布隆过滤器
引入:布隆过滤器的作用
Q1:如何判断众多整形中是否存在某个整形?
A1:有了位图,我们只需在整形对应的位上置1即可,然后再看需要判断是否存在的整形的位是否为1即可
Q2:如何判断众多字符串中是否存在某个字符串?
A2:和Q1不同,字符串想要通过位图来表示存在,一定是要用哈希函数来得到一个整形值,该整形值所对应的位,才是字符串对应的位;但有哈希函数,则必定有哈希冲突;也就是说,可能你需要判断的字符串不在,但是由于其他字符串和你通过哈希函数得到的整形值一样,你会误以为在!
布隆过滤器的意义:
用来降低这种哈希冲突,是的,仅仅只能做到降低哈希冲突,而不能完全抹除哈希冲突;方法则是让一个字符串通过多个哈希函数来映射到不同的位,多个位来表示一个字符串的存在,则会大大降低哈希冲突!
举个例子:
假设布隆过滤器使用三个哈希函数进行映射,那么“张三”这个昵称被使用后位图中会有三个比特位会被置1,当有人要使用“李四”这个昵称时,就算前两个哈希函数计算出来的位置都产生了冲突,但由于第三个哈希函数计算出的比特位的值为0,此时系统就会判定“李四”这个昵称没有被使用过
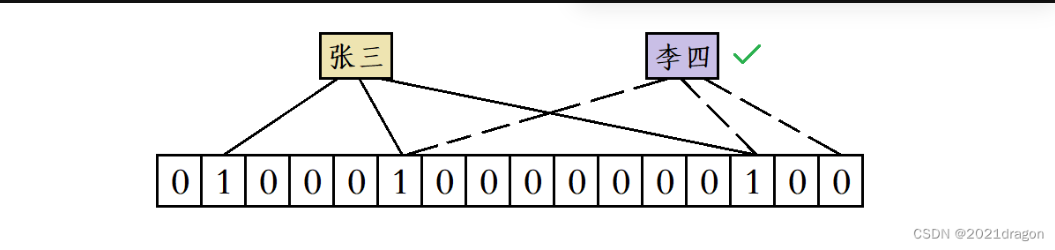
比如“张三”和“李四”都添加到位图中后,当有人要使用“王五”这个昵称时,虽然“王五”计算出来的三个位置既不和“张三”完全一样,也不和“李四”完全一样,但“王五”计算出来的三个位置分别被“张三”和“李四”占用了,此时系统也会误判为“王五”这个昵称已经被使用过了。
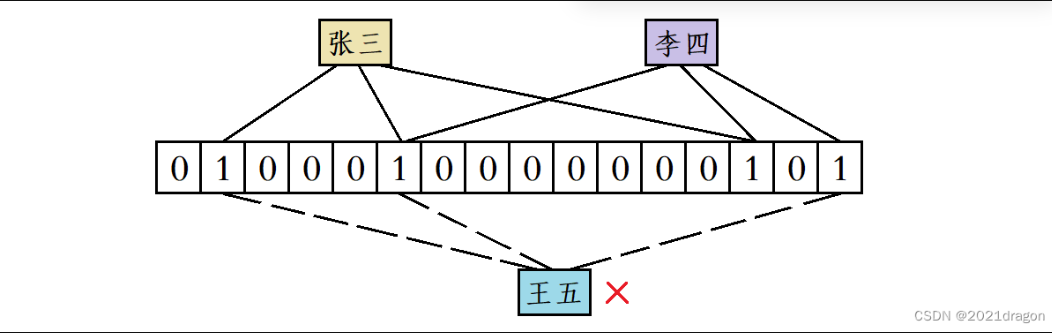
注:图片来自哈希的应用 —— 布隆过滤器_布隆过滤器怎么确认长度和hash次数-CSDN博客
所以,布隆过滤器的特点如下:
1:当布隆过滤器判断一个数据存在可能是不准确的;
因为这个数据对应的比特位可能被其他一个数据或多个数据占用了。
2:当布隆过滤器判断一个数据不存在是准确的;
因为如果该数据存在那么该数据对应的比特位都应该已经被设置为1了。
这时候,就有人要问了,我们需要这种存在误判的数据结构吗?
还真需要,且看后文....
