大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
文章目录
- 大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
- 一、项目概述
- 二、项目说明
- 三、研究意义
- 四、系统总体架构设计
- 总体框架
- 技术架构
- 数据可视化模块设计图
- 后台管理模块设计
- 数据库设计
- 五、开发技术介绍
- Flask框架
- Python爬虫之Selenium
- AJAX技术介绍
- 数据可视化
- 机器学习
- 六、开发环境介绍
- Pycharm开发工具简介
- Firefox简介
- 七、机器学习多元线性回归模型算法部分模块核心代码
- 八、项目截图
- 九、结语
大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
一、项目概述
本项目旨在设计与实现一个基于Python机器学习的产品销售数据爬虫可视化分析预测系统,结合现代数据技术,提升企业产品销售管理的智能化与数字化水平。该系统主要包括数据管理和后台管理两个核心模块,其中数据管理部分涵盖数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的销量预测五大功能模块。
在数据爬取方面,本平台使用Selenium爬虫技术,从相关网站获取销售数据,并借助Pandas进行数据清洗,最后将清洗后的数据存入MySQL数据库。在数据可视化方面,采用Echarts技术展示销售趋势及其他关键指标,使得数据更加直观易懂。平台还利用多元线性回归算法对产品销量进行预测,为管理者提供未来销售趋势的预测信息。
本平台使用Flask框架进行后台管理系统的开发,并结合Lay-UI与Bootstrap框架进行前端设计,确保界面的友好与易操作性。通过黑盒测试验证了系统的功能性与稳定性,确保平台能够高效、精准地进行数据分析与管理。该系统为企业提供了强大的数据分析与决策支持工具,助力企业提高管理效率与市场竞争力。
二、项目说明
