Kubernetes学习笔记
云计算三层模型
IaaS(基础设施即服务):提供虚拟化计算资源(如虚拟机、存储、网络)。
PaaS(平台即服务):提供应用开发和部署环境(如数据库、中间件、运行时)。(K8s)
SaaS(软件即服务):提供可直接使用的应用(如邮箱、CRM、协作工具)。
优势:
服务发现和负载均衡
存储编排(添加任何本地或云服务器)
自动部署和回滚
自动分配CPU/内存单元
自我修复(需要时启动新容器)
Secret(安全相关信息)和配置管理
大型规模的支持
开源
K8S组件插件附件
组件:Kubernetes API Server,Kubernetes Scheduler,Controller Manager ,Kube-proxy
插件:Docker, CoreDNS , ingress Controller
附件:Prometheus,Dashboard,Federation
K8s平台支持的规模数量
节点数不超过5000
每个节点的Pod数量不超过110
Pod总数不超过150000
容器总数不超过300000
Pod
介绍:Pod 是 Kubernetes 中最小部署模块,包含一个或多个容器
特点:共享网络命名空间、存储卷、IP地址和端口空间
特性:
Pause特性:
Pod内部第一个启动的容器
初始化网络栈
挂载需要的存储卷
回收僵尸进程
其他容器特性:
与Pause容器共享名字空间(Network,PID,IPC进程间通信)
网络
K8S的网络模型假定了所用的pod都在一个可以直接连通的扁平的网络空间中
网络模型原则
在不使用网络地址转换(NAT)的情况下,集群中的pod能够与任意其他pod进行通信,在集群节点上运行的程序能与同一节点上的任何Pod进行通信
每个Pod都有自己的IP地址,并且任意其他Pod都可以通过相同的这个地址访问它
CNI
CNI,容器网络接口。通过插件化的方式来集成各种网络插件,实现集群内部网络相互通信,只要实现CNI标准中定义的核心接口操作(ADD,将容器添加到网络;DEL,从网络中删除一个容器;CHECK,检查容器的网络是否符合预期)。CNI插件通常聚焦在容器到容器的网络通信。
网络模型
非封装网络(underlay):现实的物理基础层网络设备
封装网络(overlay):一个基于物理网络之上构建的逻辑网络
Calico
Calico是一个纯三层的虚拟网络,它没有复用docker的docker0网桥,而是自己实现的,calico网络不对数据包进行额外封装,不需要NAT和端口映射
架构:
Felix 负责节点层面的网络配置与策略执行;
BIRD 借助 BGP 协议完成节点间路由信息交换,构建网络连通性;
confd 动态管理组件配置文件,确保系统能随网络环境变化自动调整。
工作模式:
VXLAN(虚拟可扩展局域网)
VXLAN可以完全在内核态实现封装和解封装工作,通过隧道机制,构建出覆盖网络,基于三层的二层通信(
把整个二层帧当作 "货物",外层重新套上三层的 IP 头和 UDP 头),只要K8S三层互通,可以跨网段
封装过程:原始二层帧 → 添加 VXLAN 头(含 VNI)→ 添加 UDP 头(端口 4789)→ 添加外层 IP 头 → 传输。
IPIP:
原理:将原主机的IP数据包封装在一个新的IP数据包中。只要K8S三层互通,可以跨网段
封装过程:原始 IP 包 → 添加外层 IP 头(源 / 目的为隧道端点 IP)→ 传输。
典型用途:异种网络互联(如 IPv4 隧道传输 IPv6 包)、VPN 等。
BGP:
原理:通过 BGP 协议在节点间动态交换路由信息,直接利用三层网络转发容器流量。可以跨网段
特点:
无隧道:数据包直接通过节点 IP 路由,效率高(不用封装)。
动态路由:自动学习容器 IP 的可达性,无需手动配置。
依赖条件:网络需支持 BGP(如数据中心三层互联)。
K8s安装:
kubeadm:组件通过容器化方式运行
安装:Linux --- > docker ---> cri-docker ---> kubeadm kubelet kubctl ---> calico
kubeadm 是用于创建 Kubernetes 集群的工具,在集群搭建过程中,它会自动配置 kubelet 和其他组件,确保它们能够正常工作。
kubelet 作为节点上的代理,负责执行 kubectl 通过控制平面下发的指令,管理节点上的容器。
kubectl 则是用户与 Kubernetes 集群进行交互的主要方式,用户可以使用 kubectl 向控制平面发送请求,控制平面再将这些请求转化为具体的操作,由 kubelet 在节点上执行。
资源:
K8s中所有的内容都抽象为资源,资源实例化之后,叫做对象。
资源分类:
名称空间级别
工作负载型资源:Pod、ReplicaSet、Deployment...
