Linux:进程控制1
一:进程创建
1-1 fork函数
在Linux系统里,fork属于系统调用,其作用是创建新进程。新创建的进程叫做子进程,而发起fork调用的进程则为父进程。
工作原理
- fork调用会复制当前进程,生成一个与父进程几乎相同的子进程。这意味着子进程会拥有和父进程一样的代码段,数据段,堆栈等
- fork调用会返回两次:若进程创建成功,在父进程中返回子进程的进程ID(一个正整数),在子进程返回0;若fork创建进程失败,则返回-1
1-2 fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数
1-3 fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程超过了限制
二:进程终止
进程终止的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码
2-1 进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
2-2 退出码
在C语言提供的strerror函数中共有134个错误码, strerror的作用是将错误码转换为对应的错误消息字符串的函数,strerror处于<string.h>头文件中,而在Linux中一般将其的错误码作为程序的退出码用于查看进程的退出情况
1 #include<stdio.h>2 #include<string.h>3 4 int main()5 {6 int i = 0;7 for(;i < 134;i++)8 {9 printf("%d->%s\n",i,strerror(i));10 }11 return 0;12 }
使用上面代码就可以将所有的错误码打印出来,下面我们只截取最常见的前三个,退出码0表示成功,退出码1表示不被允许的操作,退出码2表示没有该文件或目录

2-3 查看退出码
echo $?
此命令用于查看最近一个进程退出时的退出码
正常执行且没有报错:
1 #include<stdio.h>2 #include<string.h>3 4 int main()5 {6 printf("hello world\n");7 return 0;8 }如上图所示,在上面代码中程序没有发生任何报错正常执行运行,所以使用echo $?命令打印其退出码时其值为0
![]()
正常执行却有错:
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 int main()5 {6 FILE* fp = fopen("log.txt","r");7 if(fp == NULL)8 return errno;9 }在上面代码中,我们期望使用fopen函数以只读方式打开一个不存在的文件"log.txt",由于文件不存在所以程序虽然能正常执行完毕但却没有实现打开文件的功能,其退出码为2

当程序自己内部自己设置了返回值是,将会按照自己设置的错误码作为退出码
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 int main()5 {6 FILE* fp = fopen("log.txt","r");7 if(fp == NULL)8 return 13;9 }在上面代码中,我们期望使用fopen函数以只读方式打开一个不存在的文件"log.txt",由于文件不存在所以程序虽然能正常执行完毕但却没有实现打开文件的功能,其退出码应该为2 ,但是由于我们自己设置了返回值为13,所以其退出码为13

程序异常:
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 5 int main()6 {7 int a = 10;8 9 a /= 0;10 11 return 90;12 }如上面代码所示: a /= 0这条代码会报错导致程序异常,当程序异常时,退出码就没有意义,所以我们使用echo $?打印退出码时其值并不是90而是136
![]()
2-4 exit
exit主要用于终止当前进程,相当于return,头文件为<stdlib.h>;exit(status),status代表退出码,此语句表示终止当前进程并返回进程退出码status给父进程
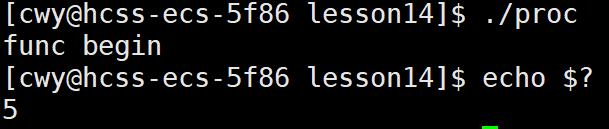
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 #include<unistd.h>5 #include<stdlib.h>6 7 int main()8 { 9 exit(30);10 }如上所示:exit将终止进程并将30作为退出码返回给父进程

1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 #include<unistd.h>5 #include<stdlib.h>6 7 void func()8 {9 printf("func begin\n");10 exit(50);11 printf("func end\n");12 } 13 14 int main()15 { 16 func();17 printf("main\n");18 return 0;19}如上所示:在main函数中,先调用func函数,再打印main这条语句,而在func函数中先打印func begin在调用exit(50)终止进程并将50作为退出码返回,最后打印func end。而通过下图我们可以看到程序最终只打印了func begin这条语句 ,这是因为当调用exit时进程就终止了,后续代码将不再执行,所以后面两条语句不再打印

2-5 _exit
_exit和exit类似,都表示立即终止当前进程 ,其头文件为<unistd.h>;_exit和exit的区别在于exit在进程终止之前会进行一系列清理操作,包括刷新缓冲区等,而_exit直接终止进程,不执行任何清理操作
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 #include<unistd.h>5 #include<stdlib.h>6 7 void func()8 {9 printf("func begin\n");10 _exit(5);11 printf("func end\n");12 } 13 14 int main()15 { 16 func();17 printf("main\n");18 return 0;19}如上面代码所示,_exit和exit的执行结果一样都是立即终止进程只打印func begin这条语句,并将退出码5返回给父进程
验证exit:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>int main()
{sleep(1);printf("hello world");exit(23);return 0;
}如上面代码所示:程序先休眠上1秒,然后在打印hello world语句时由于没有带\n因此不会自动刷新缓冲区,但是调用exit时exit会自动刷新,因此会在终端打印hello world语句
![]()
验证_exit:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>int main()
{sleep(1);printf("hello world");_exit(23);return 0;
}如上面代码所示:程序先休眠上1秒,然后在打印hello world语句时由于没有带\n因此不会自动刷新缓冲区,而且调用_exit时_exit不会自动刷新,因此不会在终端打印hello world语句

