《Python星球日记》 第49天:特征工程与全流程建模
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、特征工程基础概念
- 1. 为什么需要特征工程?
- 二、特征标准化与归一化
- 1. 标准化 (Standardization)
- 2. 归一化 (Normalization)
- 三、缺失值填充策略
- 1. 基础填充方法
- 2. 高级填充方法
- 四、特征编码:One-Hot 编码与 Label 编码
- 1. Label 编码
- 2. One-Hot 编码
- 五、特征选择方法
- 1. 卡方检验 (Chi-Square Test)
- 2. Lasso 回归特征选择
- 3. 其他常用特征选择方法
- 六、端到端建模流程
- 1. 完整机器学习工作流
- 2. 主要流程详解
- a. 问题定义
- b. 数据收集与准备
- c. 数据探索与分析 (EDA)
- d. 数据清洗
- e. 特征工程
- f. 数据分割
- g. 模型选择与训练
- h. 模型评估与调优
- i. 模型部署
- j. 模型监控与维护
- 七、代码练习:完整机器学习项目
- 项目概述:客户流失预测
- 八、总结与扩展阅读
- 1. 今日要点回顾
- 2. 应用场景
- 3. 进阶学习方向
- 4. 实践建议
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第48天:模型评估与选择
欢迎来到Python星球的第49天!🪐
今天我们将深入学习特征工程的核心技术,并掌握一个完整的机器学习建模流程。特征工程是决定模型性能的关键环节,而掌握从数据清洗到模型部署的全流程,将使你往成为一名数据科学工程师的路上更进一步!
一、特征工程基础概念
特征工程是机器学习中至关重要的环节,它直接影响模型的性能和预测能力。简单来说,特征工程是将原始数据转换为更适合机器学习算法使用的特征集合的过程。
1. 为什么需要特征工程?
良好的特征工程能够:
- 提高模型的预测准确率
- 减少过拟合风险
- 降低模型的计算复杂度
- 增强模型的可解释性
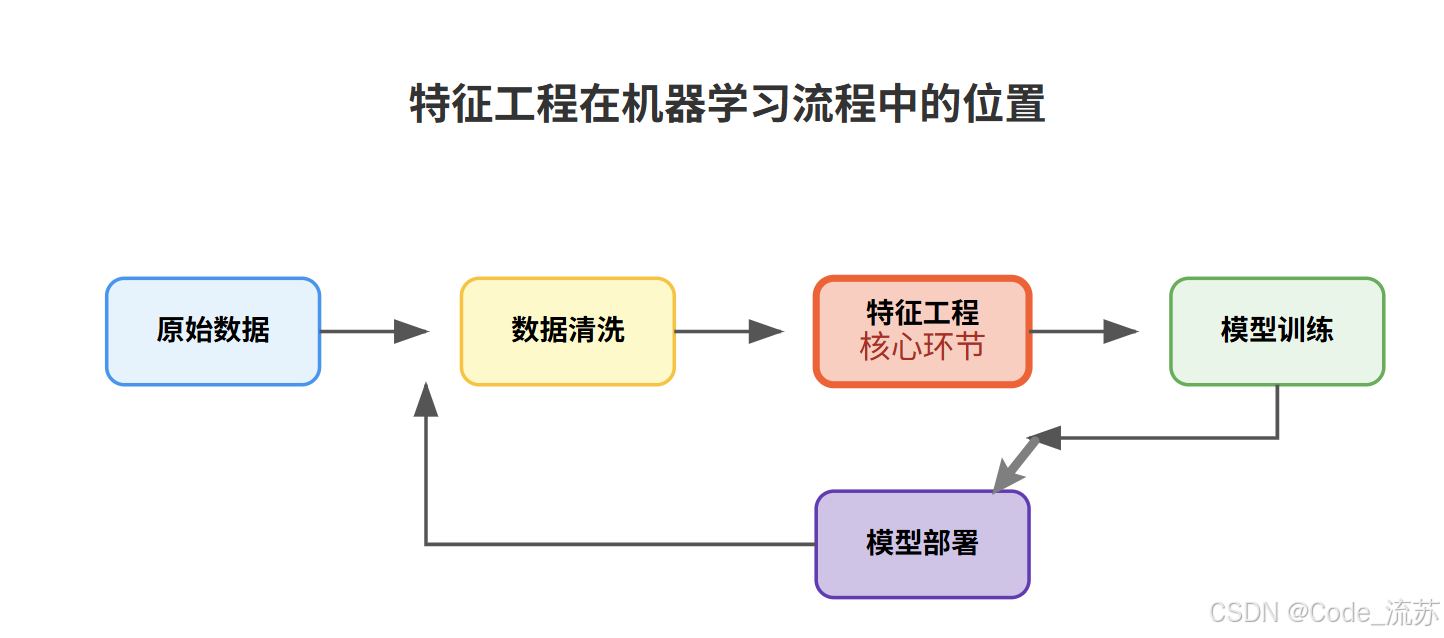
二、特征标准化与归一化
数据的尺度不一致会影响许多机器学习算法的性能,特别是基于距离的算法如KNN、SVM和神经网络。
1. 标准化 (Standardization)
标准化将特征转换为均值为0,标准差为1的分布。
- 公式: z = x − μ σ z = \frac{x - \mu}{\sigma} z=σx−μ
- 适用场景:数据大致呈现正态分布时
- 优势:降低异常值对模型的影响
from sklearn.preprocessing import StandardScaler# 创建标准化器
scaler = StandardScaler()# 拟合并转换训练数据
X_train_scaled = scaler.fit_transform(X_train)# 只转换测试数据(不拟合)
X_test_scaled = scaler.transform(X_test)
2. 归一化 (Normalization)
归一化将特征缩放到指定范围内,通常是[0,1]。
- 公式: x n o r m = x − x m i n x m a x − x m i n x_{norm} = \frac{x - x_{min}}{x_{max} - x_{min}} xnorm=xmax−xminx−xmin
- 适用场景:数据分布不确定,或者模型对特征范围敏感
- 优势:保持数据的分布形状,适用于稀疏数据
from sklearn.preprocessing import MinMaxScaler# 创建归一化器
min_max_scaler = MinMaxScaler()# 拟合并转换训练数据
X_train_norm = min_max_scaler.fit_transform(X_train)# 只转换测试数据(不拟合)
X_test_norm = min_max_scaler.transform(X_test)
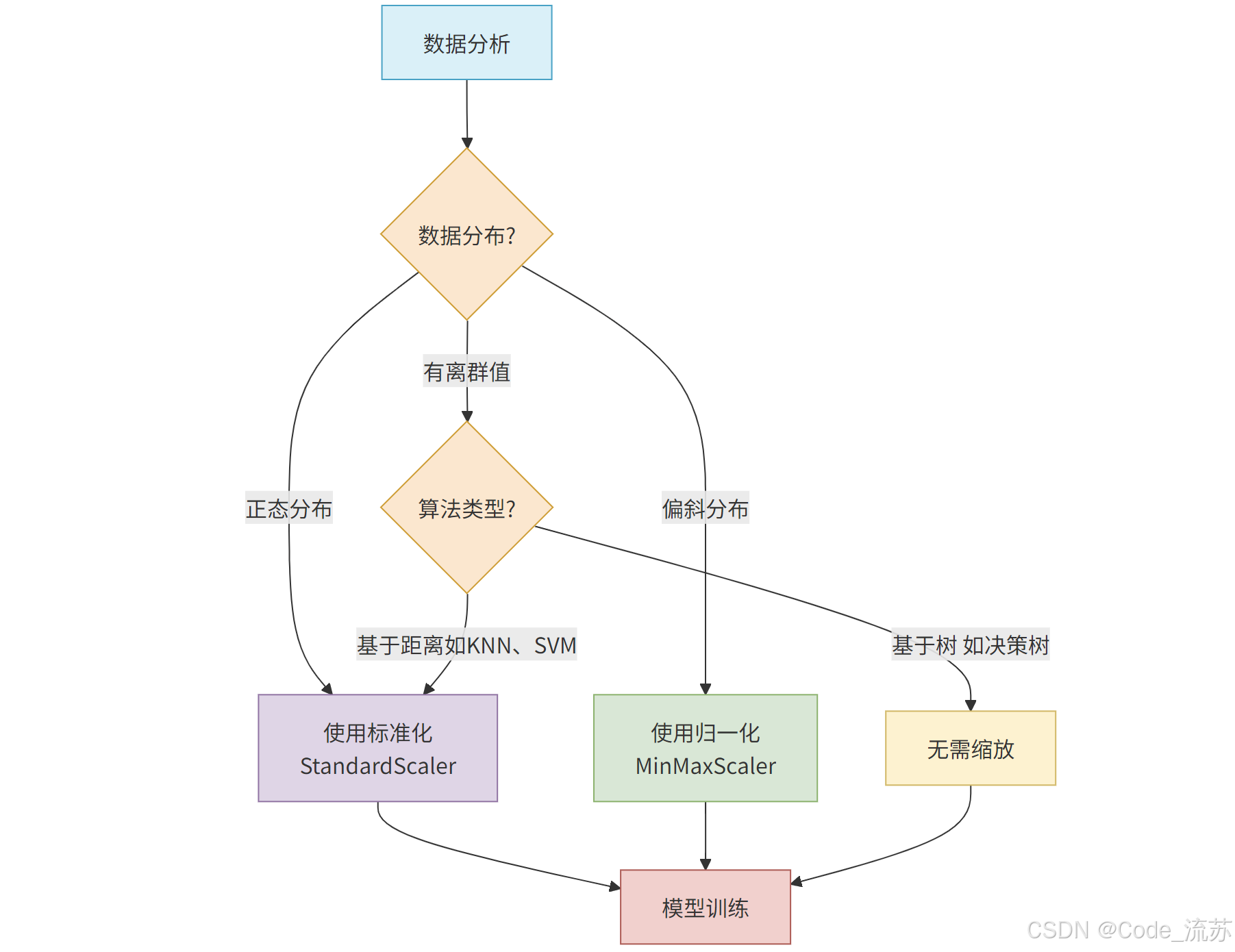
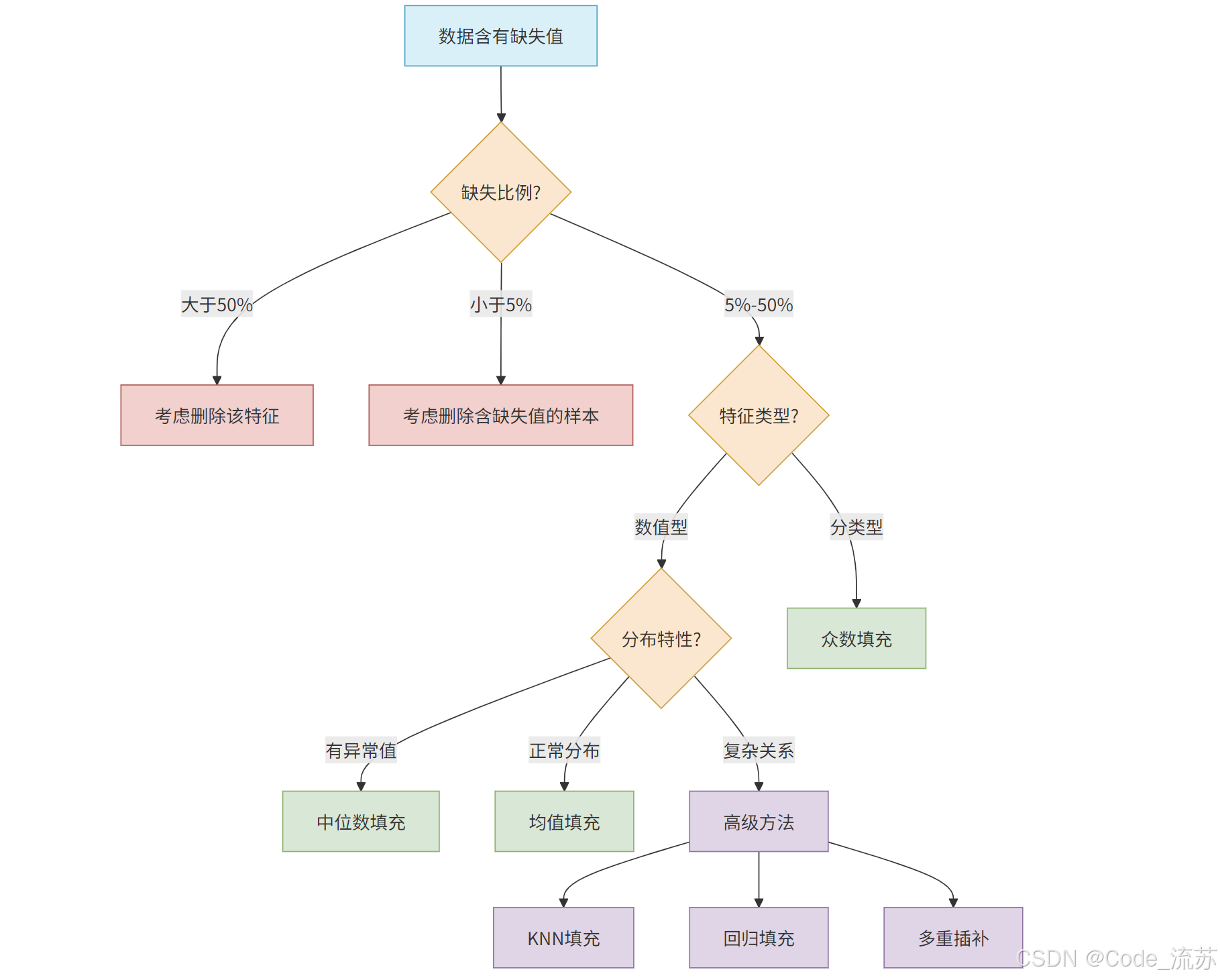
三、缺失值填充策略
数据中的缺失值是机器学习中常见的问题,不同的填充策略会对模型性能产生不同影响。
1. 基础填充方法
- 均值填充:用特征的平均值填充缺失值
- 中位数填充:用特征的中位数填充缺失值(对异常值不敏感)
- 众数填充:用特征的众数填充缺失值(适用于分类特征)
from sklearn.impute import SimpleImputer
import numpy as np# 均值填充
mean_imputer = SimpleImputer(strategy='mean')
X_mean_imputed = mean_imputer.fit_transform(X)# 中位数填充
median_imputer = SimpleImputer(strategy='median')
X_median_imputed = median_imputer.fit_transform(X)# 众数填充
mode_imputer = SimpleImputer(strategy='most_frequent')
X_mode_imputed = mode_imputer.fit_transform(X)
