{p_\theta(a_t | s_t)}{p_{\theta^k}(a_t | s_t)}, 1 - \varepsilon, 1 + \varepsilon \right) A^{\theta^k}(s_t, a_t) \right) ∑(st,at)min(pθk(at∣st)pθ(at∣st)Aθk(st,at), clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)Aθk(st,at))是红色线,在绿色的线与蓝色的线中间,我们要取一个最小的结果。
原图:
1、策略梯度知识点回顾
强化学习: 优化目标、价值函数、策略梯度方法,它们之间的联系与区别
1.优化目标:最大化累积奖励为最终优化目标,价值函数和策略梯度是实现这一目标的手段。
2. 价值函数和策略梯度(优化目标)
- 价值函数(优化目标):价值函数衡量
“状态”或“状态-动作对”的长期价值,分为状态价值函数 V π ( s ) V^\pi(s) Vπ(s) 和 动作价值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a)。- 状态价值函数 V π ( s ) V^\pi(s) Vπ(s):表示在状态 s s s 下,遵循策略 π \pi π 的期望回报。
V π ( s ) = E π [ G t ∣ S t = s ] V^\pi(s) = \mathbb{E}_\pi \left[ G_t \mid S_t = s \right] Vπ(s)=Eπ[Gt∣St=s] - 动作价值函数 Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):表示在状态 s s s 下执行动作 a a a,之后遵循策略 π \pi π 的期望回报。
Q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] Q^\pi(s, a) = \mathbb{E}_\pi \left[ G_t \mid S_t = s, A_t = a \right] Qπ(s,a)=Eπ[Gt∣St=s,At=a] - 最优价值函数(Optimal Value Function)
当智能体找到最优策略 π ∗ \pi^* π∗ 时,对应最优价值函数:
V ∗ ( s ) = max π V π ( s ) , Q ∗ ( s , a ) = max π Q π ( s , a ) V^*(s) = \max_\pi V^\pi(s), \quad Q^*(s,a) = \max_\pi Q^\pi(s,a) V∗(s)=πmaxVπ(s),Q∗(s,a)=πmaxQπ(s,a)
通过最优价值函数寻找最优策略,先学习值函数然后从中导出策略,间接优化策略(如选择价值最高的动作),属于“间接法
- 状态价值函数 V π ( s ) V^\pi(s) Vπ(s):表示在状态 s s s 下,遵循策略 π \pi π 的期望回报。
- 策略梯度(优化目标):
目标函数定义:策略 π θ ( a ∣ s ) \pi_\theta(a|s) πθ(a∣s) 是一个由参数 θ \theta θ 决定的概率分布,表示在状态 s s s 下选择动作 a a a 的概率。目标函数 J ( θ ) J(\theta) J(θ) 定义为:
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] J(θ)=Eτ∼πθ[R(τ)]
其中 τ = ( s 0 , a 0 , s 1 , a 1 , … ) \tau = (s_0, a_0, s_1, a_1, \dots) τ=(s0,a0,s1,a1,…) 是轨迹, R ( τ ) = ∑ t = 0 T γ t r t R(\tau) = \sum_{t=0}^T \gamma^t r_t R(τ)=∑t=0Tγtrt 是折扣累积回报, γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1] 是折扣因子 。
策略梯度方法是一类强化学习算法,其核心思想是直接在策略空间中搜索最优策略,而不是先学习值函数然后从中导出策略。这些算法通过优化参数化的策略函数(通常是一个神经网络),使得期望的累积奖励最大化。
具体来讲在深度强化中(我们现在使用的强化学习算法都是深度强化学习)策略π \pi π就是一个神经网络,神经网络的参数是θ \theta θ。参考:链接
- 价值函数和策略梯度区别:显式 vs. 隐式策略
- 价值函数 (隐式策略)
通过估计价值函数,间接优化策略(如选择价值最高的动作),属于“间接法”。需依赖显式策略(如贪心策略)将值函数转化为动作选择。例如,Q-learning 需要从 Q ( s , a ) Q(s,a) Q(s,a) 中选择最大值对应的动作 。特点: 更适合离散动作空间和确定性环境(如 Q-learning、DQN),但难以直接处理连续动作 。 - 策略梯度方法 (显式)
直接参数化策略(如神经网络输出动作概率分布),无需显式设计策略,策略本身是可微分的 。特点:直接对策略参数求梯度,可处理连续动作空间和随机策略。
策略梯度公式推导参考:链接备份:链接
全面强化学习教程:链接 https://github.com/datawhalechina/easy-rl
- 价值函数 (隐式策略)
策略梯度公式推导
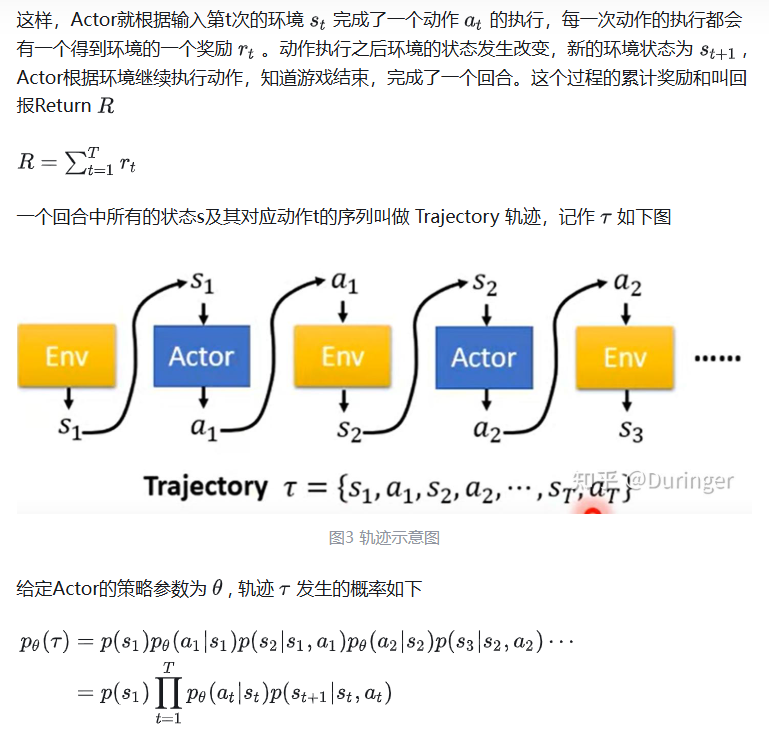

策略梯度公式推导参考:链接
1. 目标函数定义
策略梯度的目标是最大化期望回报 J ( θ ) J(\theta) J(θ),其中 θ \theta θ 是策略参数(例如神经网络权重)。
目标函数:
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] J(θ)=Eτ∼πθ[R(τ)]
- τ \tau τ 表示轨迹(trajectory),即状态-动作序列 ( s 0 , a 0 , r 0 , s 1 , a 1 , r 1 , . . . , s T ) (s_0, a_0, r_0, s_1, a_1, r_1, ..., s_T) (s0,a0,r0,s1,a1,r1,...,sT)。
- R ( τ ) R(\tau) R(τ) 是轨迹的总回报(未折扣或折扣后的累积奖励)。
2. 梯度计算