三:进程等待
3-1 进程等待的必要性
- 之前讲过,子进程退出,父进程如果不管不顾,,就可能造成僵尸进程的问题,造成内存泄漏
- 父进程派给子进程的任务完成的如何,我们需要知道。如子进程运行完成,结果对还是不对,或者是否正常退出
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
3-2 进程等待的方式
3-2-1 wait函数
功能
wait函数的作用是让父进程暂停执行,等待任意个退出的子进程,即可以等待一个子进程,也可以等待若干个。如果等待子进程,子进程没有退出,父进程会一直阻塞在wait调用处。
函数原型
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
- status:指向一个整数的指针,该整数用于存储子进程的退出状态。若不关心退出状态,可将其设置为NULL
- 返回值:若成功,返回终止子进程的进程ID;若失败,返回-1
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 #include<unistd.h>5 #include<stdlib.h>6 #include<sys/types.h>7 #include<sys/wait.h>8 9 int main()10 {11 pid_t id = fork();12 if(id == 0)13 {14 //子进程15 int cnt = 5;16 while(cnt--)17 {18 printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());19 sleep(1);20 }21 exit(0);22 }23 24 //父进程25 pid_t rid = wait(NULL);26 if(rid > 0)27 {28 printf("wait success,rid:%d\n",rid);29 }30 return 0;31 }在上面代码中,我们通过fork函数创建了一个子进程,如果创建成功,那么子进程将会循环5次打印printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());这条语句,并且我们将子进程的退出码设置为0;而父进程则是通过wait函数等待该子进程的退出,并且由于参数为NULL,表明父进程不关心子进程的退出状态,如果等待成功则打印printf("wait success,rid:%d\n",rid);该语句
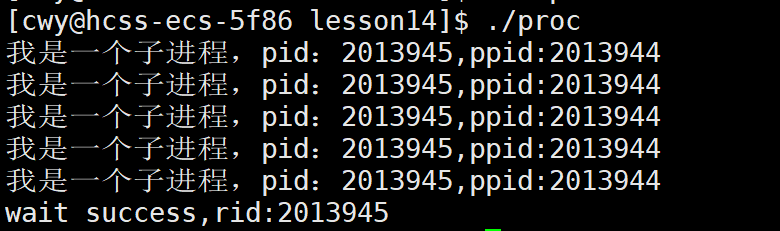
如上图所示,我们看到父进程等待子进程成功了
3-2-3 waitpid函数
在Linux中,waitpid是一个系统调用函数,用于等待子进程状态的改变。waitpid函数可让父进程等待指定的子进程结束,也能设置非阻塞模式,避免父进程一直阻塞直到子进程结束
函数原型
#include<sys/types.h>
#include<sys/wait.h>
pid_t waitpid(pid_t pid,int* status,int options);
参数说明
pid:用于指定要等待的子进程
- pid > 0:等待进程ID为pid的子进程