2. 高级填充方法
- KNN填充:基于相似样本的特征值进行填充
- 回归填充:使用其他特征预测缺失值
- 多重插补:生成多个可能的填充值,考虑不确定性
# KNN填充
from sklearn.impute import KNNImputerknn_imputer = KNNImputer(n_neighbors=5)
X_knn_imputed = knn_imputer.fit_transform(X)# 多重插补示例
from sklearn.experimental import enable_iterative_imputer # 必须导入
from sklearn.impute import IterativeImputeriter_imputer = IterativeImputer(max_iter=10, random_state=0)
X_iter_imputed = iter_imputer.fit_transform(X)
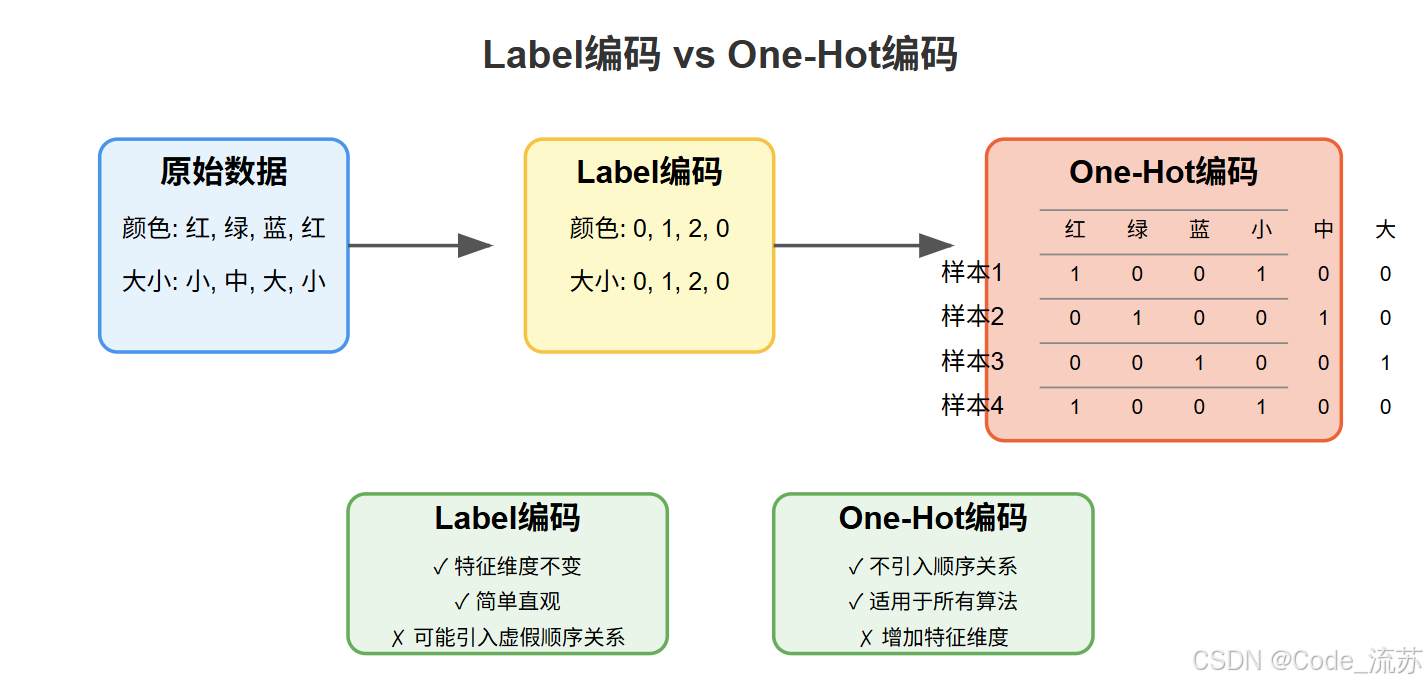
四、特征编码:One-Hot 编码与 Label 编码
机器学习算法通常要求输入特征为数值型,因此需要将分类特征转换为数值表示。
1. Label 编码
Label编码将分类值映射为整数值。
- 适用场景:序数型分类变量(如:小、中、大)
- 优势:简单直观,不增加特征维度
- 劣势:可能引入不存在的顺序关系
from sklearn.preprocessing import LabelEncoder# 创建编码器
label_encoder = LabelEncoder()# 拟合并转换
encoded_labels = label_encoder.fit_transform(categorical_feature)# 查看映射关系
for i, category in enumerate(label_encoder.classes_):print(f"{category} -> {i}")
2. One-Hot 编码
One-Hot编码将每个类别值转换为一个二进制向量,其中只有一个元素为1,其余为0。
- 适用场景:名义型分类变量(如:红、绿、蓝)
- 优势:不引入顺序关系,对于大多数算法效果好
- 劣势:增加特征维度,可能导致维度灾难
from sklearn.preprocessing import OneHotEncoder# 创建编码器
onehot_encoder = OneHotEncoder(sparse=False, drop='first')# 拟合并转换 (需要2D输入)
X_categorical = categorical_feature.reshape(-1, 1)
onehot_encoded = onehot_encoder.fit_transform(X_categorical)# 查看特征名称
feature_names = onehot_encoder.get_feature_names_out(['color'])
print(feature_names)
五、特征选择方法
特征选择技术用于识别和筛选对模型性能最有影响的特征,减少维度,提高模型效率。
1. 卡方检验 (Chi-Square Test)
卡方检验评估分类特征与目标变量之间的相关性,适用于分类问题。
- 原理:测量特征与目标之间的独立性
- 优势:非参数方法,不需要假设特征分布
- 适用场景:分类问题中的特征筛选
from sklearn.feature_selection import SelectKBest, chi2# 创建卡方特征选择器
chi2_selector = SelectKBest(chi2, k=5) # 选择前5个最重要的特征# 拟合并转换
X_chi2_selected = chi2_selector.fit_transform(X_positive, y) # 注意:X必须是非负的# 获取特征分数
feature_scores = chi2_selector.scores_
feature_names = X.columns
for feature, score in sorted(zip(feature_names, feature_scores), key=lambda x: x[1], reverse=True)[:5]:print(f"{feature}: {score}")
2. Lasso 回归特征选择
Lasso回归具有自动特征选择的能力,它使用L1正则化惩罚项,可以将不重要特征的系数压缩为零。
- 原理:基于L1正则化的自动特征选择
- 优势:能够同时进行特征选择和模型训练
- 适用场景:高维数据集的回归或分类问题
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline# 创建Lasso特征选择器
lasso_selector = Pipeline([('scaler', StandardScaler()), # Lasso要求标准化数据('lasso', Lasso(alpha=0.1)) # alpha控制稀疏度
])# 拟合模型
lasso_selector.fit(X, y)# 查看系数(非零系数对应的特征被选中)
feature_importance = abs(lasso_selector.named_steps['lasso'].coef_)
feature_names = X.columns