为了优化策略参数 θ \theta θ,我们需要计算目标函数 J ( θ ) J(\theta) J(θ) 的梯度:
∇ θ J ( θ ) = ∇ θ E τ ∼ π θ [ R ( τ ) ] \nabla_\theta J(\theta) = \nabla_\theta \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] ∇θJ(θ)=∇θEτ∼πθ[R(τ)]
根据数学期望的定义,将其展开为积分形式:
∇ θ J ( θ ) = ∇ θ ∫ P ( τ ∣ θ ) R ( τ ) d τ \nabla_\theta J(\theta) = \nabla_\theta \int P(\tau|\theta) R(\tau) d\tau ∇θJ(θ)=∇θ∫P(τ∣θ)R(τ)dτ
由于 R ( τ ) R(\tau) R(τ) 与 θ \theta θ 无关,可交换积分和梯度:
∇ θ J ( θ ) = ∫ ∇ θ P ( τ ∣ θ ) R ( τ ) d τ \nabla_\theta J(\theta) = \int \nabla_\theta P(\tau|\theta) R(\tau) d\tau ∇θJ(θ)=∫∇θP(τ∣θ)R(τ)dτ
3. 对数概率的引入
利用微分恒等式: ∇ P ( τ ∣ θ ) = P ( τ ∣ θ ) ∇ log P ( τ ∣ θ ) \nabla P(\tau|\theta) = P(\tau|\theta) \nabla \log P(\tau|\theta) ∇P(τ∣θ)=P(τ∣θ)∇logP(τ∣θ),代入上式:
∇ θ J ( θ ) = ∫ P ( τ ∣ θ ) ∇ θ log P ( τ ∣ θ ) R ( τ ) d τ \nabla_\theta J(\theta) = \int P(\tau|\theta) \nabla_\theta \log P(\tau|\theta) R(\tau) d\tau ∇θJ(θ)=∫P(τ∣θ)∇θlogP(τ∣θ)R(τ)dτ
这一步的关键是将复杂的概率梯度 ∇ P ( τ ∣ θ ) \nabla P(\tau|\theta) ∇P(τ∣θ) 转换为更易处理的对数形式 ∇ log P ( τ ∣ θ ) \nabla \log P(\tau|\theta) ∇logP(τ∣θ)。
4. 轨迹概率分解
轨迹 τ \tau τ 的概率 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ) 可分解为:
P ( τ ∣ θ ) = P ( s 0 ) ∏ t = 0 T π θ ( a t ∣ s t ) P ( s t + 1 ∣ s t , a t ) P(\tau|\theta) = P(s_0) \prod_{t=0}^T \pi_\theta(a_t|s_t) P(s_{t+1}|s_t, a_t) P(τ∣θ)=P(s0)t=0∏Tπθ(at∣st)P(st+1∣st,at)
其中:
- P ( s 0 ) P(s_0) P(s0) 是初始状态分布;
- π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st) 是策略在状态 s t s_t st 下选择动作 a t a_t at 的概率;
- P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t, a_t) P(st+1∣st,at) 是环境转移概率(与 θ \theta θ 无关)。
因此,对数概率为:
log P ( τ ∣ θ ) = log P ( s 0 ) + ∑ t = 0 T log π θ ( a t ∣ s t ) + ∑ t = 0 T log P ( s t + 1 ∣ s t , a t ) \log P(\tau|\theta) = \log P(s_0) + \sum_{t=0}^T \log \pi_\theta(a_t|s_t) + \sum_{t=0}^T \log P(s_{t+1}|s_t, a_t) logP(τ∣θ)=logP(s0)+t=0∑Tlogπθ(at∣st)+t=0∑TlogP(st+1∣st,at)
由于 P ( s 0 ) P(s_0) P(s0) 和 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t, a_t) P(st+1∣st,at) 与 θ \theta θ 无关,其梯度为 0。最终:
∇ θ log P ( τ ∣ θ ) = ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) \nabla_\theta \log P(\tau|\theta) = \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) ∇θlogP(τ∣θ)=t=0∑T∇θlogπθ(at∣st)
5. 策略梯度定理
将上述结果代入梯度公式:
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ R ( τ ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot R(\tau) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)⋅R(τ)]
这就是策略梯度定理,它表明策略梯度可以通过采样轨迹的对数概率乘以总回报来估计。
6. 优势函数与方差降低
在实际应用中,直接使用总回报 R ( τ ) R(\tau) R(τ) 可能导致高方差。为此,引入优势函数 A ( s t , a t ) A(s_t, a_t) A(st,at) 来替代 R ( τ ) R(\tau) R(τ):
∇ θ J ( θ ) = E τ ∼ π θ [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ A ( s t , a t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot A(s_t, a_t) \right] ∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)⋅A(st,at)]