服务发现及负载均衡型资源:Service、Ingress...
配置与存储型资源:Volume、CSI...
特殊类型的存储卷:ConfigMap、Secret...
集群级资源
Namespace、Node、ClusterRole、ClusterRoleBinding
元数据型资源
HPA、PodTemplate、LimitRange
编写资源清单:
实例:
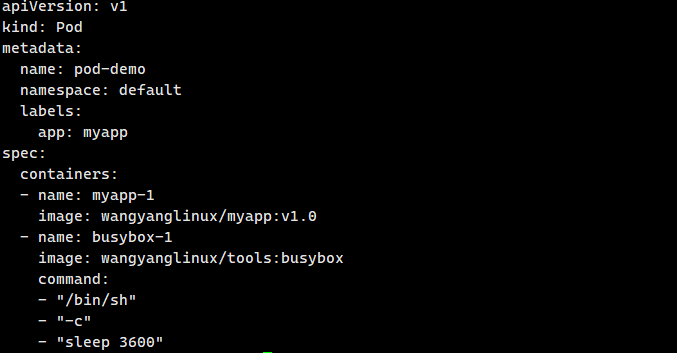
结构:
apiVersion 接口组/版本
kind 类别
metadata 元数据
name
namespace
labels
spec 期望
status 状态
常用指令:
查看资源组和版本:kubectl explain 资源类别
创建pod资源(防覆盖):kubectl create -f yaml文件 --record
### --record 参数可以记录命令,我们可以很方便的查看每次 revision 的变化
获取当前的资源
kubectl get kindName
-A,--all-namespaces 查看当前所有名称空间的资源
-n 指定名称空间,默认值 default,kube-system 空间存放是当前组件资源
--show-labels 查看当前的标签
-l 筛选资源,配合标签(key、key=value)
-o wide 详细信息包括 IP、分配的节点
-w 监视,打印当前的资源对象的变化部分
进入 Pod 内部的容器执行命令
kubectl exec -it podName -c 容器名 -- command
-c 可以省略,默认进入唯一的容器内部
查看资源的描述
kubectl explain pod.spec
查看 pod 内部容器的 日志
kubectl logs podName -c cName
查看资源对象的详细描述
kubectl describe pod podName
删除资源对象
kubectl delete kindName objName
--all 删除当前所有的资源对象
pod生命周期:
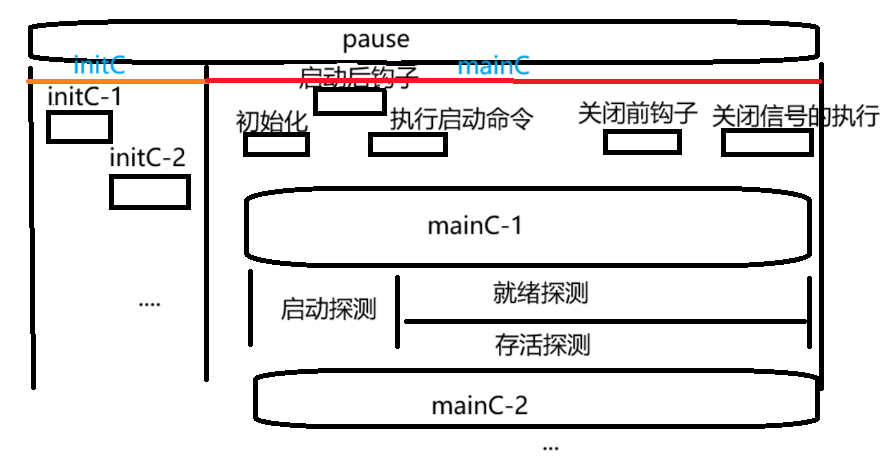
initC:
initcontainers:
线性执行
只有前一个初始化容器成功完成(退出码 0),才会执行下一个
initC执行完成,才会执行mainC
mainC:
承载实际业务逻辑的容器,如 Web 服务、数据库服务等。
需等待所有 initC 执行成功后,才会启动。
区别:
| 维度 | initContainers(初始化容器) | containers(主容器) |
| 执行顺序 | 先于主容器执行,全部完成后主容器启动。 | 后于 initC 启动。 |
| 功能定位 | 处理前置依赖、环境准备等初始化工作。 | 运行核心业务逻辑。 |
| 重启策略 | 遵循 Pod 的 restartPolicy(默认 Always,失败会重试)。 | 按 Pod 的 restartPolicy 执行(如 Always 时失败会重启)。 |
探针:
执行主体:探针由当前pod所在节点的 kubelet 对容器执行定期诊断,通过调用容器实现的 Handler 执行。
处理程序类型:
Exec:在容器内执行指定命令,若命令退出返回码为 0,则诊断成功。
HTTPGet:对容器指定端口和路径的 IP 地址执行 HTTP Get 请求,响应状态码 ≥200 且 <400 时,诊断成功。
TCPSocket:对容器指定端口的 IP 地址进行 TCP 检查,端口打开则诊断成功。
探测结果内容提取:
成功:容器通过诊断。
失败:容器未通过诊断。
未知:诊断失败,不采取任何行动。
分类:
启动探测(Startup Probe)
就绪探测(ReadinessProbe)
存活探测(Liveness Probe)
参数;
initialDelaySeconds:容器启动后等待多久开始第一次检测。
periodSeconds:检测的时间间隔(默认 10 秒)。
timeoutSeconds:单次检测的超时时间(默认 1 秒)。
successThreshold:从失败恢复为成功所需的连续成功次数(默认 1)。
failureThreshold:连续失败次数达到阈值后触发动作(默认 3)