本次设计将产品销售和数据分析系统结合,使用数字化加持,简化平台管理,赋能智慧企业的一款数据分析可视化管理系统。本文主要工作为:分析产品销售背景后,对本平台所使用到的相关技术如Selenium、Echarts、Ajax、MySQL和Flask、Lay-UI、Bootstrap框架进行介绍及对比分析,通过产品销售数据平台管理者的基本需求及相关产品销售管理模块的需求分析进行总结,对本平台的设计概要分为数据管理部分及后台管理两大核心模块,数据管理部分囊括了数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的数据预测五个板块。本课题的核心内容是以产品销售企业对数据分析平台的基本需求为背景,根据预先设计的思路进行平台的搭建。运用Selenium爬虫技术将数据爬取并用Pandas进行清洗后,将数据导入到MySQL中,使用数据可视化技术对数据进行直观地展示,同时也通过机器学习中的多元线性回归算法对产品销量进行预测,并导入后台在后台管理中查看或使用。最后,本平台运用黑盒测试对数据管理和后台管理进行功能性测试,测试结果均符合预期且平台能够正常运行。
三、研究意义
该本研究的意义在于推动产品销售管理向数字化、智能化转型,提升企业在市场竞争中的决策能力。随着大数据时代的到来,企业面对的数据量日益增多,如何从中提取有效信息进行精准决策成为企业发展的重要课题。本平台结合Python机器学习技术,构建了一个集数据爬取、存储、分析与预测为一体的系统,能够为产品销售管理提供强有力的数据支持。采用Selenium技术进行数据爬取,结合Pandas进行数据清洗与处理,解决了传统人工采集和整理数据的低效问题,极大提高了数据获取和处理的效率。其次,系统运用Echarts等数据可视化技术,将复杂的销售数据以图表形式呈现,使管理者能够直观地了解销售趋势和市场变化,为决策提供依据。更重要的是,通过多元线性回归算法的引入,系统能够对未来的产品销量进行精准预测,帮助企业预测市场需求变化,制定科学的销售策略。