常见的优势函数包括:
- 蒙特卡洛回报: A ( s t , a t ) = G t A(s_t, a_t) = G_t A(st,at)=Gt(从时间步 t t t 开始的累积折扣回报)。
- 广义优势估计 (GAE):结合多步回报,平衡偏差和方差。
七、改进方法
- 降低方差:引入基线(Baseline),如使用状态值函数 V ( s ) V(s) V(s):
∇ θ J ( θ ) ≈ E [ ∑ t = 0 T ∇ θ log π θ ( a t ∣ s t ) ⋅ ( Q ( s t , a t ) − V ( s t ) ) ] \nabla_\theta J(\theta) \approx \mathbb{E} \left[ \sum_{t=0}^T \nabla_\theta \log \pi_\theta(a_t|s_t) \cdot (Q(s_t,a_t) - V(s_t)) \right] ∇θJ(θ)≈E[t=0∑T∇θlogπθ(at∣st)⋅(Q(st,at)−V(st))] - Actor-Critic:结合值函数(Critic)和策略梯度(Actor),用Critic估计值函数辅助训练。
- 自然策略梯度/TRPO/PPO:通过约束策略更新的幅度,保证稳定性。
扩展与改进
- REINFORCE 算法:基于蒙特卡洛方法的策略梯度算法,直接使用总回报 G t G_t Gt。
- Actor-Critic 方法:结合值函数(Critic)评估优势函数,提升策略更新效率。
- PPO(Proximal Policy Optimization):通过约束策略更新幅度,避免过大的参数变化。
强化学习基于策略的方法
参考:
强化学习参考:链接
策略梯度公式推导参考:链接 https://zhuanlan.zhihu.com/p/30614572553
全面强化学习教程参考:链接 https://github.com/datawhalechina/easy-rl
其他参考:
https://blog.csdn.net/weixin_71288092/article/details/147672830
https://blog.csdn.net/qq_51399582/article/details/144205063
https://blog.csdn.net/weixin_55252589/article/details/145641271
https://www.cnblogs.com/uzuki/p/14289990.html
2、ppo原理推导
1、 重要性采样
教程参考:链接 备份:链接





2、根据梯度反推目标函数
对数求导:

示例1:重采样

目标函数 J θ ′ ( θ ) J^{\theta'}(\theta) Jθ′(θ) 的推导基于梯度公式 ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x) = f(x) \nabla \log f(x) ∇f(x)=f(x)∇logf(x)。对式(5.5) E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ∇ log p θ ( a t ∣ s t ) ] \mathbb{E}_{(s_t, a_t) \sim \pi_{\theta'}} \left[ \frac{p_\theta(a_t | s_t)}{p_{\theta'}(a_t | s_t)} A^{\theta'}(s_t, a_t) \nabla \log p_\theta(a_t | s_t) \right] E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(at∣st)],将其视为 ∇ J θ ′ ( θ ) \nabla J^{\theta'}(\theta) ∇Jθ′(θ)。根据梯度公式,反推 J θ ′ ( θ ) J^{\theta'}(\theta) Jθ′(θ) 为期望形式:
J θ ′ ( θ ) = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ] J^{\theta'}(\theta) = \mathbb{E}_{(s_t, a_t) \sim \pi_{\theta'}} \left[ \frac{p_\theta(a_t | s_t)}{p_{\theta'}(a_t | s_t)} A^{\theta'}(s_t, a_t) \right] Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
具体分析:
- 对 θ \theta θ 求梯度时, p θ ′ ( a t ∣ s t ) p_{\theta'}(a_t | s_t) pθ′(at∣st) 和 A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at) 是常数。
- 利用 ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x) = f(x) \nabla \log f(x) ∇f(x)=f(x)∇logf(x),式(5.5)中 p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) \frac{p_\theta(a_t | s_t)}{p_{\theta'}(a_t | s_t)} A^{\theta'}(s_t, a_t) pθ′(at∣st)pθ(at∣st)Aθ′(st,at) 对应 f ( x ) f(x) f(x), ∇ log p θ ( a t ∣ s t ) \nabla \log p_\theta(a_t | s_t) ∇logpθ(at∣st) 对应 ∇ log f ( x ) \nabla \log f(x) ∇logf(x)(这里 f ( x ) f(x) f(x) 实质是 p θ ( a t ∣ s t ) p_\theta(a_t | s_t) pθ(at∣st) 相关部分)。