- pid == -1:等待任意子进程,功能等同于wait函数
- pid == 0:等待与调用进程同属于一个进程组的任意子进程
- pid < -1:等待进程组ID等于pid绝对值的任意子进程
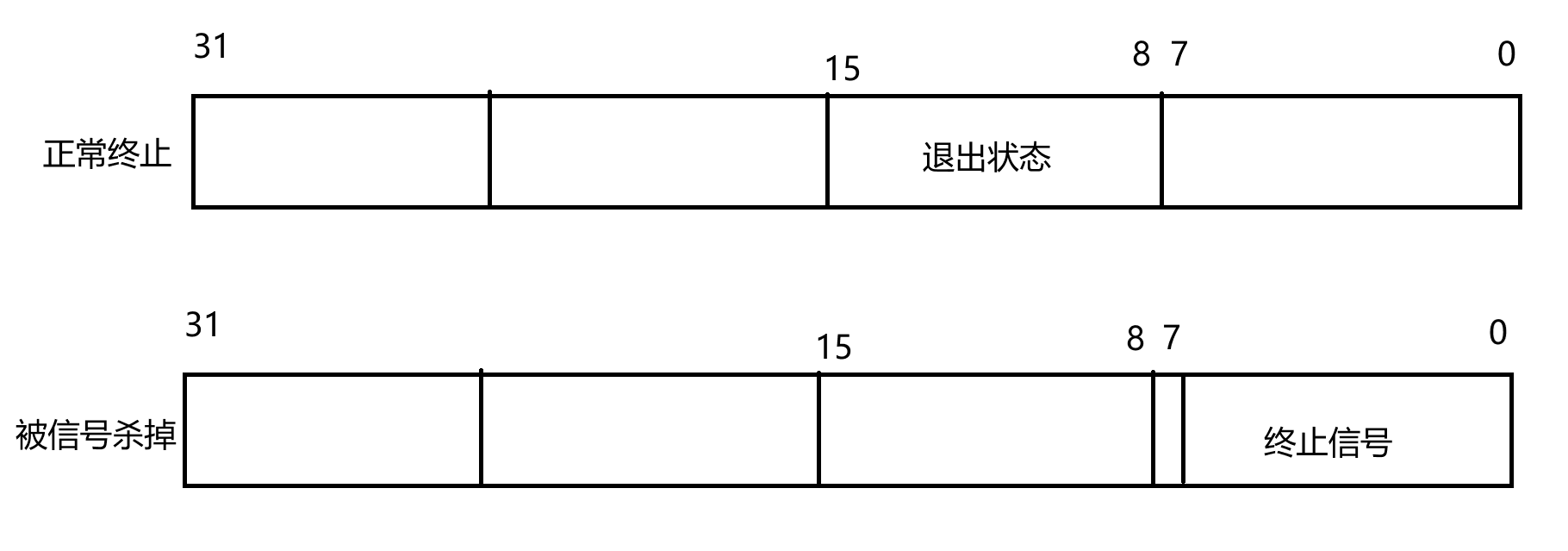
status:是一个指向整数的指针(但是并不是一个简单的整数),用于存储子进程的退出状态。若不关心退出状态,可将其设置为NULL。其中整数值是一个32个bit位的整数,高16位不用,当程序正常终止时,在低16位中取较高的8位,后8位为0;而程序异常终止时,低7位会保存异常时的对应信号编号,退出码无意义;没有异常时低7位比特位为0,如下图所示;
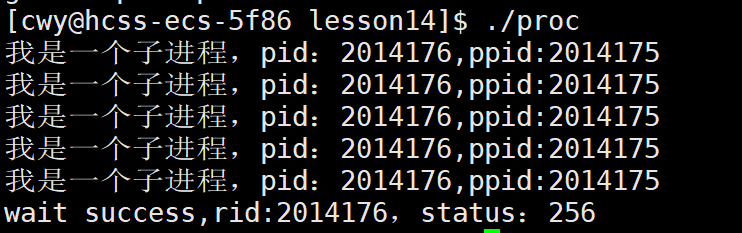
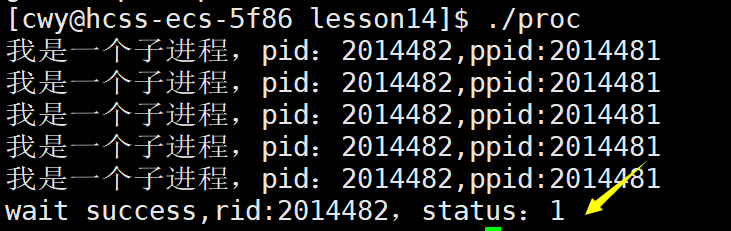
1 #include<stdio.h>2 #include<string.h>3 #include<errno.h>4 #include<unistd.h>5 #include<stdlib.h>6 #include<sys/types.h>7 #include<sys/wait.h>8 9 int main()10 {11 pid_t id = fork();12 if(id == 0)13 {14 //子进程15 int cnt = 5;16 while(cnt--)17 {18 printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());19 sleep(1);20 }21 exit(1);22 }23 24 //父进程25 int status = 0;26 pid_t rid = waitpid(id,&status,0);27 if(rid > 0)28 {29 printf("wait success,rid:%d,status:%d\n",rid,status);30 }31 else32 {33 printf("wait failed:%d:%s\n",errno,strerror(errno));34 }35 return 0;36 }37
在上面代码中,我们使用waitpid函数等待进程PID为id的子进程,状态为status,然后子进程的退出码我们设为为1,但是从下面结果我们可以看到status的值并不是1而是256,这是为什么呢?由于程序正常退出,那么status的取值应为100000000(二进制),则为256
而我们想要获取该状态可以通过一系列宏来解析该状态,常见的宏如下:
WEXITSTATUS(status):若WIFEXITED(status)为真时,获取子进程的退出状态码
如上面代码中,我们将29行代码改为printf("wait success,rid:%d,status:%d\n",rid,WEXITSTATUS(status));就可以得到进程退出码为1了
WIFEXITED(status):若子进程正常退出,则为真
options:可设置额外的选项,常用的有:
WNOHANG:非阻塞模式。若子进程没有退出,waitpid会立即返回0,而不会让父进程阻塞
返回值:
>0:等待结束,表明子进程已经执行完毕
=0:调用结束,但是子进程没有退出
<0:失败