本研究不仅为产品销售企业提供了一个高效、精准的数据分析与管理平台,还通过现代机器学习与数据技术的融合,推动了传统企业的数字化转型和智能化管理,为企业提高市场竞争力和运营效率提供了有力保障。
四、系统总体架构设计
总体框架
通过对数据的爬取、保存、计算分析、可视化展示,构成了产品销售数据分析平台的功能。其中主要包括如下几个层面:
1)产品销售数据爬虫。在本课题中,需要爬取的数据主要包括产品基本信息数据——产品名称、产品原价格、产品折扣价格、店铺名称、产品销量。
2)完整的保存爬取到的数据。在本项目中,由于存在大量的数据,合理有效地存储数据就变得非常重要。而如果使用早前单机时代的数据库,是无法保证高效读写大量数据的,所以必须采用分布式的存储系统。
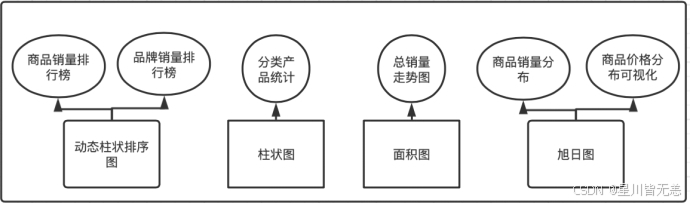
3)多角度的数据分析。基于前面的需求分析,可以从多个角度对产品销售平台的现有数据进行有效的信息挖掘。本课题采用了六种角度:产品销量排行榜,品牌销量排行榜、分类产品统计、总销量走势图、产品销量分布、产品价格分布;然后使用合适的机器学习算法对这些数据加以分析。
4)恰当的数据可视化展示。当计算分析出数据结论之后,会采用合适的方式去展示最终的结果数据。比如可以使用动态排序柱状图、旭日图、面积图等去表明数据的特点。
技术架构
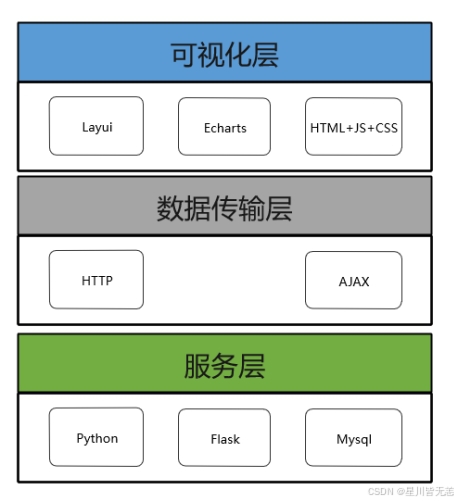
数据可视化模块设计图
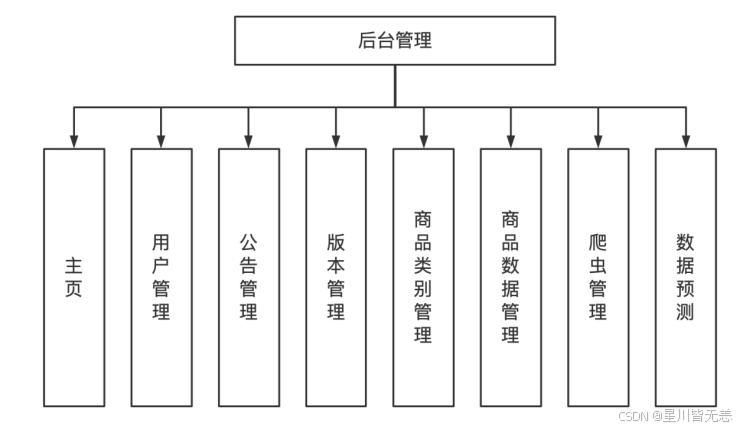
后台管理模块设计
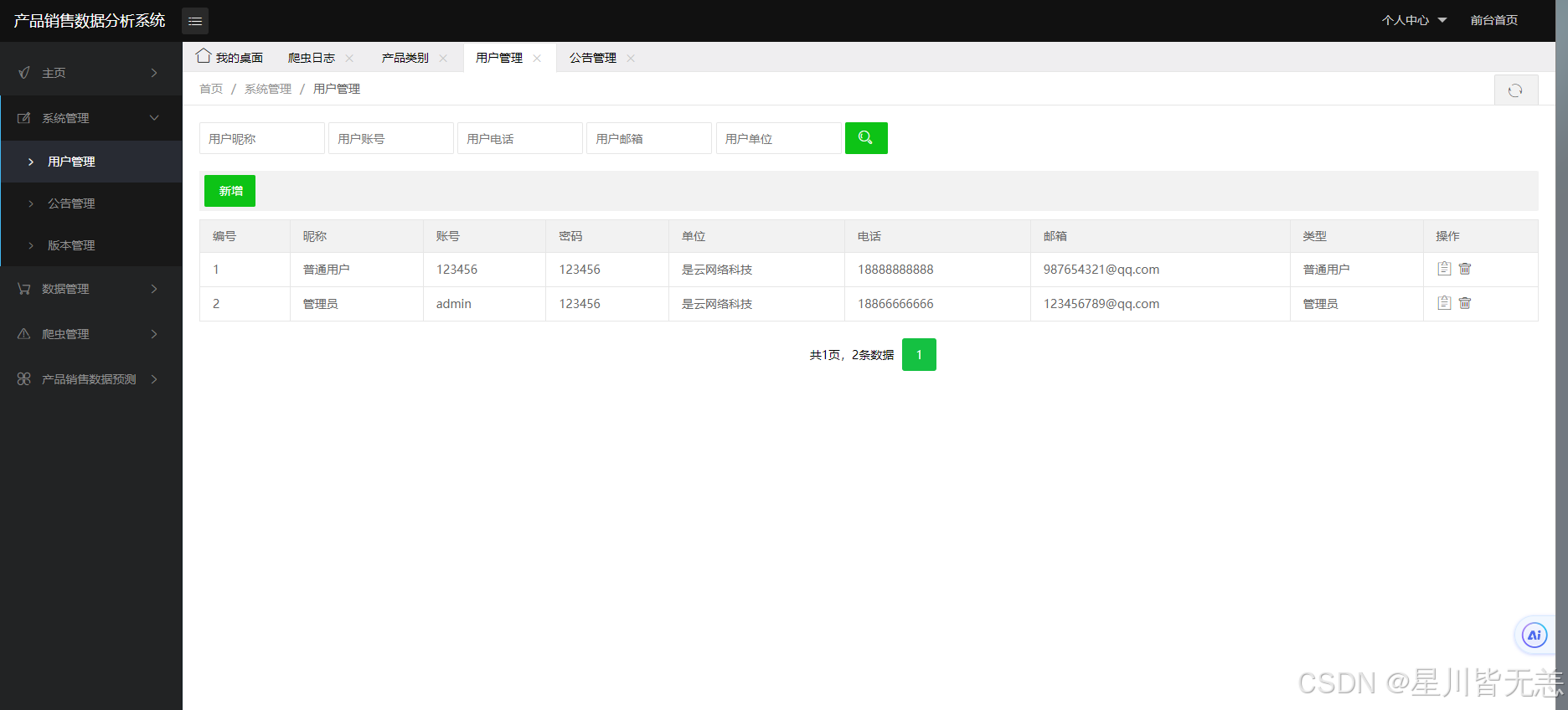
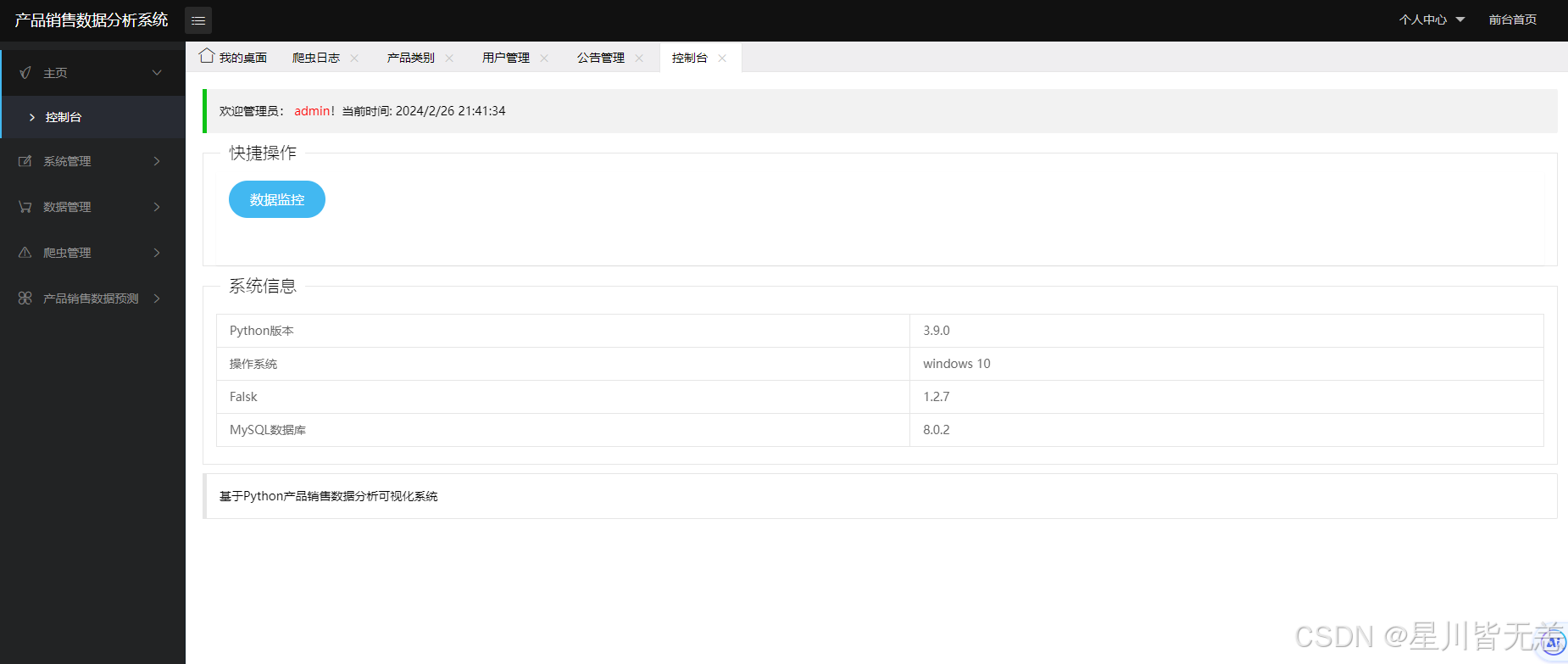
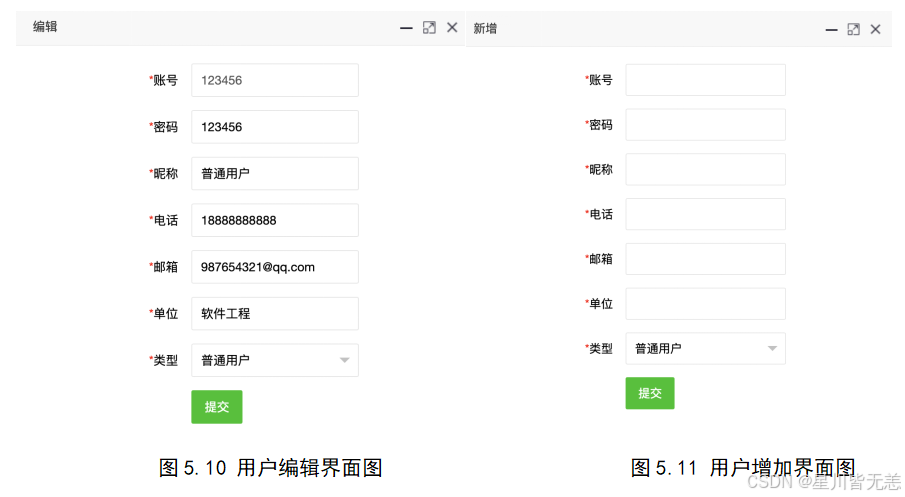
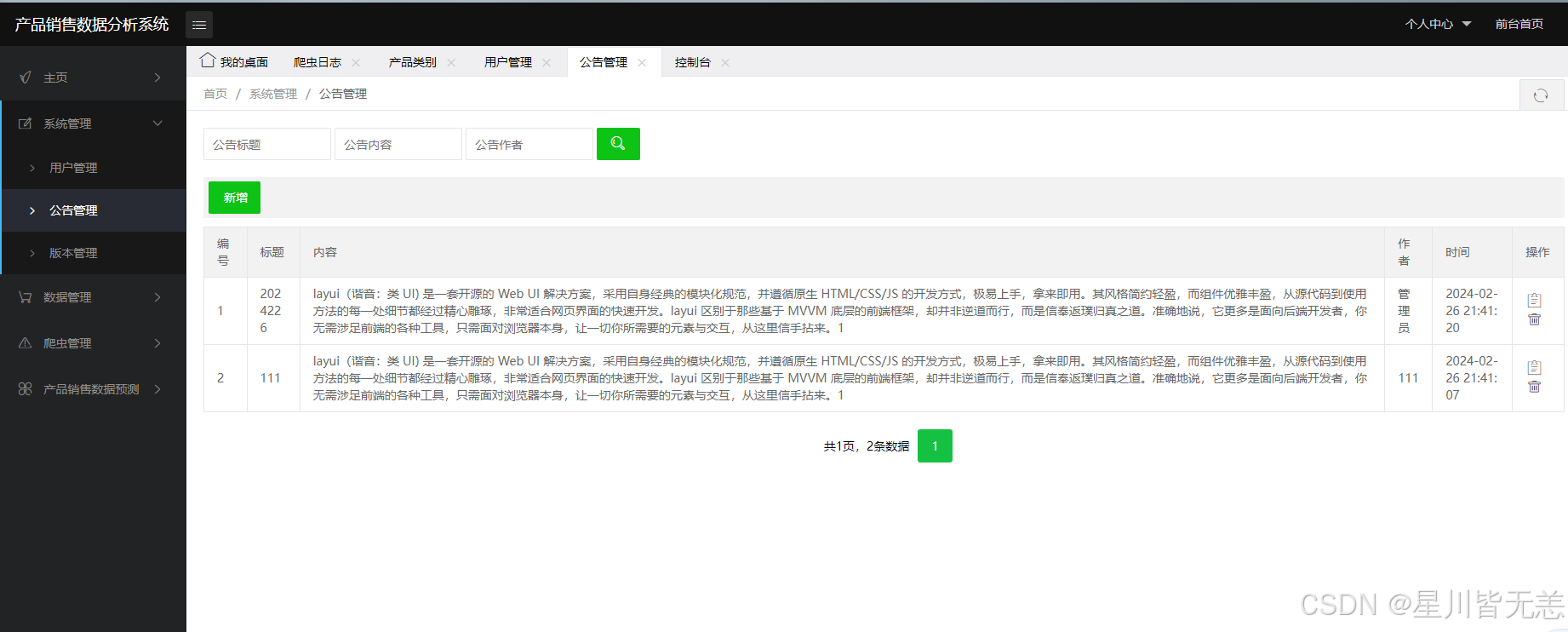