钩子:
钩子(hook),由当前pod所在节点的 kubelet 发起的,当容器中的进程启动前或者终止前,包含在容器的生命周期之中,可同时为pod中的所用容器配置hook
类型:
exec:执行一段命令
HTTP:发送HTTP请求
格式:
lifecycle:
postStart(启动后钩子)
preStop(关闭前钩子)
pod控制器:
常用指令:
修改标签:kubectl label pod objname 修改label
重建(命名式):kubectl replace -f yaml
更新(声明式): kubectl apply -f yaml
不同:kubectl diff -f yaml
调整副本数量:
kubectl scale kindName objname --replicas=num
kubectl autoscale <资源类型> <资源名称> --min=<最小副本数> --max=<最大副本数> --<指标类型>-percent=<目标值>
更新容器镜像:
kubectl set image <资源类型/名称> <容器名>=<镜像>:用于更新 Deployment 中容器镜像,触发滚动更新。
修改部署策略(补丁方式):
补丁内容可参考-o json书写
kubectl patch <资源类型/名称> -p|--patch '补丁内容':用补丁修改 Deployment 配置,如滚动更新策略。
回滚命令:
暂停与恢复滚动更新:
kubectl rollout pause <资源类型/名称>:暂停滚动更新。
kubectl rollout resume <资源类型/名称>:恢复滚动更新(与 pause 配合使用)。
查看滚动更新状态
kubectl rollout status <资源类型/名称> 检查部署的滚动更新进度和状态
查看部署历史记录
kubectl rollout history <资源类型/名称> 展示部署的历史版本、更新时间等信息
回滚部署
kubectl rollout undo <资源类型/名称> 回滚 Deployment 到上一版本。
kubectl rollout undo <资源类型/名称> --to-revision=<版本号> 回滚到指定历史版本(Revision)
快速生成yaml模板:
kubectl create deployment [NAME] --image=[IMAGE] --dry-run -o yaml
分类:
守护进程类型:
ReplicationController 和 ReplicaSet
RC 控制器
保障当前的 Pod 数量与期望值一致
RS 控制器
功能与 RC 控制器类似,但是多了标签选择的运算方式
Deployment
支持了声明式表达
支持滚动更新和回滚
原理:deployment 控制 RS 控制 pod
清理策略:修改spec.revisionHistoryLimit的值,来确定revision的记录条数
当使用 Deployment 创建 Pod 时,如果直接删除某个 Pod,Deployment 控制器会检测到当前运行的 Pod 数量未达到期望的副本数,自动创建一个新的 Pod 来替代被删除的 Pod。因此,除非删除整个 Deployment,否则 Pod 会被持续维持。
DaemonSet
保障每个节点有且只有一个 Pod 的运行,动态
批处理任务类型:
Job/CronJob
Job
保障批处理任务一个或多个成功为止
特殊说明:
RestartPolicy:仅支持 Never 或 OnFailure
单个 Pod 场景:默认 Pod 成功运行后,Job 即结束
.spec.completions:标志 Job 结束需成功运行的 Pod 个数,默认值为 1
.spec.parallelism:标志并行运行的 Pod 个数,默认值为 1
.spec.activeDeadlineSeconds:标志失败 Pod 的重试最大时间,超此时长不再重试
CronJob
.spec.schedule:
调度字段,为必需项,用于指定任务运行周期,格式与 Cron 表达式一致。
.spec.jobTemplate:
Job 模板字段,为必需项,用于定义需运行的任务,格式与普通 Job 资源一致。