for feature, importance in sorted(zip(feature_names, feature_importance), key=lambda x: x[1], reverse=True):if importance > 0:print(f"{feature}: {importance}")
3. 其他常用特征选择方法
- 方差阈值:移除方差低于阈值的特征
- 递归特征消除 (RFE):迭代移除最不重要的特征
- 随机森林重要性:基于树模型评估特征重要性
- 主成分分析 (PCA):降维并保留最大方差信息
六、端到端建模流程
一个完整的机器学习项目不仅仅涉及模型训练,还包括从数据清洗到模型部署的全流程。掌握这个流程对于成功实施机器学习项目至关重要。
1. 完整机器学习工作流
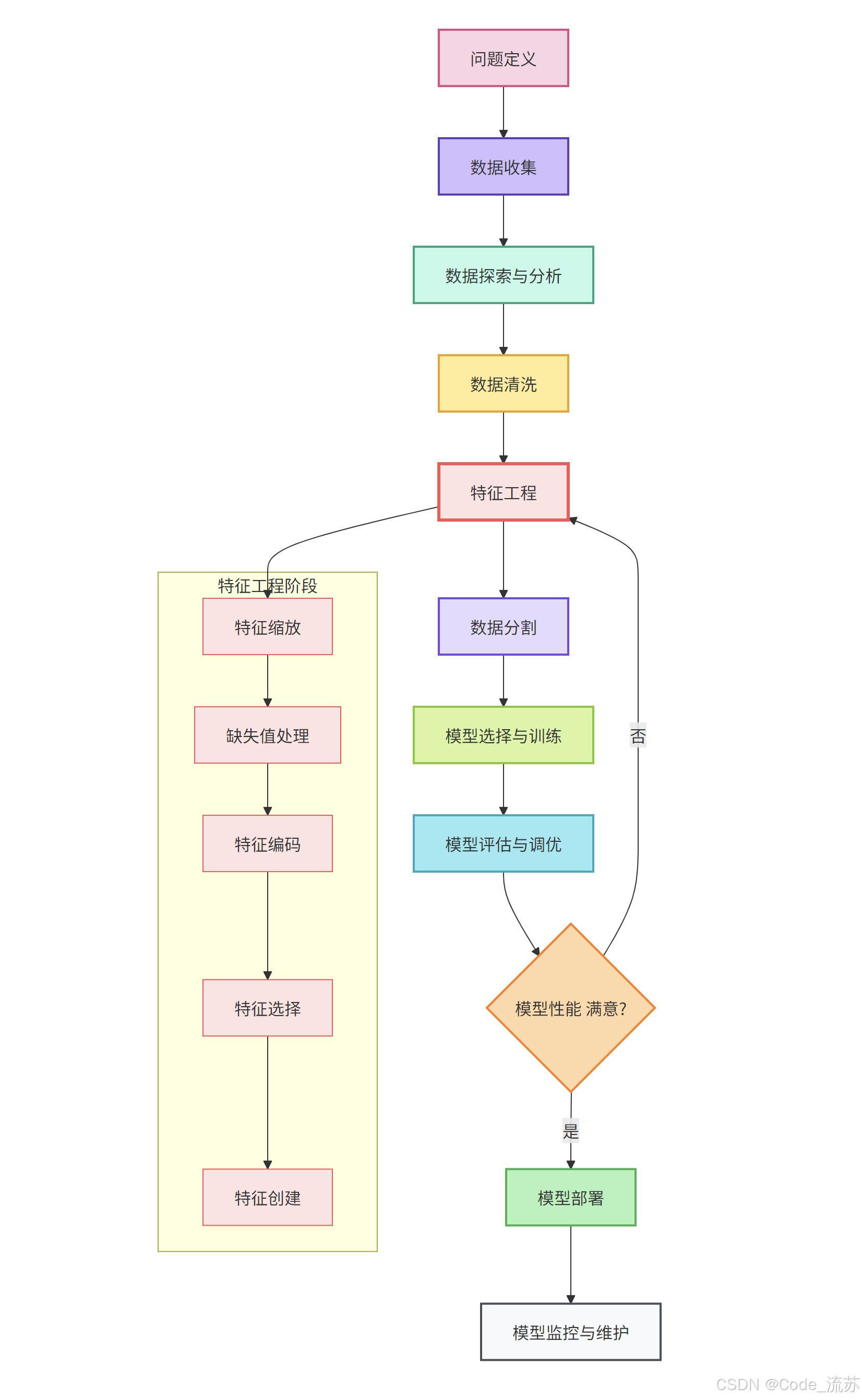
2. 主要流程详解
a. 问题定义
首先明确业务问题和目标,确定是分类、回归、聚类还是其他类型的问题。这一步决定了后续的所有技术选择。
b. 数据收集与准备
收集相关数据,并进行初步整理。这可能涉及从多个源获取数据,并将其整合到一个统一的格式中。
c. 数据探索与分析 (EDA)
通过统计分析和可视化技术,深入了解数据分布、特征关系和潜在问题。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
df = pd.read_csv('dataset.csv')# 基本统计信息
print(df.describe())
print(df.info())# 检查缺失值
print(df.isnull().sum())# 可视化数据分布
plt.figure(figsize=(12, 8))
for i, col in enumerate(df.select_dtypes(include=['float64', 'int64']).columns[:6]):plt.subplot(2, 3, i+1)sns.histplot(df[col], kde=True)plt.title(f'Distribution of {col}')
plt.tight_layout()
plt.show()# 相关性分析
plt.figure(figsize=(10, 8))
correlation_matrix = df.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Feature Correlation Matrix')
plt.show()
d. 数据清洗
处理缺失值、异常值和不一致数据,确保数据质量。
e. 特征工程
应用前面学习的技术,包括:
- 特征缩放与归一化
- 缺失值填充
- 分类特征编码
- 特征选择
- 特征创建(如多项式特征、交互特征)
f. 数据分割
将数据分为训练集、验证集和测试集,遵循正确的数据分割原则避免数据泄露。
from sklearn.model_selection import train_test_split# 首先分割出测试集
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42
)# 再从剩余数据中分割验证集
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.25, random_state=42 # 0.25 * 0.8 = 0.2
)print(f"训练集大小: {X_train.shape}")
print(f"验证集大小: {X_val.shape}")
print(f"测试集大小: {X_test.shape}")
g. 模型选择与训练
选择适合问题类型的模型,并在训练集上训练。
h. 模型评估与调优
通过交叉验证和超参数调优优化模型性能。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix# 定义模型
rf = RandomForestClassifier(random_state=42)# 定义参数网格
param_grid = {'n_estimators': [100, 200, 300],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 网格搜索
grid_search = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5,scoring='accuracy',n_jobs=-1
)# 拟合数据
grid_search.fit(X_train, y_train)# 最佳参数
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证得分: {grid_search.best_score_:.4f}")# 用最佳模型在验证集上评估
best_model = grid_search.best_estimator_
y_val_pred = best_model.predict(X_val)print("验证集分类报告:")
print(classification_report(y_val, y_val_pred))# 绘制混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix(y_val, y_val_pred), annot=True, fmt='d', cmap='Blues')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('验证集混淆矩阵')