管理员后台管理可以对用户管理、版本管理、公告管理、产品数据管理、产品类别管理、爬虫管理以及数据预测。对用户管理、版本管理、公告管理、产品数据管理、产品类别管理进行基本的查看、修改、增加、删除;在爬虫管理处可以对想要的产品进行爬取,得到一个目标数据的文件,并在爬取后进行统计,最后将此次操作的爬取内容和爬取时间记录进爬虫日志中,方便管理员对数据进行保护。数据预测部分输入索要预测的产品类别,并输入产品折扣价和原价,根据多元线性回归算法获得预测结果,并提示预测成功。
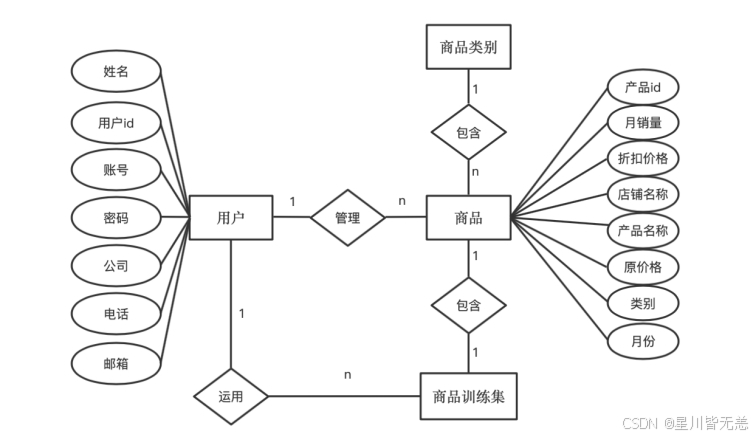
数据库设计
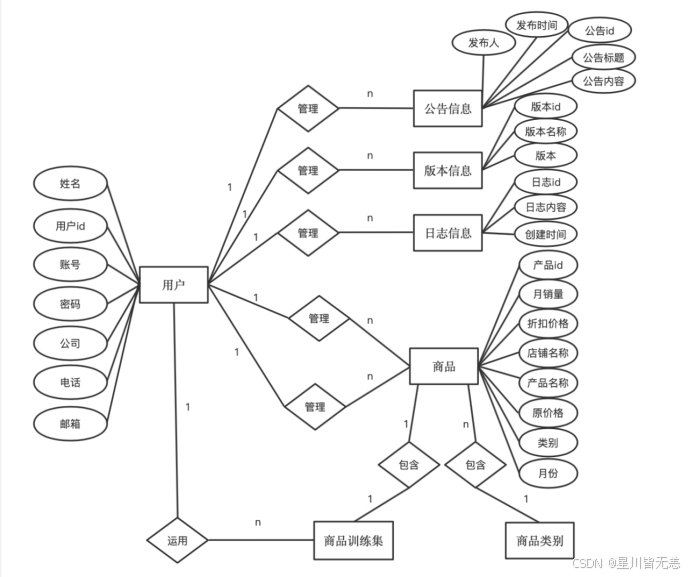
产品实体和产品训练实体是一对一的关系。
用户实体和产品实体之间是一对多的关系。
用户实体和公告实体之间是一对多的关系。
用户实体和版本实体之间是一对多的关系。
用户实体和日志实体之间是一对多的关系。
产品实体和产品类别实体是多对一的关系。
产品训练实体和产品类别实体是多对一的关系。
五、开发技术介绍
Flask框架
Flask 框架是一个轻量级的、便捷的、Python 所提供的 Web 框架,微框架基于Werkzeug(这是WSGI的工具包,即Web服务器网关接口)和Jinja(即Python的模板引擎)的基础。
Flask不仅支持关系数据库,而且还支持非关系数据库(例如MongoDB),由于Flask本身就是相当于一个内核,其结构并不含有数据库抽象层以及表单特征,所以 Flask体积很小。但是Flask具有非常强大的扩展性,用户可以自由选择和组合需要的功能。这也使得Flask变得灵活多变。这些特性让Flask框架一经推出就受到广大用户的喜爱。Flask的工作流程如图3所示,在Flask中每一个URL代表一个是视图函数。当用户访问这些URL时,系统就会调用相对应视图函数,并将函数结果返回给用户。
它更加的灵活、轻便、安全且容易上手,是目前主流的服务器框架。利用 Flask 框架,能实现前后端的数据交互,它可以不用写很多的业务代码,也可以不使用手动设置参数,就可以轻松开发出前端网页接口。Flask可以使程序员在开发时只关注开发业务的本身,而不需要去关注框架怎么设计、结构怎么设计以及框架怎么配置等操作,这样可以大大降低我们开发时所需要付出的精力,增加我们的开发效率。