- 因此,去掉梯度后,目标函数 J θ ′ ( θ ) J^{\theta'}(\theta) Jθ′(θ) 即为上述期望形式,它通过重要性采样 p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) \frac{p_\theta(a_t | s_t)}{p_{\theta'}(a_t | s_t)} pθ′(at∣st)pθ(at∣st),结合优势函数 A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at),在 θ ′ \theta' θ′ 采样的 ( s t , a t ) (s_t, a_t) (st,at) 上求期望,形成可计算的优化目标。
示例2:策略梯度

目标函数 L P G ( θ ) = E ^ t [ log π θ ( a t ∣ s t ) A ^ t ] L^{PG}(\theta) = \hat{\mathbb{E}}_t \left[ \log \pi_\theta(a_t | s_t) \hat{A}_t \right] LPG(θ)=E^t[logπθ(at∣st)A^t] 的推导基于策略梯度定理和梯度与函数的关系,具体步骤如下:
-
策略梯度定理:策略 π θ \pi_\theta πθ 的梯度为 ∇ θ J ( θ ) = E s t , a t ∼ π θ [ ∇ θ log π θ ( a t ∣ s t ) A π ( s t , a t ) ] \nabla_\theta J(\theta) = \mathbb{E}_{s_t, a_t \sim \pi_\theta} \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) A^\pi(s_t, a_t) \right] ∇θJ(θ)=Est,at∼πθ[∇θlogπθ(at∣st)Aπ(st,at)],其中 A π ( s t , a t ) A^\pi(s_t, a_t) Aπ(st,at) 是优势函数。实际应用中,用经验期望 E ^ t \hat{\mathbb{E}}_t E^t 近似期望,用 A ^ t \hat{A}_t A^t 估计优势函数,得到梯度估计 g ^ = E ^ t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] \hat{g} = \hat{\mathbb{E}}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] g^=E^t[∇θlogπθ(at∣st)A^t](公式(1))。
-
构造目标函数:利用梯度公式 ∇ f ( x ) = f ( x ) ∇ log f ( x ) \nabla f(x) = f(x) \nabla \log f(x) ∇f(x)=f(x)∇logf(x) 的逆思路,若希望目标函数的梯度为 g ^ \hat{g} g^,则构造 L P G ( θ ) = E ^ t [ log π θ ( a t ∣ s t ) A ^ t ] L^{PG}(\theta) = \hat{\mathbb{E}}_t \left[ \log \pi_\theta(a_t | s_t) \hat{A}_t \right] LPG(θ)=E^t[logπθ(at∣st)A^t]。对 L P G ( θ ) L^{PG}(\theta) LPG(θ) 求梯度 ∇ θ L P G ( θ ) \nabla_\theta L^{PG}(\theta) ∇θLPG(θ),根据求导法则,直接得到 E ^ t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] \hat{\mathbb{E}}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] E^t[∇θlogπθ(at∣st)A^t],与公式(1)的梯度估计量一致。
综上,通过策略梯度定理确定梯度形式,再构造目标函数使其梯度匹配该形式,最终得到 L P G ( θ ) = E ^ t [ log π θ ( a t ∣ s t ) A ^ t ] L^{PG}(\theta) = \hat{\mathbb{E}}_t \left[ \log \pi_\theta(a_t | s_t) \hat{A}_t \right] LPG(θ)=E^t[logπθ(at∣st)A^t]。
3、PPO算法
教程参考:链接 备份:链接



如图5.3a所示, p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) \frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)} pθ′(at∣st)pθ(at∣st) 是绿色的线; c l i p ( p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) , 1 − ε , 1 + ε ) clip\left(\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}, 1 - \varepsilon, 1 + \varepsilon\right) clip(pθ′(at∣st)pθ(at∣st),1−ε,1+ε) 是蓝色的线; ∑ ( s t , a t ) min ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) A θ k ( s t , a t ) , c l i p ( p θ ( a t ∣ s t ) p θ k ( a t ∣ s t ) , 1 − ε , 1 + ε ) A θ k ( s t , a t ) ) \sum_{(s_t, a_t)} \min \left( \frac{p_\theta(a_t | s_t)}{p_{\theta^k}(a_t | s_t)} A^{\theta^k}(s_t, a_t), \ clip \left( \frac{p_\theta(a_t | s_t)}{p_{\theta^k}(a_t | s_t)}, 1 - \varepsilon, 1 + \varepsilon \right) A^{\theta^k}(s_t, a_t) \right) ∑(st,at)min(pθk(at∣st)pθ(at∣st)Aθk(st,at), clip(pθk(at∣st)pθ(at∣st),1−ε,1+ε)Aθk(st,at))是红色线,在绿色的线与蓝色的线中间,我们要取一个最小的结果。
3、新旧策略如何更新?