plt.show()
i. 模型部署
将训练好的模型部署到生产环境,可能需要使用Flask、Django或其他框架创建API。
import pickle# 保存模型
with open('model.pkl', 'wb') as f:pickle.dump(best_model, f)# Flask部署示例框架
'''
from flask import Flask, request, jsonify
import pickle
import pandas as pdapp = Flask(__name__)# 加载模型
with open('model.pkl', 'rb') as f:model = pickle.load(f)@app.route('/predict', methods=['POST'])
def predict():# 获取输入数据data = request.json# 将数据转换为DataFrameinput_df = pd.DataFrame(data, index=[0])# 进行预处理 (与训练时相同的步骤)# ...preprocessing code here...# 预测prediction = model.predict(input_df)# 返回结果return jsonify({'prediction': prediction.tolist()})if __name__ == '__main__':app.run(debug=True)
'''
j. 模型监控与维护
持续监控模型性能,处理数据漂移问题,并在需要时更新模型。
七、代码练习:完整机器学习项目
让我们通过一个实际案例,实践从数据处理到模型部署的全流程。
项目概述:客户流失预测
我们将建立一个电信客户流失预测模型,预测哪些客户可能会取消服务。
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_curve, auc
from sklearn.feature_selection import SelectFromModel
import pickle
import warnings
warnings.filterwarnings('ignore')# 1. 加载数据
# ---------------------------------------------------------------------------------
print("第一步:加载数据并查看基本信息")
# 假设数据存储在名为'telco_churn.csv'的文件中
# 如果你要运行此代码,请修改为你的文件路径
try:df = pd.read_csv('telco_churn.csv')
except:# 假数据用于演示np.random.seed(42)n_samples = 1000# 生成特征df = pd.DataFrame({'customerID': ['CUST-' + str(i).zfill(6) for i in range(n_samples)],'gender': np.random.choice(['Male', 'Female'], size=n_samples),'SeniorCitizen': np.random.choice([0, 1], size=n_samples, p=[0.8, 0.2]),'Partner': np.random.choice(['Yes', 'No'], size=n_samples),'Dependents': np.random.choice(['Yes', 'No'], size=n_samples),'tenure': np.random.randint(0, 72, size=n_samples),'PhoneService': np.random.choice(['Yes', 'No'], size=n_samples, p=[0.9, 0.1]),'MultipleLines': np.random.choice(['Yes', 'No', 'No phone service'], size=n_samples),'InternetService': np.random.choice(['DSL', 'Fiber optic', 'No'], size=n_samples),'OnlineSecurity': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'OnlineBackup': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'DeviceProtection': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'TechSupport': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'StreamingTV': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'StreamingMovies': np.random.choice(['Yes', 'No', 