相对于适合于大型项目的Django,本系统采用性能高于Django且适合高负载的小型且不复杂的Web应用程序的Flask框架。

图2.1 Flask工作原理
Python爬虫之Selenium
Selenium是一个Web应用程序测试的工具,起初是为了网站自动化测试而开发的,作是模拟用户在浏览器上的操作。Selenium自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用,但Selenium可以直接运行在浏览器上,它支持所有主流的浏览器,包括PhantomJS这些无界面的浏览器,可谓作用之广泛。Selenium可以根据用户的指令,指导浏览器自动加载页面,获取需要的数据,甚至于网页截屏、监听网站动作等等。
由于本数据分析平台选用“淘宝”为产品销售的数据对象,而淘宝的商业数据,它的价值远远高出普通数据。在对网站的页面进行抓包分析后发现,页面中的数据带有加密混淆,所以传统的爬虫思路再次站点行不通。遇到这种情况,一般有两种解决方法第一种是通过使用JavaScript逆向技术找到站点的加密逻辑,并用Python代码将其加密逻辑模拟构造出来。第二种是通过Selenium自动化测试工具来模拟浏览器,直接获取页面源码。
基于以上原因,本系统采用的是第二种方案。首先,需要认为的对爬虫主程序进行初始化信息,需要向爬虫提供一些参数,例如目标数据所在的初始网页地址,需要爬取的页面数、关键词等。然后,设置无头浏览器,Selenium开始工作,在后台默默打开浏览器,输入网址,翻页。每次翻页过后,网页下载器便会获取当前页面的网页源代码,然后提交给网页解析器解析内容。时序图如图2.1所示。在进行元素定位后,需要设置元素等待,不然就会造成获取数据残缺甚至获取不到数据的情况。最后,将网页源代码中的目标数据提取出来,保存到数据库中,便于以后进行更进一步的处理。
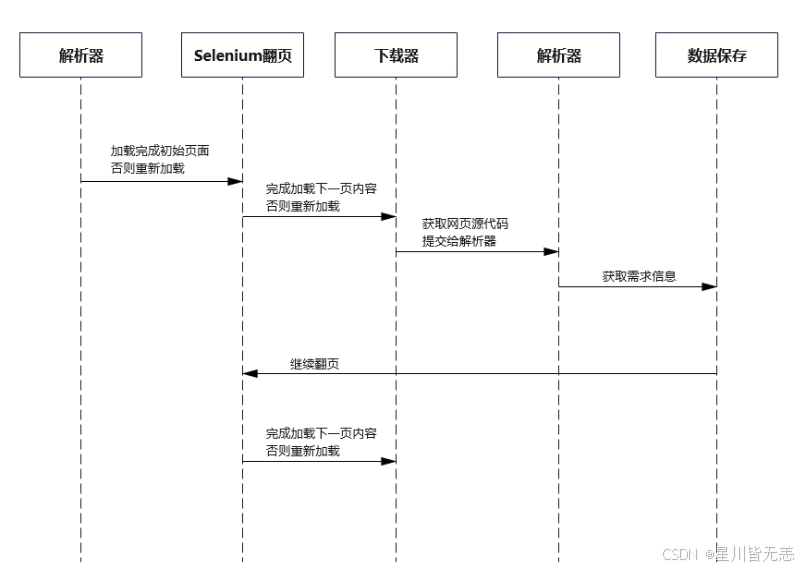
图2.1 爬虫时序图
AJAX技术介绍
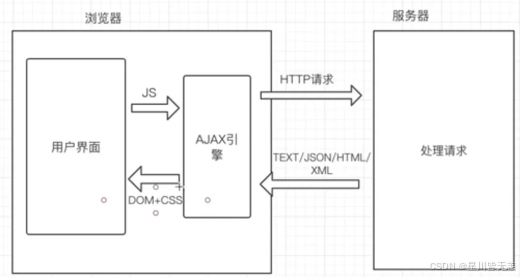
