VLM-AD:通过视觉语言模型监督实现端到端自动驾驶
《VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision》2024年12月发表,来自Cruise和美国东北大学的论文。
人类驾驶员依靠常识推理来驾驭多样化和动态的现实世界场景。现有的端到端(E2E)自动驾驶(AD)模型通常经过优化,以模拟数据中观察到的驾驶模式,而不捕获底层推理过程。这种限制限制了他们处理具有挑战性的驾驶场景的能力。为了缩小这一差距,我们提出了VLM-AD,这是一种利用视觉语言模型(VLM)作为教师的方法,通过提供包含非结构化推理信息和结构化动作标签的额外监督来加强培训。这种监督增强了模型学习更丰富的特征表示的能力,这些特征表示捕捉了驾驶模式背后的基本原理。重要的是,我们的方法在推理过程中不需要VLM,使其适用于实时部署。当与最先进的方法集成时,VLM-AD在nuScenes数据集上的规划精度和碰撞率方面取得了显著提高。
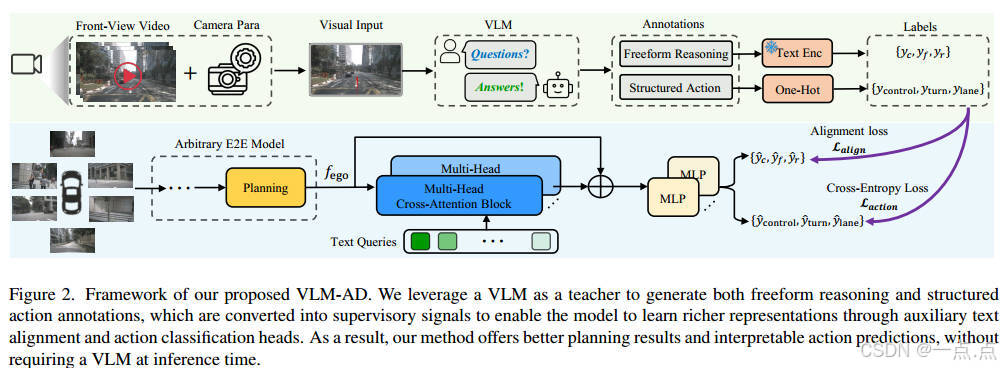
研究背景与问题
现有的端到端(E2E)自动驾驶模型通过模仿数据中的驾驶模式进行优化,但缺乏人类驾驶员在复杂场景中的常识推理能力,导致在长尾事件(如罕见交通场景)中表现不佳。传统方法依赖人工标注的轨迹数据,但标注成本高且难以捕捉隐含的推理逻辑;而直接集成大语言模型(LLM)或视觉语言模型(VLM)的方法则需要大量微调,且推理时依赖大模型,计算开销大。
核心贡献
提出 VLM-AD 方法,通过以下创新点解决上述问题:
-
VLM作为教师模型:
-
在训练阶段,利用VLM(如GPT-4)自动生成非结构化推理文本(如“当前动作”“未来预测”“推理逻辑”)和结构化动作标签(如“直行”“左转”)。
-
将未来轨迹投影到前视图像中,解决VLM对时序信息理解不足的问题。
-
-
辅助任务设计:
-
特征对齐任务:通过交叉注意力机制,将模型特征与VLM生成的文本特征对齐。
-
动作分类任务:直接预测结构化动作标签。
-
通过多任务学习联合优化,提升模型对驾驶逻辑的理解。
-
-
无需推理时依赖VLM:仅在训练阶段使用VLM生成标注,实际部署时无需大模型,保证实时性。
方法细节
-
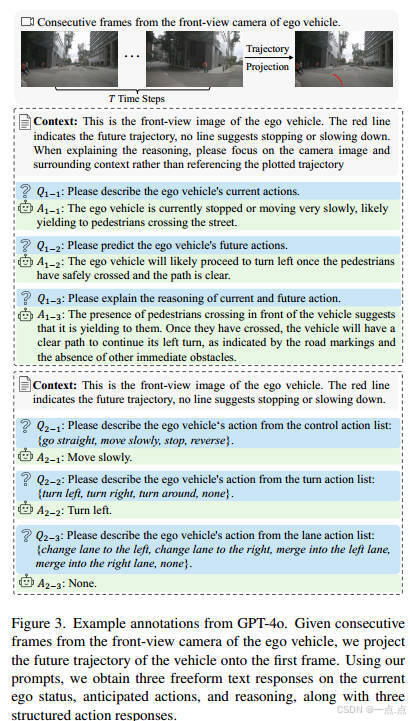
数据标注流程:
-
输入:前视图像 + 投影的未来轨迹(解决时序问题)。
-
标注生成:
-
自由文本(Q1):通过开放式问题(如“当前动作是什么?”“未来会做什么?”“推理逻辑?”)生成非结构化文本。
-
结构化动作(Q2):从预定义动作列表(如“直行”“左转”)中选择标签。
-
-
标注编码:使用CLIP将文本转为特征向量,动作标签转为one-hot编码。
-
-
模型架构:
-
辅助任务头:
-
特征对齐头:通过多头交叉注意力(MHCA)将模型特征与文本特征对齐,使用温度参数控制特征分布平滑度。
-
动作分类头:直接预测结构化动作,使用交叉熵损失优化。
-
-
损失函数:加权结合特征对齐损失(LalignLalign)和动作分类损失(LactionLaction)。
-
实验结果
-
性能提升:
-
在nuScenes数据集上,VLM-AD显著降低了规划误差(L2误差降低14.6%-33.3%)和碰撞率(降低38.7%-57.4%)。
-
集成到UniAD和VAD模型后,均优于基线方法和对比方法(如VLP)。
-
-
消融实验:
-
子问题贡献:推理问题(Q1-3)对性能提升最大,说明推理逻辑是关键。
-
特征对齐方法:提出的温度归一化方法优于MSE、KL散度等传统对齐方式。
-
模型设计:使用MHCA块和CLIP编码效果最佳。
-
-
可视化分析:
-
VLM-AD生成的轨迹更平滑且符合道路结构,而基线模型(如UniAD)轨迹抖动较大。
-
动作预测头提供了可解释性(如正确输出“直行”而非错误转向指令)。
-
局限性及未来方向
-
标注质量依赖VLM:
-
VLM可能误判动作(如将右转误标为左转)或环境状态(如混淆交通灯与行人灯)。
-
改进方向:设计更精细的提示(Prompt)或引入多模态输入(如激光雷达)。
-
-
数据集多样性不足:
-
nuScenes数据集中97%的样本为“直行”,限制了模型对复杂动作的学习。
-
改进方向:引入更多长尾场景数据或合成数据增强。
-
-
实时性挑战:
-
当前方法在训练阶段需调用VLM生成标注,未来可探索轻量化VLM或离线标注加速流程。
-
总结
VLM-AD通过VLM生成的推理监督信号,显著提升了端到端自动驾驶模型的规划能力和鲁棒性,同时避免了推理时的高计算开销。其核心价值在于:
-
低成本标注:利用VLM自动生成高质量监督信号,减少对人工标注的依赖。
-
可解释性:通过动作分类头提供人类可理解的决策逻辑。
-
通用性:可灵活集成到现有E2E框架(如UniAD、VAD),具有广泛适用性。
未来工作可进一步优化VLM标注的准确性,并结合多模态感知提升复杂场景的泛化能力。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!