1.多次使用采样
在PPO(Proximal Policy Optimization)算法中,新旧策略的采样与多次使用采样是通过重要性采样和数据复用机制实现的,其核心目标是在保证策略稳定性的同时提升数据利用效率。以下是具体机制与实现细节:
一、新旧策略的采样机制
1. 旧策略( π θ old \pi_{\theta_{\text{old}}} πθold)生成数据
- 角色:旧策略负责与环境交互,生成用于训练的轨迹数据(状态、动作、奖励等)。
- 流程:
- 使用旧策略在环境中执行动作,生成一批轨迹(Rollout),每个轨迹包含状态序列 { s t } \{s_t\} {st}、动作序列 { a t } \{a_t\} {at}、奖励序列 { r t } \{r_t\} {rt} 等。
- 存储旧策略在每个动作上的概率 π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t|s_t) πθold(at∣st) 和价值估计 V θ old ( s t ) V_{\theta_{\text{old}}}(s_t) Vθold(st),用于后续计算优势函数和重要性权重。
- 作用:旧策略的数据为新策略的优化提供基准,避免策略更新失去参考。
2. 新策略( π θ \pi_{\theta} πθ)的优化与采样
- 角色:新策略基于旧策略生成的数据进行参数更新,同时通过限制更新幅度保证稳定性。
- 流程:
- 优势估计:利用广义优势估计(GAE)计算每个动作的优势 A t A_t At,评估动作的相对价值。
- 目标函数优化:通过最大化裁剪后的目标函数(PPO-Clip)或引入KL散度惩罚项(PPO-Penalty)来更新新策略的参数,确保每次更新仅在旧策略的邻近区域内改进。
- 重复使用数据:在同一批旧数据上进行多次迭代优化(如3-5轮),通过重要性采样权重调整梯度方向,避免数据分布变化导致的不稳定。
二、多次使用采样的核心机制
1. 重要性采样(Importance Sampling)
- 作用:允许旧策略生成的数据用于优化新策略,通过权重补偿新旧策略的分布差异。
- 权重计算:
- 概率比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),衡量新策略相对于旧策略选择动作的概率变化。
- 重要性权重为 r t ( θ ) r_t(\theta) rt(θ),用于调整旧数据对新策略梯度的贡献。
- 挑战:若新旧策略差异过大,权重可能出现高方差,导致训练不稳定。PPO通过裁剪机制或KL散度惩罚限制权重范围,平衡数据复用与稳定性。
2. 数据复用的具体实现
- 多轮更新:
- 在PPO中,同一批旧数据可被重复使用多次(如3-5轮),每次迭代使用不同的小批量(mini-batch)数据进行梯度更新。
- 例如,OpenAI的PPO实现通常在每个Rollout后进行3-10次策略更新,通过减小学习率和调整裁剪参数( ϵ \epsilon ϵ)控制更新幅度。
- 数据预处理:
- 归一化:对奖励和优势进行归一化,减少数据方差对训练的影响。
- 打乱数据:将轨迹分割成小批量并随机打乱,避免梯度更新的顺序偏差。
3. 稳定性保障
- 裁剪机制(PPO-Clip):
- 将概率比率 r t ( θ ) r_t(\theta) rt(θ) 限制在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ] 范围内,强制新策略的更新幅度不超过旧策略的 ϵ \epsilon ϵ 倍。
- 目标函数为:
L CLIP ( θ ) = E t [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] L^{\text{CLIP}}(\theta) = \mathbb{E}_t \left[ \min\left(r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right] LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
- KL散度惩罚(PPO-Penalty):
- 在目标函数中加入KL散度惩罚项 β ⋅ KL ( π θ old ∣ ∣ π θ ) \beta \cdot \text{KL}(\pi_{\theta_{\text{old}}} || \pi_\theta) β⋅KL(πθold∣∣πθ),动态调整 β \beta β 以控制策略差异。
- 若KL散度超过阈值,增大 β \beta β 以限制更新;反之则减小 β \beta β,平衡探索与利用。
2.是同策略还是异策略?