Ajax是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必需重载整个网页面。有很多使用Ajax的应用程序案例:新浪微博、Google 地图、开心网等等。同样他也是一款优秀的前端框架,采用自身模块规范编写的前端UI框架严格遵循HTML/CSS/JS的开发方式,简单易用,可以说是开箱即用,对中小项目具有极高的友好度。虽然目前Lay-UI官网下架,但项目仍然在Github开源。
数据可视化
可视化技术是用来展示数据分析结果的一种大数据技术,它可以直观地表达信息,通常使用柱状图、饼状图、折线图、词云图等图来表达。一般而言,常用到的大数据可视化工具有:Tableau Desktop、QlikView、Microsoft Excel、SAS、IBM SPSS、Echarts等。下面分别来介绍三大可视化技术:
Tableau Desktop:由Tableau公司进行研发的一款智能商业软件,它既可以具有检测数据的功能,也具有良好的分析能力。Tableau将数据计算与图表完美的结合在了一起,通过拖动的方式使人们很方便使用。
QlikView是一款商业分析软件,可以构建强大的应用给研发者以及分析者使用。QlikView的存在使得用户可以用一种高度可视化的方式研究分析业务数据信息。
Echarts是由百度研发的一款图表插件,有着丰富多样的图表功能。它使用Java Script程序编写而成,遵守Apache-2.0的开源协议,供给开发人员免费使用。
本系统选用Echarts作为数据可视化技术。基于淘宝相关产品数据集,利用Python 语言的 Flask框架、ECharts 等技术完成数据的可视化。后端完成数据的提取与封装,利用 Ajax 技术完成前后端的数据交互。ECharts 技术与 Jinja2 模板引擎等技术实现数据可视化。
机器学习
机器学习是人工智能的主要表现形式,其学习形式主要分为:有监督学习、无监督学习、半监督学习等,对于“监督”一词会不明就里,其实你可以把这个词理解为习题的“参考答案”,专业术语叫做“标记”。比如有监督学习就是有参考答案的学习,而无监就是无参考答案。