.spec.startingDeadlineSeconds:
可选字段,表示启动 Job 的期限(单位:秒)。若因任何原因错过调度时间,对应 Job 会被判定为失败;若不指定,则无启动期限限制。
.spec.concurrencyPolicy:
并发策略字段,可选,用于处理 CronJob 创建的 Job 并发执行情况,仅支持以下策略:
Allow(默认):允许 Job 并发运行。
Forbid:禁止并发,若前一个 Job 未完成,直接跳过下一个 Job 的执行。
Replace:取消当前正在运行的 Job,用新 Job 替换。
补充说明:该策略仅作用于同一 CronJob 创建的 Job;若存在多个 CronJob,它们创建的 Job 之间始终允许并发运行。
Horizontal Pod Autoscaling
StateFulSet
Service
分类:
ClusterIP:默认类型,自动分配仅集群内部可访问的VIP,用于集群内服务通信。
NodePort:基于 ClusterIP,在集群每个节点绑定端口,支持通过 <NodeIP>:NodePort 从外部访问服务。
LoadBalancer:基于 NodePort,借助云服务商创建外部负载均衡器,将请求转发至 <NodeIP>:NodePort,实现外部流量负载均衡。
ExternalName:用于将集群外部服务引入内部直接使用,不创建代理,将集群内的 DNS 名称(如 my-service)映射到外部服务的域名(如 www.baidu.com)。。
作用:
服务发现:为后端 Pod 提供稳定访问入口,即使 Pod 动态创建、销毁或 IP 变更,仍可通过固定的 Service 名称 / IP 访问。
负载均衡:将外部请求流量自动分发到后端多个 Pod,实现流量均衡处理。
定义访问策略:统一配置端口、协议等访问规则,规范服务对外暴露方式。
svc选中pod的逻辑
pod是处于就绪状态
pod的标签是svc标签的集合(同一个名字空间下)
端口关系:
外部请求 → 节点(nodePort)→ Service(port)→ 转发到 Pod 容器(targetPort)→ 最终被 Web 应用处理
底层实现技术
kube-proxy 是 Service 负载均衡的核心组件,支持两种模式:
iptables 模式:通过 Linux iptables 规则实现流量转发(默认)。
IPVS 模式:基于内核级的 IP Virtual Server,支持更高效的负载均衡算法(如加权轮询、最小连接数)。
底层模型
通过 kube-proxy + IPVS/iptables 实现流量转发,结合 DNS 服务和 Endpoint 动态维护服务端点,最终提供稳定的服务访问入口
Endpoints:
Endpoints 是 Service 的“实际后端”,存储了所有匹配 Service 选择器(Selector)的 Pod 的 IP 和端口
自动关联 Endpoints(带 Selector 的 Service)
Service 通过 selector 定义筛选 Pod 的标签规则,持续监控集群中的 Pod,自动将匹配的 Pod IP 和端口存入 Endpoints 对象。
手动关联 Endpoints(无 Selector 的 Service)
需要手动创建同名 Endpoints 对象,显式指定后端 IP 和端口。
加入NotRead的pod
kubectl patch service <服务名称> -p '{"spec":{"publishNotReadyAddresses": true}}'
修改kube-proxy:
kubectl edit configmap kube-proxy -n kube-system (修改mode=ipvs)
修改完将之前的删掉kubectl delete pod -n kube-system -l k8s-app=kube-proxy(重建才生效)
LVS持久化连接
kubectl edit svc svcname
进入后修改sessionAffinity为ClientIP,默认3小时
存储
分类:
元数据
configMap:用于保存配置数据(明文)
Secret:用于保存敏感性数据(编码)