PPO(Proximal Policy Optimization)的新旧策略属于同策略(on-policy),但其实现机制融合了部分异策略(off-policy)的技巧,形成了独特的混合特性。以下是核心分析:

先回顾同策略和异策略这两种训练方法的区别。在强化学习里面,要学习的是一个智能体。如果要学习的智能体和与环境交互的智能体是相同的,我们称之为同策略。如果要学习的智能体和与环境交互的智能体不是相同的,我们称之为异策略。

为什么我们会想要考虑异策略?让我们回忆一下策略梯度。策略梯度是同策略的算法,因为在策略梯度中,我们需要一个智能体、一个策略和一个演员。演员去与环境交互搜集数据,搜集很多的轨迹τ,根据搜集到的数据按照策略梯度的公式更新策略的参数,所以策略梯度是一个同策略的算法。PPO是策略梯度的变形,


一、同策略的本质:数据生成与优化的一致性
1. 策略更新的基准依赖
PPO的核心逻辑是:新策略的优化必须基于旧策略生成的数据。具体表现为:
- 数据采集:旧策略( π θ old \pi_{\theta_{\text{old}}} πθold)与环境交互生成轨迹数据(状态、动作、奖励等),这些数据是新策略( π θ \pi_{\theta} πθ)优化的唯一依据。
- 目标函数设计:PPO的目标函数(如PPO-Clip)直接依赖旧策略的动作概率 π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t|s_t) πθold(at∣st),通过概率比率 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st) 衡量新旧策略的差异,并强制限制其变化幅度。
2. 策略连续性要求
PPO通过裁剪机制或KL散度惩罚确保新策略与旧策略的差异在可控范围内,本质上是维护策略更新的连续性。例如:
- PPO-Clip将概率比率限制在 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ] 区间内,防止新策略过度偏离旧策略。
- PPO-Penalty通过动态调整KL散度惩罚项 β \beta β,约束新旧策略的分布差异,确保优化方向与旧策略一致。
3. 同策略的理论定位
从强化学习理论框架看:
- 同策略定义:学习的策略(新策略)与生成数据的策略(旧策略)属于同一策略的不同版本,两者在更新过程中保持连续性。
- PPO的归属:尽管PPO允许复用旧数据(类似异策略),但其数据生成策略始终是当前策略的旧版本,且优化目标严格依赖旧策略的概率分布,因此被明确归类为同策略算法。
二、异策略技巧的引入:数据复用与稳定性平衡
1. 重要性采样的应用
PPO通过重要性采样复用旧数据,允许在同一批数据上进行多次策略更新。具体机制为:
- 权重补偿:使用概率比率 r t ( θ ) r_t(\theta) rt(θ) 作为重要性权重,调整旧数据对新策略梯度的贡献,补偿新旧策略的分布差异。
- 方差控制:结合裁剪机制(如PPO-Clip)限制权重范围,避免因策略差异过大导致梯度估计方差爆炸。
2. 数据复用的局限性
尽管PPO复用旧数据,但其复用能力与异策略算法(如DQN、SAC)有本质区别:
- 短期复用:PPO通常在同一批次数据上进行3-5轮更新,而不是无限次复用。
- 策略同步:每轮更新后,旧策略会被新策略完全替代,确保后续数据生成始终基于最新策略。
3. 混合特性的实际意义
PPO的混合特性使其兼具同策略与异策略的优势:
- 稳定性:通过同策略机制保证策略更新的连续性,避免异策略因分布偏移导致的训练崩溃。
- 样本效率:通过异策略技巧复用旧数据,显著减少环境交互次数,提升样本利用率。
三、关键对比:同策略与异策略的本质区别
| 维度 | 同策略(如PPO) | 异策略(如DQN、SAC) |
|---|---|---|
| 数据生成策略 | 旧策略( π θ old \pi_{\theta_{\text{old}}} πθold) | 任意行为策略(如随机策略、旧策略) |
| 策略更新依据 | 严格依赖旧策略生成的数据 | 可使用历史任意策略生成的数据 |
| 策略连续性 | 新策略是旧策略的渐进改进,保持分布连续性 | 新策略与行为策略可能完全独立 |
| 样本效率 | 中高(需定期更新数据) | 高(可无限复用历史数据) |
| 稳定性 | 高(策略更新幅度可控) | 中低(需处理分布偏移问题) |
四、实际应用中的表现与验证
1. 多智能体环境中的实证
在合作多智能体任务(如星际争霸多智能体挑战SMAC)中,PPO作为同策略算法,通过限制策略更新幅度和复用旧数据,取得了与异策略方法(如QMix)相当甚至更优的性能。这验证了其在同策略框架下的有效性。
2. RLHF中的应用
在大模型的人类反馈强化学习(RLHF)中,PPO通过同策略机制确保模型生成的回复质量逐步提升,同时利用重要性采样复用旧数据,显著降低了训练成本。
五、总结
PPO的新旧策略本质上属于同策略,因为其优化过程严格依赖旧策略生成的数据,且通过约束机制保持策略连续性。尽管引入了重要性采样和数据复用技巧(类似异策略),但其核心逻辑仍符合同策略的定义。这种设计使其在保证训练稳定性的同时,显著提升了样本效率,成为强化学习领域的主流算法之一。实际应用中,PPO的同策略特性使其尤其适合需要策略渐进改进的场景,如机器人控制、游戏AI和大模型微调。
4、策略梯度优化(优势估计)
优势估计是强化学习中连接价值评估与策略更新的桥梁,其核心目标是在偏差和方差之间找到平衡。从早期的MC和TD到经典的GAE,优势估计方法的演进推动了策略梯度算法的落地应用(如PPO在机器人控制、游戏AI中的成功)。未来研究可能聚焦于结合模型、自监督学习或自适应参数调整,进一步提升优势估计的鲁棒性和样本效率。