'No internet service'], size=n_samples),'Contract': np.random.choice(['Month-to-month', 'One year', 'Two year'], size=n_samples, p=[0.6, 0.2, 0.2]),'PaperlessBilling': np.random.choice(['Yes', 'No'], size=n_samples),'PaymentMethod': np.random.choice(['Electronic check', 'Mailed check', 'Bank transfer', 'Credit card'], size=n_samples),'MonthlyCharges': np.random.uniform(20, 120, size=n_samples),'TotalCharges': np.random.uniform(0, 8000, size=n_samples)})# 生成目标变量 (流失率约20%)churn_prob = 0.1 + 0.3 * (df['Contract'] == 'Month-to-month') - 0.1 * (df['tenure'] > 30)churn_prob = np.clip(churn_prob, 0.05, 0.95)df['Churn'] = np.random.binomial(1, churn_prob)df['Churn'] = df['Churn'].map({0: 'No', 1: 'Yes'})# 增加一些缺失值mask = np.random.random(n_samples) < 0.05df.loc[mask, 'TotalCharges'] = np.nan# 查看数据基本信息
print(f"数据集形状: {df.shape}")
print("\n前5行数据:")
print(df.head())print("\n数据类型信息:")
print(df.info())print("\n数据统计描述:")
print(df.describe())print("\n缺失值统计:")
print(df.isnull().sum())# 2. 探索性数据分析 (EDA)
# ---------------------------------------------------------------------------------
print("\n第二步:探索性数据分析")# 目标变量分布
plt.figure(figsize=(8, 6))
churn_counts = df['Churn'].value_counts()
plt.pie(churn_counts, labels=churn_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('客户流失比例')
plt.axis('equal')
plt.show()# 数值特征分布
numerical_features = df.select_dtypes(include=['float64', 'int64']).columns.tolist()
if 'customerID' in numerical_features:numerical_features.remove('customerID')plt.figure(figsize=(15, 10))
for i, feature in enumerate(numerical_features):plt.subplot(2, 3, i+1)sns.histplot(data=df, x=feature, hue='Churn', kde=True, palette='Set1')plt.title(f'{feature} 分布')
plt.tight_layout()
plt.show()# 分类特征与目标关系
categorical_features = df.select_dtypes(include=['object']).columns.tolist()
if 'customerID' in categorical_features:categorical_features.remove('customerID')
if 'Churn' in categorical_features:categorical_features.remove('Churn')plt.figure(figsize=(15, 15))
for i, feature in enumerate(categorical_features[:9]): # 展示前9个分类特征plt.subplot(3, 3, i+1)temp_df = df.groupby([feature, 'Churn']).size().unstack()temp_df.plot(kind='bar', stacked=True, ax=plt.gca())plt.title(f'{feature} vs Churn')plt.xticks(rotation=45)
plt.tight_layout()
plt.show()# 相关性分析
numerical_df = df.select_dtypes(include=['float64', 'int64'])