- 有监督学习
有监督学习(Supervised Learning),需要你事先需要准备好要输入数据(训练样本)与真实的输出结果(参考答案),然后通过计算机的学习得到一个预测模型,再用已知的模型去预测未知的样本,这种方法被称为有监督学习。这也是是最常见的机器学习方法。简单来说,就像你已经知道了试卷的标准答案,然后再去考试,相比没有答案再去考试准确率会更高,也更容易。
- 无监督学习
理解了有监督学习,那么无监督学习理解起来也变的容易。所谓无监督学习(Unsupervised Learning)就是在没有“参考答案”的前提下,计算机仅根据样本的特征或相关性,就能实现从样本数据中训练出相应的预测模型。
由于本次数据分析的数据集数据集(产品类别,产品原价、产品现价,销售量)包含来源于一些淘宝产品,采用多元线性回归算法对产品价格变动后的销量进行预测,其学习形式选定为有监督学习。
六、开发环境介绍
Pycharm开发工具简介
IntelliJ Pycharm,它是为Python语言开发的集成开发环境。目前在业界好评如潮,受广大程序爱好者所青睐,是目前公认的Python最好的开发工具之一。它的特色在于,拥有强大的代码自动补全提示功能、代码重构功能以及对各种第三方插件的高度支持,例如git、svn、代码规范、在线翻译等插件。这些优秀的功能能够大大提高开发效率以及出错概率,同时还有助于养成一个良好的代码习惯。
Firefox简介
Firefox是一款十流行的浏览器。工欲善其事必先利其器,Firefox浏览器就是这这样的利器存在,他提供强大的浏览器插件支持,可以大大提供前端调试效率,其中像Web 前端助手这样的优秀插件了包括 Json格式化、二维码生成与解码、美化、页面取色、Markdown 与 HTML 互转、正则表达式、时间转换工具、编码规范检测、页面性能检测、Ajax 接口调试、网页编码设置等各种功能。
七、机器学习多元线性回归模型算法部分模块核心代码