Downward API:容器在运行时从Kubernetes API服务器获取有关它们自身的信息
真实数据
Volume:用于存储临时或者持久性数据
PersistentVolume:申请制的持久化存储
configmap:
创建:
kubectl create configmap <configmap名称> --from-file=<文件名>
kubectl create configmap <configmap名称> --from-literal=<键1>=<值1> ...
热更新:
在不中断服务或重启 Pod 的情况下,将 ConfigMap 中更新后的配置信息应用到正在运行的 Pod 中
操作:
创建configmap文件,挂载到容器内部,当configmap发生改变时,挂载卷也会发生变化(注入)
ConfigMap 热更新限制
默认行为:更新 ConfigMap 不会自动触发关联 Pod 的滚动更新。
强制触发方法:通过修改 Pod 的 annotations 强制 Deployment 触发滚动更新。
kubectl patch deployment deployname --patch '{"spec": {"template": {"metadata": {"annotations": {"version/config":"66666666"}}}}}'
注意:
环境变量(Env)不会同步更新
卷挂载(Volume)延迟更新
不可改变:
在cm配置文件中加入immutable=true,将无法改变configmap文件,且不可逆,只能重建
优点:防止错误修改以及减少apiserver的请求压力
secret:
加密:echo -n "明文" | base64
解密:echo -n "编码" | base64 -d
volume:
emptyDir卷
emptyDir: {}
不同容器之间的数据共享;当Pod被分配给节点时,首先会创建emptyDir卷,并且只要该Pod在该节点上运行,该卷就会存在。
hostpath卷
hostPath卷将主机节点的文件系统中的文件或目录挂载到集群中
| 特性 | emptyDir | hostPath |
| 生命周期 | 随 Pod 创建/删除 | 独立于 Pod,与节点共存亡 |
| 数据持久性 | 临时数据(Pod 删除后丢失) | 持久化(除非节点数据被清理) |
| 用途 | Pod 内容器共享临时数据(如缓存) | 访问节点特定资源(如日志、系统文件) |
| 安全性 | 隔离在 Pod 内部,风险较低 | 暴露宿主机文件系统,存在安全风险 |
| 多节点适用性 | 无需关注节点位置 | Pod 必须调度到特定节点才能访问数据 |
| 配置灵活性 | 支持内存(tmpfs)或磁盘存储 | 需手动指定节点路径及类型(文件/目录) |
目录
云计算三层模型
优势:
K8S组件插件附件
Pod
特性:
Pause特性:
其他容器特性:
网络
网络模型原则
CNI
网络模型
Calico
架构:
工作模式:
K8s安装:
资源:
资源分类:
名称空间级别
集群级资源
元数据型资源
编写资源清单:
实例:
结构:
常用指令:
pod生命周期:
initC:
mainC:
区别:
探针:
处理程序类型:
探测结果内容提取:
分类:
参数;
钩子:
类型:
格式:
pod控制器:
常用指令:
分类:
守护进程类型:
批处理任务类型:
Service
分类:
作用:
svc选中pod的逻辑
底层实现技术
底层模型
修改kube-proxy:
LVS持久化连接
存储
分类:
configmap:
创建:
热更新:
secret:
volume:
PV/PVC
绑定关系:
PVC 发出存储请求后,卷分配器为其寻找一个合适的 PV 进行绑定。绑定过程会根据 PVC 的存储需求(如容量、访问模式等)和 PV 的可用资源进行匹配。一旦绑定成功,PVC 就可以使用该 PV 提供的存储资源
PV/PVC 关联条件
容量:PV 容量值不小于 PVC 要求,理想情况是两者一致。
读写策略:需完全匹配,具体类型包括:
ReadWriteOnce(RWO):单节点读写。
ReadOnlyMany(ROX):多节点只读。
ReadWriteMany(RWX):多节点读写。