correlation = numerical_df.corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.show()# 3. 数据预处理
# ---------------------------------------------------------------------------------
print("\n第三步:数据预处理")# 移除无用特征
if 'customerID' in df.columns:df = df.drop('customerID', axis=1)# 处理目标变量
target = 'Churn'
y = df[target].map({'Yes': 1, 'No': 0})
X = df.drop(target, axis=1)# 识别特征类型
numerical_features = X.select_dtypes(include=['float64', 'int64']).columns.tolist()
categorical_features = X.select_dtypes(include=['object']).columns.tolist()print(f"数值特征: {numerical_features}")
print(f"分类特征: {categorical_features}")# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f"训练集大小: {X_train.shape}, 测试集大小: {X_test.shape}")# 4. 特征工程与处理管道
# ---------------------------------------------------------------------------------
print("\n第四步:特征工程与处理管道")# 数值特征处理器 - 标准化和缺失值填充
numerical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')), # 缺失值填充('scaler', StandardScaler()) # 标准化
])# 分类特征处理器 - 独热编码和缺失值填充
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')), # 缺失值填充('onehot', OneHotEncoder(handle_unknown='ignore', sparse=False)) # 独热编码
])# 列转换器 - 将不同类型的特征应用到适当的处理器
preprocessor = ColumnTransformer(transformers=[('num', numerical_transformer, numerical_features),('cat', categorical_transformer, categorical_features)])# 5. 模型构建与特征选择
# ---------------------------------------------------------------------------------
print("\n第五步:模型构建与特征选择")# 特征选择管道 - 使用随机森林进行特征重要性筛选
# 这里我们使用了两种特征选择方法供对比# 方法1: 基于统计测试的特征选择
feature_selection1 = Pipeline(steps=[('preprocessor', preprocessor),('selector', SelectKBest(f_classif, k=10)) # 选择最重要的10个特征
])# 方法2: 基于模型的特征选择
feature_selection2 = Pipeline(steps=[('preprocessor', preprocessor),('selector', SelectFromModel(RandomForestClassifier(n_estimators=100, random_state=42)))
])# 6. 模型训练与评估
# ---------------------------------------------------------------------------------
print("\n第六步:模型训练与评估")# 定义模型
rf_model = RandomForestClassifier(random_state=42)
lr_model = LogisticRegression(random_state=42, max_iter=1000)# 使用特征选择方法1构建两个完整管道
rf_pipeline1 = Pipeline(steps=[('feature_selection', feature_selection1),('model', rf_model)
])lr_pipeline1 = Pipeline(steps=[('feature_selection', feature_selection1),('model', lr_model)
])# 使用特征选择方法2构建两个完整管道
rf_pipeline2 = Pipeline(steps=[('feature_selection', feature_selection2),('model', rf_model)