一:概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询。
①:布隆过滤器其实就是位图的一个变形和延伸,虽然无法避免存在哈希冲突,但我们可以想办法降低误判的概率。
②:当一个数据映射到位图中时,布隆过滤器会用多个哈希函数将其映射到多个比特位,当判断一个数据是否在位图当中时,需要分别根据这些哈希函数计算出对应的比特位,如果这些比特位都被设置为1则判定为该数据存在,否则则判定为该数据不存在。
③:布隆过滤器使用多个哈希函数进行映射,目的就在于降低哈希冲突的概率,一个哈希函数产生冲突的概率可能比较大,但多个哈希函数同时产生冲突的概率可就没那么大了。
哈希博客:手撕哈希表-CSDN博客
位图博客:位图的实现和拓展-CSDN博客
二:实现
哈希和位图不再赘述,博客链接已贴出
①:哈希函数的选择
选择三个著名的哈希函数:
第一个哈希函数. BKDR Hash (HashFuncBKDR)
原理:
-
采用简单的乘法和加法组合
-
初始哈希值为0
-
对每个字符执行:
hash = hash * 131 + 字符值 -
131是一个经验选择的大质数,有助于减少冲突
第二个哈希函数. AP Hash (HashFuncAP)
原理:
-
采用更复杂的位操作和条件处理
-
根据字符位置是奇数还是偶数采用不同的处理方式:
-
偶数位:
hash ^= ((hash << 7) ^ 字符 ^ (hash >> 3)) -
奇数位:
hash ^= (~((hash << 11) ^ 字符 ^ (hash >> 5)))
-
-
结合了位移、异或和取反操作
第三个哈希函数. DJB Hash (HashFuncDJB)
原理:
-
初始哈希值为5381(魔术常数)
-
对每个字符执行:
hash = hash * 33 ^ 字符值 -
33也是一个经验选择的质数
所以代码如下:
struct HashFuncBKDR
{// BKDRsize_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 131;hash += ch;}return hash;}
};struct HashFuncAP
{// APsize_t operator()(const string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶数位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇数位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));}}return hash;}
};struct HashFuncDJB
{// DJBsize_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};
②:布隆过滤器类的框架
template<size_t N,class K = string,class Hash1 = HashFuncBKDR,class Hash2 = HashFuncAP,class Hash3 = HashFuncDJB>class BloomFilter
{
public:private:static const size_t M = 10 * N;std::bitset<M>* _bs = new std::bitset<M>;
};解释:
1:模板参数
N: 预期要插入的元素数量,比如题目说有10个字符串,则这里的N为10
K: 键的类型(题目中值的类型),默认为string
Hash1, Hash2, Hash3: 三个不同的哈希函数类型,为之前介绍的BKDR、AP和DJB哈希
2:成员变量
M: 位数组的大小,设置为10*N,这是布隆过滤器的典型设计,即每个元素使用约10位
_bs: 使用std::bitset动态分配的位数组,作为布隆过滤器的存储核心
③:set函数
void Set(const K& key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;_bs->set(hash1);_bs->set(hash2);_bs->set(hash3);}解释:有了哈希函数和位图,所以布隆过滤器的set实现非常简单,仅需通过三个函数得到三个整形,再在位数组中将这几个位置为1即可
④:test函数
bool Test(const K& key)
{// 使用第一个哈希函数计算位置并检查size_t hash1 = Hash1()(key) % M;if (_bs->test(hash1) == false)return false; // 如果第一个位为0,元素肯定不存在// 使用第二个哈希函数计算位置并检查size_t hash2 = Hash2()(key) % M;if (_bs->test(hash2) == false)return false; // 如果第二个位为0,元素肯定不存在// 使用第三个哈希函数计算位置并检查size_t hash3 = Hash3()(key) % M;if (_bs->test(hash3) == false)return false; // 如果第三个位为0,元素肯定不存在return true; // 所有位都为1,元素可能存在(但有误判可能)
}解释:
test函数一般就是接收一个字符串,然后检查这个字符串是否存在于海量的数据中 ;只需要检测这个字符串的三个位的值是否为1即可,但凡一个不是,则一定不存在;反之都是1,则有可能存在,但这个存在有误判的可能性!
