卷积神经网络基础(六)
我们已经学习了误差反向传播法的好几种实例及其实现,现在我们可以开始构建神经网络了。
七、误差反向传播法的实现
本章我们通过已经实现的层来实现神经网络的构建。
7.1 神经网络学习的全貌图
前提:神经网络中有合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程被称为学习,神经网络学习分为下面四个步骤:
1、minibatch
从训练数据中随机选择一部分数据
2、计算梯度
计算损失函数关于各个权重参数的梯度
3、更新参数
将权重参数沿梯度方向进行微小的更新
4、重复
重复步骤1、2和3.
而我们之前学习的误差反向传播法会在步骤2出现,我们之前是采用数值微分求得梯度,虽然计算简单,但耗费较多时间。误差反向传播法却可以高效地求出计算梯度。
7.2 误差反向传播法的神经网络实现
现在来进行神经网络的实现,这里把两层神经网络实现为TwoLayerNet。首先我们整理一下类的实例变量和方法:

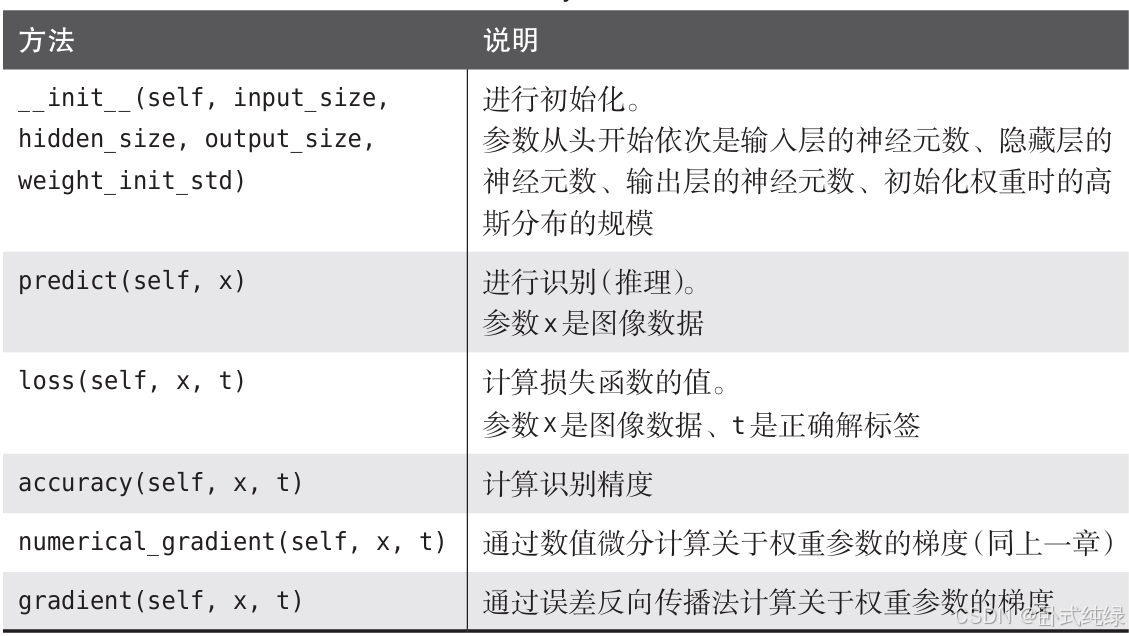
这个类的实现会比较长,但内容和之前学习的算法有很多共同的地方,不同的就是这里使用了很多之前实现过的层。通过层的实现,获得识别结果的处理和计算梯度的处理只需通过层之间的传递就可以了。下面我们来实现这个类:
import sys,os
sys.path.append(os.pardir)
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDictclass TwoLayerNet:def __init__(self, input_size, hidden_size, output_size,weight_init_std=0.01):# 初始化权重self.params = {}self.params['W1'] = weight_init_std * \np.random.randn(input_size, hidden_size)self.params['b1'] = np.zeros(hidden_size)self.params['W2'] = weight_init_std * \np.random.randn(hidden_size, output_size)self.params['b2'] = np.zeros(output_size)# 生成层self.layers = OrderedDict()self.layers['Affine1'] = \Affine(self.params['W1'], self.params['b1'])self.layers['Relu1'] = Relu()self.layers['Affine2'] = \Affine(self.params['W2'], self.params['b2'])self.lastLayer = SoftmaxWithLoss()def predict(self, x):for layer in self.layers.values():x = layer.forward(x)return x# x: 输入数据, t:监督数据def loss(self, x, t):y = self.predict(x)return self.lastLayer.forward(y, t)def accuracy(self, x, t):y = self.predict(x)y = np.argmax(y, axis=1)if t.ndim != 1 : t = np.argmax(t, axis=1)accuracy = np.sum(y == t) / float(x.shape[0])return accuracy# x: 输入数据, t:监督数据def numerical_gradient(self, x, t):loss_W = lambda W: self.loss(x, t)grads = {}grads['W1'] = numerical_gradient(loss_W, self.params['W1'])grads['b1'] = numerical_gradient(loss_W, self.params['b1'])grads['W2'] = numerical_gradient(loss_W, self.params['W2'])grads['b2'] = numerical_gradient(loss_W, self.params['b2'])return gradsdef gradient(self, x, t):# forwardself.loss(x, t)# backwarddout = 1dout = self.lastLayer.backward(dout)layers = list(self.layers.values())layers.reverse()for layer in layers:dout = layer.backward(dout)# 设定grads = {}grads['W1'] = self.layers['Affine1'].dWgrads['b1'] = self.layers['Affine1'].dbgrads['W2'] = self.layers['Affine2'].dWgrads['b2'] = self.layers['Affine2'].dbreturn grads请注意这个实现中的粗体字代码部分,尤其是将神经网络的层保存为 OrderedDict这一点非常重要。OrderedDict是有序字典,“有序”是指它可以 记住向字典里添加元素的顺序。因此,神经网络的正向传播只需按照添加元 素的顺序调用各层的forward()方法就可以完成处理,而反向传播只需要按 照相反的顺序调用各层即可。因为Affine层和ReLU层的内部会正确处理正 向传播和反向传播,所以这里要做的事情仅仅是以正确的顺序连接各层,再按顺序(或者逆序)调用各层。
像这样通过将神经网络的组成元素以层的方式实现,可以轻松地构建神经网络。这个用层进行模块化的实现具有很大优点。因为想另外构建一个神 经网络(比如5层、10层、20层……的大的神经网络)时,只需像组装乐高 积木那样添加必要的层就可以了。之后,通过各个层内部实现的正向传播和 反向传播,就可以正确计算进行识别处理或学习所需的梯度。