])lr_pipeline2 = Pipeline(steps=[('feature_selection', feature_selection2),('model', lr_model)
])# 创建模型列表
pipelines = {'RandomForest_StatTest': rf_pipeline1,'LogisticRegression_StatTest': lr_pipeline1,'RandomForest_ModelBased': rf_pipeline2,'LogisticRegression_ModelBased': lr_pipeline2
}# 超参数网格 - 简化版本以便于演示
param_grids = {'RandomForest_StatTest': {'model__n_estimators': [100, 200],'model__max_depth': [None, 10]},'LogisticRegression_StatTest': {'model__C': [0.1, 1.0]},'RandomForest_ModelBased': {'model__n_estimators': [100, 200],'model__max_depth': [None, 10]},'LogisticRegression_ModelBased': {'model__C': [0.1, 1.0]}
}# 训练和评估每个模型
best_models = {}
for name, pipeline in pipelines.items():print(f"\n训练模型: {name}")# 创建网格搜索grid_search = GridSearchCV(estimator=pipeline,param_grid=param_grids[name],cv=5,scoring='accuracy',n_jobs=-1,verbose=1)# 训练模型grid_search.fit(X_train, y_train)# 存储最佳模型best_models[name] = grid_search.best_estimator_# 在训练集上评估y_train_pred = best_models[name].predict(X_train)train_accuracy = accuracy_score(y_train, y_train_pred)# 在测试集上评估y_test_pred = best_models[name].predict(X_test)test_accuracy = accuracy_score(y_test, y_test_pred)print(f"最佳参数: {grid_search.best_params_}")print(f"训练集准确率: {train_accuracy:.4f}")print(f"测试集准确率: {test_accuracy:.4f}")# 详细分类报告print("\n分类报告:")print(classification_report(y_test, y_test_pred))# 混淆矩阵cm = confusion_matrix(y_test, y_test_pred)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.title(f'{name} 混淆矩阵')plt.xlabel('预测标签')plt.ylabel('真实标签')plt.show()# ROC曲线if hasattr(best_models[name], "predict_proba"):y_pred_proba = best_models[name].predict_proba(X_test)[:,1]fpr, tpr, _ = roc_curve(y_test, y_pred_proba)roc_auc = auc(fpr, tpr)plt.figure(figsize=(8, 6))plt.plot(fpr, tpr, label=f'ROC曲线 (AUC = {roc_auc:.3f})')plt.plot([0, 1], [0, 1], 'k--')plt.xlabel('假正例率')plt.ylabel('真正例率')plt.title(f'{name} ROC曲线')plt.legend(loc='lower right')plt.grid(True)plt.show()# 7. 选择最佳模型
# ---------------------------------------------------------------------------------
print("\n第七步:选择最佳模型")# 比较所有模型的性能
model_performances = {}
for name, model in best_models.items():y_test_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_test_pred)model_performances[name] = accuracybest_model_name = max(model_performances, key=model_performances.get)
best_model = best_models[best_model_name]print(f"最佳模型: {best_model_name}")
print(f"测试集准确率: {model_performances[best_model_name]:.4f}")# 8. 模型部署准备