存储类:PV 与 PVC 的存储类必须严格一致,不存在包容或降级关系。
PV/PVC 回收策略
Retain(保留):pvc释放后,pv上的数据保留。
Recycle(回收):pvs释放后,pv上的数据清理,给下一个pvc使用。
Delete(删除):pvc释放后,pv也被释放。
目前仅 NFS 和 HostPath 支持回收策略;AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略。
PV/PVC 状态
Available(可用):资源空闲,未被任何声明绑定。
Bound(已绑定):卷已被 PVC 声明绑定。
Released(已释放):PVC 声明被删除,但资源未被集群重新声明。
Failed(失败):卷的自动回收操作失败。
命令行可显示绑定到 PV 的 PVC 名称,便于查看关联关系。
statefulSet:
特性:有序创建,上一个pod没有RUNNING,下一个pod不允许创建。倒序回收
数据持久化pod级别
绑定关系:pod --->pvc--->pv--->nfs
(创建时pv绑定nfs,创建pod时绑定pvc,pvc又绑定pv)
回收策略为 Retain 或者 Recycle时,当pod被删除后,重建后的pod的绑定关系和数据不会丢
稳定的网络访问方式:
podName.headlessSvcName.nsname.svc.domainName
补充:
当pvc被删除,Released 状态的 PV:需手动干预(如删除并重建 PV,或通过 kubectl edit 移除 claimRef 以重置为 Available)
StorageClass:
作用:抽象和管理存储资源的动态供给,允许用户按需自动创建不同类型的持久化存储卷(PV)
调度器
默认调度器:default-scheduler
自定义调度器:通过‘spec.schedulername’参数指定调度器的名字
过程:
预选
过滤不符合条件的节点
检查节点CPU,内存,GPU是否满足Pod请求
优选
根据优先级算法选择最优节点
优先选择CPU和内存使用率较低的节点
亲和性:
硬策略(requiredDuringSchedulingIgnoredDuringExecution)
软策略(preferredDuringSchedulingIgnoredDuringExecution)
节点亲和性:
软策略:调度器会尽量把 Pod 调度到满足条件的节点,但如果没有符合条件的节点,Pod 也会被调度到其他节点。
硬策略:Pod 必须被调度到满足条件的节点上,若没有符合条件的节点,Pod 会一直处于 Pending 状态。
pod亲和性:
软策略: Pod 尽量和某些具有特定标签的 Pod 调度到同一拓扑域
硬策略: Pod 必须和某些具有特定标签的 Pod 调度到同一拓扑域
pod反亲和性
三者区别:
| 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 | |
| nodeAffinity | 主机 | In, NotIn, Exists, DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD 与指定 POD 同一拓扑域 |
| podAntiAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD 与指定 POD 不在同一拓扑域 |
污点和容忍
机制:
- Taint 和 toleration 共同作用,可防止 Pod 被分配到不合适的节点。
- 节点能应用一个或多个 Taint(污点),若 Pod 不能容忍这些污点,该节点就不会接受该 Pod。
- 若为 Pod 应用 toleration(容忍),则表示这些 Pod “可以”(但非必须)被调度到具有匹配 Taint 的节点上,即容忍使 Pod 具备了被调度到含对应污点节点的资格,但调度器仍会综合其他因素决定是否真正调度。
污点组成:
Key=value:effect
value可以为空,effect描述污点作用。Taint effect支持如下选项:
NoSchedule:表示不会将Pod调度到具有该污点的Node上
PreferNoSchedule:表示尽量避免将Pod调度到该污点的Node上