这里使用机器学习的多元线性回归算法来实现产品销量的预测。首先定义算法模型,喂入数据模型,进行训练,最终得到结果。此外,我们需要对该模型根据损失函数进行评估,这里主要使用预测值和实际值来计算准确率,得到模型的EMS损失值。具体代码如下:
# 分割数据集合
train_data = []
test_data = []
for index, item in enumerate(data):if index % 5 == 0: # 每5条数据,第6条保留为测试集合,也就是训练集:测试集=5:1test_data.append(item)else:train_data.append(item)
train_data, test_data = np.array(train_data), np.array(test_data)X = np.array(train_data[:, 1:3]).astype(float)
Y = np.array(train_data[:, 3]).astype(float)test_X = np.array(test_data[:, 1:3]).astype(float)
text_Y = np.array(test_data[:, 3]).astype(float)# 定义算法模型
model = LinearRegression()
# 喂入模型数据
model.fit(X, Y)
joblib.dump(model, "./goods.joblib")
根据上述代码运行后得到模型的EMS损失值如下:
[INFO] 多元线性回归预测销量-训练开始
[INFO] 模型EMS损失值(模型评分越低越好): 0.0049775877557516335
[INFO] 多元线性回归预测销量-训练完成
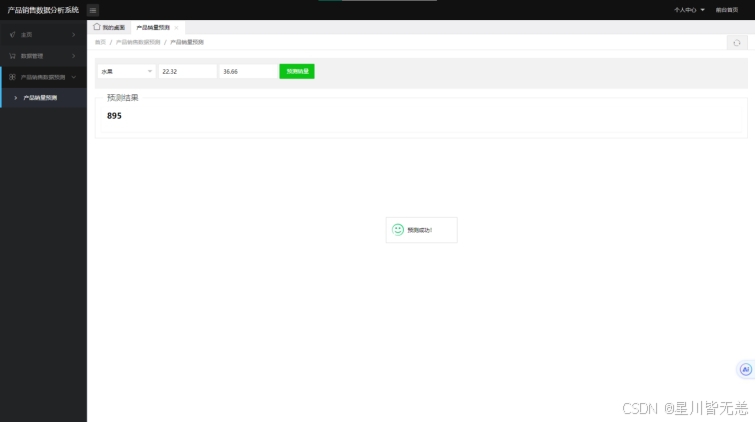
八、项目截图
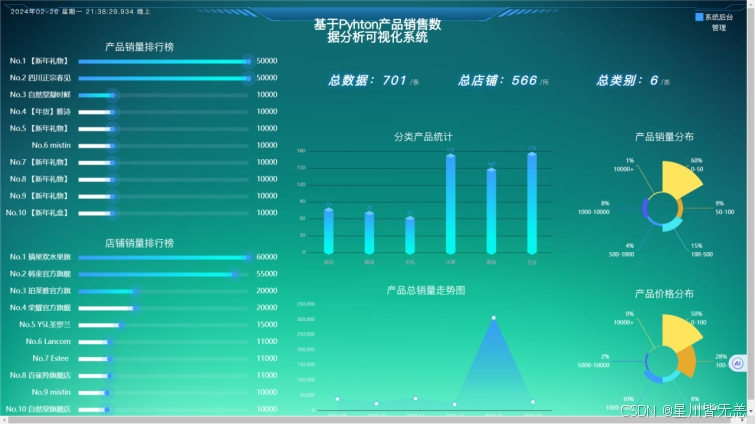
九、结语
需项目源码文档等资料/商业合作/交流探讨等可以添加下面个人名片进行源码文档等获取,后续有时间会持续更新更多优质项目内容,感谢各位的喜欢与支持!