在强化学习中,**优势估计(Advantage Estimation)**是评估特定状态-动作对(s, a)相对于当前状态下平均策略的优势的关键步骤,广泛应用于策略梯度方法(如A2C、PPO、TRPO等)。以下从定义、核心方法、应用及挑战等方面展开分析:
一、优势函数的定义与作用
1. 优势函数(Advantage Function)
优势函数 A π ( s , a ) A^\pi(s, a) Aπ(s,a) 表示在状态 s s s 下采取动作 a a a 相较于“平均动作”的价值优势,数学上定义为:
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^\pi(s, a) = Q^\pi(s, a) - V^\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
其中:
- Q π ( s , a ) Q^\pi(s, a) Qπ(s,a) 是动作价值函数(采取动作 a a a 后的期望回报);
- V π ( s ) V^\pi(s) Vπ(s) 是状态价值函数(当前状态下遵循策略 π \pi π 的期望回报,作为“基线”)。
- 意义:若 A ( s , a ) > 0 A(s, a) > 0 A(s,a)>0,说明动作 a a a 优于策略平均水平,反之则劣。
- 意义:优势函数量化了在状态 s s s 下选择动作 a a a 相对于策略的平均表现( V ( s ) V(s) V(s))的好坏。如果 A ( s , a ) > 0 A(s, a) > 0 A(s,a)>0,说明动作 a a a 比平均策略更好;反之则更差。
2. 优势估计的作用
-
减少方差:通过减去基线 V π ( s ) V^\pi(s) Vπ(s),消除不同状态绝对价值的影响,仅关注动作间的相对优势,降低策略梯度的方差。相较于直接使用Q值,优势函数通过减去基准值V(s),减少了策略梯度估计的方差,提升训练稳定性。
-
指导策略更新:在策略梯度算法中,优势函数作为权重,决定动作 a a a 对策略更新的贡献(优势为正则增加选择概率,负则减少)。
-
明确动作优劣:为策略更新提供直观信号(如PPO算法中优先选择正优势的动作)。
-
降低方差:
使用 A ( s , a ) A(s, a) A(s,a) 代替 Q ( s , a ) Q(s, a) Q(s,a) 作为策略梯度的权重,能有效减少方差,因为 V ( s ) V(s) V(s) 作为基线(baseline)减去了状态本身的固有价值。 -
策略更新方向:
策略梯度公式可写为:
∇ θ J ( θ ) = E π θ [ A ( s , a ) ∇ θ log π θ ( a ∣ s ) ] \nabla_\theta J(\theta) = \mathbb{E}_{\pi_\theta} \left[ A(s, a) \nabla_\theta \log \pi_\theta(a|s) \right] ∇θJ(θ)=Eπθ[A(s,a)∇θlogπθ(a∣s)]
优势函数直接决定了动作的更新幅度。 -
兼容性:
优势估计与Actor-Critic框架天然契合,Critic网络用于估计 V ( s ) V(s) V(s),Actor网络通过优势函数更新策略。
优势估计在强化学习中扮演关键角色,尤其在策略梯度方法(如 PPO、TRPO)中:
- 指导策略更新:
优势函数帮助智能体判断哪些动作值得鼓励(正优势)或抑制(负优势),从而优化策略。例如,在策略梯度算法中,优势函数的梯度方向直接决定了策略的更新方向。 - 减少方差:
通过减去状态值 V ( s ) V(s) V(s),优势函数去除了状态本身的基线影响,降低了策略梯度估计的方差,使训练更稳定。 - 长期规划:
优势估计考虑了未来奖励的折现累积,使智能体能够评估动作的长期影响(如资料[3]中提到的“延迟奖励”问题)。
二、优势估计的核心方法
1. 蒙特卡洛(Monte Carlo, MC)估计
-
方法:直接使用从状态 s s s 出发采取动作 a a a 后的实际回报 G t = r t + γ r t + 1 + ⋯ + γ T − t r T G_t = r_t + \gamma r_{t+1} + \dots + \gamma^{T-t} r_T Gt=rt+γrt+1+⋯+γT−trT 作为优势估计:
• 直接使用完整轨迹的累积回报 G t G_t Gt 作为估计值:
A ( s , a ) = G t − V ( s ) A(s, a) = G_t - V(s) A(s,a)=Gt−V(s) -
优点:无偏差(若价值函数准确),渐近收敛。
-
缺点:方差极高(依赖完整轨迹),样本效率低。
-
特点:无偏但方差高(依赖于完整轨迹的随机性)。
2. 时间差分(Temporal Difference, TD)估计
- 单步TD(TD(0)):用下一状态的价值估计近似未来回报,优势为单步TD误差:
A π ( s t , a t ) = r t + γ V ( s t + 1 ) − V ( s t ) A^\pi(s_t, a_t) = r_t + \gamma V(s_{t+1}) - V(s_t) Aπ(st,at)=rt+γV(st+1)−V(st) - 优点:低方差(仅依赖即时奖励和下一状态价值),在线更新。
- 缺点:有偏差(依赖价值函数近似精度)。
- 特点:低方差但有偏(仅依赖单步奖励和下一个状态的估计值)。
3. 广义优势估计(Generalized Advantage Estimation, GAE)
- 提出背景:平衡MC的无偏性和TD的低方差,由Schulman等人(2016)在PPO中引入。