NoExecute:与NoSchedule相同,同时会将Node已存在的Pod驱逐
语法:
设置污点:kubectl taint nodes <节点名称> <key>=<value>:<effect>
移除污点:kubectl taint nodes <节点名称> <key>=<value>:<effect>-
查看污点:kubectl describe node nodeName
设置容忍:
Spec.tolerations:
- key: "<key>"
operator: "<operator>"
value: "<value>"
effect: "<effect>"
tolerationSeconds: <seconds>(NoExecute 有效)
固定节点调度:
指定节点调度:
pod.spec.nodeName将Pod直接调度到指定的Node节点上,跳过Scheduler的调度策略,进行强制匹配。
指定节点标签调度:
pod.spec.nodeSelector 通过标签让调度器按规则匹配节点,由调度器调度策略匹配 label,然后调度 Pod 到目标节点,
该匹配规则属于强制约束。无法跳过Scheduler的调度策略
安全机制:
认证:
组件通常通过 HTTPS 双向认证与 API Server 通信,而 Pod 主要通过 ServiceAccount(SA)认证来访问 API Server
认证模式类型:
HTTP Token
HTTP Base
CA(最严格https认证)
HTTPS认证:
HTTPS 单向认证(RSA):
客户端发送请求,服务端产生公钥和私钥,将自己的公钥包含在证书中,发送给客户端,客户端检查证书,并将证书中的公钥提取出来,用公钥加密客户端生成的预主密钥,发送给服务器,服务器用自己的私钥解密预主密钥,客户端和服务端使用生成的会话密钥对要传输的数据进行对称加密。
HTTPS 双向认证(ECDH)
客户端发送请求,服务端产生公钥和私钥,将自己的公钥包含在证书中,发送给客户端,客户端检查证书,生成自己的非对称密钥对(公钥和私钥),公钥嵌入 客户端证书,发送给服务器,服务器验证客户端证书的合法性,服务端发送临时公钥参数(Server Params)。客户端生成临时公钥参数(Client Params),发送给服务端。双方通过 ECDH 算法协商出预主密钥(无需加密传输),客户端和服务端使用生成的会话密钥对要传输的数据进行对称加密。
kubectl,kubelet,kube-proxy的证书均需要https双向认证
ServerAccout:
SA解决pod访问apiServer认证的问题
默认,每个·namespace都会有一个SA,如果pod创建时没有指SA,就会使用Pod所属的ns的SA
组成:
ca.crt:集群的根证书,用于pod确认apiserver的安全性
token:使用apiServer私钥签发基于JWT标准的字符串,用于确认pod的安全性
namespace:用于标识当前的pod的作用域
鉴权:
RBAC:基于角色的访问控制
优势:
对集群中的资源和非资源均拥有完整的覆盖
整个 RBAC 完全由几个 API 对象完成,同其它 API 对象一样,可以用 kubectl 或 API 进行操作
可以在运行时进行调整,无需重启 API Server
资源对象:
ns级别:Role,RoleBinding
cluster级别:ClusterRole,ClusterRoleBinding
HELM
核心概念:
Chart:这是描述一组 Kubernetes 资源的文件集合,可被视为应用的蓝图。
Release:指的是在 Kubernetes 集群中部署的 Chart 的一个实例。同一个 Chart 可以在同一个集群中部署多次,每次部署都会生成一个新的 Release。
Helm cli:helm客户端组件,负责和kubernetes apiS通信
Repository:用于发布和存储Chart的仓库。
helm repo add bitnami-itboon https://helm-charts.itboon.top/bitnami --force-update
helm repo update
常用命令:
仓库管理