⑤:reset函数
布隆过滤器一般不支持删除操作,原因如下:
1:因为布隆过滤器判断一个元素存在时可能存在误判,因此无法保证要删除的元素确实在布隆过滤器当中,此时将位图中对应的比特位清0会影响其他元素。
2:此外,就算要删除的元素确实在布隆过滤器当中,也可能该元素映射的多个比特位当中有些比特位是与其他元素共用的,此时将这些比特位清0也会影响其他元素。
⑥:布隆过滤器总代码
#include<bitset>
#include<string>struct HashFuncBKDR
{// BKDRsize_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 131;hash += ch;}return hash;}
};struct HashFuncAP
{// APsize_t operator()(const string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶数位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇数位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));}}return hash;}
};struct HashFuncDJB
{// DJBsize_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};//
template<size_t N, class K = string, class Hash1 = HashFuncBKDR, class Hash2 = HashFuncAP, class Hash3 = HashFuncDJB>class BloomFilter
{
public:void Set(const K& key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;_bs->set(hash1);_bs->set(hash2);_bs->set(hash3);}bool Test(const K& key){size_t hash1 = Hash1()(key) % M;if (_bs->test(hash1) == false)return false;size_t hash2 = Hash2()(key) % M;if (_bs->test(hash2) == false)return false;size_t hash3 = Hash3()(key) % M;if (_bs->test(hash3) == false)return false;return true; // 存在误判(有可能3个位都是跟别人冲突的,所以误判)}private:static const size_t M = 10 * N;//bit::bitset<M> _bs;std::bitset<M>* _bs = new std::bitset<M>;
};
⑦:测试代码
测试1:少量数据
void TestBloomFilter1()
{string strs[] = { "百度","字节","腾讯" };BloomFilter<10> bf;for (auto& s : strs) { bf.Set(s); } // 插入测试数据// 测试已存在元素for (auto& s : strs) { cout << bf.Test(s) << endl; }// 测试相似但不存在的元素for (auto& s : strs) { cout << bf.Test(s + 'a') << endl; }// 测试完全不相关元素cout << bf.Test("摆渡") << endl;cout << bf.Test("百渡") << endl;
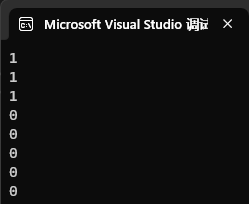
}运行结果:
解释:
1:先插入了"百度","字节","腾讯"这三个字符;
2:第二个for循环就是检查这已经存在三个字符,所以三个1了;
3:第三个for循环检测三个分贝于"百度","字节","腾讯"想进的字符串,都不存在,所以三个0;
4:最后再检测两个完全不相关元素,肯定不存在,所以两个0;
所以运行结果符合预期~
Q:不是说会有误判的可能性吗,为什么这里全对呢?
A:数据量太少,要海量数据,才会有极低的误判率~
测试2:海量数据
void TestBloomFilter2()
{srand(time(0));const size_t N = 10000000; // 10万数据量BloomFilter<N> bf;// 生成并插入N个相似字符串(如"猪八戒0"..."猪八戒99999")std::vector<std::string> v1;std::string url = "猪八戒";for (size_t i = 0; i < N; ++i) {v1.push_back(url + std::to_string(i));bf.Set(v1.back());}// 生成相似但不存在的字符串(如"猪八戒999990"...)std::vector<std::string> v2;for (size_t i = 0; i < N; ++i) {v2.push_back(url + std::to_string(99999 + i));}// 计算相似字符串的误判率size_t n2 = 0;for (auto& str : v2) {if (bf.Test(str)) ++n2; // 统计误判次数}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 生成完全不相似字符串(如"孙悟空123456")std::vector<std::string> v3;for (size_t i = 0; i < N; ++i) {v3.push_back("孙悟空" + std::to_string(i + rand()));}// 计算不相似字符串的误判率size_t n3 = 0;for (auto& str : v3) {if (bf.Test(str)) ++n3;}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}解释:
代码逻辑:
运行结果:

可以看出,当数据较多的时候,就会有误判了,但是由于哈希函数较多,所以误判率极低
三:优缺点
①:布隆过滤器的优点
1:增加和查询元素的时间复杂度为O(K)(K为哈希函数的个数,一般比较小),与数据量大小无关。
2:哈希函数相互之间没有关系,方便硬件并行运算。
3:布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
4:在能够承受一定的误判时,布隆过滤器比其他数据结构有着很大的空间优势。
5:数据量很大时,布隆过滤器可以表示全集,其他数据结构不能。
6:使用同一组哈希函数的布隆过滤器可以进行交、并、差运算。
②:布隆过滤器的缺陷
1:有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再自建一个白名单,存储可能会误判的数据)
2:不能获取元素本身。
3:一般情况下不能从布隆过滤器中删除元素。
四:适用场景
Q:我们需要这种存在误判的数据结构吗?
A:使用布隆过滤器的前提是,布隆过滤器的误判不会对业务逻辑造成影响。
举个例子:
我们注册游戏ID的时候,显式ID已被占用,我们只能换其他的!但占用有可能是误判,但这对这游戏和游戏公司有丝毫的坏处吗,没有吧~