- 核心思想:结合多步TD误差,通过参数 λ \lambda λ 平衡偏差与方差:
- 公式:通过加权求和多步TD误差,引入参数 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1] 控制偏差-方差权衡:
δ t = r t + γ V ( s t + 1 ) − V ( s t ) ( 单步TD误差 ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) \quad (\text{单步TD误差}) δt=rt+γV(st+1)−V(st)(单步TD误差)
A t G A E ( λ ) = ∑ k = 0 ∞ ( γ λ ) k δ t + k A_t^{GAE(\lambda)} = \sum_{k=0}^\infty (\gamma\lambda)^k \delta_{t+k} AtGAE(λ)=k=0∑∞(γλ)kδt+k
- 当 λ = 0 \lambda = 0 λ=0:退化为单步TD误差 δ t \delta_t δt(低方差,高偏差)。
- 当 λ = 1 \lambda = 1 λ=1:退化为MC估计(无偏,高方差)。
- 优势:通过调整 λ \lambda λ 灵活平衡偏差和方差,成为主流算法(如PPO)的标准配置。
- 优势:灵活调整 λ \lambda λ(接近0时偏向TD,接近1时接近MC),适用于复杂动态环境。
- 特点:通过加权多步TD误差,在偏差和方差之间取得平衡。
GAE(Generalized Advantage Estimation)是 John Schulman 提出的折中方法,通过加权平均 TD 和 MC 估计,在偏差与方差之间取得平衡。其公式为:
A ^ t GAE ( λ ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat{A}_t^{\text{GAE}(\lambda)} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} A^tGAE(λ)=l=0∑∞(γλ)lδt+l
- 参数 λ \lambda λ:
- λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1],控制估计的偏差与方差。
- λ → 0 \lambda \to 0 λ→0:接近 TD 方法(高偏差、低方差)。
- λ → 1 \lambda \to 1 λ→1:接近 MC 方法(低偏差、高方差)。
- 实际应用:
4. 截断重要性采样(Truncated Importance Sampling)
- 在离线强化学习或策略更新间隔较大时,使用重要性采样权重修正旧策略与新策略的差异,但需截断以控制方差。
三、优势估计在算法中的应用
(1) 策略梯度算法
- REINFORCE:直接使用 MC 估计的优势函数更新策略。
- PPO(近端策略优化):结合 GAE 和剪切机制(Clipping),确保策略更新的稳定性(如资料[2]中玛丽游戏的训练流程)。
1. 策略梯度中的优势加权
在策略梯度公式 ∇ J ( π ) ≈ E [ ∇ log π ( a ∣ s ) ⋅ A ( s , a ) ] \nabla J(\pi) \approx \mathbb{E}[\nabla \log \pi(a|s) \cdot A(s, a)] ∇J(π)≈E[∇logπ(a∣s)⋅A(s,a)] 中,优势函数直接作为梯度的权重,决定动作的更新方向和幅度。
2. PPO中的优势处理
PPO通过GAE估计优势,并对优势进行标准化(减去均值、除以标准差),避免不同状态优势的尺度差异影响训练稳定性。
3. 价值函数的同步训练
优势估计依赖状态价值函数 V ( s ) V(s) V(s),通常通过神经网络与策略网络联合训练(如演员-评论家架构),价值函数的准确性直接影响优势估计质量。
四、关键挑战与改进方向
1. 价值函数的偏差
- 若 V ( s ) V(s) V(s) 估计不准确(如过估计或欠估计),优势函数会引入偏差,导致策略更新错误。
- 改进:使用更稳定的价值函数训练方法(如梯度裁剪、正则化),或结合模型预测(Model-Based RL)提升价值估计精度。
2. 超参数敏感性
- GAE中的 λ \lambda λ 和折扣因子 γ \gamma γ 需仔细调优: λ \lambda λ 接近0适合稀疏奖励场景,接近1适合连续奖励场景。
3. 高维/连续动作空间
- 动作空间复杂时,优势估计的方差更高,需结合探索策略(如熵正则化)或经验回放缓解。
4. 离线强化学习中的挑战
- 离线场景下,优势估计需修正分布偏移(Distribution Shift),常用重要性采样或离策略校正技术。
五、总结
优势估计是强化学习中连接价值评估与策略更新的桥梁,其核心目标是在偏差和方差之间找到平衡。从早期的MC和TD到经典的GAE,优势估计方法的演进推动了策略梯度算法的落地应用(如PPO在机器人控制、游戏AI中的成功)。未来研究可能聚焦于结合模型、自监督学习或自适应参数调整,进一步提升优势估计的鲁棒性和样本效率。
| 方法 | 偏差 | 方差 | 适用场景 |
|---|---|---|---|
| TD 方法 | 高 | 低 | 在线学习、快速响应任务 |
| MC 方法 | 低 | 高 | 离线学习、长序列任务 |
| GAE(λ-return) | 可调 | 可调 | 多数强化学习任务(默认选择) |
优势估计是强化学习中连接价值函数与策略优化的核心桥梁。通过合理选择估计方法(如 GAE),智能体能够在复杂环境中高效学习最优策略,推动人工智能在机器人、工业控制、推荐系统等领域的落地应用。