添加 Helm 仓库:helm repo add <仓库名称> <仓库地址>
更新仓库缓存:helm repo update
列出已添加的仓库:helm repo list
移除仓库:helm repo remove <repo-name>
Chart 查找与搜索
在已添加仓库中搜索 Chart:helm search repo <关键词>
在 Helm Hub 中搜索 Chart:helm search hub <关键词>
Chart 安装
手动指定名称安装:helm install <发行版名称> <仓库/Chart 名称>
自动生成名称安装:helm install <仓库/Chart 名称> --generate-name
配置传递:
通过 -f/--values 引用 YAML 文件覆盖配置。
通过 --set key=value 从命令行覆盖特定配置项
查看安装信息
列出已安装的发行版:helm list
查看发行版详细状态:helm status <发行版名称>
查看chart默认值:helm show values <repo-name>/<chart-name>
Chart 升级与回滚
升级发行版:helm upgrade <发行版名称> <仓库/Chart 名称>
回滚发行版:helm rollback <发行版名称> [版本号]
Chart 删除
删除发行版:helm uninstall <发行版名称>
Chart 创建与打包
创建新的 Chart 模板:helm create <Chart 名称>
打包 Chart:helm package <Chart 名称>
Chart 验证
验证 Chart 语法和结构:helm lint <Chart 名称>
ingress-nginx
逻辑层:Ingress -> Service -> Pod(逻辑抽象)。
物理层:Ingress Controller 直接转发到 Pod(通过 Endpoints 发现)。
核心角色:Ingress Controller 是实际流量控制者,Service 提供动态服务发现
核心配置:
.metadata.annotations:
nginx.ingress.kubernetes.io/xxx:xxx
常见 nginx.ingress.kubernetes.io/ 注解及用途:
流量控制与负载均衡
指定负载均衡算法:nginx.ingress.kubernetes.io/load-balance
会话保持(粘性会话):nginx.ingress.kubernetes.io/affinity
请求限速(每秒请求数):nginx.ingress.kubernetes.io/limit-rps
路径与请求处理
路径重写:nginx.ingress.kubernetes.io/rewrite-target
强制 HTTPS 重定向:nginx.ingress.kubernetes.io/force-ssl-redirect
自定义请求头传递:nginx.ingress.kubernetes.io/proxy-set-headers
安全与证书
后端协议配置(如 HTTPS):nginx.ingress.kubernetes.io/backend-protocol
启用跨域资源共享(CORS):nginx.ingress.kubernetes.io/enable-cors
强制 SSL 重定向:nginx.ingress.kubernetes.io/ssl-redirect
性能优化
客户端请求体大小限制:nginx.ingress.kubernetes.io/proxy-body-size
代理连接超时设置:nginx.ingress.kubernetes.io/proxy-connect-timeout
启用 Gzip 压缩:nginx.ingress.kubernetes.io/enable-gzip
高级配置
自定义错误页面:nginx.ingress.kubernetes.io/custom-http-errors
TCP/UDP 流量转发配置:nginx.ingress.kubernetes.io/tcp-services
灰度/金丝雀发布(Canary 分流):nginx.ingress.kubernetes.io/canary