# ---------------------------------------------------------------------------------
print("\n第八步:模型部署准备")# 保存模型
with open('churn_prediction_model.pkl', 'wb') as f:pickle.dump(best_model, f)
print("模型已保存为 'churn_prediction_model.pkl'")# 示例:如何加载模型并进行预测
with open('churn_prediction_model.pkl', 'rb') as f:loaded_model = pickle.load(f)# 创建一个示例新客户数据
new_customer = X.iloc[[0]].copy() # 使用第一行数据作为示例
print("\n新客户数据:")
print(new_customer)# 使用加载的模型进行预测
prediction = loaded_model.predict(new_customer)
prediction_proba = loaded_model.predict_proba(new_customer)print(f"\n流失预测: {'是' if prediction[0] == 1 else '否'}")
print(f"流失概率: {prediction_proba[0][1]:.4f}")# 9. 部署示例(伪代码)
# ---------------------------------------------------------------------------------
print("\n第九步:部署示例(Flask API)")"""
# 这部分是Flask API的伪代码示例,不会实际运行
from flask import Flask, request, jsonify
import pandas as pd
import pickleapp = Flask(__name__)# 加载模型
with open('churn_prediction_model.pkl', 'rb') as f:model = pickle.load(f)@app.route('/predict', methods=['POST'])
def predict_churn():# 获取客户数据data = request.json# 将数据转换为DataFramecustomer_df = pd.DataFrame(data, index=[0])# 进行预测churn_probability = model.predict_proba(customer_df)[0][1]churn_prediction = model.predict(customer_df)[0]# 返回预测结果return jsonify({'churn_prediction': bool(churn_prediction),'churn_probability': float(churn_probability),'message': '该客户预计将流失' if churn_prediction else '该客户预计不会流失'})if __name__ == '__main__':app.run(debug=True, host='0.0.0.0', port=5000)
"""print("完整电信客户流失预测模型已构建完成!")
八、总结与扩展阅读
1. 今日要点回顾
在第49天的学习中,我们深入探讨了特征工程的核心技术,并学习了一个完整的机器学习建模流程。主要内容包括:
- 特征标准化与归一化的差异及应用场景
- 多种缺失值填充策略及其选择原则
- 特征编码技术:One-Hot编码与Label编码
- 特征选择方法:卡方检验与Lasso回归
- 端到端建模流程:从数据清洗到模型部署
- 通过实战项目掌握全流程建模技巧
2. 应用场景
特征工程和端到端建模在以下场景中有广泛应用:
- 客户流失预测:预测哪些客户可能取消服务
- 信用风险评估:预测借款人是否会违约
- 医疗诊断:从患者数据预测疾病风险
- 推荐系统:根据用户特征推荐产品
- 异常检测:识别欺诈交易或系统故障
3. 进阶学习方向
想要在特征工程和机器学习建模领域进一步提升,可以探索以下方向:
- 自动化特征工程:使用FeatureTools等库自动创建特征
- 深度学习特征提取:使用神经网络自动学习特征表示
- 时间序列特征工程:处理时间依赖性数据的特殊技术
- MLOps与模型监控:学习如何在生产环境中部署和监控模型
- 可解释机器学习:理解和解释模型决策的方法
4. 实践建议
要真正掌握特征工程和机器学习建模,建议:
- 参加Kaggle竞赛,学习顶尖数据科学家的特征工程技巧
- 阅读《Feature Engineering for Machine Learning》等经典书籍
- 构建个人项目组合,解决不同类型的问题
- 学习AutoML工具,如TPOT、auto-sklearn等
- 练习在生产环境中部署模型,如使用Flask、FastAPI或MLflow
明天,我们将继续深入机器学习领域,探讨深度学习的基础概念和神经网络架构。请继续关注《Python星球日记》!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!